HPEC中子程序级推测并行性分析
2020-08-19王欣夷王耀彬卜得庆刘志勤
王欣夷,王耀彬,李 凌,杨 洋,卜得庆,刘志勤
(1.西南科技大学 a.计算机科学与技术学院; b.四川省军民融合研究院,四川 绵阳 621010;2.四川省计算机研究院,成都 610041)
0 概述
随着半导体工艺的发展,单个芯片上的核心数量不断增加,其为芯片带来了更多的可用计算资源[1],但如何充分利用这些片上计算资源成为目前亟待解决的问题。程序并行化是有效利用现有片上计算资源的一种手段,但手动并行化方法较为繁琐且容易出错,因此,线程级推测(Thread-Level Speculation,TLS)技术受到广泛关注[2]。
TLS技术作为一种支持多核处理器的自动并行化技术,可有效提高并行化效率,并在不违反串行执行语义的情况下,将串行代码划分到多个线程中并行执行,自动挖掘程序潜在并行性,进而提高片上硬件计算资源利用率[3-5]。在TLS技术中,由于子程序和循环迭代在程序中运行时间较长,常将其作为推测线程的候选区域[6]。目前,TLS技术的研究主要以循环迭代为主,并未在子程序方面进行深入分析。由于子程序中局部变量的作用范围通常在其内部,局部变量的访问极少与作用域外的程序产生数据依赖,具有较好的独立性[7],因此对TLS技术的子程序级进行深入分析是很有必要的。
早期研究主要通过比较单位时间内运行指令数的多少来评测处理器性能,其衡量标准过于单一,并不能系统地评测处理器多方面因素所造成的影响。相较而言,20世纪80年代提出的benchmark更为业界所认可。HPEC基准套件由麻省理工学院研发,旨在为信号处理、通信等领域提供一套明确定义的基准,以对其库和系统的性能进行评测[8]。目前,该基准套件已在GPU、DSP以及基于VSIPL++的并行应用程序接口(Application Programming Interface,API)等方面得到应用,但并未使用TLS技术,特别是在子程序级方面未对其进行深入研究。
本文对HPEC应用在子程序级推测并行化中的并行性提升潜力和运行时的影响因子进行分析。通过选取HPEC中7个具有代表性的程序,设计一种子程序结构的动态剖析机制,结合用于保存子程序调用的核心数据结构,分析线程粒度、可推测并行区域覆盖率、线程间数据依赖、子程序调用次数以及程序源代码对程序并行化性能提升潜力的影响,并结合推测执行结果分析程序加速比的主要影响因素。
1 相关工作
在对TLS技术的软硬件支持[9]进行综合研究后,各种线程推测方案相继出现,较为典型的方案包括Hydra多处理器[10]、POSH线程级推测系统[11]、SMA系统[12]等。文献[13-14]使用基于模糊聚类的推测多线程划分算法对Olden程序进行测试,其加速比平均可达1.85。文献[15]在硬件事务内存上进行线程级推测,其循环结构获得3.8倍的加速。文献[16]对反向传播神经网络等应用的线程级推测并行性进行了分析。综上所述,线程级推测技术已能有效地运用在多种类型的串行应用自动并行化工作中。
目前,关于HPEC的研究集中在循环结构方面。文献[17]在GPU上开发了HPEC基准测试的高效实现方案,并在GPU和DSP上比较其性能和功效,结果显示,HPEC在DSP上的实现效果更好。文献[8]使用VSIPL++的并行API分析HPEC中存在的数据并行性,其在大多数情况下产生的加速比是线性或超线性的。文献[18]使用HPEC评估OpenSPARC处理器在Virtex-5FPGA上的性能,发现复制浮点单元消耗小,可对浮点应用程序的性能产生显著影响。然而目前,研究人员仍未对HPEC的子程序级线程推测方面进行深入分析。
2 推测执行模型与剖析机制
2.1 推测执行模型
图1(a)和图1(b)分别为传统程序的串行执行过程和基于线程级推测技术的子程序并行执行过程。线程级推测技术在程序执行到需要被推测执行的子程序时,其推测处理器会创建新的线程执行子程序代码,主处理器对子程序返回值进行预测,并使用该预测值执行后续代码。当推测处理器中的子程序执行完成后,会通知主处理器。主处理器将子程序预测值与推测线程中子程序的返回值进行比较,若结果相同,程序继续运行,否则程序跳转至子程序调用的返回点并重新运行。可以看出,在推测执行期间只有一个非推测线程,并且仅允许非推测线程将结果提交到内存[19]。

图1 子程序结构的推测执行模型Fig.1 Speculative execution model of subroutine structure
2.2 剖析机制
程序剖析是一种根据程序运行时的信息,动态分析程序运行特征的方法,其主要目的是得到函数执行次数、执行时间以及代码覆盖率等性能数据[20]。本文设计了一种针对子程序的剖析工具Profun,该分析工具能够提供程序在推测执行时的可推测并行区域覆盖率、线程粒度、线程间数据依赖等关键信息,从而指导程序员或编译器对串行程序进行并行划分。
子程序结构的剖析流程如图2所示,其具体过程如下:
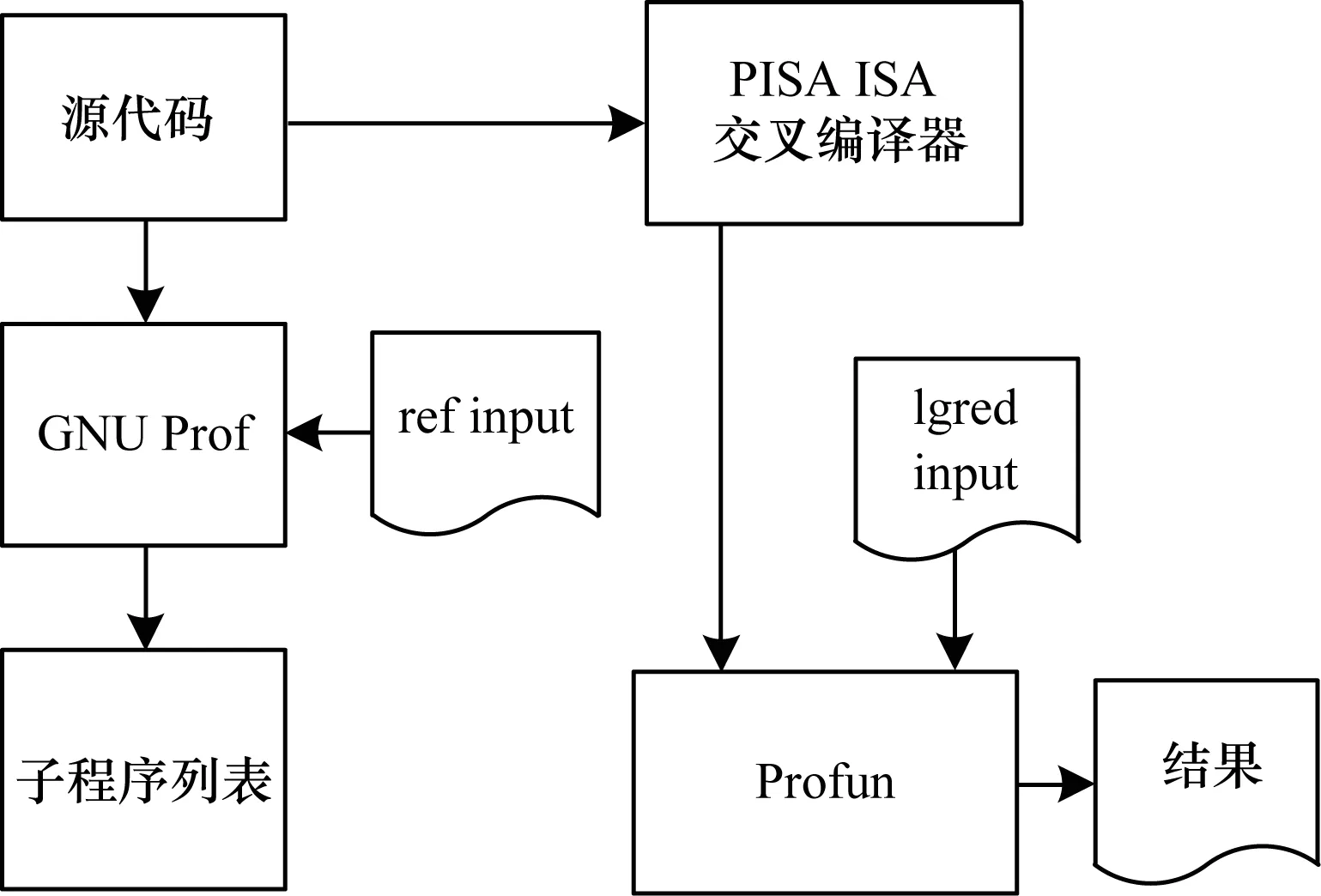
图2 子程序结构剖析流程Fig.2 Analysis procedure of subroutine structure
1)使用GNU Prof工具对程序进行初步分析,得到该程序的函数间调用关系、每个函数运行时间的比例以及函数调用的层次关系等。
2)结合上述信息,选出占程序运行时间5%以上的热点片段作为热点剖析区域。
3)交叉编译器对程序源代码进行编译,生成可执行的二进制代码文件。
4)剖析工具通过识别汇编文件中的jr、jal和jarl指令,结合候选热点区域文件对热点区域进行剖析,并根据关键因素(可推测并行区域覆盖率、线程粒度、线程间数据依赖)的量化分析,得到剖析结果。
为获取更多程序调用的行为信息,本文使用针对PISA指令集的反汇编工具objdump4pisa,将二进制代码反汇编成汇编文件。程序源码及其部分汇编代码如图3所示,可以看出,子程序返回地址被保存在31号寄存器中,全局变量sum被保存在28号寄存器中,在对sum进行运算前,将其加载到2号寄存器,运算结束后将结果保存到3号寄存器中。

图3 子程序反汇编代码示例Fig.3 Example of disassembly code of subroutine
图4给出子程序剖析的核心数据结构。其中,call_list结构记录待剖析子程序结构的每一次调用与返回时间,其每一项对应一个call_list_entry_t结构,且每个call_list_entry_t对应n个call_t结构,call_t用于记录函数被调用的相关信息。Hash_list结构用于记录对存储器的写操作,当程序存在大量子程序调用时,通过Hash_list中的call_list_head与call_list_tail遍历查找,即可快速找到该子程序结构的某次特定调用。

图4 子程序剖析的核心数据结构Fig.4 Core data structure of subroutine analysis
程序对所有全局数据段的数据读写操作保存在如图5所示的last_write_hash_list结构中。在执行到待剖析子程序时,该子程序在执行读操作时会被剖析工具拦截,通过对last_write_hash_list结构进行检索,获得其最后一次写操作的时间。如果最后一次写操作的时间大于当前时间,则将其替换为当前时间,并保存串行版本的运行时间,上述2个时间的比值即为最终加速比。

图5 last_write_hash_list数据结构Fig.5 Data structure of last_write_hash_list
3 性能影响因素
影响子程序线程级推测的因素包括线程粒度、可推测并行区域覆盖率、子程序调用次数以及线程间数据依赖。
线程粒度过小会导致推测执行过程中产生的开销增多,影响并行效果;线程粒度过大可能会出现错误冲突,从而导致不必要的推测线程压缩。此外,线程粒度不一致可能会导致负载不平衡。在推测执行过程中,子程序调用次数过少会影响程序性能提升潜力,进而影响程序加速效果。
数据依赖是影响程序推测并行化性能提升潜力的一个重要因素。本文将线程间的数据依赖关系简化为数据生产者与数据消费者之间的关系,生产数据即对存储器的写操作,消费数据即对存储器的读操作。在剖析工作中,使用生产距离与消费距离的比值分析线程间的数据依赖关系。
将生产距离定义为最后一次写操作到线程开始执行之间的指令数,消费距离定义为第一次读操作到线程开始执行之间的指令数,如图6所示。当消费距离小于生产距离时,数据依赖冲突发生的可能性极大。定义α=消费距离/生产距离,α值越小,数据依赖程度越严重。当0<α<0.4时,数据依赖程度为重度数据依赖;当0.4<α<1时,为轻度数据依赖;当α>1时,为安全数据依赖,不会发生数据依赖冲突;当α趋近于0时,推测线程间的执行方式类似于程序的串行执行方式。

图6 生产距离与消费距离的定义Fig.6 Definition of production distance and consumption distance
综上所述,线程粒度大小适中、可推测并行区域覆盖率高、子程序调用次数多、线程间数据依赖程度较轻的程序能获得较大的性能提升。
4 实验结果与分析
4.1 实验环境
本文实验平台为基于Linux的Ubuntu 14.04开发版本,指令集采用Simplescalar工具集的PISA指令集,编译器采用Simplescalar工具集中提供的经过后端改造的gcc-2.7.2.3。为了使剖析时间能更好地适应编译器整体开销,剖析器采用基于Simplescalar工具集中功能模拟器sim-fast修改扩充的版本,该模拟器每个周期可执行一条指令。本文选取HPEC中7个具有代表性的程序,所选程序及其介绍如表1所示。

表1 测试程序相关信息Table 1 Relevant information of testing program
4.2 结果分析
4.2.1 加速比
在最大程度地挖掘程序性能潜力后,程序加速比的结果如表2所示。可以看出,大部分程序的性能提升效果较好,程序加速比都在2以上。其中,tdfir程序的加速比达到221.78,而文献[17]通过循环结构对tdfir程序进行加速,所得加速比为28.80,因此,tdfir程序非常适合采用子程序级线程推测技术开发并行性。此外,ct程序和pm程序的程序性能提升效果较差,加速比仅为1.00。

表2 程序最大加速比Table 2 Maximum acceleration ratio of programs
4.2.2 子程序调用次数
7个测试程序的子程序调用次数的对比结果如表3所示。由表3可知,子程序调用次数较少的程序为ct、pm以及svd程序中的mat_mult_cx_by_real程序,并且在所有测试程序中,以上3个程序的加速比相对较小。此外,ct程序和pm程序中只存在一个子程序,其调用次数为1,因此,子程序调用可能是造成ct和pm程序并行性差的主要原因。对于svd程序,其仅有一个子程序的调用次数较少,其他子程序的调用次数较多,因此,需综合考虑性能影响因素对程序加速效果的影响。
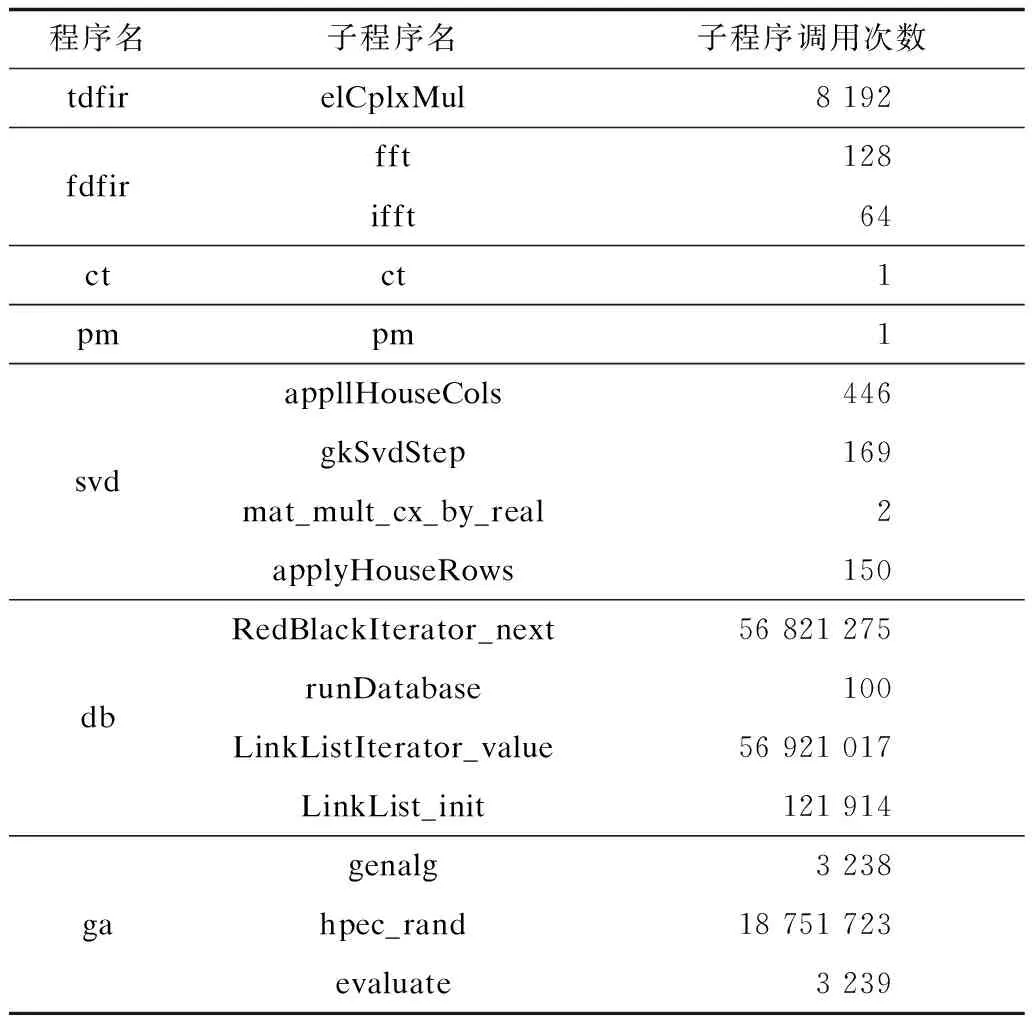
表3 子程序调用次数对比Table 3 Comparison of number of subroutine calls
4.2.3 可推测并行区域覆盖率
根据Amdahl定律,程序推测并行区域覆盖率越高,可并行性越好。图7给出7个程序的可推测并行区域覆盖率对比。可以看出,所有的测试程序可并行化区域都在90%以上,其中,fdfir、tdfir、ct、pm程序的并行区域达到100%,因此,应着重考虑其他因素对程序并行性的影响。

图7 并行区域覆盖率对比Fig.7 Comparison of coverage rate of parallel regions
4.2.4 线程粒度
所选测试程序的线程粒度如图8所示。可以看出,多数子程序的线程粒度都在105~108,但Hydra项目组提出线程最适宜的粒度应为102~104,因此,可能会出现线程粒度太大而造成处理器缓存溢出的情况。ct、tdfir、pm程序中的线程粒度均匀,但其线程粒度过大仍是造成加速比不高的主要原因。svd、db和ga程序中存在线程粒度过大和不均匀的情况。综合以上情况,线程粒度可能对大部分测试程序的加速效果产生影响。

图8 程序的线程粒度对比Fig.8 Comparison of program granularity
4.2.5 线程间数据依赖关系
本文第2节给出生产距离、消费距离和α的定义,并将数据的依赖程度分为重度依赖、轻度依赖和安全依赖。7个程序的线程间数据依赖对比如图9所示。可以看出,ga、db、svd以及tdfir程序的线程间数据存在轻度和重度依赖,其中svd、db、ga程序中存在重度数据依赖,虽在程序中所占比例较小,但也可能会对程序加速效果造成影响。此外,大部分程序中的依赖关系属于安全依赖,fdfir、ct和pm程序中安全依赖的比例达到100%,因此,可考虑其他因素对fdfir、ct和pm程序性能提升的影响。

图9 线程间数据依赖关系对比Fig.9 Comparison of data dependency results of threads
4.2.6 加速比综合分析
本文结合上述性能影响因素以及源码,分析7个测试程序加速比的原因,具体如下:
1)tdfir、fdfir程序同属有限脉冲响应滤波器。tdfir程序的加速比最高,达到221.78,其主要原因是子程序在双层嵌套循环中,使得该函数的调用次数较大,因此,即使tdfir存在轻度数据依赖,程序也能获得较高加速比。fdfir程序的加速比为10.49,综合各种性能影响因素后发现,程序中仅存在安全数据依赖,子程序的线程粒度大小较为合适,并在程序运行时对子程序进行多次调用,因此,fdfir程序的加速效果较好。但tdfir子程序的调用次数远高于fdfir,导致fdfir程序加速比低于tdfir程序。
2)db程序的加速比为11.31。综合推测结果发现,db程序存在重度数据依赖和线程粒度大小不均匀的问题,但重度数据依赖的比例小于1%。对源代码进行分析发现,存在重度数据依赖的子程序调用了存在安全数据依赖的子程序,被调用子程序的并行化区域比调用子程序大65%左右,并且被调用子程序的调用次数也远高于调用子程序,因此,即使调用子程序存在重度数据依赖,其最终加速比依然较高。
3)ga程序的加速比为3.17,该程序中存在不同程度的数据依赖,并且线程粒度大小不均匀。分析程序源代码后发现,可推测并行区域覆盖率最高的子程序中调用了其他2个子程序。第1个被调用子程序为一个返回值类型为float的随机函数,在程序推测执行过程中,将返回值与预测值进行多次对比。第2个被调子程序中存在对指针变量的操作,因此,程序存在不同程度的数据依赖,但ga程序中子程序的调用次数较多,其性能提升潜力较大。
4)svd程序的加速比为2.23。综合影响因素以及加速比可知,svd程序的线程粒度不均匀,且线程粒度较大,程序中还存在不同程度的数据依赖。由于安全依赖的占比远远大于重度依赖和轻度依赖的占比,因此线程粒度较大是影响svd程序加速效果的主要原因。但是,svd程序中其他子程序的调用次数较多,因此,程序最终获得较好的加速效果。
5)ct、pm程序的加速比为1.00。综合分析性能影响因素发现,ct、pm程序中仅存在一个子程序且其调用次数都为1次。因此,即使ct和pm程序中仅存在安全数据依赖,程序的加速效果也不理想。
综上所述,子程序中存在的重度或者轻度数据依赖会对程序性能提升产生影响,但子程序调用次数与线程间数据依赖情况成反比。因此,即使子程序存在少量重度或者轻度数据依赖,程序仍可在子程序调用次数较多的情况下获得较高的加速比。
5 结束语
本文基于线程级推测技术对HPEC基准测试集中的7个程序进行分析。通过Profun分析工具获取程序在执行推测时的可推测并行区域覆盖率、线程粒度、线程间数据依赖关系等关键信息,从而对串行程序进行热点区域划分。利用交叉编译器编译程序源代码,并结合热点区域文件实现量化分析。分析结果表明,7个程序中有5个程序能获得较好的加速效果,其中,tdfir程序的加速比达到221.78,远高于通过循环结构所得的加速比,其更适合采用子程序级的TLS技术挖掘潜在并行性。对于存在较多轻度和安全数据依赖的子程序调用,采用子程序级线程推测技术可获得较好的加速效果。虽然HPEC中部分测试程序不宜采用子程序级TLS进行推测加速,但其代码中存在大量可推测的循环迭代,下一步可通过循环级TLS技术挖掘其推测并行性,并与本文工作进行对比,以找到更适合此类程序的线程级推测方式。
