基于改进时间卷积网络的日志序列异常检测
2020-08-19杨瑞朋朱少卫钱叶魁唐永旺
杨瑞朋,屈 丹,朱少卫,钱叶魁,唐永旺
(1.中国人民解放军战略支援部队信息工程大学 信息系统工程学院,郑州 450002;2.中国人民解放军陆军炮兵防空兵学院(郑州校区),郑州 450002)
0 概述
随着网络应用和系统规模的不断增大,程序的执行路径难以预测,并且硬件环境不再可靠,难以在部署前发现可能发生的错误。另一方面,随着互联网的不断发展,各类网络应用在生产生活中发挥着越来越重要的作用。但与此同时,网络环境日益复杂,针对网络应用和系统的攻击不断涌现,且攻击形式多样。一旦针对网络应用和系统的攻击成功或者网络应用自身出现异常,将给应用的所有者及用户带来不可估量的损失。攻击和错误越早发现,所能采用的补救措施就越多,造成的损失就会越少[1]。因此,研究异常检测技术具有非常重要的意义。
在网络应用运行的过程中,应用本身和监控程序都会产生各类日志来记录应用的状态、重要的运行事件和网络流量,因此日志包含应用运行的动态信息,适合用于异常检测。通过日志对网络行为和系统分析的异常检测技术能够充分挖掘、利用网络内在信息及其相互关系,具有较好的灵活性、适应性,已成为目前异常检测领域的研究热点[2-4]。因日志本身就是序列数据,日志的出现序列有一定的依赖关系,且有时依赖的长度较长。如一些新型攻击一旦实施,并不会立即产生破坏,而是达到某些先决条件,或是进行某些正常操作后才产生破坏,体现在日志序列中即长时依赖关系。
为更好地挖掘长时依赖关系,本文提出一种基于时间卷积网络(Temporal Convolutional Network,TCN)的日志序列异常检测框架TCNLog。时间卷积网络基于卷积神经网络,是一种能够处理时间序列数据的网络结构。TCN引入padding机制,使模型的输入和输出长度相同,同时卷积后的特征较少丢失。该框架避免传统机器学习方法复杂的特征提取步骤,并借助于深度学习强大的自动学习特征的能力[5],将经过充分训练的日志模板的语义向量表示输入TCN网络,其中的空洞卷积机制能获取日志序列更大的感受视野,实现没有“漏接”的历史信息,以更好地解决序列的长时依赖问题。
1 相关工作
异常检测是保障网络和系统安全的支撑技术之一,目前流行的异常检测方法主要有基于网络流量的异常检测、基于恶意代码的异常检测和基于社交网络安全事件的异常检测[6]。但是网络流量异常检测技术容易漏过宽时间域内的网络攻击。此外,现代网络攻击往往是多种攻击手段的组合,而网络流量异常检测技术的数据源种类较为单一。因此,传统网络流量异常检测技术存在局限性。恶意代码异常检测技术可以有效检测数量快速增长的未知恶意程序。然而,新型攻击中恶意代码伪装性和隐蔽性很高,恶意代码异常检测技术在应对仍然存在时空关联能力差和漏检率较高等问题。社交网络安全事件挖掘技术可以识别用户行为异常,并为攻击检测提供指导,但社交网络中蕴含的攻击信息毕竟有限,该技术需要与其他异常检测技术配合使用,才能更有效地检测网络攻击。
日志中蕴含着丰富的信息,面向异常检测的日志挖掘作为近几年新兴的一类检测手段,是建立安全可信计算机系统的一项重要任务,具有攻击问题分析准确、攻击链可重构性等特点。传统日志分析通过人工检验或者使用事先定义好的异常规则来实现。当日志大小有限以及异常类型可知时,这些方法十分有效并且也比较灵活,但是对于当前程序产生的百万行规模的日志,人工检测很难实现[7],提前获取所有可能的异常也很困难[8]。随着系统和应用程序变得越来越复杂,攻击者可能会利用更多的漏洞和弱点来发起攻击。这样,攻击也变得越来越复杂,且日志的数据量太大,非结构化、没有领域知识、不易理解等都给分析造成很大的挑战。因此,面向异常检测的日志挖掘更具挑战性。
随着机器学习的发展,有很多研究采用特征工程,利用各种聚类[9]的方法发现异常点用于异常检测。并且大量的异常检测日志挖掘方法是为不同应用设计的,这种方法虽然准确,但是仅限于特定场景的应用并且需要领域专家。基于日常序列的异常检测方法也被广泛研究。文献[10]将痕迹视为序列数据,并使用基于概率后缀树的方法来组织和区分序列所具有的重要统计特性。随着深度学习的发展,循环神经网络在序列数据中有很好的应用,一些学者对日志序列的异常检测问题运用循环神经网络模型进行一些尝试。文献[11]对来自多个日志源的原始日志文本使用聚类技术生成特征序列,并输入到LSTM模型中以进行故障预测。文献[12]对系统日志的原始文本解析,生成日志模板序列输入LSTM以检测拒绝服务攻击。最近的研究[13]表明,将时间卷积神经网络应用到序列任务中,特别是处理长时依赖关系时,具有比循环神经网络更好的效果。
对比传统的日志序列异常检测方法,本文的主要贡献主要有以下3个方面:
1)提出一种基于时间卷积网络的日志序列异常检测框架,实验验证该框架在更长序列上有很好的异常检测能力。
2)分析并对比了不同激活函数在异常检测模型中的效果,说明了PReLU激活函数在该问题中的适用性。
3)分析了网络中全连接层参数量大的不足,提出了用自适应平均池化层代替全连接层,将1×1卷积层与全连接层进行对比,证明了自适应平均池化层的优势。
2 基于TCN的异常检测框架
时间卷积网络是一种基于卷积神经网络的能够处理时间序列数据的网络结构。该网络具有两个特点:一是网络的输入长度和输出长度相等;二是没有漏接的历史信息。为使网络输入和输出长度相等,TCN网络采用一维全卷积,并在每层加入0-padding以实现输入长度和输出长度相等;为实现序列建模任务,引入因果卷积[14],当序列长度增加时,为不遗漏历史信息,需要增加网络深度,但增加了参数量。为解决该问题,TCN引入空洞卷积[15],在不增加参数量的前提下,尽量少地增加网络深度,扩大感受视野。增加网络深度会导致梯度弥散或梯度爆炸,但可通过确保中间的正则化层(Batch Normalization)解决该问题,这样可以确保几十层的网络能够收敛。虽然通过上述方法能够进行训练,但是又会出现退化问题。文献[16]提出残差网络来解决退化问题。TCN的网络结构如图1所示。

图1 TCN网络结构Fig.1 TCN network structure
一个日志文件包含多个事件类型,每个事件类型包含若干条日志,属于同一个事件类型的日志有共同的模板,可以把一个日志序列理解为发生的一系列事件,即原始日志序列对应的日志模板的序列。文献[17]从原始日志中进行日志模板的提取。本文的研究工作是:对原始日志序列对应的日志模板序列的异常进行检测,判定异常的依据为根据当前序列预测下一个日志模板,若预测值和实际模板相同,则认为正常,否则认为异常。
TCN结构中激活函数使用ReLU[18],虽然收敛速度快,但容易引起神经元“坏死”,无法学习到日志序列中更多的有效特征。另一个问题是检测框架中的全连接层相当于一个“分类器”,预测输入序列的下一个日志模板。如果能减少参数量,则能有效地避免网络的过拟合问题,但妨碍了整个网络的泛化能力。针对上述问题,本文对基于TCN的日志序列检测框架进行了改进,即改进激活函数与全连接层。异常检测框架TCNLog如图2所示。
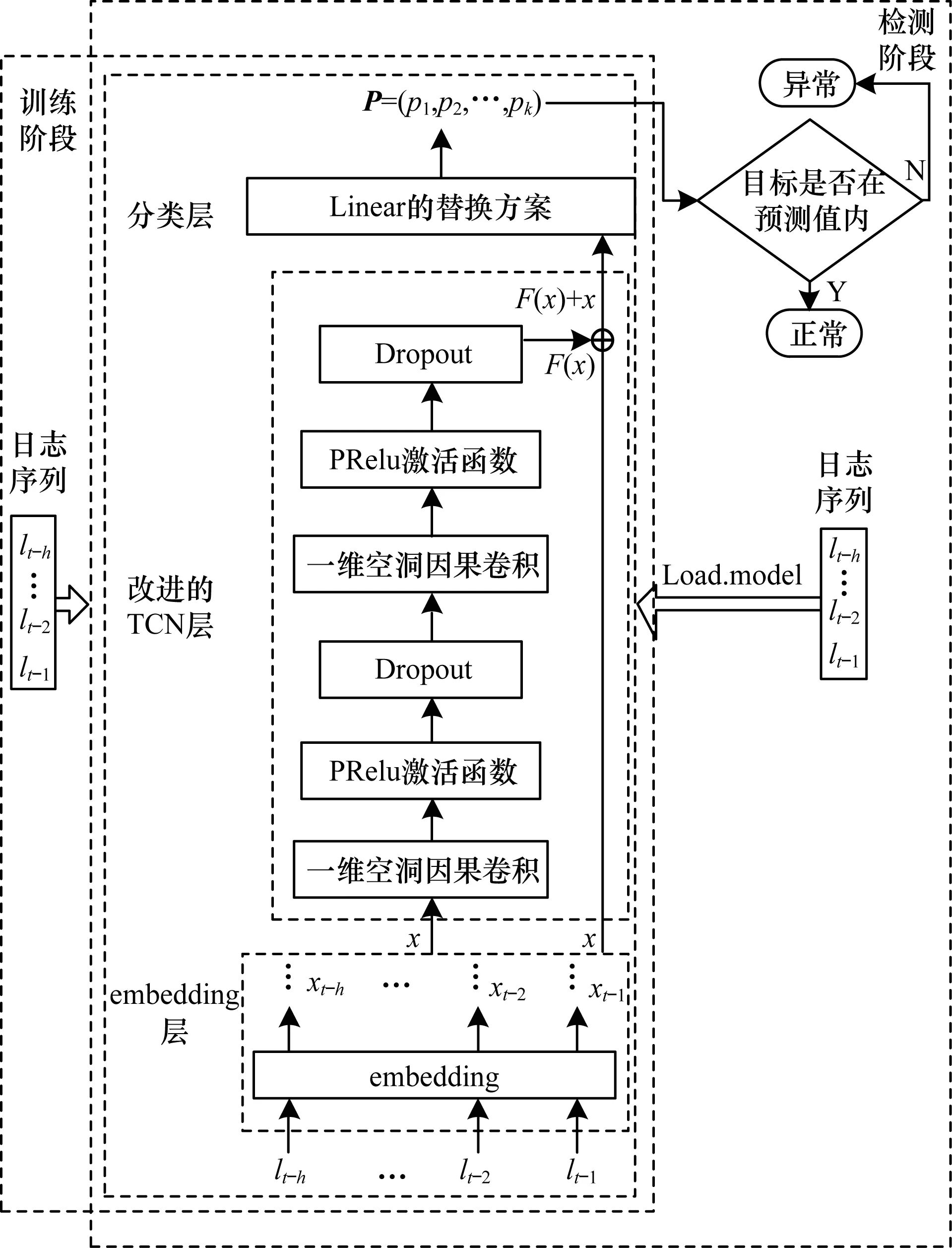
图2 日志序列异常检测框架TCNLogFig.2 Anomaly detection framework TCNLog of log sequence
2.1 激活函数的选择和改进
卷积神经网络具有很强的建模能力,特别是加入了ReLU激活函数后,能够表达输入日志序列间的非线性关系。但是对日志序列的预测效果好坏与网络训练的每个细节息息相关。本文从卷积神经网络的训练过程方面进行优化,对激活函数进行比较和选择。
原始TCN网络中使用的是ReLU激活函数。ReLU函数属于非饱和激活函数,在正数不饱和,在负数硬饱和,如图3(a)所示。它对正数原样输出,负数直接置零。幂运算更节省计算量,因而收敛较快,在CNN中常用。但ReLU也有缺点,即神经元“坏死”(ReLU在负数区域被kill的现象叫做坏死),ReLU强制的稀疏处理会减少模型的有效容量,特征被屏蔽太多,导致模型无法学习到有效特征。由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置0,而且这个神经元有可能再也不会被任何数据激活。例如,一个非常大的梯度流过一个ReLU神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象,那么这个神经元的梯度就永远都会是0。
为解决这一问题,文献[19]提出PReLU (Parametric Rectified Linear Unit)激活函数。带参数的ReLU如图3(b)所示,对应中的参数a是可学习的,根据任务数据来定义,而非预先定义。这样仅增加了一点额外的计算量和过拟合的风险,但提高了零值附近的模型拟合能力。当a=0时,PReLU退化成ReLU,当a是非常小的一个数如0.01时,PReLU退化成Leaky ReLU[20]。Leaky ReLU在负轴上的斜率是一个固定的较小的常数,虽然保留了一些负轴的值,使得负轴的信息不会全部丢失,但是这一事先指定的斜率不一定适合数据分布。激活函数ELUs如图3(c)所示。

图3 激活函数图像对比Fig.3 Comparison of activation function images
以上是对ReLU负轴上的优化策略,但对ReLU函数的正半轴不施加任何非线性约束,因此当输入为正大数时,易引起正半轴上的梯度爆炸。Relu 6如式(1)所示:
f(x)=min(max(0,x),6)
(1)
它对正半轴施加了非线性约束,但并没有消除神经元“坏死”,坏死区域为Relu的(-∞,0)~Relu 6的(-∞,0)∪(6,+∞)。
本文修改TCN网络中的激活函数ReLU为PReLU,初始化参数a=0.25,网络自动学习更新参数,在实验中,对Leaky ReLU、ELUs和ReLU 6激活函数进行比较。
2.2 检测模型
检测模型包含embedding层、改进的TCN层和自适应平均池化层。
2.2.1 embedding层
embedding层是把日志模板序列作为输入,用于异常检测框架的前端输入,将序列中的每个日志模板序号映射成密集的词嵌入。embedding层作为异常检测模型的一部分,生成词向量时需要指定维度,向量以小的随机数进行初始化,采用反向传播算法进行训练更新。和开源的预训练包Word2Vec和GloVe相比,embedding层虽然是一个较慢的方法,但可以通过模型训练为特定的日志数据集定制词嵌入。基于神经网络训练的词嵌入包含丰富的上下文信息,既可以很好地表现目标词在当前日志序列中的语义规则,又实现了降维的目的。
2.2.2 改进的TCN层
日志模板序列经过embedding层初始化后,需要以下步骤生成日志模板序列特征表示:
步骤1输入第一个一维空洞卷积层,并进行归一化。需要指明的参数包括日志模板词嵌入的维度、日志模板词典的大小、卷积核尺寸、步长、padding大小及是否加入空洞。
步骤2根据第一个卷积层的输出与padding的大小,对卷积后的张量进行切片来实现因果卷积。因果卷积是利用卷积来学习当前输入模型的日志序列中最后一个日志模板前的日志模板序列(长度h),来预测下一个日志模板,即该卷积层的输出仅依赖于序列步为1,2,…,h的输入,不会依赖于h+1以及之后的输入。
步骤3添加PReLU激活函数。
步骤4Dropout正则化方法完成第一个卷积块,Dropout是在训练神经网络模型时样本数据过少,防止过拟合而采用的策略。
步骤5堆叠同样结构的第2个卷积块,这样构成了一个残差块。
2.2.3 替代全连接层的方案
原始TCN之后加入全连接层是一种线性变换,转换成维数为日志模板词典的大小的概率向量P=(p1,p2,…,pk)(日志文件中包含k个日志模板),pi表示对当前序列预测的下一个日志模板为ei。假设序列长度为h,词向量的维度为embedding,日志模板词典大小为k,从参数量的角度考虑,全连接层需要学习的参数量是h×embedding×k。受文献[21]提出的全局平均池化思想的启发,即卷积后加一个全局平均池化层替换全连接层,因为池化不需要训练模型参数,所以减少了模型训练参数量。因为本文是采用一维全卷积,经过TCN卷积后的输出除去batch_size和序列长度外,是一个维度为词嵌入长度的一维向量,所以不能对该输出计算全局平均池化。经过TCN模型输出的形状batch_size×h×embedding,经过全连接层线性变换之后,输出形状变为batch_size×h×k,可以看出,仅是通道数的改变。为达到改变通道数的目的,防止过拟合并提高模型的泛化能力和准确率,本文在改进TCN模型基础上通过用自适应平均池化层(Adaptive Average Pooling,AAP)改变通道数,用池化层代替全连接层。在算法中只需要设置该层的输出维度为日志模板类别,自适应平均池化层会根据输入形状和输出维度的值,自动计算卷积核尺寸及步长,确定每一步的卷积区域,并求出在该卷积块上的均值。该算法的伪代码如下(以一维为例):
for 输出向量位置索引号←0 to 输出长度
卷积块起始位置= floor (索引号×输入长度/输出长度)
卷积块终止位置= ceil ((索引号+1)×输入长度/输出长度)
ks←(卷积块终止位置-卷积块起始位置)
for 当前卷积块的起始位置←0 to ks
sum (输入向量[卷积块起始位置,卷积块终止位置-1])
end
输出向量当前位置对应的值←(sum/ks)
end
在算法中,floor函数表示取下限,ceil函数表示取上限。
从自适应平均池化的执行过程可以看出,当输入长度mod输出长度≠0时,卷积核尺寸和步长并不是固定不变的,而且卷积块会在某些位置有重叠,池化操作后,每一维度的值可以理解为每个类别生成的一个特征值,向量中最大的特征值所在维度即为预测的日志模板编号。自适应平均池化层没有优化参数,提高了模型的训练时间和测试时间,避免在该层过拟合。自适应平均池化对网络在结构上做正则化处理,其直接剔除了全连接层中黑箱的特征,直接赋予了每个通道实际的类别意义。
2.3 模型训练
假设一个日志文件中包含k个日志模板E={e1,e2,…,ek},训练阶段的输入为日志模板的序列,一个长度为h的日志序列lt-h,…,lt-2,lt-1中包含的日志模板li∈E,t-h≤i≤t-1,且一个序列中的日志模板数|lt-h,…,lt-2,lt-1|=m≤h。为方便处理数据,首先将每个日志模板对应一个模板号,并生成日志模板词典,然后把正常的日志模板序列生成输入序列和目标数据代入异常检测模型进行训练。序列建模学习的目标是训练一个网络f使得模型输出和实际的日志模板之间的损失函数loss(lt,f(lt-h,lt-h+1,…,lt-1))最小,训练中的损失函数采用交叉熵。交叉熵误差函数的表达式为:
(2)
其中,yi是类别i的真实标签,pi是softmax计算出的类别i的概率值,k是类别数,N是样本总数。
对损失函数的优化采用自适应梯度下降法(Stochastic Gradient Descent,SGD)。在训练时,SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,下一次训练再随机抽取一组,再更新一次,因此,每次的学习速度较快。在样本量非常大的情况下,不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型。SGD最大的缺点在于每次更新可能并不会按照正确的方向进行,可以带来优化波动,这个波动会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,因此会使得迭代次数(学习次数)增多,即收敛速度变慢。为了加快收敛速度,在实验设置中,选择SGD梯度下降算法,并使用学习速率(learing rate,lr)退火调整。针对本文任务,经过多次实验,确定的退火方法为:lr=lr*(0.5**(epoch//10)),即每训练10次,学习率缩小2倍。
2.4 检测阶段
数据输入的方法同训练阶段,用训练阶段生成的模型进行异常检测,模型输出为一个概率向量P=(p1,p2,…,pk),pi表示目标日志模板为ei的概率,模型直接的输出实际上可以理解为多分类问题,但最后的结果为正常和异常的二分类问题,所以需要进一步判定。依据经验,特别是在日志模板数较少的情况下,一个输入序列的目标日志模板不止一种情况,认为P中的前g个大的概率值对应的日志模板是正常的。图2所示的“目标是否在预测值内”中的“预测值”是概率较大的前g个日志模板。如果实际目标数据在预测值内,则判定为该日志序列正常,否则判定为异常。
3 实验结果与分析
3.1 实验环境与数据集
本文的实验环境采用Ubuntu 16.04 LT,64位系统,62.8 GB内存,Processor Intel Xeon®CPU E5-2620v4 @ 2.1 GHz×16处理器,Graphic Geforce GTX 1080 Ti/PCIe/SSE2双GPU平台。实验日志数据为BlueGene/L (BGL)日志数据集。数据集BlueGene/L(BGL)[22]包含215天的4 747 963条原始日志,大小为708 MB。本文对BGL数据集不进行按固定时间窗进行划分,而是按模型参数中指定的序列长度进行划分并预测,并利用滑动窗口的方法取下一个序列。选择数据集80%的正常序列为训练集。数据集信息如表1所示。

表1 数据集信息Table 1 Data set information
3.2 评价标准
考虑到日志数据集多数是正常日志多、异常日志少的不平衡数据集。评价本文提出的基于时间卷积网络异常检测框架的检测性能,主要采用检测率、误报率、准确率3个指标,这样分别考察真实样本情况为异常日志序列和正常日志序列上的检测效果,而不受“不平衡”这一特性的影响。日志序列异常检测的混淆矩阵如表2所示。
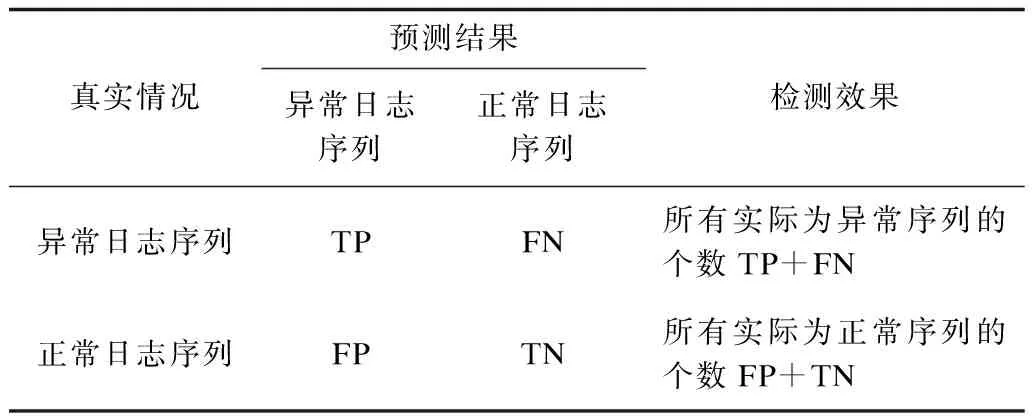
表2 日志序列异常检测混淆矩阵Table 2 Confusion matrix of log sequence anomaly detection
在表2中,TP表示异常日志序列被正确检测为异常的数量,FN表示异常日志序列被错误检测为正常的数量,FP表示正常日志序列被错误检测为异常的数量,TN表示正常日志序列被正确检测为正常的数量。对应的几项评价指标如下:
1)真正类率(True Positive Rate,TPR),又称为检测率,表示被正确检测为异常的异常日志序列数占异常日志序列总数的比率,值越大,性能越好。计算公式为:
(3)
2)假正类率(False Positive Rate,FPR),又称误报率,表示被错误检测为异常的正常日志序列占实际正常日志序列总数的比率,值越小,性能越好。计算公式为:
(4)
3)准确率(Accuracy),表示检测结果是正确的样本数占样本总数的比率,值越大,性能越好。计算公式为:
(5)
对测试集中的正常日志集和异常日志集,取和训练过程中相同的序列长度,分别载入已训练好的模型进行测试,如果模型对当前序列预测得到的前g个日志模板中不包含实际的下一个日志模板,则对正常日志序列集,FP加1,对异常日志序列集,TP加1。
3.3 参数设置
本文通过反复实验不同的参数组合,确定了模型的最优参数。后续实验均采用最优参数进行比对实验。词嵌入维度input_size设置为100,卷积核尺寸k设置为3,每层的隐藏单元数hidden设置为100,embedding层的dropout设置为0.25,卷积层的dropout设置为0.45,初始学习率设置为4,在检测阶段,如2.4节所述,g被设置为20。
3.4 结果分析
Deeplog[12]分析并验证了2层LSTM在日志序列异常检测的效果,本文在2层LSTM之上加上自注意力层,能更好地保留和控制序列的上下文信息,解决序列的长时依赖问题。文献[13]通过理论分析和对文本数据集的实验验证,得到TCN对更长序列有很好的建模能力。为了考察本文改进TCN的检测模型对日志长序列的异常检测能力,该实验选择自注意力机制的LSTM作为本文的对比模型,对不同序列长度分别用本文方法和“2层LSTM+自注意力层”异常检测模型进行比较,实验结果如图4所示。
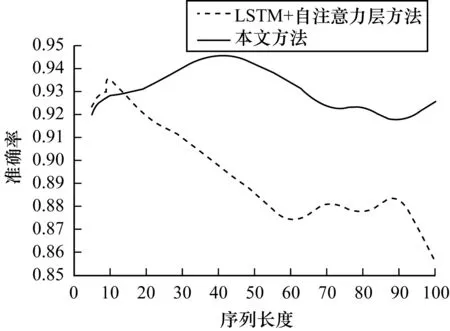
图4 两种方法对不同序列长度的准确率比较Fig.4 Accuracy comparison of two methods for different sequence lengths
从图4可以看出,在序列长度seq_len≤10时,“LSTM+自注意力层”有更好的检测能力;但seq_len>10时,“LSTM+自注意力层”在seq_len>10之后,准确率快速下降,而本文方法有很明显的检测优势。主要原因是LSTM的记忆门和忘记门在忘记不再需要的记忆并保存输入信息的有用部分后,会得到更新后的长期记忆,但隐含层的输入对于网络输出的影响随着序列长度的不断增加而衰退,丢失了很多细节信息。文献[23]表明,当序列长度非常长(>100 s)时,LSTM很难训练。时间卷积网络对长时间数据来建模,能调整感受野的长度以及卷积核大小灵活调整可以学习的序列的长度。本文的检测模型在给定的参数设置下,实验结果显示,在seq_len=40时,最好的检测准确率为0.945 56,并在seq_len=70后,有相对稳定的检测效果,可见本文的改进模型有更好的鲁棒性。
为考察不同激活函数对模型检测的影响,取序列长度h=100时,分析“TCN+AAP”中时间卷积网络分别采用PReLU、Leaky ReLU、ReLU6和ELUs激活函数的检测性能,实验结果如图5、图6所示。

图5 不同激活函数检测性能对比Fig.5 Comparison of detection performance of different activation functions

图6 不同激活函数对损失函数的影响Fig.6 Effect of different activation functions on loss function
从图5可以看出,在采用PReLU时,检测模型取得了最高的准确率和最低的误报率,综合性能评价最优。从图6可以看出,虽然采用不同的激活函数收敛速度相当,但采用PReLU时,有最小的损失函数值。
为考察自适应均值池化层替换全连接层后对检测模型精度的影响,在序列长度h=100时对比了时间卷积网络分别采用TCN+Linear、TCN+AAP、改进的TCN+AAP和改进的TCN+Linear 4组检测结果,如表3所示。从误报率、检测率和准确率3个指标可以看出,采用同样的下层网络结构连接全连接层和自适应均值池化层后,对日志序列的异常检测能力均得到了提高。如下层网络用TCN时,采用自适应均值池化层比全连接层误报率降低了4.483%,检测率提高了1.589%,准确率提高了3.661%;下层网络用改进TCN网络时,采用自适应均值池化层比全连接层误报率降低了3.237%,准确率提高了2.325%。因此,自适应均值池化层代替全连接层后不仅该层的参数量从h×embedding×k降低到了0,而且检测性能得到有效提升。

表3 自适应池化层对检测性能的影响Table 3 Influence of adaptive pooling layer on detection performance
文献[21]提出1×1卷积核可用来改变通道数,本文实验设置在基线模型基础上通过用1×1卷积核改变通道数,进行卷积层代替全连接层及数据标准化处理。设置输出通道数为日志模板类别,卷积后每一维度的值可以理解为每个类别生成的一个特征值,向量中最大的特征值所在维度即为预测的日志模板编号。采用1×1卷积核用到的参数量为:1×embedding×k,和全连接层相比,当序列长度时间很长时,有效降低参数量。这种通过强制特征值和类别之间的对应,是对卷积结构更原始的反映。
为比较自适应池化层和1×1卷积核在检测模型上的准确率和收敛速度,取序列长度h=100时,分别对改进的TCN + AAP和改进的TCN + 1×1卷积核以及改进的TCN + Linear进行50轮实验,从图7可以看出,采用自适应均值池化层,在epoch=10之前,检测准确度振荡上升,之后准确度相对稳定,在epoch=33时,达到最大的准确率0.925 35;采用Linear全连接层,在epoch=4时,达到89.319%的准确率,在epoch=20时,可以达到最大的准确率0.900 44,采用1×1卷积核,在epoch=12之前,检测准确度振荡快速上升,之后有个相对稳定的准确度,在epoch=37时,达到最大的准确率0.870 96。可以看出,采用自适应均值池化和1×1卷积核2种方案收敛速度相当,但采用自适应均值池化的准确率明显高于采用1×1卷积核。采用Linear全连接层,收敛速度较快,但准确率不及采用自适应均值池化。自适应均值池化层既不含训练参数,又达到了比使用Linear全连接层和1×1卷积核更高的准确率。

图7 最后一层对准确率和收敛速度的影响Fig.7 Effect of last layer on accuracy and convergence speed
4 结束语
日志中蕴含了丰富的网络和系统信息,通过分析日志可以检测异常行为和挖掘潜在安全威胁。现有基于循环神经网络的日志序列异常检测模型对较短序列有很好的检测能力,但对长序列的检测存在不足,针对时间卷积网络中的激活函数ReLU容易引起神经元“坏死”,以及无法学习到日志序列中更多有效特征的特点,本文提出用带参数的ReLU替换ReLU。针对全连接层因参数量较多,容易引起过拟合的问题,提出用不需要参数量的自适应平均池化层替换全连接层,准确率提高5.886%。实验结果表明,该检测框架用于日志序列异常检测的总体准确率优于TCN+Linear等方法,且自适应池化层不需要参数量。下一步将研究异常检测关键技术,进行异常定位并分析异常原因。
