面向区块链交易可视分析的地址增量聚类方法
2020-08-19王劲松吕志梅赵泽宁张洪玮
王劲松,吕志梅,赵泽宁,张洪玮
(天津理工大学 a.计算机科学与工程学院; b.天津市智能计算及软件新技术重点实验室;c.计算机病毒防治技术国家工程实验室,天津 300457)
0 概述
比特币自2009年问世以来,就因具有分布式、匿名性、可溯源等与传统货币不同的特征而发展迅速,此后各种类似的加密货币也随之出现。根据CoinMarketCap的统计数据,到2019年4月加密货币种类已经超过2 100种。比特币本质是一种基于区块链的分布式账本,系统中所有用户通过基于公钥的钱包地址进行点对点的直接交易,无需通过任何中心化金融机构,所有交易记录都不可篡改地永久记录在区块链上[1-2],交易只与双方的钱包地址有关,与钱包所有人的真实身份没有直接联系,以此来保护用户隐私。比特币在保护用户隐私的同时也常被用于异常交易活动,并且给追踪这些交易团体增大了难度。通过分析交易数据,可以发现交易特征并识别实体[3-4],同时推测实体类型并发现实体之间的联系,进而对交易数据进行可视分析,帮助研究人员更好地感知区块链交易信息,分析交易中的安全事件。
文献[5-9]针对比特币地址聚类和实体识别进行研究。文献[5]利用Petri网对比特币网络进行建模,把所有交易地址和交易映射为矩阵的行和列,通过分析矩阵来解决比特币实体识别的问题,但是如果交易数量过多,会造成矩阵维数过大,这是此方法的不足。文献[6]提出一个模块化的框架BitIodine,通过解析区块链和可能属于同一个实体的地址,对这些实体分类并贴上标签。文献[7]对用户的交易规律进行抽象,提出一种基于参数的身份识别方法,能够有效识别匿名区块链地址对应的真实用户身份。文献[8]通过分析比特币交易数据,基于实体识别对勒索软件CryptoLocker的攻击行为进行分析。文献[9]通过设计模拟实验,采用基于行为的聚类技术对比特币交易数据进行分析,能够匹配40%的用户身份和地址。
上述研究都认为如果比特币一条交易中包括多个输入地址,那么这些地址都属于同一实体,把这一条件作为启发式聚类条件,在实体识别和进一步数据分析方面能够取得很好的效果。文献[10]分析得到这种启发式聚类方法有效的主要原因,即地址重用、可避免的合并、具有高中心性的超级集群以及地址集群的增量增长。文献[11]提出将多输入地址和找零地址结合作为启发式条件进行聚类的方法,并通过大量实验验证方法的准确性和全面性,同时分析实验迭代次数对聚类效率的影响。文献[12]对20个月中生成的交易进行分析,将35 770 360个地址聚类为13 062 822个集合,但未对聚类后的实体及其之间的联系进一步分析。文献[13]提出一个基于图的数据挖掘工具对比特币交易数据进行可视分析,实现了对任意给定的一个或一组地址的局部聚类,适用于对已知事件中的地址进行详细行为和关联分析,但聚类结果没有与实体类型联系。
上述方法都是基于某一时段的比特币交易数据进行聚类,没有对实体的演变情况进行分析。为此,本文提出一种基于比特币交易数据特征的地址增量聚类方法。采集比特币的区块流数据对原始流数据进行解析和结构化处理,提取符合聚类条件的交易和地址形成聚类地址组,并通过散列函数生成聚类地址组的数据索引,获得聚类地址组之间的聚合关系。在此基础上,利用并查集算法实现对此关系的增量聚类以发现交易实体,进而对交易数据进行重标记和再分析,得到比特币实体间的的交易特征。此外,本文通过对聚类过程中各阶段实体的特点及实体间交易联系进行可视分析,得到地址增量聚类过程中实体的变化特征。
1 增量聚类方法
基于比特币交易数据的地址增量聚类方法主要包括数据采集及数据预处理、聚合关系集合获取、数据增量聚类和存储聚类4个部分。
1.1 数据采集及预处理
本文通过配置区块链环境和搭建比特币客户端Bitcoin Core,将区块流数据同步到本地,Dt表示截止至t时刻的所有区块数据。
当生成新区块后,将新的区块数据同步到本地,Dt′-t表示t到t′时刻之间产生的区块数据。同步到本地的区块数据Dt是二进制流数据,图1所示为创世区块的十六进制格式的数据。为进一步实验,通过分析区块的数据结构[14-15],对原始流数据Dt解析和结构化处理[16],得到比特币交易数据集St,St=Json(Dt),该数据集为t时刻之前的区块数据经过处理后得到的结构化数据。图2所示为创世区块经过处理后的交易数据。

图1 创世区块原始数据Fig.1 Original data of genesis block

图2 创世区块结构化数据Fig.2 Structured data of genesis block
基于比特币交易数据集提取用于增量聚类的可聚类交易T。T必须满足以下条件:交易T不是挖矿交易;交易T包含两个以上不同的输入地址。可聚类交易中的地址即为聚类地址组,用ci标识,i为一个自增的整数,Ct为t时刻之前生成的ci。
图3所示为两例可聚类交易模型(地址的颜色不同表示地址所属实体不同),其中,聚类地址组表示为c0={a1,a2},c1={a1,a6,a8}。

图3 可聚类交易模型Fig.3 Clustered transaction models
1.2 聚合关系集合获取
基于聚类地址组Ct通过散列函数生成哈希表Ht,其中,k为地址,v为地址所属组。当读取到已存在于Ht的地址但地址所属组与Ht中对应的值不一致时,说明这两个地址组间存在聚合关系,其中地址属于同一实体,聚合关系用(rc0,rc1)表示,将t时刻之前的所有聚合关系放入集合Rt中:
Ht,c={vt,c|c∈Ct,c=kt}
Rt={(rc0,rc1)|c0,c1∈Ct,Ht,c0≠Ht,c1}
其中,(rc0,rc1)表示关系对中的聚类地址组。关系集合生成算法描述如下:
算法1聚合关系集合生成算法
输入t时刻之前所有聚类地址组Ct
输出哈希表Ht,聚合关系集合Rt
for ciin Ctdo
for a in cido
if a as in Ht.k and Ht[a].v≠cithen
(rc0,rc1)←(Ht[a].v,ci)
将聚合关系(rc0,rc1)添加到Rt中
else
Ht[a].v=ci
end
end
例如图3交易中的聚类地址组有c0、c1,地址a1在c0中也在c1中,经过算法1处理后,Ht中{a1:c0}更新为{a1:c1},同时生成一个聚合关系r:(c0,c1),存储最终生成的聚合关系集合,同时输入并查集算法进行聚类。
1.3 增量聚类
由于区块链数据是增量的,传统聚类方法需要获取创世区块到当前区块的所有关系集合进行聚类,会导致效率下降,因此本文基于聚类地址组间聚合关系通过并查集算法实现实体增量聚类。并查集是一种树型的数据结构,常用于判断两个子集是否属于同一集合以及按照一定顺序将属于同一集合的子集合并,时间复杂度是线性的,适用于解决数据量大的应用问题,基本操作包括初始化、查找、合并。
初始化集合G,集合中的元素为聚类地址组的标识名称ci。由于比特币交易数据量较大,因此采用路径压缩方法优化查询操作,查询函数Find(x)如下:
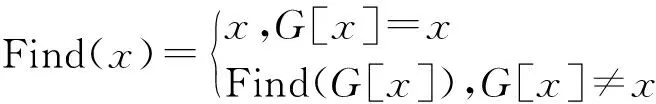
其中,x为G中的元素。执行查找函数后的两个元素若属于不同集合则将其合并,合并函数Union(x,y)如下:
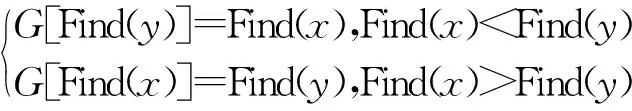
初始集合和结果集合同一位置的元素属于同一集合,元素相同的个数代表聚类后实体的数量,因此,通过并查集算法可以对比特币交易数据中的所有聚类地址组进行聚类。基于聚合关系的并查集算法描述如下:
算法2基于聚合关系的并查集算法
输入关系集合Rt
输出并查集G
初始化数组G
if Rt≠∅ then
for (rc0,rc1) in Rtdo
Find(ci),Find(cj)
if Find(ci)≠Find(cj) then
Union(ci,cj)
end
//合并整理
for k←0 to G.length do
if G[k]≠k then
Find(k)
end
如图4所示,一个节点代表一个聚类地址组,同一聚合关系中的两个组用实线连接,用虚线连接关系之间存在关联的节点。图4(a)中虚线圈出的为存在聚合关系的所有节点,合并之后节点分布如图4(b)所示。

图4 基于聚合关系的并查集算法模型Fig.4 Model of union-find set algorithm based on aggregation relationship
聚合聚类算法完成后,存储中间结果G,并检查是否有新的区块数据生成,若有生成新区块,则对新区块数据进行结构化处理,提取区块中的所有聚类地址组Ct′-t,执行算法1生成新的关系集合Rt′-t。基于中间结果G集合对Rt′-t进行算法2中操作即可生成新的聚类结果Ft′,Ft′为基于t′时刻前数据生成的聚类结果。
重复使用上述方法对新数据进行处理以实现增量聚类的效果。基于并查集方法实现增量聚类的时间复杂度低,并且在更新G集合的过程不需要额外的空间,适用于比特币这种数据量大的问题。数据采集及数据预处理、聚合关系集合获取、数据增量聚类和存储聚类4个模块之间的数据交互过程如图5所示。

图5 基于比特币交易信息的地址增量聚类方法时序图Fig.5 Sequence diagram of address increment clustering method based on Bitcoin transaction information
2 实验与结果分析
2.1 数据集
本文采集比特币网络前278 878个区块数据作为实验的数据源,数据覆盖时间为2009年至2013年,数据的具体参数如表1所示。

表1 实验参数Table 1 Experimental parameters
2.2 聚类结果分析
2009年2月3日前交易的输入地址都是单个或重复,实验处理了2 817个区块后首次出现符合条件的可聚类交易。图6所示为交易实体、地址、关系对数量随时间的变化。可以看出,2009年至2012年地址增长速率相对缓慢,2012年后地址增长率显著提高,并且2013年关系对增长量较之前明显降低。出现此现象原因可能为:在线交易服务的出现,使用比特币的用户迅速增长,用户逐渐意识到可聚类交易对隐私的影响。
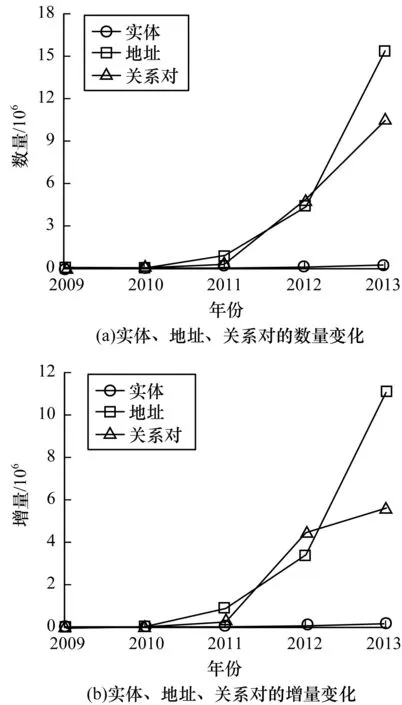
图6 实体、地址、关系对数量及增量随时间的变化Fig.6 Change of number and increment of entity,address and relationship pair over time
表2和表3中的数据为实体标识,通过对实体中钱包地址进行哈希运算后取哈希值前十位得到该标识。如果实体中包含多个地址,则使用最小的哈希,其中10位哈希值和CoinJoinMess标识的实体均为普通钱包实体,提供在线服务的实体用服务的名称标识。

表2 基于可聚类交易数量的实体排名Table 2 Entity ranking based on number of clustering transactions
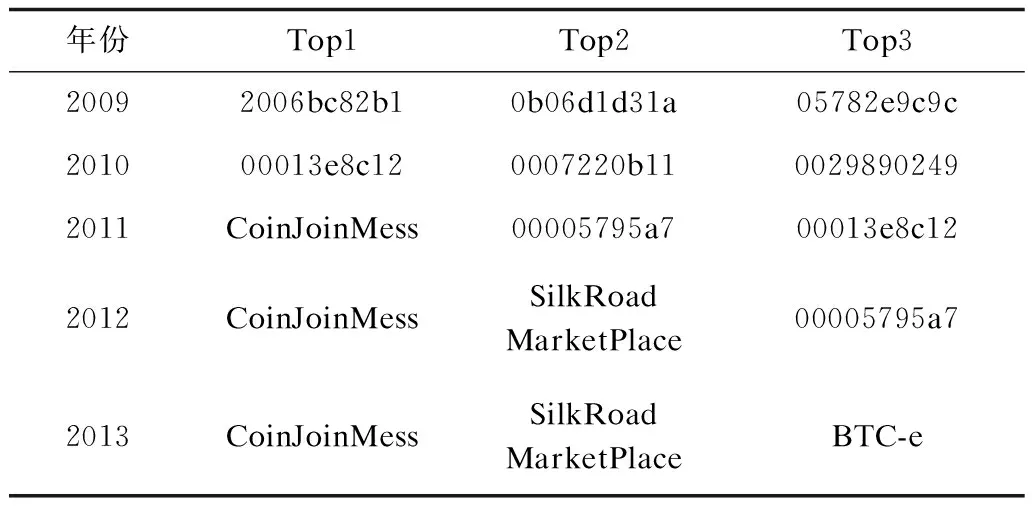
表3 基于地址数量的实体排名Table 3 Entity ranking based on number of addresses
由表2数据可以发现:2009年至2011年可聚类交易最多的Top3实体皆为普通钱包;在2012年前三名的实体中首次出现了钱包外的新类型,即比特币在线服务SatoshiDice,其为一款从2012年开始运营的“基于区块链的在线服务”;2013年出现了同类型新实体BitZillions,其为2013年起开始提供的加密货币下注的市场[17]。
表3按包含的可聚类地址数量对实体排名,从中可以发现:在2012年前三名的实体中首次出现了比特币在线服务SilkRoad MarketPlace,该服务成立于2011年,提供各类商品在线匿名交易服务,这一特点使其发展迅速[18],2012年后成为地址数量Top3的实体;2013年出现的新实体BTC-e,是一个比特币交易网站。同时从表3数据也可以看出,2010年后实体包含的地址明显增多,这是因为2010年上半年是比特币初始阶段[19],主要用于挖矿,而2010年下半年是比特币交易阶段,逐渐出现了各种各样的用户和在线服务提供商[20]。
2.3 交易行为可视分析
对3个地址数量最多的实体进行交易行为可视分析。图7(a)所示为截止至2012年Top3实体的交易行为,图7(b)所示为截止至2013年Top3实体的交易行为,其中不同样式的节点与图例中相应样式的实体类型相对应,交易的数量用节点的大小编码,实体间的交易次数越多,节点间的距离越小。
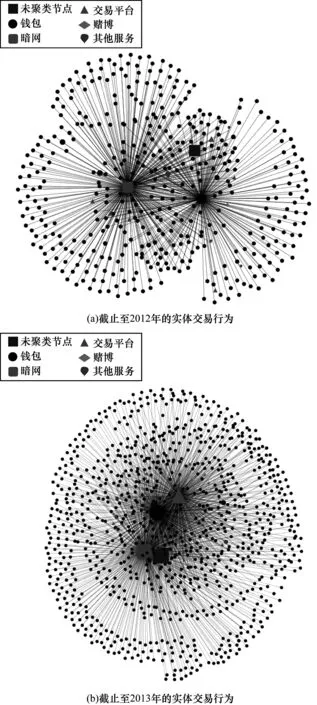
图7 Top3实体交易行为Fig.7 Top3 entity transaction behaviors
可以看出,图7(a)中形成了2个明确的交易集群,其中一个集群的交易中心为SilkRoad实体,将鼠标悬浮在节点上可以看到中心节点SilkRoad MarketPlace实体与图中其他类型的实体都有交易行为;另一交易团体中心为钱包实体,与其交易密切的实体类型也是钱包,推测其为钱包服务。
为防止节点过密而造成节点相互遮挡,在图7(b)中显示交易数量超过500次的实体。图中形成3个交易集群,中心节点分别是钱包服务、交易平台以及匿名交易网站SilkRoad MarketPlace。可以看出,与图7(a)相比,图7(b)中交易平台类型的实体数量明显增多,并且出现了新的匿名交易网站Sheep Marketplace,与其交易密切是实体分别为SilkRoad MarketPlace、BTC-e以及钱包实体。此外,BTC-e在2013年是地址数Top3的实体,出现此现象的原因为:在2013年在线匿名交易网站Sheep Marketplace通过BTC-e来进行洗钱[21],产生了大量地址和交易。
2.4 性能分析
与Walletexplorer.com 网站聚类的结果相比,本文方法进行实体聚类能够达到100%正确率。表4为截止至2012年随机选取的3个实体的地址数量对比。

表4 本文方法与Walletexplorer.com网站的聚类结果对比Table 4 Comparison of clustering results by the proposed method and WalletExplorer.com
图8所示为传统聚类方法与本文方法的执行并查集算法时间对比。可以看出,第1次实验即处理2009年的数据时两种方法用时相同,而之后由于本文增量聚类方法无需初始化集合和处理重复数据,因此用时较少,时间复杂度较低,因此效率更高。
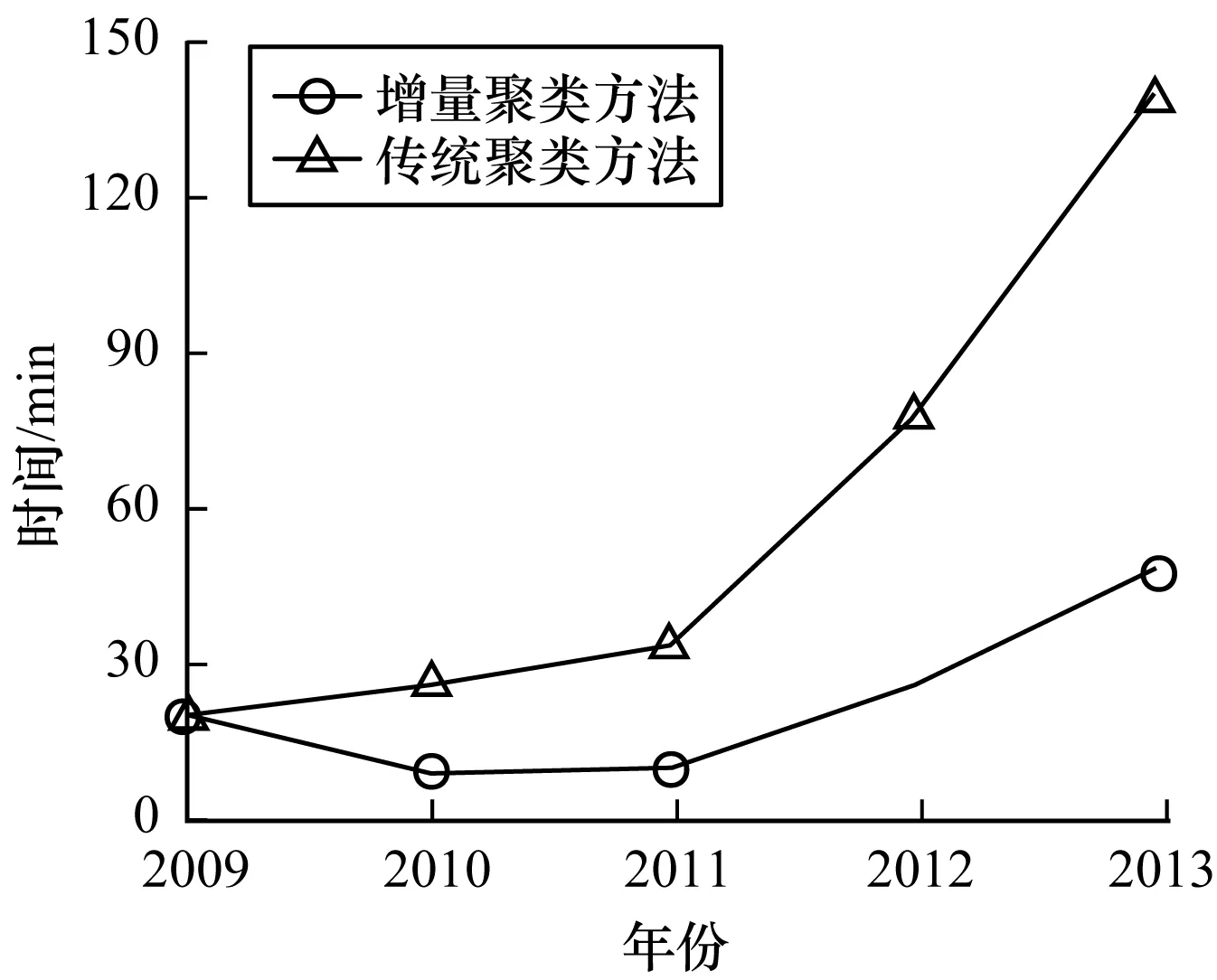
图8 并查集算法时间对比Fig.8 Comparison of time of union-find algorithm
图9所示为传统聚类方法与本文方法的聚类时间对比。可以看出,在比特币初始阶段,两种方法的聚类用时相同,但随着时间推移,每年生成的区块数量和聚合关系集合越来越多,本文增量聚类方法性能优势越明显。
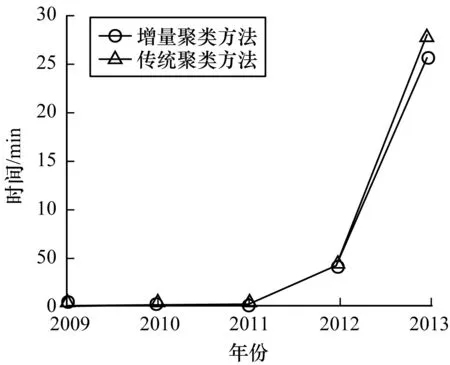
图9 聚类时间对比Fig.9 Comparison of clustering time
3 结束语
本文在启发式聚类方法的基础上,提出一种比特币交易数据的增量聚类方法。通过对区块流数据的分析及结构化处理,提取可聚类交易和聚类地址组并获取聚类地址组间聚合关系,在此基础上进行增量聚类,实现对比特币实体类型和数量的演变分析,同时对地址数量最多的前三名实体的交易做进一步可视分析,发现不同时期实体间的交易特征。实验结果表明,本文方法对多输入交易的地址具有较好的效果,但不能将全部的交易地址覆盖到聚类分析中。下一步将对此进行改进,提高该方法的交易地址覆盖率。
