面向物联网的边云协同实体搜索方法
2020-08-19王汝言刘宇哲张普宁亢旭源李学芳
王汝言,刘宇哲,张普宁,亢旭源,李学芳
(1.重庆邮电大学 通信与信息工程学院,重庆 400065; 2.重庆高校市级光通信与网络重点实验室,重庆 400065;3.泛在感知与互联重庆市重点实验室,重庆 400065)
0 概述
随着智能感知设备的大规模部署,在物联网中准确获取用户兴趣信息[1]的难度也在不断加大,因此物联网搜索技术应运而生。物联网搜索[2]是指通过使用相应的策略与方法从物理世界中获取各种结构化的实体信息(如物体、人、网页等)并对其进行存储与管理[3],便于用户搜索。而由于物联网中物理实体信息[4]的海量性与异构性[5]及搜索的高实时性[6]要求,传统互联网搜索模式[7-8]已不适用于物联网搜索[9],因此如何在由海量异构物理实体组成的物理世界中精准、高效地获取用户兴趣信息已成为亟需解决的问题。研究人员将云计算技术[10]应用于物联网搜索中,为用户提供一个安全可靠的数据存储单元,并将通过泛在网络连接的海量计算资源进行统一管理与调度。文献[11]将HTTP与MQTT相结合,在物联网-云架构下实现物联网的部分功能。文献[12]通过在云端建立数据库存储传感器采集的数据以方便用户搜索。文献[13]设计一种基于云计算的物联网搜索和发现方法,查询邻近实体状态信息。文献[14]提出一种云端数据共享搜索方法SeDaSC,将数据加密后存储至云端,用户通过服务器递交访问请求后再从云端搜索数据。文献[15]提出一种层次化搜索方法LHPM,在网关接收用户搜索请求后,通过查找相应传感器并读取数据返还搜索结果至用户。然而,受限于传感器的计算、通信与存储能力,传感器与云端之间的通信距离过长[16],导致搜索时延较大。
边缘计算的提出为解决物联网搜索的实时性问题提供了新思路。由于云计算适用于非实时、长周期数据,而边缘计算[17]在实时、短周期数据及本地决策等场景中有较大优势,因此文献[18]指出可将边缘服务器作为传感器与云端通信的中介,在边缘处理本地化数据后再与云端进行交互,从而提高搜索效率。文献[19]通过在边缘建立深度学习模型计算和处理来自原始传感器的数据。文献[20]利用边缘计算来最小化物联网异构化数据的处理延迟。
由于现有研究结合云端和边缘的特点设计物联网搜索方法,但未考虑物理实体的状态数据与用户搜索特征,并且物理实体的状态时变性[21]差异较大,用户在不同时段对不同实体的访问兴趣度有所区别,因此将实体状态数据全部存储于边缘或云端无法满足用户获取实体的准确性和实时性需求。
本文针对物联网搜索的实时性和准确性需求,考虑物理实体状态差异化分布的特征,提出面向物联网搜索的边云协同实体搜索方法(Edge and Cloud Collaborative Entity Search Method,ECCS),结合云计算与边缘计算的优势,设计适用于物联网搜索的边云协同实体搜索架构,提高物联网实体搜索效率。利用面向边缘侧的实体识别算法准确区分热门与冷门实体,将强时变性、高访问度的热门实体状态信息存储于边缘侧,弱时变性、低访问度的冷门实体状态信息存储于云端,以保障搜索时效性和准确性,改善用户搜索体验。
1 系统架构
边云协同的物联网搜索系统架构如图1所示,将物联网搜索系统分为3层:第1层为智慧实体层,实体所附传感器采集实体状态信息并上传;第2层为边缘层,由搜索系统的边缘服务器构成,边缘服务器采用实体识别方法,依据收集到的实体状态信息对实体进行分类;第3层为云端层,云端服务器对边缘服务器进行统一管理。
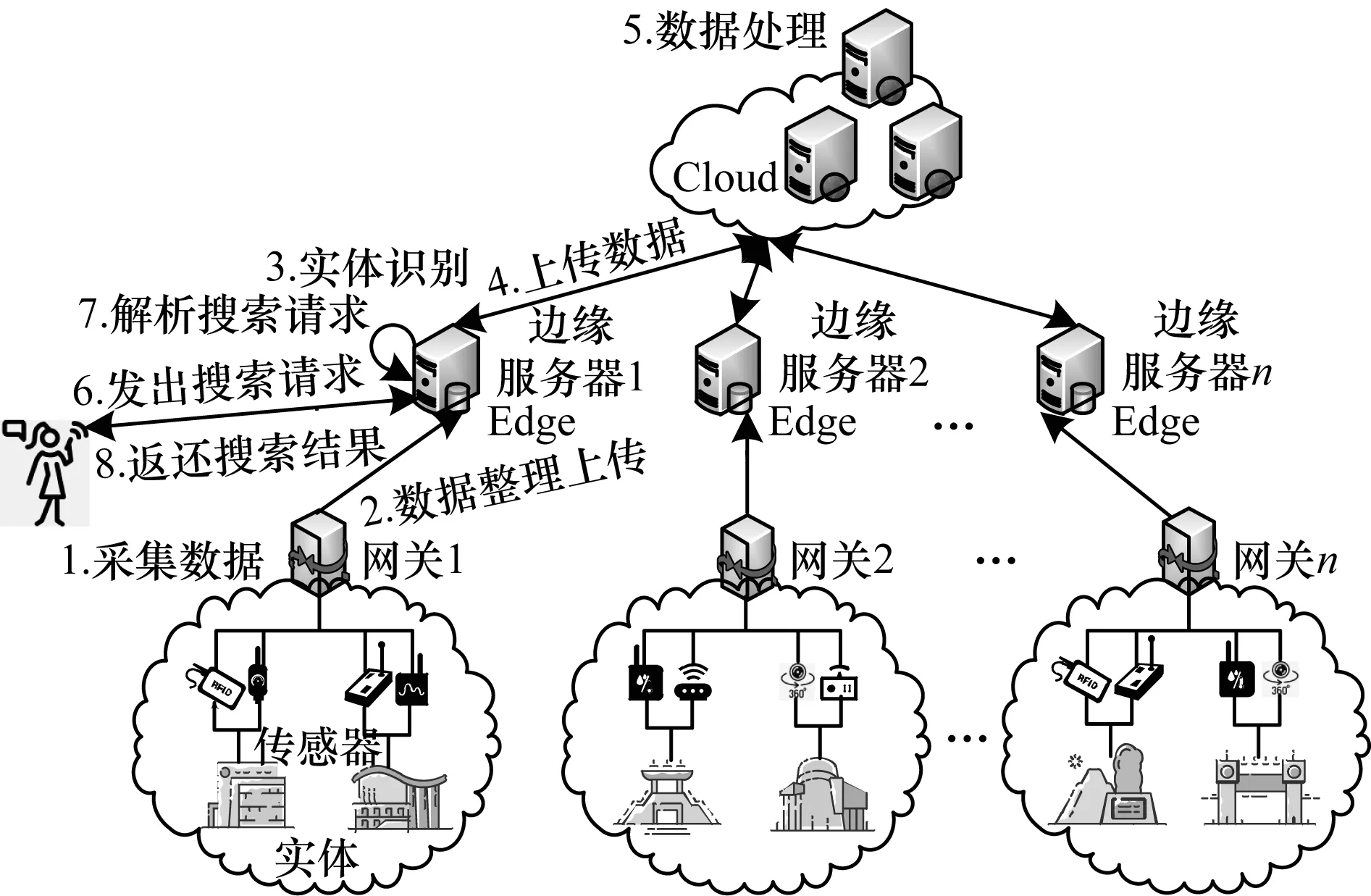
图1 边云协同的物联网搜索系统架构Fig.1 Architecture of edge and cloud collaborative search system in IoT
在传统物联网搜索模式中,用户通过与云端中心服务器直接通信发出搜索请求以获得搜索结果,云端中心服务器收到请求后需要遍历匹配的传感器以获得实体的状态信息。但由于用户与云端中心服务器的通信距离过长,当搜寻时变性较强的实体时,用户接收到的云端中心服务器反馈的结果已无法准确反映实体当前的状态。而边缘服务器靠近用户与实体,从边缘服务器获取实体状态信息相较于传统搜索方式能保障用户获取的实体状态信息的时效性。
边云协同实体搜索方法的具体步骤如下:
1)智慧实体关联的传感器采集到数据后,将采集到的实体状态信息周期性上传至上层网关,每个网关下辖有多个智慧实体。
2)各网关将智慧实体状态信息上传至其上层的边缘服务器。
3)边缘服务器接收到下辖网关上传的实体状态信息后,结合本地的搜索记录,采用实体识别算法对实体进行识别与分类。
4)边缘服务器将识别出的强时变性、高访问度的热门实体存储在边缘服务器中,并将弱时变性、低访问度的冷门实体状态信息上传至云端。
5)云端服务器存储并处理边缘服务器上传的冷门实体的状态信息。
6)用户通过邻近的边缘服务器提交对实体状态信息的搜索请求。
7)边缘服务器接收到用户发出的搜索请求后,对搜索请求信息进行解析,并对请求实体的类别进行判别。
8)边缘服务器若识别用户请求信息为存储在用户邻近边缘服务器的热门实体状态信息,则直接将此信息反馈给用户;否则从云端下载实体状态信息反馈给用户,完成此次搜索过程。
2 边云协同搜索
将强时变性、高访问度的热门实体信息存储于靠近用户的边缘侧处理,可有效解决因通信距离过长所产生的时延导致搜索反馈结果精度较低的问题。因此,本文提出面向边缘侧的实体识别方法,在边缘侧对实体进行有效区分。
在边缘服务器中执行实体识别算法,如图2所示,对于边缘服务器覆盖范围内的实体,由于覆盖范围内的实体数目有限,因此收集覆盖范围内嵌入实体中的传感器所上传的实体状态信息以及用户对于物理实体状态信息的搜索记录,并在此基础上建立深度学习模型,通过实体的多维度特征,甄别热门实体与冷门实体。在区分实体后,将强时变性、高访问度的热门实体状态信息(如图2中实体1、实体3所示)存储在边缘服务器中,由边缘服务器处理并存储,弱时变性、低访问度的冷门实体状态信息(如图2中实体2、实体4所示)则上传至云端存储,在用户有访问需要时进行调用。
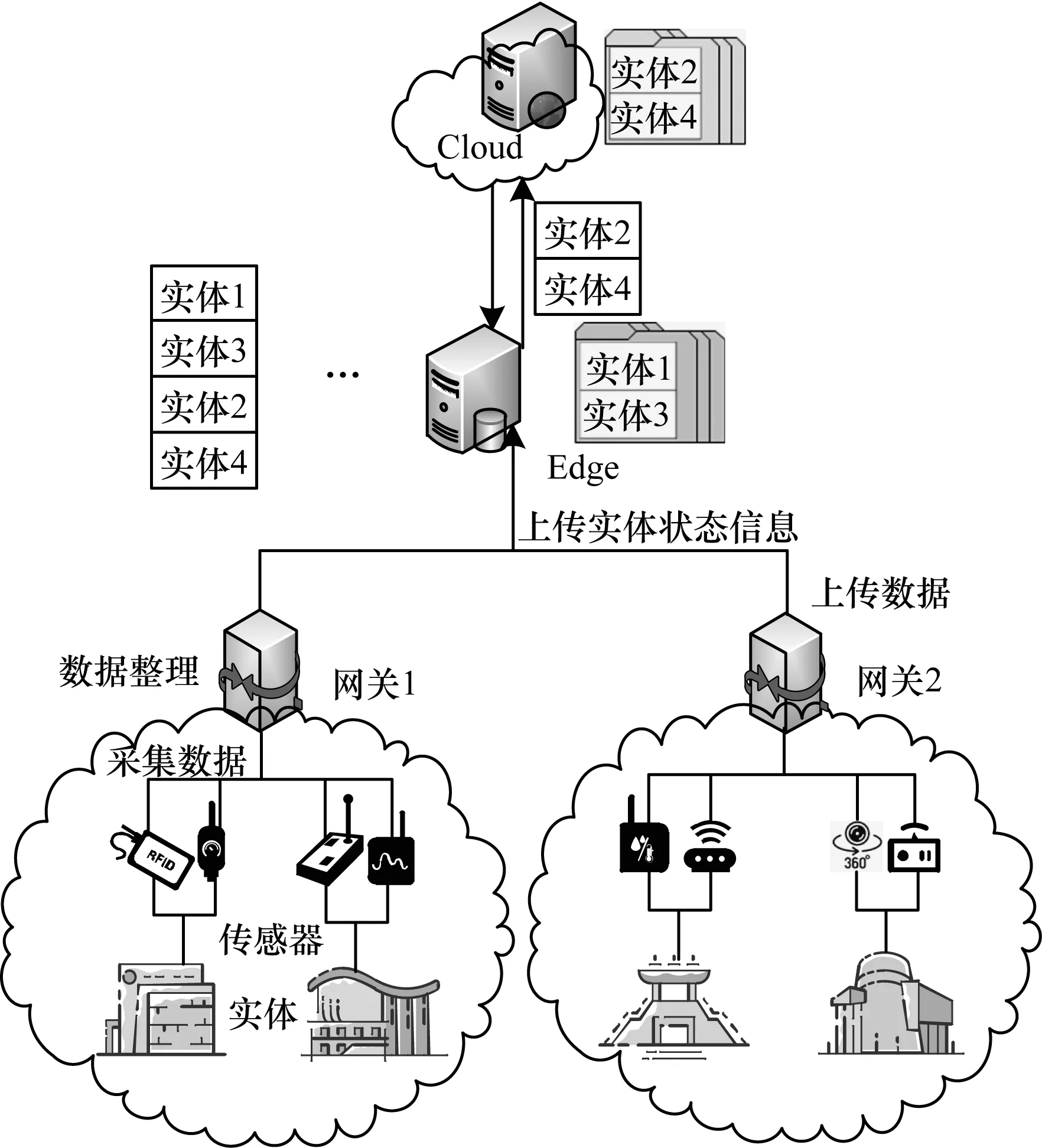
图2 实体识别分类存储Fig.2 Entity recognition classification and storage
实体识别算法基于深度信念网络(Deep Belief Network,DBN)模型[22]进行实体状态信息与用户访问特征的提取,进而采用K-means聚类[23]算法对实体类别进行无监督划分,算法流程如图3所示,主要分为实体特征提取与实体识别分类两部分。
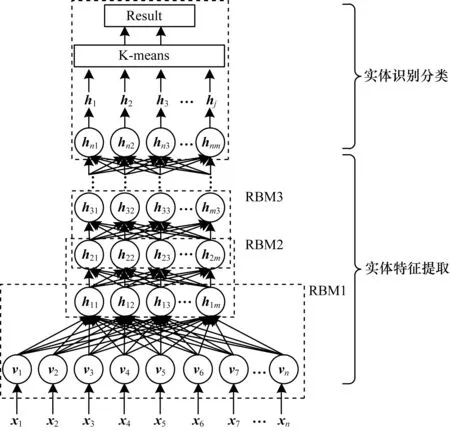
图3 基于深度信念网络的实体识别算法流程Fig.3 Procedure of entity recognition algorithm based on deep belief network
2.1 实体特征提取
特征提取是实体识别算法中最重要的环节,对该算法而言,只需将实体最终区分为热门实体与冷门实体,而单个实体通常具有多个特征,直接对多个特征进行识别分类显然将影响分类结果的精度,因此利用特征提取将多个实体特征通过属性间的关系进行组合以改变特征空间从而达到降维的效果,减轻分类算法的负担,提高分类准确度。
深度信念网络为由多层受限玻尔兹曼机[24](Restricted Boltzmann Machines,RBM)组成的神经网络。RBM由显层(v)和隐层(h)构成,显层由显性神经元组成,用于接收输入的实体状态特征;隐层由隐性神经元组成,用于提取实体状态特征。DBN的训练是逐层进行,在每一层中使用最底层的数据向量来推断隐层,再将该隐层作为下一层的数据向量。
实体特征提取的具体步骤如下:
1)充分训练第1层RBM1。
2)固定RBM1的权重和偏移量,然后使用得到的隐性神经元的状态,作为第2层RBM2的输入向量。
3)在充分训练RBM2后,将RBM2堆叠在RBM1的上方。
4)重复以上步骤直至DBN收敛,从而得到降维后的实体特征。
在图3中,输入的实体特征xi包括实体状态变化频率、实体状态变化幅度、实体状态采样周期、实体访问频率、实体搜索次数、实体访问时间、实体访问次数和实体评分。显层接收到输入特征后得到其神经元状态向量vi,v=[v1,v2,…,vn],隐层神经元状态向量hj,h=[h1,h2,…,hm],其中n和m为显层和隐层神经元数量。若给定(v,h),则能量函数的计算公式为:
(1)
其中,θ={a,b,w}为RBM中的实体参数集,ai∈a为显层神经元的偏置,bj∈b为隐层神经元的偏置,wij∈w为连接显层与隐层的权值。RBM在参数θ下的联合概率分布为:
(2)
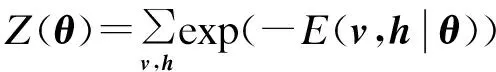
(3)
2.2 实体识别分类
通过DBN对实体特征进行训练后,可得到实体特征集合D={h1,h2,…,hj}。为有效区分实体的类别,从而对实体状态信息的存储位置进行决策,本文进一步采用K-means聚类算法对特征集合进行聚类分析,算法步骤具体如下:
1)从实体特征集合D={h1,h2,…,hj}中随机选取{x1,x2,…,xk}个特征作为簇中心。
2)对剩余的每个实体特征,测量其到每个簇中心的欧氏距离(如式(4)所示),并将其归类到最近的簇中。
(4)
其中,D表示处理后实体特征的个数。
3)K-means聚类算法在每次迭代时,需要更新对应的簇中心:对应簇中所有实体特征对象的均值,即更新后该类簇的簇中心。第k个簇中心的更新方式为:
(5)
其中,Ck表示第k个簇,|Ck|表示第k个簇中实体特征的个数。
4)迭代步骤2和步骤3直至新的簇中心与原簇中心相等或小于指定阈值,则算法收敛。
在聚类算法结束后,得到热门实体与冷门实体的集合,边缘服务器根据分类结果进行决策,将热门实体集合所对应的实体状态信息存储至本地,冷门实体集合所对应的实体状态信息上传至云端。
3 仿真结果与验证
本文所用数据集为经过归一化及抽样处理后的Intellab[25]数据集,该数据集包含54个部署在不同位置的温度与湿度传感器所采集上传的数据,样本数为10 000。开发环境为64位Windows 10操作系统,处理器为Intel®CoreTMi5-3337U,内存为8 GB,CPU 1.80 GHz,开发工具为Matlab R2017b。DBN参数设置如表1所示,在K-means聚类中K值为2,性能验证结果均为搜索1 000次后的平均值。

表1 深度信念网络参数设置Table 1 Parameters setting of deep belief network
3.1 基于深度信念网络的实体识别算法性能验证
图4为基于深度信念网络的实体识别算法分类结果。可以看出,经过算法提取实体特征后将实体分为两类,即热门实体与冷门实体。图5为基于深度信念网络的实体识别算法在不同实体数量下提取特征并进行分类所需时长,可以看出随着实体数量的增多,算法提取实体特征并进行分类所需时长也随之增加,这是由于实体数量的增加导致计算开销增加,从而引起计算时间变长。
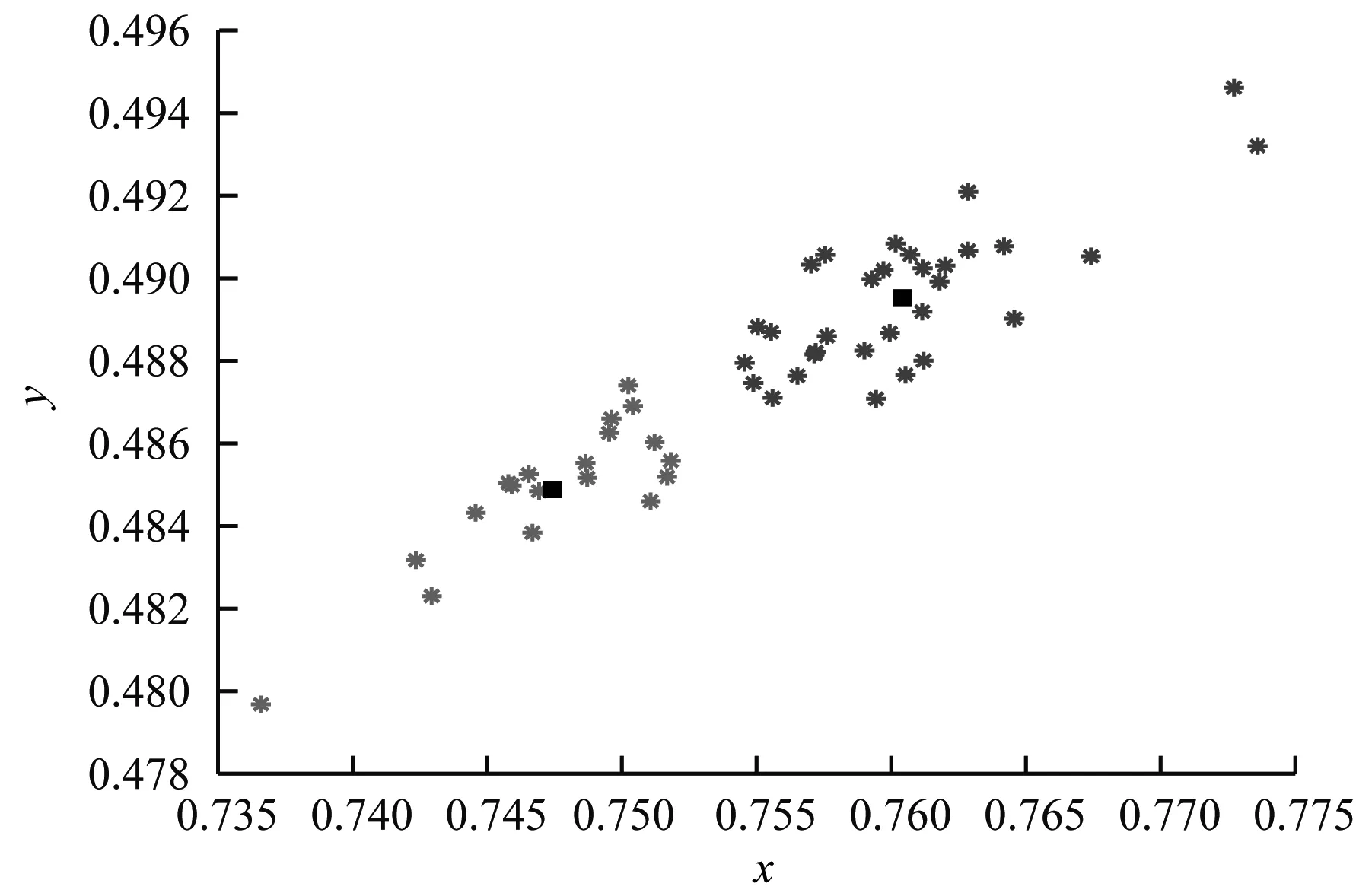
图4 基于深度信念网络的实体识别算法分类结果Fig.4 Classification results of entity recognition algorithm based on deep belief network

图5 不同实体数量下的实体识别算法运行时间Fig.5 Running time of entity recognition algorithm with different number of entities
3.2 查准率与查全率验证
经过基于深度信念网络的实体识别算法将实体分类后,对强时变性的实体进行仿真验证。将热门实体状态信息存储在边缘服务器及云端并分别执行ECCS与SeDaSC方法后,对该类实体所得到的搜索结果进行对比,结果如图6所示。其中,ECCS方法搜索得到温度数据的平均误差为1.200 5 ℃,SeDaSC方法搜索得到温度数据的平均误差为5.270 8 ℃,LHPM方法搜索得到温度数据的平均误差为8.211 9 ℃。可以看出,对于强时变性的实体,由于通信时延的缘故,因此存储在边缘服务器后得到的搜索结果远比存储在云端精确。

图6 云端与边缘服务器的热门实体搜索结果对比Fig.6 Comparison of popular entity search results between cloud and edge servers
查准率和查全率计算公式如式(6)、式(7)所示:
(6)
(7)
其中:S1为指定搜索传感器数值范围后,传感器搜索结果集合;S2表示在搜索结果集合S1中,传感器真实数值在给定范围中的传感器集合;S3表示所有真实数值在给定范围内的传感器集合。
图7、图8为不同用户容忍度误差下,热门实体存储在边缘服务器与云端的查准率与查全率对比。
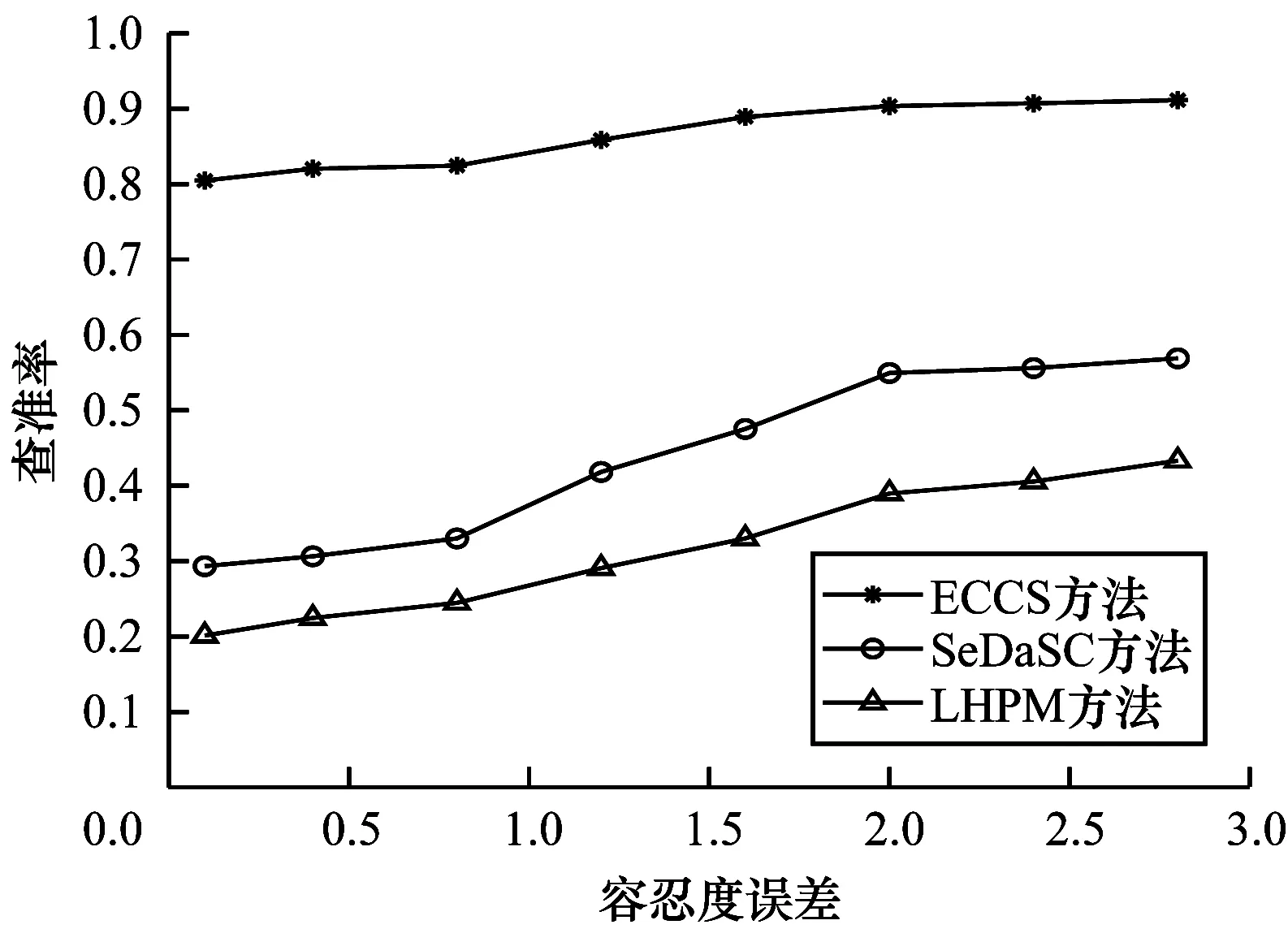
图7 不同容忍度误差下热门实体的查准率对比Fig.7 Comparison of the precision of popular entities at different tolerance degree errors

图8 不同容忍度误差下热门实体的查全率对比Fig.8 Comparison of the recall of popular entities at different tolerance degree errors
可以看出,由于热门实体强时变性的关系,并且从边缘服务器中搜索数据的时延较短,所获取的搜索结果与真实值更为接近,因此将热门实体状态信息存储在边缘服务器后进行搜索得到的查准率与查全率远高于云端。同时,随着用户对于搜索结果的容忍度误差的增大,搜索查准率与查全率通常也有少量增长,这是因为随着容忍度误差的增大,搜索结果所允许的数值范围变大,导致集合S2中传感器个数增多以及查准率与查全率的增长。
3.3 搜索方法性能验证
图9、图10为随着搜索方法运行时间的增长,所得到搜索结果的查准率与查全率情况。可以看出,ECCS方法的查准率和查全率稳定程度均高于SeDaSC方法和LHPM方法。这是由于热门实体强时变的特性,在ECCS方法中,边缘服务器靠近用户的特性,从边缘服务器获取搜索结果的时延较短,用户在获取到搜索结果前实体当前状态不容易发生改变,搜索结果与实体当前状态的匹配率更高,因此查准率和查全率波动较小。在SeDaSC方法中,长距离通信的时延较大,在用户获取搜索结果前实体状态发生变化的概率较大,因此搜索结果并不匹配实体当前状态,从而使得查准率与查全率波动较明显。在LHPM方法中,网关接收并解析用户的搜索请求后,需要访问搜索请求所匹配的传感器并获取数据,由于通信距离过长,返回搜索结果时实体状态已经发生改变,因此查准率与查全率波动较大。
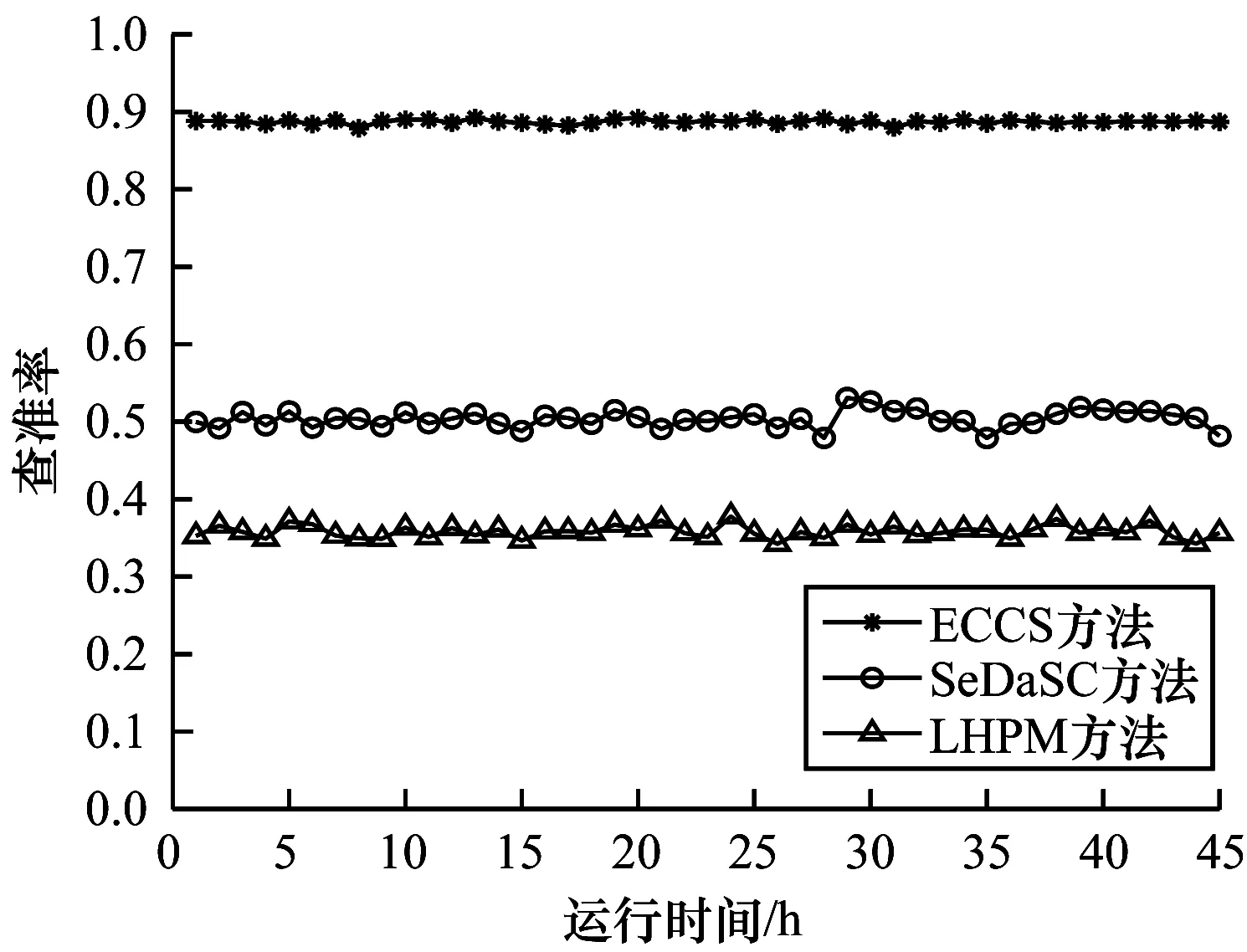
图9 3种搜索方法的查准率对比Fig.9 Comparison of the precision of three search methods

图10 3种搜索方法的查全率对比Fig.10 Comparison of the recall of three search methods
图11为随着搜索方法运行时间的增加,从边缘服务器和云端搜索数据的时延波动情况。可以看出,随着搜索方法运行时间的增长,ECCS方法所耗费时延的波动范围与波动程度均小于SeDaSC方法和LHPM方法。这是由于用户与边缘服务器的通信距离较短,通信稳定程度较高,因此时延波动较小;云服务器与用户之间的通信距离过长,同时与云服务器通信的终端数目较大,出现拥塞或排队的概率较高,从而导致时延的波动较大。
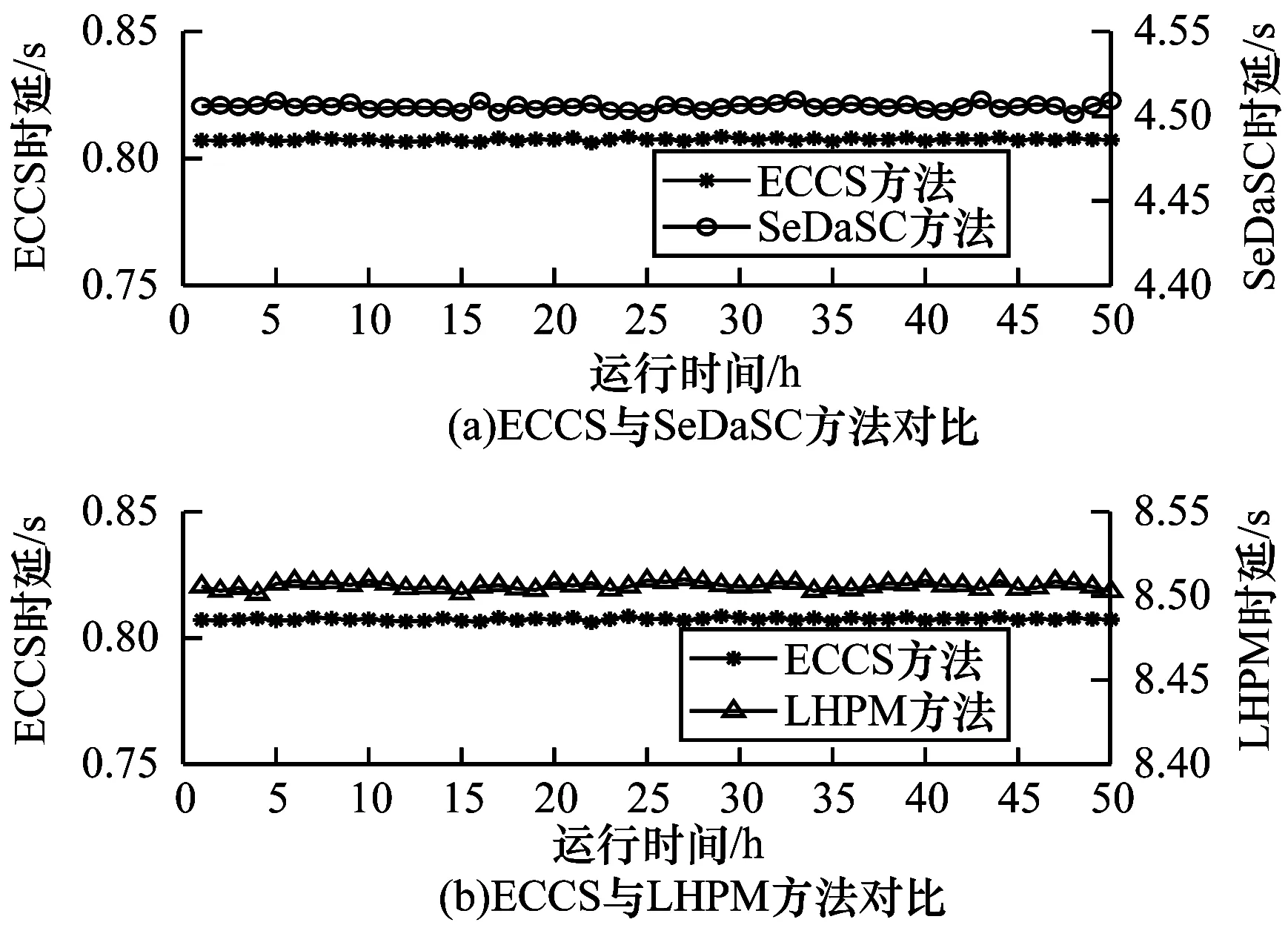
图11 3种搜索方法的时延对比Fig.11 Comparison of the time delay of three search methods
4 结束语
物理世界中存在海量状态时变性较强的实体,并且用户对获取实体信息的实时性要求较高。针对强时变性实体的搜索问题,本文提出面向物联网的边云协同实体搜索方法。构建边云协同的实体搜索系统架构,联合云端与边缘侧协同进行实体信息搜索,并采用基于深度信念网络的实体识别算法准确区分热门与冷门实体。仿真结果表明,该搜索方法相比传统搜索方法可有效提升实体状态信息搜索的实时性与准确性。下一步将针对用户个人偏好进行物理实体信息研究,提高搜索引擎智能化水平。
