基于实例过滤与迁移的跨项目缺陷预测方法
2020-08-19范贵生刁旭炀虞慧群陈丽琼
范贵生,刁旭炀,虞慧群,陈丽琼
(1.华东理工大学 计算机科学与工程系,上海 200237; 2.上海市计算机软件评测重点实验室,上海 201112;3.上海应用技术大学 计算机科学与信息工程系,上海 201418)
0 概述
软件缺陷产生于软件开发过程中开发人员的错误编码,含有缺陷的编码在软件运行过程中可能会产生意料之外的结果或行为,从而带来不必要的企业经济损失。在软件项目开发的生命周期中,发现缺陷的时间越晚,带来的风险和修复代价就越高。因此,在软件部署上线之前必须进行软件测试和代码审查。然而目前保障软件质量的常规方法往往不能及时检查出缺陷,并且无法在有限的资源内对所有程序模块进行审核。为了及时帮助开发和测试人员定位软件中存在的缺陷,软件缺陷预测成为当前软件工程数据挖掘[1]领域的重点研究方向。软件缺陷预测[2-3]是指挖掘软件仓库的历史数据信息,如代码复杂度、类型、变更记录等,可设计缺陷相关的度量元并构建分类器来预测软件中潜在的缺陷。
目前,大部分研究工作关注的是同一项目内的软件缺陷预测[4](Within-Project Defect Prediction,WPDP),即利用项目内的历史数据对新版本进行建模预测。但在实际的软件开发过程中,对于新启动的项目而言,通常没有足够多的训练数据来建模训练,而重新对新项目中的缺陷数据集进行标注,需要耗费大量的人力与物力资源。因此,一些研究人员开始关注跨项目软件缺陷预测[4-5](Cross-Project Defect Prediction,CPDP),即利用其他项目(源项目)的历史数据建立缺陷预测模型,然后对当前项目(目标项目)进行缺陷预测。然而,由于源项目和目标项目之间的数据分布存在较大差异,会导致直接利用源项目中的数据进行建模不能达到较好的预测性能,因此缩小源项目和目标项目数据集之间分布的差异性是跨项目软件缺陷预测领域中的关键问题。此外,人工标注项目数据集的过程中容易产生噪声数据,这将导致后续实例迁移的偏差。
针对实例存在噪声和数据分布差异性的问题,本文从实例过滤和实例迁移的角度出发,提出一种两阶段跨项目缺陷预测方法CLNI-KMM。在实例过滤阶段,借助CLNI[6]算法对训练数据集中的每一个实例选取其附近的k个邻居,计算与该实例标签相反的邻居占所有邻居的比例,如果有一定数量的邻居具有相反的标签,则该实例被视为噪声并被过滤。在实例迁移阶段,借助KMM[7]算法,利用源项目和目标项目中的数据计算源项目所有实例的训练权重,对与目标项目实例分布相近的实例赋予较高的权重。在此基础上,利用目标项目集中已有的少量有标注数据,结合带有权重的源项目训练数据建立缺陷预测模型。
1 相关工作
跨项目软件缺陷预测采用其他项目(即源项目)的训练数据集进行模型的建模,然后对当前目标项目进行缺陷预测。为解决不同数据源之间的分布差异性问题,迁移学习的相关方法被应用到了跨项目软件缺陷预测领域中。TCA[8]是基于特征的经典迁移学习方法,采用TCA来从源项目中提取与目标项目相关的特征,从而减少源于和目标域的距离。在基于实例迁移方法中,NNfilter[9]过滤与目标项目集中的实例不够接近的源项目中的实例,只保留每个目标项目实例中最接近的k个源项目实例邻居。文献[10]提出一种迁移朴素贝叶斯(TNB)的方法,首先通过调整源项目中的实例权重,削弱不相关实例的影响,然后将带有权重的训练实例放入朴素贝叶斯模型中进行训练。文献[11]提出了基于Box-Cox转换的集成跨项目软件缺陷预测方法。文献[12]利用 Box-Cox、Log和Rank转换对源项目进行多重变换,最终得到最接近于目标项目的训练实例集。文献[13]提出了一种基于度量元相似度的多源异构缺陷预测方法。研究表明,利用目标项目中少量的有标记数据能提升跨项目软件缺陷预测模型的性能。
然而,无论是基于特征迁移的TCA、基于实例过滤的NNfilter,还是基于实例权重调整的TNB、基于特征变换的Box-Cox或相似度计算的多源异构,都要对源项目中的实例进行筛选、权重调整或特征变换。因此,实例标注的准确性会对后序的源项目实例迁移和缺陷模型的构建产生重大的影响。然而在挖掘软件历史仓库时,对软件程序模块进行类型标注时可能产生噪声,这些噪声的存在会影响到实例迁移的效果。而上述研究工作并没有对可能产生噪声数据的源项目进行去噪处理,从而影响了跨项目缺陷预测模型的性能。
针对实例的噪声和分布差异性问题,本文从实例过滤和实例迁移的角度出发,利用源项目的训练数据集和目标项目中的少部分标注数据集建立缺陷预测模型,提出一种两阶段跨项目软件缺陷预测方法CLNI-KMM。
2 CLNI-KMM跨项目缺陷预测方法
如图1所示,CLNI-KMM方法包含2个阶段:实例过滤和实例迁移阶段。在实例过滤阶段,为去除源项目集中的噪声数据,CLNI-KMM方法首先对源项目集中的每一个实例,选取最靠近它的k个邻居。当这k个邻居中与该实例标签相反的个数达到一定数量时,则该实例被判定为噪声数据,过滤所有的噪声数据,最后得到去除噪声后的源项目集。在实例迁移阶段,为降低源项目集和目标项目集之间分布的差异性,采用KMM算法计算源项目实例与目标项目实例之间的相似度,为每个实例分配相应的训练权重,提高与目标项目集相似的实例权重,降低与目标项目集差异大的实例权重,再结合目标项目集中少量的有标签数据,建立缺陷预测模型,对新项目中的程序模块进行缺陷预测。

图1 CLNI-KMM软件缺陷预测流程Fig.1 Procedure of software defect prediction of CLNI-KMM
2.1 实例过滤阶段
人工采集标注的源项目数据集通常会因为标记错误导致后期预测模型的性能下降。如果能在建模之前找出这些噪声并将其从实例中过滤,那么过滤后的数据将更有利于分类器建立准确的预测模型。根据文献[6]研究可知,CLNI算法在不同的噪声比例下都表现出了良好性能,使得预测模型的准确度得到提升。因此,本文采用了一种有效的错误标签检测方法CLNI来去除噪声数据。对于每一个实例,选取距离该实例最近的k个邻居。当有一定数量的邻居和该实例的缺陷标注类型相反时,则认为该实例大概率是噪声数据。
算法1CLNI实例过滤

输出源项目中的噪声实例集合A
初始化列表A,阈值δ、ε,邻居个数k
1.For each iteration j:
7.End
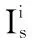
θ=n/k*100%
9.If θ≥δ:
11.End
12.End
13.If |A)j∩Aj-1|/|Aj|≥ε:break
14.End
15.return Aj

2.2 实例迁移阶段
在实例迁移阶段,本文采用KMM实例迁移算法,目的是调整源项目中训练样本的权重,降低与目标项目分布差异较大的实例对缺陷预测模型的影响。与其他的实例迁移算法不同,KMM是一种非参数方法,不需要估计不同类别的概率分布。此外,该方法只要使用源项目和目标项目的实例集合就能求解出样本的训练权重,不需要使用类标签信息。
通常,源项目和目标项目之间的分布差异性较大,因此,根据源项目的联合概率分布Prs(x,y)和目标项目的联合概率分布Prt(x,y)无法推断出很好的估计量。因此,KMM假设源项目和目标项目的2个条件概率分布是相同的,即Prs(y|x))=Prt(y|x))。基于上述假设,以及Pr(x,y)=Pr(y|x))Pr(x),可以得出Prs(x,y)和Prt(x,y)只受Prs(x)和Prt(x)影响。因此,降低Prs(x,y)和Prt(x,y)的分布差异性可以转化为降低Prs(x)和Prt(x)的边缘分布的差异。

(1)

式(1)是一个有约束的二次规划问题,可以被转化为以下形式:
(2)
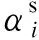
3 实验设计
3.1 实验数据集
为评估CLNI-KMM方法,本文采集了15个Java开源项目作为实验数据集,项目的静态度量元特征和其对应代码文件的缺陷标注数据集来源于Promise公开数据库(https://github.com/klainfo/DefectData)。表1展示了这些项目的具体信息,包括项目名称、项目版本、代码文件数和缺陷率。此外,本实验选取的20个静态度量元特征都是由文献[21]针对面向对象程序语言设计提取的,包括代码行数、子类个数、公共方法的个数、树的继承深度以及相关代码复杂度特征等。

表1 Java项目数据集信息Table 1 Dataset information of Java project
3.2 实验环境与类不平衡问题
本实验中,采用cvxopt,Scikit-learn(0.19.2)和Python3.6来构建缺陷预测模型。实验运行环境是Ubuntu16.04服务器,配有3.60 GHz的因特尔i7处理器和8 GB内存。表1中的一些项目(jedit,elearn)的缺陷率很低,而有一些项目(log4j,xalan)则拥有很高的缺陷率,这表明Promise数据集存在类不平衡问题。为解决此问题,本文使用过采样技术SMOTE[22]来合成少数类,从而使得两类达到平衡。
3.3 评价指标
本文采用2种评测指标,即F1值和准确率来评价缺陷预测模型的性能,其中F1值用来度量预测模型的稳定性,而准确率用来度量预测模型精确度。F1值是综合考虑了查准率和召回率的度量方法。本文用c代表无缺陷的程序文件,用b代表有缺陷的程序文件。然后,定义以下3种情况:1)b→b代表将有缺陷的文件预测为有缺陷的;2)b→c表示将有缺陷的文件预测为无缺陷的;3)c→b则是将无缺陷的文件预测为有缺陷的。N代表了每种情况下的数量,比如Nb→b表示第一种情况的数量。最后定义软件缺陷预测中的查准率、召回率、F1值和准确率,如式(3)~式(6)所示。
查准率:标记为有缺陷的文件被正确预测的数量在所有被预测为有缺陷的文件中的占比。
(3)
召回率:标记为有缺陷的文件被正确预测的数量在所有标记为有缺陷文件中的占比。
(4)
F1值:查准率和召回率的调和平均数。
(5)
Acc值:预测正确的文件数在总文件数中的占比。
(6)
此外,使用Friedman[23-25]检验来分析评价指标在统计上的显著性。Friedman检验服从自由度为k-1的卡方分布,其原假设为多个方法间的效果不存在显著的差异。如果发现检验结果的p值足够的小(小于0.05),则认为原假设并不成立,即各个方法之间存在显著性差异。进一步,采用Nemenyi[26]的后置检验来比较CLNI-KMM方法和其他经典的跨项目缺陷预测方法之间的差异。
4 实验与结果分析

4.1 与其他经典CPDP方法的预测性能对比
为检验CLNI-KMM方法与其他3种经典CPDP方法之间的差异性,本文采用Friedman检验方法对各个方法的Acc值进行分析。由于共有5种方法,因此自由度k=4。如表2所示,检验结果的p值为8.77×10-8(远小于0.05),反映了CLNI-KMM和其他经典CPDP方法之间的差异性。

表2 CLNI-KMM与4种CPDP方法之间的Friedman检验结果Table 2 Friedman test results of CLNI-KMM and four CPDP methods
表3展示了CLNI-KMM和其他4种CPDP方法之间的Nemenyi后置检验结果。实验结果表明,CLNI-KMM方法与其他经典CPDP方法之间的显著性差异主要体现在TCA和NNFilter中。

表3 CLNI-KMM与4种CPDP方法之间的Nemenyi检验结果Table 3 Nemenyi test results of CLNI-KMM and four CPDP methods
表4和表5分别列出了不同方法之间的Acc和F1值对比结果,其中粗数据表示最佳值。所有其他方法都与CLNI-KMM方法一样,在训练集中加入来自目标项目中的少量(5%)有标签数据。
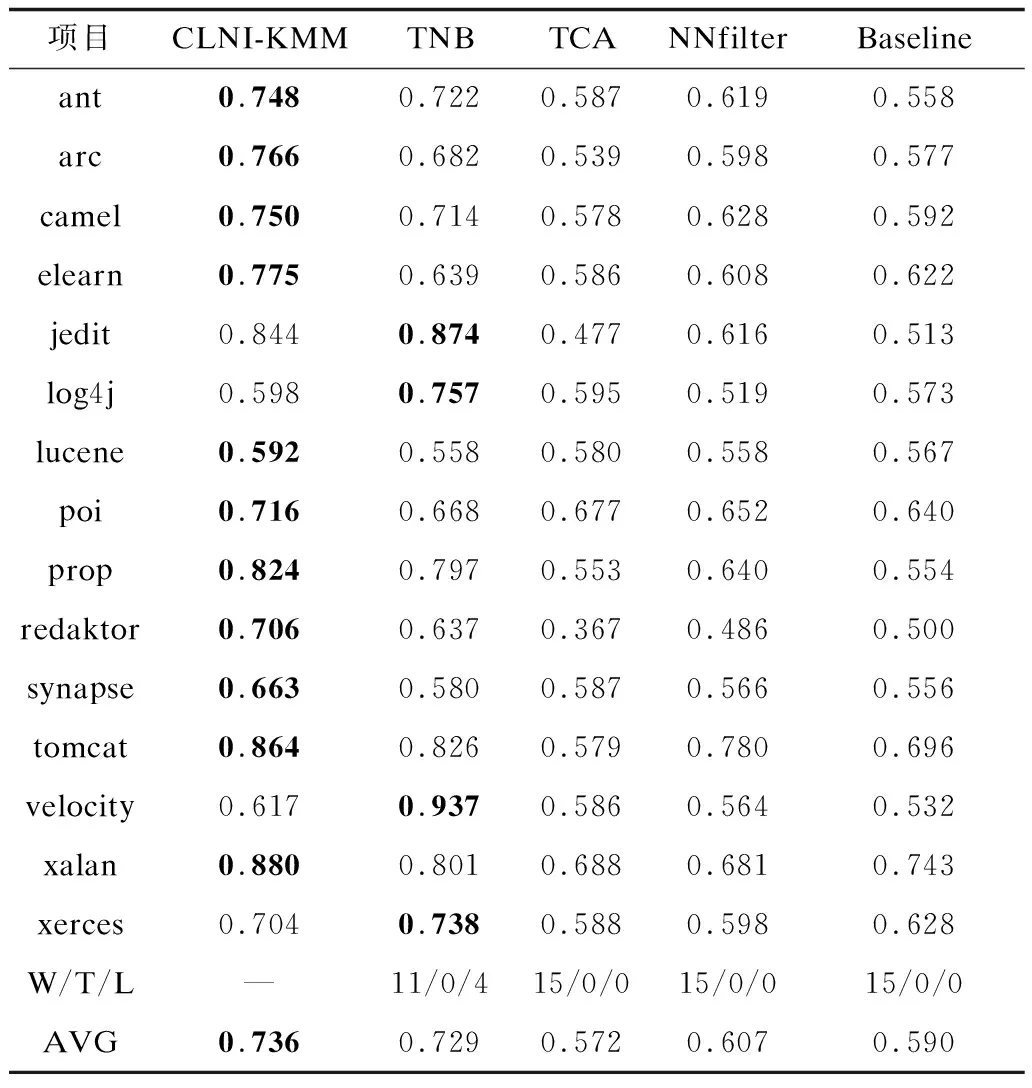
表4 CLNI-KMM与CPDP之间的Acc值比较Table 4 Comparison of Acc between CLNI-KMM and CPDP

表5 CLNI-KMM与CPDP之间的F1值比较Table 5 Comparison of F1 value between CLNI-KMM and CPDP
相较于TNB方法,CLNI-KMM方法在Acc和F1值的W/T/L上分别赢了11次和10次,这表明CLNI-KMM在模型在稳定性和预测准确性上都占有较大的优势。相较于经典的TCA方法,CLNI-KMM方法在Acc的W/T/L上全部占优,而在F1值的W/T/L比较中与TCA持平。该结果表明CLNI-KMM的模型稳定性与TCA方法接近,而在模型的准确率上有较大的提升。从外,在Acc和F1值的W/T/L比较中,CLNI-KMM都比NNfilter方法表现得更为出色,分别赢了15次和11次,这都反映出了CLNI-KMM模型的优越预测性能。最后,根据Acc和F1-值的平均值来看,CLNI-KMM也比TNB、TCA以及NNfilter在Acc和F1值上分别提升了1.0,28.7,21.3和3.3,0.7,10.4个百分点。
基于上述分析,相较于经典的CPDP方法,CLNI-KMM通过同时考虑实例过滤和实例迁移,在使用CLNI算法过滤源项目噪声的基础之上,再运用KMM算法对实例进行迁移,提升了软件缺陷预测模型的准确率和稳定性,达到更好的预测性能。
4.2 有效性影响因素分析
从外部有效性和内部有效性2个角度对本文方法进行有效性分析。外部有效性反映的是实验研究得到的结论是否具有普遍性,本文采用Apache下开源的Java项目数据集,所有关于项目程序模块的静态度量元数据集能从Promise公开数据库中获得,因此,可以保证研究结论具有一定的代表性。内部有效性则反映实验结果的正确性,本文编写的代码主要是基于Python的cvxopt模块和Scikit-learn机器学习包,因此,可以最大程度上保证模型构建的正确性。在评估指标上,本文从模型的准确性和稳定性出发,采用Acc和F1值分别进行衡量,保证了评价指标的可靠性。
5 结束语
本文以跨项目软件缺陷预测为研究背景,提出一种跨项目软件缺陷预测方法CLNI-KMM,其中包含实例过滤和实例迁移2个阶段。对源项目进行噪声实例的过滤,保证源项目实例集的可靠性,并在实例迁移过程中为源项目的实例分配训练权重,减少与目标项目不相关实例的负面影响。在此基础上,结合目标项目集中少量的有标签数据集建立缺陷预测模型,对新项目中的程序文件进行缺陷预测。基于实际项目数据集的实验结果验证了本文方法的有效性。后续将尝试在实例迁移完成后,去除权重过低的实例,并验证此步骤是否会提升预测性能,同时将利用更多实际项目的数据集进一步验证本文方法的普适性。
