一种基于云模型和MNL结合的产品优化定位设计方法
2020-08-17刘电霆
刘电霆,黄 霞
(桂林理工大学 a.机械与控制工程学院;b.信息科学与工程学院,广西 桂林 541006)
0 引 言
产品定位[1]是指在已知顾客偏好、 竞争产品以及市场信息的前提下, 确定一个新产品的属性水平值的决策过程。企业在开发一款产品之前, 调查顾客的需求和偏好, 建立优化模型来求得最优的产品属性水平值及属性组合, 同时将产品的工程性能和市场性能结合起来优化新产品的设计[2]。
在产品定位中,顾客的选择购买行为表示方法主要是概率规则[3],它能真实地表示顾客选择行为,近年来被广泛应用。在概率选择规则假设下,效用被假设为一个随机变量,顾客购买行为是一个随机过程,故有学者提出了一些概率选择规则,例如多项式分对数规则(MNL)。国内外对产品定位开展了一些研究工作:雒兴刚等[4]讨论了小规模问题的精确求解方法,并针对顾客选择行为中负效用问题,采用多项分类评定模型(multinomial logit model, MNL)进行新产品定位; Hadjinicola 等[5]提出了一种基于自组织映射神经网络方法的新产品定位方法, 该方法结合了影响环的概念, 公司根据消费者购买竞争产品的概率来评估个体消费者,并决定追求消费者的强度;苗蕴慧等[6]借鉴参考依赖模型改进传统的MNL模型,在考虑套餐的多个属性及其参考点的前提下, 预测有限理性消费者选择套餐的行为; 舒方[7]引入基于层级离散选择实验的新产品定位与定价优化模型,以达到企业产品线利润最大化为目标,并通过实例验证了模型的可行性和有效性。
在MNL模型中, 属性效用值的计算涉及到定性与定量的问题。 本文引入云模型[8-14]描述顾客对产品属性的定性评价等, 实现定性与定量之间的转换, 再结合MNL模型来实现产品定位设计。
1 顾客对产品属性评价的云模型描述
1.1 产品定位设计概念
一般来说,产品属性水平之间的组合是有效的,产品轮廓可以由一组属性水平的组合来表示,如产品k有I个产品属性,每个属性i有J个属性水平,而每个属性的重要程度也不一样。产品定位设计的目标是:在最大化公司总利润的基础上,选取属性水平进行组合,求得其最优产品轮廓。产品定位轮廓如表1所示。

表1 产品定位轮廓Table 1 Product positioning profile
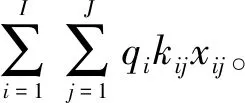
1.2 云模型
虽然自然语言的定性描述符合人们习惯、明了易懂,但定性描述越抽象,精确性就越差,反之亦然。这给计算机处理带来困难,需要建立由定性到定量的转化,因此本文采用云模型来实现。
设U是一个用数值表示的定量论域,C是U上的定性概念。 若定量数值d∈U是定性概念C的一次随机实现,d对C的确定度μ(d)∈[0, 1]是具有稳定倾向的随机数, 即μ:U→[0,1], ∀d∈U,d→μ(d), 则d在论域U上的分布称为云,即为C(D),每个d为一个云滴。利用期望(Ex)、 熵(En)、 超熵(He)3个数字特征描述不确定性, 即一个云模型可用(Ex,En,He)描述。
1.3 顾客对产品属性评价及其云模型的转换
设顾客采用n级标度对产品属性进行评价, 其中n=2t+1(t∈N), 其评价值用自然语言集记为H:H={hv|v=-t,…,0,…t,t∈N}。v表示顾客对产品属性进行评价的标度;t表示顾客对产品属性评价的标度范围最大值。例如, 按7级评价标度,对产品属性的语言评价集为H={h-3=非常差,h-2=差,h-1=较差,h0=一般,h1=较好,h2=好,h3=非常好}。 表2为产品属性定性评价, 其中,第一行表示产品的各属性水平; 第二行表示某个顾客对每个属性水平的自然语言评价;(hv)ij表示产品第i个属性选择第j个属性水平的自然语言评价。

表2 产品属性定性评价Table 2 Product attribute qualitative evaluation
定义1给定语言评价集H={hv|v=-t,…,0,…,t,t∈N},存在一个函数f可以将hv
转化为相应的数值θv,θv∈[0,1],即
(1)
式中:a的取值在[1.36,1.4], 可由试验得到[15], 本文取a≈1.37。
将定性的自然语言评价转换为定量的数值,步骤如下:
Step 1: 利用式(1)计算θv;
Step 2: 根据论域[Dmin,Dmax]的上下限值,计算期望Exv
Exv=Dmin+θv(Dmax-Dmin);
(2)
Step 3: 计算熵Env
(3)
(4)
Step 4: 根据Step 3,计算超熵Hev
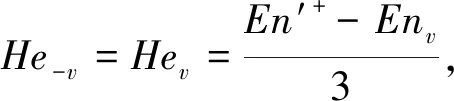
(5)
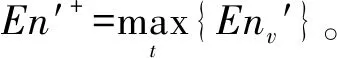
经过以上步骤, 定性的自然语言评价转换为定量的数值, 解决了评价语言的模糊性, 即利用标准评价云表示各语言评价区间的云数字特征Y(Exv,Env,Hev)。表3为产品属性评价云, 第一行代表产品各属性的水平值kij, 第二行代表顾客对各属性水平的自然语言评价(hv)ij, 第三行代表顾客评价的语言值转换后的云Y((Exv)ij, (Env)ij,(Hev)ij)。
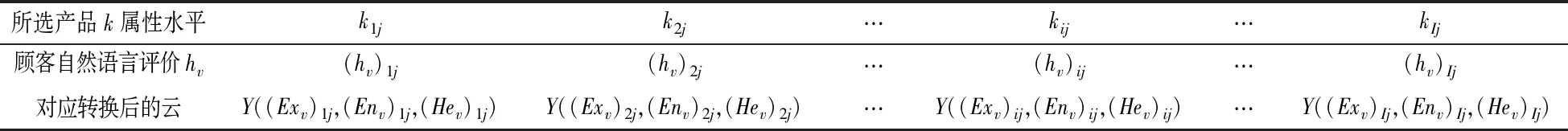
表3 产品属性评价云Table 3 Product attribute evaluation cloud
2 产品选择概率计算
Step 1: 根据顾客对产品各属性水平的评价云Y((Exv)ij,(Env)ij,(Hev)ij)计算属性水平效用值uij。
一类产品一般有多类顾客,而实际生活中不同顾客有着不同的特征属性,如性别、年龄、职位等,因此顾客也需要分类,而每类顾客占比不同,对产品评价的重要程度也就不同。在对属性水平效用值uij的解算过程中引入一个加权因子β,可根据顾客特征属性占比调整β取值,再结合评价云的Exv计算,以增强其合理性和可信度。设产品k有L类顾客,每类顾客有M人。uij的计算如下:
(6)
(7)
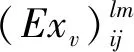
Step 2: 计算属性权重qi。
在产品定位设计中, 常根据经验确定属性权重, 主观性太强, 缺乏客观合理性, 且很难保证一致性。 为此, 本文结合云模型来确定属性权重。
经云模型转换后,对产品各属性的评价变为由3个数字特征组成的云模型,综合评价值越高,属性的效用值就越高,由此提出一种基于云模型确定权重的优化方法。对传统定位方法中要求保证所有权重和为1作出改进,将权重的平方和为1作为约束条件,从而降低权重模糊性。
模型如下:
(8)
其中,qi为各属性的权重值; 当第i个产品属性的第j个属性水平被选定时xij=1, 否则xij=0。
使用拉格朗日函数进行求解,最后得到权重:
(9)
Step 3: 计算顾客偏好Uk。
最常用的顾客偏好的表示方法是将产品属性水平效用值的线性叠加, 即
(10)
Step 4: 计算产品选择概率Ck。
根据多项式MNL模型,在相关竞争产品中, 顾客选择产品实例k的概率Ck为
(11)
式中:Ur是第r个竞争产品的效用值r=1,2,…,R,γ是MNL比例系数, 如果其趋近于无限大, 该模型就近似于确定性选择, 即顾客是绝对理性的, 只选择性能偏好的产品; 如果γ趋近于0, 则模型就近似于随机选择, 选择概率趋向于随机均匀分布, 本文γ标定为0.5。
3 云模型和MNL结合的产品定位优化建模
3.1 产品获利能力指标
在顾客购买规则基础上, 购买新产品k的期望顾客数量为Qk=QCk, 则产品获利能力指标EP为
(12)
式中:fij为第i个属性的第j个属性水平的单元费用;Q为顾客人数;W为产品成本费用;p为产品的价格。
3.2 优化模型
最大化产品的获利能力指标EP下,产品定位设计的优化模型为
(13)
3.3 模型求解算法的选择
上述优化模型是一个非线性模型, 包含离散型决策变量xij和连续型变量p, 可以将模型看作一个产品配置问题, 即确定产品属性水平和价格的组合。 产品属性繁多复杂, 属于组合优化中NP难问题。 鉴于人工蜂群算法(artificial bee colony algorithm, ABC)相比GA(遗传算法)、 PSO(粒子群算法)和DE(差分进化算法)等, 具有参数设置少 、收敛速度快, 且收敛精度高等优点[16-19]。 本文采用ABC算法对上述产品定位设计优化模型进行求解。
在ABC算法中,有两次随机产生初始解:一次是种群初始化时,另一次是当一个食物源在最大循环次数limit内没有更新,则由侦查蜂产生初始解。因此,本文将初始化分开改进,并对搜索策略方法也提出了改进的方法。具体改进方法为
1)种群初始化改进。因为初始解是随机产生的,所以随机解中可能出现个体过度集中,降低算法全局搜索性能,过度依赖侦查蜂的现象。因此,本文结合反向学习策略对初始化进行改进。在搜索空间范围内随机产生N/2个食物源(设种群数量为N=r×M), 设空间解为gi, j∈(gi, min,gi,max),反向解计算公式为
gi,j′=(gi,min+gi,max-gi,j)。
(14)
计算所有食物源的适应度, 包括反向食物源, 选择最好的r个食物源分别作为思维进化思想中的子种群的中心点。 以r个中心点为基准分布, 各生成M个服从正态分布的随机食物源。
2)侦查蜂初始化改进。传统的ABC算法对侦查蜂的初始化生成的食物源位置随机性太强,导致收敛速度慢,而且容易陷入局部最优。然而高斯分布具有很强的扰动性,在高斯分布中,随机扰动项的应用能够解决个体陷入局部最优问题,提高解的精度:
gi,j=gbest,j+gbest,j·N(0,1)。
(15)
3)搜索策略方法改进。原始的人工蜂群算法中,侦查蜂和跟随蜂进行搜索时,所采用的搜索策略全局搜索的能力比较好,但是忽略了局部搜索的能力。因此,参照粒子群算法,引入当前最优解和次优解,提出一种新的搜索方式:
vi,j=gbest,j+φi,j(gw,j-gk,j)+δi,j(gsecondbest,j-gi,j)。
(16)
其中,vi,j是候选食物源;gw,j、gk,j是随机产生不相等的已知解;φi,j、δi,j是[-1,1]上的随机值;gbest,j是当前最优食物源的位置;gsecondbest,j是当前次优的食物源位置,引入当前最优解和次优解后,可在一定程度上提高算法的局部搜索能力,加快收敛速度。
4 算例及其分析
4.1 问题描述
某企业进行某型号手机的产品设计定位,其属性及属性水平见表4。新产品定位设计的目标是在最大化公司总利润的基础上,选取属性水平进行组合,求得其最优产品轮廓。
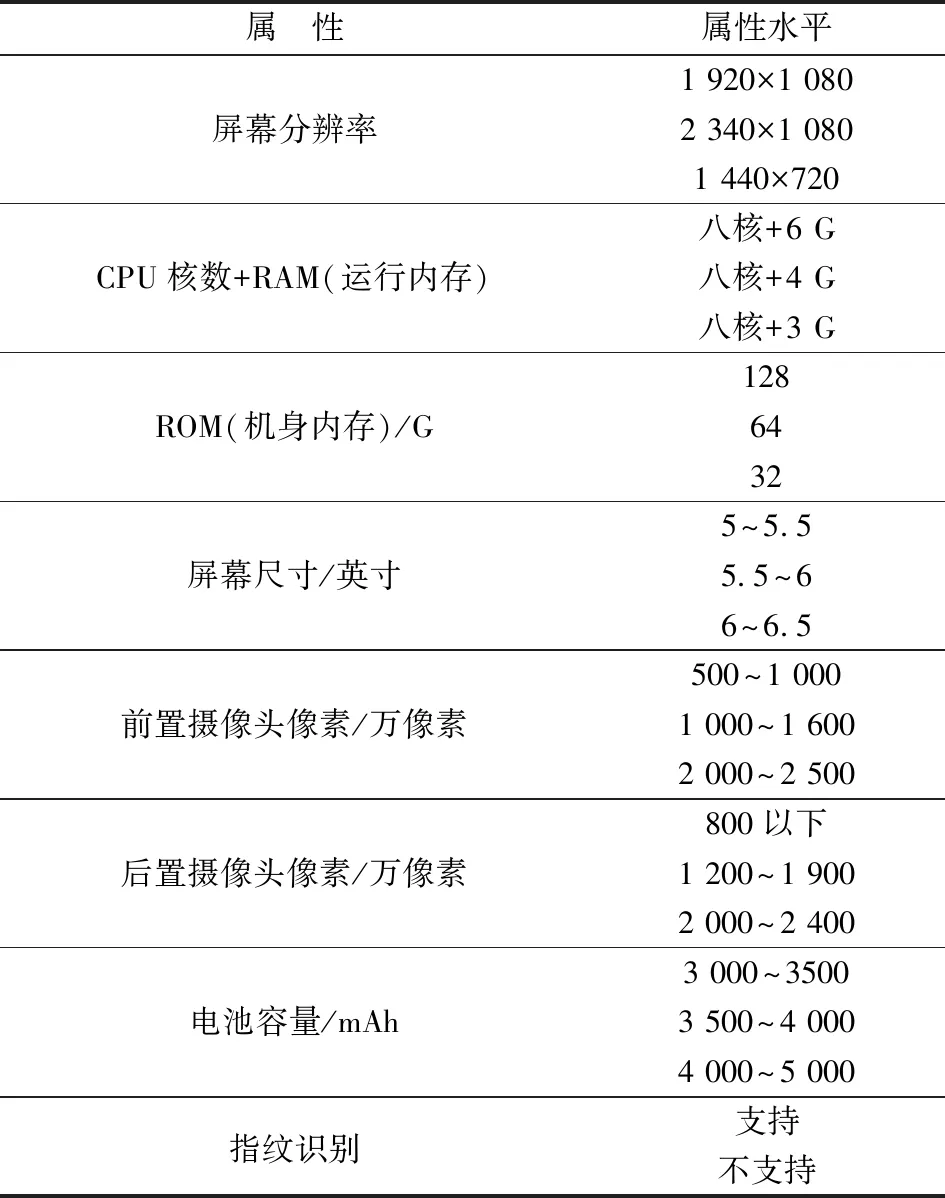
表4 某型号手机的产品属性及属性水平Table 4 Product attribute and attribute level of a type of mobile phone
4.2 调查结果分析
4.2.1 属性偏好问卷调查 本次问卷对确定要研究的手机23个属性水平的偏好程度设置问题,选项包括非常好、 好、 较好、 一般、 较差、 差和非常差7个等级。 面向在校学生,随机抽取200名作为调查的对象。所获得的200份统计结果中有效问卷数为186份,其中男性100份,女性86份。分析186份有效问卷,得出手机的属性水平效用值。
4.2.2 调查结果分析 部分调查结果见表5。

表5 调研结果展示Table 5 Survey results list
1)根据式(1)可以求得θi, 定性评价语言转换为云模型,t=3, 则θ-3=0,θ-2=0.221,θ-1=0.382,θ0=0.5,θ1=0.618,θ2=0.779,θ3=1。
2)利用式(2)~(5), 计算得出3个数字特征, 设论域范围[Dmin,Dmax]=[2, 8], 则Ex-3=2,Ex-2=3.326,Ex-1=4.292,Ex0=5,Ex1=5.708,Ex2=6.674,Ex3=8;En-3=1.779,En-2=En2=1.598,En1=En-1=1.265,En0=1.157,En3=1;He-3=He3=0.074,He-2=He2=0.134,He-1=He1=0.245,He0=0.281。
3)七标度的语言值转换为七朵云:Y-3(2, 1.779, 0.074),Y-2(3.326, 1.589, 0.134),Y-1(4.292, 1.265, 0.245),Y0(5, 1.157, 0.281),Y1(5.708, 1.265, 0.245),Y2(6.674, 1.598, 0.134),Y3(8, 1.779, 0.074)。
4)通过式(6)、 (7)求得uij, 式(8)、(9)求得qi, 结果见表6。
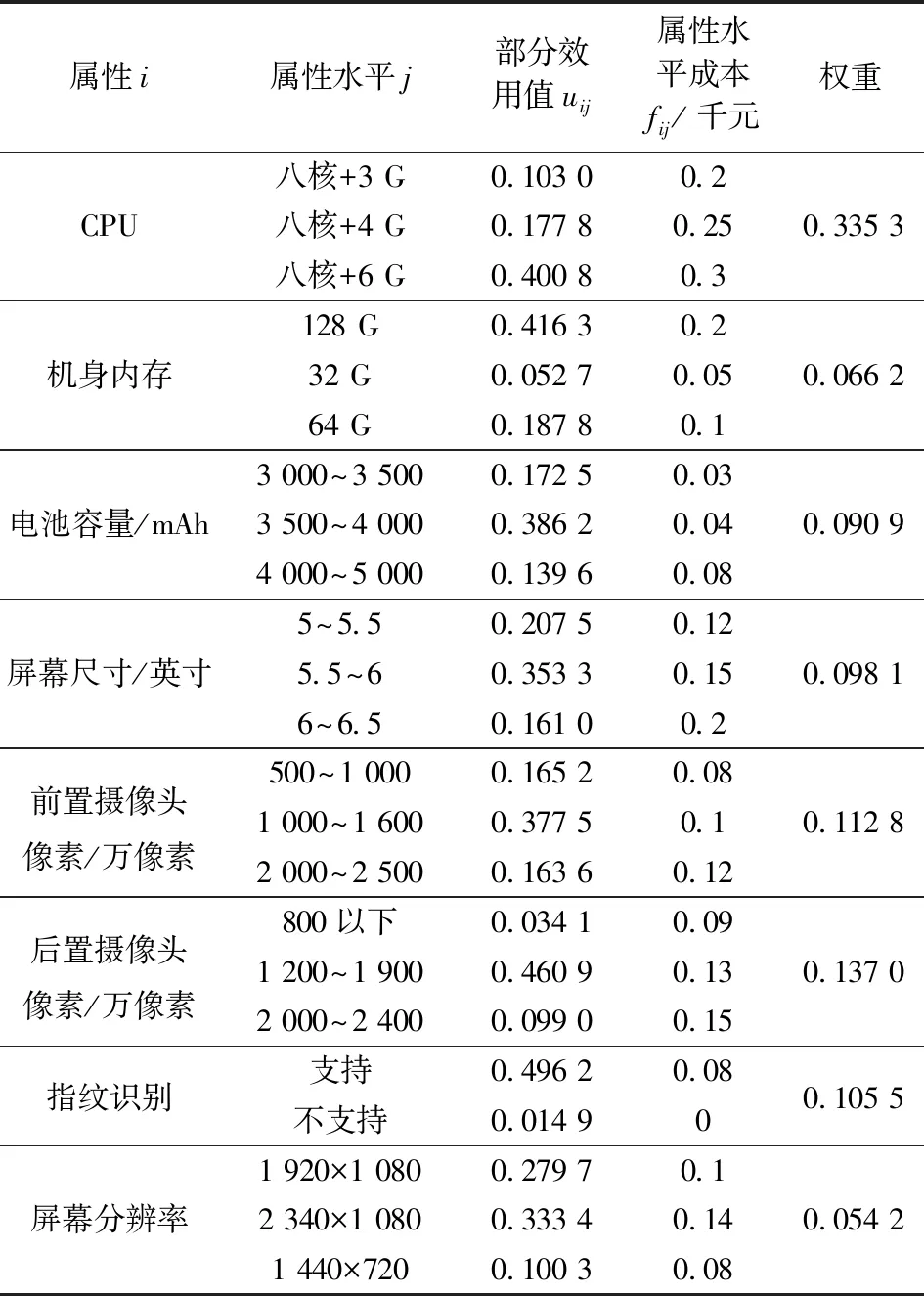
表6 属性水平的部分效用值、成本费用及属性权重Table 6 Partial utility value,cost and weight of attribute level
4.3 实验结果及分析
4.3.1 算法比较结果及分析 使用MATLAB分别对原始版本的ABC算法、 文献[20]算法(IABC)和本文改进的ABC算法进行仿真实验, 3种算法的初始解都是随机生成的。 设置种群的规模N=100, 搜索的空间维数Dim=50, 迭代次数最大值MCN=2 000, 循环次数limit=100。 将原始ABC算法、 文献[20]算法(IABC)与本文改进的ABC算法分别在Rosenbrock函数和Rastrigin 函数上进行测试, 对测试效果进行一一对比分析。 各测试函数参数见表7, 3种算法的测试结果如图1、 图2所示。

表7 两种测试函数的表达式、搜索范围、最小值Table 7 Expressions, search range and minimum values of the two test functions
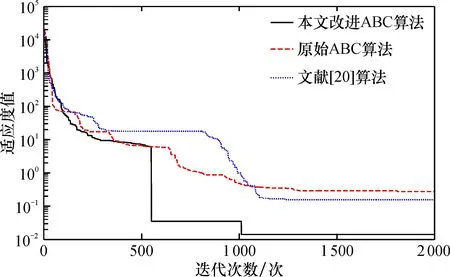
图1 Rosenbrock函数的适应度Fig.1 Fitness of Rosenbrock function
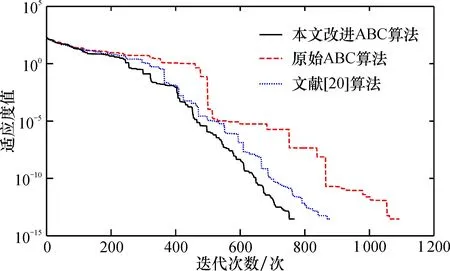
图2 Rastrigin函数的适应度Fig.2 Fitness of Rastrigin function
可以看出,原始ABC算法在测试函数上出现陷入局部最优以及收敛速度缓慢;与原始算法相比,文献[20]算法虽然在迭代次数上有所减少,收敛速度也有所提高,但是在全局搜索能力上还是有所欠缺;本文改进的ABC算法结合反向学习策略对种群初始化进行改进,有了很好的全局搜索能力;在搜索策略方面,本文方法引入当前最优解和次优解后,算法的局部搜索能力得到了一定的提高,收敛速度也有所加快,减少了迭代次数;在侦查蜂初始化时,引入了高斯分布因子之后,可以帮助个体跳出局部最优解,从而提高求解精度(图1)。
通过实验对比两种测试函数,改进的人工蜂群算法相比于文献[20]算法和原始的人工蜂群算法,提高了求解精度和收敛速度,在一定程度上解决了人工蜂群算法容易陷入局部最优解和后期收敛速度比较慢的缺点。
4.3.2 产品功能属性配置模型求解结果对比 图3为产品线利润的迭代图,用原始的ABC算法求解模型时,要迭代51次才能找到最优解,而本文改进的ABC算法在迭代29次就找到最优解,说明本文算法更好,加快了收敛速度,全局搜索能力也很好。通过不断的迭代,目标函数值增加,直到找到最优解,即目标函数值最大也就是产品利润最大。根据算法的运行结果,当期望顾客数量Q=200时,产生的新产品最大总利润值为EP=87.64千元,每部新手机产品的利润为0.93千元。表8给出了人工蜂群算法的最优解,得到了新产品定位的最优组合。
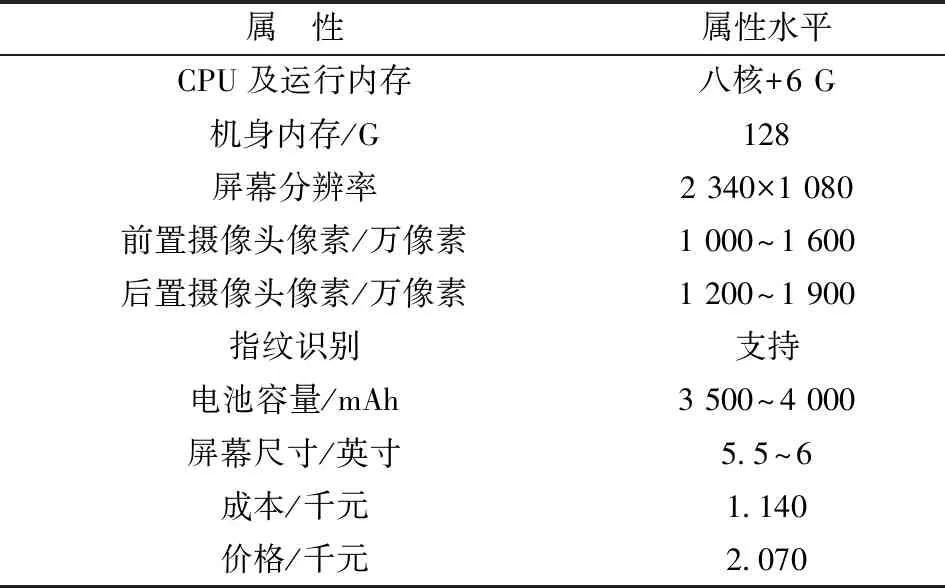
表8 产品定位的最优解Table 8 Optimal solutions for product positioning
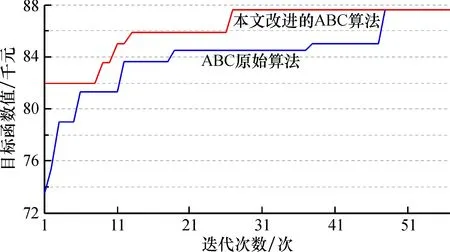
图3 产品利润迭代Fig.3 Product profit iteration
可见,产品的定位并不是将所有最优的属性水平进行组合,而是将这些属性的属性水平进行重新搭配,降低某些用户不太关注的产品属性配置,也降低了产品的价格,最终达到产品利润最大化的目标。
5 结束语
产品定位的精准性一直是企业最关心的问题。本文利用云模型完成属性评价语言定性到定量的转换,解决了属性评价语言的模糊性,根据顾客特征属性计算产品属性效用值,结合MNL模型建立产品定位优化模型,采用改进的人工蜂群算法进行模型的求解,并以手机产品为案例验证了该产品定位设计方法的可行性和合理性。
本文研究的只是单一的以利润最大化为目标的产品定位设计优化问题,今后的研究方向是考虑多目标的新产品定位设计优化问题,但是会增加模型求解的难度。另外,进行消费者网络上大量购买行为的挖掘,也是下一步需要研究的,可以通过互联网+大数据的爬取和分析得到,从而构建一个大数据驱动的产品定位设计模型系统,为广大企业产品开发提供支持。
