一种融合情感规则与机器学习的情感分类方法
2020-08-16宛艳萍孟竹唐家明谷佳真张芳
宛艳萍,孟竹,唐家明,谷佳真,张芳
一种融合情感规则与机器学习的情感分类方法
宛艳萍,孟竹,唐家明,谷佳真,张芳
(河北工业大学 人工智能与数据科学学院,天津 300401)
针对评论型长文本的情感倾向性问题,提出了一种融合情感规则与机器学习的分类方法.基于情感规则得出评论的情感得分,该方法将文本分解为一组子句,以词汇为基本颗粒进行分数计算,得出最佳位置权重系数.同时,不同类型句式共归纳出4类关联词与之对应.将所得权重系数与关联词得分相结合,总结出情感计算公式.然后将所得情感得分作为特征融合到机器学习分类器的输入矩阵中,构造最优情感分类器.实验所得最优分类器准确率为0.979,高于同类算法.
情感倾向性;情感规则;权重调优;关联词;特征融合;最优情感分类器
情感分析通过对文本语义信息进行挖掘,能够识别出文本所蕴含的积极或消极的情感.现今用户通过发布售后评论、电影评论等来表达自己的情感,这些评论都包含着丰富的观点信息,可供商家和消费者参考而做出更加合理的判断.
朱嫣岚[1]等提出了词汇语义倾向的概念,将重点放在词汇情感倾向上.刘知远[2]等基于不同规模的词典语料库建立了汉语词同现网.张磊[3]通过条件随机场算法提取核心句并计算相应的情感权值.经阅读大量文献发现,当前的情感分析研究大致分为2种.第1种方法,通过设定一系列语义规则并构建情感词典[4-6],对文本进行分级处理,计算整体情感分值,其情感分析的基础对象是单个词汇.第2种方法,基于机器学习.首先对训练数据进行预处理,然后结合TF-IDF等方法提取特征向量,构建向量特征空间,但对一些特殊句式不能准确识别其情感倾向,所以本文将两者特征融合,来构造最优情感分类器.
本文以数码产品的售后跟踪与评价为例,从评论中获取用户的情感信息,准确地分析出用户评论中的情感倾向性,有利于商家准确地了解市场情感,推出大众更容易接受和喜爱的产品.
1 情感词典的构建
情感词典需要不断整理归纳,本文整合基础词典、网络热点词词典、专业领域词典以及表情符号词典,最终得到覆盖领域较大的中文情感词典.
1.1 基础情感词典
本文选取的中文情感词典包括:HowNet情感词典和NTUSD情感词典[7],将HowNet中文情感词典进行整理后有褒义词4 560个,贬义词4 370个;NTUSD包含褒义词2 810个,贬义词8 270个.
1.2 网络热词词典
在如今信息时代,网络用语日新月异,基础情感词典已经不能满足要求,如柠檬精、笔芯等词带有明显的情感倾向,为了提高情感分类的准确度,构建了网络热点词情感词典.本文在网络热词发现过程中利用互信息合并候选字符串,结合了N-gram算法发现新词并更新词典,收集网络热点词完成情感词典的构建.其中包括褒义网络词,如小确幸、中国梦、逆袭等280个;贬义网络词,如玻璃心、柠檬精、坑爹等250个.
1.3 领域情感词典
由于在线评论中有很多专业词语,基础情感词典难以识别,本文构造了专属领域情感词典,其中包括手机、相机以及笔记本电脑领域的专业词汇.领域词典包括顺畅、清晰、画质高、颗粒感等240个褒义词;黑屏、死机、卡顿、Bug等180个贬义词.
2 权重调优算法
从最基本的词汇粒度出发,将一篇评论文本划分为不同的部分并给予不同的权重,再以词汇为基本颗粒进行分数计算.一篇文本的每个部分重要程度不同,对于一段评论文本,设定‘Head_num’,‘Tail_num’这2个参数,分别代表文本[0:Head_num]句和[Tail_num-1:]句.一般来说这2部分分数的权重相比于中间部分[Head_num:Tail_num]的权重更高.可以按文本长度设定参数的值,本文经过反复实验比较,设定参数值为2,即首2句和末2句.
若评论文本过短,本文认为其不够长度来进行分块,即[0:Head_num]∩[Tail_num -1:]≠∅,此时全文则采用统一权重来计算分数.为了减少首尾权重对于文本整体的影响过大,以至于算法忽略文本中间部分的分数,将首尾部分得出的分数乘以对应的频率,公式为
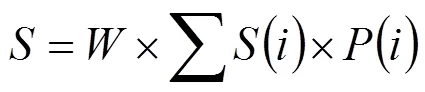
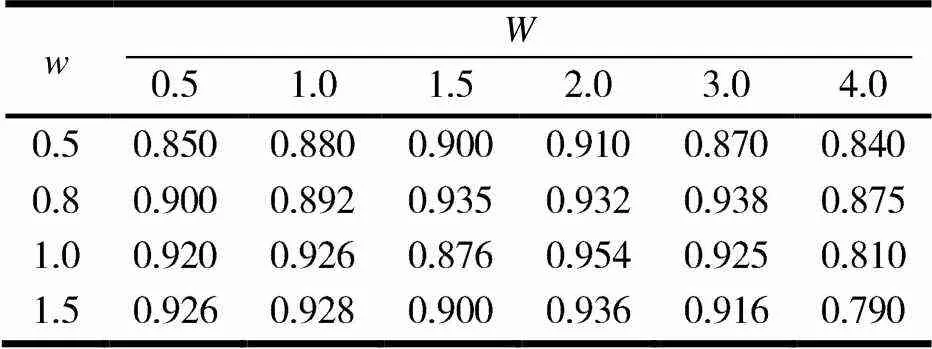
表1 积极评论准确率

表2 消极评论准确率
3 特殊句式处理算法
3.1 程度副词
在中文句式表达中,程度副词不可或缺,可以加强或削弱用户表达的语义情感[8].人工收集整理出70个程度副词,根据它们不同的语义表达将其细化为7个层次,程度副词强度值分布见表3.

表3 程度副词词表
根据程度副词不同的强度值赋予句子不同的情感得分,具体方法是在情感词的位置处向前搜索1~2个位置,根据其强度值,对分数乘以不同的系数.为了提高算法质量,降低程序在判定子分支语句方面的时间损耗.本文采用哈夫曼树的优化思想:将条件分支‘if-else’看成二叉树的结构,根据程度副词在日常用语中出现的频率,首先判断‘very’和‘over’,再依次判断‘more’‘most’和‘some’‘ish’和‘inverse’,来达到树的加权路径最小的目的.
3.2 提取关联词
经过对大量句式研究总结,本文将句式分为9类.其情感倾向主要通过关联词后的情感词体现,本文共总结为4类关联词R1,R2,R3,R4分别对应几类句式,具体分布见表4.

表4 关联词
第1类关联词引导的分句通常与用户真正想表达的情感意图相反;第2类关联词引导的分句通常与用户真正想表达的意图情感相同;第3类则是用户情感意识的加强表达,如关联词“而且”“又…又”增加了句子相应的情感分数;第4类是直接将该总结句的情感判别为整个文本的情感.同时,否定词语对判定文本整体的情感非常重要.通过总结其在日常用语中出现的频次,本文收集55个否定词,构建了否定词典.
3.3 情感计算公式


4 机器学习算法
基于机器学习算法构建情感分类器,在对数据集进行相关的预处理过后,运用卡方统计方法进行特征提取,之后进行向量化,将所得到的特征词组(1,2,…,X)作为独立属性输入到各分类器中进行情感分类.数据集是从京东网站抓取的不同品牌的电子商品评论数据,人工标注后存储到不同的Excel表格中.选取8 000条有价值的电商售后评论,使用正、负评价集作为语料库,训练情感分类器,使用Python的Nltk api进行分类任务.本文比对了多个分类器的分类结果,实验结果见图1.
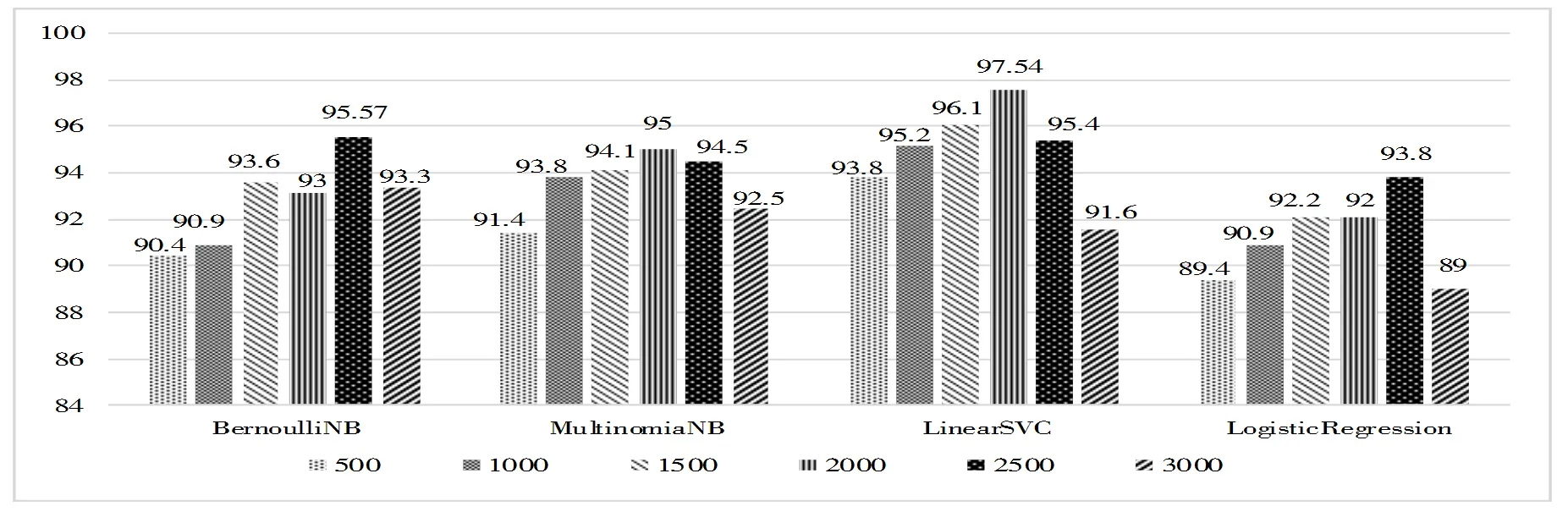
图1 不同分类器的分类准确率
由图1可知,当特征维数为2 000维时LinearSVC分类准确率最高,为97.54%;当特征维数为2 500维时BernoulliNB分类准确率最高,为95.57%.
5 实验结果
5.1 实验语料
本文数据是从京东网站抓取的不同品牌的电子商品评论数据,如华为、小米、Canon、Lenovo等,进行数据的去重、去噪等数据清洗工作,人工标注后存储到不同的Excel表格中.选取8 000条有价值的电商售后评论,其中手机品牌的4 000条,相机和笔记本各2 000条.
5.2 实验对比
为了进行对比,先后实现了李爱萍[9]等提出的句子情感加权算法和基于关键句分析的微博情感倾向性(SOAS)算法(见表5)[10].由表5可知,本文提出的权重调优及特殊句式处理算法在各评价指标中均高于其它方法.
表5 情感分析对比结果
5.3 融合情感规则特征

归一化就是要把需要处理的数据经过处理后限制在需要的一定范围内.本文是将评论分数归一化到(-1,+1)之间,是对原始数据的线性变换,使结果落到[-1,1]区间,公式为
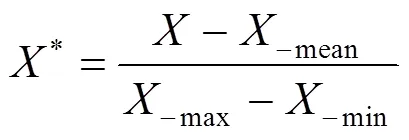
由图2可知,融合特征后各分类器准确率基本提高,在各个维度SVM的分类准确率普遍较高;当特征维数为2 000维时,LinearSVC分类准确率最高,为97.9%.整体情感分析过程见图3.
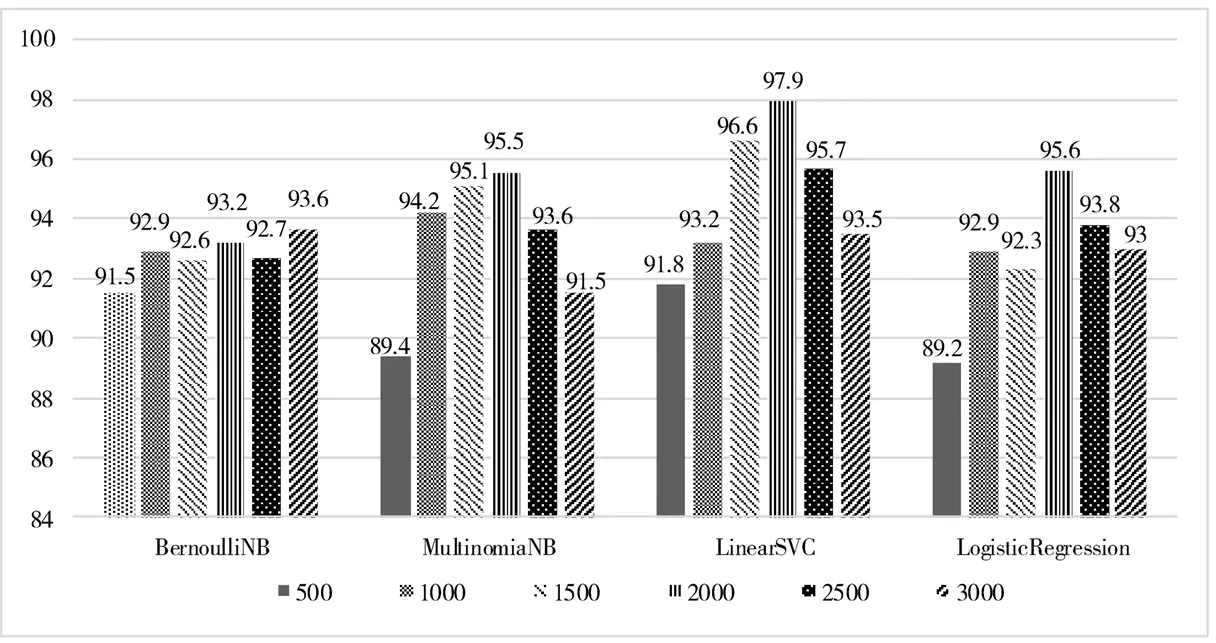
图2 融合特征后的分类准确率

表4 关联词
6 结语
本文构建了情感词典,包括网络热词词典、领域专属词典等,并通过N-gram算法进行网络新词发现更新情感词典.对文本进行分块处理权重调优,文本不同部分赋予不同的位置权重,进一步提出特殊句式情感计算规则,将特殊句式分为9类,不同类型的特殊句式所具有的关联词对文本有不同的影响,本文共总结为4类关联词.将权重调优实验所得最佳位置权重与特殊句式情感计算规则相结合,依次判定各评论文本所得情感分数,总结出情感计算公式.在对电商售后评论的情感分析中得到了较高的准确率.同时实现基于机器学习算法的情感分类,将所得评论情感分数归一化后作为特征融合到SVM,NB分类器中训练得到最优情感分类器,进一步提升了分类器的准确率.但仍存在不足之处,如有时一句话可能表达反义.因此,还需进一步研究确定不同句式表达对整个文本情感的影响.
[1] 朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):16-22
[2] 刘知远,孙茂松.汉语词同现网络的小世界效应和无标度特性[J].中文信息学报,2007,21(6):52-58
[3] 张磊.基于机器学习的情感分析方法研究[D].成都:电子科技大学,2018
[4] Xu Weidi,Tan Ying.Semi-supervised target-oriented sentiment classification[J].Neurocomputing,2019,337(14):120-128
[5] 杨欢.文本情感分类预处理研究[J].计算机技术应用,2016(10):187
[6] 卢兴.基于统计方法的中文短文本情感分析[D].北京:北京理工大学,2016
[7] Zhai Zhongwu,Xu Hua,Kang Bada,et al.Exploiting effective features for Chinese sentiment classification[J].Expert Systems with Applications,2014,38(8):9139-9146
[8] 林江豪,顾也力,周咏梅.基于表情符号的情感词典的构建研究[J].计算机技术与发展,2019,29(6):182-185
[9] 李爱萍,邸鹏,段利国.基于句子情感加权算法的篇章情感分析[J].小型微型计算机系统,2015,10(10):2252-2256
[10] 邵帅,刘学军,李斌.基于关键句分析的微博情感倾向性研究[J].计算机应用研究,2018(4):983-987
A method of emotion classification which combines emotion rules and machine learning
WAN Yanping,MENG Zhu,TANG Jiaming,GU Jiazhen,ZHANG Fang
(School of Artificial Intelligence and Data Science,Hebei University of Technology,Tianjin 300401,China)
A classification method combining emotional rules and machine learning is proposed to solve the problem of emotional orientation of long critical texts.First of all,the emotional score of the comment is obtained based on the emotional rules,the method refines the text into a set of clauses,with vocabulary as the basic particle scores calculated,it is concluded that the best position weight coefficient.Meanwhile,there are four types of related words corresponding to different types of sentence patterns.Combining the weight coefficient with the score of related words,the formula of emotion calculation is summarized.Then,the obtained emotion score is integrated into the input matrix of machine learning classifier to construct the optimal emotion classifier.The accuracy of the optimal classifier is 0.979,higher than the similar algorithm.
emotional tendency;emotional rules;weight tuning;relative term;feature fusion;optimal emotion classifier
TP391
A
10.3969/j.issn.1007-9831.2020.06.007
1007-9831(2020)06-0031-05
2020-01-03
河北省高等学校科学技术研究重点项目(ZD2014051)
宛艳萍(1968-),女,河北文安人,副教授,硕士,从事大数据处理与智能计算研究.E-mail:wanyp_ok@126.com
