强化学习框架下移动自组织网络分步路由算法
2020-08-14蒯振然王少尉
蒯振然,王少尉
(南京大学 电子科学与工程学院, 江苏 南京 210023)
移动自组织网络(Mobile Ad hoc NETwork,MANET)是一种无基础设施、由移动通信节点组成的无线网络,具有组网灵活、配置方便和抗毁性强等特点[1]。由于节点的通信范围有限,源节点与目的节点之间的通信经过中间节点的多跳路由完成。然而,在一些动态场景下,节点的移动性使得拓扑结构频繁变化,传统的路由协议需要不断地计算端到端的路由来保证数据的传输,缺乏对动态网络的自适应能力,而简单的洪泛机制会产生大量开销[2-3]。因此,研究针对MANET动态特性的具备自适应性和可靠性的路由方式,有重要的理论和应用价值。
最早将强化学习应用于MANET路由的工作见诸文献[4],文中提出的Q-Routing算法使用了强化学习的经典Q-Learning框架,将衡量路径优劣的权值置于每个节点维护的Q表中,根据Q表选择下一跳节点,传回的确认字符(ACKnowledge character,ACK)用来更新Q表以选择更好的路由。文献[5]则根据网络拓扑结构中节点的度来调整强化学习的学习速率,更高的节点度对应更高的学习速率,从而使用更少的时间来探测网络的真实状态。
在强化学习算法收敛到最优路由的过程中会伴随着吞吐率的损失,在高度动态的场景下,这种损失会使信息的传递效率降低,所以上述方法并不能直接应用于对信息完整性要求较高的情况。文献[6]提出从节点的广播消息获得邻居节点的Q值,通过这种方式减少探索网络状态所需的时间,降低算法在学习过程中的性能损失。文献[7]提出通过随机轮询邻节点的自适应Q-routing,用于防止数据包回传,该方法提高了路由在高负载条件下的稳定性。文献[8]提出了基于强化学习的智能鲁棒路由(Smart Robust Routing,SRR)算法,对每个节点,使用置信度来衡量邻居节点的可靠性。当网络状态相对稳定时,使用结合置信度的Q-routing方法进行路由,而节点移动导致网络状态不稳定时,则以一定概率使用广播的方式确保将信息传到目的节点,这种方式加快了在网络状态不稳定时路由的收敛速率,并保证了系统的吞吐率。然而,广播机制增加了路由开销。并且在Q值和置信度一直动态变化的情况下,按照统一度量选择下一跳节点,会有陷入路由环路的情况,使重复包检测机制进行丢包处理。
本文研究了MANET中的路由问题,对SRR算法的局限性做出改进,提出了一种基于强化学习的分步路由算法,通过结合强化学习路由Q-Routing和利用Q值筛选符合路由目标节点的方式,使节点更倾向于选择提升MANET网络性能的路由,保障数据包到达率。在筛选出的节点基础上,结合置信度实现在网络条件较差时只向部分节点广播,在提升路由可靠性的同时,降低了网络的路由开销。
1 强化学习路由框架
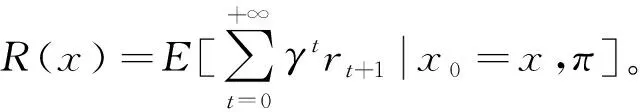
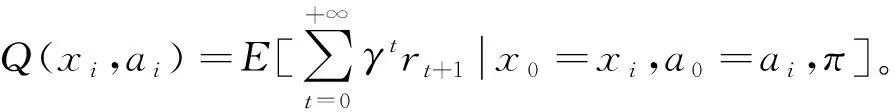
Qt+1(xt,at)=(1-αt)Qt(xt,at)+
(1)
式中,αt∈(0,1]是学习速率。式(1)代表以αt的速率用估计的累积奖赏对当前的累积奖赏进行更新[9]。在与环境交互的过程中,随着Q表的更新,Q值会逐渐接近于真实的累积奖赏,智能体在各种状态下会趋向于选择最优的动作。
1.1 Q-Routing
本节将介绍文献[4]如何将MANET路由问题归约到Q-learning算法的框架下,并具体说明在强化学习框架下所采用的奖赏与更新方式。对每个节点,可以将其看作智能体,每个节点只有在数据包到达节点时,才需要转发,所以只存在一种需要做动作的状态。节点需转发数据包至邻居节点,最终目的地是目的节点。
假设发送端可以检测发出数据包和接收到ACK之间的往返时延(Round Trip Time,RTT),可以将其作为节点选择下一跳节点的奖赏。以Q-Learning算法为框架,让每个节点m维护一个元素数目为其邻居节点数量的Q表。表中的每一项为Qm(d,n),代表选择邻居节点n作为下一跳节点的情况下,在到达目的节点d前的总RTT。该数值可以一定程度上体现节点的端到端时延性能,可以将最小化总RTT作为Q-Routing的目标。

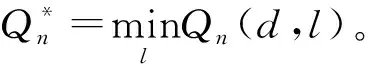
Qm,t+1(d,n)=(1-αt)Qm,t(d,n)+
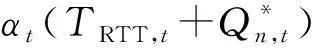
(2)
式中,等号右边第一项代表Q值的原始值,第二项可以代表Q值的更新部分,TRTT,t是第t次传输返回的RTT,αt∈(0,1]是第t次更新的学习速率,代表了Q值更新信息所占的权重。随着估计值接近真实值,αt通常随着更新次数减小,为了使Q值收敛,将把αt的取值与置信度的取值相联系。当更新次数增加到j次时,经过迭代,对于节点m,对应邻节点为n的Q值为:
(3)
式中,Qm,0(d,n)是节点m对应于邻节点n的初始Q值。从等号右边第二项可以看出,Q值更新信息距离当前时刻越近,赋予的权重越高,对Q值的估计也因此越容易跟踪网络的变化。
1.2 置信度
网络中每个节点同样维护一个置信度表,每一项为Cm(d,n),代表节点m选择邻居节点n作为下一跳节点的情况下,能到达目的节点d的可信度,其中Cm(d,n)∈[0,1]。

当数据包被转发时,更新过程[5]为:
Cm,t+1(d,n)=(1-η)Cm,t(d,n)
(4)
节点m接收节点n的ACK后,更新过程为:
(5)
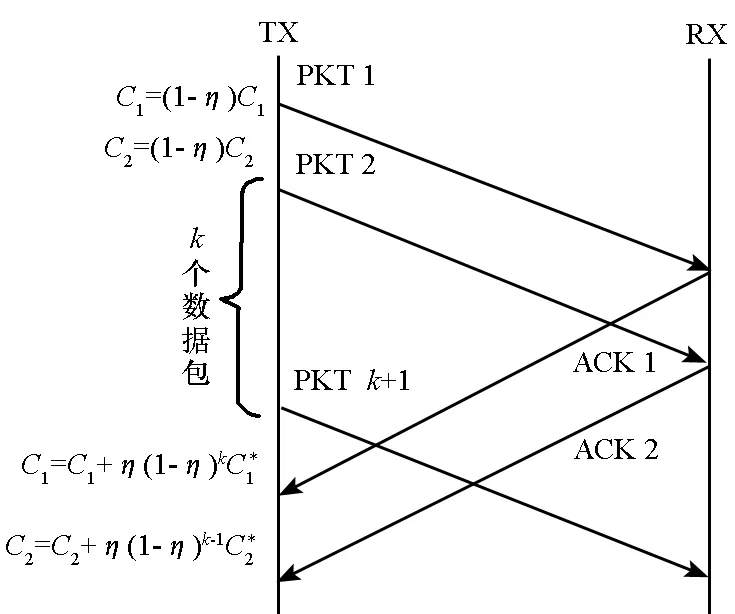
图1 置信度更新过程Fig.1 Process of updating confidence factors
其中,η是置信度更新的学习速率,代表置信度更新信息所占权重。然而,ACK包存在延迟的情况,即在节点m发射端TX接收到接收端RX相应的ACK包之前,又转发了k个数据包,如图1所示。因为不同时刻的ACK影响是不同的,例如k=4时,前两个数据包转发失败,后两个数据包转发成功意味着通信链路条件变好。因此仅使用式(4)、式(5)更新并不能反映类似的变化。于是将数据包转发成功时更新过程改为:
式中,(1-η)k是对接收到的置信度更新信息根据延迟的结果进行缩放处理。文献[8]证明了式(5)与式(6)在更新次数足够多的情况下是趋向于相等的,因此成功转发数据包时,采用式(6)对置信度进行更新。
置信度值除了用来选择更加可靠的节点,还用来在接收到ACK而未更新置信度之前,调整Q-Routing学习速率αt[10]。
(7)
目的是在邻居节点置信度更高,或当前节点转发数据包前的置信度更低时,对邻居节点返回的Q值在更新时赋予更高的权重。
2 分步路由选择算法
为了保证路由可靠性的同时,降低路由开销,提出了分步路由选择算法,使用Q-Routing和置信度结合来进行路由,目标是最小化总RTT。源节点s发送和中间节点转发数据包时,先结合Q表和置信度表选出下一跳节点,根据该节点的置信度来选择是广播还是直接转发数据包至该节点。
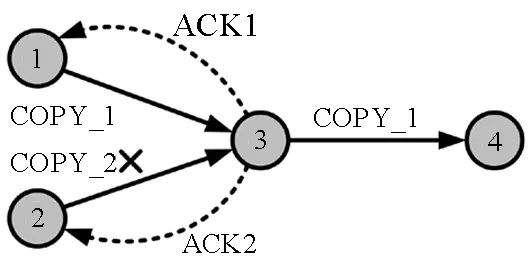
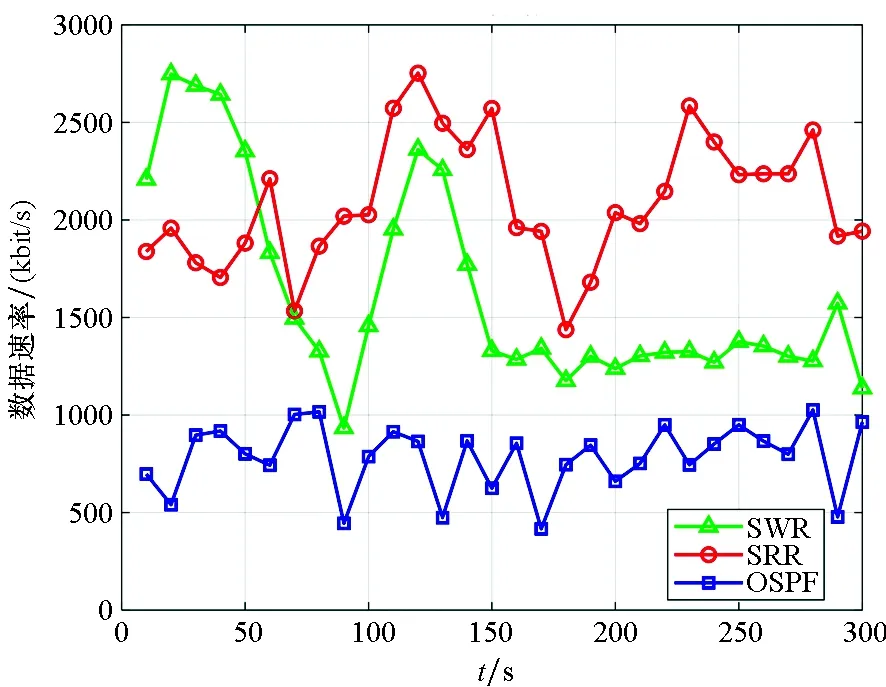
在选择下一跳节点时,结合Q-Routing算法和置信度来进行选择,本文考虑的选择度量为SCQ=Qm(d,n)[1-Cm(d,n)],目标是选择Q值较小、可信度较高的下一跳节点。然而,节点的移动性导致节点的Q值和置信度会变化,仅基于该度量进行下一跳节点的选择,会增大选择不符合路由目标节点的概率,甚至陷入路由环路,从而增加路由开销。为了提升节点选择的容错率,先筛选出符合路由目标的节点。设节点m的邻居节点数量为N,设节点Q表中的Q值按数值大小排序,即Qm(d,a1) 第一步选择Q表中比例为λ、Q值最小的邻居节点子集Nc,大小为「λN⎤,该集合表示为: Nc={a1,a2,…,a「λN⎤} (8) 第二步从Nc中选择度量SCQ最小的节点。 (9) 先基于Q值进行选择也是为了减小在置信度未收敛时,对路由开销带来的负面影响。因为在确定了下一跳节点n*之后,SRR算法根据置信度确定是否需要进行广播来保证路由可靠性。而SRR算法以广播的方式进行传输在增加了路由开销的条件下可以保证数据包到达率的性能,所以为了保留可靠性,并降低路由开销,提出的分步路由算法将数据包广播给在节点选择阶段筛选出的最符合路由目标的邻居节点子集Nc,而是否进行广播的概率则根据置信度计算,可以表示为: pU=ε+(1-ε)[1-Cm(d,n*)] (10) 由式(10)看出:置信度接近0时,节点进行广播的概率更大;置信度接近1时,广播的概率应当减小并趋于ε。在节点发送数据包或拓扑改变的初期,置信度值不够高,就会有更高的概率选择广播的方式传输,Q值和置信度值也会更快地更新,而且在转发初期或网络拓扑改变初期,Q表未收敛时,广播的方式也使路由的可靠性得到了保障。 所有收到广播数据包的节点,都需要传回ACK,包含其自身的节点序列号、下一跳节点的Q值和置信度等信息。 (11) 目的是在拓扑变化时能及时更新邻居节点信息。尽管有部分邻居节点并未在筛选的集合Nc中,但是如果判断为广播数据包,仍然需要传回ACK,使广播节点掌握邻居节点的信息。 当根据广播数据包的ACK更新信息时,并不像SRR算法一样保存Q表和置信度表中所有节点的信息,而是选择删除表中不再是邻居节点的信息。若仍为邻居节点,则按照规则更新Q值和置信度,新的邻居节点将对应Q值设为表中其余节点Q值的均值,置信度则设为1以缩短收敛时间。若不需要进行广播,节点就根据选择的下一跳节点转发,转发后根据式(4)更新置信度。目的是在拓扑变化影响到路由时,更新节点本地信息。在转发成功,下一跳节点接收到数据包后,发送的ACK数据包包括了所选下一跳节点n*的Q值和置信度以及相关节点信息。接收ACK的节点,则由ACK包含的信息根据式(7)、式(2)、式(6)更新αt、Q值和置信度。 所有数据包传输的过程都采用了重复包检测机制,如图2所示。当出现路由环路时,接收包的节点进行丢包处理,如果只是广播的包的复制,进行丢包处理,但会传回ACK,以提供确认该路由可用的信息来更新置信度。分步路由选择算法的步骤如算法1所示。 (a) 形成路由环路(a) Traverse a routing loop (b) 重复包到达(b) Arrival of duplicate packets图2 重复数据包检测Fig.2 Duplicate packet detection 算法1 分步路由算法 本节给出了提出的分步路由选择算法的仿真结果。将仿真的场景设置在1000 m×600 m的矩形区域,源节点和目的节点设为静止,分别位于区域600 m宽边的中间位置。中间节点数为30,在矩形区域内均匀分布,节点的移动速度在[0 m/s,30 m/s]内均匀分布,方向在[0,2π]范围内均匀分布,以当前方向和速率持续的时间也在仿真时间内均匀分布,如果持续的时间结束,或者超出仿真区域范围,则重新分配速度、方向和持续时间,节点通信的范围为300 m。仿真模拟了从源节点发送数据包到目的节点的过程。源节点以每秒10个1500 Byte数据包的速率发送数据,即速率为120 kbit/s,置信度更新参数η=0.3。随着Q值和置信度更新,置信度接近于1,此时根据Q值和置信度已经可以确保路由的可靠性,参数ε过高会增加广播概率,进而增加路由开销,因此选取ε=0.05。 图3比较了在不同λ情况下,300 s内平均路由开销与数据包到达速率的比值。该比值用来体现不同λ对路由开销和数据包到达率的整体影响。路由开销则使用网络中所有链路的数据速率总和来衡量。可以看出,当λ值较高,接近于1时,广播时目标为所有邻节点,这大大增加了路由开销;当λ值较低时,路由初期无法尽快更新Q值与置信度信息,降低路由可靠性。通过比较,确定λ=0.4,此时,为了保障数据包到达速率而付出的路由开销要远小于对所有节点进行广播的方式。 将提出的分布路由算法(StepWise Routing,SWR)与SSR算法和开放最短路径优先(Open Shortest Path First,OSPF)路由[11]相比较,来分析不同算法对路由开销与数据包到达速率的影响。仿真中,以目的节点的数据速率来衡量数据包到达目的节点的成功率,并且以网络中所有链路的数据速率来衡量系统的路由开销。 图4比较了在300 s内不同路由方法在目的节点的吞吐率;图5则比较了对应的路由开销。从图5中可以看出,OSPF路由拥有的路由开销更低,但是对目的节点来说,数据包到达率不够稳定,因为节点的移动会改变拓扑结构,使得以OSPF的方式路由的成功率降低。基于强化学习的SRR算法相对于OSPF算法提升了路由的稳定性,数据成功传输率平均增加了70%,平均丢包率仅有1.6%,相对地,也增加了1倍以上的路由开销。 图3 路由开销与数据包到达速率比值Fig.3 Ratio of routing overhead to packet delivery rate 图4 数据包到达速率仿真结果Fig.4 Results of packet delivery rate 图5 路由开销仿真结果Fig.5 Results of routing overhead 所提出的SWR算法在数据成功传输率上接近SRR算法,平均丢包率为4%,而平均路由开销在0~40 s时相对于SRR算法稍高,原因是路由开始时置信度尚未收敛,SWR广播的节点数量较少,广播次数多,开销较大。40 s之后相对于SRR降低30%,平均开销降低了23%。因为在路由时,SWR算法基于Q值筛选出节点集合的方式再选择,所以避免了在直接结合置信度的选择中选择较差的节点;同时,即便选择广播,也利用了路由时筛选出的节点信息,从而减少无益于到达目的节点的路由选择。 本文研究了MANET中的路由问题,基于强化学习提出了分步路由算法。通过结合强化学习路由Q-Routing和利用Q值筛选符合路由目标节点的方式,使节点更倾向于选择提升MANET网络性能的路由,保障数据包到达率。在筛选出的节点基础上,结合置信度实现在网络条件较差时只向部分节点广播,在提升路由可靠性的同时,降低了网络的路由开销。仿真结果表明:和传统OSPF路由相比,以少量的路由开销为代价,数据传输成功率提升了70%;和基于强化学习的SRR算法相比,数据传输成功率相差仅2.4%的情况下,路由开销降低了23%。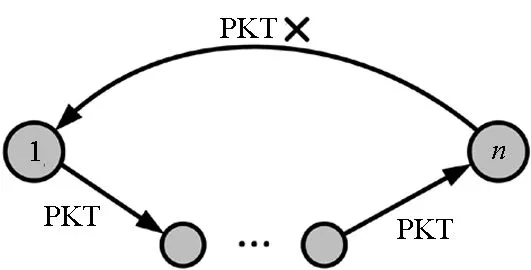

3 仿真结果与分析


4 结论
