高校教育大数据平台的构建与关键技术研究
2020-08-13罗云芳唐运乐闵金花
罗云芳,唐运乐,闵金花
(1.广西职业技术学院,广西 南宁 530226;2.南宁师范大学师园学院,广西 南宁 530226)
引言
大数据等新一代信息技术已成为推动各领域创新、改革与发展的新动力。我国的教育大数据发展战略,目的是通过成立研究机构和设置相关机制,研究和推动大数据在教育领域的应用,利用大数据为教育的改革与发展赋能,使大数据成为教育改革与发展的新引擎[1]。随着校园信息化建设的迅速发展,教育数据大量产生。构建融基础数据采集、存储计算和数据的分析、挖掘、应用于一体的高校教育大数据平台成为了实现业务系统数据融合,消除信息孤岛,助推教育创新、改革与发展的重要保障手段[2]。目前各高校尚未构建能有效驱动教育改革与发展的完整的大数据平台架构。将教育改革与发展的关键问题与当前前沿的大数据技术相结合,在此基础上研究高校教育大数据平台的构建,进一步完善智慧校园技术体系,具有很好的现实意义。
1 高校教育大数据的特点与融合存储问题
根据大数据概念,教育大数据指的是教育教学过程中产生的结构化和非结构化的,需要借助分布式存储管理等新处理模式和新技术才能管理、分析和挖掘其价值的高速增长的具有多样化、低密度价值的数据信息[3]。大数据新处理模式和新技术主要包括Hadoop分布式集群、HDFS分布式文件系统、HBase分布式数据库、机器学习、认知计算等存储和分析挖掘算法[4]。对高校而言,高校大数据即是高校在教育管理、教学和科研活动中产生的,对推动高校教育教学改革、综合管理、发展规划和决策等具有巨大价值的信息数据。目前高校产生的大数据主要包括学生的基本信息(如选课、成绩、教材、食堂消费、网络行为等),教师基本信息、科研基本信息、教学相关信息等,这些数据孤立地存储在各独立的信息系统中,且呈现出数据来源多元化、数据类型多样化、数据异构维度高和数据整体价值高等特性[5]。要充分挖掘出这些数据的潜在价值,新构建的高校教育大数据平台需具备如下功能:一要能对历史数据进行有效的融合存储,二要能对新产生的数据进行规范统一的整体性存储。因此,在构建高校教育大数据平台时需重点围绕“管理+治理+应用”三方面对高校教育大数据存在的数据标准不统一、数据源头多样化、数据不同步、数据存储分散等问题进行处理,具体的措施有:从信息服务顶层切入,制定数据统一标准,对历史数据进行充分地清洗;确定数据产生的唯一性归口和数据访问统一接口;对错误和残缺的数据进行解析、关联、清洗和交换,提升数据质量;构建标准的数据交换接口和利用ODI等工具建设数据交换平台中间件,提高数据共享水平;对数据采集、管理和应用的全过程进行规范管理,完善数据维度,实现数据全量融合与综合分析。
2 高校教育大数据平台的构建
构建高校教育大数据平台可形成统一的中心数据库,通过有效的数据挖掘,可为高校学生的个人学习与发展,教师的教学、科研与职业发展,学校的教育教学管理(如网络教学管理、专业诊断改进和规划建设等)提供强大的数据支持。高校教育大数据平台应具有如下功能:(1)提供连接各应用系统数据的采集接口,实现结构化、非结构化和实时行为数据的采集、存储和融合;(2)综合利用HDFS、HBase等分布式存储系统,实现各类型、各形式数据的存储,并提供高容错和高吞吐的管理与快速查询功能;(3)根据上层分析、挖掘和应用的需要,提供并行计算、实时计算和图式计算等算法,实现海量数据的分析、挖掘、计算和应用;(4)根据高校教育教学管理、规划发展和决策需要,提供分析、挖掘模型和算法。高校教育大数据平台应覆盖从数据采集、存储计算、分析挖掘到具体应用的全过程,其构建总体架构如图1所示。
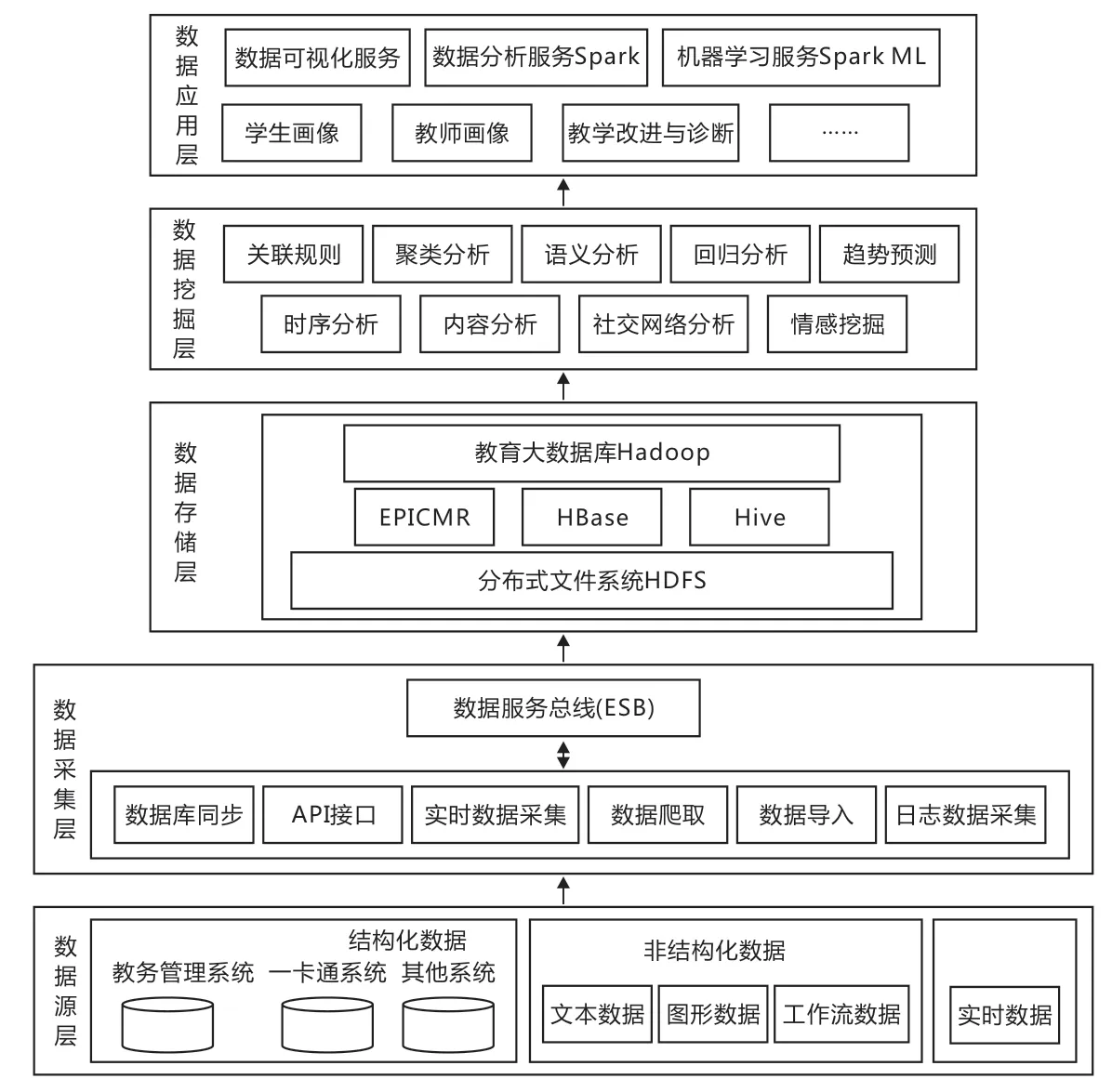
图1 高校教育大数据平台总体架构
2.1 数据源层
高校教育数据包括三类。第一类是以结构化形式存储于教务管理系统、科研管理系统、教学诊断与改进管理系统、一卡通系统、实践教学管理系统和就业管理系统等各类业务管理系统中的数据;第二类是在教育教学过程中产生的图形、音频、视频和文档等非结构化数据,如音视频素材文件、Excel文件、PPT文件、PDF文件等;第三类是智慧教室等系统采集的实时行为数据,如教学过程中产生的演示和指导等行为数据,学习过程中产生的答题和在课堂中讨论等行为数据。
2.2 数据采集层
高校教育大数据平台数据的采集主要包括对原来各业务管理系统中数据的采集和对实时产生的数据的采集两种:对原来业务管理系统中数据的采集一般通过直接读取数据库记录、公开接口处理或批量导入等方式实现;教学等实时数据的采集则通过Agent技术来实现;对于非数字化数据可采用图像识别等技术来实现采集。
2.3 数据存储层
数据存储层是以Hadoop技术为基础,利用Hadoop分布式计算框架和服务器硬件构建起来的能提供HBase、Hive等标准大数据服务,能完成高可靠、高容错和高吞吐的复杂分析挖掘任务的具有高可靠性和高可扩展性的并行分布式系统,可实现和满足不同数据结构和不同存储方式的高校教育大数据的汇集和海量存储需求,为数据挖掘层提供有效的数据存储服务。
2.4 数据挖掘层
高校大数据的分析、挖掘和应用主要包括教学和管理两大方面,具体涉及教学分析、学习分析、专业诊断分析、科研分析、学生行为分析和规划决策分析等内容,主要涉及两个大方向的技术。一是根据数据挖掘的新需求,设计新的挖掘模型;二是通过数据挖掘,解决当前教育大数据在应
用中存在的核心问题,涉及的技术主要包括关联、聚类、时序、回归、语义等。
2.5 教育应用层
数据挖掘的目的是找出其中的价值,而价值则体现在具体应用之中。如针对学生数据的挖掘,通过对学生的学习规律、生活规律、心理、知识技能和素质等数据进行深入挖掘,可形成学生在未来学习表现、心理问题、在校成长轨迹和就业岗位匹配等方面的精准画像;对教师数据的挖掘,可形成教师在教学、科研等方面的精准画像,帮助教师改进教学方式方法,发现科研中存在的问题,助力教师提升科研能力,做好项目研究工作等。对专业发展的诊断分析,可以找出制约专业改革与发展的核心问题,形成专业改进方案,促进专业改革与发展,此外,还可对学校均衡发展等问题进行分析、挖掘与预测。
3 高校教育大数据平台构建的关键技术
3.1 高校教育大数据平台的数据采集技术
平台数据的采集主要通过两种渠道实现。一是对接原有各业务管理系统,将各业务管理系统数据统一存储到大数据中心仓库,可在制定数据存取标准的基础上,通过直接读取业务管理系统数据库、数据处理接口API对接等方式实现;二是直接采集存储于数据中心仓库的行为数据,本大数据平台采用Flume技术实现对行为数据的采集。利用Flume实现行为数据采集的处理过程如图2所示。采集具体过程是行为对象触发产生事件对象对行为根据的采集。事件监听器监听到事件后,对应事件处理器就会采集行为对象的数据,汇聚采集的数据后推送给服务器接收组件,服务器接收组件处理后将数据存入到数据缓存组件中,然后通过数据分发组件将存储于缓存组件中的数据发送到Kafka消息队列中。
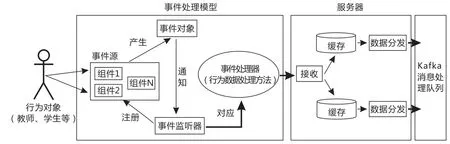
图2 行为数据采集处理过程
3.2 高校教育大数据的仓库设计技术
历史数据都分布存储于各业务管理系统中,在对历史数据进行采集抽取、清洗过滤、数据转换、关联分析、知识点获取和构建数据仓库后将其存储到大数据仓库中。结合数据颗粒度原理,按学生、教师、专业等不同应用主题和行为分析需求进行数据组织,本研究设计的高校教育大数据平台数据存储仓库设计结构如图3所示。
3.3 高校教育大数据的存储与计算技术
高校教育大数据涉及到结构化、非结构化数据和流式数据,其数据来源和体量都已超越小规模数据范畴[6]。对于教育大数据的存储和管理,利用Hadoop技术构建分布式集群和分布式存储,并实现存储和计算一体化。在数据存储方面,利用HDFS存储非结构化数据,利用HBase和Hive存储结构化数据,利用Kafka和Redis缓存经常处理和需要快速响应的数据。在并行计算方面,利用MapReduce进行大规模数据集计算,利用Spark技术实现流式数据处理和内存计算,以满足实时性数据处理要求和高速统计分析,利用Graph图计算技术,满足知识结构图谱的计算处理需求。
3.4 高校大数据的特征工程技术
3.4.1 数据变换与扩充处理采集的数据中,有些数据往往包含大量信息,如学生身份证号码包含了省份信息,隐含了饮食习惯差异、语言差异、气候差异、人均GDP差异等对学生心理产生影响的重要信息,因此要对身份证信息数据进行变换与扩充处理。
3.4.2 数据缺失值处理
针对采集到的数据存在的数据值缺失情况,需要通过相关技术手段进行补全处理。如采集的“父母受教育水平”数据就可能出现数据值缺失的情况,可以使用均值方式填补缺失值,采集的“家庭月收入”数据也可能出现数据值缺失的情况,可以使用聚类填充方式进行处理。
3.4.3 归一化与标准化处理
在建立模型进行数据分析之前,需要将不同规格的数据转换为同一规格,这种需求被称为将数据“无量纲化”。线性的无量纲化包括中心化处理和缩放处理,中心化和缩放是实现线性无量纲化的两种形式。中心化是将所有记录减去一个固定值,使原数据处理成统一规格;缩放是将原数据除以一个固定的数,将样本缩放到固定的范围中。归一化和标准化处理实现方法如表1所示。
3.5 高校教育大数据的分析挖掘技术
建设高校教育大数据平台的目的就是对数据进行分析和挖掘,充分实现数据的价值。在对数据进行过滤、清洗、扩充、转换和关联等处理后,利用机器学习、神经网络和概率等算法构建模型,分析、挖掘出数据所蕴含的价值。本研究所设计的高校教育大数据平台利用关联规则挖掘学生数据,可发现学生的选课规律和优异学生的学习习惯,在此基础上构建反映知识点关联的概念图[7];还可利用手势、神态识别、心理表现建模、学生行为特征抽取等技术,通过多功能摄像头,捕捉学生的学习动态特征行为,如神态、表情、手势等多模态数据,综合分析学生的学习动态行为[8]。本文主要介绍箱式图、概率和神经网络分析算法三种分析挖掘技术。
3.5.1 箱式图单维度离群值分析
利用箱式图进行单维度离群值分析的步骤是:将数据按升序排序,如果是奇数个数值则取最中间一个值作为中位数,之后最中间的值在计算1/4分位点Q1和3/4分位点Q3时不再使用;如果是偶数个数值,中位数则是最中间两个数的平均值,这两个数在计算Q1和Q3时继续使用。Q1:以中位数为分界点,数值中最小值到分界点的数据再按中位数取法求得Q1;Q3:同Q1取法,取分界点到最大值的中位数,计算IQR(四分位数间距),即IQR=Q3-Q1,所有不在(Q1-1.5IQR,Q3+1.5IQR)区间内的数为离群值,根据不同的应用情况,有的只取离群大值,有的取离群小值。
3.5.2 概率模型单维度离群值分析
使用onehot编码或者其他方式模拟分布概率,如学生就餐分析,将学生就餐时间分为三个时间段,分别为早餐、午餐、晚餐。在每个就餐时间段中再进行分段,每个就餐时间对应一个onehot值,并用多日数据求出向量均值,此向量即为在此时间段就餐的概率分布,具体分析过程如图4所示。同理,求出全校学生就餐时间对应的概率分布,以学校的数据为标准,对比学生数据,概率分布差异越大代表就餐时间越不规律。利用此方法还可找到出入宿舍时间分布,出入校门时间分布,活动轨迹分布等学生在校的多维分析。
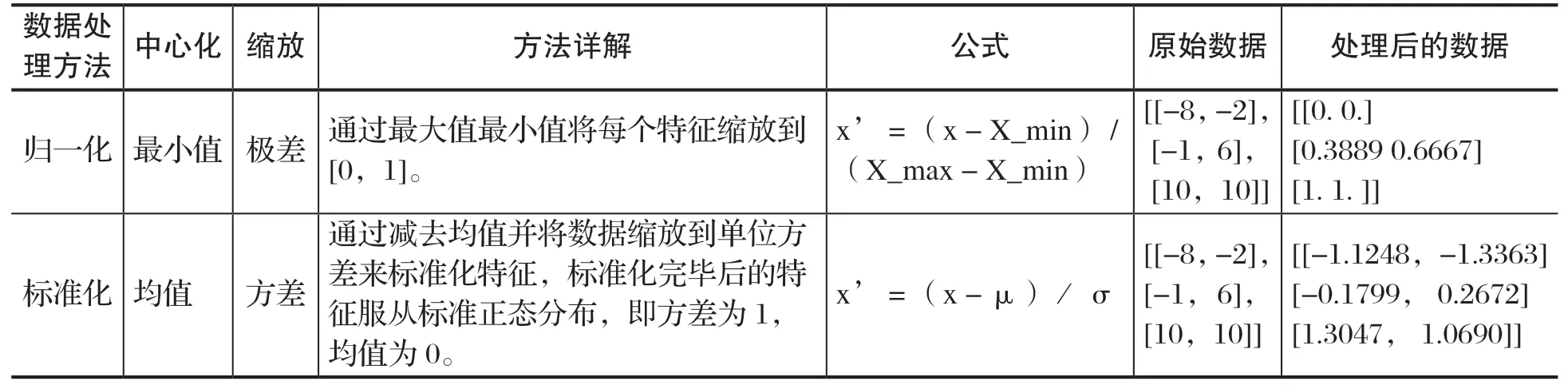
表1 归一化和标准化处理实现方法
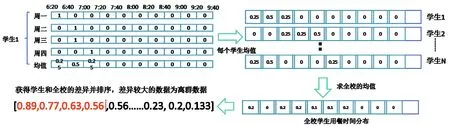
图4 概率模型分析学生用餐时间过程
3.5.3 利用神经网络进行多尺度回归预测
学生发展预测是一个多维度指标体系,是一个各个指标之间既相对独立,但又存在联系的多属性训练集,属于多个具有相关性的任务在同一训练集的同时学习问题,可利用神经网络结合多尺度回归法进行预测,形成学生发展预测画像。如利用如下方式(见图5)建模,并利用三层神经网络算法对学生的发展进行多尺度回归预测(如图5所示)。
4 总结
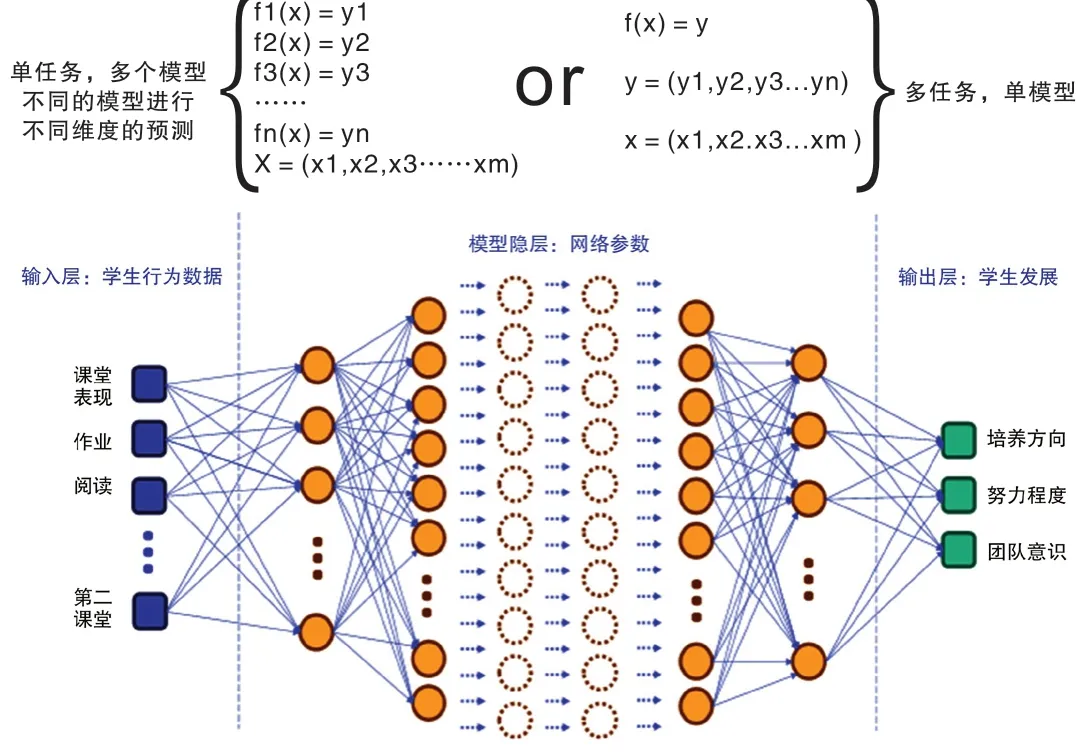
图5 三层神经网络多回归预测学生发展
构建高校大数据平台,对教育数据进行挖掘具有重要现实意义,一可为高校培养大数据技术相关专业人才提供真实的教学资源和实训条件;二可为高校的教育、教学和科研的改革与决策发展赋能。本研究重点阐述了高校教育大数据平台的构建和涉及的相关技术,但对专业诊断与改进方面如何进行数据挖掘还没有具体的阐述,今后的研究将在这方面进行拓展,为高校的改革与发展提供更优质的参考。
