BiLSTM在跨站脚本检测中的应用研究*
2020-08-12程琪芩
程琪芩,万 良+
1.贵州大学 计算机科学与技术学院,贵阳 550025
2.贵州大学 计算机软件与理论研究所,贵阳 550025
1 引言
随着信息时代的不断发展,网络安全问题日益受到人们的关注。跨站脚本(cross-site scripting,XSS)作为一种威胁网络平台安全的攻击形式,对其进行有效的检测已成为当今网络安全领域的重要研究内容[1]。
XSS 攻击的形成是由于攻击者在客户端注入了恶意代码,从而达到窃取用户敏感信息等攻击目标[2-3]。XSS攻击主要分为三类:反射型XSS攻击(又称非持久型XSS 攻击)、存储型XSS 攻击(又称持久型XSS攻击)和基于文档对象模型(document object model,DOM)的XSS攻击(又称type-0 XSS攻击)[4]。形式复杂多变的XSS攻击导致了传统检测方法在检测性能上存在不足,经过混淆处理后的XSS 代码更是成为提高检测性能的一大难点[5]。
传统的检测技术有基于模糊测试技术[6]、基于黑盒技术[7]等,随后又提出了基于机器学习[8]的检测技术。文献[9]分别构造了检测准确率优于其他决策树的交替决策树(alternating decision tree,ADTree)分类器和组合多个弱分类器的自适应提升算法(adaptive Boosting,Adaboost)分类器用于XSS 检测,并在此基础上建立了网页数据库。该方法前期采用了大量的人工特征提取工作,分类效果直接受提取特征好坏的影响。文献[10]人工提取了25个关键特征,并使用10 种不同的机器学习分类器检测XSS 攻击,检测效率良好。文献[11]人工提取了18个特征,作为检测恶意网页的重要依据。文献[12]耗费时间提取特征后再使用朴素贝叶斯(naive Bayesian)、支持向量机(support vector machine,SVM)和J48 决策树(J48 decision tree,J48DT)三种机器学习算法预测XSS 攻击。随着研究不断深入,发现现有的Web 应用XSS检测技术还存在着以下不足:(1)需要手工提取特征,工作量大的同时主观性很强[13];(2)XSS攻击所注入的代码常通过恶意混淆来躲避检测,可读性低,不易检测[14];(3)现有检测技术未能很好地利用注入代码中XSS的有关信息[2]。针对上述不足,一些研究学者开始使用自动学习特征的深度神经网络来检测XSS。文献[15]将深度学习中的长短时记忆网络(long-short term memory,LSTM)运用到漏洞检测。文献[16]在研究中采用卷积神经网络(convolutional neural networks,CNN)、LSTM、CNN-LSTM模型进行漏洞检测。实验结果表明,上述方法的预测精度要优于传统的多层感知器(multilayer perceptron,MLP)方法。文献[17]使用LSTM网络构建XSS检测模型,实验结果表明,基于LSTM的检测方法能有效地应用于XSS 检测中,但其对于恶意混淆的XSS 检测还不够准确。
结合上述文献研究,本文提出了一种基于双向长短时记忆网络(bidirectional long-short term memory,BiLSTM)的跨站脚本检测方法。LSTM 是一种带有记忆单元的神经网络,常用于处理序列问题,能解决长序列依赖的问题,从而广泛应用在自然语言处理领域中。但是单向的LSTM 只能处理上文对下文的依赖问题,而无法解决下文对上文的依赖,从而对于XSS 特征学习过程中,忽略了下文与上文语义关系,使得提取的特征不够充分。在此基础上本文借鉴双向循环神经网络(bidirectional recurrent neural network,BiRNN)双向处理序列的特点,选择BiLSTM 来双向学习XSS代码,获取更全面的XSS特征,提高检测性能。首先,通过数据预处理,解决样本数据恶意编码混淆的问题,提高XSS代码的可读性。其次,BiLSTM在经典LSTM 的基础上加强了对后文的依赖性的处理,能更全面地学习XSS的相关信息,得到更全面的抽象特征。最后,使用softmax 分类器对学习到的特征实现分类。实验结果表明,该方法具有良好的分类效果和泛化能力。
2 神经网络
2.1 长短时记忆网络(LSTM)
循环神经网络(recurrent neural network,RNN)能够根据历史信息保持记忆,使其可以利用距离特征预测当前输出。但是,RNN具有梯度消失的缺陷,不利于长序列的处理。LSTM 是RNN 的一种变形,通过增加记忆单元来解决序列的长期依赖问题,以避免梯度消失。
LSTM的工作原理如图1所示。LSTM有四个重要的组成部分[18]:细胞状态、遗忘门、输入门和输出门。其中细胞状态为LSTM的核心部分;遗忘门决定丢弃上一个细胞状态ct-1传递到该细胞状态ct的哪些信息;输入门决定更新值it和更新候选细胞状态;通过遗忘门、输入门以及细胞状态,此时得到了更新的ct,可以传递到下一个细胞状态ct+1;输出门决定输出值ht。数学表达式如下:
更新遗忘门输出ft:

式中,wf为遗忘门层的权值矩阵,bf为偏置向量,σ1(x)为遗忘门的激活函数,表示sigmoid 函数,用于计算ft。
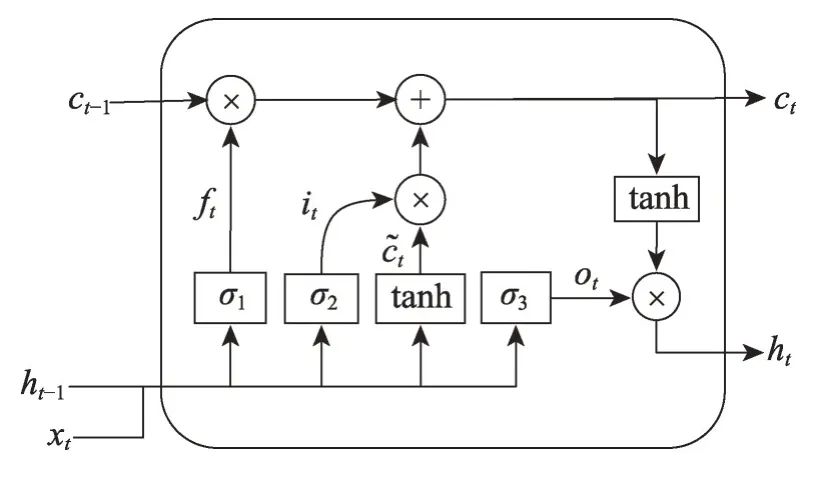
Fig.1 Structure of LSTM图1 长短时记忆网络结构
更新输入门输出it并计算候选状态:
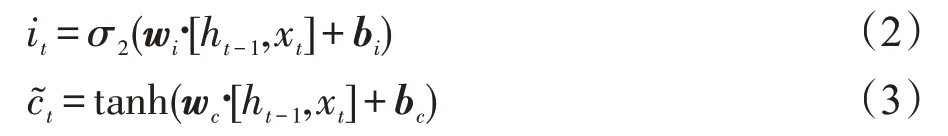
式中,wi为输入门的权重矩阵,bi为偏置向量,σ2(x)为输入门的激活函数,表示sigmoid 函数,用于计算it。wc为tanh层的权重矩阵,bc为偏置向量,tanh(x)为激活函数,用于计算候选状态。
更新细胞状态ct:

更新输出门输出ht:

式中,wo为输出门的权重矩阵,bo为偏置向量,σ3(x)为输出门的激活函数,表示sigmoid 函数,用于计算ot。tanh(x)为tanh 层的激活函数,用于计算输出ht。
2.2 双向长短时记忆网络(BiLSTM)
LSTM可以处理长序列中存在的长期依赖,但是单向LSTM只能从前向后获取序列信息,而序列预测问题可能由前面若干输入和后面若干输入共同决定,使序列中与预测结果相关的信息被充分应用,使预测结果更加准确。基于此,双向长短时记忆网络应运而生。
BiLSTM主要包含两部分:(1)自前向后的LSTM层(forward layer);(2)自后向前的LSTM 层(back-ward layer)。其网络结构如图2所示。
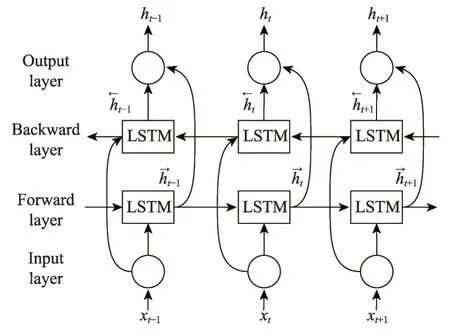
Fig.2 Structure of BiLSTM图2 BiLSTM网络结构
BiLSTM 的核心思想[19]为:在t时刻,在Forward层自前向后正向计算一遍,得到并保存每个时刻向后隐含层的输出;在Backward 层自后向前反向计算一遍,得到并保存每个时刻向前隐含层的输出;最后在每个时刻结合Forward 层和Backward 层的输出,得到最终的输出
3 一种基于BiLSTM的检测方法
检测方法的整体框架如图3所示,首先利用爬虫工具从XSSed 数据库和DMOZ 数据库收集大量数据,再经过数据预处理(见3.1节)得到适应神经网络输入的标准数据集,最后构建双向长短时记忆网络模型(见3.2节)进行检测分类。
3.1 数据预处理
检测性能不仅受检测方法的影响,很多时候良好的输入数据能带来更好的检测性能。在此基础上,本文对所收集的XSS 代码数据和正常代码数据进行了预处理,分为数据清洗、分词以及向量化三部分。
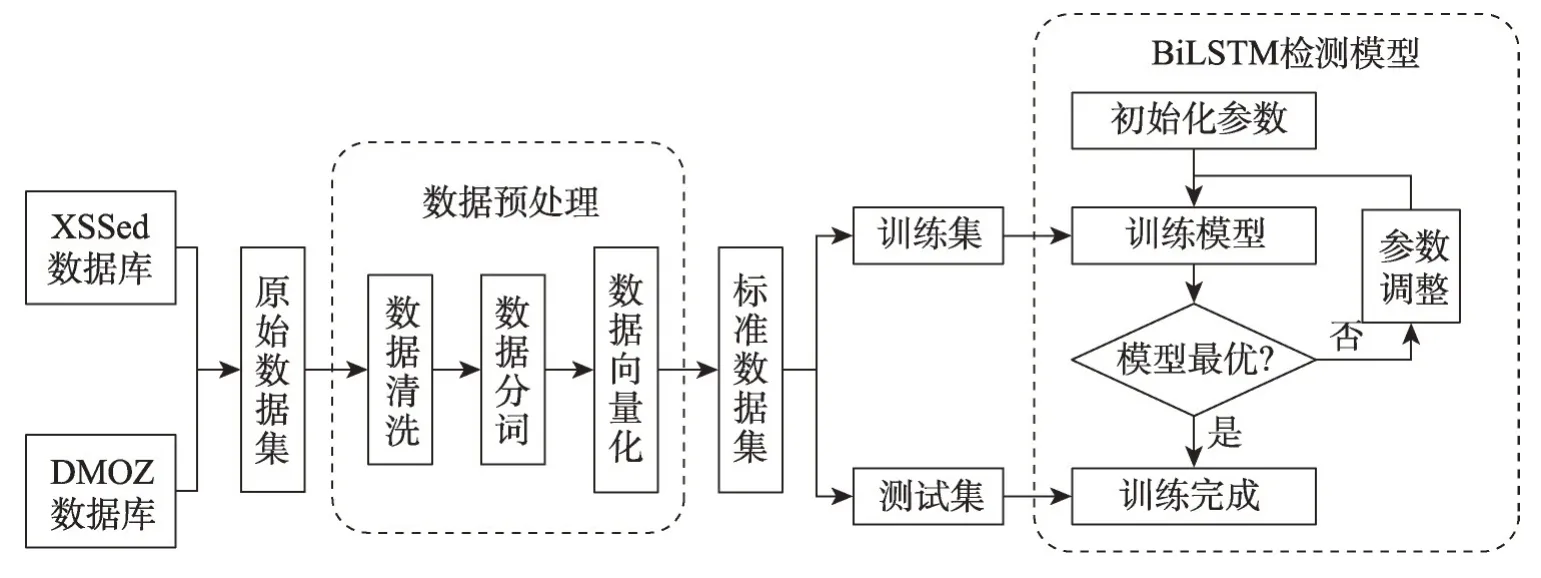
Fig.3 Overall architecture of detection method图3 检测方法的整体架构
(1)数据清洗:为了提高输入数据的质量,优化检测方法的性能,本文对原始数据进行了清洗工作。XSS 代码主要通过编码技术进行恶意混淆来躲避检测,因此本文对数据进行了解码操作,实现XSS代码的反混淆。图4 显示了混淆代码经过解码还原为原始代码的一个实例。经过解码后,对数据进行去噪处理,主要是为了去除重复、不完整以及错误的数据。

Fig.4 Instance of original codes decoded and restored by obfuscated codes图4 混淆代码经过解码还原为原始代码的实例
(2)分词:对数据进行清洗后,为了降低向量化后的数据维度,本文先将代码中的数字转换为0,将链接如“http://www.baidu.com”转换为“http://u”。然后利用XSS 代码符合脚本语言的特点,根据不同功能的分词类别,设计了一系列自定义正则表达式对输入的代码数据进行分词,如表1 所示,分词结果如图5所示。
(3)向量化:本文根据词频-逆文件频率(termfrequency-inverse document frequency,TFIDF)建立一个词汇库,为每个词设置一个数值id,每个词出现频率越高,对XSS的重要性越高,id越小。最后,根据词汇库,将代码转换为数值型数据,再利用深度学习中的word2vec 工具将已经完成分词的代码转换为向量,转换结果如表2所示。由于神经网络的输入长度固定,而样本的长度不固定,选择合适的向量维度极其重要。故根据样例长度,将长度超过向量维度的进行截断,长度不足的用-1进行填充,使所有的向量长度一致。

Table 1 Tokenization表1 分词

Fig.5 Tokenized result of sample图5 样例经过分词的结果

Table 2 Vectorization result表2 向量化结果
3.2 BiLSTM检测模型
文献[17]提出了使用LSTM 的深度学习检测模型DeepXSS,但该模型对于XSS 下文对上文的信息依赖利用不够充分。故而,本文提出了BiLSTM检测模型,该模型包含了四个组成部分:输入层、BiLSTM层、dropout层、输出层。其中BiLSTM层是模型的核心部分,用于学习样本的上下文信息,从而抽取有效特征,进而将有效特征用于分类器分类预测跨站脚本。
3.2.1 模型设计
为了实现对XSS 的检测,本文构建了一种基于BiLSTM的检测模型,结构自下而上如图6所示。
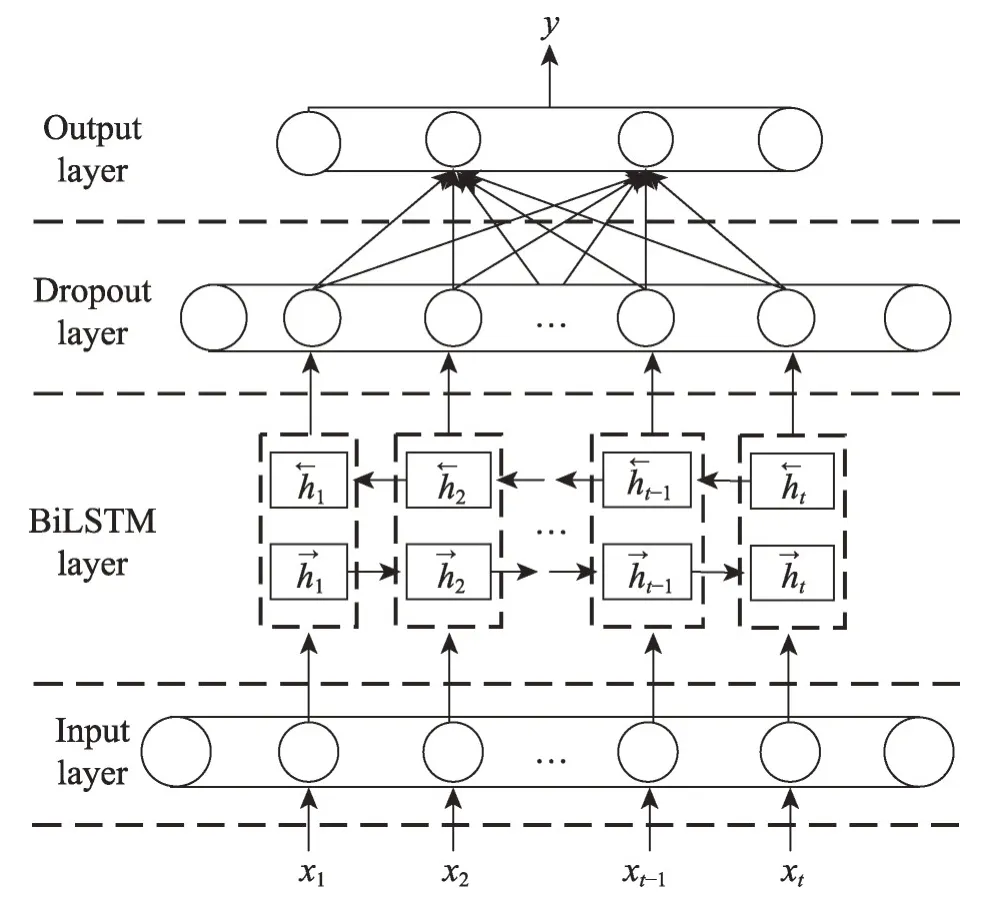
Fig.6 Detection model based on BiLSTM图6 基于BiLSTM的检测模型
Input layer:输入层。在本层中,数据以二阶张量形式来表示,同时设置每次输入到神经网络中训练样本的个数(batch_size)。在数据预处理时预先训练了词向量矩阵embedding,因此本模型不再使用embedding层。
BiLSTM layer:双向长短时记忆网络层。利用BiLSTM 能捕获数据的时序性和能解决长程依赖问题的优点,将其自动学习XSS攻击的抽象特征,使检测性能更好。
Dropout layer:用来提高方法的泛化能力,避免过拟合。
Output layer:输出层。输出分类器的分类结果。
检测模型具体步骤如下(以一个样本Ri={x1,x2,…,x49,x50}为例):
步骤1提取抽象特征
(1)将Ri输入到输入层,得到输入层输出向量Ii={i1,i2,…,i49,i50}。
(2)将Ii作为BiLSTM 层的forward layer 的输入,先经过前向学习输出最后一个时间步,作为与XSS相关的特征向量f={f1,f2,…,f63,f64}。
(3)将Ii作为双向LSTM 层的backward layer 的输入,先经过后向学习输出最后一个时间步,作为与XSS相关的特征向量b={b1,b2,…,b63,b64}。
(4)将前向学习到的特征f和后向学习到的特征b结合起来,得到双向长短时记忆网络提取出的抽象特征h=[f:b]={f1,f2,…,f63,f64,b1,b2,…,b63,b64}。
步骤2使用softmax分类器对抽象特征h进行分类预测。
(1)利用dropout 使部分双向长短时记忆单元随机失活,避免训练结果出现过拟合。将抽象特征h作为dropout 层的输入,输出为d={d1,d2,…,d127,d128},其中这128个值以dropout比率被置为0。数学公式如下:

其中,Bernoulli函数用于生成概率向量r∈(0,1),h以r的概率置零得到d。
(2)将抽象特征d输入到softmax 函数中进行分类预测,得到表示为01或10的2维输出。公式如下:

其中,ws和bs是softmax函数的权重与偏置,p∈(0,1)。
3.2.2 算法设计
原始数据经过数据预处理,得到适应神经网络输入的标准训练集TrR={R1,R2,…,Rn}、标准测试集TeR={R1,R2,…,Rm},其中n、m分别为训练集和测试集的样本数,Ri(50×128维)代表每个样本。BiLSTM检测模型算法设计如下:
输入:训练集TrR和测试集TeR。
输出:通过分类器softmax 分类得到的分类结果TrY(2维)。
1.构建BiLSTM网络并初始化其权重和偏置;
2.构建softmax分类器并初始化其权重和偏置;
3.将预处理后的训练集TrR作为输入;
4.foriin epochs #epochs为训练迭代次数
5.将TrR作为输入层的输入,得到输出TrI(50×128维);
6.将TrI作为BiLSTM 层的输入,经过forward layer学习得到抽象特征h1(64 维),经过backward layer 学习得到抽象特征h2(64维),结合h1、h2后得到抽象特征h=[h1:h2](128维);
7.将抽象特征h作为softmax分类器的输入,得到分类结果TrY(2维);
8.根据分类结果与实际标签的误差,反向传播调整参数;
9.更新softmax分类器的权重和偏置;
10.更新BiLSTM网络的权重和偏置;
11.end for
12.将测试集TeR作为训练好的检测模型的输入,输出测试结果。
4 实验及分析
4.1 数据集
本文数据集中,恶意样例来源于XSSed 数据库,经过数据预处理得到27 252 条标准数据;正常样例来源于DMOZ 数据库,经过数据预处理得到77 216条标准数据。实验中,将恶意样例和正常样例放在一起,运用交叉验证中的train_test_split函数,从样本中以7∶3 的比例随机选取训练集和测试集。数据集的分布情况如表3所示。
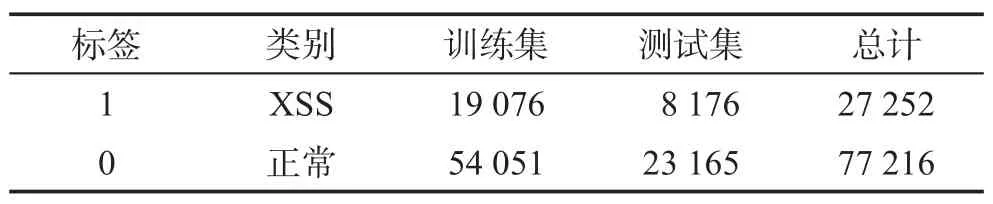
Table 3 Dataset distribution表3 数据集分布
4.2 实验环境
本文实验使用的计算机配置为:处理器Intel®CoreTMi3-2367M CPU@1.40 GHz,内存6 GB,64位win10操作系统。实验环境为Python 3.5.2、TensorFlow 1.12.0、Keras 2.2.4。
4.3 实验结果及分析
为了验证检测方法的性能,本文使用了准确率(precision)、召回率(recall)、F1值对模型评估。在本文的评估指标中,将XSS作为正样本,将正常样例作为负样本,评估指标的混淆矩阵如表4所示。


Table 4 Evaluation index confusion matrix表4 评估指标混淆矩阵
4.3.1 检测方法分析
(1)向量维度
神经网络输入向量的维度一致,而样本的维度不一致,选择一个合适的向量维度,才能充分利用样本信息。若向量维度过短,会遗失大量有效信息,降低检测准确率;若向量维度过长,会增加大量计算,降低检测实时性。为了得到合适的向量维度,本文比较了不同向量维度对准确率和训练时间的影响,结果如图7 所示。可以看出,维度超过50 时准确率变化不太明显,但是训练时间几乎成倍增长,维度为100 和50 的准确率能达到最优,但是维度为50 的训练时间明显低于维度超过50 的训练时间,从而选择50作为向量维度能使检测性能达到最优。

Fig.7 Vector dimension图7 向量维度
(2)优化器
优化函数是一种不断调整参数使损失函数值loss越来越小,最终使预测值尽可能接近真实值的方法,而神经网络中的优化器用来更新和计算模型训练与模型输出的网络参数,使其逼近或达到最优值。优化器的不同,会导致损失函数值有所不同,为了找到最小化的损失函数,本文对常见的优化器Adam、SGD、RMSprop、Adagrad、Adadelta、Adamax进行了对比实验,损失函数关系曲线如图8所示。从该图可以看出,SGD优化效果最差,而其他几种优化器优化效果差异不明显。故选择了Adam 优化检测模型,使其能快速将损失函数收敛到一定值。

Fig.8 Optimizer图8 优化器
(3)分类器
分类器的作用是利用已知标签的训练数据来学习分类规则,然后对未知标签的数据进行分类预测。分类器的选择有很多,而本文采用BiLSTM 对XSS进行检测,因此需要选择适用于神经网络的分类器。LR 分类器和softmax 分类器是神经网络常用的分类器,LR分类器常用于二分类,也可以用多个二分类实现多分类,适用于非互斥的分类问题,softmax分类器常用于多分类,也可以用于二分类,适用互斥的分类问题。实验对比了这两种神经网络分类器,结果如表5 所示。可以看出,softmax 分类器的分类效果要优于LR 分类器,故本文选择softmax 分类器作为模型的分类器。
(4)实验结果
本文选择向量维度为50、优化器为Adam对模型进行测试。首先分析各个参数对于网络结构以及性能的影响,然后根据实验结果调整参数,直至检测方法达到最优。最终检测模型的参数设置如表6所示。

Table 5 Classifier表5 分类器

Table 6 Parameter setting of model表6 模型参数设置
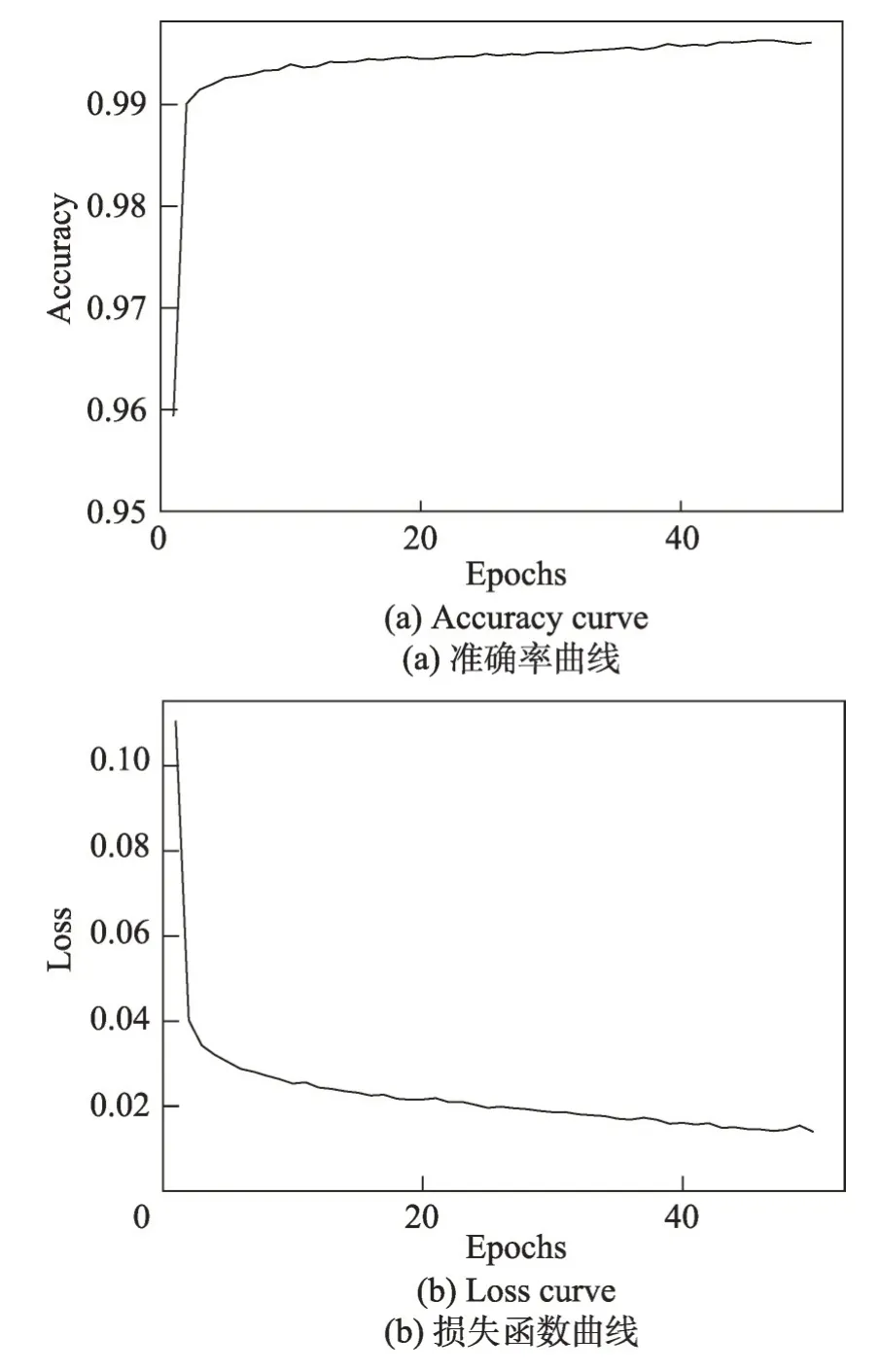
Fig.9 Training results图9 训练结果
对经过调整后的检测方法进行训练和测试,准确率和损失函数变化曲线如图9 所示。从这两组图像可以看出,准确率曲线稳步上升的同时损失函数曲线稳步下降且两者均收敛到一定值,表明检测方法具有良好的训练效果,分类效果良好。
4.3.2 对比实验
为了验证模型的有效性和优势,本文设计了两组对比实验:(1)机器学习对比实验;(2)深度学习对比实验。
(1)机器学习对比实验
为了验证本文提出的检测方法性能要优于传统机器学习算法,且因文献[9]所使用的数据集与本文的数据集都来源于相同数据库,所以将本文提出的检测方法与文献[9]中的ADTree、AdaBoost检测方法进行对比。ADTree分类器是一种基于Boosting的决策树学习算法,它的分类性能要优于其他决策树。AdaBoost 针对同一个训练集训练多个弱分类器,然后将弱分类器集合成一个强分类器,分类性能更优。同时,为了增加对比性,本文选择XSS检测中常用的SVM(support vector machine)分类器进行对比实验,SVM是一种按监督学习方式对数据进行二元分类的广义线性分类器。实验中,运用了sklearn 中的SVM算法对代码样本进行分类。实验结果如表7 和图10所示。可以看出,ADTree、AdaBoost 准确率分别为93.8%和94.2%,SVM准确率为98.9%,而本文所提出的方法准确率高达99.7%,召回率高达98.1%,F1 值高达98.7%,性能明显要优于ADTree、AdaBoost、SVM这些传统机器学习算法。
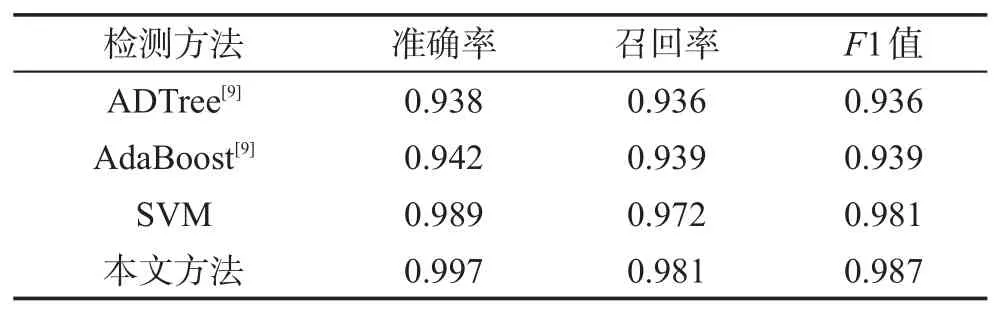
Table 7 Detection results of proposed method and machine learning methods表7 本文方法与机器学习方法的检测结果
(2)深度学习对比实验
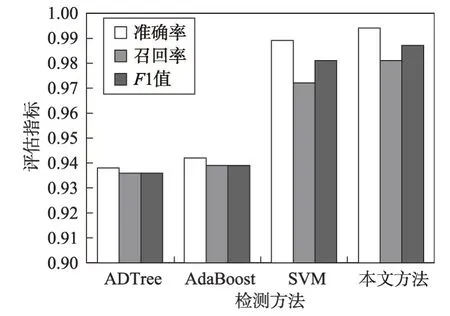
Fig.10 Comparison of proposed method with machine learning methods图10 本文方法与机器学习方法对比
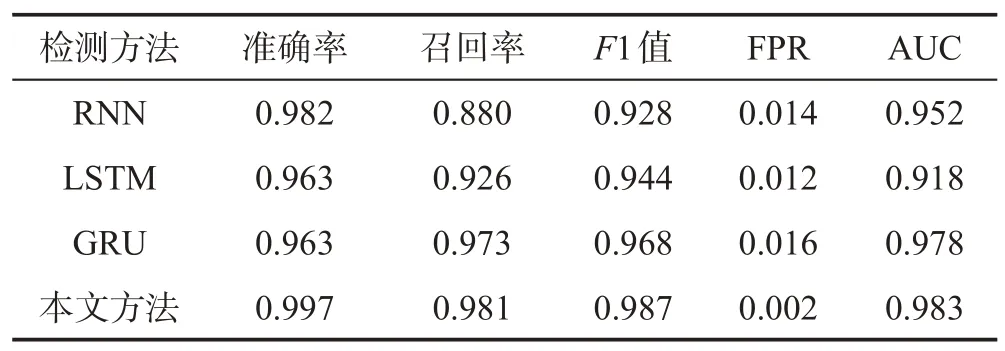
Table 8 Detection results of proposed method and similar deep learning methods表8 本文方法与类似深度学习方法检测结果

Fig.11 Comparison of different deep learning detection methods图11 不同深度学习检测方法的对比
为了验证本文提出的检测方法相对于其他深度学习检测方法具有更好的检测性能,将本文方法与RNN、LSTM和门循环单元(gated recurrent unit,GRU)进行了对比实验,结果如表8 和图11 所示。可以看出,深度学习中常见的RNN、LSTM、GRU 检测方法对跨站脚本攻击实现了良好的检测,但是相对于本文提出的BiLSTM 检测方法,它们在准确率、召回率和F1值都有所欠缺。同时可以看到本文方法与其他三种方法相比具有最低的误报率(false positive rate,FPR)。图12 绘制了四种方法的ROC 曲线(receiver operating characteristic curve),并计算出AUC(area under the curve)值。可以看出,BiLSTM网络比单向的RNN、LSTM、GRU网络更适用于跨站脚本检测。
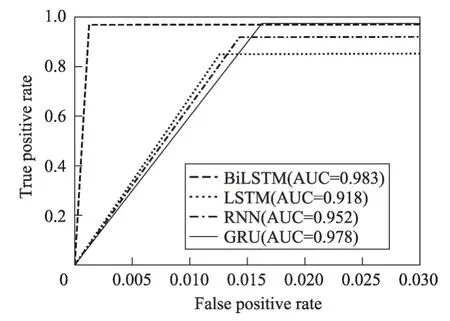
Fig.12 ROC curves图12 ROC曲线
5 结束语
针对现如今复杂网络中的XSS 攻击问题,本文提出一种基于双向长短时记忆网络的XSS 检测方法。首先,由于XSS 通常采用编码技术进行恶意混淆,为了提高检测精度,先对数据解码;然后,通过数据预处理使其向量化作为神经网络的输入;其次,采用BiLSTM 提取XSS 的抽象特征;最后,利用分类器根据抽象特征进行分类,完成检测。与三种传统的机器学习方法相比,本文所提方法不需要人工提取XSS 代码特征,大大降低了人力成本,并且得到了更好的检测结果。与三种深度学习方法相比,本文方法更充分地利用了与XSS 相关的信息,在XSS 检测上取得了更高的准确率和更低的误报率。本文提出的检测方法可能面临着以下挑战:一是BiLSTM提取的特征中有与XSS 相关性不高的信息,从而加大了模型计算量;二是模型可能对于其他类型的XSS 检测性能不高。因此下一步将进行针对这两方面的研究:一是使用注意力机制对模型进行改进,运用注意力机制计算BiLSTM提取特征的注意力权重,使模型显著关注与XSS相关性高的特征,从而优化模型;二是收集其他类型XSS数据,提高检测模型的泛化能力。
