机器人演示学习编程技术研究综述
2020-08-12殷聪聪张秋菊
殷聪聪,张秋菊+
1.江南大学 机械工程学院,江苏 无锡 214122
2.江苏省食品先进制造装备技术重点实验室,江苏 无锡 214122
1 引言
近年来机器人产业发展迅猛,2019 年全球机器人市场规模预计将达到294.1亿美元,2014—2019年的平均增长率约为12.3%[1]。从统计数据中可以看出无论工业机器人还是服务机器人,产业规模都在快速增长。
工业机器人在制造业中的应用越来越广泛,从最初的汽车制造业,到近年来快速发展的3C 电子产品制造业,工业机器人在其中都发挥着重要作用。然而,随着社会经济的快速发展,工业产品逐步呈现出多品种、小批量、短周期的特点[2],这对机器人编程的便捷性和快速性提出了更高的要求。传统工业机器人的编程方式对从业人员的编程水平有着较高的要求,并且编程周期较长,针对一种新的产品,机器人编程调试可能要花费数天,甚至数周的时间,难以满足产品多品种、小批量、短周期的生产需求。服务机器人近年来也取得了快速发展,尤其家庭服务机器人,已逐步走进日常生活。与工业机器人相比,服务机器人主要针对的是非专业用户,这对机器人编程的人机交互体验提出了更高的要求。
下一代智能机器人有望实现和人类协作共同完成任务。这就需要机器人能够在非结构化环境中灵活、安全、可靠地与人类互动。其中需要解决的两个重要问题是:机器人如何理解人类动作以及如何执行所学的任务。
针对上述情况,基于演示学习(learning from de-monstration,LfD)的机器人编程技术的研究逐渐兴起。演示学习编程技术是通过人的示范行为向机器人传递知识的一种新方式,不需要专业人员通过编程语言来告诉机器人应该怎么做,而是让机器人具备识别并理解操作人员示范行为中的有效信息,并能够将这些信息转换成机器人的执行文件,进而重现操作人员的示范行为,完成相应任务的能力[3]。该技术不仅可以大幅降低工业机器人的编程难度,还可以大幅提高工业机器人的编程效率,可推广应用到家庭服务机器人、特种机器人等领域,对提高机器人智能化水平,提高制造业生产效率以及提升服务机器人的人机交互体验都具有重要意义。
欧美国家在机器人演示学习方面的研究起步较早。20世纪90年代已有学者提出基于隐马尔可夫模型的人体演示技能获取方法[4]。2008年,Billard等人[5]指出机器人演示编程(programming by demonstration,PbD)是一种很有前途的方法,它可以使繁琐的机器人手工编程自动化,降低工厂中机器人开发和维护的成本。同时提出,PbD 也可以称为机器人模仿学习。2011 年,Aksoy 等人[6]提出采用语义事件链(se-mantic event chain,SEC)来描述演示操作过程中对象关系的变化,以便于机器人在新的场景中重现演示任务。2015 年,Cubek 等人[7]使用概念空间让机器人在更高的概念抽象级别上解释人类演示的抓取和放置动作。近年来,在工业机器人领域的机器人演示编程研究逐渐增多。2017年,Ramirez-Amaro等人[8-9]开发了一种可快速部署的工业机器人演示编程系统。该系统借助一种电子皮肤和深度相机来获取人类的演示信息,使非专业的操作者能够对工业机器人进行新的任务编程。2018 年,Kyrarini 等人[10]提出一种机器人学习框架,通过演示让机器人学习装配任务的动作顺序,而不需要预先编程。
国内虽然对机器人演示学习的研究起步较晚,但近年来也取得了一些重要成果,值得后续的研究者们借鉴学习。2014 年,深圳机器人学院的Gu 等人[11]为了通过人体演示使机器人获得装配技能,利用RGB-D 摄像机,建立了一个可识别零件/工具、动作和装配状态的便携式装配演示系统,该系统能够生成装配脚本,具有良好的目标识别、动作识别和装配状态估计精度。东南大学马旭东教授等人[12-13]对服务机器人的演示学习进行了深入研究,将服务机器人的任务分为联动任务和非联动任务,并分别设计不同的学习方法。浙江大学的熊蓉教授等人[14-16]针对工业装配任务的演示编程进行了广泛的研究。开发了基于概率图的空间装配关系推理系统,着重研究了演示过程中动作识别与物体跟踪方法,建立了一个机器人装配任务自动编程框架。
国内外研究者都对机器人演示编程(PbD)开展了广泛的研究。本文针对不同的演示学习方式,对近年来较为典型的研究工作进行综述,探讨现阶段机器人演示学习面临的挑战,并指明其发展趋势。
2 LfD编程技术的分类
LfD编程技术按照传感器的类型分为:动觉演示编程[17-18]、视觉演示编程[19-21]、遥操作演示编程[22]。按照其学习信息的逻辑层次可以分为:基于运动的演示学习[17-18,20,23]和基于任务的演示学习[19,21,24-25]。本文采用按照其学习信息的逻辑层次进行分类阐述,如图1所示。
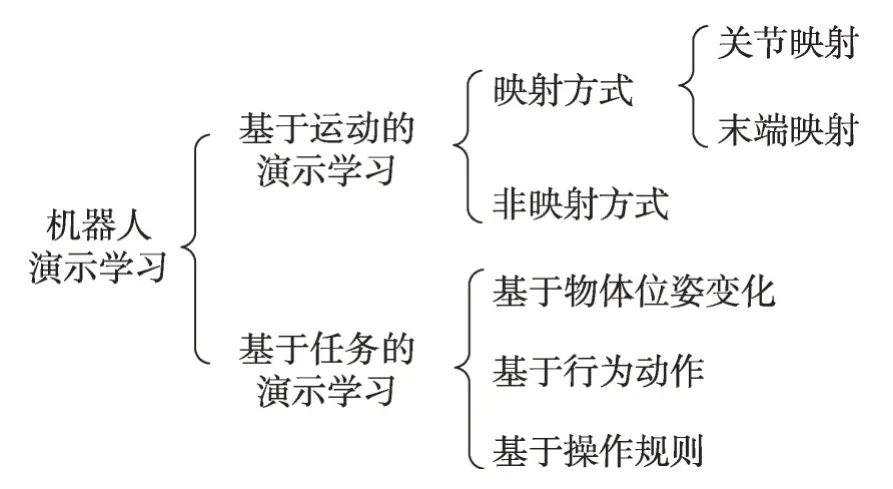
Fig.1 Classification of robot learning from demonstration图1 机器人演示学习分类
基于任务的演示学习和基于运动的演示学习在行为表达上分别对应于语义符号层面和运动轨迹层面[26]。也有的研究工作中这两种演示学习方法同时被采用,以应对不同类型的演示学习编程任务[26-27]。基于任务的演示学习将机器人观察到的人类的示范行为和人类与场景中物体的交互行为采用符号基元进行描述,整个示范行为由一个语义符号描述序列来表达;基于运动的演示学习则直接记录人类示范行为的运动轨迹,用传感器记录的轨迹和运动规划器所规划的轨迹之间的非线性映射关系来描述人类的示范行为。
与传统的机器人示教编程技术不同的是,演示学习编程技术不是简单重复人类的演示动作,而是要从示范行为数据中提取到有效信息,生成相应的运动模型,并能够将其应用到新的任务场景中,具备一定的轨迹泛化和任务泛化能力,能够根据学习到的技能在新的场景下完成相应的任务。因此,演示学习编程技术可以分为演示和执行两个阶段:在演示阶段,机器人需要识别人类的示范行为,并且能够对行为中的子动作进行分割,由此建立运动基元库;在执行阶段,需要根据行为的抽象表示和运动基元建立具有泛化能力的运动模型,以满足新场景下完成任务的要求。
3 基于运动的演示学习
基于运动的演示学习根据是否需要关节或者末端映射可以分为映射方式和非映射方式。其中,映射方式又分为关节映射和末端映射两种。
3.1 映射方式
映射学习方式通常采用视觉识别或数据手套等方式来提取人的示范行为中关节或手末端的运动轨迹信息,并将处理后的轨迹信息映射到机器人空间,使机器人能够重现操作人员的演示动作。
若仅识别提取人手末端或者人手所持的工具的运动轨迹信息,称之为末端映射方式。Huang等[20]提出了一种基于视觉的多机器人操作演示学习。操作人员首先演示如何使用工具执行任务,同时使用视觉系统观察工具的运动。然后使用统计模型对演示进行编码,以生成参考运动轨迹。机器人使用相同的工具和学习模型,在视觉的引导下完成任务。如图2所示,该方法为了快速精确地跟踪手持工具的运动轨迹,在工具上设置了一个五面体二维码以确保任何一个角度下相机都可以看到两个不平行平面上的二维码,用于估算工具末端位姿。

Fig.2 Pentahedral QR code used to estimate terminal pose图2 用于估算末端位姿的五面体二维码
如图3所示,张思伦[28]利用二维码作为人手末端位姿轨迹估计的标记,并提出在动态运动基元(dyna-mic movement primitives,DMPS)中加入运动特征与障碍物的耦合项因子,拓展为具备避障功能的运动规划系统,使得机器人能够从操作人员多次演示轨迹中根据实际场景中障碍物的约束自主泛化出新的轨迹。

Fig.3 Estimation of human hand end pose trajectory using QR code图3 利用二维码估算人手末端位姿轨迹
除了利用多面体二维码或者平面二维码作为运动轨迹和位姿的标记外,还有的研究者针对具体的工作场景,设计了专门的标记物。Ferreira 等[29]针对喷漆等作业条件较为恶劣的应用场景,设计了一个带有多个高强度led 发光标记的20 面体结构(如图4所示)。其优点是,结构紧凑,方便安装,对作业环境的光线没有要求,使机器人能够快速根据演示行为自主编程。Lin 等[30]设计了一种示教笔(如图5 所示),利用运动捕捉系统捕捉示教笔上的标记点位置,计算出示教笔的姿态。通过记录示教笔的轨迹,并将其映射到机器人的末端来实现工业机器人的自动编程。

Fig.4 Icosahedral structure with luminescent mark图4 有发光标记的20面体结构
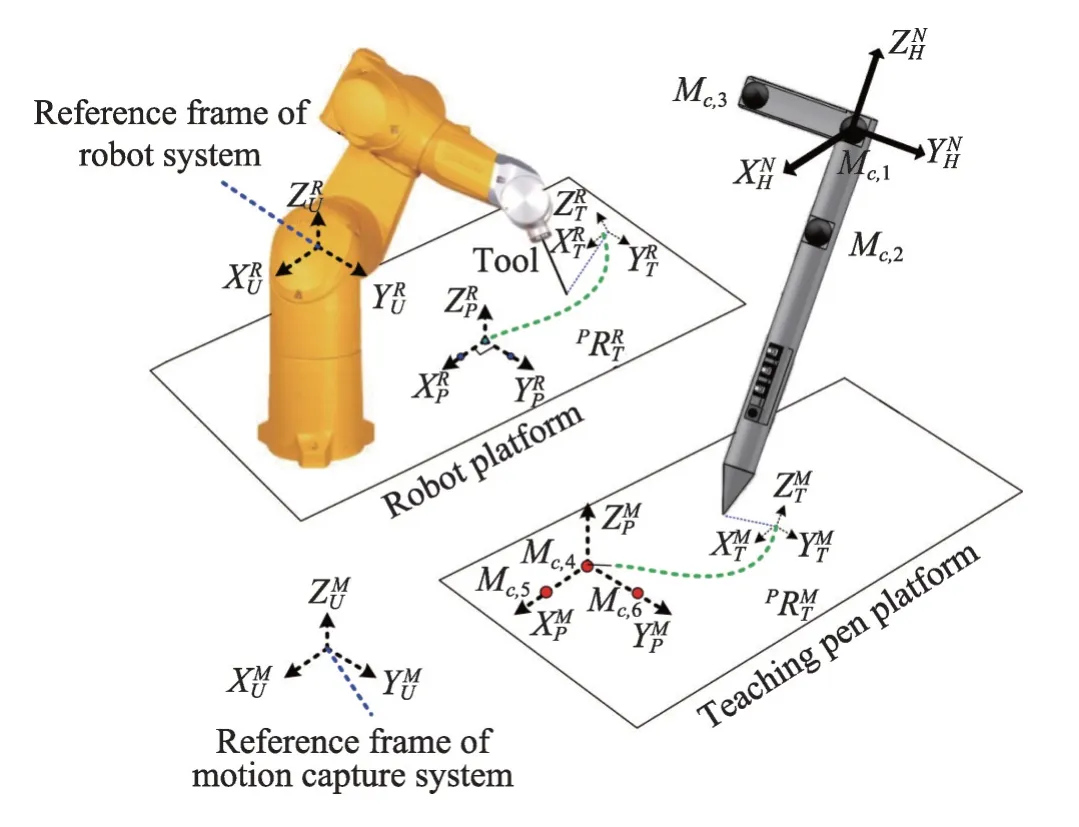
Fig.5 Schematic diagram of teaching pen teaching system图5 示教笔示教系统示意图
目前针对末端轨迹的学习映射方式多采用上述设置固定标记特征点的方案,这类方案的优点可以较为精确地估算出工具末端的姿态和精确地记录末端轨迹。由于设置有特殊的标记点,特征提取速度很快,轨迹跟踪可以做到很高的帧率,可以满足较高的实时性要求。然而,此类方法的缺点也较为明显,尤其是在一些需要徒手操作的场景下,人手不可能在持有特殊标记物的情况下再执行其他任务。固定标记物只是解决了某个点的轨迹跟踪问题,对于某些需要人手多指配合,甚至是双手配合完成的工作,此类方法基本是无效的。因此,如何快速高精度地跟踪记录徒手操作的运动轨迹,或者设计一种不影响徒手操作的标记物等问题还有待于进一步研究。
与末端映射相对应的是关节映射。王朝阳[31]采用Kinect相机获取人臂特征点的位置数据,提出并推导了一种基于肘部约束的冗余七自由度逆运动学解法来获得人臂关节角度数据,建立了人机7-DOF 关节映射将人臂运动传递给机械臂。如图6所示,该方法实现了基于视觉的人体手臂对机械臂的直接示教。与此类似,Jha 等[32]利用人手臂和机器人的运动学模型以及基于Kinect 的运动传感系统实现对机器人的视觉示教。如图7所示,与王朝阳的工作不同之处在于Jha等采用了多台相机从不同角度采集人体姿态数据,并加以互补融合得到更为精确的轨迹数据。

Fig.6 Teaching of manipulator based on vision图6 基于视觉的机械臂示教

Fig.7 Teaching system of manipulator with multiple Kinects图7 采用多台Kinect的机械臂示教系统
Sander等[33]提出一种基于遗传算法(genetic algo-rithm,GA)和主成分分析(principal components ana-lysis,PCA)技术相结合的学习算法,用于仿人机器人模拟人自举动作。如图8 所示,在这项工作中,视觉引导技术成功地应用于学习捕捉人体姿势。

Fig.8 Humanoid robot simulating human self lifting action图8 仿人机器人模拟人自举动作
从上述工作中可以看出,关节映射方式适用于仿人机器人或者结构与人体类似的机械臂,能够让机器人做出更类似于人的动作。但是,因为人手臂自由度较多,将其映射到结构差异较大的机器人空间中非常困难。而末端映射方式的使用场景较为广泛,无需考虑机器人结构上的差异,只需要关注机器人末端轨迹,机器人其他关节的运动可采用其他算法根据实际情况进行规划。
3.2 非映射方式
非映射方式是指从机器人本体的运动数据中学习,通常通过牵引或者遥操作来控制机器人进行示范运动[34]。
Chen等[35]利用KUKA LBR iiwa机器人的拖动演示的功能,针对指定任务进行多次拖动示教,然后利用高斯混合回归对人的示范动作进行粗略建模,接着基于李雅普诺夫稳定性定理,建立了一个约束非线性优化模型,并对之前的微分方程进行了迭代求解,最后得到机器人在动态场景下的动作泛化能力。如图9 所示,即使每次瓶子所放置的位置不一样,机器人依然可以通过轨迹泛化来得到新的运动路径去完成抓取瓶子的任务。

Fig.9 Completing dynamic tasks through teaching and learning图9 通过示教学习完成动态任务
采用拖动示教的机器人通常在末端设置有一个六维力传感器或者机器人关节中配置有力矩传感器。因此机器人不仅仅可以获取示教过程中的轨迹信息,还可以获取在演示过程中的交互力信息。Duan等[36]提出了一个新的学习框架,该框架采用序贯学习神经网络对机器人运动进行编码,并采用一种新的基于力的变阻抗学习方法来估计三个方向的变化阻尼和刚度矩阵。通过多次拖动演示记录轨迹和力信息(如图10 所示),演示结束后,无需手动编码,可以自动获得统一的控制策略。该项研究中机器人从演示动作中不仅学习到了轨迹信息,还学习到了示范行为中的柔顺性。

Fig.10 Obtaining interaction information from demonstration图10 从演示中获取交互力信息
采用拖动演示的方式,往往存在一些冗余动作,不能充分利用机器人的自由度。针对这个问题,Koc等[37]提出一种演示参数稀疏学习算法(learning sparse demonstration parameters,LSDP),来实现关节空间参数的稀疏性,该方法将多任务弹性网络回归与非线性优化交替进行。弹性网络将解投射到稀疏特征集上,而在非线性优化过程中,这些特征(基函数)在二次优化中与数据相适应。如图11 所示,该方法可以成功地在较少参数的情况下捕捉到动作的风格,减少冗余运动的产生。

Fig.11 Learning action style from demonstration图11 从演示中学习动作风格
从已有的研究工作中可以看出,非映射学习方式需要机器人本身具备相应的功能,而且对于小而精的任务难以通过拖动示教的方式进行学习,无法对于需要双手完成的工作进行演示。而映射方式,尤其是末端映射学习方式,可以借助外部传感器,进行非接触式自然学习。特别是近年来发展迅速的视觉传感器在末端映射学习中应用越来越广泛。
4 基于任务的演示学习
基于运动的演示学习主要是学习示范行为中动作的轨迹信息与交互力信息,然后根据所提取的有效信息建立相应的运动控制模型,来提高机器人对工作场景变化后的自适应性。而基于任务的演示学习则注重对任务语义层次的学习,需要对获取的信息进行理解和推理,并能够将其应用到相应的任务中。与基于运动的演示学习相比,基于任务的演示学习能更好地适应任务环境的变动。因此,基于任务的演示学习引起了很多研究者的关注,逐渐成为研究热点。按照不同类型的任务语义,基于任务的演示学习可以分为基于物体位姿变化的语义学习、基于行为动作的语义学习、基于操作规则的语义学习三类。
4.1 基于物体位姿变化的语义学习
基于物体位姿变化的语义学习是指通过识别判断物体在被操作前后的位姿空间关系来推理出操作行为的语义信息。如图12 所示,Dantam 等[38]通过演示中的物体间的装配逻辑,将人类装配演示行为离散化为语义上相关的对象连接操作序列。然后,从一组任务演示中推断出表示任务语义信息的机器人动作语法。最后,将任务语义与机器人的动作语法结合起来,在仿真中展示了机器人执行所演示的装配任务。该工作实现了装配任务从人到机器人的自动转移。
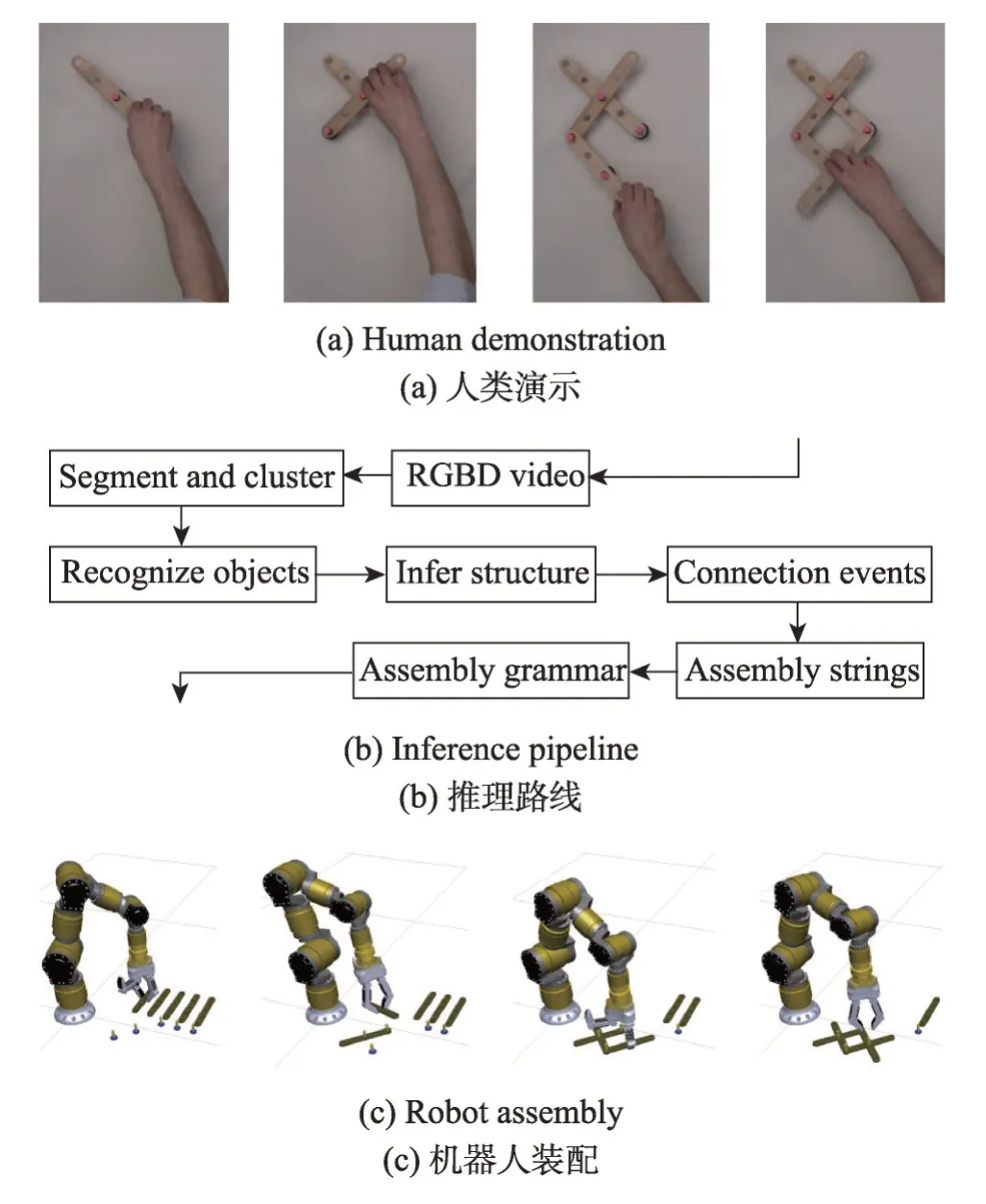
Fig.12 Learning assembly sequence from demonstration图12 从演示中学习装配序列
Ahmadzadeh等[39]提出了一种融合模仿学习(imita-tion learning,IL)、视觉空间技能学习(visuospatial skill learning,VSL)和传统规划方法的机器人学习方法。该方法能够通过观察演示来学习连续的任务。利用IL 学习基于轨迹的原始动作,VSL 通过视觉感知学习操作的顺序。如图13 所示,通过判断物块的空间位置来学习演示动作中的推拉语义信息。

Fig.13 Inferring operation semantics according to change of location of object block图13 根据物块的位置变化推理操作语义
Ahmadzadeh 的研究中没有涉及到多个物体之间的位置关系,当任务中存在多个被操作物体时,问题将会变得复杂。如图14所示,Das等[40]提出一种基于符号编码的技能学习方法,针对任务中的多个物体,分别提取它们的绝对位置变化(absolute position change,APC)、相对位置变化(relative position change,RPC)、绝对方向变化(absolute orientation change,AOC)、相对方向变化(relative orientation change,ROC)以及各物体间的邻近关系推理出演示动作的序列关系。最后调用规划模块来让机器人执行用户想要放置的对象的动作序列。

Fig.14 Operation sequence reasoning图14 操作序列推理
在有些场景中,不仅包含被操作物本身,还包含不同类型的操作工具。Gu等[41]建立了一个便携式装配演示(portable assembly demonstration,PAD)系统,该系统能够自动识别所涉及的对象(部件/工具)、所进行的动作以及表征部件间空间关系的装配状态。如图15所示,为了方便表征部件的识别定位,该系统在部件上贴有二维码,并通过工具与物体之间的交互行为来推理装配关系。

Fig.15 Inferring assembly relationship through interaction between tool and object图15 通过工具与物体的交互推理装配关系
基于物体位姿变化的语义学习注重的是物体间的空间关系,避免直接识别较为复杂的手势动作,适合物体种类固定的且操作逻辑简单的场景,例如:分拣、抓取等。然而有些场景下,物体被操作前后没有明显的位置变化。例如装配任务中的按压操作、拧紧操作对工件的空间位置变化影响很小,难以被察觉。因此,在需要对物体进行精细化操作的场景中,仅通过物体位姿变化难以提取动作的语义信息。
4.2 基于行为动作的语义学习
基于行为动作的语义学习是指通过对示范行为的识别分割,根据前后动作的逻辑关系推理出任务的语义信息。Lambrecht等[42]设计了一种基于无标记手势识别和移动增强现实技术的工业机器人编程系统。用户可以在三维空间中通过手势与真实或虚拟对象进行自然交互,程序员可以在机器人工作空间的一张桌子上移动和旋转他面前的虚拟物体,根据变化自动调整机器人程序。研究中通过对pick-and-place 任务编程的演示,展示了该系统任务级编程的能力。该系统可以使非专业人员在没有广泛实践和经验的情况下定义、评估和操作机器人任务。如图16所示,与其他研究中多采用固定相机的方式不同,该系统中除了配置有固定相机,还配置有一个手持相机设备用于辅助识别人的操作手势。通过这种方式可以在一定程度上减弱视线遮挡对手势识别的影响。但是利用现有移动设备上的相机作为辅助相机,影响人操作的灵活性,并且只能单手操作。如图17所示,Chen 等[43]设计了一种可穿戴的手势视觉识别设备,通过手腕处的相机采集手势图像,较好地解决了常规固定相机存在的视线遮挡问题,便于演示人员灵活操作。

Fig.16 Hand camera assisting gesture recognition图16 手持相机辅助手势识别

Fig.17 Wearable camera equipment图17 可穿戴相机设备
Ramirez-Amaro等[44]提出一种结合手部运动信息和两种物体属性来提取人类演示行为意义的方法。该方法通过在演示学习过程中采集的人的运动信息(move,not move,tool use)和物体状态属性(object acted on,object in hand)来构建知识库。如图18 所示,机器人利用知识库中的信息推理出新任务中的动作序列。
Lin等[45]提出一种卷积神经网络用来识别演示动作中的手势并生成动作序列,在机器人控制模块中实现相应的运动原语,最后基于可扩展代理行为规范语言(extensible agent behavior specification language,XABSL)在机器人上实现拾取和放置任务。该系统的特点是将基于手势识别系统与基于行为的编程平台结合,前者为后者提供高层次的任务序列输入,来完成人工演示中的取放任务。如图19所示,该系统通过基于XABSL的平台实现了一个立方体的堆积任务。
相对于“拿-放”操作任务的示范学习,对动作精细化要求较高的装配作业任务的示范学习要困难很多。因为相同的手势可能出现在不同的装配环节,代表了不同的装配任务,例如拧紧操作,其手势姿态与拿取操作没有明显区别。这对动作的精确识别分割提出了较高的要求。Wang等[46]提出了结合滑动窗口的分割点检测和基于迭代动态规划的识别优化的方法以实现连续装配动作分割与识别。如图20 所示,该方法成功从演示动作中识别分割出不同的装配动作。
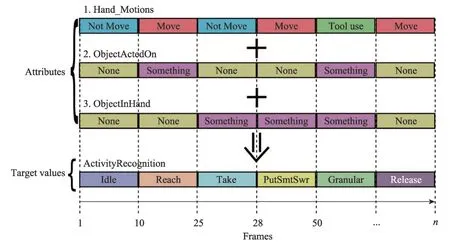
Fig.18 Inferring action sequence图18 推理动作序列

Fig.19 Cube stacking task图19 立方体堆积任务

Fig.20 Recognition and segmentation of assembly action图20 识别分割装配动作
基于行为动作的语义学习主要研究如何从人连续的演示动作中提取语义信息,有些研究工作中也同时考虑了物体的属性[44],且这些属性的变化通常是由操作行为引起的,这与基于物体位姿变化的语义学习中单纯考虑物体属性不同。由于基于行为动作的语义学习不依赖于特定的操作对象,因此方法通用性强,具有广阔的应用前景。但是,对连续操作动作进行实时识别分割很具有挑战性。目前大部分研究工作主要针对较为简单的连续动作进行识别分割,如何提高对复杂且持续时间较长的连续动作进行识别分割的精度和稳定性还有待于进一步研究。
4.3 基于操作规则的语义学习
基于操作规则的语义学习是指从示范行为和物体位姿的相互关系中提取完成相应任务所需要的规则约束,根据所获取的约束条件来完成同类型任务。Lee等[47]提出了一种模仿学习的句法方法,这种方法在有噪声的情况下从相当少的样本中以概率激活语法的形式捕获重要的任务结构。这些学习到的语法可以用于帮助识别不可预见的、共享底层结构的更复杂的任务。如图21 所示,利用该方法从演示视频中学习推理出解决汉诺塔问题的规则,并利用这些规则解决更大规模的汉诺塔问题。该方法适用于具有相同底层规则的任务,通过对小规模问题的演示学习,来解决大规模问题。

Fig.21 Solving Hanoi Tower problem by learning rules图21 通过学习规则解决汉诺塔问题
陈世佳等[48]提出一种基于对比示范的演示学习方法,通过动作识别和状态检测将信息抽象成符号形式,然后经过认知推理得到演示任务的执行决策和约束条件,并通过动作共享指导机器人重现任务。如图22 所示,演示者分别演示先拿悬空的杯子和先拿桌子上的杯子,通过不同的取杯顺序告诉机器人任务的约束条件是先拿悬空的杯子,否则悬空的杯子会摔落。

Fig.22 Extracting task constraints from comparative demonstration图22 从对比示范中提取任务约束
在各种演示学习的研究中,基于操作规则的语义学习相对较少。在针对具体的生产生活中包含的规则种类不多的场景中,可以利用机器人来学习相关的基础规则,使机器人能够根据这些基础规则推理出如何执行包含若干基础规则的复杂任务。例如搭积木、拼图、恢复魔方等规则性较强的任务。
5 面临的挑战与发展趋势
针对基于演示学习的机器人编程问题,国内外研究者已经开展了较为广泛的研究工作。基于运动的演示学习注重获取演示者的运动轨迹信息,通常应用于工作内容较为简单的场景。其优点是,可借助机器人本体的拖动示教功能或者借助特定的标记物来记录用于建模的轨迹信息,避免了对复杂手势的识别,大大降低了演示学习的实施难度。然而,在工作内容较为复杂的场景下,轨迹信息复杂,甚至还包含不同工具的切换信息,使用基于运动的演示学习往往难以满足要求。基于任务的演示学习则关注任务本身的语义信息,通过解析任务的语义序列,利用动作原语库,根据语义序列对原语动作进行组合来重现演示任务。这大大增强了机器人对不同任务灵活应变的能力。但是解析语义序列,需要对连续动作进行识别和分割,这是一项具有挑战性的工作。
现阶段大部分研究工作主要针对简单的演示任务,仍处于实验阶段。若要将基于演示学习的机器人编程技术推广到实际生产应用中,仍面临以下挑战:
(1)建立具备通用性的编程框架
现有的演示编程技术往往针对某一具体场景,通用性较低,难以将相关方法移植到其他任务场景下。例如基于拖动演示的方法要求机器人本身具备相应的功能,难以移植到传统的机器人上。近年来发展迅速的机器人视觉技术是提高演示编程技术通用性很有潜力的一种方法。建立一套可移植性强的演示编程框架,是一项具有挑战性的工作。
(2)稳定可靠的语义提取方法
与实验环境相比,实际的应用场景中的工作条件不可预知,因此相关的示范行为识别分割方法需要较高的环境自适应性和鲁棒性。语义序列提取出错,可能导致机器人执行任务过程中发生严重的事故。一些应用场景下可能涉及到较为复杂和精细化的操作,例如缝补操作、细小零件装配操作等。提高这些动作在动态场景下的识别率,对于提高演示编程的稳定性具有重要意义。
(3)良好的人机交互体验
与传统机器人编程技术相比,演示编程技术虽然降低了对操作人员专业性的要求,然而现有的演示编程技术的人机交互体验离自然人机交互的要求还有很大的距离。在使用前往往需要一定程度的培训,例如:需要告知演示者一些特定的手势动作[43];配置特定的演示环境[46]等。建立良好的人机交互机制,是发展演示编程技术的重要目标之一。利用多源信息融合提高人机交互体验是很有前景的方案。
随着模式识别、人工智能技术的快速发展,基于演示学习的机器人编程技术将向着智能化、通用化方向发展:
(1)多感官信息融合
面对建立通用性的编程框架和开发稳定可靠的语义提取方法等挑战,多感官信息融合是提高通用性和可靠性的有效手段。文献[49-50]利用视觉、惯性单元、肌电信号等不同种类的传感信息来获取演示行为中高层次的语义信息。多源信息融合可以增强算法框架对不同任务环境的适应能力,提高了机器人演示编程技术的智能化和通用化水平,是优化人机交互体验的重要手段。在可预期的未来,机器人演示编程技术将借助模式识别、人工智能,通过多感官信息融合向智能化、通用化方向发展。
(2)利用深度神经网络实现端到端学习
近年来,快速发展的深度神经网络技术逐渐引起了机器人领域相关研究者的注意。2018年英伟达公司开发了一套采用神经网络的机器人演示学习系统,并在2019年的开发者大会上进行了现场展示[51]。该系统每个环节都由神经网络组成,可根据人类的演示动作,重现物块堆叠任务。2018年,中国科学院自动化研究所智能机器人系统研究中心也开展了类似的研究工作[52]。也有的研究者利用深度神经网络实现了端到端的演示学习[53-54]。端到端的学习方式将研究人员从繁琐的特征提取环节中解放出来,降低了机器人演示学习框架的复杂性。深度神经网络还具有很强的泛化能力,使得演示学习框架在不同类型的机器人间的移植相对容易,提高了演示学习框架的通用性。利用深度神经网络实现端到端的机器人演示学习方法将逐渐成为研究热点。
6 结束语
近年来,随着制造业的快速发展,机器人在生产活动中的应用越来越广泛。如何简化机器人编程、提高编程效率、降低机器人的使用门槛对企业提高生产效率、降低成本具有重要意义。基于演示学习的机器人编程技术是实现这一目标的重要途经之一。现阶段基于演示学习的机器人编程技术仍不成熟。可预期的未来,模式识别、人工智能技术的快速发展,将会对机器人演示学习技术的完善起到重要的推动作用。另外,人们不仅通过视觉特征,而且通过声音、动作和其他特征来与其他人交流、学习。与此类似,机器人仅通过单一的感知方法很难学习到高层次的语义信息。因此,多感官信息融合和人工智能技术相结合是演示编程技术发展的一大趋势。
