高效众核DSP仿真调试结构的设计与实现*
2020-08-11王慧丽雷元武吴虎成
潘 奇 王慧丽 雷元武 吴虎成
(国防科技大学计算机学院 长沙 410073)
1 引言
集成电路制造工艺和微体系结构的迅速发展,对数字信号处理器(DSP)的处理能力及效率要求越来越高。单核DSP已经远远不能满足市场需求,多核DSP的发展成为主流。然而,随着DSP的单核数量的增加,DSP的仿真调试效率却面临着巨大的挑战。
对于数字信号处理系统,其大部分功能需要通过仿真调试技术来进行功能验证和调试开发[1]。仿真调试技术基于JTAG(Joint Test Action Group,联合测试行动小组)标准协议[2~3],采用串行结构,而众核DSP芯片因为核数量众多,串联调试链路过长,导致调试效率很低。因此如何加速众核DSP芯片的仿真调试,也成为芯片设计者关注的重点之一。
文章基于我国自主设计研制的银河飞腾[4]高性能数字信号处理器X-DSP,在经典菊花链仿真调试技术的基础上,采用分组共享的优化策略,实现了一种总-分结构的仿真调试设计,极大地提高了众核DSP仿真调试效率,缩短了芯片流片前的研发时间,高效地支持了DSP用户的在线调试及应用需求。
2 基于经典菊花链的众核DSP仿真调试效率分析
基于经典菊花链的多核调试设计[5~6],如图1所示。DSPCorex为多核处理器中的单核DSP,ETx为不同单核DSP中的仿真调试部件。在TAP(Test Access Port)控制器的作用下,指令通过TDI端口,串行扫描进入DSP内部,并将需要进行调试的指令移位至对应单核ET部件的指令/数据寄存器(IR/DR)中。ET对该IR/DR中的调试指令进行解码,向DSP单核发送调试请求,并将调试返回数据/状态经由TDO输出到DSP外部。

图1 基于经典菊花链的仿真调试结构
经典菊花链的串联设计方式,广泛应用于嵌入式芯片的调试设计中[7~9]。但是,当 DSP 单核数量增加时,处理器的整条调试链路会变得很长。假设DSP中单核数量多达N个,而一个IR/DR的位宽为IR_Len,则采用菊花链结构时,其调试链路长度为N*IR_Len。在图1中,如果对DSP CoreN进行调试,则至少需要经过N*IR_Len个测试时钟周期(TCK),调试指令才能由芯片TDI端口到达DSP CoreN。对于N达到一定规模的众核DSP处理器,芯片的调试效率会发生显著的下降[10~13]。因此,如何设计更为高效的仿真调试结构,是众核DSP处理器仿真调试的重点研究内容。
3 基于分组共享策略的众核仿真调试结构优化
3.1 基于分组共享策略的优化方法
在众核处理器中,经典菊花链的调试效率低下,一个重要的原因在于:调试指令只能在软件的控制下,以串联的方式,逐位进入到需要进行调试的单核中,即使很多单核并不是调试的对象,也不可避免地串联进了扫描链路中。因此,在调试指令到达调试目标单核的过程中,减少不必要的单核进入扫描链路,是提高调试效率所面临的最主要的难题。而基于分组共享的优化策略,则比较高效地解决了这个问题。
图2描述了基于分组共享策略的优化方法。如图2中所示,每两个DSP单核为一组,共享一个带有ID标识的IR/DR资源;JTAG调试链路不再进入到单核内部,而是以分组为单位,依次串联每个分组共享的IR/DR。在进行调试时,软件将带有ID标识的调试指令发送到对应的分组中,每个分组再根据ID标识,将IR/DR发送到对应的DSP单核中。基于分组共享策略的优化方法,其分组方式可以根据实际处理的结构和大小进行调整。

图2 基于分组共享策略的优化方法
3.2 X-DSP众核处理器的总-分仿真调试结构
X-DSP众核处理器中,包含了M个DSP簇(DSP Cluster),每个簇包含Z个DSP单核(Core)。结合X-DSP的体系结构及单核数目,对图2中的分组方式进行了相应的调整,设计了一种基于分组共享策略的总-分JTAG仿真调试结构,如图3所示。在每个簇中设计一个JTAG指令译码控制(JTAG-Controller,JTAGC),M 个 DSP Cluster在处理器顶层以菊花链形式串联,接收基于JTAG协议的调试命令;每个簇内的Z个单核共享本簇内的一个JTAG控制器,JTAGC在对调试指令携带的每个Core的ID标识进行译码后,通过AXI协议将指令发送到对应的Core中。基于分组共享策略的总-分调试结构,其最长的调试链路为M*(ID+IR_Len),大幅减小了最长调试链路,有效地提高了调试效率。
X-DSP的调试通路进行优化设计后,仿真/调试部件包括两个主要部分:位于DSP簇内的JTAG控制器与DSP单核内部的仿真调试部件(ET)。JTAG控制器负责TAP控制器以及对Core ID的译码,同时采用AXI协议与单核进行通信;单核内部ET则负责对IR/DR进行译码,并执行相应的调试工作,实现对X-DSP的资源访问、流水线控制,以及事件统计的调试功能。

图3 X-DSP众核处理器的总-分仿真调试结构
3.3 内核ET的设计
X-DSP众核处理器中,DSP单核内部调试通路,如图4所示。单核内ET采用AXI协议,将JTAGC发送到单核的IR/DR进行译码后,按照调试通路的类型,实现以下三种仿真调试功能[14~15]:1)配置空间的读写访问(包括核内私有地址空间以及核外共享地址空间),通过配置总线通路进行访问;2)数据空间的读写访问(包括核内私有地址空间AM/SM以及核外共享数据空间),通过DMA通路进行访问;3)核内的映射(mem-map)地址空间(全部映射到ET的配置空间地址内),此部分包括核内的非全局编址的寄存器资源,流水线资源,ET的寄存器等,由ET直接进行访问。
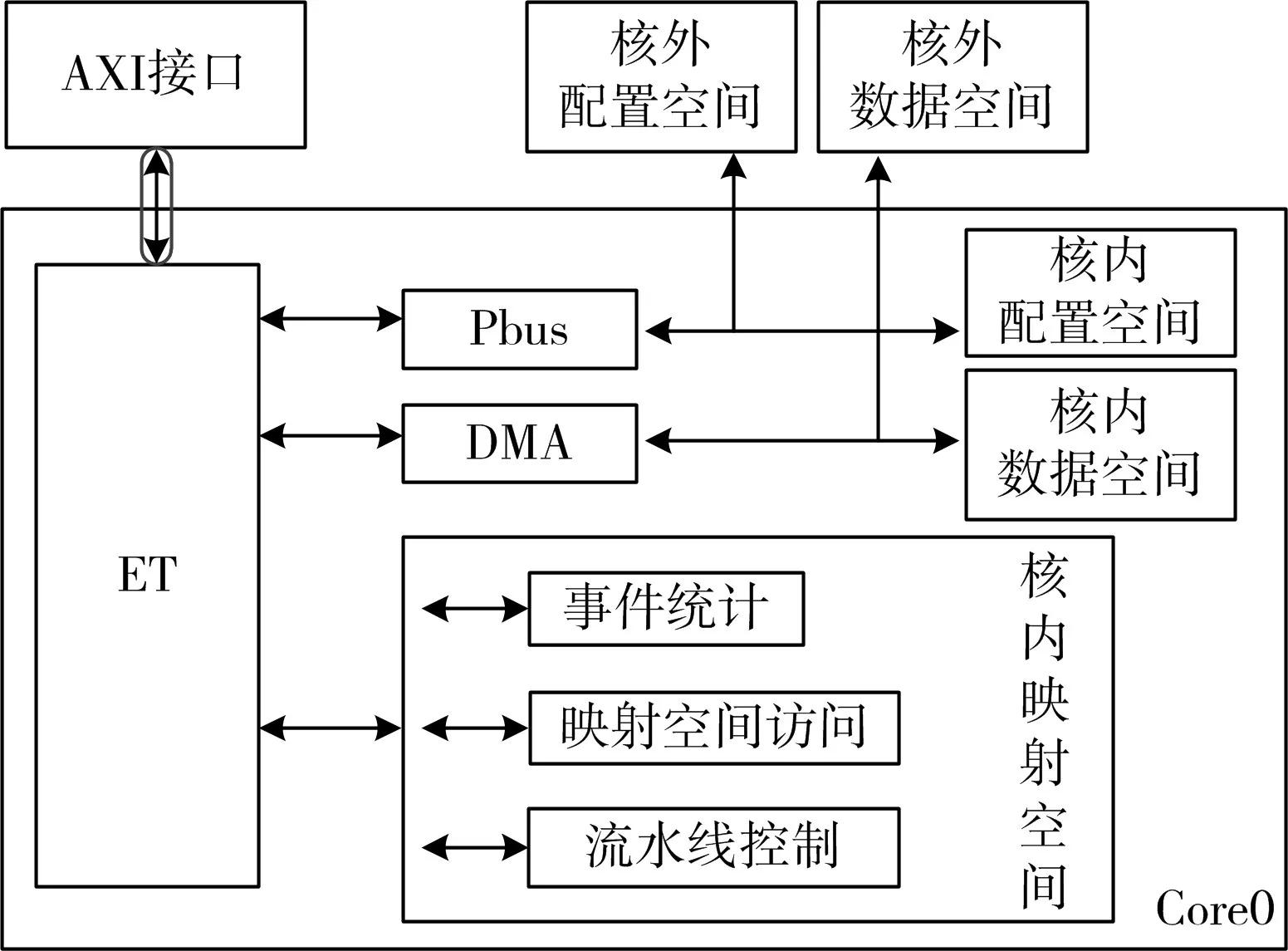
图4 单核内的调试通路
3.4 软硬件联合优化
高效的仿真调试设计,需要软件和硬件的协同工作[16]。X-DSP在减少JTAG串行链路长度提高调试效率的同时,在软件层面也通过灵活的驱动调用方式对存储空间的大批量读操作进行了优化。
优化前的仿真调试部件,访问一次存储空间的64bit数据,需要软件发送一个读指令IR_Read和一个捕获数据指令IR_Capture。IR_Read负责将所需数据读取到ET内部IR寄存器中进行保存(64位宽),IR_Capture则负责对ET的IR寄存器的数据进行捕获。如果用户需要访问一个512bit的数据时,则需要分别发送8次IR_Read和IR_Capture,共16条指令。X-DSP经过硬件优化后的仿真/调试部件中,ET访问存储体宽度提高为512位,JTAGC接收到一个IR_Read指令后,即可将512位数据读取到ET中进行保存;再通过8个连续的Capture指令,将512位数据以64bit为单位分8拍返回。此时,如果用户需要访问一个512bit的数据时,则只需要由软件发送1次IR_Read和8次IR_Capture,共9条指令。软硬件的联合优化方式,极大地提高了对内存资源访问时的效率。
4 验证与综合
4.1 功能验证
X-DSP众核处理器的仿真/调试部件采用两种验证手段:一种是在NC_verilog环境下进行的模拟验证;另一种是基于FPGA的原型验证。对仿真调试/部件的验证需要汇编程序测试激励作为背景程序,此外还需要手工编写仿真/调试指令和数据。通过分析设计文档提炼出相应的功能验证点有如下:1)ET在进行资源访问时,与DMA以及总线之间的通信机制验证。2)流水线基本操作的验证:运行、暂停、单步。3)软件断点的设置、恢复以及取消的验证,硬件断点的验证。4)性能统计:对关键事件统计次数的验证。
抽取部分验证结果如图5~6所示。

图5 ET通过DMA的读操作
图5为ET通过DMA通道对向量存储器AM地址为0X4_0000_0000进行读写读操作。如图所示,当ET接收到IR寄存器中的112位命令(0X3FF4_00000001_00000004_00000000)后向DMA发送请求信号ET_DMA_Rd以及要读向量寄存器的地址;DMA接收到ET的访问请求后,在不受到其他条件的干扰下,会将ET_DMA_Rd(DMA给ET读数据返回有效信号)信号拉高的同时将访问该地址的内容通过ET_DMA_Rd信号以512位数据返回。
图6为ET通过设置硬件断点控制流水线的情况,硬件断点的设置不会改变目标指令,但是会消耗掉很多硬件资源,因此对硬件断点的存储是有限制的,X-DSP为ET部件分配了8个32的硬件断点地址寄存器(HBPAR0~7),以及8个1位的硬件断点使能寄存器(HBPER0~7)。如图所示,设置硬件断点为0X163,将执行指令地址与用户设置的地址进行比较,发现一致则触发硬件断点。断点指令停在E1站即BR_PCE1信号,硬件断点标志信号HBPC_HWBP拉高,使流水线拉高即ET_Stall信号拉高,进入调试状态。
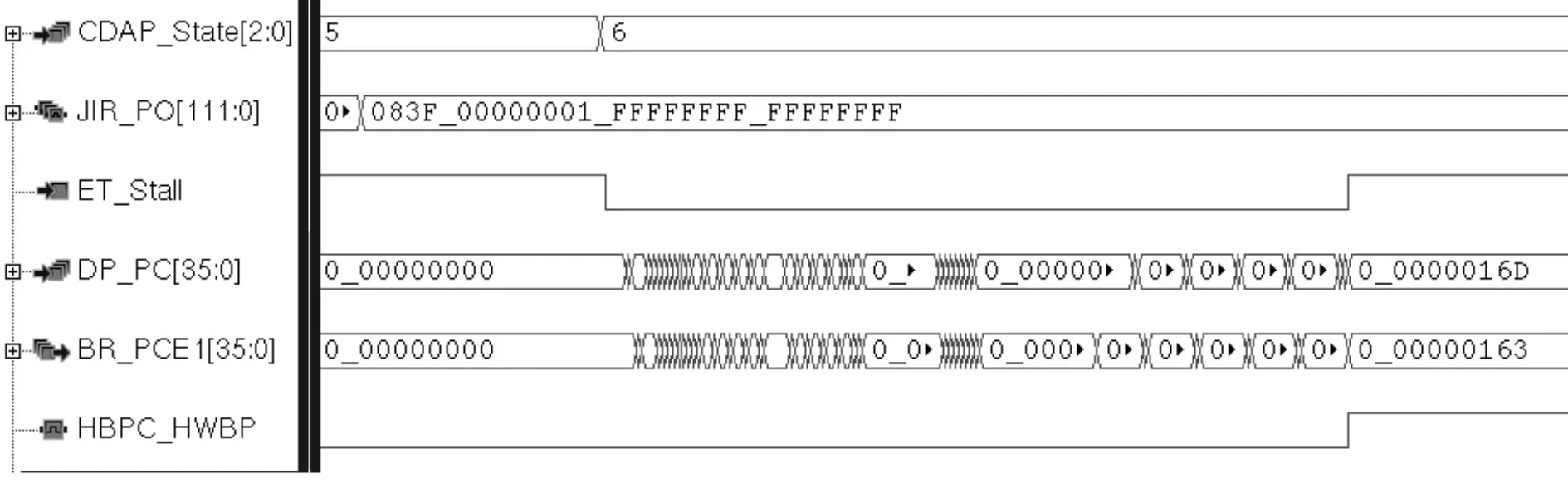
图6 ET的硬件断点操作
4.2 面积与时序
对本文提出的设计进行综合,面积和时序报告如表1。
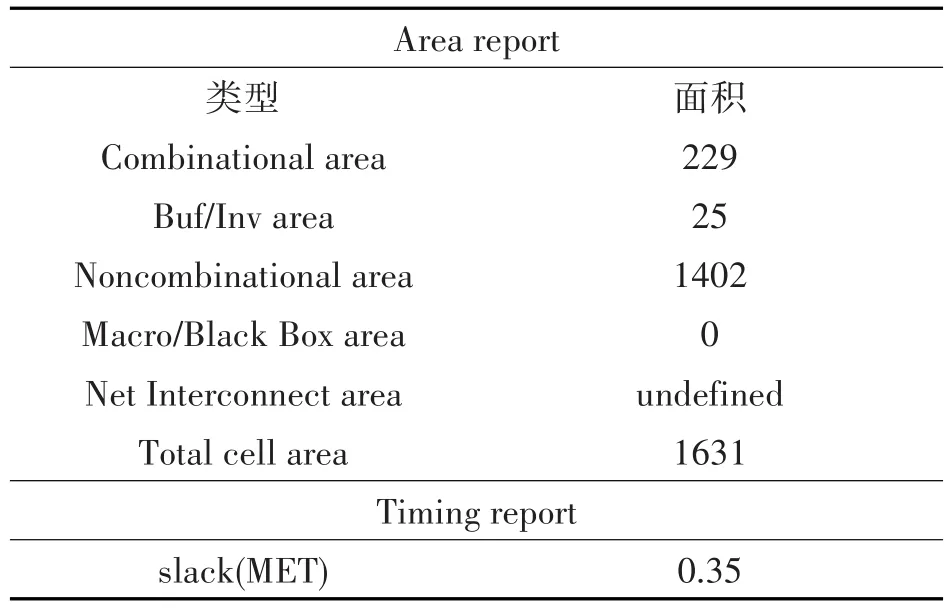
表1 面积和时序报告
4.3 性能评估
指令寄存器IR(78bit)是与JTAG标准兼容的指令寄存器并且连入TDI和TDO之间。IR本质是基于移位寄存器的设计,在有效状态下对TDI的串行输入数据进行移位处理并进行相应操作。IR即可以存储指令,也可以产生指令通路的JTAG输出信号TDO。优化前X-DSP的N个单核采取依次串联的方式构成调试通路,所以调试链路长度为78*N。经过优化后JTAG调试通路结构如3.1小节,调试通路有M个JTAGC控制,每个DSP簇中包含Z个DSP单核,IR宽度扩至78+Z位,为了提高X-DSP芯片的高性能预留了8个单核用于扩展,即IR宽度调至86+Z位。因此优化后的调试链路长度为(86+Z)*M,X-DSP的JTAG串行链路长度降低了1-(86+Z)*M/(78*N)。3.4小节对存储体的进行大批量读操作时,优化前需要8个IR_Read和8个IR_Capture。通过软硬件联合优化后,需要1个IR_Read和8个IR_Capture。所以进行大批量读操所需时间降低了(112+8*112)/(8*(112+112))。综上所述,在这种新型的JTAG调试设计中,假设M为4,Z为24,相比未采用新的JTAG调试链路时,JTAG串行链路长度整体降低了94%,进行大批量读操作所需时间降低了56%。
5 结语
本文首先对经典菊花链仿真调试结构在众核处理器中的工作原理进行了介绍,分析这种结构随着单核数目增加,而出现的调试链路过长,调试效率下降的原因,提出了基于分组共享策略的优化方法,并结合对X-DSP众核处理器的体系结构和单核数目,提出了基于分组共享策略的总-分调试结构,大大提高了X-DSP的调试性能。最后通过软件驱动与硬件设计相结合的软硬件联合优化方法,大幅度提升了批量读内存操作的效率。在硬件逻辑设计完成后,对X-DSP中仿真调试部件进行了功能验证,以及后期的综合优化。最终验证结果与设计规范的期望一致。
