结合文本语义图和词频统计的网页分类算法研究*
2020-08-11周文文黄树成
周文文 韩 斌 黄树成
(江苏科技大学计算机学院 镇江 212003)
1 引言
互联网的快速发展带给人数不尽的网页,面对如此爆炸式丰富的内容,如何精准快速地查询到自己所需要的信息成了计算机领域近些年来研究的热点,在这种情况下,网页分类技术应运而生并一直处在发展进步中。
简单来讲,网页分类就是一个依照不同的种类、等级或性质研究网页相似性,然后将网页分别归类的过程。现在主要发展有两个方向,一个是占主流的依照文本内容分类[1],即分类实现依托于各种词频统计权值算法。另一个是依照文本语义[2]分类,但由于中文语义的错综复杂,这一方向还有待发展。前者的思路是将网页文本在预处理分词后根据词条在文本出现的频次和在其他网页中出现的频次[3]为基础发展改进的,重点在于词语出现与否以及出现的次数,缺乏了对词语语义语法结构和句法的考虑,忽略了词语本身自带的信息。后者则侧重于词义本身和文本结构性[4]信息,以词义以及词语和词语间关系为依托进行网页间的相似性判别,但也忽略了文本自身词语的比例组成。
为了提高网页分类效率,本文提出一种通过分析网页词义,以词语组合代替单独的词语作为特征项构建文本语义图为基础的网页分类,兼顾词语间的相似性和词语相关性,然后融入对于词语组成词频统计的研究,结合文本语义图和内容共同进行网页分类,并作出相应改进。
2 词汇网络构建
2.1 语义图节点获取
获取网页内容,经过源网页解析[5]和文本预处理,网页文本内容以一系列词的形式存在。要选取合适的词语作为特征词组成特征词空间,考虑词频对词语重要性的影响,且为了减少词语冗余,增加计算工作量,从中选取频次 f>fmin(给定最小词频)的词语作为特征词语义图节点空间。
2.2 词语相似性
2.2.1 同义词词林
同义词词林[6~7]是梅家驹先生于1983年编纂而成的一部同义词辞典,哈尔滨工业大学信息检索实验室又对其中词语进行了更新,完成了扩展板部分的改良。扩展版共含有7万多个词语,这些词语又被分为12个大类,94个中类,1428个小类,再细化小类为词群和原子词群。整部辞典呈五层树状构架存在,遵循从具体到抽象的准则,随级别逐层细分,第五层即为不可再细分的原子词群。值得一提的是,在第五级词群中,不仅分有同义词,例如东南西北和四方同属一个编码,这类词明显相似性最强,还有相关词,例如液体、流体是为同类相关词,同属一个编码,但这种词相似性比前者要弱。同时还存在有独立词,即该词既没有同义词也没有相关词,显然这类词相关性最低。对这三类词,编者分别用“=”“#”“@”三种符号在编码末加以标注区分。
2.2.2 词语相似性计算
词语相似性[8]是一个取值范围在0~1之间的数值,次遇见相似性越高,相似度越接近1,词语和其本身相似度即为1。根据词语在词林中距离的远近,又考虑到词语所在词林树的密度及分支数,若两词语在第 i层分支,定义词语相似度[9]sim(x,y)为
其中,θi为词林第i层分支下的分支系数,m为i层总分类数,k为两分支间距离。分别计算不同节点间的相似度,给定最小相似度值 simmin,当时,在两节点间建立一条边,形成初步语义网络。
2.3 词语相关性
2.3.1 频繁项集
研究语义的过程中,不仅要考虑词义自身所含的特性,还需要考虑该词语在整个文本中发挥的作用,查看在特定文本中词语间的相关性,即当多个词语同时出现在同一个文本类中,可以推断这些词语间有很强的相关性。首先给出频繁项集[10]的概念,记文本中词汇集合 D={wordi,wordj,…,wordn}为数据集,有 X={wordi,wordj…} ,若 wordi∈D ,则称X为项集。而对于项集X,若X的支持度满(最小支持度)时,则称 X是数据集 D 上的频繁项项集[11],wordi,wordj… 具有词语相关性。
2.3.2 频繁项集挖掘
在频繁项集的基础上找出关联规则的过程即为频繁项集挖掘。以X是频繁项集为基础,对于则 X就被称为数据集D上的最大频繁集[12]。又因为最大频繁集的非空子集一定是频繁项集,所以只需要保留最大频繁集即可,由所有最大频繁集组成而成相关词集。遍历最终的相关词集,在相关词集中的每一个相关词组合之间建立一条边,将新的边添加到语义网络中,得到最终完整的词汇语义网络。
3 词频统计方法
3.1 IDF算法
在形成词汇网络的过程中,算法仅对词语出现的总体词频做出考虑,缺少对类内词频分布的考虑,也对特征词所在的文本在全部文本中的分布信息没有关注,显然这种考虑并不充分的。对于这种缺失,首先引入 IDF算法[13~14]。IDF算法是逆文档频率权重法,它认为在少数文本中出现的特征词更具有代表性,故出现文本数量越小的词语给予的IDF值越大,显示该词语区别能力越强。这种算法很好地考虑到了特征词所在的文本在整个语料库的分布信息。在结合词语类内的分布,有词频权重值wfi:
其中,wfi是特征词ti的词频权重值,idf(ti)是逆文档频率权重值,mi是特征词在该类中出现的文本数,Mi为该类文本总数,当词语在该类中文本占比越多,则该词语越能代表该类网页,权重值越大。
3.2 IDF改进算法
在上述分析中,对于词语出现的文本占比,逆文档频率算法仅从宏观角度去度量,但对于每类样本空间,有一种词语属于网页常见词,在多个类别中都有不均衡出现,这种词语词频偏高,文本总占比不高,但携带的类别特征信息却仍然很少,区分度并不高,易引发混淆,影响网页分类的效率,为减少这类词语的影响,对逆文档频率算法做出改进,有

其中,N为总文本数,ni为词语ti所在文本数,Ci为词语ti所在的类别的类别数,当Ci越大即词语所在种类越多时,词语ti所携带的分类信息越少,给予较低权重。综合上述分析,词频权重wfi更新为

4 特征向量
4.1 PageRank算法应用
基于词汇网络图的特征权重计算,这里引入PageRank 算法[15~16]。PageRank 是 Google创始人提出用来计算网页排序的经典算法,用网页间的互相链接表现网页的重要程度。若一个网页被很多其他网页链接到则认为该网页很重要,给予大的PageRank值,而当一个网页被一个高PR值网页链接时,它也将相应提高自身的PR值。PageRank以此为基础对网页进行排序,同样的思想借鉴到词汇网络为节点重要程度排序中。在词汇网络中,当一个节点被其他很多节点指向时,认为这个节点较为重要。同样地,当一个比较重要的节点指向其他节点时,被指向的节点重要程度也将提高。这里节点更重要就是指这个节点携带信息量多,区分度高,因而具有较强的分类能力,对分类效果会产生较大影响。一个节点的PR值[17]为

其中,FVi为指向节点Vi的节点合集,LVj是从节点Vi出发指向其他节点的边的条数,N为网络中的节点总数,d为阻尼系数,帮助节点的PR值实现收敛,通常d取0.85。为提高PR值的收敛速度,指定计算PR初值为
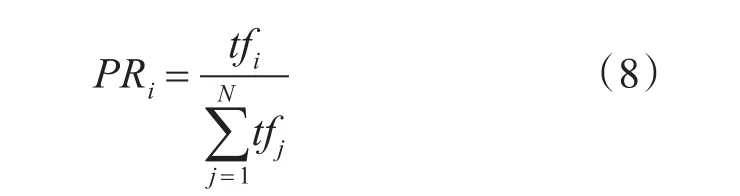
根据公式可以计算每个节点的PR值,当节点PR值经过不断迭代趋于平稳时,得到最终PR值,记每个节点的语义权重值Wi=PRi。
4.2 特征向量计算
由PageRank算法,可以得到特征词的语义权重值,结合改进的词频权重算法得出的词频权重值,得到最终权重值Wi:

5 实验结果与分析
网络上公开的中文网页文本库并不多,故通过人工抓取获得4028个网页,分别有游戏、旅游、医疗、招聘、金融五个类别,其中2754个网页作为训练集,剩下1274个网页作为测试集。具体类别分布如表1。

表1 文本语料库分布表
实验选用K最近邻算法(KNN)[18]训练分类器。
实验一:对比基于文本语义图网页分类算法、基于词频统计网页分类算法和结合文本语义图和词频统计的算法分类效率,结果如表2。

表2 三种算法效率对比表
由实验结果表明,仅基于词汇网络和仅基于词频统计的网页分类效果明显差于融合两种算法的网页分类算法,说明这种结合是行之有效的。
实验二:对比算法改进前后网页算法的分类效率,结果如图1所示。

图1 权值改进前后效率对比图
由图1可以清晰看出,对特征权值改进后,网页分类效率明显优于改进前。实验结果表明,改进方法可以有效地进一步提高分类器分类能力。
6 结语
本文针对传统网页分类算法进行分析,在构建文本语义图的基础上实现PageRank算法,并结合词频统计算法实现两种分类方法的融合,另外对算法做出一定改进,通过添加词频权值的方式将词语的重要性区分开来,提高词语区分度,提高分类效率。实验结果表明这种改进算法在准确率,召回率和Fl均值三种评价方式中均有明显的提高,相较于其他网页分类方法具有很大的优势。接下来,如何让这两种方式结合的更加完美以取得网页分类效率的进一步提高将是研究重点。
