用户属性感知的移动社交网络边缘缓存机制
2020-08-05李红霞
杨 静,武 佳,李红霞
1) 重庆邮电大学通信与信息工程学院,重庆 400065 2) 重庆高校市级光通信与网络重点实验室,重庆 400065 3) 泛在感知与互联重庆市重点实验室,重庆 400065 4) 中国联合网络通信有限公司重庆市分公司,重庆 401123
随着智能终端设备数量以及无线多媒体应用的快速增长,使得移动通信流量爆发式增长,根据美国思科公司的思科视觉网络指数预测,到2022年全球移动数据流量将增长至2017年的3倍[1],这将给回程链路造成巨大压力.移动社交网络是一个承载在无线通信网络上的社交网络,不仅具有无线通信网络中的移动特性也具有社交网络的社会特性[2−3],基于其移动与社会特性,用户可通过相遇机会进行内容分享,从而减少从内容服务器中获取内容的次数,减轻回程链路压力,同时,在移动社交网络中,微基站通常被部署在靠近用户终端,具有较强的储存和计算能力,相比于距离较远的云,将内容缓存在微基站可减少内容传输延迟,提高用户体验质量.
然而,由于边缘节点(终端用户、微基站)的存储容量有限以及用户需求的多样化[4],使得边缘节点既不能缓存内容服务器中所有的内容,也不能在存储容量的限制下,随机缓存内容,因此缓存内容的选择对提高边缘缓存性能至关重要,同时,用户的移动性是移动社交网络中实现内容分享的重要特性,但也可能因为移动性使缓存用户和请求用户不在终端直接通信技术(D2D)通信范围内,最终导致内容分享失败,因此,为提高缓存命中率、减少传输时延,选择合适的缓存用户对提高边缘缓存性能至关重要.
综上所述,缓存内容选择以及缓存用户选择是提高网络性能、保证用户体验质量的关键问题.在文献中,这两个问题通常被独立的研究.对于缓存内容选择的问题,通常是选择流行的内容,为此需要对内容流行度进行预测,文献[5]使用聚类分析将内容划分为不同类型,利用自回归积分移动平均模型预测不同类型的内容流行度;文献[6]使用印度自助餐过程来分析内容选择问题,进而预测内容流行度;文献[7]基于用户的上下文,使用回声状态网络来预测用户的内容请求分布,进而预测出内容流行度.文献[5]~[7]虽然在一定程度上提升了网络性能,但都没有考虑缓存用户的选择问题.对于缓存用户选择的问题,文献[8]提出一种基于用户重要性的缓存策略,基于用户的物理属性与社会行为选择排名较高的用户来缓存内容;文献[9]提出一种分布式缓存用户选择方案,基于概率论模型来选择高速缓存用户,以防止内容的重传;文献[10]提出一种缓存用户选择方案,基于用户设备的剩余功率以及内容的最低传输功率来选择分数高的用户作为缓存用户.然而,文献[8]~[10]主要聚焦在缓存用户的选择问题,没有对内容流行度进行预测.目前,很少有文献将内容流行度的预测与缓存用户的选择结合在一起.
为此,本文提出一种用户属性感知的边缘缓存机制(User-aware edge caching mechanism, UAEC),为提高缓存命中率,减少传输时延,首先,考虑用户的偏好,预测出本地流行内容,并通过微基站将之协作缓存,同时根据用户偏好的变化将之实时更新,然后,为进一步减少传输时延,基于用户偏好构建兴趣社区,在每个兴趣社区中,考虑用户的缓存意愿及缓存能力选择合适的缓存用户缓存目标内容并分享给普通用户.
1 系统模型
考虑一个宏基站小区内的边缘缓存问题,如图1所示,该模型由内容服务器、宏基站、微基站和终端用户组成.内容服务器负责存储用户所需的所有内容F={f1,f2,···,fN},并假设每个内容的大小相同为d,宏基站负责管理整个小区内的缓存资源、计算资源和通信资源,为充分利用缓存资源,减少缓存冗余,微基站负责将本地流行内容协作缓存,并通过蜂窝链路发送到内容请求者,终端用户分为缓存用户和普通用户,普通用户可从缓存用户中获取所需内容,考虑到用户的自私性可能不愿意缓存其不感兴趣的内容,为此将具有相似内容请求偏好的用户划分为同一兴趣社区,如图1所示,具有相同颜色的终端用户处于同一兴趣社区,缓存用户只需缓存所处兴趣社区请求概率最高且自己感兴趣的内容集,当普通用户请求内容时,可通过D2D的方式进行内容分享.
假设用户与用户之间的平均传输时延为Td1,用户到微基站的平均传输时延为Td2,微基站到内容服务器的平均传输时延为Td3.则用户获取内容的平均传输时延T1为:
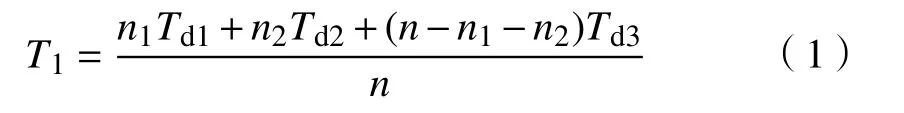
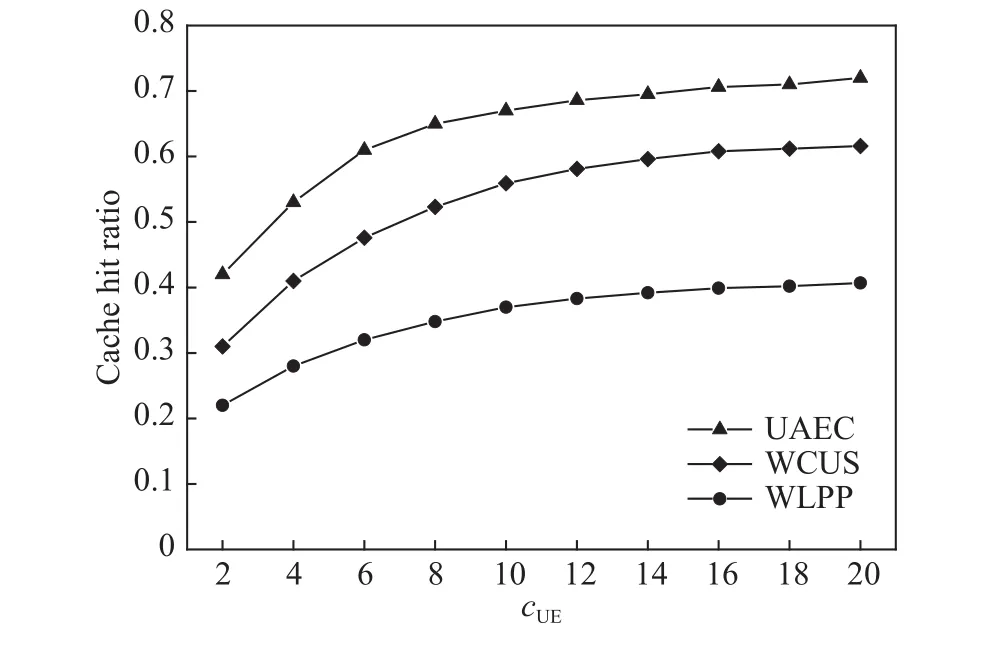
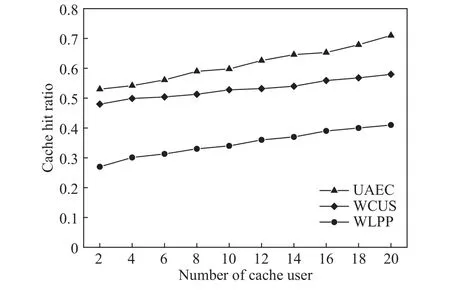
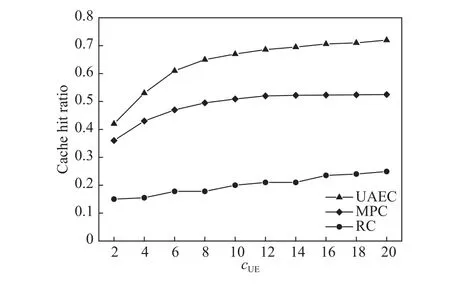
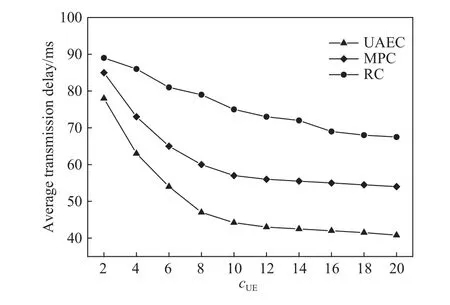
其中,Td1 图1 用户属性感知的边缘缓存模型Fig.1 User-aware edge-caching model 为减少传输时延,提高用户体验质量,从公式(1)可推出,需要尽可能将用户所需内容缓存,为此需要在有限的缓存容量下,提高微基站与缓存用户的缓存命中率.为提高缓存命中率,需要进行本地流行内容预测,以便将用户请求概率最高的内容集缓存,与此同时,考虑到D2D的传输距离以及用户的自私性,需要研究缓存用户的选择及其内容的缓存问题以保证用户所需内容的成功缓存与传递.因此本地流行内容与终端用户缓存策略对提高缓存命中率、减少传输时延、提高用户体验质量至关重要. 在传统的无线网络中,通常是各基站独立地缓存最流行的内容,但由于用户的兴趣不同,同一内容对不同用户有着不同的兴趣度,因此缓存最流行的内容不仅不能满足所有用户的偏好,还会存在缓存冗余,浪费缓存资源的现象.为满足用户偏好,提高缓存命中率,减少缓存冗余,本文从用户的角度出发,预测出本地流行内容,并将之协作缓存.本地流行内容预测分为内容请求概率预测、协作缓存、缓存内容更新. 本文使用隐语义模型来预测内容请求概率,基于用户的偏好,通过隐含特征将用户的兴趣和内容联系起来,从而获知用户对每类内容的兴趣度,进而预测出用户对所有内容的请求概率.不同于传统的人工分类,隐语义模型是基于用户的行为自动聚类,因此避免了人工分类的主观性,提高了预测精度. 在内容服务器处获取一段时间内用户的内容评分矩阵R,其矩阵值rufi表示用户u对 内容fi的评分,rufi∈[0,5].通过用户对内容的评分可推出用户对内容的请求概率,由于用户不可能对内容服务器中所有内容都评过分,因此矩阵是高度稀疏的.利用隐语义模型对矩阵进行填充,可预测出用户对所有内容的评分,最终预测出用户对所有内容的请求概率.假设内容服务器中内容的隐含特征有k类,基于内容在k类隐含特征中所占的权重,以及用户对k类隐含特征的兴趣度,可预测出用户对内容的评分 利用随机梯度下降法来最小化损失函数,随机梯度下降法是通过不断判断和选择当前目标下最优的路径,从而在最短路径下达到最优结果,因此,可通过对puk、qkfi两个参数求偏导,不断判断和选择损失函数最快的下降方向,puk和qkfi对应的偏导数求解如下: 不断修改puk,qkfi的值,使损失函数的值越来越小,直到收敛为止.最终使得矩阵P和 矩阵Q的乘积越逼近矩阵R.迭代更新公式如下: 式中,α是学习率,决定迭代下降的速率,取值范围为[0,1]. 宏基站较微基站有更大的覆盖区域,可以服务更多用户,但存在信号覆盖的盲区和弱区,微基站通常部署在靠近用户终端,虽然覆盖范围小,但适合小范围精确的覆盖可以弥补宏基站覆盖的不足,通过宏基站的协调将内容缓存在微基站可使用户就近获取缓存资源,减少时延,提高用户体验质量,但由于微基站的缓存容量有限,为充分利用缓存资源,减少缓存冗余,提高缓存内容多样性,增加缓存命中率,需要宏基站小区内的微基站协作缓存.从2.1节可得到宏基站小区内的终端用户对所有内容的请求概率 p rou,fi,将请求概率按降序排列,得到用户i未请求过的前n个内容假设宏基站小区内有m个终端用户,s={S1,S2,···,Ss}个微基站,每个微基站的缓存容量相同且为cSBS,每个微基站小区内有mSi个终端用户,且满足m=mS1+mS2+···+mSs.对微基站Si小区内所有用户未请求过的前n个内容求交集F1∩F2∩···∩=其中表示内容f1在微基站Si中将请求的次数,ni表示微基站覆盖范围内用户请求的内容总数,在微基站缓存容量的限制下其中a表示在每个微基站中能缓存的最大内容数量,得到微基站小区内请求数量最多的内容集,满足并将之缓存,在宏基站中储存了所管理微基站的缓存列表,宏基站协调微基站进行内容缓存,使之满足每个微基站内缓存的内容无重复使得缓存资源得到充分利用,并提高了缓存命中率.综合所有微基站缓存的内容即为本地流行内容Flocal= 考虑到用户的偏好可能随时间而不断变化,以及预测结果不完善造成某些请求概率较高的内容未被缓存的情况,因此需要及时更新缓存的本地流行内容. 内容的缓存可分为主动缓存和被动缓存.主动缓存是指通过预测内容的流行度,提前将流行的内容缓存,被动缓存是指根据内容的历史访问情况决定该内容是否被缓存.预测的内容流行度与实际内容流行度误差较小时,主动缓存可大大提高缓存效益,但若误差较大,缓存性能将不如被动缓存,被动缓存的缓存效益稳定,但存在较大的提升空间.为提高缓存性能,结合主动缓存与被动缓存的优点,本文将微基站分为两个缓存区:c1缓存区和c2缓存区,两缓存区的总存储容量为cSBS,两缓存区的大小可自适应调整.在c1区进行主动缓存,其内容缓存时间不超过一个有限时间Tcache,在c2区进行被动缓存,其内容缓存时间超过一个有限时间Tcache.内容缓存到微基站后,微基站实时记录每个用户的内容请求,并在一个时间段t(t 随着缓存以及D2D技术的发展,终端用户可以不依赖于基站就能直接进行内容分享,为进一步减少传输延迟,本文在这部分研究终端用户的缓存策略,分为兴趣社区划分、缓存用户确定、内容缓存. 考虑到用户的自私性可能不愿意缓存其不感兴趣的内容,因此需要将兴趣相似的用户划分为一个兴趣社区,使缓存用户只需为同一兴趣社区的用户缓存内容,这可以提高用户的缓存意愿.从2.1节可得到每个用户对隐含特征的兴趣度Pu={pu1,pu2,···,puk},使用欧式距离来衡量用户间的兴趣相似度,距离与相似度成反比,距离越近相似度越高. 其中,d ist(ui,uj)表示用户ui,uj之间的距离,表示用户ui,uj之间的兴趣相似度. 由于k-means++聚类算法具有对数据进行分析并自动聚类的特点,并且有效缓解了k-means聚类算法对初始中心选取不当而陷入局部最优的情形,因此,本文选用k-means++算法对用户进行聚类,进而形成兴趣社区.首先,随机选择一个用户作为第一个聚类中心 µ1,然后计算所有用户到 µ 1的距离,选择距离最大的用户作为第二个聚类中心µ2=argmaxj∈{2,··,m}dist(uj,u1),以此类推,选出K个聚类中心.然后,计算每个用户uj到K个聚类中心 µK的距离,用户uj将与自己最近的聚类中心 µK聚类进而形成兴趣社区Ck={j:K=arg mini∈{1,2,··,K}dist(ui,uj)},每个用户找到自己的兴趣社区后,再重新计算新的聚类中心,重复,直到聚类中心不再有变化或达到最大迭代次数. 在每个兴趣社区CK中,基于用户的缓存意愿以及缓存能力来确定缓存用户. 在移动社交网络中,用户的缓存意愿与用户间的社交关系密切相关,通过考虑缓存用户与普通用户间的信任度与社交相似度,来确定其缓存意愿.信任度是用来评估缓存用户是否愿意将内容分享给普通用户的信任程度.在一段时间内,假设用户ub从用户ua中成功获取内容的次数为Numub,ua,从所有用户中成功获取内容的次数为,则用户ub对ua的信任度为综合兴趣社区CK中所有用户对ua的信任度,即可得到用户ua的信任值,将用户的信任值范围限定到0到1之间,即可得到用户ua的信任概率 社交相似度是指用户社会背景(年龄、性别、职业等)的相似度,用户间的社交相似度越高,则用户为其缓存内容的意愿越强.设={Ia1,Ia2,···IaL}为用户ua的社交特征向量,其中L表示用户社交特征的数量,使用余弦相似度来衡量用户间的社交相似度 综合兴趣社区CK中所有用户与ua的社交相似度,即可得到用户ua的社交相似度将社交相似度范围限定到0到1之间,即可得到用户ua的社交概率 在移动社交网络中,由于用户的移动性,可能使两个用户不在D2D通信范围内,最终导致无法进行内容分享,因此,除了考虑用户的缓存意愿还需考虑用户的缓存能力,用户的缓存能力可用用户的交互相似度来衡量.交互相似度是由相遇平均间隔、相遇平均持续时间共同决定. 用户在一段时间内的相遇间隔越短,则分享内容的概率越大.若在时间段T内用户ua和用户ub第i次交互过程的起始时刻和终止时刻为和,交互次数为ninter,两个用户在时间段T内第i次和第i+1次的交互过程的时间间隔 ∆ti为,则在时间段T内,两个用户的相遇平均间隔为: 用户在一段时间内的相遇持续时间越长,内容分享成功的概率越高,若两个用户在时间段T内第i次交互的持续时间为,距离当前时刻近的交互过程更能准确反应用户间的交互关系,使用排序加权权重法[11]来得到时间段T内两个用户间的相遇平均持续时间为: 综合兴趣社区CK中所有用户与ua的交互相似度,即可得到用户ua的交互概率: 其中,mCK表示兴趣社区CK中用户的总数. 根据用户的缓存意愿和缓存能力,最终得到用户作为缓存用户的概率 最后,将兴趣社区CK中,用户的缓存概率按降序排列,选择缓存概率最高的前mUE个终端用户作为缓存用户. 考虑到用户的自私性以及有限的缓存资源,在确定缓存用户后,为提高缓存命中率、减小传输时延,需要为其分配合适的内容来缓存.从2.2节可得终端用户未请求内容中请求概率最高的内容集,综合兴趣社区CK中所有用户的内容请求概率,按请求次数降序排列,最终得到兴趣社区CK中请求概率最高的内容集将缓存用户请求概率最高的内容集Fi以及兴趣社区CK中请求概率最高的内容集求交集,将交集内容中请求次数最高的内容集发送给缓存用户使之缓存.缓存用户ui缓存的内容为: 本节在MATLAB平台下,对所提出的用户属性感知的边缘缓存机制(UAEC)的性能进行分析,仿真参数设置如下,考虑一个宏基站小区内的边缘缓存场景,由6个微基站和78个终端用户组成,采用INFOCOM2006 会议的实测数据[12]来分析终端用户的移动特性,采用GroupLens小组提供的MovieLens的数据集[13]来分析终端用户的偏好以及社会属性,隐语义模型使用的正则化系数 λ为0.11,学习率a为 0.1,隐含特征k为20,总的内容数量为1682,并假设内容服务器到终端用户的平均传输时延为98 ms,微基站到终端用户的平均传输时延为10 ms,终端用户到终端用户的平均传输时延为 3 ms,微基站的覆盖半径为 100 m,D2D 的通信距离为30 m,微基站和缓存用户的缓存容量的比例为 {cSBS,cUE}={30·cUE,cUE}. 为分析本地流行内容预测和缓存用户的选择对所提机制的性能影响,将所提机制(UAEC)与下面两种情况在缓存命中率方面进行对比,缓存命中率是指缓存的内容请求数占总的内容请求数的比例. 1)没有本地流行内容预测(Without local popular prediction,WLPP):不根据用户的偏好对本地流行内容进行预测,并假设内容流行度服从Zipf分布,其中β表示内容流行度偏度[14]. 2)没有缓存用户的选择(Without cache users selection,WCUS):不考虑终端用户的缓存意愿与缓存能力,而是以相同的概率来选择缓存用户. 由图2可知,随着缓存容量的增加,所提机制与其它两种情况的缓存命中率均呈现上升趋势,这是因为随着缓存容量的增加,在微基站和缓存用户中缓存的内容数增加,使更多用户的需求得到满足.而本文所提机制相比其他两种情况有更高的缓存命中率,这是因为由于用户的自私性,可能不愿意占用自己的缓存资源来缓存不感兴趣的内容,若让缓存用户缓存其不感兴趣的内容,可能造成内容丢弃,最终导致较低的缓存命中率,与此同时,若缓存用户与请求者不在D2D通信范围内,将不能进行内容分享,最终也导致较低的缓存命中率,而所提机制基于用户兴趣,构建兴趣社区,在每个兴趣社区中基于用户的缓存意愿以及缓存能力,对缓存用户进行选择进而提高缓存命中率.对于内容流行度,若考虑所有用户的内容流行度服从同一分布,也将造成较低的缓存命中率,这是因为内容流行度对不同用户是不一样的,为此,所提机制基于用户的偏好,来预测用户的内容流行度,从而提高了缓存命中率. 图2 不同缓存容量下的缓存命中率Fig.2 Cache hit ratio versus cache capacity 图3展示了缓存用户数对缓存命中率的影响,从图中可以看出,随着缓存用户数的增加,缓存命中率逐渐增加,这是因为内容总数不变的情况下,更多的缓存用户意味着有更多的缓存容量,因此可以为内容请求者缓存更多其感兴趣的内容.其中所提机制UAEC和WLPP机制比WCUS机制变化的更快,是因为这两种机制对缓存用户进行了选择,相比于WLPP机制和WCUS机制,本文所提机制实现更高的缓存性能,当缓存用户数为20时,比没有选择缓存用户和没有预测本地流行内容的情况,在缓存命中率方面分别提高了13%和30%. 图3 不同缓存用户数下的缓存命中率Fig.3 Cache hit ratio versus number of cache users 为证明本文所提机制的性能,将其与现存在的两种机制进行比较: 1)最流行内容缓存[15]( Most popular caching,MPC):在每个微基站和缓存用户中都缓存最流行的内容,且随机选择缓存用户. 2)随机缓存[16](Random caching,RC):微基站和缓存用户以相同的概率缓存所有内容,且随机选择缓存用户. 由图4可知,随着微基站和缓存用户缓存容量的增加,所提机制UAEC与其它两种机制MPC和RC的缓存命中率都逐渐增加,相比于其他两种机制,所提机制实现更好的性能,这是因为MPC机制,只考虑缓存最流行的内容,忽略了用户的偏好,不能满足部分用户的需求,同时,在微基站和缓存用户都缓存最流行内容,会造成缓存冗余,减少缓存内容多样性的现象,最终使缓存命中率较低,对于RC机制,没有考虑用户的偏好,随机缓存内容,因此有较低的缓存命中率,当缓存容量为20时,所提机制的缓存命中率比MPC机制和RC机制分别提高了19.5%和47%. 图4 不同机制中缓存命中率随着缓存容量的变化Fig.4 Cache hit ratio versus cache capacity in different mechanisms 图5展示了不同机制下缓存用户数对缓存命中率的影响,由图可知,随着缓存用户数的增加,三种机制的缓存命中率都逐渐增加,这是因为随着缓存用户数的增加使总的缓存容量增加,缓存用户可以缓存更多的内容来满足请求者的需求.其中所提机制比其他两种机制的缓存命中率更高,是因为所提机制基于用户的缓存意愿和缓存能力来选择合适的用户作为缓存用户,提高了请求者获取感兴趣内容的概率,因此有更高的缓存命中率,当缓存用户数为20时,所提机制的缓存命中率比MPC机制和RC机制分别提高了29.5%和40%. 图5 不同机制中缓存命中率随着缓存用户数变化Fig.5 Cache hit ratio versus number of cache users in different mechanisms 图6展示了不同机制下缓存容量对平均传输时延的影响,三种机制的平均传输时延随着缓存容量的增加而减小,其原因在于随着缓存容量增加使得缓存命中率增加,用户可以从微基站和缓存用户中更多的获取所需内容,减少了从用户到微基站及微基站到内容服务器间的传输时延,因此降低了平均传输时延.由图可知,本文所提机制比RC机制和MPC机制整体上有更低的平均传输延迟,是因为相比于其它两种机制本文所提机制针对用户的偏好,来进行内容缓存,同时考虑了用户的缓存意愿和缓存能力来选择缓存用户,增大用户从缓存用户获取内容的概率,因此有较低的平均传输时延. 图6 不同缓存容量下的平均传输时延比较Fig.6 Average transmission delay versus cache capacity 针对数据流量爆发式增长所引发的网络拥塞、用户体验质量恶化等问题,提出一种用户属性感知的边缘缓存机制.基于用户偏好预测出本地流行内容,通过微基站将之协作缓存,并根据用户偏好变化,将之实时更新.为进一步减少传输时延,基于用户偏好构建兴趣社区,在每个兴趣社区中基于用户的缓存意愿和缓存能力选择合适的缓存用户来缓存目标内容.结果表明,所提机制能够有效的提高缓存命中率,降低平均传输时延,提高用户体验质量.本文虽然考虑的是单个宏基站覆盖范围内的缓存方案,但对多个宏基站情况下,所提机制也同样适用,并且通过考虑宏基站间的协作缓存,可进一步减少传输时延,提高用户体验质量.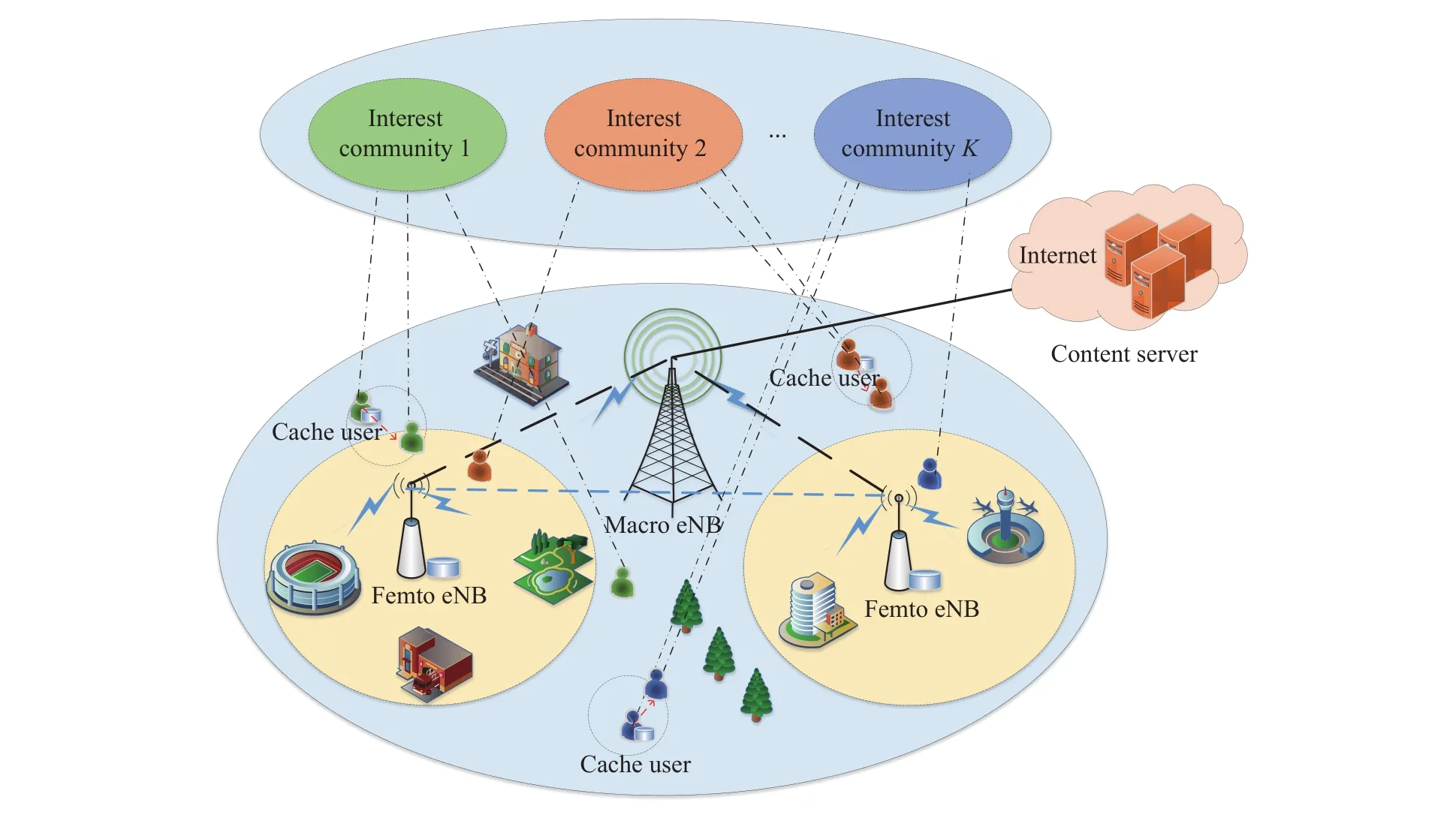
2 本地流行内容预测
2.1 内容请求概率预测
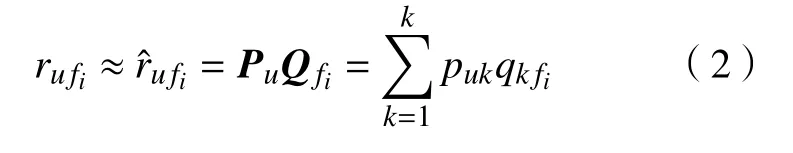
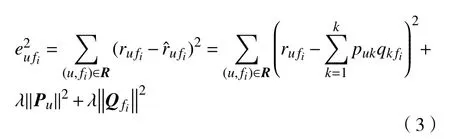
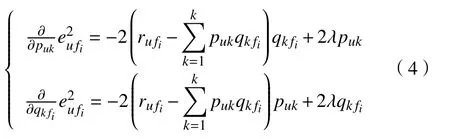

2.2 协作缓存
2.3 缓存内容更新
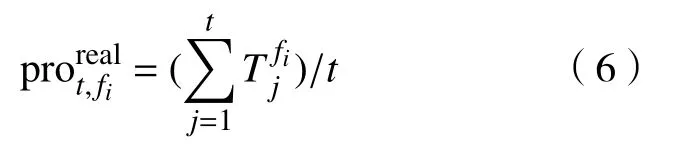
3 终端用户缓存策略
3.1 兴趣社区划分
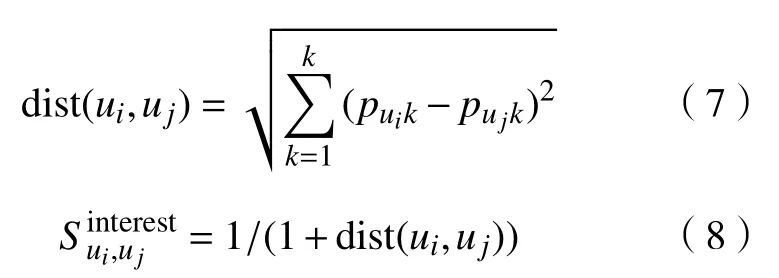
3.2 缓存用户确定

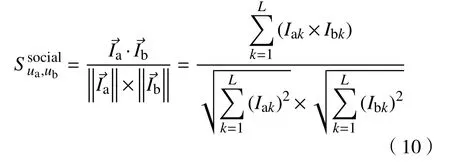
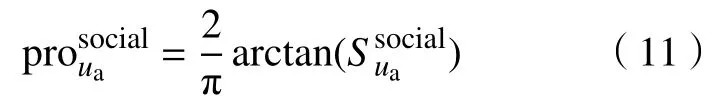
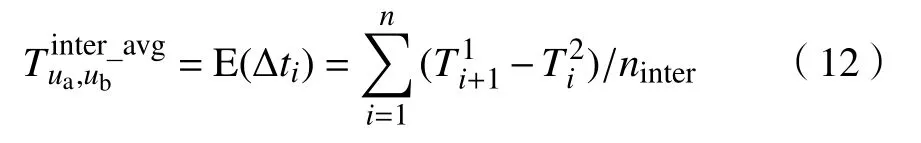
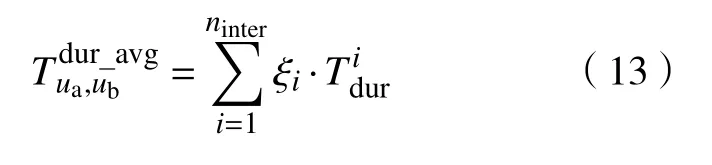
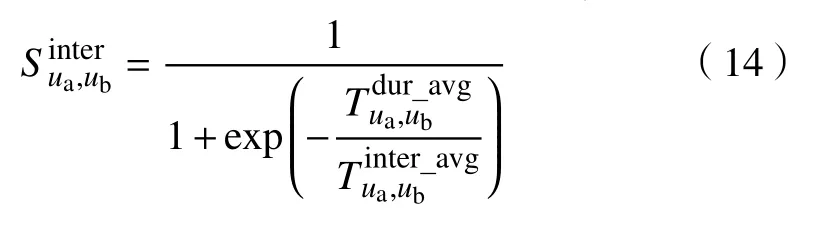
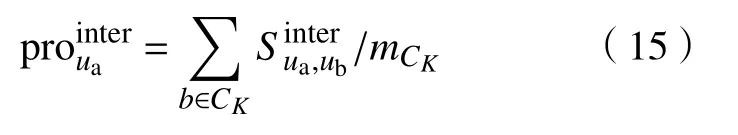
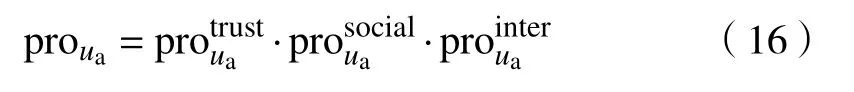
3.3 内容缓存
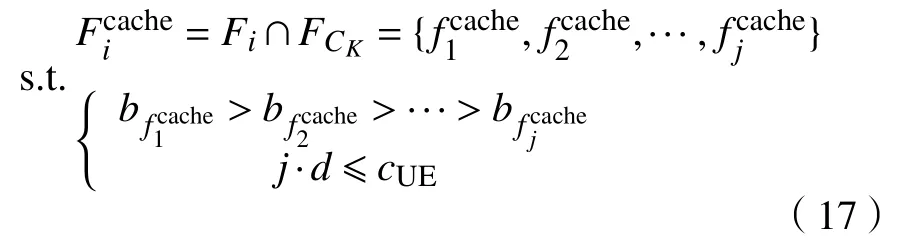
4 数值结果分析
4.1 性能分析
4.2 与其他机制的比较

5 结论
