基于特征优化的广告点击率预测模型研究
2020-08-04贺小娟郭新顺
贺小娟 郭新顺


摘要: 针对互聯网广告数据具有高维稀疏性的特点, 在现有的点击率(Click-Through Rate, CTR) 预测问题的相关理论和技术基础上, 给出了一种基于梯度提升决策树(Gradient Boosting Decision Tree, GBDT)的卷积神经网络(Convolutional Neural Networks, CNN) 在线广告特征提取模型(CNN Based on GBDT,CNN+). CNN+模型不仅能从原始数据中提取出深度高阶特征, 还能解决卷积神经网络在稀疏、高维特征中提取特征困难的问题. 在真实数据集上的实验结果表明, 与主成分分析(Principal Component Analysis,PCA) 和梯度提升决策树这两种特征提取方法相比, CNN+模型提取的特征更加有效.
关键词: 广告点击率预测; 梯度提升决策树; 卷积神经网络; 特征学习
中图分类号: TP391 文献标志码: A DOI: 10.3969/j.issn.1000-5641.201921007
0 引言
在线广告(Online Advertisement) 是随着互联网的诞生与发展而衍生出的一种广告形式, 即有广告发布需求的广告主通过具备广告发布能力的在线广告发布商, 将具有宣传其产品或服务的广告向互联网用户发布, 这些广告以图片、视频或文本链接等多种方式呈现在互联网用户面前[1]. 在线广告点击率(CTR) 预测[2] 是根据给定的用户点击广告的历史数据以及其他相关数据, 预测出用户点击广告的概率. 但是互联网中积累的大多数广告日志具有数据稀疏、特征维度大等特点, 这给如何使用模型高效地从数据中提取出有效信息以提高点击率预测的准确度带来了巨大的挑战.
随着数据挖掘、自然语言处理等技术的发展, 在广告点击率预测方面已经有了不少成熟的研究.逻辑回归(Logistic Regression, LR) 模型直接对用户是否点击广告的概率进行建模, 不但实现效率高,并且通过正则化的使用, 使模型对数据中的小噪声具有很好的鲁棒性, 是工业界最常使用的在线广告点击率预测模型. Matthew 等[3] 分别利用逻辑回归和MART 模型(Multiple Additive Regression Tress,多元可加回归树) 进行训练, 得到的实验结果表明逻辑回归的预测效果优于MART. 沈芳瑶等[4] 提出了一种基于在线最优化算法—FTRL (Follow the Regularized Leader) 求解的逻辑回归模型, 该方法采用L21 混合正则化, 在缩短参数计算时间的同时也有效降低了模型的对数损失. 但是逻辑回归模型的性能非常依赖参与训练的特征, 并且在稀疏数据中的表现能力也有限. 一个合适的自动特征提取模型是提高逻辑回归模型预测性能的有效工具.
为此, 李春红等[5] 提出了一种基于LASSO (Least Absolute Shrinkage and Selection Operator) 变量选择方法的广告点击率预测模型, 该模型通过剔除与预测无关的部分特征, 有效克服了广告数据高维性的问题, 并在一定程度上缓和了预测结果过拟合的问题. Ling 等[6] 介绍了阿里所使用的CGL(Coupled Group LASSO) 模型, 该模型使用Group LASSO 在用户特征和广告特征中进行正则化处理,避免了模型引入过于庞大的矩阵, 并减少了模型的参数. 然而, LASSO 变量选择方法只是简单地从原始特征中提取出那些对预测比较重要的特征, 选择出来的特征用于点击率的预测效果不佳. 为了实现特征之间的自动组合, He 等[7] 提出了使用梯度提升决策树(GBDT) 模型在原始特征中自动地进行特征组合和转换, 通过使用逻辑回归模型在转换后的特征上进行实验, 结果表明原始特征经过梯度提升树进行转换后能极大地提高预测模型的预测性能. 田嫦丽等[8] 在Spark 大数据分布式平台使用GBDT提取广告中的特征, 实验结果证明了GBDT 模型在分布式环境下同样有助于提高预测模型的准确率与性能. GBDT 在特征处理的过程中, 对每个特征进行单独处理, 不能学习到特征中的交互关系. LASSO变量选择方法和GBDT 这两种特征提取的方法虽然很容易实现, 但是由于它们都忽视了特征之间的相互关系, 往往不能取得良好的预测效果.
深度学习能够自动探索数据间的局部依赖关系并且可建立特征之间的密集表示, 使神经网络能够在原始数据中提取出高阶特征, 这种有效学习高阶隐含信息的能力也被应用到了CTR 预测中. 张志强等[9] 提出了基于张量分解的特征降维方法, 利用栈式自编码网络算法挖掘出特征之间存在的高度非线性关联关系. 杨长春等[10] 结合K-means 聚类算法以及张量分解对高维广告特征进行了降维处理,将降维后的数据利用深度置信网络(Deep Belief Network, DBN) 进行在线广告的点击率预测, 验证了模型的有效性. Cheng 等[11] 提出了Wide & Deep 模型: Wide 模型泛指传统的需要人工挑选特征的模型, 如逻辑回归模型; Deep 模型是指可自动进行特征转化的模型, 例如因子分解机模型; 将Wide 模型与Deep 模型进行组合, 就得到了Wide & Deep 模型.
传统的逻辑回归模型简单易实现, 但是需要配合使用有效的自动化特征方法. 互联网中存在的广告日志存在数据稀疏、特征维度大等问题, 使得特征之间的相互信息很难被挖掘, 提高广告点击率预测效果也存在很大的挑战. 但是大部分浅层的特征工程方法, 例如GBDT、LASSO 等, 由于没有考虑特征之间的内在联系, 导致提取出来的特征不能很好地表达出原始数据的内部关系, 并且模型的可扩展能力很弱. 针对这些问题, 本文在广告点击率预测问题的特征工程方面进行了深度特征学习的探索,提出了基于GBDT 模型的卷积神经网络(CNN) 特征提取模型CNN+, 该模型不但能有效学习广告特征之间的内在关系, 实现高阶特征的提取, 还能有效降低原始稀疏数据对卷积神经网络特征提取的影响, 减少内存占用的压力.
1 相关理论基礎
1.1 主成分分析方法
主成分分析(PCA) 是一种常见的特征降维手段, 基于变量的协方差矩阵从原始数据中提取出一组各个维度上线性无关的综合变量[12]. PCA 的基本原理是原始特征基于协方差矩阵变换成新的特征,新特征的总方差保持不变, 并且按照方差的顺序大小进行依次排列, 再根据主成分的方差总贡献率或主成分的特征值选择出最终的主成分个数. 使用PCA 进行特征提取能降低特征之间的冗余, 但是将数据从高维空间映射到低维空间会容易造成原始信息的丢失, 最终模型的预测性能可能会变差.
1.2 梯度提升决策树
用来预测点击率的数据往往存在高维性特点, 但是实际上并不是把所有的特征都用上得到的预测效果就会越好, 需要平衡好效果和效率的关系. 因此, 在点击率预测的过程中, 需要尽可能地获取与点击率精度高相关的特征, 以减少预测过程中时间和物力的代价. 常见的特征转换的方法有两种: 一种非线性转换方法,该方法是将特征合并, 将合并生成的新的索引视为新的分类特征; 第二种方法是构建元组输入特征, 对于分类变量, 通过使用笛卡尔积得到原始特征所有可能的取值, 然后删除对预测结果没有影响的组合. 而梯度提升决策树(GBDT) 就是实现以上两种特征转换方式的强有力的方法[7].
使用GBDT 进行特征转换的思想是, 将每个单独的树视为一个分类特征, 将每个变量最终落入的叶子的索引值作为值, 然后使用独热编码生成最终的新特征. GBDT 模型采用集成学习的思想, 具有非常好的非线性拟合能力, 能很好地挖掘出数据中的低阶信息; 但是对训练数据中没有出现特征的学习能力差, 并且没有利用特征之间的相互信息.
1.3 逻辑回归模型
逻辑回归(LR) 模型通过Sigmoid 函数引入非线性因素, 将线性回归模型产生的预测值转换成位于(0,1) 之间的概率值, 正好对应用户点击广告的概率; 而且LR 模型求解简单,可解释性强,对数据中小噪声的鲁棒性很好, 是工业界使用最多的广告点击率预测模型[13]. 对于给定的输入变量, 二项LR 模型使用Sigmoid 替代函数将线性回归产生的预测值转换成事件的概率分布为
1.4 卷积神经网络
卷积神经网络(CNN) 是近年来深度学习领域研究应用最广泛的模型之一, 一般由数据输入层、卷积层、激励层、池化层和全连接层组成, 其中数据输入层与机器学习模型中的数据预处理方法相同[14]. 使用CNN 提取高阶特征的原理是: 首先, 卷积层采用局部感知和参数共享机制, 通过卷积运算可以学习到特征域中大小不同的模式; 然后, 通过池化层的池化运算可以对特征域进行缩放, 因此可以从数据中自动地提取出有效的特征, 并且构造出数据的深度高阶特征[15]. 使用CNN 进行特征提取的优势有两点: 一是可以从数据中自动地提取出有效的特征, 挖掘出特征之间的相关关系, 这主要依赖于CNN 的局部感知和权值共享机制, 使提取的新特征在很好地表达出原始数据特性的同时还能挖掘出数据中的隐含关系; 二是通过池化层随机丢弃一些不重要的特征, 使最终的特征提取模型对那些没有在训练数据中出现过的数据, 模型也能很好地学习.
目前CNN 提取特征多应用于图像领域, 使用CNN 进行广告高阶特征提取的研究相对较少. 主要是因为广告数据存在大量的分类特征, 如果直接对这些特征进行标签编码处理,会使处理后的数据丧失表达原始数据的能力; 如果直接使用独热编码对特征进行处理,会使数据特征维度爆炸、模型参数过多而影响预测的效率, 并给设备造成压力.
2 基于GBDT 的CNN 模型CNN+
本文利用GBDT 与CNN 模型相融合的思想, 一方面来源于He 等[7] 使用梯度提升树解决了LR的人工提取特征的问题, 并且他们也从各个角度验证了GBDT 在稀疏数据和多值分类特征中提取的有效性; 另一方面来源于已被验证的CNN 在提取高阶特征方面的强大能力, 但是面对多值类别特征时CNN 的特征提取能力有限, 在训练网络的过程中要求很大的内存资源以及计算机强大的运算力.
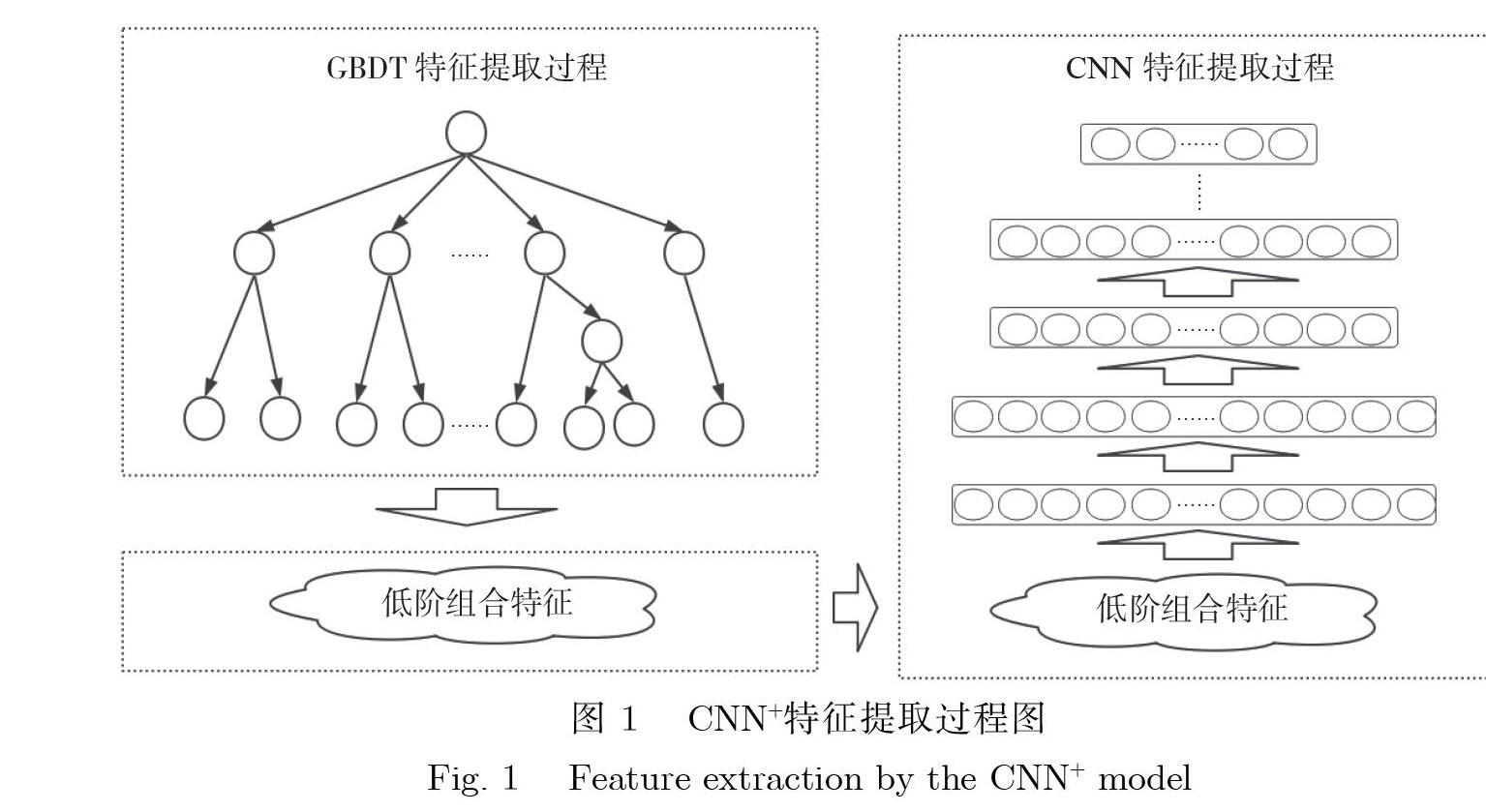
使用CNN+-LR 模型进行广告特征提取和广告点击率预测的大致过程: 首先使用GBDT 挖掘出广告日志中低阶的特征以及特征组合, 将原始的稀疏数据和多值分类特征进行有效的预处理; 然后利用CNN 强大的特征提取能力在低阶特征中进一步提取高阶特征; 最后使用原始的LR 模型对在线广告的点击率进行预测. CNN+的特征提取过程如图1 所示.
3 算法测试与实验结果分析
3.1 数据说明
本文实验数据来源于DataCastle 竞赛中“2018 科大讯飞AI 营销算法大赛”的数据集, 即来自真实的公司环境. 广告数据主要分为4 大类: 基本数据、广告信息、媒体信息、上下文信息. 数据的类别分布和字段标签如表1 所示. 对于所给定的数据, 通过统计得到的样本总数为1 001 650 条, 其中用户点击广告的样本数占总样本数的19.8%.
实验结果分析如下.
(1) 3 种方法提取的特征较原始特征在点击率预测问题中都表现出了一定的相对优势. 和原始LR 模型相比, PCA-LR 虽然在AAUC 和LLog_loss 的取值上没有明显优势, 但是最终选择的主成分个数比原始特征要少, 从而降低了预测模型的复杂度, 提高了预测效率; GBDT-LR 和CNN+-LR 两种模型与原始LR 模型相比得到的AAUC 至少提高了3%, LLog_loss 降低了2%, 这充分说明了使用GBDT 和CNN+模型提取特征的有效性.
(2) CNN+-LR 模型的AAUC 和LLog_loss 均优于GBDT-LR 模型, 其AAUC 提高了2.0%, LLog_loss降低了0.94%. 分析原因: 两种方法都是用GBDT 在预处理后的原始数据中提取特征; 使用LR 模型预测用户是否点击广告, 二者的区别在于,CNN+-LR 模型在初步提取的数据中再次使用了CNN 进行深度特征学习, CNN 能够挖掘出特征之间更深层的规律, 并且得益于池化层的池化运算, 提取的特征经过CNN+后可扩展性更强.
4 结论
本文針对互联网广告数据具有高维稀疏性、人工提取深度高阶特征费时费力等特点, 研究实现了基于GBDT 的CNN 在线广告特征提取模型CNN+. 通过与主成分分析、梯度提升树两种不同的特征方法进行的对比实验, 证明了CNN+在广告特征提取上的效果更佳. CNN+模型不但能从原始数据中自动提取出深度高阶特征, 减少人工特征工程的人力和物力, 同时还通过梯度提升树模型在多值分类特征中提取组合特征的优势, 解决了CNN 在稀疏、高维特征中提取特征困难的问题.
[ 参 考 文 献]
[ 1 ] 高驰, 卢志茂. 在线广告发展态势与特性分析 [J]. 哈尔滨工业大学学报(社会科学版), 2003, 5(2): 122-125.
[ 2 ] 周傲英, 周敏奇, 宫学庆. 计算广告: 以数据为核心的Web综合应用 [J]. 计算机学报, 2011, 34(10): 1805-1819.
[ 3 ]RICHARDSON M, DOMINOWSKA E, RAGNO R. Predicting clicks: Estimating the click-through rate for new ads [C]// Proceedingsof the 16th International Conference on World Wide Web. ACM, 2007: 521-530.
[ 4 ] 沈方瑶, 戴国骏, 代成雷, 等. 基于特征关联模型的广告点击率预测 [J]. 清华大学学报(自然科学版), 2018, 58(4): 374-379.
[ 5 ] 李春红, 吴英, 覃朝勇. 基于LASSO变量选择方法的网络广告点击率预测模型研究 [J]. 数理统计与管理, 2016, 35(5): 803-809.
[ 6 ]YAN L, LI W J, XUE G R, et al. Coupled group lasso for Web-scale CTR prediction in display advertising [J]. Proceedings ofMachine Learning Research, 2014, 32(2): 802-810.
[ 7 ]HE X R, PAN J F, JIN O, et al. Practical lessons from predicting clicks on ads at Facebook [C]// Proceedings of the 8th InternationalWorkshop on Data Mining for Online Advertising, ADKDD 2014. ACM, 2014: 5:1-5:9.
[ 8 ] 魏晓航, 于重重, 田嫦丽, 等. 大数据平台下的互联网广告点击率预估模型 [J]. 计算机工程与设计, 2017, 38(9): 2504-2508.
[ 9 ]张志强, 周永, 谢晓芹, 等. 基于特征学习的广告点击率预估技术研究 [J]. 计算机学报, 2016, 39(4): 780-794. DOI: 10.11897/SP.J.1016.2016.00780.
[10] 杨长春, 梅佳俊, 吴云, 等. 基于特征降维和DBN的广告点击率预测 [J]. 计算机工程与设计, 2018, 39(12): 3700-3704.
[11]CHENG H T, KOC L, HARMSEN J, et al. Wide & deep learning for recommender systems [C]// DLRS 2016: Proceedings of the 1stWorkshop on Deep Learning for Recommender Systems. ACM, 2016: 7-10. DOI: 10.1145/2988450.2988454.
[12]ABDI H, WILLIAMS L. Principal component analysis [J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(4): 433-459. DOI: 10.1002/wics.101.
[13]肖垚, 毕军芳, 韩易, 等. 在线广告中点击率预测研究 [J]. 华东师范大学学报(自然科学版), 2017(5): 80-86. DOI: 10.3969/j.issn.1000-5641.2017.05.008.
[14]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]//NIPS12:Proceedings of the 25th International Conference on Neural Information Processing Systems- Volume 1. New York:Curran Associates Inc., 2012: 1097-1105.
[15]MA L, LU Z D, SHANG L F, et al. Multimodal convolutional neural networks for matching image and sentence [C]// 2015 IEEEInternational Conference on Computer Vision (ICCV). IEEE, 2015: 2623-2631. DOI: 10.1109/ICCV.2015.301.
[16]LOBO J M, JIM?NEZ-VALVERDE A, REAL R. AUC: A misleading measure of the performance of predictive distribution models[J]. Global Ecology and Biogeography, 2008, 17(2): 145-151. DOI: 10.1111/j.1466-8238.2007.00358.x.
(责任编辑: 李 艺)
