基于杂交链式反应工序问题的DNA计算模型
2020-08-03殷志祥杨新木
杨 静, 殷志祥, 唐 震, 杨新木
(1.安徽理工大学 数学与大数据学院, 安徽 淮南 232001; 2.香港大学 教育学院, 香港 999077; 3.上海工程技术大学 数理与统计学院, 上海 201620)
DNA计算作为仿生计算的一员历经25年的发展,DNA纳米结构已经成为构建纳米材料的主力军.DNA全称脱氧核糖核酸,作为生命的主要遗传物质,它包含A、T、C、G四种碱基,并且按照Watson-Crick互补原则进行信息编码.Adelman[1]1994年首次利用DNA分子计算给出了具有7个顶点图的哈密顿路的求解方法,之后在众多科研人员的努力下,DNA计算从一维结构到二维结构再到三维结构[2-5],在NP问题中起到越来越重要的作用.2006年Rothemund[6]提出了一种新的DNA纳米自组装技术——DNA折纸术.通过DNA折纸术, Rothemund得到了三角形、方形、矩形、五角星和笑脸等精细复杂的二维结构.DNA折纸术是由大量DNA短链作为固定链,将一条含有7 000多个碱基的噬菌体单链DNA origami折叠成任意纳米级的几何图形,所得的图案称为DNA origami.每条短链都具有有序特异性,故被称为订图钉链.它使得DNA折纸术具有精确的可寻址性.DNA折纸术具有设计简单、组装效率较高、纳米可编程和纳米可寻址的优势.随后2006年钱璐璐等[7]利用DNA折纸术构建了纳米级的中国地图.晁洁课题组利用DNA折纸术作为基底给出了有向图的最短哈密顿路[8],之后采用DNA纳米折纸结构编码无向图的顶点,借助纳米结构之间的粘性末端进行自组装,给出了图着色问题的解决方案[9],在2019年又利用DNA折纸术结合杂交链式反应给出了迷宫问题的求解[10].2017年,Tikhomirov等[11]利用方形DNA折纸作为基本单元,以递归方式进行多次自组装,得到了微米级蒙娜丽莎的图案.这些成果都展示了DNA折纸术在NP问题求解中显示出其参与计算的优势.文献[12]给出利用噬菌体制备DNA折纸所需的DNA链,为DNA折纸术的应用和产量提供了保障.
杂交链式反应(Hybridization Chain Reaction,HCR)是一个无酶参与的反应过程.它通过设计合理的不同寡核苷酸,由一小段核苷酸链作为引发剂,诱导寡核苷酸相互杂交形成一条具有二维或三维空间结构的双链DNA[13-14].它是利用启动链诱发两种不同类型发夹结构的DNA分子交替杂交,交替打开发夹结构,形成带有缺口的双链DNA聚合物,且此过程无需酶参与,反应条件温和,操作简单,可适用于其他传感器的信号放大.目前,杂交链式反应已经广泛应用于核酸、蛋白质检测和生物传感器等领域[15-20].2012年,Dong等[21]利用结合HCR与G-quadruplex构建了一种免标记检测目标DNA的荧光传感器,目标DNA存在时,目标DNA作为引发链打开两个发夹探针与其杂交,进行杂交链式反应形成长双链,释放出G-quadruplex结构,加入锌卟啉(ZnPPIX)后,荧光强度增强.体系前后荧光强度的变化可以检测目标DNA.Xiao等[22]通过将DNA微阵列与邻近结合诱导的杂交链反应扩增整合,设计多重化学发光成像,并用于蛋白质生物标记物的灵敏筛选检测.Zou等[23]提出利用杂交链式反应和DNA三链组装的无标记点亮荧光传感器的方法.由于该方法具有操作简单和成本较低等优点,在生物标志物测定、临床诊断和生物医学检测中有很高的应用价值.2019年,Chao等[10]利用杂交链式反应提出单分子DNA导航仪(DNA navigator).自此,杂交链反应结合荧光检测给NP问题求解也带来了生机.
1 工序问题的计算模型
1.1 工序问题
工序问题是生产过程时间组织的一个重要问题,是如何将多种不同零件(工件),安排到相应的设备上并决定它们的加工顺序,以利于充分地利用设备和缩短生产周期,从而提高工作效率的问题.它是图论中的一个问题,到目前为止还没有有效的方法.这里介绍多种工件在一台机器上的生产排序问题.
例如,在某工厂中,设某台机器必须加工多种工件J1,J2,…,Jn,每一种工件Ji可以是一类模具.在一种工件加工完毕之后,为了加工下一种工件,机器必须调整.如果从工件Ji到工件Jj的调整时间是tij(表1),求这些工件的一个排序,使整个机器的调整时间最少.这个问题其实就是求一个权和最小的有向哈密顿路,到目前还没有有效解法.本文把工序问题先转化为一个有向图G,每种工件Ji在G中即为图的顶点.
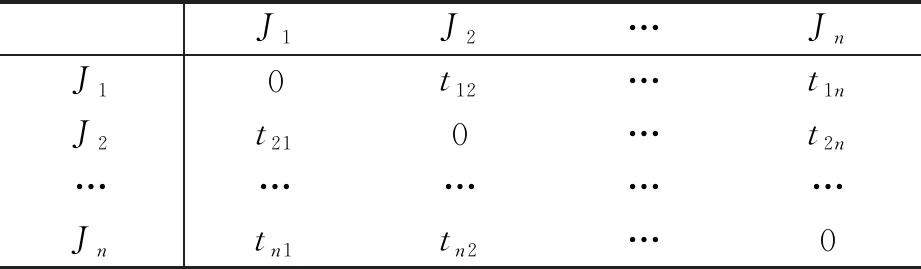
表1 从工件Ji到工件Jj的调整时间表
(1)以有向图G的顶点Ji表示工件Ji(i=1,2,…,n).
(2)以E表示有向图G的所有弧集,(Ji,Jj)∈E.
(3)给(vi,vj)赋权tij.
这样一个工序问题就和一个求赋权有向图的权与最小的有向哈密顿路对应,该有向哈密顿路对应图的顶点顺序即为各工件的加工次序.
1.2 基本算法
步骤1:搜索出工序问题所对应图G的所有有向途径;
步骤2:保留那些经过G所有顶点的有向途径;
步骤3:保留最短的有向途径;
步骤4:确定出有向途径所经过图的顶点次序,进而求出工序问题的解.
1.3 实例模型
假设一台机器可以生产5种工件J1,J2,…,J5,在加工完Ji后需要调整机器才能加工Jj,调整时间需要tij(i=1,2,…,5,j=1,2,…,5).将工件之间的调整关系抽象为图1,用调整矩阵的形式给出工件之间的调整时间(tij)5×5(表2).问题是如何寻求一种工件加工顺序使得所需总的调整时间最短,加工效率最高.
忻州的硬件条件不是最好的,但整个工作得到了老同志的普遍认可,工作成效非常好,可以说工作做的是最好的。忻州的思路和做法,是贫困地区做好老干部工作的一个贡献和一种引导。
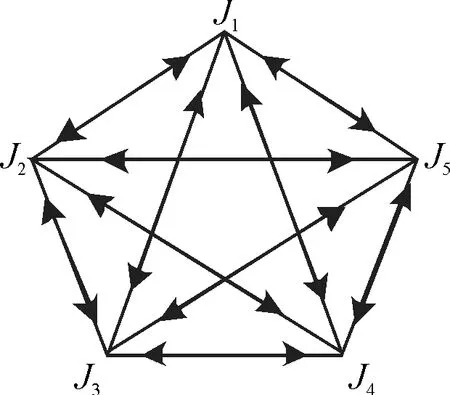
图1 5种工件的双向图GFig.1 Bidirectional graph G of 5 kinds of workpiece

表2 工件的调整矩阵
为求解5种工件工序问题的解,首先将其问题的解空间映射为树T(图2).不失一般性,假设从J1开始加工,下一个加工的对象就是J2,J3,J4,J5中的一种,以此类推.在树中两顶点间的距离就表示从工件Ji到工件Jj的调整时间tij,也即这是有向赋权树T,那么问题的解就是从根节点开始到叶子的所有有向路径中寻求权值最小的有向路径.
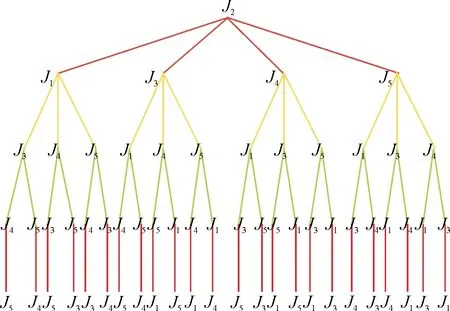
图2 解空间映射为树TFig.2 Solution space mapped to the tree T
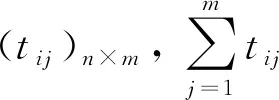
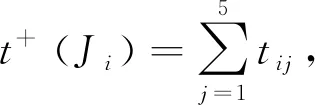
在利用此模型进行求解前,先介绍此模型的组成.模型主要由三部分构成:折纸基底、DNA锚定链和辅助链.
1.3.1 折纸基底
用大量订图钉链将环形噬菌体(M13mp18)折叠成二维矩形作为折纸基底(图3).

图3 DNA折纸基底Fig.3 DNA origami base
一般选择分子信标作为锚定链.具有发夹结构的分子信标一般包括两个部分:①环状区,长度是15~30碱基的序列,能与目标靶序列特异结合;②茎干区,长度是8个碱基的互补序列.分子信标具有结构简单、特异性强及可荧光标记等特点.所以,DNA锚定链的制备就选择具有这些特性的分子信标.
将带有发夹结构的DNA链与带有粘性末端的订图钉链结合,将其锚定在DNA折纸基底上,排列成图4的等价形式.这些链包含顶点Ji(图5),两个顶点之间的距离用来表示从工件Ji到工件Jj的调整时间(权值)tij.根据问题中权值的具体大小选取代表单位时间的权值(单位权值),一个单位权值用一个DNA锚定链表示.单位权值记为unit weight,它是由4个寡聚核苷酸片断组成3′-b*-t-b-a-5′,其中b和b*互补,在b*的末端标记上荧光基团,在b的末端标记上猝灭基团.这里单位权值的定义适用于权值之间差别较小的图,若是权值之间相差太大,此方法就不适用.作为根节点的工件J2是由4个寡聚核苷酸片断组成3′-b*-cJi-b-j2-5′,其余4种工件也是由4个寡聚核苷酸片断组成3′-b*-cJi-b-a-5′,环部用来表示节点的区分.
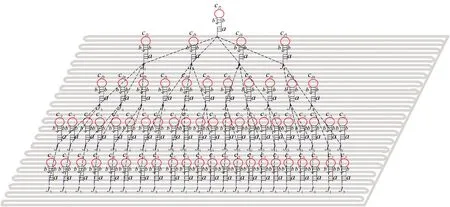
图4 折纸基底上有向树Fig.4 Directed tree on origami base
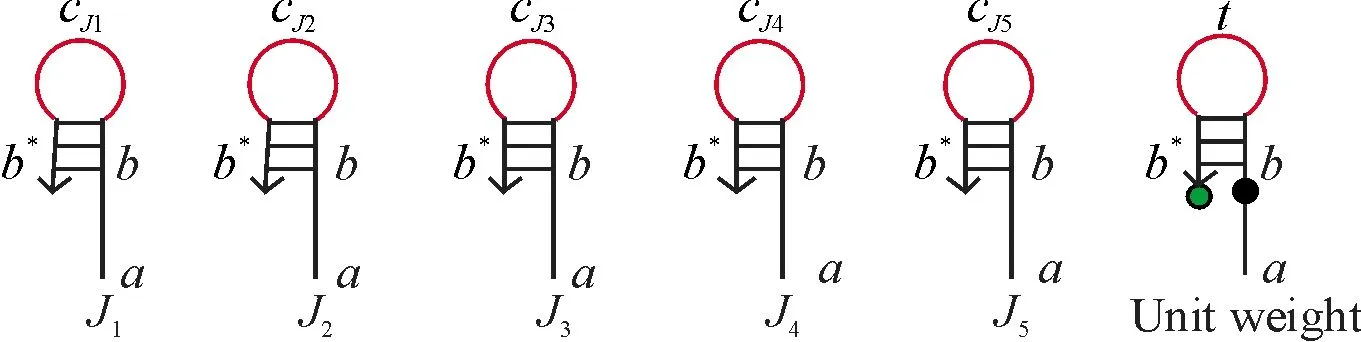
图5 5种工件对应的DNA链和表示单位权值带有荧光标记的DNA链
1.3.3 辅助链
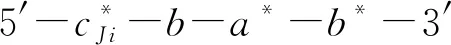
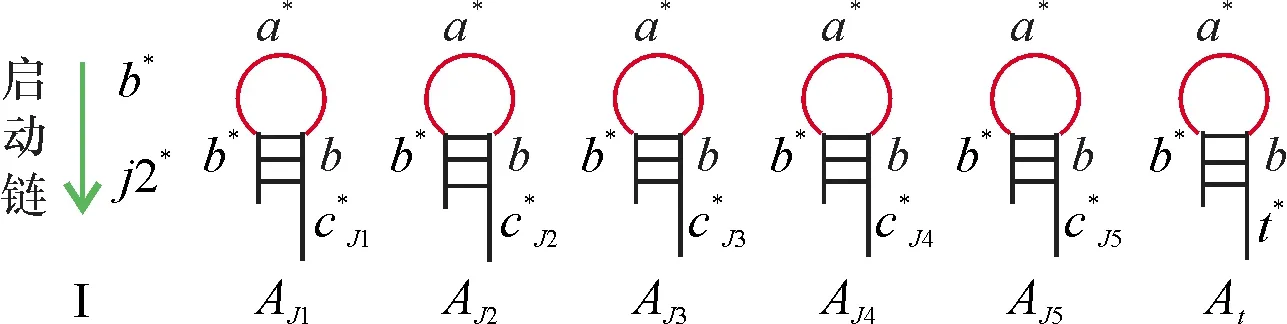
图6 启动连和辅助链Fig.6 The startup chain and auxiliary chains
2 工序问题的模型求解
利用模型求解工序问题解的原理:根据节点的个数和权重建立求解模型,将问题映射为有向树,利用订书钉链将锚定链按有向树的结构锚定在折纸基底上(图4).整个折纸基底在试管中大量稳定存在,不发生反应.当加入足量的启动链I后(启动链I示意图见图6),启动链与根节点中的茎杆部和环部是互补的,根节点的发夹结构打开,反应开始.辅助链在试管中大量存在,杂交链式反应继续.根据生化反应的特点,有向反应发生在哪条路径上是随机的.在选择的有向路上充分反应后,可以利用荧光光谱仪检测到这条路上发出荧光的个数,从而得到这条有向路径上的权值大小即调整时间之和.在这些所有可能的有向路径中,只要找到荧光个数最小的有向路径(调整时间之和最小)就是工序问题的最优解.
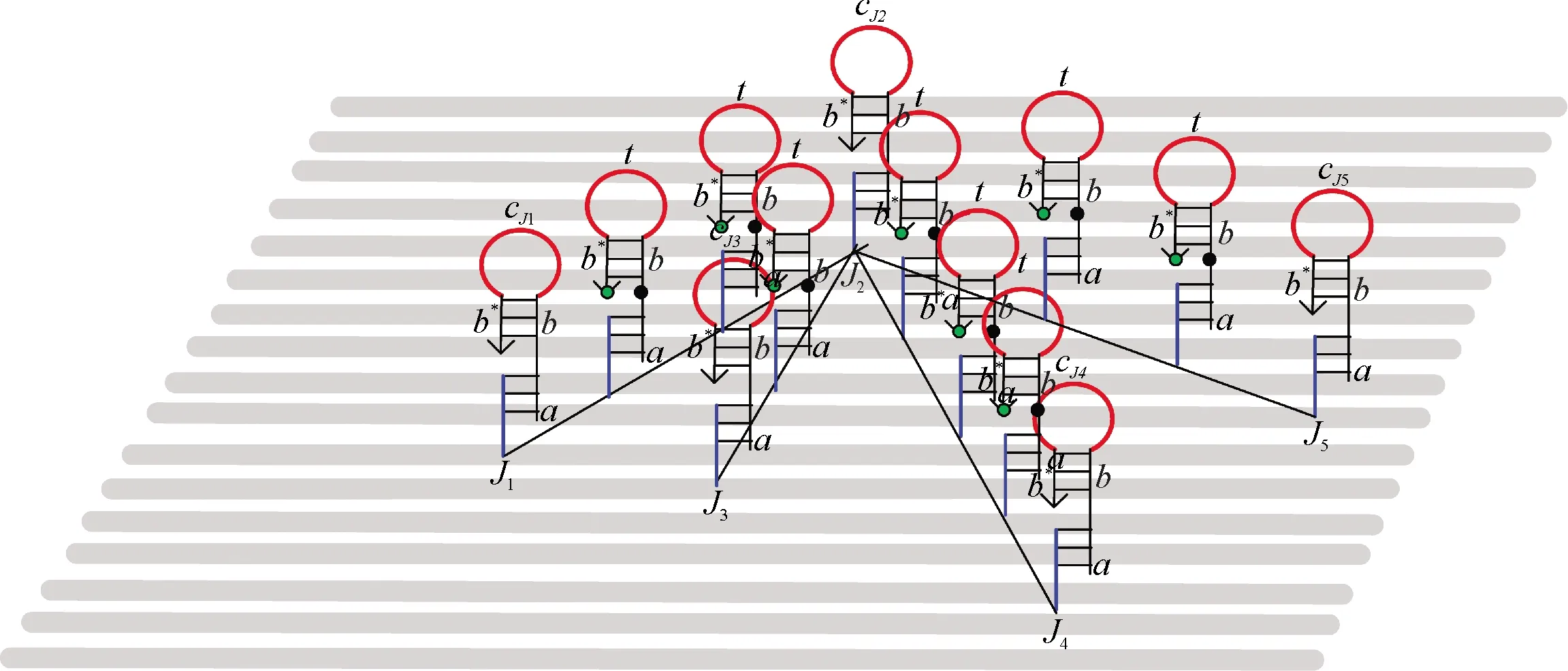
图7 折纸基底上J2→Jj权值的表示Fig.7 The representation of J2→Jj weights on origami base
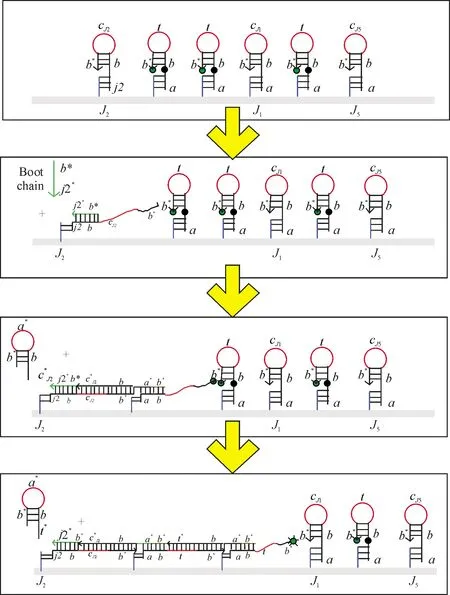
图8 J2→J1的反应示意图Fig.8 The reaction scheme of J2→J1
试管中也大量存在着辅助链At,反应继续,表示权值的第二个发夹结构也被打开,同时检测到荧光.此时辅助链第二个At中的a*-b*与AJ1中的a-b互补,继续反应将AJ1发夹结构打开,反应直到节点J5反应结束,此时可检测到荧光个数为8.在其他路径上的反应类似.通过荧光的个数最后得到问题的最优解就是J2→J3→J4→J5→J1,荧光个数为5(图9).
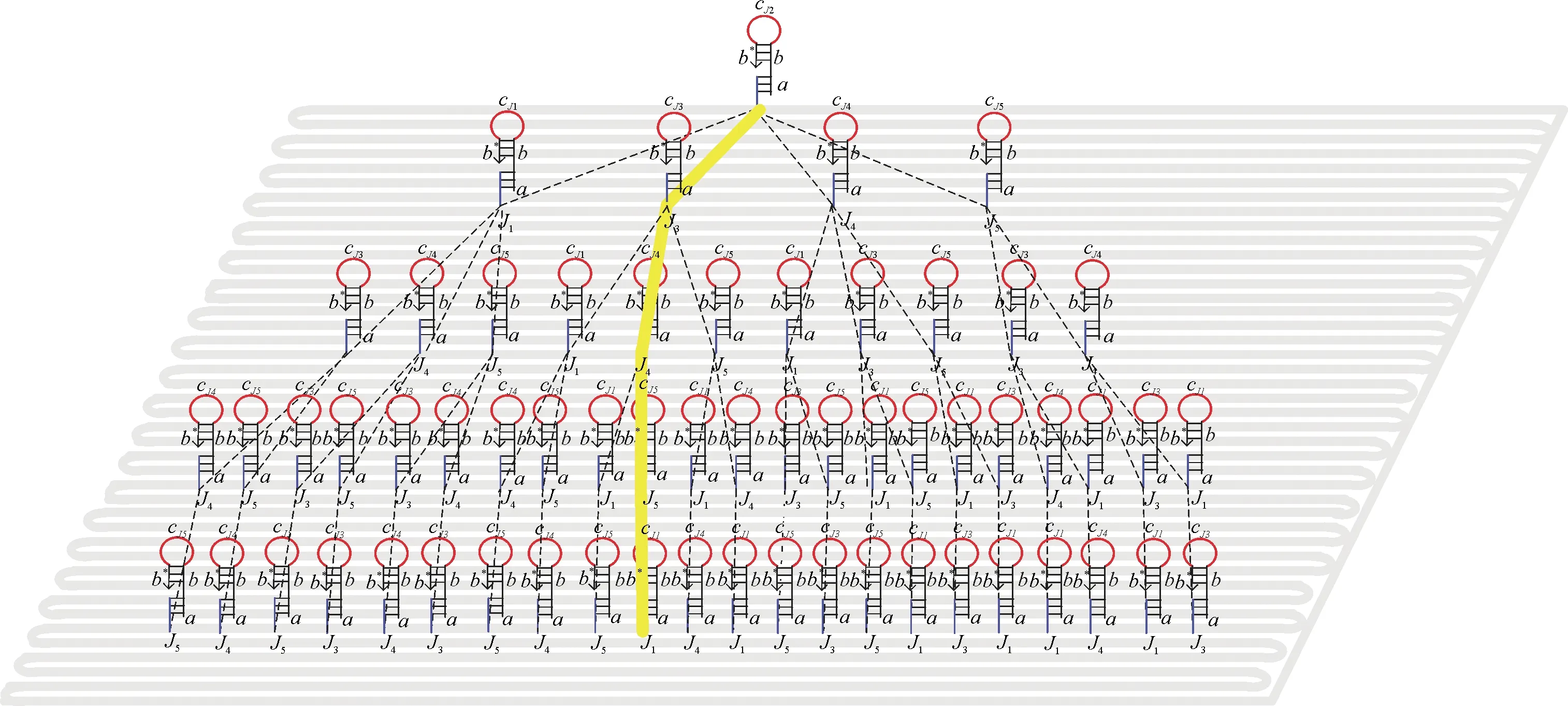
图9 有向树中的最优解Fig.9 The optimal solution in the directed tree
3 实例仿真
Visual DSD是常用的DNA杂交链式反应的仿真软件.软件的界面由三部分组成:编码区、设置区和显示区.编码区给出参与反应的DNA序列组成、浓度及反应时间的设定;设置区进行语法模式及仿真模式的设定;显示区显示DNA序列随反应进行变化的曲线、产物的结构等.启动链为input、折纸基底Origami、辅助链At及其他辅助链的浓度分别设定为20 nM、20 nM、100 nM和20 nM,反应时间设定为7 000 s.随着启动链input的加入,诱导杂交反应开始,辅助链AJ2最先与启动链input反应,在图10中,AJ2较其他辅助链的浓度先呈下降趋势,随着反应的进行,辅助链的消耗顺序也是以J2→J1→J3→J4→J5这个顺序依次下降.反应继续进行,中间产物的浓度先增加,达到最大峰值后,浓度逐渐减小,最终趋于0,最终产物sp26则趋于稳定.这些中间产物分别对应于从根节点到子节点的有向路,当反应完成后,生成根节点到叶的有向路时,中间产物的浓度趋于0.在图10中可以看到,当启动链加入后,中间产物sp9的浓度最先达到峰值为6.1 nM,这个中间产物就启动链I与根节点AJ2反应的生成物,随着反应的继续,它的浓度也最终趋于0.最终产物sp26表示的J2→J1→J3→J4→J5有向路,它随着反应的继续浓度不断增加.充分反应后,浓度趋于稳定.图11给出了J2→J1、J2→J1→J3、J2→J1→J3→J4的中间生成物的链式结构.

图11 J2→J1,J2→J1→J3,J2→J1→J3→J4的中间产物的链式结构Fig.11 Chain structures of intermediate products of J2→J1,J2→J1→J3,J2→J1→J3→J4
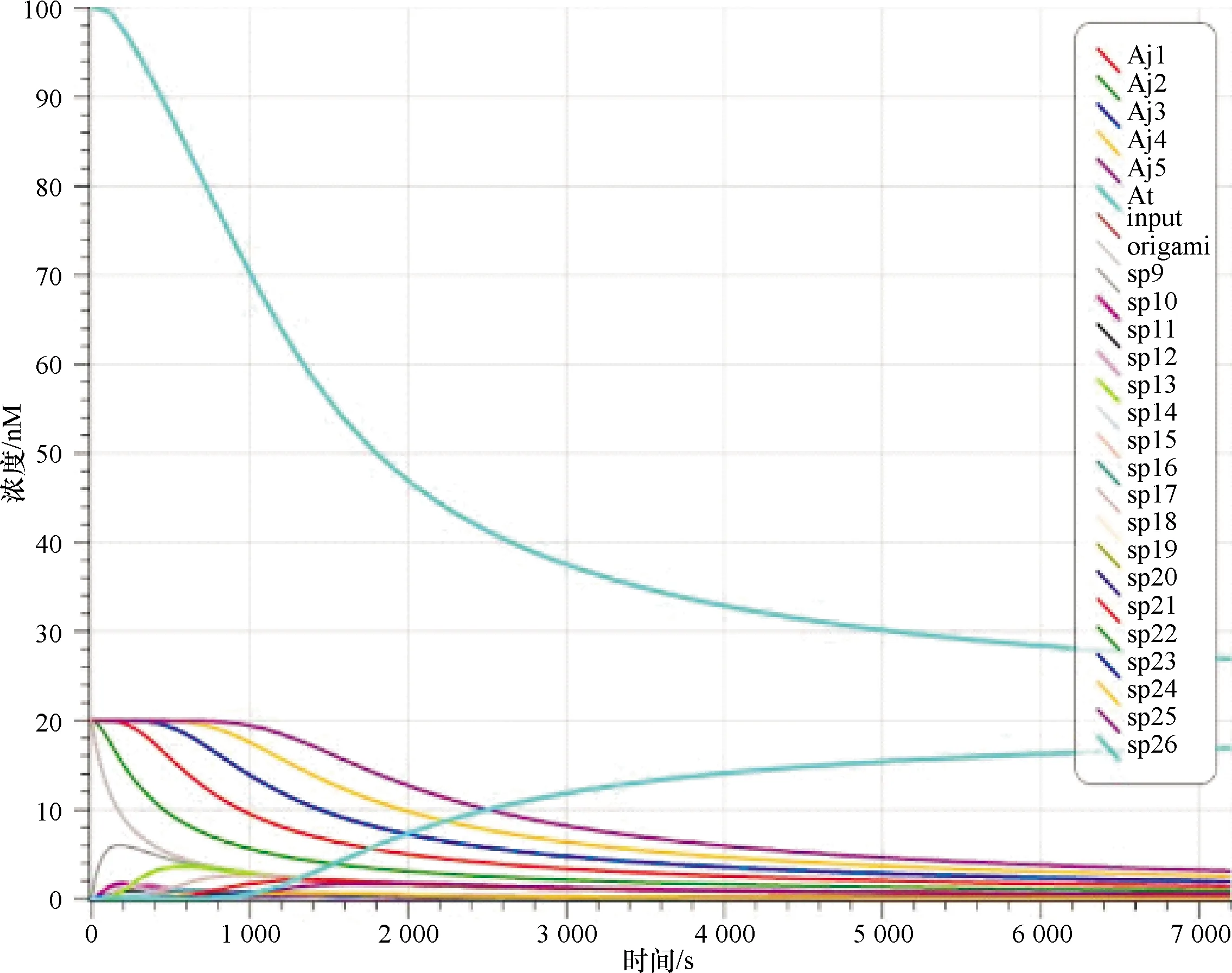
图10 解J2→J1→J3→J4→J5的模拟结果Fig.10 The simulation results of solutionJ2→J1→J3→J4→J5
文中只针对J2→J1→J3→J4→J5有向路径进行了仿真,其他路径的仿真是类似的,这里就不一一列举了.最终通过各路径上荧光个数的判定能够得出工序问题的最优解是J2→J3→J4→J5→J1.
利用此模型求解工序问题,在很大程度上降低了问题的复杂度.Brun在文献[24]中指出自组装模型的复杂度计算理论,应从两方面来考虑此模型的复杂度:计算时间复杂度以及该模型所需参与计算的分子结构的种类.该模型是利用杂交链式反应,将求解过程映射到折纸基底上进行.由引理知,该模型的自组装时间与反应(树)的深度有关,即Tim(T)=Θ(depth(T)).而所参与杂交自组装的分子结构主要是表示工件的分子信标n种,表示单位权值的分子信标1种,表示辅助链的分子信标n+1种和启动链1种,所以此模型计算时所需的分子结构的种类为Num(T)=n+n+1+1=Θ(n).利用自组装反应的优势,得到该模型的复杂度为Tim(T)+Num(T)=Θ(depth(T))+Θ(n).
4 结 论
本文针对工序问题给出了一种基于杂交链式反应的求解方法.将工序问题映射为有向树,待加工的工件映射为节点,选出t+(Ji)最小的节点作为根节点.然后将有向树锚定在矩形的折纸基底上,利用杂交链式反应来求解问题的最优解.此模型在试管中进行,只有加入了启动链以后,反应才可进行.继续反应,当发夹结构打开后,反应是不可逆的.因此,最终生成的都是以根节点为起点,以叶子为终点的路径.而且该模型中的发夹结构只在环部进行区分,设计简单.模型用荧光光谱仪连续记录荧光信号的个数来确定每条有向路径的权值,从而寻找最优解,模型中解的检测也非常简便.与传统的计算模型相比,通过生物分子计算将问题的求解过程以生化反应过程展现出来,该模型充分利用了它高度的并行性和可靠性.
