智慧水务中新型自然语义数据可视化方法探索
2020-08-02桑玉坤
李 航,林 劼,高 菱,桑玉坤
(1.成都市河湖保护和智慧水务中心,610072,成都;2.电子科技大学,611731,成都)
关键字:语义解析;数据可视化;智慧水务;水务大数据
一、研究背景
1.智慧水务数据可视化现状与问题
近年,成都市紧密结合建设“智慧城市” 要求推进智慧水务建设,将智慧水务建设与锦江水生态治理智慧项目整合推进, 以城市大脑为基础,通过若干控制性重点水务信息化项目建设,整合和完善现有信息系统功能,全面接入以“六水”(即水资源、水安全、水净化、水生态、水管理、水文化)为代表的各业务功能,打造全域的泛在感知系统,全量汇聚水务数据,强化数据挖掘在山洪预测、管网优化、 水资源调度等领域的应用,建立统一物联感知平台、统一数据支撑平台和统一应用服务平台。
由于整合的各项信息系统存在大量、繁杂的水务数据,如何甄别其中的价值信息并进行可视化展示,从而实现更高效的管理,成为摆在水务工作者面前的一大问题,促使新型智慧水务数据可视化概念的提出。 在大数据架构基础之上,通过对水务大数据进行可视化,可以让管理者、决策者更高效地了解水务生态环境的重要信息和细节层次,从而进行有效的决策判断。 现有的水务大数据可视化系统主要依托商业智能报表可视化作为数据可视化核心技术,在需要对某时空、项目的数据统计、查看时,需要专业程序员操作,花费的人工和时间较多。
成都市河长制管理信息系统是成都市智慧水务架构的重要组成部分, 该系统前期采用传统商业智能报表可视化技术为数据展现方式。商业智能报表可视化技术以数据为驱动元素, 联动业务支撑与业务数据展现。 其数据展现过程主要分为两种模式。
①组合型展示模式: 预先构建不同的数据模型, 每个数据模型对应一个可视化单元(如曲线图、饼图等),最后多个可视化单元组装成可视化页面, 实现数据的综合性展示呈现。
②预定报表型展示模式:该模式下可视化页面预先定义。 用户通过对预先设定的查询条件进行选择组合,形成查询组合,系统根据查询组合构建对应的数据模型,最终形成的查询结果以可视化形式进行呈现。
如上所描述,当每次产生新数据展现需求时,该系统都需要经过人工定制查询代码、数据模型、展示组件,最终导出数据文件并展现这一繁琐过程。 虽然系统可以达到数据可视化效果, 但无论是组合型展示模式还是预定报表型展示方式, 由于其预定和固定数据模型的缺点, 相关业务人员很难真正进行有效数据发掘, 从而灵活便捷地获取到想要的数据信息。
目前已有的水务大数据可视化方案, 均存在以下问题: ①依然采用数据模型预先固定或查询条件预先限制的静态数据模型模式,缺乏数据模型的动态构建性,无法满足数据探索分析中数据模型的可变性要求; ②需要预先定制开发可视化方案,且定制复杂费时,定制的可视化方案难于扩展来满足快速变化的数据探索需求; ③无法做到很好的人机交互性, 只是对定制的数据展示进行机械性的执行和呈现,系统无法理解使用者的数据展现意图和思想。
2.语义型数据可视化方案的提出
针对如何寻求智慧水务中真正智慧数据可视化方案的问题, 本文探索了一种结合语义解释能力、知识理解能力和动态数据建模能力为一体的智慧水务数据可视化技术。技术框架如图1 所示, 其通过对用户的数据探索语言进行自然语义理解,获知用户的数据探索意图,并结合水务系统数据知识, 形成数据模型理解, 进一步动态构建数据模型实现数据的语义型探索, 最后再将探索到的数据以灵活的可视化方式进行呈现。 该方案实现了人类语义和水务数据语义二维语义相结合的新型智慧水务可视化过程, 不仅可以减轻在水务数据探索过程中纷繁复杂的人工定制可视化操作, 也能为水务行业相关人员提供更灵活、准确、可无限扩展、以意图为导向的数据展示服务。
二、语义型水务数据可视化整体方案

图1 语义型水务数据可视化整体方案流程
语义型水务数据可视化方案如图1 所示,系统对用户输入的任意一个数据探索语言都通过以下三个关键步骤完成从自然语言到水务数据查询可视化转变:①自然语义理解过程。 该模块主要对用户输入的数据探索语言进行自然语言解析。 具体步骤包括语言分词、依存关系分析、时间解析、数字解析。 该模块的目的是通过语义解析将自然语言转换为对应的数据语言。 ②知识映射过程。 该模块实现了数据语言到数据模型的映射。 包括表名解析、列名解析、查询条件解析和结合Type-Aware 技术的数据模型生成。③数据可视化过程。该模块采用传统商业智能数据可视化展现技术, 基于WEB 的数据可视化组件(如条形图、多维数据可视化组件、饼图等)作为数据可视化单元,根据生成的数据模型所获取到的查询结果,通过可视化技术进行数据展现。
本节首先对整体方案流程中关键技术及其实现进行了描述,然后给出了智慧水务语义型可视化系统的分层框架结构。
1.自然语义理解过程
(1)语言分词
汉语处理的第一个步骤是做语言分词。 语言分词是指将完整的一句话根据其语义分拣成一个词语项集, 该词语项集作为后续语义分析的基本单元。 根据分词策略不同,语言分词共有基于词典的算法、 基于统计的算法和前两者结合的算法三种方法。
语义型水务数据可视化方案中需要添加很多特殊专业词汇,因此分词策略可采用结合词典与统计的方法。 在建立词典的基础之上,再根据词频来进行语言分词。 经典的词典匹配分词方法包括正向匹配算法、逆向匹配算法、双向匹配算法、最大匹配算法和最小匹配算法。
系统采用双向匹配算法为基准分词方法,以“2013 年成都地区河流的污染率信息展示”为例,经过语言分词后的分词序列为 “2013 年-t,成都-ns,地区-n,河流-u,污染率-n,信息-n,展示-v”。其中,t 为时间词,ns 为地名词,n 为名词,u 为助词,v 为动词。
(2)时间解析
在查询语句中需要对时间描述部分做特殊的语义解释,并将其解释为标准化的时间格式,例如“前年”需要解释为“2018/01/01—2018/12/31”的时间格。 因为时间表达格式相对稳定,比较主流的解释方法是基于规则的方法, 即通过人工或自动化的方法来总结语法规律, 最终将这些规律转化为计算机可以理解的形式,如正则表达式。
具体做法:首先通过一定方式构建时间触发词词典,如从训练语料或人为经验中总结出触发词词典,然后根据触发词周围的修饰词以及前缀和后缀等成分来构建时间缀词词典,最后通过触发词和缀词的组合来识别时间表达式。 以 “2019 年3 月4日”的解释为例,其中“年”“月”“日”是触发词, 然后再根据触发词前缀“2019”“3”“4” 等成分即可将该时间描述解释为标准化时间格式“2019/03/04”。 通过以上时间解析过程可以将查询语句中所的时间描述统一成标准格式,以待后续数据模型构建。
(3)依存关系分析与数值解析
数值解析主要用于确定数据模型中出现的数值情况。 在查询语句中,例如“成都市各地区排污口总量小于80 的地区有哪些”,需要对数值型描述(如“小于80”)判断其归属列名,形成查询条件。 依存关系分析可以将查询语句词与词之间的关系转化为语义依存描述, 如动宾关系、主谓关系、定中关系、并列关系等。 在依存关系中,所有受支配成分都以某种依存关系从属于支配者。 因此本系统采用依存关系来分析解释数值描述的列归属关系, 例如本例中数值80就归属为排污口总量。
在语义水务可视化系统中,主要运用主谓关系和动宾关系来发掘数值和对应列的从属关系。 图2 即是语句“成都市各地区排污口总量小于80的地区有哪些”的依存关系展示。 结合依存关系分析与数值解析就可以确定数据模型中与数值有关的查询条件,如“大于”“小于”等情况。
2.知识映射过程
(1)水务知识库构建过程
知识映射技术需要依托于水务知识库中的知识,将自然语义理解过程获得的数据语言映射为数据模型。语义型水务数据可视化方案中的水务知识库主要由3 个知识体构成,分别是元数据结构知识、维度—列信息知识和表名知识。 元数据结构知识包括数据库中表及其字段列信息、表与表之间列的映射关系(如外键关系)。
维度—列信息知识主要包括维度表具体列值与作为外键被引用列的映射关系。 以成都地区表为例,建立“都江堰”“青白江”“锦江”等具体地区名与其在表中的字段/列的映射,当查询语句出现 “都江堰”“青白江”“锦江” 等词时即可得知其在数据模型查询条件中对应的列/字段名,从而构建查询条件。
表名知识包括实体表表名、表中列名及列的类型、时间维度对应的列名、维度列和非维度列等知识。 其中维度列表明该列与一个维度表的列相对应(如外键关系),非维度列则表明该列与其他表中的列无任何关系。表1 展示的是表名知识的具体结构。
(2)表名解析、列名解析、查询条件解析
数据模型生成的第一步是识别表名和对应的查询列名来填充数据模型中的查询项。 表名解析用于获得数据模型中的表名,它主要根据前面所述分词过程获得的分词序列和知识库中的表名知识匹配来映射表名。具体来说将分词集合中的所有名词在表名知识库中进行模糊匹配,如果与表名知识中的一个表名相匹配,则可获得要查询的表名。
列名解析用于获得数据模型要查询的列名,其根据分词过程获得的分词序列和表名解析过程获得的表名,进一步通过表名知识结构进行解析。 对分词中的所有名词使用模糊查询来与已经解析到的表名所在的表名知识结构进行匹配, 如果匹配成功,则认为解析到了列名。
查询条件解析用于获得数据模型中的查询条件。 根据前面的时间解析、 数值解析和维度—列信息知识,可以对应获得查询的时间信息以及对应列的数值信息和查询值。
(3)Type-Aware 数据模型构建技术

图2 依存关系分析
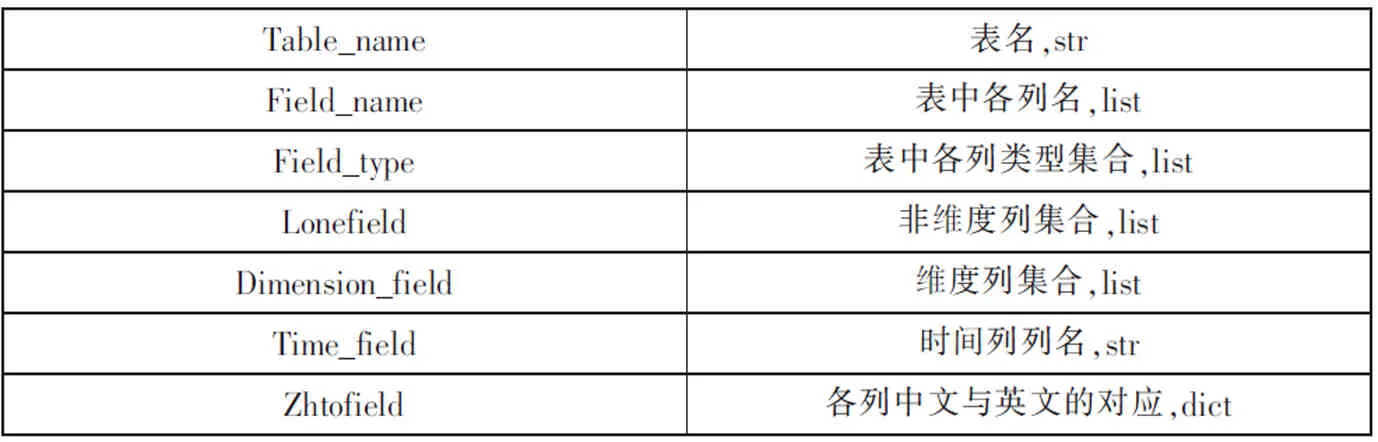
表1 表名知识结构

表2 输入查询语句与生成的数据模型之间的对照关系
自然语言中对数据模型中聚合函 数、GROUP BY、HAVING、ORDER BY 等查询模块的解析方法称为Type-Aware 技术目前典型的Type-Aware 技术采用深度学习端到端的框架, 通过语言嵌入和多类分类器判别查询结构。 采用论文和论文的Type-Aware 模式实现了聚合函数、GROUP BY、HAVING、ORDER BY等模块的识别, 并根据识别结果组织数据模型生成树, 完成了数据模型中查询结构部分的构建。 结合前面表名、 列名和查询条件等解析结果,即可得到一个完整的数据模型。
3.系统架构
在智慧水务系统中,语义型可视化系统架构共分为三层,分别是数据知识库层、引擎层和接口层。 ①数据知识库层主要用来构建元数据知识,包括元数据结构信息库、维度—列信息库和表名信息库。 ②引擎层主要包含语义型水务数据可视化方案中的关键功能引擎, 包括自然语义理解引擎、 知识映射引擎和可视化报表引擎。 ③对外接口层主要用来提供对外服务,包括查询服务、可视化服务、自然语言处理服务、元数据抽取服务。
三、系统效果展示
以成都市排污口统计数据为例演示本文所提出的语义数据可视化系统的数据模型构建与可视化效果。
例如,当用户通过语音识别方式或手动输入查询语句为“去年成都市各个地区的排污口总量信息,并根据排污口类型、年度排污量、许可登记、布局合理来区分”时,最后生成的数据模型以及与输入语句两者之间的对照关系见表2 所示。
表2 的输入查询语句经过语义解析与知识映射过程共生成5 个数据模型。 其分别对应查询语句中的“排污口总量信息”“排污口类型”“年度排污量”“许可登记”“布局合理”五个查询要求。 从生成的数据模型中可以看到 “去年”被解析为“2018”年,以及用模糊查询的方式来处理“成都市各个地区”的情况(在数据库中,成都各地区location_id 以‘20’开头)。而数据模型中的具体列名信息则根据构建的元数据知识推断得出。
系统根据生成的数据模型进行数据查询,并将结果数据以图表结合的形式在平台上进行可视化数据展现,形成自然语义型的数据可视化交互。 例如,排污口统计数据结果以表格形式在平台上进行展现,实现将查询所在地区编号及名称、排污口总量信息、排污口类型(企业工厂、市政生活、雨污合流、混合污水)、年度排污量(超标和未超标)、许可登记(已登记和未登记)和布局合理(合理和不合理)等信息的展示。 为了给用户更直观的数据展示,在数据表格展现的基础之上, 配合以饼图的形式展示“排污口类型”“年度排污量”“许可登记”“布局合理”四个维度中子类型的所占比重。
以上即是针对成都市排污口统计数据的一次查询与可视化效果展示示例,可以看到在达到传统可视化展示效果的同时,语义型可视化方式无需绑定固定的数据模型,因而具有灵活性、准确性和易于扩展性。
四、结 语
本文分析了现有水务大数据可视化系统中存在的问题,以自然语义和数据语义理解融合为出发点,研究了一种以自然语言对话交互方式取代传统规则条件查询生成方式的水务数据可视化展现新技术。 该技术尝试了数据可视化展现技术的对话式和交互式,实现了水务多维数据的一句话智能可视化展现,解决了现今水务大数据平台中简单交互式图表数据可视化方式存在的缺乏数据智能理解能力、固化图表缺乏数据灵活组合展现能力、定制度高、变更开发复杂度高的关键问题。 ■
