基于指标体系违约鉴别能力最大的小企业债信评级体系及实证
2020-07-22于善丽迟国泰
于善丽,迟国泰,姜 欣
(1.大连理工大学经济管理学院,辽宁 大连 116024;2.中国人民银行金融研究所博士后科研流动站,北京 100800;3.银行间市场清算所股份有限公司,上海 200002)
1 引言
小企业的债信评级事关重大。一是小企业占企业总数多。例如中国小企业占企业总数的76%以上[1],全球小企业数量占企业的95%以上[2]。二是小企业提供了大量的就业机会。例如,中国小企业提供了70%的就业机会[1],全球小企业提供了50%以上的就业机会[2]。小企业已经成为经济发展的重要组成和缓解社会就业压力的重要力量。然而,融资难已经成为影响小企业发展的瓶颈。而造成小企业融资难的主要原因之一是小企业贷款数据获取极难,甚至一些银行都没有足够的小企业贷款样本,导致至今没有一套行之有效的、针对小企业特点的债信评级体系,银行因而囿于贷款风险管控问题,对小企业贷款惜贷甚至不贷。
因此,急需建立一套行之有效的小企业债信评级体系,一是帮助银行等金融机构鉴别小企业信用风险,为小企业贷款决策提供依据。二是帮助银行等金融机构测算贷款违约风险参数,为小企业贷款定价提供依据。三是帮助小企业缓解融资难问题。
债信评级体系的构建中,通过违约鉴别能力遴选一个又一个的单个指标固然不错,但是一个又一个的单个指标好,指标体系不一定好,单个违约鉴别力强的指标组成的体系违约鉴别力不一定也强,而对债信评级而言,指标体系整体的违约鉴别力更重要。前者根据单个指标的违约鉴别力构建债信评级体系很难,后者根据指标体系整体的违约鉴别力构建债信评级体系更难。
现有国内外关于小企业债信评级研究主要集中在以下三个方面。
在指标体系建立方面,赵志冲和迟国泰[3]利用相关分析删除信息冗余指标,通过Logistic回归的似然比检验保留对违约状态影响显著的单个指标,组成了信用评级指标体系。Kruppa等[4]通过随机森林方法和最近邻方法建立了信用评级指标体系。Mileris[5]使用因子分析与Probit模型建立了信用评级指标体系。Nandi和Choudhary[6]运用典型多元判别分析方法建立了信用评级指标体系。Niklis等[7]运用线性支持向量机和非线性支持向量机方法构建了信用评级体系。沈沛龙和周浩[8]基于支持向量机理论建立了中小企业信用评价体系。Tsai和Hung[9]基于神经网络集成方法和混合神经网络方法建立了信用评价体系。
在指标赋权方面,迟国泰和陈洪海[10]通过指标的信息敏感性占全部指标信息敏感性的比例进行指标的赋权。Ono 等[11]运用倾向得分匹配法对指标进行赋权,建立了日本小企业信用评分模型。于亮等[12]研究了基于灰色类别差异特性的评价指标客观权重极大熵配置模型。Chen Yibing等[13]通过对不同行业系统性风险分析,运用熵权法对行业进行赋权,建立信用评价模型。
在信用等级划分方面,石宝峰等[14]按照信用等级越高,违约损失率越低标准,将商户小额贷款划分为9个信用等级。Lyra等[15]研究了门槛值接受法(TA)在基于违约概率的最优等级划分方法中的运用,并提出了基于每个级别的实际违约数量的新型计算方法。Zhi Hongyan 和 Yang Zhongyan[16]根据各信用等级人数近似服从正态分布的特征,将200个企业划分为9个信用等级。张洪祥和毛志忠[17]采用灰色关联分析方法和模糊聚类方法,将客户划分为8个信用等级。
现有研究多未以指标体系整体违约鉴别力最大为标准构建评级指标体系,而指标体系整体的违约鉴别能力对信用评级更重要。因此本文通过对比删除一个指标前后的两个指标体系的违约鉴别力b值,遴选指标体系违约鉴别能力b最大,而不是单个指标违约鉴别能力最大的指标体系,构建了基于指标体系整体违约鉴别力最强的小企业债信评级体系。
2 债信评级体系构建的原理
2.1 债信评级体系构建的原则
原则一:债信评级体系整体应具有显著的违约鉴别能力。单个指标违约鉴别力强,组成的评级体系违约鉴别能力不一定也强。指标再流行、评级体系再完整,若评级体系整体不具有显著的违约鉴别力,也是不合理的。
应该指出,本研究以指标体系违约鉴别能力最大为原则进行指标体系的构建,是一种构建指标体系的优化思路和标准,换一套海选指标或者遴选方法,最终建立的指标体系可能会发生变化。
原则二:债信评级体系应简洁且尽可能的照顾到各个准则层的信息。指标太多(例如,80多个指标)不仅容易造成评价体系繁杂冗余,而且由于小企业多数指标的数据不容易获取到,造成评级体系实用性差。指标过少 (例如,仅含有2、3个指标),则覆盖信用信息不全面,会造成评级结果的失真。
根据对中国某商业银行信贷管理专家调研,一般认为指标个数在17-25个比较合理。
2.2 债信评级体系构建的难点及突破难点的思路
难点1:如何保证评级体系整体、而非单个指标具有显著的违约鉴别力。
突破思路:本文通过对比删除一个指标前后的两个指标体系的违约鉴别力b值这个信用得分与违约状态(违约为1,非违约为0)的距离,遴选指标体系违约鉴别能力b最大、而不是单个指标的违约鉴别能力最大的指标体系,构建了基于指标体系整体违约鉴别力最强的小企业债信评级体系。这也是本文的主要创新点。
难点2:删除信息重复的指标时,如何避免误删区分违约状态能力强的指标。
突破思路:在相关系数大于其阈值、即反映信息重复的指标对中,删除指标b值小、即区分违约能力弱的指标,既避免了指标体系的信息冗余,又避免了误删区分违约状态能力大的指标。
难点3:指标体系相同,指标权重不同时,构造的评级体系也大相径庭,如何保证违约鉴别力越大的指标,权重越大。
突破思路:根据指标的违约鉴别力b越大,指标权重越大的思路确定指标权重,确保违约鉴别力大的指标权重大,违约鉴别力小的指标权重小,避免现有研究指标赋权与违约鉴别力无关的弊端。
综上,基于指标体系违约鉴别能力最大的小企业债信评级体系构建原理如图1所示。
2.3 本文债信评级体系构建与现有研究的区别
本文评级体系构建与现有研究[3-13]的区别主要有二:
(1)构建思路的区别
现有评级体系构建[3-13]是根据信息含量或者违约鉴别力来遴选单个指标,而本文是根据指标体系整体的违约鉴别力来遴选指标体系,确保了被选中的指标体系对违约状态具有最为显著的鉴别能力,改变了现有研究[3-13]构建评级体系时立足于单个指标遴选的弊端,完善了信用评级体系建立的方法。
(2)评级方法的适用特点的区别
现有常用评级方法的适用特点如表1所示。

表1 常用评级方法的弊端
本文选取布莱尔分数为小企业债信评级体系构建方法,主要原因:
一是布莱尔分数b能显著鉴别单个评级指标或指标体系整体的违约鉴别力。
二是可以将“布莱尔分数b衡量违约鉴别力”的原理灵活应用在小企业债信评级体系构建的各个环节。评级指标体系的构建环节,通过“债信评分的布莱尔分数b最大、即指标体系整体违约鉴别力最大”的思路遴选指标体系。保证了指标体系整体、而非单个指标具有显著鉴别违约力。删除信息冗余指标环节,在信息冗余指标中,保留布莱尔分数b较大、也即违约鉴别力较大的指标,保证了违约鉴别力强的指标不被误删。评级指标的赋权环节,通过“布莱尔分数b越大、也即指标违约鉴别力越大,权重就越大”的思路赋权,保证违约鉴别力越大的指标,权重越大。
三是布莱尔分数b值不要求变量的分布类型。
3 债信评级体系构建方法
3.1 指标数据标准化方法
指标数据标准化的目的是将指标原始数值转化为0-1之间的标准化数值,消除指标量纲的影响。
设:xij-第i个小企业第j个指标标准化值;vij-第i个小企业第j个指标的指标数据;n-小企业总数。
(1)正向指标标准化
正向指标是数值越大,小企业债信状况越好的一类指标。则xij为[19]:
(1)
(2)负向指标标准化
负向指标是数值越小,小企业债信状况越好的指标。则xij为[19]:
(2)
(3)区间型指标标准化
区间型指标是当指标值在某一特定区间内时,小企业债信状况较好,指标值偏离特定区间越远,债信越差的指标。本研究涉及两个区间型指标:“居民消费价格指数”,其最佳区间是[101,105][17];“年龄”,其最佳区间为[31,45][17]。
设:q1-指标特定区间左边界;q2-指标特定区间右边界。则xij为[19]:
xij
(3)
(4)定性指标打分
定性指标打分标准是通过与国内某商业银行中信用评级的专家访谈调研等方式制定,具体如表2所示。

表2 定性指标打分标准
3.2 布莱尔分数b值的计算
布莱尔分数b值计算的目的有三:
一是为了避免信息冗余,需要在相关性较强的一对指标中删除一个指标,此时需要对比这两个指标的违约鉴别力b值的大小,以便删除违约鉴别力b值较小的指标,避免误删。
二是布莱尔分数b值代表了违约鉴别能力的大小,在根据违约能力对单个指标赋权时需要用到这个参数。
三是在指标体系的遴选上,需要对比由多个指标组成的加权评分的数值所对应的b值来鉴别和遴选指标体系。
布莱尔分数b值的计算包括两种对象。一是单个指标b值的计算,这用于第一次指标筛选的相关分析中作为删除标准,也用于单个指标的赋权。二是多个指标加权评分结果的b的计算,它用于指标体系的筛选。
不论是单个指标、还是多个指标b计算,其步骤是一样的。但单个指标用的是客户指标数值,而多个指标用的是由评级方程得到的加权平均分数。
下边以多个指标为例,说明b值计算的步骤。

(4)

3.3 基于相关分析的指标第一次筛选
第一次筛选的目的是删除同一准则层内反映信息冗余指标,确保评级体系简洁。

(5)
(2)计算单个指标的布莱尔分数b值。计算过程详见上文“3.2”;只不过是把其步骤中的加权平均的“债信得分”换成“单个指标的标准化得分”。
(3)相关性指标的删除。当指标间相关系数绝对值大于0.7[21],则指标反映信息冗余。在信息冗余的指标对中,保留b值大、也即违约鉴别力强的指标,删除另一个,避免违约鉴别力强的指标被误删。
3.4 基于指标体系违约鉴别力最大的第二次筛选
第二次筛选的目的是确定整体违约鉴别力最大的评级指标体系。
步骤1:基于b值对指标赋权
根据“指标违约鉴别力b值越大,指标权重就越大”的思路赋权。
设:wj-第j个指标的权重;bj-第j个指标的布莱尔分数;k-需要赋权的指标数,k=1,2,…K,K为相关分析后剩余的指标总数。则:
(6)
式(6)含义:违约鉴别力bj越大,则指标权重wj越大,确保了指标权重体现违约鉴别力。
步骤2:建立债信评分方程
(7)
式(7)含义:式(7)表示第i个小企业的债信得分,其值在[0,1]之间。
步骤3:计算K个指标的体系违约鉴别力bK。
根据式(7)计算的K个指标的债信得分,求解出这K个指标组成体系的债信得分的违约鉴别力bK值。其中bK的计算见上文“3.2”的式(4)。
步骤5:遴选出违约鉴别力b值强的指标体系。
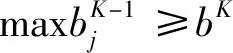
步骤6:重复步骤4和步骤5,继续删除指标。
步骤7:删除指标的终止。设:k-待遴选指标体系内的指标数,k=1,2,…,K。

此时若还满足bk≥0.7[22],说明k个指标的评级体系违约鉴别力显著,则保留k个指标的评级体系,指标体系遴选截止。
若bk<0.7[22],说明k个指标的评级体系违约鉴别力不显著。此时,需要重新海选指标,重复“3.1-3.4”,直至遴选出违约鉴别力最优的指标体系。
第二次筛选的具体步骤如图2所示。

图2 第二次筛选步骤
3.5 债信评分模型的构建
(1)确定指标权重。设:wj-第j个指标的权重;bj-第j个指标的布莱尔分数。则:
(8)
式(8)与式(6)的不同:式(8)是指标体系建好后的指标赋权,其中m为最终遴选的指标数;而式(6)是遴选指标体系过程中、待遴选指标的赋权,k为待遴选指标体系内的指标数。
(2)评分方程的建立。设:Si-第i个小企业债信得分;Zi-第i个小企业的标准化债信得分。则[17]:
(9)
(10)
式(9)与式(7)的不同:式(9)是指标体系建好后的债信得分方程,其中m为最终遴选的指标数;而式(7)是遴选指标体系过程中、待遴选体系的债信得分计算方程,k为待遴选指标体系内的指标数。
式(10)的含义:由于计算的债信得分Si值在[0,1]之间,不能显著体现债信得分的差异,故用式(10)将债信得分Si进行标准化,使之变为[0,100]之间的标准化得分Zi,以显著体现债信得分的差异。
3.6 债信等级的划分
划分满足“债信等级越高,损失率越低”标准的债信等级。
(1)初步划分为9个债信等级。将客户按照式(10)计算的债信得分降序排列,并初步划分为AAA,AA,…,C等9个等级。
(2)确定债信等级。每个债信等级的损失率为等级内所有客户的年总应收未收本息占年总应收本息的比重。因此通过改变每个债信等级对应的债信得分上下限,可以改变等级内的客户数,进而改变债信等级对应的损失率。
通过对每个债信等级的得分上下限不断调整,直至得到满足“债信等级越高,损失率越低”标准的债信等级划分结果。
上述债信等级划分思路是我们团队被授权的中华人民共和国发明专利[23]的思路,不展开详述,计算量较大,由计算机完成。
(3)债信等级的损失率计算说明
本研究中债信等级的损失率
损失率=等级内所有客户的年总应收未收本息和/年总应收本息和
(11)
巴塞尔新资本协议中的预期损失率
预期损失率=预期损失额EL/违约风险暴露EAD=违约概率PD×违约损失率LGD
(12)
本研究中损失率与巴塞尔新资本协议中的损失率计算的区别:式(11)中损失率的分子为实际应收未收本息,分母为实际应收本息,是真实值,而式(12)中损失率的分子为预期损失额EL,分母为违约风险暴露EAD,是估计值。显然,本研究中运用实际违约损失相关数据计算的损失率,对贷款等金融产品的投资与定价更有参考价值。
4 实证研究
4.1 评级指标的海选
通过梳理国内外经典文献,参考邓白氏、标普等国外权威评级机构,中国工商银行、中诚信等国内典型机构的小企业信用评级体系,以及通过调研访谈等方式,建立了企业内部财务因素、企业内部非财务因素等7个准则层,具体如表3第b列所示。海选了81个指标,如表3第c列所示。表3第d列是指标类型。
4.2 样本及数据来源
本文选取了中国某商业银行全部分支行近20年的3045个小企业贷款数据作为实证样本,包括2995个非违约小企业、50个违约小企业,涉及京、津、沪、渝等28个城市的小企业贷款数据。
其中,小企业是根据中国工业和信息化部等四部委发布的《中小企业划型标准规定》[24]进行界定的,如表4所示。
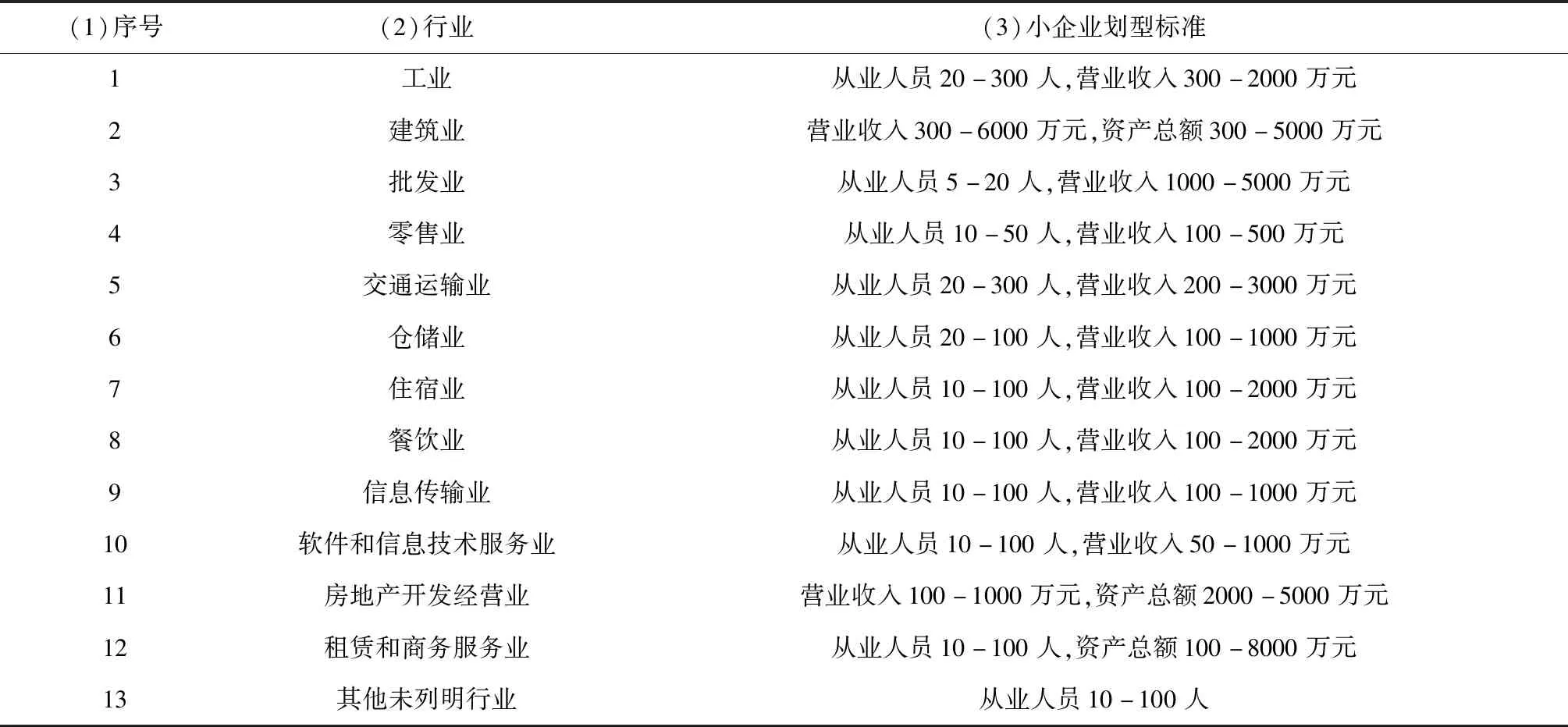
表4 中国不同行业小企业划型标准
指标原始数据列入表3第1-3045列前81行,对应的标准化数据列于第3046-6090列,标准化过程见下文“4.3”。表3第82行是小企业违约状态标识,用1标识违约,用0标识非违约。
4.3 评级指标数据标准化
根据表3第d列指标类型,将表3第c列中定量指标每一行的原始数据vij、最大值max(vi,j)、最小值min(vi,j)分别代入式(1)、式(2)或式(3),得到定量指标的标准化值打分xij,结果列入表3第3046-6090列对应行。根据表2打分标准,对表3第c列中的定性指标进行打分,结果列入表3第3046-6090列对应行。综上,得到了表3前81行第3046-6090列的全部数值。

表3 小企业81个指标及数据
4.4 基于相关性分析的指标第一次筛选
(1)计算相关系数。根据表3第b列准则层,将同一准则层内指标第3046-6090列数据阵中的任意两行代入式(5),计算指标间的相关系数。将相关系数>0.7[21]的指标名称列入表5第2列和第4列,相关系数值列入表5的第6列。
(2)计算指标布莱尔分数b值。将客户总数n=3045,表3第3046-6090列数据分别代入式(4),得到指标的b值。将这81个指标的b值分别列入表5第3列和第5列,以及表6第3048列对应行。
(3)删除相关性指标。表5的每一行中均有不同的相关性指标及其b值,删除每行中b值小的指标,列入表5第7列,同时列入表3第G列对应位置。

表5 基于相关性分析的指标筛选
经相关性分析,81个指标中共删除15个指标,剩余66个指标,列入表6第2列第1-66行。
4.5 基于指标体系违约鉴别能力最大的第二次筛选
(1)计算66个指标组成体系的b66值
步骤1:基于b值对66个指标赋权wj
将表6第3048列指标的bj值代入式(6),得到66个指标的权重wj,列入表6第3049列。

表6 指标的第二次筛选

步骤3:计算66个指标组成体系的b66值
将客户总数n=3045,表6第67行第3-3047列数据,以及违约客户的yi=1、非违约客户的yi=0代入式(4),得到66个指标组成体系的债信得分的b66值=0.495。

步骤1:基于b值对65个指标赋权wj
将表6第3048列第1-42行及第44-66行数据bj代入式(6),得到这65个指标的权重wj,结果见表6第3050列相应行。
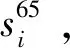
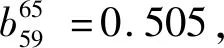

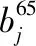
表7 66个值
(3)遴选违约鉴别力强的评级指标体系
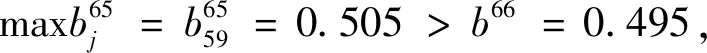
至此,第一个评级体系的遴选结束。
每去一个指标,均形成一个新体系,与去掉指标前的体系进行对比,重复上述过程。直至剩余指标组成的体系违约鉴别力最大,且大于0.7[22],且体系内指标能尽可能的照顾到小企业各个准则层的信息。
经上述遴选,最终选定剩余18个指标组成的体系。在剩余18个指标时停止遴选的原因:一是这18个指标组成体系的违约鉴别力b18=0.81,远大于临界值0.7[22],具有显著的违约鉴别力。二是若继续删除指标,则将删去“企业到位注册资金类别”这个仅有的衡量企业基本信用准则的指标,虽然17个指标的体系违约鉴别力变大,即有b18=0.81 保留的18个指标列入表8第2列。删去的48个指标结果列入表6第3092列,同时列入表3第G列对应行。表8第3列为这18个指标的bj值,bj值来自表6第3048列。 将表8第3列的bj值代入式(8),得到指标的权重Wj,列入表8第4列相应行。 将表8第4列的权重Wj,及表3第3046-6090列这18个指标所在行的数据xij,代入式(9),得到3045个小企业的债信得分Si,列入表6第116行。 将表6第116行债信得分Si代入式(10),得到小企业的标准化债信得分Zi,列入表6第117行。 将客户按照表6第117行的标准化债信得分Zi降序排列,并初步划分为AAA、AA等9个等级。 每改变不同等级对应的债信得分上下限,就可以改变等级内的客户数,而客户数改变会引起等级内客户群总应收、总应收未收的变化,进而引起损失率变化。因此,通过不断调整每个债信等级的得分上下限,直至得到满足“越高债信等级,违约后的损失率越低”标准的债信等级划分结果。这种调整计算量大,可方便地通过我们团队被授权的中华人民共和国发明专利[23]实现。 最终等级划分结果如图3所示。由图3明显看出,由我们团队被授权的中华人民共和国发明专利模型[23]划分的债信等级满足“债信等级越高,损失率越低”的客观实际。 图3 小企业债信等级分布 (1)对比分析一 与单个违约鉴别能力b值最强的指标组成的指标体系进行对比。 根据表6第3048列b值,从表6第2列的66个非冗余指标中,选取违约鉴别力b值最大的18个指标组成一个评级指标体系,这18个指标列入表8第5列,相应的b值列入表8第6列。根据上文“3.4步骤1-步骤3”,计算得到这18个指标组成体系的违约鉴别力b值为0.73。 18个违约鉴别力最强的单个指标组成体系的违约鉴别力b=0.73,小于本文建立的体系违约鉴别力b=0.81。说明单个违约鉴别能力最强的指标,组合起来的体系鉴别能力反而不强。 (2)对比分析二 与看似很好、很流行的单个指标组合起来的指标体系进行对比。 本文根据文献[25]梳理的穆迪、标普等国际权威机构以及信用评级文献中出现频率较高的18个指标,列入表8第7列,出现的频率列入表8第9列,相应的违约鉴别力b值列入表8第8列,该值来自表6第3048列。 根据上文“3.4步骤1-步骤3”,计算得到这18个指标组成的体系的违约鉴别力b值为0.431,小于本文建立的体系的违约鉴别力b值为0.81,说明看似很好、很流行的单个指标,组合起来的指标体系整体鉴别力不一定也好。 (3)对比分析三 与指标个数较多的评级指标体系进行对比。 根据上文“4.5”知,在66个指标基础上,不断去掉一个指标后,剩余指标组成体系的违约鉴别力b值在不断增强。以体系内指标个数为纵坐标,以体系的违约鉴别力b值为横坐标,绘制图4。 由图4可直观看出,随着指标个数的降低,指标体系的违约鉴别力b值反而升高,因此,对评级指标体系而言,并不是指标个数越多越好。 图4 指标个数与评级指标体系b值的对应 (4)对比分析启示 由于指标间的相互影响,单个违约鉴别能力最强的指标,组合起来的体系鉴别能力不一定也最强。看似很好、很流行的单个指标,组合起来的指标体系整体违约鉴别力不一定也好。同样的,体系内指标个数也不是越多越好。在构建债信评级体系时,不应认为指标个数越多越好,也不应关注单个指标的违约鉴别力或者单个指标的流行与否,而应重点关注指标体系整体的违约鉴别能力。 (1)企业外部宏观环境指标至关重要。 由表8第18行第4列可知,企业外部宏观因素“居民消费价格指数”的权重为0.107,是本文建立的指标体系中权重第二大、也即违约鉴别力第二强的指标。且实际中,大企业也难以抵挡外部宏观环境变化带来的风险,小企业更不行。因此,对小企业债信评级时,企业外部宏观环境指标至关重要。 (2)非财务指标在小企业债信评级中更重要。 由表8第4列知,占67%(财务指标个数12/体系内总指标数18=67%)的财务类指标总权重仅为0.4(为表8第1-12行第4列指标权重之和),而占33%(1-67%=33%)的非财务类指标总权重却为0.6(为表8第13-18行第4列指标权重之和),可见非财务类指标在小企业债信评级中地位更加重要。 (3)未偿还贷款占资产总额比、未偿还贷款总额占净资产比指标不容忽视。 由表8第4列知,未偿还贷款占资产总额比权重最大,为0.108;未偿还贷款总额占净资产比权重第三大,为0.101,可见未偿还贷款占资产总额比、未偿还贷款总额占净资产比指标是影响违约鉴别力极其重要的指标,不容忽视。 表8 本文建立的小企业指标体系及其对比体系 (4)等级划分符合“债信等级越高,违约后损失率越低”的客观实际。 任何债信等级都应符合“债信等级越高、损失率越低”原则,否则,无论看似多么合理的等级划分都是不对的。由图3可知,按我们团队被授权的中华人民共和国发明专利[23]划分的债信等级符合“债信等级越高,损失率越低”的客观实际,同时给出各等级客户对应的损失率。 本文以中国某商业银行全部分支行近20年的3045个小企业贷款数据为实证样本,将布莱尔分数和逐步向后剔除算法相结合,以指标构成的指标体系整体违约鉴别能力最大为标准,在由n和n-1个指标构成的两组指标中,根据两组指标体系的非违约客户的综合得分Si越高,则Si偏离非违约状态(yi=0)的距离越大,违约客户的综合得分Si越低,Si偏离违约状态(yi=1)的距离越大,则布莱尔分数b越大,指标体系违约鉴别能力就越强的思路来遴选违约鉴别能力最大的指标体系,最终建立了包括全部资本化率、企业法律纠纷情况、居民消费价格指数等18个指标的小企业债信评级指标体系。 基于构建的债信评级指标体系,对小企业债信进行信用风险评价,并将小企业划分到AAA、AA、A等9个信用等级。 同时,本研究通过将单个违约鉴别能力最强的指标组成的指标体系的b值、流行的指标组成的指标体系的b值、指标个数较多的指标体系的b值,分别与本文建立的整体违约鉴别力最大的指标体系的b值对比,证明了单个违约鉴别能力最强的指标,组合起来的体系鉴别能力不一定也最强。看似很好、很流行的单个指标,组合起来的指标体系整体违约鉴别力不一定也好。同样的,体系内指标个数也不是越多越好。在构建债信评级体系时,不应认为指标个数越多越好,也不应关注单个指标的违约鉴别力或者单个指标的流行与否,而应重点关注指标体系整体的违约鉴别能力。4.6 小企业债信得分的计算
4.7 小企业债信等级的划分

4.8 对比分析

4.9 小企业债信评级体系特点分析

5 结语
