结合边缘特征先验引导的深度卷积显著性检测
2020-07-17时斐斐张松龙
时斐斐,张松龙,彭 力
江南大学 物联网工程学院 物联网技术应用教育部工程研究中心,江苏 无锡 214122
1 引言
显著性检测作为计算机视觉系统模拟人类视觉注意力机制的一项技术,其主要解决问题是如何快速准确地从各类场景中提取有效显著目标,目前显著性检测算法研究主要采用自底而上和自顶而下两种策略。自底而上的目标注意力机制主要基于数据驱动,通过设计显著性检测的分类器模型,通过大量训练数据集对模型进行训练指导模型收敛并在测试数据集上验证,最后得到参数模型;自顶而上的目标注意力机制主要基于任务驱动,通过跨学科观察分析等方法得出背景、对比度和中心先验信息,利用先验信息或通过人工提取的低级特征与先验信息相融合建模来检测显著性区域,该方法在简单的场景中取得了良好的效果。
自底而上基于数据驱动的显著性检测模型依赖于监督学习方法以及庞大的数据集做驱动。2016年Li等[1]提出了一种基于深度卷积网络提取各区域卷积特征对比的显著性检测网络,其特点是使用全卷积网络提取各个阶段的多尺度卷积特征直接预测显著图;2017年Zhang等人[2]提出一种学习不确定卷积的显著性检测网络,网络在特定卷积层后映入随机生成的丢弃层,构建了一个不确定的内部单元特征集合从而增加算法的鲁棒性和准确性;2018年Wang等人[3]提出了注意力显著性网络AsNet,利用眼动预测的结果图逐步推断目标显著性,并使用新颖的损失函数做了进一步优化从而提升了算法的准确度。自顶而下基于任务驱动的显著性检测模型主要是通过先验信息或者先验信息与人工提取特征组合建模的方式检测显著性区域。早在1998年Itti等[4]跨学科地根据灵长类动物的视觉神经系统设计出显著性视觉注意模型,其利用多尺度金字塔融合亮度、方向、颜色特征得到最终显著图,这被认为是第一个完整的显著性检测模型。至今,人们利用颜色对比度、中心先验、背景先验等先验信息提出了大量的基于任务驱动的显著性检测模型。2013年Yang等[5]将图像分割为超像素,利用背景先验假设将边界超像素与背景超像素进行显著值传播,通过预测各个超像素对应的显著值得到显著图。
利用先验信息的任务驱动显著性检测方法对特征提取方式比较简单,不需要大量数据集以及复杂漫长的训练过程,在显著性检测领域发展初期得到了很好的发展。但随着近年来大数据时代的到来以及深度学习技术的流行,基于数据驱动的显著性检测模型通过大量训练集学习充分图像深度特征,大大提升了检测精度,而传统的基于先验信息的任务驱动显著性检测方法无法充分利用大数据优势,同时对图像特征提取和理解程度不够导致在面对复杂场景时精度远远达不到预期效果,所以近几年研究学者们将研究重点转向了自底而上基于数据驱动的显著性检测模型。但因此,近几年研究忽视了先验信息的引导,而先验信息是对人类视觉注意机制的科学总结与归纳,更贴合人类观察显著区域的本质。在基于深度学习算法训练时,如果训练集没有包含类似测试场景的图像时,其算法检测出的显著区域往往精度偏低且缺乏鲁棒性,容易出现误检或者漏检,模型的不完善性和单调性也就暴露了出来。此外,虽然目前卷积特征取代了手工提取特征,但如何合理使用各阶段卷积特征仍然是研究中的难点问题。
针对上述因缺乏先验引导导致的深度学习算法问题,本文提出了一种结合边缘特征先验引导的全卷积神经网络显著性检测方法。首先使用基于ResNet-101的特征编码网络提取原图深度卷积特征,通过使用SLIC图像超像素分割算法保留图像原有特征的同时降低后续计算复杂度,从对比度先验、背景先验两种先验信息入手,计算每一个超像素与边缘像素的RGB、CIELAB和LBP三种颜色特征对比度以区分前景-边缘-背景,同时在计算时引入中心先验信息的高斯权重,获取更鲁棒的先验图;将上述先验图输入先验信息辅助网络学习先验特征,并使用前景-边缘-背景三分类损失函数使之收敛;提出先验信息融合模块,将得到的先验特征与深度卷积特征通过注意力机制有效地融合,利用特征解码网络参数并将编码特征图放大到原图像大小;最后提出CC-FO(Circular Convolution-Feedback Optimization,循环卷积反馈优化)优化策略,自动地学习改进显著性映射,从而得到更加可靠的最终预测。
2 网络模型
2.1 模型架构

图1 模型结构示意图
如图1所示,本文网络模型由3个子网络组成,分别是特征编码网络、先验信息辅助网络、特征解码网络。特征编码网络是基于ResNet-101[6]的编码网络,主要用于提取原图的深度卷积特征。ResNet-101由4个残差模块组成,共101层卷积层,因此可以获得丰富的高级语义信息。先验信息辅助网络用于学习输入先验图的先验特征并使用前景-边缘-背景三分类约束收敛,并通过先验信息融合模块(Prior Information Fusion Module,PIFM)融合深度卷积特征与先验信息,将其作为特征解码网络输入。特征解码网络由卷积层和上采样层组成的解码网络,目的是学习网络参数并将显著图恢复到原图分辨率。该网络由5个卷积层、5个上采样层和最后的显著图预测层组成,上采样层采用反卷积实现,逐阶段恢复特征图的分辨率;最后将显著图预测层输入到sigmoid函数来判别各像素点属于显著区域的概率,并利用交叉熵损失函数实现网络的反向传播。
2.2 边缘先验图
先验知识是通过跨学科观察分析等方法基于人类视觉机制得出的科学结论,最初基于先验信息任务驱动的显著性算法是人们使用对比度、背景、中心先验等先验知识组合人工提取的低级特征建模检测显著区域。其中对比度先验知识认为对比度越大的区域显著值越高;中心先验方法认为人在观察图像时最先注意的区域就是图像的中心位置,因此在计算图像显著性区域的时候,以高斯模型实现从中心向四周递减的方法实现;背景先验是指目标边界以及背景区域的像素点显著值比较低。而这三种先验知识被证明可以实现互补[7],且在传统的显著性检测中效果突出。为了得到更好的边缘先验图,本文基于对比度先验、中心先验和背景先验三种被经常用到的先验知识,计算每一个超像素与边缘像素的RGB、CIELAB[8]和LBP[9](Local Binary Pattern,局部二值模式)三种特征的对比度,同时在计算对比度时引入中心先验的高斯权重,使获取的先验图更鲁棒。本文采用RGB和CIELAB两种颜色特征的对比度是为了使两种特征发生互补,使之对显著性检测更有利。RGB颜色空间是人们最常用的颜色空间,该颜色空间中R为红色,G为绿色,B为蓝色;CIELAB颜色特征通过模拟人眼对颜色特征的感知,使其更加符合人眼观察颜色的本质。CIELAB颜色空间中L分量表示的是取值范围为[0,100]的像素亮度,a分量表示取值范围为[127,-128]的从红色到绿色区间,b分量表示取值范围为[127,-128]从黄色到蓝色的区间。
输入的先验图分辨率越高,内容表达越准确,则输入网络学习后的显著图的准确度也越高。而一幅图像中的多数像素点都有相似的颜色、亮度、纹理等特征,在处理过程中如果将每个像素都按照既定方法运算一次,将会带来庞大的计算量和时间损耗。为了减少算法计算占用内存,增加运算效率,本文使用简单线性迭代聚类(Simple Linear Iterative Clustering,SLIC)[10]算法对输入图像做图像超像素分割。该算法在有效捕捉到图像的特征的同时,极大地减少了图像后续处理的计算量,广泛用于语义分割[11]、显著性检测[12]等各领域。SLIC方法需要将图像从RGB空间转换到CIELAB颜色空间,并设定分割超像素的个数k,将图像分割成一定数量的具有相似特征的超像素,不仅较好地保留图像的原有特征,同时降低了图像后续处理的计算复杂度,图2所示不同的k值设定算法得到的分割图对比。将一幅像素点总数为N的图像分割为像素点数为N/k的单个超像素,其两个相邻超像素聚类中心空间距离近似为S= N/k,SLIC算法将初始化聚类点设定为边距为S的网格节点,然后根据聚类点2S×2S正方形区域内计算像素点与初始聚类点的欧氏距离,进而判断聚类点周围的点是否应该划分到该超像素中。像素点与该初始聚类点的欧式距离是该正方形区域内点的空间距离与颜色距离的加权值:
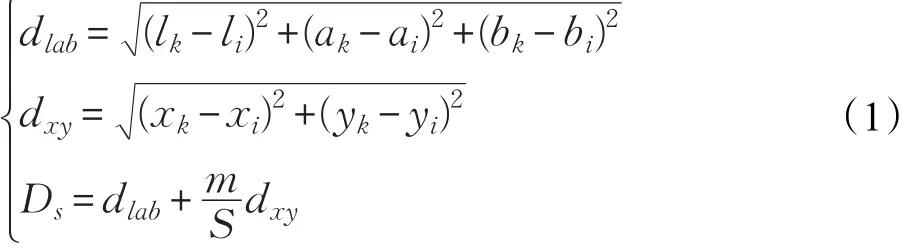
其中,[l,a,b]为CIELAB空间的颜色平均值,[x,y]为位置空间,dlab为像素的颜色距离,dxy为像素的空间距离,Di是像素颜色距离和空间距离加权后的总距离,m控制颜色和空间权重。该算法可以将图像分割成一定数量的具有相似特征,且感知均匀的超像素,不仅较好地保留图像的原有特征,同时降低了图像后续处理的计算复杂度。图2展示了SLIC超像素分割算法不同尺度分割图直观效果对比。实验证明[10],使用SLIC算法显著地降低了像素的线性复杂度,展示了目前最优的边界依从性,在PascalVOC 2010数据集上测试,相比于同类分割算法QS 09方法提升了分割精度,并将生成超像素的时间减少了一个数量级。

图2 不同尺度的SLIC分割图对比

其中,α和 p分别为超像素的平均RGB的值和空间中心位置,Γi表示为归一化项,β为一个尺度项,本文固定其值为0.5。
LBP特征是一种用来描述图像的局部纹理的特征。首先,它设定窗口中心值为阈值,将周围的像素值与该阈值比较,若大于阈值则标记为1,反之则标记为0。然后,将标记值按照的顺序排成一列组成二进制值,将该二进制值作为中心点的值。二值模式变化求取纹理的转换方法如下:

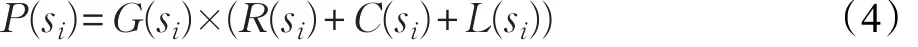
其中,G(si)表示为超像素si的中心先验值,利用文献[11]高斯中心先验方法计算得到。图3为先验图结果示例,从图中可以看出,先验显著图通过先验知识可以准确地找到显著区域,但是依然存在显著区域不突出、误检等问题。

图3 显著性先验图结果示例
2.3 基于注意力机制的先验信息辅助网络
虽然基于数据驱动的显著性检测模型算法远远超过了利用先验信息的任务驱动算法的性能,但是先验信息是对人类视觉注意机制的总结[13],更符合人类观察显著区域的本质。因此,本节设计了基于注意力机制的先验信息辅助网络,有效地利用先验信息辅助神经网络获得更鲁棒的显著预测。先验信息辅助网络主要由5个卷积层和5个池化层组成,该网络输入为上节得到的先验图,通过5层卷积学习得到先验图的卷积特征。由于先验卷积特征中包含丰富的先验语义信息,这可以帮助引导特征解码网络对于特征的选择,从而达到选择更为精准的卷积特征。
通道注意力模块是一种实现对原特征重新校准和选择的方式[14]。本节基于通道注意力提出了先验信息融合模块(Prior Information Fusion Module,PIFM),如图4所示,首先将先验图卷积特征进行全局池化得到全局信息,然后通过卷积核为1×1的卷积学习相互依赖系数,最后相互依赖系数与解码网络的深度特征各通道相互点乘,实现先验卷积特征引导解码深度特征选择对显著性更有用的特征。

图4 先验注意力引导模块
通过构建的先验信息融合模块,实现对原特征的重新校准,从而提高了算法精度,图5是使用PIFM模块与普通融合策略[15]得到的显著图对比。可明显看出图5(c)相比图5(b)在边缘区域、内部区域得到了明显的改善,特征更加明显。通过实验表明,使用该模块提升了对特征的利用率。

图5 PIFM结构使用效果对比
2.4 循环卷积反馈优化
传统的全卷积神经网络[16]由于只包含前馈网络结构,缺乏反馈信息,导致网络无法自性修正预测错误的显著区域,从而输出的显著图包含很多噪声。针对这一问题,对全卷积网络进行改进,提出CC-FO(Circular Convolution-Feedback Optimization,循环卷积反馈优化)优化策略,通过将先验图特征和显著图特征循环送入解卷积网络,形成反馈信息优化每阶段的显著图。不同于RFCN算法循环处理方法,本文算法只循环先验信息辅助网络和特征解码网络,先验信息辅助网络主要是为了在循环中逐步提取前一阶段得到的特征对应的先验信息,而特征编码网络持有原图最本质的特征,将两者信息融合互相矫正从而达到更好的效果。另外运行一次特征编码并且复用到后面的循环优化中的原因,一方面是因为特征编码网络由ResNet-101组成,若每阶段循环优化都加入该网络,势必会带来巨大的计算量;另一方面经实验测试若每阶段重新计算特征编码,结果表明对算法精度帮助非常有限。
如图6所示,在第一时间段中,将先验信息辅助网络输出F(P;θ)和特征编码网络输出F(I;θ)通过PIFM模块融合后的卷积特征作为特征解码网络的输入,通过特征解码网络得到显著性预测图如下式:
G1=U(F1(I;θ),F2(P;θ);φ) (5)其中,U表示反卷积操作,F表示卷积操作,I表示输入图像,P表示输入先验图,θ表示卷积参数,φ表示解码网络参数。在之后的第t时间段中,网络将上一个时间阶段预测的显著图Gt-1作为先验图送入先验卷积网络,得到先验卷积特征F2(Gt-1;θ),再将第一时间阶段的编码部分卷积特征F(I;θ)与先验卷积特征Ft(Gt-1;θ)通过PIFM模块融合输入特征解码卷积网络。解码部分利用融合特征图得到优化后的显著性预测记为下式:

经过大量实验测试证明,当时间阶段T=4时,网络预测的显著图达到最好的效果,而往后再进行迭代,显著图的预测准确度明显下降,说明整个预测控制过程从发散到收敛,再往后变为过拟合,而T=4时达到最优效果。实测效果如图7所示。因此,本网络的循环步数设置为T=4。
3 仿真实验分析
3.1 实验细节说明
本文算法的实验平台是在64位的Ubuntu16.04操作系统和英伟达显卡GTX Genforce 1080 GPU,采用的软件为Pycharm(Python2.7)和深度学习框架PyTorch。本文用于训练的数据集为MSRA10K[17]公开数据集,其中含有10 000张高像素图片,同时大多数图片只含有一个显著性目标。为了增加训练集数据量和样本的多样性,通过数据增强(Data Augmentation)对原始数据集进行旋转,并镜像得到80 000张样本用作训练。测试集采用SED2[18]和ECSSD[19]两个数据集共1 100张图片,其中SED2中含有100张测试图,虽然规模小,但其含有像素级别的真值标注,且背景相对复杂并均为多显著性目标图,极具挑战性;ECSSD含有1 000张种类繁多、背景结构信息丰富的图片,具有很高的参考性和测试价值。本文使用随机梯度下降方法训练网络,训练时动量设置为0.9,权重衰减为0.000 5,基础学习率为0.001。本文算法训练共花费90 min,在迭代6 000次后达到收敛。
3.2 实验结果定性分析
为验证本文算法的优越性,将该方法与目前主流的9种显著性检测算法进行对比,包括2种基于先验信息的任务驱动显著性检测方法以及7种基于数据驱动的深度学习显著性检测模型学习,分别为wCO[18]、RFCN[19]、BL[20]、MDF[21]、DCL[22]、DHS[23]、Amulet[24]、UCF[25]、SRM[26]。通过图8直观的显著图结果对比,本文算法的检测直观比较效果相对较好。传统算法wCO算法检测出的显著区域不突出,并且夹杂着背景噪声;BL算法虽然也是基于数据驱动的算法,但是该算法采用人工提取特征,因此缺乏高级的语义信息导致显著区域模糊和漏检;MDF、DCL、DHS、Amulet、UCF、SRM这些基于深度学习的算法完全抛弃了传统先验方法的指导,导致检测到显著图存在误检测区域,面对复杂场景时缺乏鲁棒性。RFCN算法虽然采用先验图的指导,但是仅将原图与先验图串联使得整个网络需要学习整张先验图,存在大量计算冗余的同时未能有效地提取出先验图的重要信息。最后是本文提出的基于先验特征引导的显著性检测算法,可以看出几乎完整地检测出显著区域的同时,也抑制了背景噪声的干扰,在面对第五行这种复杂背景时依旧具有良好的鲁棒性。

图6 循环解卷积网络示例

图7 不同时间步网络显著性预测结果

图8 显著图结果直观对比
3.3 实验结果定量分析
3.3.1 评价指标
本文采用准确率(Precision,P)为纵坐标,召回率(Recall,R)做横坐标构建P-R曲线[27]、曲线下面积(Area Under the Curve,AUC)、F-measure值和平均绝对误差(Mean Absolute Error,MAE)指标对比本文算法与主流算法。对于F-measure值,有:

其中,β2为权重参数,取β=0.3;对于MAE值,有:

其中,M,N为显著图的长和宽,GT(x,y)表示人工标注图在(x,y)处的值,S(x,y)表示显著图在(x,y)处的值,MAE值越小,说明算法得到的显著图与人工标注图的差异越小,性能越优异。
3.3.2 ECSSD数据集定量分析
由图9、图10和表1可以看出基于学习的算法比传统算法具有明显的优势。对本文算法在数据集ECSSD中针对查准率、召回率、MAE、F-measure值和AUC值几个指标进行测试并与其余9种算法对比,各指标都取得最优结果。从柱状图可以看出本文所提方法的准确率和AUC值明显高于其他算法。在P-R曲线图中本文算法几乎将其他算法都围在下方,且算法的下降速度缓慢,曲线表现更加平滑。

图9 ECSSD数据集指标柱状图

图10 ECSSD数据集P-R曲线

表1 ECSSD中不同算法的指标对比
3.3.3 SED2数据集定量分析
图11、图12以及表2数据展示了本文算法与其余9种算法在SED2数据集上的性能测试结果。SED2是针对多目标复杂场景的数据集,对算法的准确性、鲁棒性都有较高的要求,在目前的显著性目标检测中具有较高挑战性。由图11、12和表2可以看出,本文算法在SED2数据集上F-measure值取得了最优效果,AUC值与MAE值都排第二,取得综合最优的结果。

图11 SED2数据集指标柱状图

图12 SED2数据集P-R曲线

表2 SED2中不同算法的指标对比
分析P-R曲线可以看出,本文算法虽然在低召回率时查准率与其他算法无多大差异,但召回率达到0.65到0.9时准确率明显提高,这是因为网络在先验卷积特征注意机制的指导下,算法能够准确地找出显著区域。
在表2中,本文算法虽然在MAE、AUC指标未达到最好的效果,但同其他算法相比具有更高的F-measure值,MAE值与AUC值性能也处于前列,综合表明算法能够适应多种场景,模型鲁棒性也更好。
4 结论
本文提出一种基于先验特征引导的显著性区域检测算法。首先,根据先验假设计算出初步的先验显著图。然后通过先验辅助网络学习先验特征,将先验特征与深度卷积特征注意力通道有效地融合,最终通过循环解码网络优化上一阶段的显著图,得到最终的显著图。实验表明,本文算法结合循环解码网络通过有效地利用先验信息得到更加准确且完整的显著区域,各项评价指标相比其他几种算法均有明显的提高。
