基于Spark 的快速短文本数据流分类方法
2020-07-17胡学钢李培培
胡 阳,胡学钢 ,2,李培培
1.合肥工业大学 计算机与信息学院,合肥 230009
2.工业安全与应急技术安徽省重点实验室,合肥 230009
1 引言
随着互联网信息技术的发展,实际应用领域产生了大量的短文本数据流,包括微博、推文和实时评论等。这些短文本数据流具有以下三个显著特点:首先每个文本都很短,没有充分的上下文语义信息,导致特征高维稀疏、信息模糊;其次,随时间推移短文本大量涌现,导致信息快速发生变化,上下文信息不对称;再者,文本流会随着时间变化而发生概念漂移现象,影响所建模型的稳定性,导致其预测精度降低。上述特点使得传统的K最邻近(KNN)、支持向量机(SVM)、逻辑回归(LR)等长文本分类方法难以直接应用,也使得已有的单机版短文本数据流分类方法面临分类精度低与时间代价高的挑战。为了解决短文本的特征稀疏性问题,已有的研究工作一方面通过外部语料库获取词与词上下文关联语料以扩充短文本,如文献[1],然而利用外部语料库丰富短文本,会使得分类器性能严重依赖于外部语料库的丰富程度,导致分类器性能不稳定。另一方面,通过挖掘短文本自身上下文关系,利用关联规则实现自扩展,如文献[2]。然而,上述技术仅适用于数据规模恒定的静态数据集,严重限制了它们在流数据上的应用。目前,流行的短文本数据流分类方法如文献[3]多采用基于滑动窗口机制划分数据块并构建集成分类器模型,从而进行更新与预测,然而,由于较大时间开销无法解决流式数据中I/O同步问题。同时在模型更新策略上也忽略了历史数据流样本对模型的贡献以及概念漂移带来的影响,导致一定精度的丢失。
因此,本文提出一种基于Spark的分布式快速短文本数据流分类方法,其主要贡献如下:(1)利用外部语料库构建Word2vec词向量模型向量化表示短文本,以解决短文本的高维稀疏性,并在训练过程中获取未在外部语料库词表中出现的新词文本集合用来构建词向量扩展库,从而减轻模型分类器性能对外部语料库的依赖程度。(2)提出一种基于在线梯度下降的LR分类器集成模型用于短文本数据流分类,降低训练样本迭代次数,减少对数据块的处理时间,从而缓解数据流中I/O同步问题;同时引入时间因子加权机制以有效缓解概念漂移带来的影响。(3)在Apache Spark分布式环境实现所提方法,并行化加速对海量短文本数据流的分类处理。(4)实验结果表明:所提分布式短文本数据流分类方法比目前主流的文本分类算法具有更高的分类精度和较低的时间代价。
2 相关工作
本章主要介绍短文本与长文本分类的相关工作。
短文本分类的代表工作如下:文献[4]通过外部语料库构建Word2vec与CNN的组合词向量模型,以提高短文本分类;文献[5]利用Web资源构建专有的类别词典,来对特有的短文本进行扩展以实现相关短文本的情感分类;文献[6]将LSTM与词嵌入结合检测极性短文,用于社交媒体中的情感分类;文献[7]同样利用主题模型挖掘隐含主题,然后将短文本中每一个词映射到相应的主题上,进而利用获得的主题进行分类;文献[8]提出一种利用随机投影和分段线性模型策略降低文本特征向量以实现短文本分类;文献[9]提出一种从多种语料库中挖掘隐含主题来扩展短文本的分类方法;文献[10]首先提出了一种端到端的深存储网络以期望从长文本集合获取相关信息来扩展短文本;文献[11]利用分层聚类在语义空间中获取聚类中心向量,以扩展短文本单词向量;文献[12]提出一个通过基于密度峰值搜索的聚类算法用词嵌入来扩展短文本语义信息;文献[4]提出一种基于文本扩展的短文本分类方法,主要抽取短文本中出现的概念,通过文本概念对短文本进行扩展;文献[13]提出基于神经网络的短文本自我管理分类方法,利用深度神经网络将短文本投影到紧凑的向量空间;文献[14]通过在外部语料库上构建主题模型,考虑单词共现信息来扩展文本;文献[15]构建卷积神经网络构建扩展矩阵,通过扩展矩阵完成对文本扩展;文献[16]通过Probase知识库进行术语获取,利用语义概念扩展短文本的特征空间。这些方法虽然降低了短文本的稀疏性,提高了分类的准确性。但是获取覆盖所有类标签的数据域的外部语料库是十分困难的。
长文本分类的代表工作如下:文献[17]提出基于词袋模型的fastText文本分类方法;文献[18]考虑文本中句法和语义单词关系,改进Skip-gram模型,引入短语单元,获取词与短语的矢量,在训练采用二次负采样以加速Skip-gram模型的建立;文献[19]为了克服LDA模型中主题特征与词的重要性不一致的问题,提出一种改良的LDA模型:引入词加权与主题加权使算法期望最大化以进行文本分类;文献[20]提出一种结合TF-IDF与LDA的文本挖掘方法;文献[21]提出一种基于神经网络(BP-MLL)的多标签情感学习方法;文献[22]提出一种多协同训练的文本分类方法,利用TF-IDF、LDA、Doc2Vec对文本进行特征变换,训练多个模型对文本进行加权预测,以提高文本分类精度。但是,上述分类方法都是属于批处理算法,几乎不涉及数据流的分类。同时,他们也未考虑隐藏在短文本数据流中的概念漂移问题。
3 分布式快速短文本数据流分类方法及其在Spark环境下的实现框架
本章提出一种基于Spark的分布式快速短文本数据流分类方法。首先给出短文本数据流增量式分类方法的问题定义,并详述其技术细节:包括扩展Word2vec模型,短文本数据流集成分类模型,模型的增量更新与预测。最后,给出算法在Spark环境下的分布式实现框架。
3.1 问题定义
图1给出了所提短文本数据流分类方法的框架。随着数据块Dt的到来,记为t时刻,首先用词向量集合对数据块文本Dt进行向量化表示,其次训练向量化后的短文本数据块Dt以完成集成模型的构建与更新,对下一个数据块Dt+1中未知数据进行预测。其中,为了构建增量式分类器并能够实时更新参数模型,分别为t时刻第r个类构建Logistic Regression分类器记为 fr(1≤r≤ ||R, ||R ≤L),R为t时刻已出现的类标签集合,从而得到 ||R个分类器集成模型
短文本数据流的增量式分类方法的问题形式化如下:基于滑动窗口机制将给定数据流划分成尺寸大小固定的数据块,记为D={D1,D2,…,Dt,…,DT},其中T→∞,。而在预测阶段,针对数据块Dt+1的任一未知短文本,根据Word2vec训练得到的词向量集Vec向量化为,利用公式(1)预测其标签集合记为;最后利用文本上下文更新扩展词向量集合VecE。

3.2 扩展Word2vec模型与短文本向量化
Word2vec是一组用于生成单词向量的神经网络模型,主要利用语料库文本中词语上下文关系训练模型,将词转化为词向量,用于度量词与词之间相似度,Word2vec提供两种方法(即CBOW与skip-gram)来训练模型,在CBOW架构中,模型通过指定窗口截取上下文来预测当前词;在skip-gram架构中,模型通过当前词预测上下文单词,相比于skip-gram架构,CBOW模型训练时间少,但是对不常见的单词效果不好。因此,利用skip-gram模型架构。训练模型主要有分层softmax和负采样两种方法,为了将算法并行化,本文方法采用分层softmax训练外部语料库的词向量集合VecS,同时为了减少最大化条件对数似然函数的时间开销,引入哈夫曼树技术;主要思想如下:遍历数据块中的每个短文本,如果文本中单词并未出现在外部语料库词表中,则将文本加入集合S。遍历结束后构建Word2vec更新或增加对应词向量至集合VecE。利用短文本数据流中的上下文信息,不断更新新词的词向量,同时为了避免增加处理的时间开销,设置更新阈值ϕ,并过滤在外部语料库中已有的词。扩展Word2vec模型如算法1所示。
算法1扩展Word2vec算法
输入:在当前时刻t获取的数据块D;VecEt-1为t-1时刻扩展词向量集合;S为新词文本集合;Vcab为外部语料库的词表;ϕ为S的最大文本数。
输出:t时刻扩展词向量集合VecEt。
4.end if
5.end for
6.ifS.size>ϕ:
7. forwdinS.words:
8. ifVecEt-1haswd vector:
9. UpdateVect-1
10. else
11.VecEt(wd)←zero

图1 短文本数据流分类框架图
12.end if
13.end for
14. UseSBuild Word2vec,updateVecEt
15.S←emptySet
16.end if
针对外部语料构建Word2Vec模型得到词向量化集合Vec。随着短文本数据块的到来,利用Word2Vec模型训练出的向量集合进行向量化表示。例如,对数据块Dt中短文本向量化表示记为:

3.3 短文本数据流集成分类模型
本节将详细介绍基于线性LR分类器的增量式分类模型的构建,同时,为适应短文本数据流环境,采用在线梯度下降FTRL算法更新特征权重。
3.3.1 LR集成模型的构建
根据类标签分布将数据块Dt划分为 ||Rt个具有相同类标签的短文本集合,其中 ||Rt表示数据块Dt中短文本包含的类标签个数。选择第r个具有相同类标签的短文本集合作为正例集合,Dt中其他的短文本集合作为负例训练构建线性LR分类器,形成分类器集成模表示数据块Dt中第r个类标签对应的的线性LR分类器,记为对应的权重集合表示为=,初始值权值设为 0;Vec(Dt)表示Dt数据块的所有文档向量化集合。
这样做的目的是尽可能地减少分类器构建过程中对样本的迭代次数,同时增大分类器与分类器之间的差异度;以实现更好的分类效果。
3.3.2 在线梯度下降FTRL算法
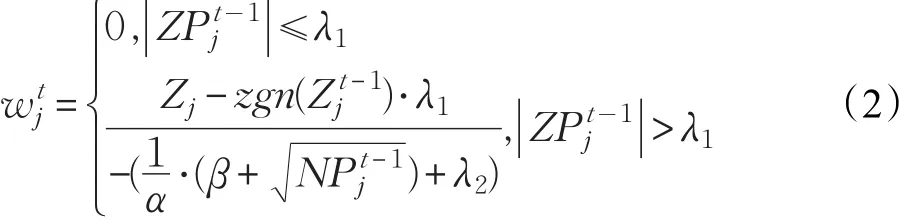
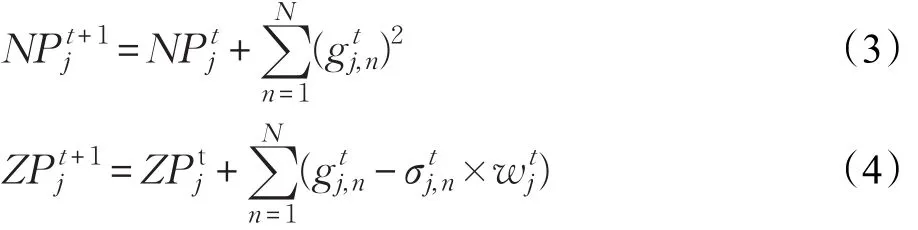
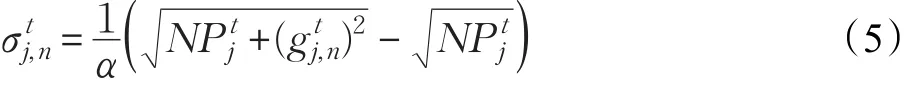
其中,λ1、λ2、α和β均为算法的超参数常数,zgn()⋅为向上取整函数。
3.4 集成模型的增量更新与预测
为了适应短文本数据流环境,模型增量更新机制如下:遍历数据块Dt的短文本,如果类标签Ltn∈R,则利用训练样本更新模型中第r个分类器的学习参数,则新建类标签的分类器并初始化权重与参数NPt、ZPt分别为0,并将放入R中,再利用训练样本更新当前参数,最后利用更新好的模型参数计算分类器新的特征权重并加入模型Ft。考虑到不同时间维度的数据块对模型贡献程度不一致,以及短文本数据流的概念漂移现象。本文在对当前模型进行更新的同时,引入时间因子作为权值,增大邻近数据块对模型参数的贡献量,从而缓解发生概念漂移时模型的准确率急速下降,具体如下:对当前数据块Dt,首先利用模型对其进行预测,获取模型对数据块Dt的准确度Acct,如果相比较之前准确率发生较大下滑,即Acct-1-Acct>θ;其中θ为漂移阈值,则增大当前数据块对模型的贡献量,使模型Ft适应可能在此发生的概念漂移环境,本文方法是利用当前数据块Dt重复更新模型Ft,直至Acct-1-Acct>θ。否则,执行下一个数据块Dt+1。算法2给出了整体的实现过程。
算法2模型更新与预测
1.UseF predictDtand calculateAcct
2.Iter=0/*初始化迭代次数*/
3.if(Acct-1-Acct)<θ:Iter=1
4.else:Iter=3
5.end if
6.iter=1
8. ifLn∉R:
9.InitializeNP andZP zero
10. Update Nt-1and Zt-1
11. AddLntoR
12. end if
13.end for
14.iter=iter+1,turn 6,untiliter>Iter
15.modify Nt-1and Zt-1to Ntand Zt
16.calculateWt+1
为了更好对未知短文本数据流进行预测,首先利用算法1获取词向量集合,向量化单词,将短文本转为文本向量;其次构建可扩展的增量式集成分类器模型,根据数据块类标签,动态增加分类器个数;然后通过每个短文本对模型权重进行增量式更新;最后预测未知短文本的类标签,并且根据预测短文本上下文更新扩展词向量集合。保证扩展词向量的实时更新。使得整个方法中的扩展词向量集合VecE,分类器模型随时间进行实时更新扩展,使得整个方法在短文本数据流的复杂环境下,仍能保证较高分类精度。
3.5 短文本数据流的分类方法分布式并行化实现框架
本节主要介绍本文所提的短文本数据流分类方法中模型训练的分布式并行化,模型更新与扩展Word2vec分布式并行化,其中以一个主节点Driver与三个子节点Node构成的集群为例。
3.5.1 分布式训练
本文方法主要利用数据同步并行的分布式训练策略[24]完成对模型的构建,分布式更新框架如图2所示。其中每个数据块数据将分布存储至各个子节点,以数据块Dt为例,首先Driver主节点将所有分类器的权重分发至所有的工作子节点Node,本文采用三个子节点,因此Dt划分成三份数据集合,即等待所有子节点的数据块训练完成之后,聚合每个节点处理的子集的权重更新量得到)可表示为 ||R 维的权值向量,记为其中表示对应分类器 ftr的LR权值集合,然后主节点执行一次参数的更新。
3.5.2 分布式预测与扩展word2vec
本文方法中模型预测与Word2vec扩展分布式化框架见图3。以在数据块Dt+1上的分布式预测为例,Dt+1划分成三份数据集合,即Dt+1={Dt+11,Dt+12,Dt+13},并根据3.2节描述的根据Word2vec训练的向量化集合对其向量化表示,得到短文本向量化表示Vec(Dt+11)、Vec(Dt+12)和Vec(Dt+13)。Driver主节点将集成分类器Ft分发至所有的子节点Node,等待子节点完成对短文本d(d∈Dt+1)的预测,并将子节点中的新词文本选择出来,获取所有子节点的预测信息与新词文本集合信息;然后主节点将预测信息输出,并聚合所有的新词文本集合以扩展Word2vec。
4 实验与分析
本章主要为了验证本文提出的短文本数据流分类算法的有效性,对比了本文所提算法与相关基准算法的分类结果,首先给出了所需的短文本数据流数据集与使用的相关基准算法,然后说明了实验有关的参数设置与性能评估参数,最后验证了本文所提的方法在短文本数据流分类上的有效性。

图2 分布式参数更新框架图

图3 分布式模型预测与扩展Word2vec框架
4.1 数据集
选择了三个公开的短文本数据集来验证本文所提算法的有效性,表1给出数据集的元数据信息。
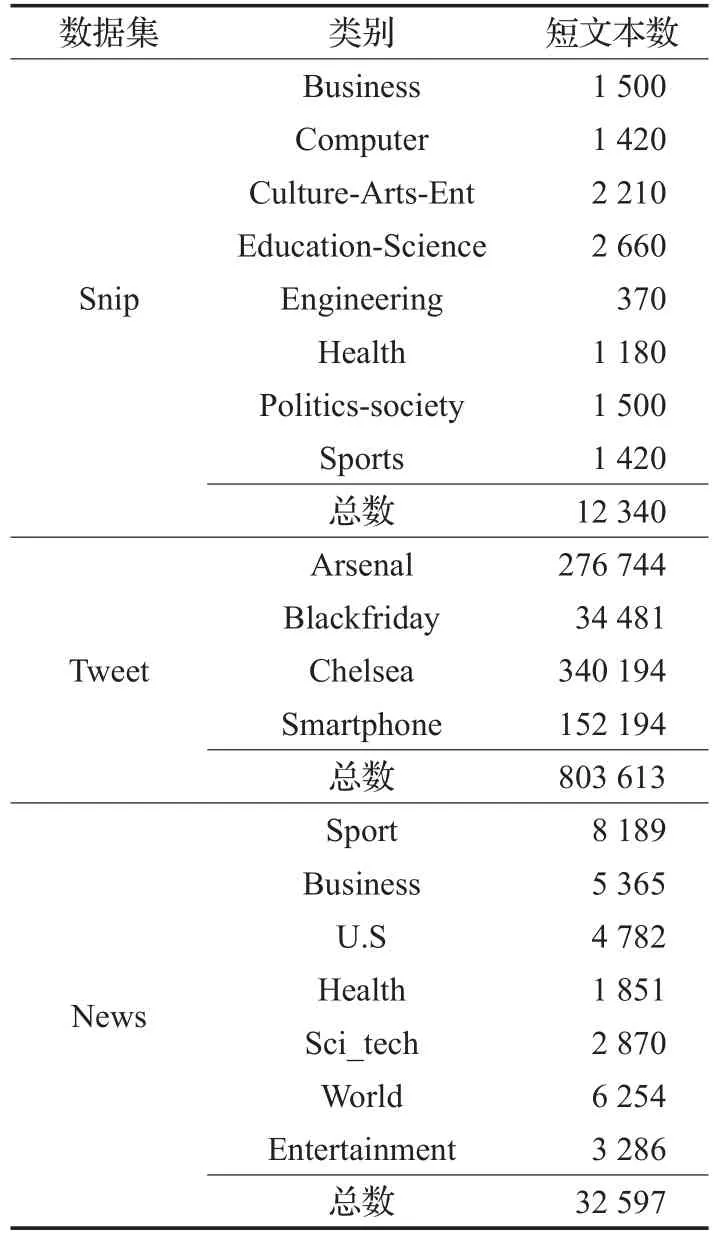
表1 数据集
(1)Tweet[25]数据集:借助推特API进行关键字追踪,从推特中获取的2012年11月到12月的推文数据总共4类。实验中仅使用2012年12月的推文,按时间顺序获得803 613条短文本数据。
(2)News数据集:来源于TagMyNews数据集,总共7类。获取短标题作为数据集,总共有32 597条短文本。
(3)Snip数据集:是将预设定的表达放在网络搜索引擎上搜索的结果,总共8个类别,12 340条短文本。
上述三个数据集均是通过分词、去停用词、过滤特殊字符等预处理之后得到的。同时为了验证本文算法能够很好地抵抗概念漂移,重新修改了News与Snip数据集的上下文顺序,使得数据块与数据块之间人为发生概念漂移,并根据数据集大小设置数据块切分区间。
4.2 基准算法
本节给出了目前主流的2个短文本分类框架:fastText与sk-learn,以及一个短文本数据流分类算法:扩展onlineBTM,用于验证本文提出的增量式短文本数据流分类算法的有效性,表2为上述分类算法的主要信息。其中fastText与sk-learn源码均来源于相关官网,扩展onlineBTM来源于文献[3]。本文基于Word2vec增量式分类模型用ICM-Wordvec表示。

表2 基准算法
4.3 参数设置与评估标准
本节通过获取模型对测试样本预测的增量准确率来衡量模型对短文本数据流分类的有效性。利用滑动窗口将数据流划分为数据块进行处理,获取邻近数据块来更新或替换模型,计算对当前测试数据块的增量分类精度作为性能评估参数。其中增量分类精度计算见式(6):

其中,Inc-acct为模型对第t个数据块的增量分类精度,acci为模型对第i个数据块的分类精度。
本文中ICM-Word2vec方法的特征维数为200,增量式学习算法中超参数λ1、λ2、α、β分别为0.01、0.01、0.016、0.01;基准算法利用前K个最邻近数据块对下个数据块进行进行预测,其中K=4。数据集News与Snip中数据块大小设置为100,而Tweet数据集由于数据样本大,将数据块大小设为1 000。最后基准实验fastText,sk-learn(LR),E.Drift-ensenmble在Core i7 4核处理器,频率为2.80 GHz和8 GB内存的centos7 VM虚拟机上实现。本文方法ICM-Word2vec在集群上利用spark2.4.0与scala2.11进行实验。其中集群由一个驱动节点(Core i7处理器CPU-1核,频率为2.80 GHz,1 GB内存)与四个工作节点(Core i7处理器 CPU-2核,频率为2.80 GHz,4 GB内存)构成。
4.4 实验结果与分析
本节主要验证了与基准对比算法相比,本文的ICM-Word2vec方法在短文本数据流分类上的有效性。
4.4.1 分类性能对比
图4和图5给出了本文方法ICM-Word2vec与基准算法在三个数据集上的分类精度与增量分类精度的实验结果。由于第一个数据块没有训练数据块从而无法预测,故下面所有的数据块的下标都进行了减1操作。由实验结果可知:(1)fastText在Tweet数据集上较其他两个数据集有较好分类精度,因为fastText适合于大量训练数据,类标签较少的场景;并且算法fastText的分类精度在时间上发生剧烈波动,因为算法没有考虑文本数据流中概念漂移。(2)E.Drift-ensenmble算法在 News、Snip两个数据集具有较好的分类精度而在Tweet数据集却发生精度下降,主要由于Tweet相邻数据块之间类别分布差异较大,而其他两个数据集中类别分布较均匀。并且E.Drift-ensenmble算法在维持算法精度的稳定性的同时,导致了一定精度的降低。(3)sk-learn在三个数据集上的分类精度都较低,由于sk-learn没有对短文本中存在的信息稀疏问题进行处理,同时没有考虑数据流中存在的概念漂移。从而导致在数据集上的分类精度较低,并且分类精度随时间发生剧烈波动。(4)本文所提出的ICM-Word2vec短文本数据流分类算法在增量分类精度与分类精度上都优于其他三个基准算法,由于本文方法并没有利用最邻近的方式构建分类模型,而是通过利用所有的数据样本维护模型参数NP、ZP,通过模型参数更新模型,充分利用所有历史数据样本,并且本文方法通过引入时间因子,以及扩展Word2vec的手段,使本文的分类精度较稳定,通过实验结果可知本文的模型稳定性与E.Drift-ensenmble算法相当,明显优于其他两个算法,在Tweet数据集上表现尤为明显,并且分类精度也略优于E.Drift-ensenmble算法。
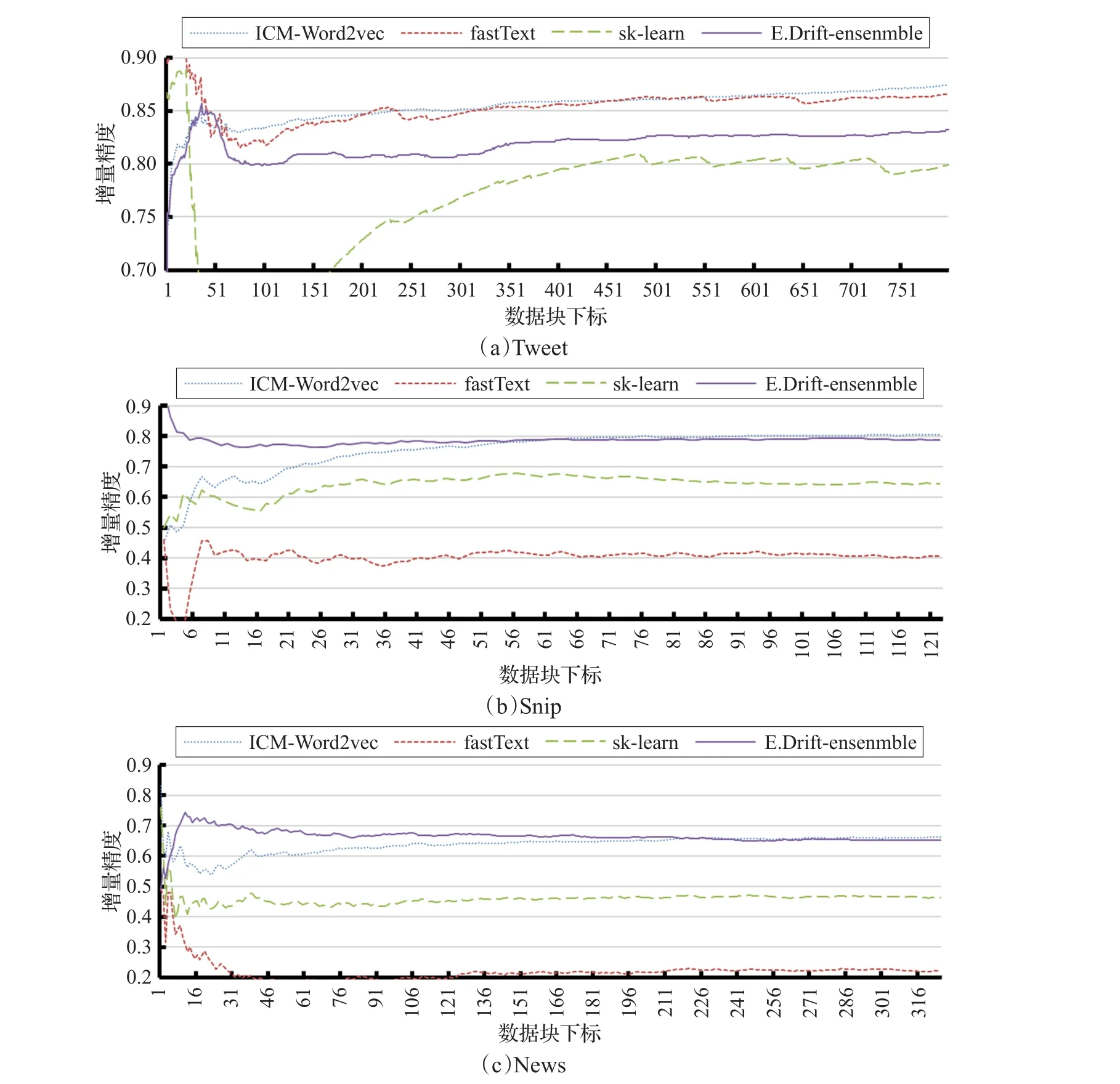
图4 ICM-Word2vec与基准算法在增量式分类精度上的比较

图5 ICM-Word2vec与基准算法在分类精度上的比较
4.4.2 时间性能对比
图6对比了ICM-Word2vec算法与基准算法的时间消耗,由实验结果可知:在Snip与News数据集上ICMWord2vec时间消耗与E.Drift-ensenmble算法相当,甚至还高,这是因为当数据样本较少时,Spark集群的每次任务中资源调度、信息通信以及并行化的额外开销将占整个时间的较大比重,导致时间消耗不低于E.Driftensenmble。当数据量大时,本文方法时间消耗远低于E.Drift-ensenmble算法。在Tweet数据集上实验也表明这一特点,E.Drift-ensenmble算法在Tweet数据集上的时间消耗急剧上升,而ICM-Word2vec的时间消耗并没有明显加大。其中fastText与sk-learn在三个数据集的时间消耗远低于ICM-Word2vec与E.Drift-ensenmble算法。这是由于fastText与sk-learn算法在训练数据时并没有对短文本的高维稀疏性进行扩展,也没有对数据流中存在的概念漂移现象进行处理,而ICM-Word2vec与E.Drift-ensenmble对短文本分类中存在的问题进行有效的处理,导致时间消耗增加。fastText与sk-learn算法虽然其时间开销明显减少,但模型分类精度却严重下降。无法对短文本进行高质量的预测。
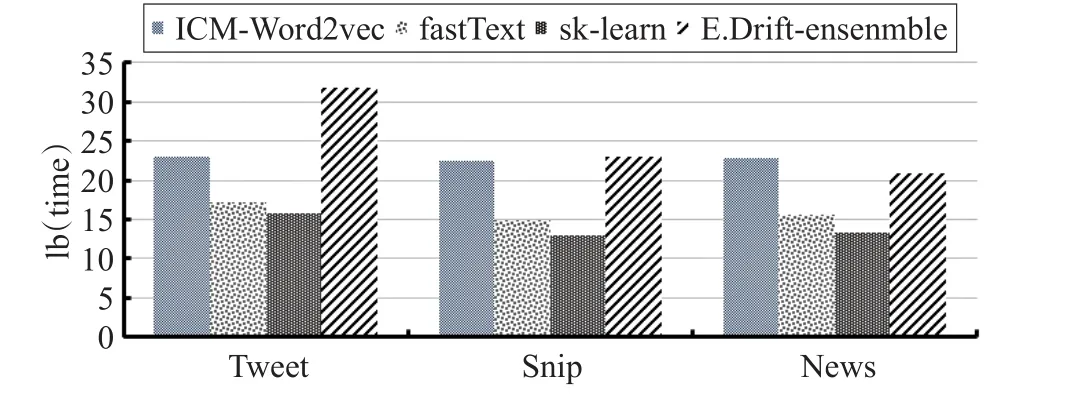
图6 ICM-Word2vec与基准算法在时间上的比较
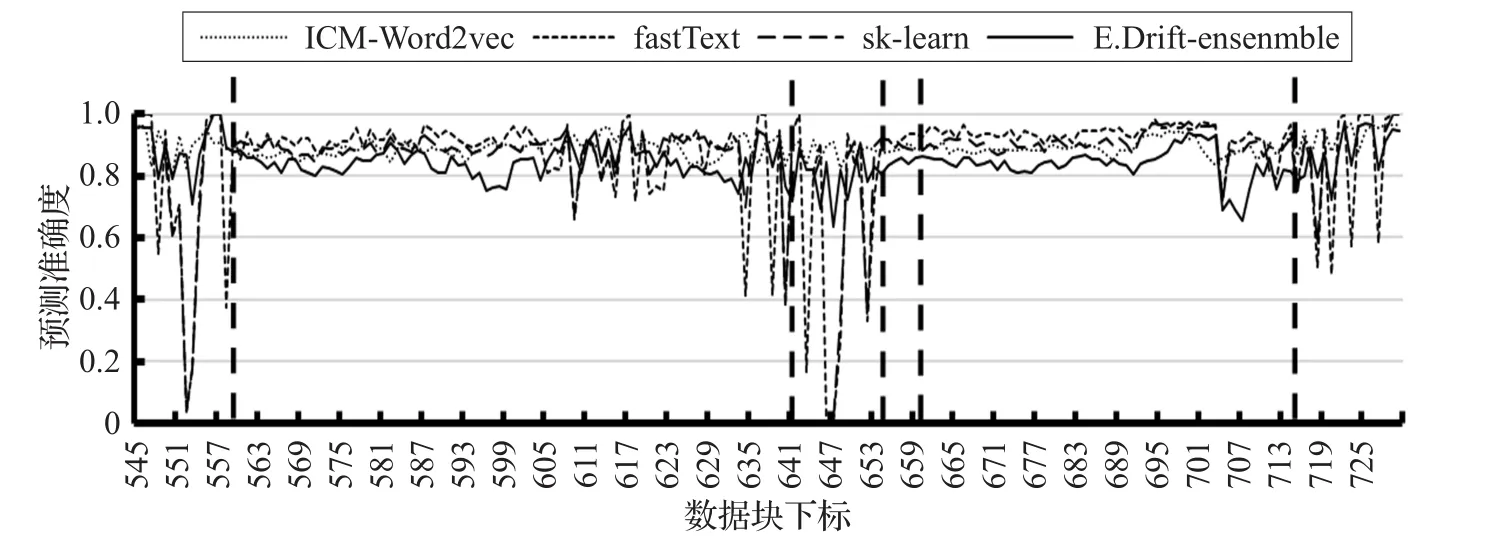
图7 ICM-Word2vec与基准算法在概念漂移上的比较
4.4.3 时间适应概念漂移的性能对比
图7表明了ICM-Word2vec算法与基准算法在时间序列上对短文本数据流中的概念漂移的适应能力。由实验结果可知:与基准算法相比,ICM-Word2vec算法能很好地适应概念漂移环境,在发生概念漂移的数据块能够较好地稳定分类精度。主要是因为数据流中概念漂移是在已知概念中进行漂移,并未产生新的概念,而基准算法主要是通过最邻近数据块机制构建模型,无法很快适应概念漂移环境,ICM-Word2vec算法是利用历史信息并引入时间因子增量式更新模型,故能较好地保持分类精度。E.Drift-ensenmble是在发生概念漂移时,选择与发生漂移的数据块具有类似主题分布的数据块进行模型构建来适应概念漂移环境。
5 结束语
本文提出了一种基于Spark的分布式快速短文本数据流分类方法。首先用外部语料库来构建Word2vec模型,用词向量来表示单词;在训练中,获取并更新新词向量进行词向量集合扩展;其次,为了能够很好地抵抗概念漂移,引入了时间因子来计算邻近数据块对模型的贡献值;同时,使用FTRL算法计算多个线性分类器的特征权重以构建集成模型来对未知数据块进行预测。整个模型运行于大数据处理平台Spark上,并进行分布式并行化对方法进行加速;最后,广泛的结果表明,与传统方法相比,本文方法可以在短文本数据流分类和抵抗概念漂移中获得更好的性能。然而,本文方法在处理数据集规模较小的情况下,不具有时间优势,因此,如何处理缺失数据集以获得更好的分类性能是未来工作的方向。致谢 在论文完成之际,特此感谢合肥工业大学计算机与信息学院任恒同学在论文代码实现上的贡献。
