基于FasterMDNet的 视频目标跟踪算法
2020-07-17李岩芳
王 玲,王 辉,王 鹏,李岩芳
长春理工大学 计算机科学技术学院,长春 130022
1 引言
视频目标跟踪是计算机视觉的重要研究课题,目的是估计目标在各种场景下的位置,它在视频监控、机器人、人机交互[1]等方面具有广泛应用。人们可以很容易地选择有用特征来区分目标和背景。然而,视频目标跟踪由于复杂的背景干扰,如目标缺失、遮挡、天气、光照以及人为因素等,成为计算机视频跟踪领域最难解决的问题之一。目标跟踪模型一般归于两类:生成式模型和判别式模型,生成式模型主要通过学习目标外观模型,然后以此为模板在搜索区内进行最小化重构误差的模式匹配,从而实现目标跟踪。Tao等人[2]提出的具有代表性的生成式模型,通过引入孪生网络,计算目标外观模型的表示误差,选择与目标模型最接近的区域作为跟踪结果;Zhang等人[3]利用循环稀疏结构模板和傅里叶变换增大样本空间,以此提高跟踪速度。判别式模型主要把跟踪问题看成二分类问题,通过训练图像序列区分目标和背景。经典的判别式跟踪算法代表有KCF[4]、C-COT[5]、Staple[6],在标准视频跟踪上取得了较好的效果。近年卷积神经网络(CNN)在目标检测和识别方面取得巨大成功,基于CNN的目标跟踪算法属于判别式方法[7]。但上述模型存在问题是,目标跟踪速度提高的同时准确率不高,而准确率提高的同时速度不高。
MDNet[8]提出了一种新的CNN架构,通过学习不同视频图像序列的通用目标进行目标跟踪,并具有很好的跟踪准确率。但是,它的网络结构具有明显的缺陷:它采用选择性搜索的方式对视频图像提取ROI,然后分别将候选框输入网络提取特征,增加计算复杂度,没有共享完整图像卷积特征,采用选择性搜索的方式还导致产生很多对训练网络模型没有作用的ROI,跟踪速度和准确性均受到影响。
本研究针对上述问题提出了快速多域卷积神经网络(FasterMDNet),在模型中加入RPN网络和ROIAlign层,将整张图像作为输入来提取特征,卷积层输出的完整特征图作为RPN网络的输入,采用滑动窗口的形式在整张特征图上提取ROI,然后在ROIAlign层利用双线性插值[9]对每个ROI提取特征,最后池化成固定大小的特征图,将其送入全连接层进行视频目标跟踪性能评估。
2 相关工作
2.1 基于CNN目标检测
基于区域建议候选框卷积神经网络的提出使目标检测取得巨大成功,R-CNN[10]第一次将CNN网络应用在目标检测中并达到很高的准确率,它利用深度网络在少量的检测数据中训练很高的特征表示模型,从而高效地实现目标的定位性能。但R-CNN采用选择性搜索的方式提取ROI,没有共享图像卷积特征,对每个ROI单独提取特征,重复输入到卷积层进行计算,增加了计算复杂度。Fast R-CNN[11]通过使用ROIPooling层把大小不同的ROI特征映射成一个固定尺度的特征向量的方式,达到共享图像卷积特征的目的从而减少了计算的复杂度,但是由于候选框的选取仍采用了选择性搜索的方式,大部分时间都消耗在ROI的提取上。Faster R-CNN[12]很好地解决了Fast R-CNN的问题,通过加入RPN网络,对整张图像特征提取ROI,然后通过ROIPooling的方式固定ROI特征大小,很大程度上减少了计算复杂度,提高网络模型性能。
2.2 基于CNN目标跟踪
基于CNN的网络模型在计算机视觉中展现了杰出的特征表示能力,目前最新的相关滤波技术通过融合深层神经网络学习表示,达到很好的跟踪性能。Song等人[13]提出将特征提取、模型更新集成到神经网络中进行端到端的训练,采用残差学习减少在线模型更新退化,达到不错的跟踪效果;Danelljan等人[14]提出通过分解卷积因子,减少模型参数,通过训练紧凑的样本数据和保守的模型更新策略,降低模型计算复杂度,提高跟踪速度。目前基于CNN的大部分跟踪算法在跟踪准确率上是成功的,但是由于多样本特征计算、模型反向传播更新、深度学习提取特征等使计算复杂性很大,导致计算成本大大提高。所以出现了一些基于CNN的离线训练,在线不更新的目标跟踪模型[15-16],但跟踪准确率较低。MDNet通过利用自然语言处理中广泛采取的多域学习,对CNN进行离线训练和在线模型更新,通过学习多域信息最后整合多域信息特征表示,取得很好的跟踪效果。
3 快速多域卷积神经网络(FasterMDNet)
本章详细介绍改进的MDNet网络结构,在它的网络结构中通过引入RPN和ROIAlign层,从而加快候选区域建议框特征的提取,降低特征空间信息量化损失,改进的MDNet网络结构在保持跟踪准确率提高的同时并加快特征提取以提高跟踪速度。
3.1 网络架构
改进的快速多域卷积神经网络(FasterMDNet)网络模型架构如图1所示。网络中有三个卷积层用来提取整张图片的特征,通道依次为96、256、512;RPN网络层用来在图片的特征图上提取ROI,512-d表示输入特征为512个通道,网络内部输出一个2分类分支和一个4位置边框回归信息分支,k表示RPN定义的每个锚点产生k个锚盒;ROIAlign层对ROI进行特征提取,将得到的特征作为全连接层的输入,RPN网络层和ROIAlign层的输入和输出如表1所示;网络中共有三个全连接层用于二分类,区分目标和背景,前两个全连接层(FC4、FC5)表示目标和背景特征,输出均为512个单元,第三个全连接层(FC61~FC6k)表示多域层,具有k个域分支,每个视频序列对应一个域,训练期间用于学习区分目标和背景,其中红色表示目标,黄色表示背景。

表1 RPN网络层和ROIAlign层输入和输出
3.2 RPN网络
RPN网络将最后一层卷积层的输出作为输入,输出一组不同大小矩形目标框。网络由相关部分和监督部分组成,监督部分有两个分支,一个是目标和背景分类分支,一个是边框回归分支;相关部分是将特征通道各自通过两个卷积层增加到两个分支上。如图2所示,在FasterMDNet网络中,对每个视频序列中第一帧图片进行两次输入提取特征处理,第一次输入选取原图像作为输入,用W表示,第二次根据第一次输入选取与原图像重叠域最大的ROI作为RPN的输入,用Q表示,两次输入共享CNN参数。把第一次输入提取得到的最后一层卷积特征用α(W)表示,第二次输入特征用α(Q)表示。对于RPN网络如果有k个锚盒则会输出2k个分类通道和4k个边框回归通道,α(Q)输入到RPN网络中分别通过两个卷积层增加到两个分支上,两个分支由[α(Q)]cls和[α(Q)]reg表示,它们分别有2k和4k个通道,相应的α(W)特征的两个分支由 [α(W)]cls和 [α(W)]reg表示,但通道倍数不变,保持一个2分类通道,一个4位置边框回归通道。[α(Q)]以组的方式作为[α(W)]的相关滤波器,得到分类分支和边框回归分支的计算公式为:

第二次输入得到的特征图[α(Q)]cls和[α(Q)]reg作为内核,其中⊗表示卷积符号。例如公式(1)包含2k个通道向量,表示每个锚盒在原图上映射的正样本和负样本,包含 4k通道向量,表示预测目标位置 (εx,εy,εw,εh),其中 (εx,εy)表示预测目标包围框中心点坐标,(εw,εh)表示目标包围框宽和高。
MDNet损失函数仅能区分相同视频域中目标和背景,不能区分不同视频域中目标和背景,在对网络上多个锚盒进行训练时,本文的损失函数遵循FasterR-CNN,分类损失函数采用交叉熵分类损失函数,回归损失函数采用smooth L1和归一化坐标的方式。用 (βx,βy,βw,βh)表示锚盒真实位置,归一化距离为:
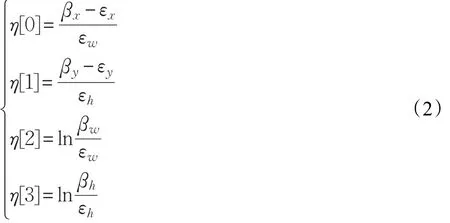
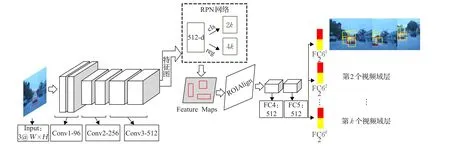
图1 FasterMDNet网络模型架构图

图2 RPN网络第一帧两次输入结构图
优化的损失函数为:

其中,Lcls为交叉损失熵函数,θ为平衡两部分的超参数,Lreg定义为:

smooth L1损失函数为:

3.3 ROIAlign
本文网络还有一个ROIAlign层,ROIPooling是一个粗量化的特征信息提取方法,它是从每个ROI中提取小特征的标准操作,对ROI提取特征时需要两次空间量化信息操作,为了消除ROIPooling量化操作,在网络中引入ROIAlign层,利用双线性插值的方法正确地将提取特征与输入对齐。取消ROIPooling在第一步和第二步执行量化时将浮点数四舍五入取整操作,使用双线性插值的方法计算每个ROI单元中四个采样位置输入的精确要素值。ROIAlign具体实现如下,已知要被池化的目标位置(dstx,dsty),根据公式:

求其被池化前在原图的位置(srcx,srcy),srcwidth,srcheigh和dstwidth,dstheigh分别表示原图和目标图的大小。求得原图位置是一个浮点数,由此可得四个位置坐标Q1,Q2,Q3,Q4。根据图3先对X轴方向R1,R2进行插值,再对Y轴方向P点进行插值,得到像素点计算公式f,所以可得本研究目标图像素F(dstx,dsty)计算公式为:

通过减少特征图空间信息的量化损失,从而获取更高分辨率和含有丰富语义的特征信息表示。

图3 双线性插值
4 FasterMDNet训练和跟踪
4.1 网络初始化与输入输出
网络中输入的图片大小为107×107,共享卷积层权重从VGG-M[17]网络相对应部分传递,RPN采用3×3的滑动窗口,在最后一层卷积层输出特征图上进行滑动,滑动窗口中心定义为锚点,每个锚点产生k个锚盒,每个锚盒对应一个二分类分支和一个边框回归的四位置信息分支,所以k个锚盒有2k个二分类通道和4k个边框回归通道,通过对锚盒进行筛除,输出ROI。根据本文的网络设置,ROIAlign层会产生一个7×7×512的特征图,并用一个最大池化层将特征映射为3×3×512,然后输入全连接层为512个单元特征图,最后由第三个全连接层评估目标位置最优得分并输出跟踪目标。
4.2 离线训练
使用在ImageNet-Vid[18]上预先训练好的网络参数来初始化本文网络,本文网络离线训练时对于每个视频序列第一帧使用RPN来提取ROI特征,需要两次输入处理,从而获得更高特征语义信息表示。采用随机梯度(SGD)的方式在大量的标准目标跟踪视频数据集上对FasterMDNet网络实现端到端的离线预训练。使用的锚盒固定比为[0.3,0.5,1,2,3],用锚盒与实际边界框的重叠最高交并比(IoU)和两个参数thhi和thlo作为测量标准。当IoU>thhi作为正样本,IoU FasterMDNet完成网络预训练后,需要将最后一个全连接层(FC61~FC6k)的多个分支由单个分支FC6替代,训练阶段的目的是学习目标表示用于目标跟踪,在线微调跟踪时每个测试视频序列第1帧,根据离线训练中IoU标准,在第一帧选取500个正样本和5 000个负样本,从第2帧开始收集每帧跟踪后的数据,用于在线更新的训练数据,然后根据IoU标准大于0.7为正样本,小于0.3的为负样本,最后收集50个正样本和200个负样本,从第1帧到第n帧正负样本结果展示如表2所示,每10帧进行一次长期更新模型,然后由RPN输出最后收集的正负样本,ROIAlign对样本提取ROI特征,将特征作为输入送进全连接层,通过网络进行评估,最后由对应的视频域全连接层softmax层输出目标分数f+(xi)和背景分数 f-(xi),其中i=1,2,…,N,xi表示第i帧目标状态,网络第i帧目标最大得分为: 表2 正负样本展示 FasterMDNet在线跟踪算法伪代码: 算法1 FasterMDNet算法 输入:预训练好的FasterMDNet卷积权重{w1,w2,w3,w4,w5}、RPN网络,初始化目标状态x1。 输出:预测帧输出之后目标状态x*。 1.随机初始化最后特定域层权重为w6 2.训练边界框回归模型 3.if(i==1) 4.输出第1帧图像卷积特征α(W)和α(Q) 5. else if 6.输出第2帧和之后图像卷积特征α(Wλ) 7. RPN由第4步或第6步结果输出ROI为Si 11.重复步骤3~9 12.绘制目标候选样本状态xi 14. if f+()≥0.5 then 22. end for 23.直到视频序列结束 24.end for 为了保证模型的健壮性和自适应性,采用长期更新和短期更新,长周期收集的正样本定期应用于长期更新,当目标估计分数低于定义域值并且结果不可靠时(目标得分小于0.5),就会触发短期正样本更新。然而,在本文网络中正样本数量远小于负样本数量,很多负样本通常是不重要或是冗余的,在每一次迭代中通过采用难例小批量挖掘技术在得到的负样本中选取得分最高的一部分作为困难负样本,然后把得到的困难负样本放进网络中不断进行迭代训练,加强网络辨别能力。一个小批量样本是由128个样本组成,其中有32个正样本和96个负样本,采用难例小批次挖掘方式进行迭代学习,将1 024个负样本作为测试。 在快速多域卷积神经网络中,采用随机梯度下降(SGD)方法进行1 000次迭代训练,网络离线训练期间将卷积层的学习率设置为0.000 1,在线跟踪时迭代的损失函数变化值如图4所示,优化后图4(b)的损失函数比优化前的损失函数图4(a)值更小,很小的误差值变化会对目标跟踪结果产生很大的影响。训练时,先对每个视频序列初始化第一帧,然后全连接层FC4、FC5和FC6 30次迭代的学习率前者是0.000 1,后者是前者10倍。网络在线跟踪期间,微调迭代次数设置为15,学习率设置为网络离线训练期间全连接层FC4、FC5学习率的3倍,在线跟踪期间网络全连接层FC4、FC5和FC6为10次迭代,其学习率分别设置为0.000 3和0.003,权重损失因子和动量分别设置为0.000 5和0.9。 图4 在线跟踪损失函数变化值 本文算法的跟踪性能是在三种标准数据集上进行测试的,数据集分别是OTB2013[19]、OTB100[20]、VOT2016[21],前两个数据集包含51个视频序列和100个视频序列,它们都被地面真实距离包围框和各种属性注释,后一个数据集包含60个视频序列。本文的实验环境是在Matlab R2017b,MatConvNet1.0-beta10,CUDA9.0,CUDNN7.5,Visual Studio2015,Intel®CoreTMi5-7500CPU@3.40 GHz,NVIDIA Quadro K60。 OTB视频性能评估的标准有两个,一个是中心定位误差即精确率,一个是包围框重叠比即成功率。图5、图6分别是在OTB2013和OTB100进行测试的结果。 从图5和图6中可以看出,选择了与当前目标跟踪较好的算法 C-COT、STRCF[22]、DeepSTRCF[22]、ECO[14]、BACF[23]、DSST[24]、Staple、KCF、MDNet结果作对比。 表3表示使用双线性插值前后在OTB数据集上目标的跟踪结果和感受野分辨率变化值,可以看出插值前后感受野分辨率值相差不大,但较小的感受野分辨率差别对目标跟踪算法准确率和成功率有很大的影响。 表3 双线性插值前后目标跟踪结果和感受野分辨率值变化 图7展示了不同跟踪算法在几种具有挑战性的OTB数据集上实时跟踪结果,在光照变化、复杂背景、尺度变化下本文的跟踪算法效果优于其他跟踪算法。 图5 OTB2013目标跟踪结果 图6 OTB100目标跟踪结果 图7 几种具有挑战环境下实时目标跟踪 由实验结果可知:(1)本文算法在OTB2013数据集上精确率达到95.0%,成功率达到70.2%,在OTB100数据集上精确率为92.5%,成功率为69.6%,对比MDNet分别提高7%、1.2%、2.5%、2.8%。(2)从图5(a)、图6(a)中看出,本文算法在两个评估跟踪性能标准上均明显高于其他测试跟踪算法,在像素阈值设置为30时,表明本文算法跟踪目标效果很稳定。(3)图5(b)、图6(b)可以看出随着重叠阈值设置变大,跟踪成功率变小,但当重叠阈值设置为一样时本文算法跟踪效果优于其他方法。(4)重叠阈值≤0.5时,本文跟踪算法成功率开始趋于下降趋势,其他测试算法也是如此,这是目前跟踪算法存在的缺陷。 VOT2016包含60个具有挑战性的视频序列,性能评估主要有4个指标,报告准确性表示跟踪边框重叠率;鲁棒性表示发生故障次数;预期平均重叠率表示跟踪一定帧之后下一帧跟踪成功的几率;成功率则类似OTB评估标准中的AUC(成功率图)。通过上面4个指标更加全面评估跟踪算法性能。与C-COT、Staple、STAPLEp[21]、SiamRPN[25]、DeepSRDCF[26]、MDNet 6 种较好的跟踪算法性能做对比。 从表4看出本文跟踪算法相比于其他测试算法在VOT2016数据集上跟踪性能具有较明显优势,特别是与MDNet算法比较,跟踪准确率提高8.04%,鲁棒性也优于MDNet算法,降低了27%。本文算法的跟踪帧率为15帧/s,虽然比其他速度快的跟踪算法慢,但相比于MDNet算法的跟踪速度提高了近12倍,并且本文算法的预期平均重叠率为33.10%,如图8所示,优于其他算法。通过实验证明本文算法的有效性。 表4 不同跟踪算法在VOT2016上精确度和鲁棒性得分,跟踪算法帧率以及预期重叠率对比表 图8 预期重叠率从右到左(Order为对应算法) 图9 中趋势展示了本文算法在阈值为0.7之前都是优于其他算法,在0.7之后具有明显下降趋势,这是因为CNN自身存在的缺陷,当重叠阈值设置过大时容易丢失跟踪目标。 图9 不同重叠阈值下平均成功率 在三种标准的视频数据集上,证明了本文算法的跟踪性能均优于MDNet算法,并且跟踪速度达到15 FPS,充分说明了对MDNet算法改进的有效性。通过引入RPN网络加快ROI的产生,加入ROIAlign层,采用双线性插值的方法对ROI提取特征,减少空间信息量损失,从而获得更显著的信息特征表示。实验证明,提出的FasterMDNet网络结构是合理的。虽然FasterMDNet的算法速度比MDNet算法提高12倍,但对比其他速度快的算法优势并不明显,这将是今后着重研究的方向。4.3 在线跟踪



4.4 在线模型更新
4.5 网络学习
5 实验
5.1 实验环境

5.2 评估OTB数据集




5.3 评估VOT2016数据集



6 结语
