集成FM 的短视频喜好率预测模型
2020-07-17王丽苗许青林姜文超符基高
王丽苗,许青林,姜文超,符基高
广东工业大学 计算机学院,广州 510006
1 引言
随着以智能手机为代表的各类智能化移动终端的日益普及,移动互联网广告行业得到了迅猛的发展,尤其是移动短视频广告。根据QuestMobile发布的数据,截止2017年9月,中国短视频的用户数突破3亿,同比增长94.1%;而移动短视频广告的喜好率也远高于其他形式的广告。喜好率(Like-Through Rate,LTR)是衡量移动短视频广告投放效果的重要指标。通过对移动短视频广告的分析与预测,不仅能够让用户浏览到自己感兴趣的视频,改善用户体验,还能辅助广告主合理使用预算,将广告精准传递给目标人群,同时提高移动媒体的网站收益。
近年来,喜好率和点击率预测等相关问题的研究已取得了大量的进展[1]。目前工业界应用最广泛的预测方法是利用逻辑回归(Logistic Regression,LR)来学习点击率预测模型[2-4]。LR的优点是简单、非常容易实现大规模实时并行处理,但是线性模型的学习能力有限,不能捕获高阶特征携带的信息(非线性信息)[5],从而限制了LR的预测性能。Joachims[6]提出用支持向量机(Support Vector Machine,SVM)模型预测广告点击率,能够有效地处理多维非线性数据,但无法对大数据量的稀疏广告进行预测。Lee等人[7]从媒体、用户和广告主三方角度出发,对数据进行分层建模来缓解数据稀疏性,进而提高展示广告转化率预测的准确性。Shen等人[8]提出了基于协同过滤和张量分解的点击率预测模型。该模型根据用户、查询和文档的关系来挖掘用户的个性化偏好,以提升预测精度。匡俊等人[9]使用矩阵分解等方法生成交叉特征,通过将用户特征和视频特征进行交叉组合,来提高模型的精度。潘书敏等人[10]提出了USFD模型来对广告点击率进行预测,该模型从用户的角度出发,对具有相似特征的用户进行建模分析,挖掘特征差异对用户点击行为的影响,来提高点击率预测精度。Rendle[11]结合支持向量机(SVM)和分解模型的优点,提出了一种因子分解机(Factorization Machines,FM)模型,FM使用分解参数模拟变量之间的所有交互,可以在非常稀疏的数据下进行参数估计,相比于SVM有较好的预测质量,此外,FM是一种可以与任何实值特征向量一起使用的通用预测器。朱志北等[12]提出的LDA-FMS模型预测广告点击率,能有效地解决广告和用户数据量大且数据稀疏的问题,但是其没有考虑特征工程的成本和时间。田嫦丽等[13]提出了一种基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)模型的高影响力特征提取方法。使用该方法降低了特征提取的人工和时间成本,具有很好的参考意义。
此外,随着神经网络和深度学习[14]的不断发展,刘梦娟等人[15]提出了能够融合不同结构的神经网络来学习特征的高阶表示,来提高模型精度;张志强等人[16]使用张量分解和神经网络来解决广告数据的稀疏性问题和非线性关系。深度学习方法的主要劣势在于可解释性差,训练过程较为复杂,训练耗时较长。
基于以上分析,本文从移动短视频广告的多主题性质出发,针对特征工程费时费力问题,采用集成的思想,提出了基于LDA-GBDT-FM的短视频喜好率预测模型。该模型的主要贡献如下:(1)利用LDA对原有训练集进行基于主题的分割,分割生成的每个子训练集显著小于原始训练集,在一定程度上降低了计算复杂度。(2)对不同主题下的训练集采用GBDT模型进行特征的自动选择以及特征的非线性转换,减少基线算法中人工特征工程对时间和人力的依赖。(3)利用因子分解机非线性模型,可有效解决数据的高度稀疏问题。(4)通过集成不同主题的预测结果,进而提高预测精度。实验证明基于LDA-GBDT-FM模型能有效提高预测短视频点击事件的准确率。
2 LDA-GBDT-FM短视频喜好率预测模型
短视频本身具有多主题的性质,即一个短视频可以对应多个主题。本文从短视频标题本身的潜在语义出发,充分利用短视频的多主题性,提出一种基于LDAGBDT-FM的短视频喜好率预测模型。图1表示短视频喜好率的预测框架。

图1 LDA-GBDT-FM模型结构图
如图1所示,首先利用LDA主题模型对短视频标题进行建模,得到短视频的主题分布,再对原始训练集进行基于主题的分割,得到不同主题下的子训练集,在每个子训练集上,利用GBDT提取连续型特征的高影响力特征,再将提取到的高影响力特征与离散型特征合并后进行独热编码,训练FM并建立子模型,最后利用合成策略将子模型集成得到最终的预测。
2.1 LDA算法建模生成不同主题的子训练集
(1)短视频标题集建模
对短视频标题集进行LDA[17]建模,利用吉布斯抽样算法(Gibbssampling)学习得到短视频主题分布β,如式(1)所示:

其中,βnk表示短视频n属于主题k的概率,即:

本文将βnk称为短视频n与主题k的相关度。
(2)分割短视频训练数据集
利用短视频主题分布β将训练集分成不同主题的子训练集。
定义1(短视频主题相关阈值)当n与k的相关度βnk大于σ(0≤σ<1)时,表示n属于k,σ称为短视频主题相关阈值。
假设有K个主题,则n属于k的平均概率为1/K,当βnk大于1/K时,则说明n与k的相关度较大。因此在LDA-GBDT-FM模型中,将σ设为平均概率,即σ=1/K。
分割思想如下:对短视频训练数据集D进行遍历,查看每条数据的短视频主题分布βnk,若大于σ,则将n存到相应的子训练集dk中。应当注意,因为短视频具有多主题性,对于同一个短视频,其相关度大于σ的主题会不止一个,因此,不同主题的子训练集中可能具有相同的短视频数据。
2.2 利用GBDT提取高影响力特征
分割短视频训练数据集D后,得到不同主题的子训练集d1,d2,…,dk。利用GBDT对每个子训练集中的连续特征提取高影响力特征。GBDT是由Friedman J H[18]在2000年提出的一种非线性模型,它采用的是Boosting集成学习方法[19],每次迭代都在残差减少的梯度方向新建立一棵决策树,即最终迭代次数与决策树的数目相等,决策树的叶子节点可以直接作为特征向量的一个维度。GBDT的这种思想使其具备很大优势,发现多种有区分性的特征和特征组合,构造的高影响力特征可以直接作为预估模型输入特征,节约人工成本,提高效率。图2表示使用GBDT前后的特征选择示意图,融合前人工发掘有区分度的特征,融合后直接通过GBDT非线性模型提取高影响力特征。

图2 使用GBDT前后的特征选择示意图
2.3 训练不同主题下的喜好率预测模型
本文使用FM作为短视频喜好率的预测模型。FM因子分解机可以使用分解参数模拟不同类型变量间的所有交互,并且可对任意实值向量进行预测,因此,FM在面对高度稀疏数据时具有较高的预测精度。
在短视频喜好率预测的背景下,本文将GBDT提取到的高影响力特征与离散型特征合并后进行独热编码后,作为FM的输入,对输入的特征向量进行两两因子分解,短视频的喜好率作为输出,短视频喜好率预测模型如式(2)所示:

其中,xi为第i个特征的值,n是短视频特征的维度,w0∈R为全局偏差,wi∈Rn是第i个特征的影响因子,V∈Rn×h为互异特征分量之间的交互参数。 Vi,Vj表示的是两个维度为h的向量Vi和向量Vj的点积:

其中,Vi表示的是系数矩阵V的第i维向量,且Vi=是超参数。

本文采用随机梯度下降(Stochastic Gradient Descent,SGD)的方法对FM模型进行参数计算。该方法通过最小化每条样本的损失函数来达到目的,为了防止参数过多而导致的过拟合问题,在优化函数中加入正则化项L2范式,其定义如下:
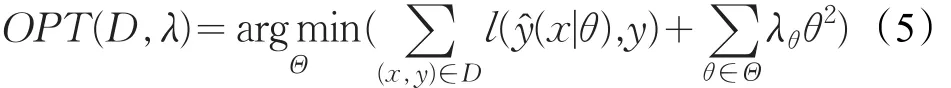
其中,l(y1,y2)=(y1-y2)2为最小平方损失函数。
SGD通过遍历训练集中的每条数据并按照一定的学习率沿着负梯度方向更新参数,直至收敛,参数更新方法如下:

其中,α∈R+为学习速率.。
2.4 短视频喜好率预测
短视频喜好率预测过程中,充分考虑短视频的多主题性,先利用2.3节中训练得到的喜好率预测模型分别计算每个主题的短视频喜好率;再将2.1节中得到的短视频与主题的相关度作为每个主题的短视频喜好率的权重;最后,将K个主题下的预测结果集成起来产生最终的短视频喜好率。
对于一条短视频n,其喜好率预测结果可表示为:

其中,βnk为短视频n与主题k的相关度。
模型LDA-GBDT-FM:
输入:训练集D,经过步骤1和步骤2预处理的测试集X,主题数目K。
输出:测试集中每条数据的喜好率p。
步骤1 Topic clustering
1.读取训练集D,提取短视频广告的标题特征样本集合W
2.利用吉布斯抽样法,得到短视频-主题分布:β={β11,β12,…,βnk}
3.设置短视频-主题关联阈值σ
4.For eachninD:
5.For eachkinK:
6.Ifβnk>σ:
7.n∈dk
8.ReturnD={d1,d2,…,dk}和β
步骤2 Feature extraction
9.For eachdiinD:
10.从d中提取连续特征集U={u1,u2,…,ut}和离散特征集V={v1,v2,…,vt}
11.设置梯度提升决策树的棵数α=30和深度η=4
12.利用GBDT训练连续特征集U得到高影响力特征集G={g1,g2,…,gt}
13.结合G和V,得到重构训练样本集γi={gi}∪{vi}
14.Returnγ={γ1,γ2,…,γt}
步骤3 Training
15.For eachγiinγ:
16.训练因子分解机FM模型ŷdk
17.ReturnFM={ŷd1,ŷd2,…,ŷdk}
步骤4 Predicting
18.For eachxinX:
19.For eachŷdiinFM:

3 实验及结果分析
3.1 实验数据集和实验环境介绍
本文的数据集采用Bytedance公司的短视频广告历史日志。该数据集包含19 624 543条短视频历史数据。数据集中的一条数据包含用户信息、短视频广告信息以及用户与短视频的交互信息,如表1所示。

表1 数据集列名
本文程序由Python3.6编写完成,运行环境为Ubuntu16.04,内存大小64GB,Intel®CoreTMi9-7900X CPU@3.30 GHz。
3.2 实验结果与分析
本文使用曲线下方的面积(Area Under Curve,AUC)[20]指标来检验短视频喜好率预测模型的训练效果,因为LDA-GBDT-FM模型研究的主要目的是通过提高短视频喜好率预测的精度来对短视频广告的展示和排序产生一定的指导意义。
(1)GBDT的树棵数和树深度的设定
表2表示GBDT模型的树棵数和树深度以及学习率取不同值时,对LDA-GBDT-FM模型准确度的影响。如表2所示,随着树的数量和树的深度的增加,AUC没有显著提高,综合考虑,后面的实验中将采用树数量为30,树深度为4,学习率为0.13作为最终的GBDT的模型参数。

表2 GBDT高层提取实验记录
(2)主题个数对喜好率预测的影响
在LDA-GBDT-FM模型和LDA-FM模型中,主题数量作为原始训练集分割和预测结果集成的依据,是一个重要的超参数。本实验将短视频广告按照不同的主题数量进行划分,分别计算模型对不同主题数量的数据集的喜好率预测情况。
如图3所示,随着主题数量的增加,AUC的值逐渐上升,当达到20时,上升趋势平缓,当主题数目为35时,能够取得最佳的预测结果,因此,后续实验取主题数目为35时的实验结果。

图3 不同主题下喜好率预测结果
(3)预测结果分析
为了检验模型的有效性,本实验在相同的实验环境和相同的参数设置下将LDA-GBDT-FM模型与逻辑回归模型(LR)、因子分解机模型(FM)和LDA-FM模型三种点击率预测模型进行对比,实验结果如图4所示。

图4 LDA-GBDT-FM与其他喜好率预测模型对比
如图4所示,在预测短视频广告的喜好率时,本文提出的模型有更高的预测准确度,具体来说,LDA-GBDTFM相较LDA-FM、FM和LR的AUC分别提高了3.0%、5.7%和8.5%。这说明GBDT对每个主题的FM预测模型是有效的,提升了模型的预测准确度,因为GBDT可以对特征进行非线性转换,发掘高影响力特征,消除噪声的干扰。
4 结束语
计算广告学蓬勃发展,精准的短视频广告喜好率对APP运营商、广告主和用户都有着重要意义。本文的主要工作是从短视频的多主题性质出发,提出了一种基于LDA-GBDT-FM短视频喜好率预测方法,通过对不同主题的数据,提取高影响力特征来训练模型,根据短视频与主题的关联度,将子模型集成来提高短视频喜好率预测精度。实验结果表明,LDA-GBDT-FM模型相较于以往的模型在喜好率预测方面具有更高的准确性。
