基于联合模型的多标签文本分类研究
2020-07-17刘心惠陈文实鲁明羽
刘心惠,陈文实,周 爱,陈 飞,屈 雯,鲁明羽
大连海事大学 信息科学技术学院,辽宁 大连 116026
1 引言
多标签文本分类是自然语言处理领域的一个重要研究方向,目标是为数据集中的每个样本分配一个或多个类别标签。目前多标签文本分类算法广泛应用于推荐算法[1]、信息检索[2]、垃圾邮件检测[3]等任务。
当前多标签文本分类方法大致分为三类:问题转换方法、算法适应方法和神经网络方法。问题转换方法将多标签分类转化为单标签分类问题,Binary Relevance(BR)算法将每个标签作为单独的类别进行分类处理[4];Label Powerset(LP)方法为每一个标签组合创建一个二进制分类器[5];Classifier Chains(CC)算法通过模拟标签之间的相关性进行分类[6]。算法适应方法通过扩展现有的算法,使其适用多标签分类任务,不需要进行问题转换,Clare等人通过ML-DT方法构建基于多标签熵的决策时进行分类[7];Elisseeff等人提出Rank-SVM,使用支持向量机进行分类[8];陆凯等人使用ML-KNN方法来处理大数据集问题[9]。上述两类方法都是基于传统机器学习的方法,依赖于大量的特征工程,随着深度学习的发展,神经网络方法被广泛应用于多标签文本分类任务,相比于传统机器学习方法,深度学习方法可以自动学习文本特征,具有泛化性更强的优点。
当前主流神经网络有卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)等,在不同的领域表现出较好的性能[10]。胶囊网络(CapsuleNet)由深度学习之父Hinton提出,在图像处理领域表现出较好的结果,但是在自然语言处理领域的有效性仍在探索[11]。Zhao等人首次将胶囊网络应用在文本分类任务上,分类性能超过CNN[12]。Google团队提出多头注意力机制,在输入文本序列内部做注意力操作,寻找序列内部之间的联系,自动学习输入文本序列的权重分布[13]。
本文利用多头注意力机制、胶囊网络和BiLSTM组成联合模型,获得更为丰富的信息。注意力机制对文本中的每个单词的向量权重进行重新分配,对文本内容贡献大的信息赋以较大的权重,从而来区分每个单词对于文本识别重要性的大小。再通过特征融合的方式将胶囊网络提取的局部特征和BiLSTM提取的全局特征进行平均融合,可以同时提取不同层次、具有不同特点的文本特征。
2 相关研究
深度学习在自然语言处理领域的应用广泛[14],与传统的机器学习方法相比,不需要人工设计特征,可以自动学习并提取文本特征,并且取得了比传统方法更好的效果。周志华等人提出了BP-MLL方法,首次将神经网络模型用于多标签文本分类,使用全连接网络和排序损失来进行分类[15];Nam等人在周志华提出的方法上,采用adagrad和dropout来加速收敛并防止训练过程中发生过拟合,将交叉熵函数作为目标函数[16];Berger等人使用预训练的word2vec词向量捕获单词顺序,作用在CNN和GRU上直接用到多标签文本分类中,相比于传统的词袋模型分类性能得到提升[17];Kurata等人把CNN的输出层利用类别标签之间的共现关系进行初始化,来获得标签之间相关性[18];Chen等人提出一种CNN和RNN的融合机制,把CNN得到的输出作为RNN的输入,来捕获文本的语义信息,然后进行类别的预测[19];Nam首次将机器翻译中的Encoder-Decoder模型用于多标签分类,提出一种计算标签联合概率的公式,按照顺序生成类别标签[20];Yang等人首次将强化学习用于多标签文本分类,提出基于深度强化学习的Encoder-Decoder模型,把类别标签视为集合,来减弱标签之间的依赖关系[21]。
上述模型大多基于CNN和RNN网络结构,CNN的池化操作造成信息丢失,RNN会随着序列输入长度的增加而产生梯度爆炸或梯度消失问题。胶囊网络不仅获取单词在文本中的位置信息,还可以捕获文本的局部空间特征;BiLSTM不仅加入门控机制,而且可以捕获文本的上下文顺序信息[22]。另外,考虑到文本序列中词语的重要程度对分类结果的影响不同,本文引入注意力机制(attention mechanism)。注意力机制是一种用来识别关键词信息的选择机制,广泛应用于神经机器翻译任务中,考虑输入文本的单词贡献差异,突出关键输入对输出类别标签的作用,对贡献大的词赋予较高的权重,其他词赋予较低的权重[23]。
本文模型提出一种基于联合模型的多标签文本分类方法,利用多头注意力机制来获取关键词信息,胶囊网络提取文本的局部特征表示,BiLSTM提取文本的全局特征表示,并通过融合层将其融合,从而获得更为全面、细致的文本特征,提升分类性能。
3 模型构建
多标签分类问题可以定义为:设X=ℝd表示输入样本有d维特征空间,Y={y1,y2,…,yq}表示所有类别标签集合,共有q个类别标签。通过训练集D={(xi,Yi)|1≤i≤n}训练样本得到分类器 f:X→2Y,其中 xi∈X是输入空间X的训练样本,Yi∈Y是xi的类别标签集合,最终通过分类器 f得到测试样本的所属标签集合[24]。
基于联合模型的多标签文本分类框架如图1所示,本文所提出的模型由五部分组成:文本的向量表示、多头注意力机制、特征提取、模型融合和分类。
(1)向量表示:通过预训练GloVe词嵌入将输入的文本序列转化为向量表示。
(2)多头注意力机制:在文本向量表示的基础上使用多头注意力机制来发现文本中的重要信息,自动学习输入文本序列的相对重要的单词。
(3)特征提取:将注意力运算后的结果作为胶囊网络和BiLSTM的输入,不仅可以获得文本的局部特征表示,还可以捕捉文本的局部特征表示。
(4)模型融合:利用融合层实现对全局特征信息和局部特征信息进行平均融合,实现多层次提取文本信息,有效减少文本信息丢失。
(5)分类:将特征融合后的向量信息输入到sigmoid分类器中,进行分类操作。

图1 联合模型结构图
3.1 多头注意力机制模型
将输入序列表示为W=(w1,w2,…,wn),n为输入文本序列的单词数,通过词嵌入将每个词进行向量化表示,每篇文章形成一个词向量矩阵E={e1,e2,…,en},ei代表第i个词的词向量,维度为z,其中e∈ℝn×z。
由于多标签文本分类任务的每篇文本对应多个类别标签,不同单词对不同类别标签的影响程度不同,多头注意力机制可以作用在对分类具有决定性作用的词汇上,与其他注意力相比,多头注意力机制可以同时捕获与多个类别标签相关的不同单词,从多角度多层面获取重要的单词信息。
多头注意力机制使用单独的注意头在相同的输入上多次应用注意机制,获取不同类别标签的关键单词,从不同方面提取不同类别标签的重要信息。多头注意力机制的计算方法为:

Q∈ℝn×dk,K∈ℝm×dk,V∈ℝn×dv,i∈h
其中,Q、K、V 分别代表query矩阵、key矩阵、value矩阵,attention操作表示为查询Q到键值对K-V的映射。将其编码形成一个新的n×dv的序列,起到调节作用,控制Q和K的内积不会太大,每个注意力的头部使用自注意力机制,寻找序列内部之间的联系。在文本分类任务中,Q、K、V的值相等,代表嵌入层的输出E,大小为n×dk,其中dk为嵌入层的输出维数。h表示头的数量,i表示第i个注意力头部,每个注意力的头部采用公式(2)计算,从左到右拼接每个头,最终形成注意力矩阵X。
3.2 胶囊网络模型
传统的CNN通过池化操作来降低卷积运算的计算复杂度,来捕获局部特征,但是池化操作会造成信息损失。胶囊网络中使用神经元向量(胶囊)代替传统神经网络的单个神经元节点,每一个值都由向量表示,通过动态路由(Dynamic Routing)训练神经网络学习单词之间的关系,对特征向量进行特征间聚类,从而不仅获取单词在文本中的位置信息,还可以捕获文本的局部空间特征。动态路由过程如图2所示,计算方法如公式(4)~(9)所示。

其中,sj为网络的输入,u为上一层胶囊的输出,W为权重矩阵,cij为耦合系数,用来预测上层胶囊和下层胶囊之间的相似性,bij的初始值设置为0,通过动态路由更新bij从而更新cij。
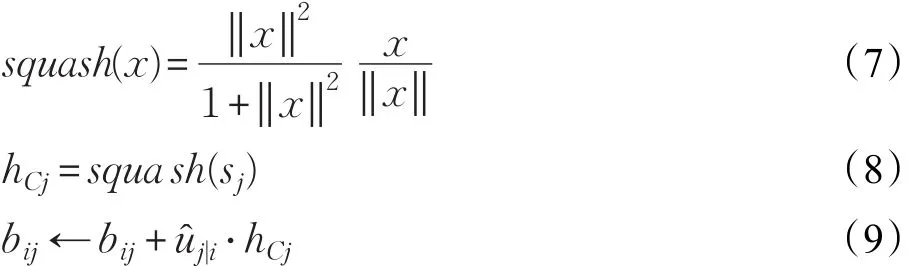
squash为压缩激活函数,对向量进行压缩,得到向量的模长hj。向量的模长越大,所表示的特征就越强。整个动态路由过程迭代r次,以获取局部特征向量HC=(hC1,hC2,…,hCn)。

图2 动态路由过程
3.3 BiLSTM模型
LSTM模型是在RNN的基础上改进而来,由门机制和记忆单元组成,可以选择性地记住或遗忘记忆单元中的信息,门机制包括遗忘门、输入门和输出门,从而每一个LSTM单元都具有记忆能力,可以体现上下文信息之间的相互影响。神经单元计算方法如下:


其中,ft、it、ot分别表示遗忘门、输入门、输出门,x、h、c表示输入层、隐藏层、记忆单元,W、b表示权重矩阵、偏置。

3.4 特征融合
胶囊网络无法体现上下文之间的深层语义影响,只能提取局部的文本特征;BiLSTM单元在同层神经网络之间相互传递,能体现相隔较远的单词之间的联系,从而提取文本的全局特征表示。单一的神经网络提取的特征有局限性,通过特征融合的方式可以同时利用不同神经网络的各自特点,优势互补,获得不同层次上的文本信息特征,提高分类效果。
本文在特征融合阶段使用平均融合的方式,而不是采用合并拼接的融合方式即拼接胶囊网络生成的特征向量和BiLSTM生成的特征向量,形成一个维度更大的特征向量。采用拼接方式的缺点是由于维度过大,产生梯度爆炸问题。胶囊网络输出的维度和BiLSTM输出具有相同的维度,不会增加数据维度计算,不仅节约计算成本,还能获取不同层次的文本特征。胶囊网络输出的特征向量HC=(hC1,hC2,…,hCn)和BiLSTM输出的特征向量HL=(hL1,hL2,…,hLn)进行特征融合,形成一个新的特征向量H,计算方法为:

本文模型采用sigmoid分类器:

函数返回值为不同的概率值,每个概率值对应于一个输出类别的概率,以此划分该文本所属类别信息,完成分类。计算特征融合后的向量H属于各个类别标签的概率,概率值在[0,1]之间,设定一个阈值,本实验选取的阈值为0.5,如果大于该阈值,则认为属于某个类别。
4 实验与结果分析
本文采用路透社新闻语料库Reuters-21578和arxiv网站上与计算机相关论文的摘要,每篇论文对应不同的主题的AAPD(Arxiv Academic Paper Dataset)语料库进行实验。
4.1 实验数据
Reuters-21578和AAPD数据集概况如表1所示。

表1 数据集概况
表1表示数据集的基本信息,T表示数据集文本总数,L表示类别标签数量,VC表示每个数据集的平均标签数,VL表示平均文本长度,M表示最大标签数。本文将数据集中的2/3用于训练集,1/3用于测试集,并且训练集中的1/5用于验证集。
4.2 实验设置
本文实验基于Keras框架,TensorFlow后端实现,编程语言为python3.6。通过多次实验及验证实验结果,选定最优的实验参数。由于提取的文本特征维度过大容易产生梯度爆炸问题,维度过少无法提取充分的特征信息,因此提取全局特征和局部特征的维度为设置为240。本文使用GloVe预训练的300维词向量,选定Adam(Adaptive Moment Estimation)作为优化器函数来优化神经网络,dropout值设置为0.5来防止过拟合。模型的具体参数设置如表2。

表2 实验参数设置
4.3 评价指标
本文使用四个性能评价指标来评价本文模型的实验效果,分别是精确率(P)、召回率(R)、F1值(F1 Score)、汉明损失(Hamming Loss)(公式(20)),其中F1值为主要的参考指标。

其中, ||D表示样本总数, ||L表示标签总数,xi和yi分别表示预测的标签结果和真实标签,xor表示异或运算。
4.4 结果分析与讨论
本文提出的基于联合模型的多标签分类方法ATTCapsule-BiLSTM在Reuters-21578和AAPD数据集上的实验结果如表3和表4所示,在P、R、F1、HL四个评价指标上进行对比,P、R、F1中“+”表示该值越大,模型性能越好,HL中“-”表示该值越小,模型性能越好。下面通过对比实验来验证本文提出方法的有效性。
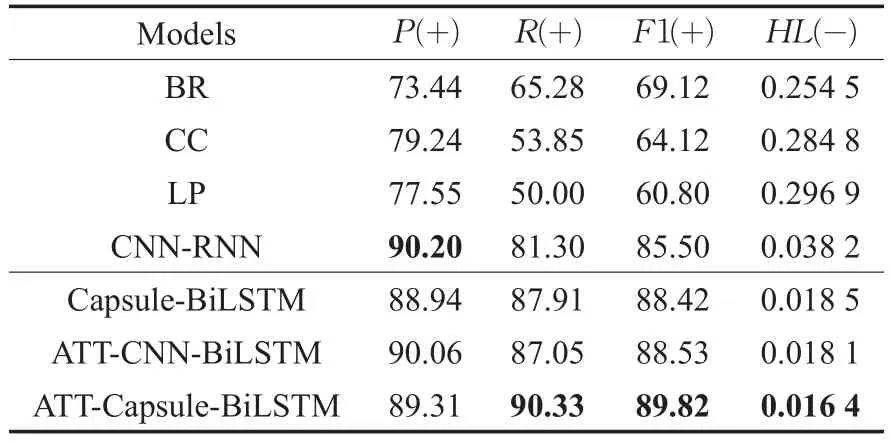
表3 Reuters-21578数据集实验结果
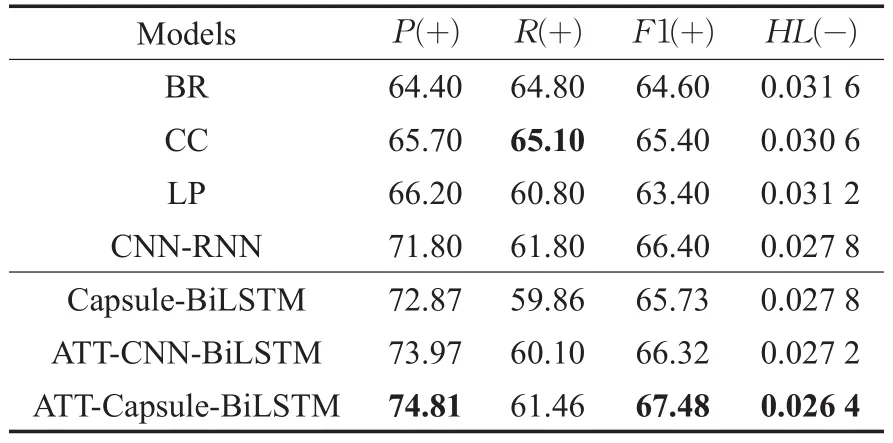
表4 AAPD数据集实验结果
为了验证本文提出ATT-Capsule-BiLSTM模型的有效性,设置与代表性的机器学习方法Binary Relevance(BR)、Classifier Chains(CC)、Label Powerset(LP)和深度学习CNN-RNN方法进行对比实验,并将CNN-RNN方法[19]作为基线模型。
上述结果表明,与传统机器学习方法相比,本文模型不基于特征工程,取得了合理的性能。在Reuters-21578数据集上,其F1指标取得了较好的性能,相比于CNN-RNN模型提升了4.32%;在AAPD数据集上,其F1值提升了1.08%。并且本文的模型在P、R和HL指标上也展现出了较好的结果。
为了验证胶囊网络相比较于CNN提取局部文本局部特征展现出的优势,设置ATT-CNN-BiLSTM和ATTCapsule-BiLSTM对比实验。使用胶囊网络提取特征展现了较好的效果,几乎所有的指标都超过了使用CNN网络提取的特征的结果,F1值分别提升了1.29%和1.16%。
对实验结果进行进一步分析,比较了数据集中不同类别的F1值差异,和不同实例的分类情况如图3~图6所示。

图3 21578数据集各个类别标签的分类情况
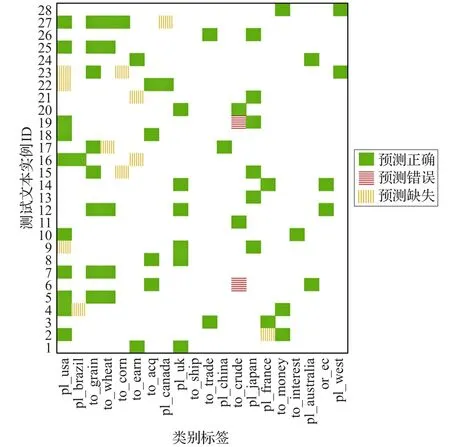
图4 21578数据集样本预测结果可视化
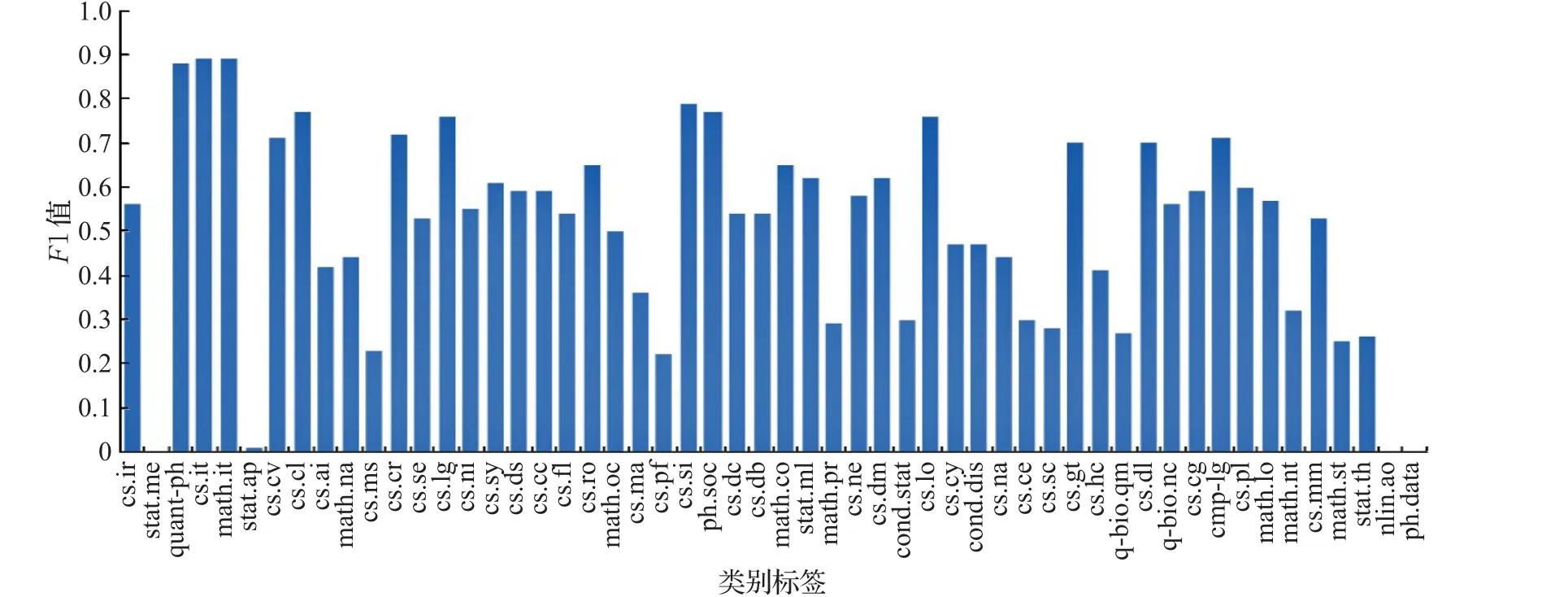
图5 AAPD数据集各个类别标签的分类情况

图6AAPD数据集样本预测结果可视化
图3 表示21578数据集每个类别标签的分类效果,横轴表示类别标签,纵轴表示F1值,4/5的类别标签的分类结果F1值超过0.8,取得了较好的效果。
图4表示在21578数据集的测试集随机抽取28个文本实例,查看其分类情况,纵轴表示测试文本实例的ID。绿色代表该类别预测正确,红色代表类别预测错误,橙色代表没有预测到该类别。从图4中可以看出,只有2个标签预测错误,11个类别标签预测缺失,其余均预测正确。
图5表示AAPD数据集每个类别标签的分类效果,横轴表示类别标签,纵轴表示F1值,1/4的类别标签的分类结果F1值超过0.7,由于类别分布不平衡,属于cs.it和math.it类别的文本数占总文本数的32%。因此F1值达到了89%;math.st占总文本数的1.63%,F1值仅为25%,导致分类结果较差。
图6表示在AAPD数据集的测试集随机抽取28个文本实例,查看其分类情况,横轴表示类别标签(未涉及到的类别已剔除),纵轴表示测试文本实例的ID。绿色代表该类别预测正确,红色代表类别预测错误,橙色代表没有预测到该类别。从图6中可以看出,ID为28的实例“Algorithmic randomness theory starts with a notion of an individual random object to be reasonable,this notion should have some natural properties,an object should be random with respect to image distribution only if it has a random preimage this result was known for a long time in this paper we prove its natural generalization for layerwise computable mappings,discuss the related quantitative results.”预测结果最差,其真实类别标签共有四个“math.io;cs.it;math.it;math.pr”,预测结果为“cs.ds;cond.stat;cs.pl”,有1个标签预测正确,漏掉了3个标签,2个标签预测错误。该实例中有64个单词,而AAPD数据集的文本平均长度是111,由于这个实例中文本长度过短,未表达出能预测所有类别的信息,导致这个实例的预测效果最差。
结合图3~图6分析可知,由于21578数据集的平均标签数为1.34,AAPD数据集的平均标签数为2.41,并且21578数据集的标签数和平均文本长度都远小于AAPD数据集,因此在21578数据集的F1值高于AAPD数据集。
5 结束语
本文提出了一种基于多头注意力机制、胶囊网络和BiLSTM网络的联合模型用于多标签文本分类研究,利用于多头注意力机制学习输入文本中的关键信息,胶囊网络有效提取文本的局部特征,BiLSTM充分考虑了词的上下文信息提取文本的全局特征。通过不同层次的特征融合,减少信息丢失。结果表明,本文提出的联合模型在F1指标上优于对比模型,有效地提升了分类的性能。本文的下一步工作是将该模型的结构用于seq2seq模型的编码器结构中,不仅可以学习文本不同层次的特征信息,还可以捕获类别标签的相关性。
