面向连续查询的敏感语义位置隐私保护方案
2020-07-17王永录左开中曾海燕郭良敏
王永录,左开中 ,曾海燕,刘 蕊,郭良敏
1.安徽师范大学 计算机与信息学院,安徽 芜湖 241002
2.安徽师范大学 网络与信息安全安徽省重点实验室,安徽 芜湖 241002
1 引言
随着移动技术与定位技术的不断发展,基于位置的服务(Location-Based Services,LBS)已逐步应用到更为广泛的领域[1-3]。根据用户查询方式不同,LBS主要分为快照查询和连续查询。其中,连续查询作为常见的LBS服务,用户需要在查询有效期内不断更新位置,存在一定的风险,即位置隐私泄漏问题[4-5]。因此,如何在连续查询中保护位置隐私已成为国内外学者关注的热点。
现有路网环境下面向连续查询的位置隐私保护方法大多基于K-匿名和L-路段多样性[6-8],即匿名区域至少包含K个用户和L条路段。Wang等[9]通过历史数据预测移动用户在路网中的运动情况,来构造匿名区域。潘晓等[10]通过在连续查询的最初时刻为用户生成统一匿名用户集,结合路网环境构建具有L条连通路段的匿名区域,来保护用户位置隐私。Zhang等[11]提出在混合区域中共享相同查询内容和时间间隔,使得攻击者无法通过子轨迹推测真实用户,保护位置隐私。张磊等[12]提出一种提高当前路段查询密度值的密度压缩算法,通过在用户真实位置附近添加大量噪声用户,保护位置隐私。与基于语义位置的方法相比,现有连续查询位置隐私保护方法均未考虑用户所处语义位置信息,存在语义推断攻击[13],导致用户隐私泄漏。
已有路网环境下的语义位置隐私保护方法主要集中于快照查询,即用户只需向LBS服务器提供一次位置信息,LBS服务器根据用户的位置和查询内容提供服务。针对语义推断攻击问题,Li等[14]利用城市路网中的道路交叉口和语义位置进行Voronoi图划分,通过位置语义信息有选择地添加邻近Voronoi单元,构建语义安全匿名区域,实现隐私保护,但该方法存在匿名区域过大问题。Xu等[15]针对匿名区域过大问题,提出一种基于全局最优和局部最优的增量查询方法,通过减少添加不必要的Voronoi单元,缩减匿名区域面积,降低查询开销,提升服务质量。陈慧等[16]针对敏感位置信息泄漏问题,提出一种基于用户个性化隐私需求的语义位置保护方法。然而,若将这些方法简单应用于连续查询,攻击者就可以利用相邻时刻匿名用户集间的关联关系,通过识别用户身份标识信息推测真实查询用户,即连续查询追踪攻击[17],导致用户隐私泄漏。
基于此,本文提出一种路网环境下面向连续查询的敏感语义位置隐私保护方案,通过设计(K,θ)-隐私模型构建匿名区域,提高用户身份的不确定性和所处敏感语义位置的隐私保护程度,更为有效地同时抵御连续查询追踪攻击和语义推断攻击。
2 预备知识
2.1 相关定义
连续查询可以分为新到查询用户和活动查询用户两种[10]。新到查询用户是指首次发出连续查询的用户;活动查询用户是指在连续查询有效期内发生位置更新的用户。鉴于路网环境下的连续查询过程中,用户在交叉路口的运动具有不可预知性,本文假设已知用户在查询有效期内的移动路径[10],如“查询从北京大学路径清华大学、人民大学到达上地过程中距离我最近的医院”。
定义1(带Voronoi划分的路网)路网是现实生活中多条道路(即路段)构成的交通网络,可以形式化表示为一个无向图G(V,E),其中:
(1)E是边的集合,每条边对应一条路段,记为e={eid,(vi,vj),velmax},其中,eid表示路段编号,(vi,vj)表示路段始点和终点(即路段结点),velmax表示路段最大速度限制。
(2)V 是路段结点的集合,记为V={v1,v2,…},其中v表示路段结点。路网G(V,E)中每个路段结点的Voronoi单元满足Voronoi(v)={z:d(z,v)≤d(z,w),w≠v,(w,v)∈V},其中,d(z,v)表示z到v的欧式距离,z表示路网中的任意位置。这些Voronoi单元互不重合,包含多条路段。
因此,一个带Voronoi划分的路网可以表示为G(V,E,Voronoi(v))。
定义2(语义位置流行度)是指用户访问该语义位置的概率。设loc是一个语义位置,U(loc)={u1,u2,…,um}是访问过该语义位置的用户集合,并设nj是用户uj对loc的访问次数,该语义位置被访问的总数记为因此该语义位置的流行度定义为P(loc)=中,H(loc)=,它表示该语义位置的信息熵,即被用户访问的可能性。为了便于区分语义位置与道路交叉口,设置道路交叉口的流行度为0。
定义3(语义位置)是指具有坐标、语义位置类型(如医院、学校等)和流行度等特征的位置,记为loc={(x,y),type,P(loc)},在路网中使用距离最近的路段结点表示,其中,(x,y)表示语义位置坐标,type表示语义位置类型,P(loc)表示语义位置流行度。语义位置是否敏感由用户定义,例如医院,部分患者认为是敏感的,医生则认为是非敏感的。
定义4(连续查询移动路径)是指用户连续查询期间经过的路段结点。一个连续查询移动路径被形式化表示为路段结点的有序序列,记为 path={ }nodes,size,其中,nodes表示经过的路段结点集合,记为nodes=表示经过的路段结点个数。为了简便,假设系统中连续查询用户的起点和终点都为路段结点。若连续查询用户位于路段中的某个位置点上,系统会自动将其转化为最近邻路段结点。
定义5(用户)是指在路网上发起连续查询请求的移动对象,记为u={u id,loc,e,path,vel,PR} ,其中,uid表示用户编号,loc表示用户所处语义位置,e表示用户所在路段,path表示用户连续查询移动路径,vel表示用户移动速度,PR表示用户的隐私需求,记为PR={K ,θ,senstype},其中,K表示用户定义的匿名用户数量,θ表示用户定义的语义安全阈值,senstype表示用户定义的敏感语义位置类型。
定义6(匿名区域)是指一个用来隐藏用户语义位置的空间区域,记为CR={ }users,Voronois,其中,users表示CR中的匿名用户集合,记为users={u1,u2,…},Voronois表示CR中的Voronoi单元集合,记为Voronois={Voronoi(v1),Voronoi(v2),…},这些Voronoi单元可以构成连通图,具有连通性。
定义7(θ-语义安全匿名区域)已知一个匿名区域CR和一个用户u,对用户u来说CR中属于敏感的语义位置用senslocsu表示,则匿名区域敏感语义位置总流行度记为 popCR(senslocsu),匿名区域语义位置总流行度记为 popCR(⋅),匿名区域语义安全程度用d(CR)表示:

若匿名区域的语义安全程度d(CR)≤u.PR.θ,称CR对用户u来说是一个θ-语义安全匿名区域。
定义8(平均移动速度)是指用户移动速度的平均值vavg,可表示为:

其含义是根据用户当前移动速度来预测在整个连续查询移动路径上的平均速度,其中,u.vel表示用户当前移动速度,u.e.velmax表示用户所在路段最大限制速度,vi表示用户经过路段结点集合中第i个路段结点,e.velmax表示以(vi,vi+1)作为始点和终点的路段最大限制速度。
定义9(时空相似性)是指两个用户在连续查询移动路径和移动速度方面的相似程度,其值越大,移动路径和移动速度越相似。已知2个用户ui和uj,其对应的连续查询移动路径为 pathi和 pathj,平均移动速度为ui.vavg和uj.vavg,则时空相似性δ可表示为:

2.2 系统架构
本文方案采用的是匿名保护方法下的LBS中心服务器系统架构[9-10],如图1所示。该系统架构由用户、匿名服务器及LBS服务器3部分组成。本文假定匿名服务器是可信的,由匿名区域构造模块和候选结果集求精模块组成。其中,匿名区域构造模块负责对用户位置进行匿名处理;候选结果集求精模块负责对LBS服务器返回的结果进行求精。当用户发出请求时,将自己的位置信息、隐私需求和查询内容发送给匿名服务器。匿名服务器根据隐私保护算法进行匿名处理,并将处理后的查询请求发送给LBS服务器。LBS服务器计算出候选查询结果集并返回给匿名服务器。匿名服务器对LBS服务器返回的结果进行筛选,并将精确查询结果返回给用户。本系统中,匿名服务器需要保存当前的地图信息、语义位置信息及流行度。
3 方案描述
针对连续查询位置服务中存在连续查询追踪攻击和语义推断攻击问题,本文方案通过设计(K,θ)-隐私模型构建匿名区域,来保护用户身份和敏感语义位置隐私。
3.1 (K,θ)-隐私模型设计
假设CRi(1≤i≤t)为用户u在第i时刻形成的匿名区域,CR1.users表示用户u在初始时刻根据时空相似性构建的匿名用户集,CRi.users表示第i时刻的匿名用户集,u.loci.type表示用户在第i时刻所处语义位置类型,u.PR.K表示用户定义的匿名用户数量,u.PR.senstype表示用户定义的敏感语义位置类型,u.PR.θ表示用户定义的语义安全阈值。如果CRi满足如下四个条件:
(1)| C Ri.users|≥u.PR.K;
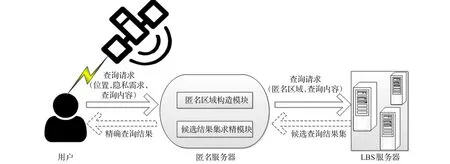
图1 LBS中心服务器系统架构
(2)CRi.users=CR1.users;
(3)if u.loci.type∈u.PR.senstype,d(CRi)≤u.PR.θ;
(4)∀u∈CRi.users,u发布CRi作为匿名区域。
则称CRi满足(K,θ)-隐私模型,其中:条件1确保匿名用户集至少有K个用户,满足K匿名性质;条件2确保每个时刻匿名区域的匿名用户集都包含相同的用户,防止连续查询追踪攻击;条件3确保匿名区域语义安全程度满足用户的语义安全需求,防止语义推断攻击;条件4确保每个CRi.users中的用户在该时刻形成的匿名区域都是相同的,满足位置K-共享性质。
3.2 算法设计
本文方案基于(K,θ)-隐私模型,提出一种路网环境下面向连续查询的敏感语义位置隐私保护算法,主要思想如图2所示。

图2 算法流程图
(1)利用城市路网语义位置和道路交叉口进行Voronoi图划分。
(2)判断连续查询用户状态。若用户为新到查询用户,则基于时空相似性为用户构建满足K匿名的用户集,并以此作为该用户连续查询的统一匿名用户集;否则,执行步骤(3)。
(3)根据匿名用户集各用户当前时刻所处语义位置的Voronoi单元构建具有连通性的匿名区域。
(4)若匿名用户集中有用户处于敏感语义位置,根据用户设定的敏感语义位置类型计算匿名区域语义安全程度;否则,返回匿名区域。
(5)若匿名区域语义安全程度满足用户设定的语义安全阈值,返回匿名区域;否则,遍历所有与匿名区域相连通的邻近语义位置。优先添加流行度最大的非敏感语义位置,其次随机选择道路交叉口,最后选择流行度最小的敏感语义位置。
(6)将该语义位置对应的Voronoi单元加入匿名区域,执行步骤(5)。
算法1给出了路网环境下面向连续查询的敏感语义位置隐私保护算法(Sensitive-semantic Location Privacy Protection Algorithm for Continuous Query under Road Network Environment,SLPP)的伪代码。首先判断用户的查询状态(第1行),对于新到查询用户,调用算法2分组构建匿名用户集(第2~11行),根据初始时刻匿名用户集中各用户所处语义位置及隐私需求调用算法3构建匿名区域(第12~22行);对于活动查询用户,则根据当前时刻匿名用户集各用户所处语义位置、敏感语义位置类型和语义安全阈值调用算法3构建匿名区域(第24、25行)。
算法1路网环境下面向连续查询的敏感语义位置隐私保护算法
输入:连续查询路径 path、隐私需求PR、带Voronoi划分的路网G(V,E,Voronoi(v))、时空相似性δ
输出:时刻ti的匿名区域CRi(1≤i≤t)
1.If{NewUsers}是新到查询用户 then
2. Uset=∅;//记录分组构造的匿名用户集
3. While true do
4. If{NewUsers}≠∅ then
5. 从{NewUsers}集合中随机选择u;
6. Uset=Uset⋃使用算法2为u生成的匿名用户集users;
7. {NewUsers}={NewUsers}-users;
8. Else
9. Break;
10. End if
11.End while
12.Forusers∈Usetdo
13. 根据匿名用户集users,找到users中用户所处语义位置集合vset1;
14. Voronois1=GetVoronoi(vset1);//获取各语义位置所在Voronoi单元
15. IfVoronois1是非连通的 then
16. 添加必要连通Voronoi单元,更新Voronois1;
17. End if
18. If ∃u∈users,u.loc1.type∈u.PR.senstypethen
19. 使用算法3生成匿名区域;
20. End if
21.End for
22.Return{CR1};
23.Else//活动查询用户
24.使用算法3生成语义安全匿名区域;
25.Return{CRi};
26.End if
在构建匿名用户集时,本文方案使用时空相似性选择匿名用户。主要思想是从用户所在路段出发,计算连续查询用户与其他用户的时空相似性,将满足要求的移动用户加入匿名用户集,直至满足该集合所有用户的K匿名需求。算法2给出了伪代码,首先初始化系统变量(第1~4行),从用户当前所在路段出发,依次计算其他用户与当前查询用户的时空相似性,将满足要求的用户加入集合USERset(第9~12行),若能找到K个用户,则从第5~25行的循环中跳出,否则从连续查询用户所在路段进行宽度优先搜索,执行第5~25行。最后判断USERset中的匿名用户数量是否大于等于K(第26行),若满足,则返回匿名用户集(第27行)。
算法2匿名用户集构建算法
输入:连续查询用户u、带Voronoi划分的路网G(V,E,Voronoi(v))、时空相似性δ
输出:匿名用户集合
1. USERset=∅;
2. Edgeset=∅;//记录已经遍历的路段
3. Nearedgeset={u.e};//相邻路段集合
4. count=0;//记录查找相邻路段的次数
5.While true do
6. Foregde∈Nearedgesetdo//遍历所有相邻路段
7. Edgeset.add(edge);
8. Foruser∈edgedo//遍历每条相邻路段上的用户
9. If(u,user)的时空相似性≥δ then
10. USERset.add(user);
12. End if
13. End for
14. If |USERset|≥u.PR.K then
15. Break;
16. End if
17. End for
18. If |USERset|≥u.PR.K||count>(1-δ)×10then
19. Break;
20. Else
21. Nearedgeset=∅;
22. Nearedgeset=Edgeset所有相邻路段;
23. count++;
24. End if
25.End while
26.If |USERset|≥u.PR.K then
27. ReturnUSERset;
28.Else
29. Break;
30.End if
在构建语义安全匿名区域时,本文方案根据匿名用户集各用户定义的敏感语义位置类型和语义安全阈值构建匿名区域。主要思想是针对处于敏感语义位置的用户,通过添加非敏感的相邻语义位置,降低敏感语义位置流行度比重,直至满足用户的语义安全需求。算法3给出了伪代码,首先初始化系统变量(第1~2行),找到连续查询用户在初始时刻构建的匿名用户集Users、当前时刻各用户所处语义位置集合vseti以及各语义位置所在Voronoi单元集合Voronoisi(第3~5行),将当前时刻处于敏感语义位置的用户加入集合TUset,并将对应的敏感位置类型加入集合SLset(第6~11行),通过添加必要连通Voronoi单元使得Voronoisi集合内Voronoi单元具有连通性(第12~15行)。若当前时刻TUset为空集,直接返回匿名区域;否则计算匿名区域语义安全程度是否满足TUset中每一个用户的语义安全阈值,满足则返回匿名区域,否则根据SLset添加邻近Voronoi单元,直至满足TUset中每一个用户的语义安全阈值,返回匿名区域(第15~35行)。
算法3语义安全匿名区域构建算法
输入:连续查询用户u,带Voronoi划分的路网G(V,E,Voronoi(v))
输出:θ-语义安全匿名区域
1. SLset=∅;//敏感语义位置类型集合
2. TUset=∅;//位于敏感语义位置的用户集合
3. Users=用户u的匿名用户集;
4. 找到Users中用户当前时刻所处语义位置集合vseti;
5. Voronoisi=GetVoronoi(vseti);//获取 vseti中各语义位置所在Voronoi单元
6.Foruser∈Usersdo
7. Ifuser.loci.type∈user.PR.senstypethen
8. TUset=TUset⋃user;
9. SLset=SLset⋃user.PR.senstype;
10. End if
11.End for
12.IfVoronoisi是非连通的 then
13. 添加必要连通Voronoi单元,更新Voronoisi;
14.End if
15.IfTUset=∅ then
16.ReturnCRi;
17.Else
18.While true do
19. If ∀u∈TUset,d(CRi)≤u.PR.θthen
20. Break;
21. Else//查找与匿名区域具有连通路段的所有语义位置
22.NSset=GetNSLinks(CRi,SLset);//记录非敏感语义位置结点
23.INset=GetINLinks(CRi,SLset);//记录道路交叉口结点
24.SNset=GetSNLinks(CRi,SLset);//记录敏感语义位置结点
25. IfNSset≠∅ then
26.vlink=SelectMaxpop(NSset);//选择流行度最大的语义位置
27. Else ifINset≠∅ then
28.vlink=RandomSelect(INset);//随机选择一个道路交叉口
29. Else ifSNset≠∅ then
30.vlink=SelectMinpop(SNset);//选择流行度最小的语义位置
31. End if
32.Voronoisi=Voronoisi⋃Voronoi(vlink);
33. End if
34.End while
35.ReturnCRi;
36.End if
4 实验及结果分析
4.1 实验设置
本文对比了SCPA算法[10]和TB算法[18],因为SCPA算法、TB算法和本文算法都是通过构建具有K个共同用户的匿名用户集抵御连续查询追踪攻击,但没有考虑语义安全性。其中,SCPA算法基于K匿名和L多样性(L默认设置为3),TB算法基于K匿名和四叉树。
所有的匿名算法均用Java实现,并运行在一台配置为2.83 GHz Intel CoreTM2,2 GB内存的Windows7计算机上。本实验使用Thomas Brinkhoff移动对象生成器[19]生成模拟移动对象,生成器的输入是德国Oldenburg地图,包含6 105个结点和7 035条边。实验模拟生成10 000个移动用户,设每个对象均提出连续查询,默认包括20个快照位置。同时实验还设置了1000个均匀分布的语义位置(均分布在路段结点),共6种类型(见表1)。

表1 实验参数设置
实验采用控制变量法,在保证其他参数不变的情况下,通过改变匿名用户数、语义安全阈值和语义位置数量进行验证。为了计算简单,假设类型相同的语义位置具有相同的流行度,取值为{学校:0.2,医院:0.15,办公:0.25,娱乐:0.15,商场:0.15,公园:0.1,路口:0},敏感语义位置类型设置为{医院、娱乐},时空相似性δ取值为0.7,其中,δ值与文献[10]取值相同。表1列出了实验参数具体信息。
4.2 实验结果分析
(1)隐私保护度。它是指满足语义安全阈值的匿名区域数量同总产生的匿名区域数量之比,比值越大,隐私保护度越好。图3比较了θ值以及K值的变化对隐私保护度的影响。从图3可以看出,由于SLPP算法始终考虑语义安全性,而SCPA算法和TB算法不考虑,所以SLPP算法的隐私保护度始终高于SCPA算法和TB算法,且几乎不受K值变化影响。因此,SLPP算法所提供的隐私保护度更高。
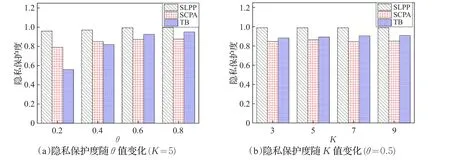
图3 隐私保护度比较
(2)系统开销。它使用平均匿名区域面积来度量,匿名区域面积越大,查询和处理开销越大,对应系统开销越大。图4比较了θ值以及K值的变化对平均匿名区域面积的影响。如图4(a)所示,由于SCPA算法和TB算法不考虑语义安全性,所以匿名区域面积不受θ值影响。随着θ值增加,SLPP算法生成的匿名区域面积呈下降趋势。这是因为θ值越大,构建语义安全匿名区域需要添加的相邻语义位置越少,使得匿名区域面积相应减小。如图4(b)所示,随着K值增加,三种算法的平均匿名区域面积呈上升趋势。其中,在K值小于等于5时,SLPP算法的平均匿名区域面积高于TB算法,大于5时要低于TB算法,这是因为K值越大,TB算法需要不断将匿名区域扩展为所在四叉树结点的父结点,直至每个时刻的匿名区域都包含K个公共用户,导致匿名区域不断变大。但SLPP算法的匿名区域面积始终小于SCPA算法,因此SLPP算法的系统开销较低。
(3)平均执行时间。平均执行时间是指算法成功匿名所用的时间,平均执行时间越少,算法执行效率越好。图5比较了θ值以及K值的变化对平均执行时间的影响。如图5(a)所示,由于SCPA算法和TB算法不考虑语义安全性,所以平均执行时间不受θ值影响。随着θ值增加,SLPP算法执行时间呈下降趋势。这是因为θ值越大,语义安全要求越宽松,添加相邻语义位置的次数逐渐减少,算法执行时间相应减少。如图5(b)所示,随着K值增加,三种算法的平均执行时间呈上升趋势,但SLPP算法的平均执行时间一直低于TB算法,略高于SCPA算法。这是因为SCPA算法只考虑匿名区域的路段多样性,并没有考虑语义安全性,因此执行时间略低于SLPP算法;TB算法通过不断扩展匿名区域,确保每个时刻生成的匿名区域包含K个公共用户,花费时间较多;SLPP算法始终考虑语义安全性,通过不断添加相邻语义位置构建语义安全匿名区域。然而,SLPP算法仅比SCPA算法大约多花费了1%的执行时间。
(4)可扩展性。可扩展性是评价算法可执行性的一个重要指标。图6给出了总语义位置数量从1 000增加到1 800时,系统开销和平均执行时间的变化情况。其中:K值为5,θ值为0.5,敏感语义位置类型为{医院、娱乐}。由于SCPA算法和TB算法不考虑语义安全性,所以语义位置数量的变动与它们无关。从图6可以看出,随着语义位置数量的增加,SLPP算法在系统开销和平均执行时间方面均呈下降趋势。这是因为随着语义位置数量增加,非敏感语义位置数量逐渐增多,构建语义安全匿名区域时需要添加的相邻语义位置数量减少,缩减匿名区域面积,减少算法执行时间。由此可见,SLPP算法的可扩展性更好。
5 结束语
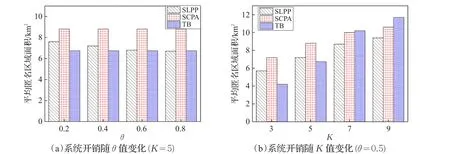
图4 系统开销比较
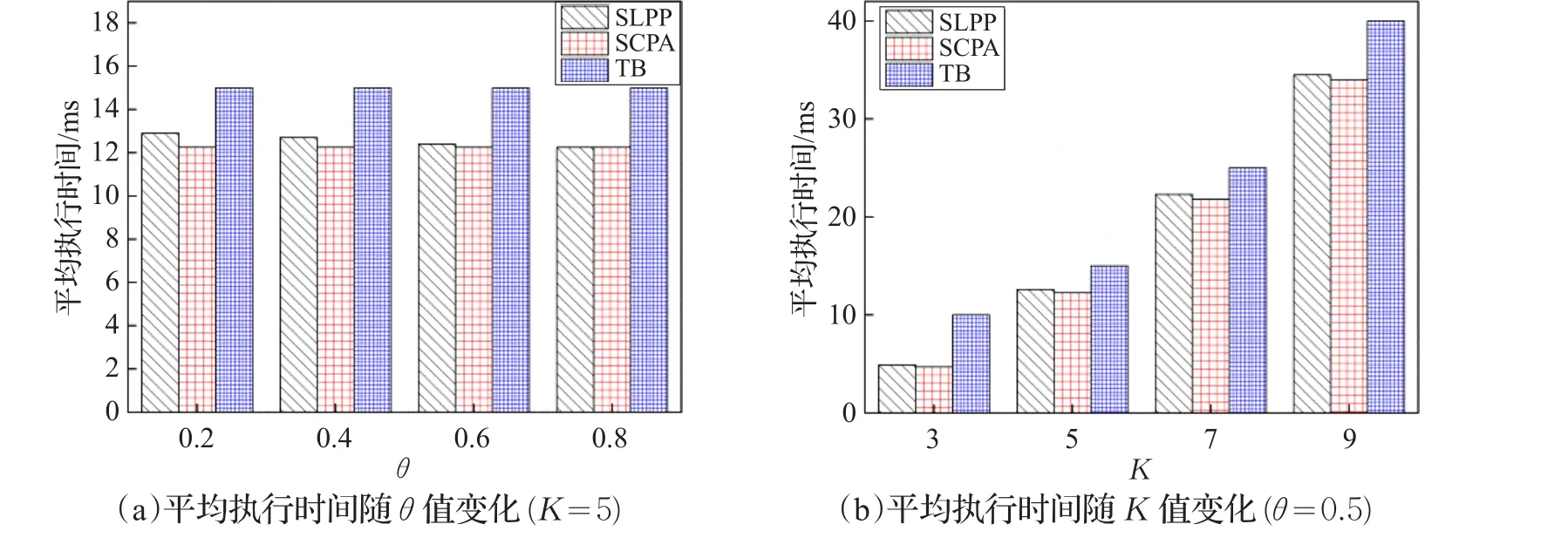
图5 平均执行时间比较

图6 可扩展性比较
本文针对连续查询位置服务中存在的连续查询追踪攻击和语义推断攻击,通过设计(K,θ)-隐私模型,提出一种路网环境下面向连续查询的敏感语义位置隐私保护方案。该方案利用时空相似性为连续查询用户构建统一匿名用户集,并依据该匿名用户集用户的语义安全需求构建匿名区域。最后,采用模拟数据进行大量实验,验证了本文所提方案的有效性。
然而,本文方案仅利用语义位置的空间分布来构建匿名区域,未考虑时间维度。因此,下一阶段的研究可以结合语义位置的空间分布和时间维度构建匿名区域,进一步增强隐私保护程度。
