基于引证关系的“作者群体—关键字—引文”多重网络构建
2020-07-14刘爱琴吴瑞瑞
刘爱琴 吴瑞瑞
摘 要 本文从数据库检索因子优化入手,以CNKI中国引文数据库的数据作为依据,基于引证关系,对知识发现领域研究群体进行知识图谱构建和聚类分析,展示群体族群关系及整体知识架构,并验证将二次凝练因子作为基础特征项进行應用的效果,挖掘出知识发现领域作者群体、关键字及引文之间的超网络模型,提高了信息检索的查全率和查准率,弥补信息检索的缺陷。
关键词 知识图谱 知识关联 多重共现 引证关系
分类号 G251.6
DOI 10.16810/j.cnki.1672-514X.2020.05.010
Abstract Based on the data of CNKI Chinese citation database, this paper starts with the optimization of database retrieval factors, builds knowledge map and cluster analysis on the research groups in the field of knowledge discovery based on citation relations, shows the relationship between groups and the overall knowledge structure, and verifies the effect of applying the second refinement factor as the basic feature item. The super network model among authors, keywords and citations in the field of knowledge discovery is mined, which improves the recall and precision of information retrieval and makes up for the defects of information retrieval.
Keywords Knowledge map. Knowledge association. Multiple co-occurrence. Citation relationship.
人们在对某一学科或某一领域进行研究分析时,为了寻找到事物或现象之间的背后因素,常常通过论文共现分析来发现研究对象之间的关联程度, 挖掘潜在知识,并揭示其内在特征[1]。随着可视化技术的不断完善,知识图谱成为形式化表述共现现象的一种重要方式。利用可视化工具描述知识资源及其载体,深层次地挖掘知识内容及其结构关系,表征知识之间的关联,能够有效提高信息检索效率和准确率,实现数据库服务模式创新[2]。为了更加清晰了解和应用共现分析方法,本文将基于引证关系,对知识发现领域研究群体进行知识图谱构建和聚类分析,一方面展示群体族群关系及整体知识架构,挖掘作者群体、关键字及引文之间的超网络模型;另一方面提高信息检索的查全率和查准率,弥补信息检索的缺陷。
1 研究现状
知识图谱最早出现在管理学领域,随后向信息技术领域和图情领域发展,慢慢渗透到各行各业[3]。国外对知识图谱的研究起步相对较早,在文献数量、质量上占有一定优势。ODonnell认为,知识图谱是一种节点链接,通过一系列的链接与其他概念相连,以知识图谱作为认知加工的支架有助于人们在认知过程中快速产生有效响应[4]。Van Eck全面描述了VOSviewer显示大型书目的强大功能,并通过构建和显示数千种主要期刊的共引图来证明VOSviewer程序构造的合理性[5]。Boyack通过直接引用、书目耦合、共引文分析以及基于引文与文内耦合的多重方法,对生物医学文献的聚类情况进行研究,比较不同方法的聚类精确度[6]。Porter通过运用新的跨学科指标和科学制图可视化方法研究不同领域的跨学科程度,发现跨学科指数呈现适度增长,但只略微增加了与远距离认知领域的关系,主要分布仍然集中在邻近学科,并认为叠加学科知识图谱能够为未来跨学科研究提供通用标准[7]。
2005年,由陈悦和刘则渊共同署名的《悄然兴起的科学知识图谱》在《科学学研究》上发表,标志着国内知识图谱领域研究的开始,其认为科学知识图谱是科学计量学表达形式转换的产物,在揭示科学知识内涵、结构及其活动规律的进程中起到了简化作用[8]。侯海燕通过对科学计量学、应用数学及计算机科学等相关学科进行可视化研究,交叉整合各学科代表性成果并绘制图谱,剖析科研热点,同时预测演进趋势[9]。陈悦给出知识图谱发展历程简介,并将传统知识图谱与现代知识图谱的类型和实现原理进行对比,表明了其作为知识管理工具的有效性[10]。秦长江和候汉靖主要讲述构建知识图谱的理论及方法技术,并结合具体应用疏通知识图谱的发展脉络[11]。赵蓉英和王菊运用Cite SpaceⅡ,以图书馆为主题展开讨论,对引文数据和主题词数据进行分析,梳理了该学科的代表文献和领军人物[12]。庞宏燊优化了交叉图技术, 以竞争情报研究领域为例,对其发展趋势进行了多重共现可视化分析[13]。郭秋萍构建基于作者—关键词—引文3个子网的多重共现超网络,并以图书馆、情报与文献学学科领域的“知识服务”为主题进行实证分析,揭示科技文献网络不同节点之间的关联关系,为研究文献之间的隐性关联关系提供了新的方法[14]。郭红梅将一系列具有语义信息的术语进行叠加,检测多重术语关系在识别文本核心主题方面的效用性,结果表明三种关系的叠加使文本主题更为凸显,克服了单独考虑一种关系时造成的信息缺失[15]。周娜等基于LDA主题模型构建作者、内容与方法的多重共现,为揭示学科领域隐性知识组合提供新的范式[1]。
综上所述,在当前研究中,学者主要运用可视化工具对某一领域的基础元素进行研究,并分析其具体应用和发展趋势,没有进行整合提升。本文以CNKI中国引文数据库为数据源,首先通过作者间的引证关系形成同被引网络知识图谱,再运用社会网络分析法对该群体进行凝聚子群分析,构建作者群体与关键字、引文之间的多重共现超网络模型,达到凝练整合效果。通过构建三者之间更精准的关联体系框架,有效提高信息检索效率和准确率,实现数据库服务模式的创新。
2 基于引证关系的作者“群体—关键字—引文”多重网络构建
2.1 群体可视化知识图谱构建与分析
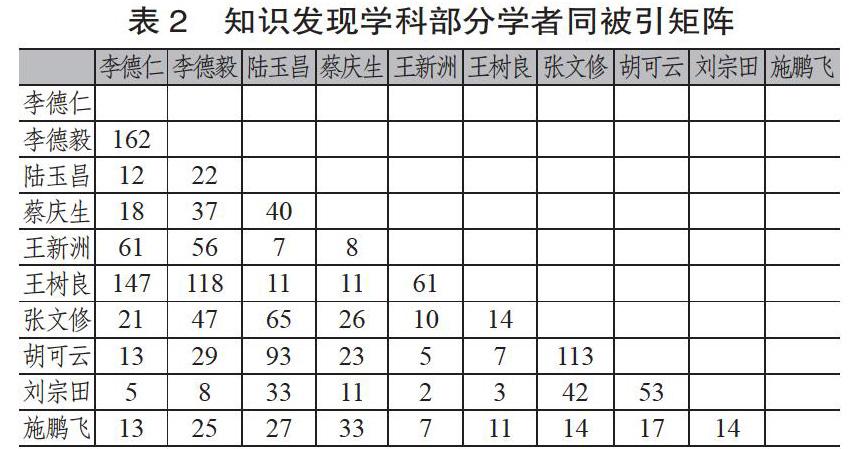
在科学文献体系结构中,引证文献是论文的基本属性,也是文献之间得以连接的内在枢纽。基于引证文献之间的关联能够构建引文矩阵,著者同被引又是由引证文献延伸而来,本文借助被引证文献构建著者同被引网络,具体方法及数据处理如下。
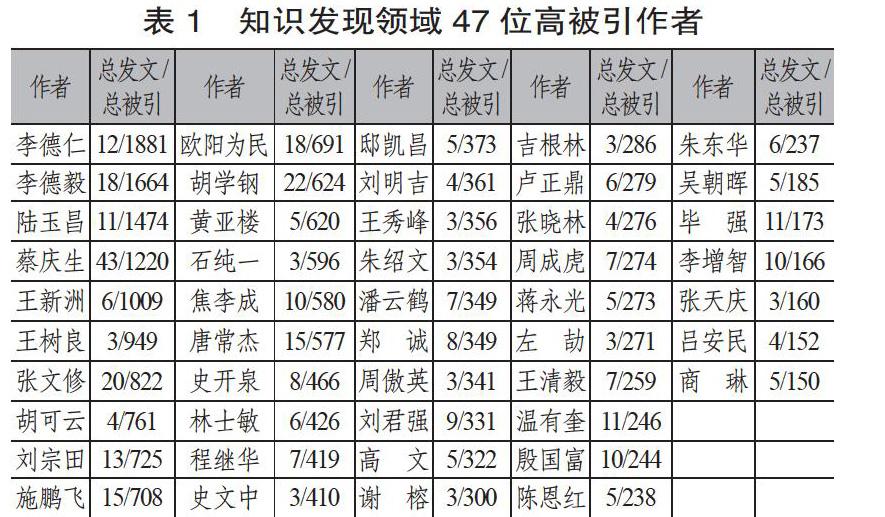
第一步:在知识发现范围内进行检索,统计CNKI中国引文数据库中收录的文献。以发表数≥3,被引总数≥150作为筛选条件,选出47位高被引作者作为研究对象,见表1。
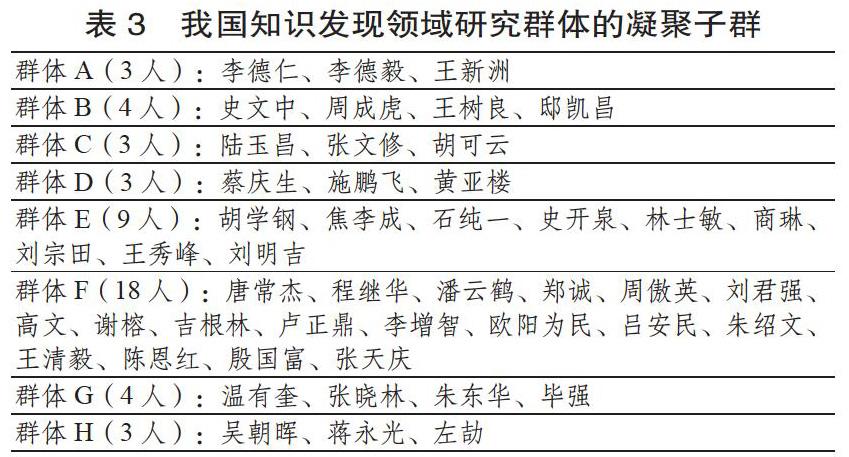
其中,群体A三位学者专注于数据库方面的研究。李德仁与王新洲侧重空间数据挖掘的理论方法与应用,李德毅则比较注重数据库与知识发现的应用。从发文情况来看,多数作品均由其中两人或三人共同署名,总发文数相差不多,但被引次数李德仁最多,为1881次,其次是李德毅1664次、王新洲1009次。从同被引频次来看,李德仁与李德毅同被引频次最高,达162次,李德毅与王新洲、李德仁与王新洲相差无几,分别为61次和56次。李德毅的同被引频次总和在整个网络中最高,达1106次,其次是李德仁954次,王新洲423,三位学者总被引频次整体排位靠前,在整个网络中地位十分重要。
群体B四位学者的主要研究方向是空间数据挖掘。其中,邸凯昌偏重于相关理论与实际应用,其他三人则更倾向于方法、分类等。从该群体的同被引频次分析,王树良与史文中和邸凯昌分别为89和81,史文中和邸凯昌为57,王树良和周成虎,邸凯昌和周成虎均为56,史文中和周成虎最少,为44。从同被引频次总和看,王树良是557,史文中555,邸凯昌718,周成虎433。可见,邸凯昌不论是在该群体还是在整个网络中,影响力都比较大。
群体C三位学者主要关注知识发现领域的人工智能、粗糙集等技术,且以算法为主。从该群体彼此间的同被引频次来看,张文修和胡可云最多,有113次,其次是陆玉昌和胡可云,陆玉昌与张文修,分别为93次,65次。从同被引频次总和看,陆玉昌742次,张文修750次,胡可云695次。由数据可知该群体成员关系较为亲密,学术地位相当。
群体D三位学者研究方向集中在数据挖掘与关联规则。其中,施鹏飞以算法运用为主,蔡庆生与黄亚楼则主要描述算法的实现过程。该群体成员同被引次数相对较少,蔡庆生与施鹏飞33次,蔡庆生与黄亚楼11次,施鹏飞与黄亚楼7次。从同被引频次总和看,蔡庆生709,施鹏飞439,黄亚楼224,相较其作品数量而言,被引次数较多。
群体E九位学者的作品多属同一时期,集中在該学科萌芽阶段,侧重于论证相关算法的形成过程。胡学钢、刘宗田关注关联规则,王秀峰和刘宗田研究决策树,焦李成、商琳以及林士敏探索数据挖掘,石纯一和史开泉则注重粗糙集。从该群体的同被引频次看,刘明吉和王秀峰最多,为47次,其次是石纯一和刘宗田,石纯一和胡学钢,石纯一和王秀峰,分别为33次,21次,14次,剩余俩俩之间次数较少,均在10次以下,表明其研究成果关联度不大。从同被引频次总和看,石纯一最多,为561次,之后依次是刘宗田,胡学钢,王秀峰,焦李成,刘明吉,林士敏、商琳,史开泉。
群体F有18位学者,在整个网络中占比最大。该群体研究范围广泛,在数据库、算法、应用、关联规则、数据挖掘等方面均有所涉足,研究方向有所交叉,又有所侧重。例如唐常杰、程继华、郑诚、刘君强、李增智、欧阳为民、王清毅、陈恩红均涉及关联规则,但唐常杰围绕基因表达式展开,欧阳为民以数据库为主,陈恩红则借助贝叶斯方法进行研究。从同被引频次来看,次数较少,甚至多数人之间都没有共被引关系;从同被引频次总和来看,欧阳为民最高,之后依次是高文,程继华,吉根林,郑诚,陈恩红,王清毅,潘云鹤,唐常杰,吕安民,朱绍文,刘君强,周傲英,卢正鼎,谢榕,张天庆,殷国富,李增智。
群体G四位学者的共同研究方向是图书馆的数字资源整合、图书馆的变革方向以及图书馆知识发现。温有奎和毕强从语义检索方向研究检索方法的改进,张晓林和朱东华则从数据处理方面入手。从该群体的同被引频次来看,张晓林与毕强和温有奎次数较多,但也仅有16次和13次,剩余彼此之间次数很少,从同被引频次总和而言,张晓林最多,其次是毕强、温有奎。
群体H的三位学者主要研究知识发现在医药领域的应用。同被引频次显示,只有蒋永光与吴朝晖之间有同被引关系,频次是8,其余俩俩之间没有关联,只是共同将知识发现作为工具,在其他领域加以应用,且3人的总被引频次偏少,表明3人的研究方向与群体其他人员之间的一致程度较低。
通过对47位学者同被引网络的可视化成果进行分析,揭示出了我国知识发现领域学术群体结构分布、成员地位,明确了主要学者之间的关联程度。
2.2 “作者群体—关键字—引文”的多重共现超网络模型构建
选定某一学科的科技文献集合作为样本,用A={a1,a2,a3,...,am}表示作者群体集合, K={k1,k2,k3,...kn}表示关键字集合,C={c1,c2,c3,...cp}表示引文集合,则对于作者群体、关键字和引文之间的关联关系可做出如下定义:R={(ai,kt)|1≤i≤m, 1≤t≤n}∪{(ai,cv,)|1≤i≤m,1≤v≤p}∪{(kt,cv)|1≤t≤n, 1≤v≤p}∪{(ai,kt,cv)|1≤i≤m, 1≤t≤n,1≤v≤p},该定义描述以下4种共现情况:作者群体ai与关键字kt的共现;作者群体ai与引文cv的共现;关键字kt与引文cv的共现;作者群体ai与关键字kt、引文cv的共现。
2.2.1 “作者群体—关键字—引文”的多重共现超网络模型构建步骤
首先,按照作者、关键字和引文之间的对应关系,识别每篇文献对应作者所属子群,得到每篇文献的作者、关键字和引文关系表;随后,通过Bib Excel整理得到文献标号与作者群体、关键字和引文之间的对应关系,以及作者群体共现矩阵、关键字共现矩阵和引文共现矩阵;第三,导入SQL Server,生成作者群体表、关键字表、引文表,并借助SQL Server的查询功能和Excel的统计功能,对作者群体、关键字、引文之间的关联关系进行整理记录,得到作者群体、关键字、引文共现频次表;第四,与关键字—引文共现频次表、作者群体—关键字共现频次表、作者群体——引文共现频次表逐一对应进行转换,生成作者群体—关键字—引文共现矩阵;最后,将共现矩阵导入Ucinet软件,对作者群体—关键字—引文矩阵进行可视化操作,生成多重共现超网络。
