基于机器学习的网站识别方案
2020-07-13刘天一张汝娴袁艺邢韦川林清然周延森指导老师
◆刘天一 张汝娴 袁艺 邢韦川 林清然 周延森指导老师
(国际关系学院 北京 100091)
1 引言
近年来互联网技术发展迅速,网络资源丰富了生活。但与此同时,大量博彩、色情等非法网站的出现严重影响了网络环境,非法网站检测也成为保护网络安全的一环。
有关部门已开展大量专项整治行动,但由于网络建站成本低、活动隐蔽性强及监管难度大等特点,许多诸如色情、博彩等非法网站仍屡禁不止,对网络安全造成严重威胁,目前急需高效检测的技术手段。
非法网站检测目前主要有三类技术:黑名单、静态检测、动态检测。基于URL 检测黑名单的技术简单且准确率较高,但灵活性较差,且人工维护黑名单耗时耗力。静态检测是目前主流,多数预先采用网络爬虫获取目标网站静态数据,通过机器学习提取特征构建分类识别模型[2-4],其关键是选取有效检测特征与构建适合的分类器。动态检测耗时长且难度较大,针对挂马类恶意网站识别率较高,而对于博彩、色情等网站效果欠佳。
相比已有的非法网站检测工作,我们针对不同类型非法网站采用不同手段,进而提高识别的准确性与效率。一方面,使用自然语言处理技术提取网页特征并利用SVM 生成博彩网站识别与分类模型。另一方面,在已有NSFW 色情图片识别平台基础上实现色情网站检测模型。
2 非法网站系统构建
本文所设计的非法网站检测系统框架如图1,输入指定URL 后系统依次对其进行是否为博彩、色情网站的识别,从而对其是否为非法网站作出初步判断。

图1 非法网站识别系统
2.1 基于SVM 的博彩网站检测
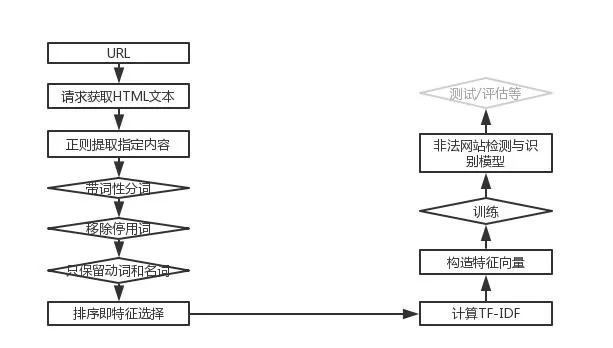
博彩网站检测模型构建步骤如图2。
(1)请求URL 获取HTML 文本;
(2)通过正则匹配从HTML 指定标签中提取文本。由于各个国家对非法网站的界定不同,目前本模型只针对国内网站进行识别,因此正则后只保留中文字符;
(3)对中文文本进行分词并保留词性。依据经验制定任务相关停用词表,并同通用停用词表结合,移除停用词及非动、名词等无意义的词,过程中建立语料库,统计加入了语料库词的词频;
(4)采用指定方式对语料库排序,进行特征选择。分别采用信息增益、卡方检验、频次等方式排序,指定维数并且完成特征提取;
(5)根据所选特征,即排序后的前[指定维数]个词,重复(2)(3),计算tf-idf,形成特征向量。
至此得到HTML 的特征向量,将其作为分类器的输入,完成分类、识别等任务。
本实验选用已知非法网站和从chinaz 中随机选取的URL 组成数据集,预先分别将其标注为合法/非法。选取过程中过滤不可正常访问网站和非中文网站。考虑到数据集规模较小,特征维数较高,任务目标为二分类,因此选用SVM。考虑到过拟合等问题,此处在特征选择时指定维数为3000。数据集划分为70/30 进行训练/测试,并统计训练集和测试集的各项指标。
实验结果表明训练集中测试的准确率为97.14%,测试集中为95.56%,而80/20 划分训练/测试集的情况下可达99.9%,未发生过拟合。其中,采取了十折交叉验证以保证可信度。后期如需进一步扩大数据集,特征选择时选定的维数应相应增多。实验说明本文通过自然语言处理对HTML 进行的特征提取、特征选择等操作可形成明确划分界限,可供分类器进行处理,以及结合SVM 进行分类的模型基本可行。
2.2 基于NSFW 的色情网站识别
NSFW 标识链接中存在的不适宜公众场合内容。本文基于NSFW色情图片识别模型来实现网站检测,该模型经训练能对图像进行5个维度的检测并输出符合概率,因此可用于检测URL 中图片。5 个维度分别是:绘画drawings、变态hentai、中立neutral、色情porn、性感sexy,其概率总和为1。
借助NSFW,本文从每个URL 中爬取所有图片,将单个网站的所有图片输入以获取概率结果,与设定的阈值比较,以此来判别。为避免漏报,使用MAX(Porn)+MAX(Hentai)作为score 值输出,此即网站的描述特征。只要某网站中一张图片被判定为色情图片,就将其识别为存在色情信息的网站。
本实验数据集构造与前一模型相似。逐一计算URL 所对应的score,与设定的阈值比较,如低于阈值则输出“通过检测”,反之判定为色情网站并输出“未通过检测”。
色情网站界定标准存在主观因素,需反复调整,通过实验分析大量正常网站阈值的各项统计指标,最终将阈值取0.85 较合理。
最终以此确定色情网站识别模型,与博彩网站检测并行,构成一个功能较为多元的非法网站检测系统。
3 总结
本文以非法网站检测为目标,基于机器学习算法实现了集成博彩和色情网站识别的检测系统。可以改进的地方在于本系统目前只能针对合法网站数据量进行扩展,没有更多的训练评估。未来可以考虑在非法网站获取样本,检验本文的检测算法对此类非法样本的可靠性。
