基于cw2vec-BiLSTM-CRF的汽车名称和属性识别方法
2020-07-13李德玉王佳王素格
李德玉,王佳,王素格
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
随着社交媒体、网络论坛的流行,消费者更多地通过社交媒体、网络论坛来发表自己对于已购买产品的评价,评论中既包含对产品整体的评价,也包含了对产品某一部件或是某一性能的评价,而且,一些潜在消费者也会发表自己对于新产品的期待。在产品评论领域中,用户评论经常带有明确的指向,例如,针对产品的某一部分或某一功能做出评价。为了对这些评论文本进行处理、分析、归纳和推理[1],抽取其评价对象是必不可少的环节[2-3],而评价对象在评价文本中包括被评论中产品名称或产品属性。
对于评价对象的抽取,目前已经有许多相关工作,大致分为两大类:基于规则的方法和基于机器学习的方法。基于规则的方法有江腾蛟等人[2]结合语义角色标注与依存句法分析,设计了评价对象-情感词对抽取规则,用于解决评价对象构成的复杂性问题。Li等人[3]利用情感词典和主题词词典筛选出〈情感词,评价对象〉的组合,使用该二元组中的评价词与评价对象之间的关系进行抽取。Popescu等人[4]利用互信息算法抽取特性。基于统计机器学习方法有王荣洋等人[5]采用CRF模型,探索了多种特征在评价对象抽取任务中的性能,并将特征归纳为词法、依存关系、相对位置、语义四大类别,引入语义角色标注新特征,表明其提出的语义角色标注特征对评价对象抽取有较好地指示作用。郑敏洁等人[6]提出了一种基于层叠条件随机场的中文句子评价对象抽取方法。该方法首先通过低层条件随机场获得候选评价对象集,然后通过降噪模型对噪声进行过滤,补充模型对缺失的候选评价对象进行补充,合并模型对复合短语候选评价对象进行合并,最后抽取出评价对象。实验结果显示,该方法能有效地识别复合词评价对象和未登录评价对象,从而提高了中文句子评价对象的识别精度。近年来,研究者不断将深度学习技术应用于评价对象的抽取任务,李盛秋等人[7-8]将长短期记忆模型(LSTM)应用于手机、笔记本、相机和汽车四个领域评价对象的抽取,实验证明LSTM在评价对象抽取任务上有较好的表现。程梦等人[9]利用双向LSTM和注意力机制,对句子进行了重新表示,并使用CRF模型对属性进行了标注。上述研究是针对评价对象实体进行单独抽取,并没有考虑评价属性。若能同时正确抽取出评价对象实体与属性,可以更快捷地获取到评价产品更多的信息。
在产品评论中,用户不仅关心评价产品实体,同时也关注评价产品属性。通过对大量真实产品评论文本的观察发现,产品评价对象经常以这三种方式出现:①产品的整体;②产品的某个部件;③产品的特性及其外延[10]。例如:在汽车评论文本中,被评价的对象通常有:“奔驰依旧是表现最出色的”“丰田的车型真是好看”“宝马的安全、质量和口碑真是没得说”。为了叙述的方便,本文对上述情形不再细分,我们将第①类的评价对象称为“产品名称”,例句中,“奔驰”“丰田”“宝马”就是评价产品名称;第②类和第③类的评价对象统称为“产品属性”。例句中的“车型”“安全”“质量”“口碑”即为评价产品属性。为了同时抽取汽车产品名称和产品属性,本文引入了挖掘中文内部笔画信息的cw2vec模型,并将双向长短期记忆模型(BiLSTM)结合CRF模型,构建了cw2vec-BiLSTM-CRF模型,用于汽车产品名称和产品属性的抽取。通过在汽车产品的评论数据集上进行实验,实验结果表明,cw2vec模型和BiLSTM-CRF模型的结合识别的汽车产品名称和产品属性性能更加有效。
1 cw2vec-BiLSTM-CRF模型构建
1.1 cw2vec[11]
目前已经存在很多的词向量模型,但是较多的词向量模型都是基于西方语言,然而,由于中文书写和西方语言完全不同,单个英文字符是不具备语义的,而中文汉字往往具有很强的语义信息,中文词语包含很少的中文字符,然而,中文字符内部包含了较强的语义信息,因此,本文使用了基于汉字笔画信息的中文词向量模型cw2vec[11]来训练词向量,以达到充分利用中文字符内部的语义信息的目标。
cw2vec模型是使用一种基于n元笔画的损失函数,公式如下:
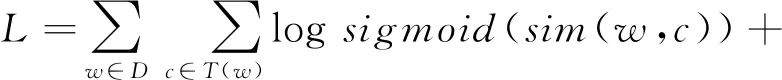
λEw′~P[logsigmoid(-sim(w,w′))]
(1)
其中,w和c分别表示当前词语和上下文的词语,T(w)是当前词语上下文窗口内的所有词语集合,D是训练语料,λ是负采样的数量。Ew′~P[·]是期望,并且选择的负采样w′服从分布P,主要按照词频分布,因此,语料中出现次数越多的词语越容易被采样。词语相似性计算函数构造如下:
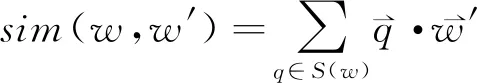
(2)
(1)词语分割:把中文词语分割为单个字。
(2)词语笔画信息获取:将词语按照字的笔画获取信息,并将这些笔画信息合并,得到词语的笔画信息。
(3)笔画特征数字化:将笔画划分为5类,利用数字1-5表示,其对应关系如表1所示。

表1 笔画名称与数字的对应关系
(4)N元笔画特征获取:提取词语笔画信息的N-gram特征。
以“宝马车型好看”为例,分词结果为:宝马 车型 好看;以“车型”为当前词语,其上下文词为:宝马、好看。cw2vec模型表示如图1所示。
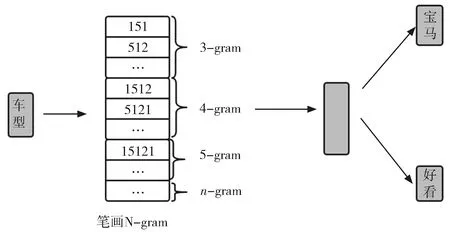
图1 以“宝马车型好看”为示例的cw2vec模型表示
如图1所示,对于“宝马 车型 好看”。首先将当前词语“车型”拆解成n元笔画,并找出其数字编码,然后按照窗口大小得到所有n元笔画,计算当前词语的n元笔画和上下文词语的相似度,再根据损失函数求梯度,并对上下文词向量和n元笔画向量进行更新。最后,利用上下文词向量(context word embedding)作为最终cw2vec模型的输出词向量。
1.2 BiLSTM-CRF
LSTM是一种基于序列标注数据的神经网络。输入序列变量(x1,x2, …,xn),返回相对应的另一个序列(h1,h2,…,hn)。LSTM模型通过特有的门结构来保持和更新状态,以达到长期记忆功能,并且已经被证明该模型能够捕获长距离依赖信息[12-14]。短期记忆模型中“三门”记忆单元计算公式分别如下:
it=σ(Wxixt+Whiht-1+Wcixt-1+bi,
(3)
ft=σ(Wxfxt+Whfht-1+Wcfxt-1+bf) ,
(4)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc) ,
(5)
ot=σ(Wxoxt+Whoht-1+Wcoxt-1+bo) ,
(6)
ht=ottanh(ct) ,
(7)
其中,σ是logistic sigmoid 函数,i表示输入门,f表示遗忘门,o表示输出门,c表示神经元向量。所有计算过程中的向量维度都与隐藏层向量h维度保持一致。其中,Whi表示隐藏层输入门矩阵,Wxo表示输入-输出门矩阵等。其中,权重矩阵是神经单元到门向量的对角矩阵,因此,每个元素在每一个门单元中只接收当前元素的单元向量。

CRF主要综合了隐马尔科夫模型和最大熵模型的优点。在CRF模型中,已知输入序列x=x1,…,xn-1,xn的情况下,可求出输出序列Y的概率p(y|x)最大时的状态序列,因此,CRF模型可用来解决序列标注问题[16]。y的条件概率定义如下:
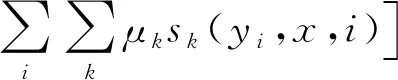
(8)
其中tk(yi-1,yi,x,i),sk(yi,x,i)表示特征函数,λk,μk是其相对应的权重,Z(x)表示归一化函数:
1.3 使用cw2vec-BiLSTM-CRF模型抽取汽车领域产品名称和产品属性
为了同时抽取评论文本中的评价对象和评价属性,本文利用cw2vec进行词向量表示,再结合BiLSTM和CRF两种模型进行抽取,其网络结构示意图如图2所示。
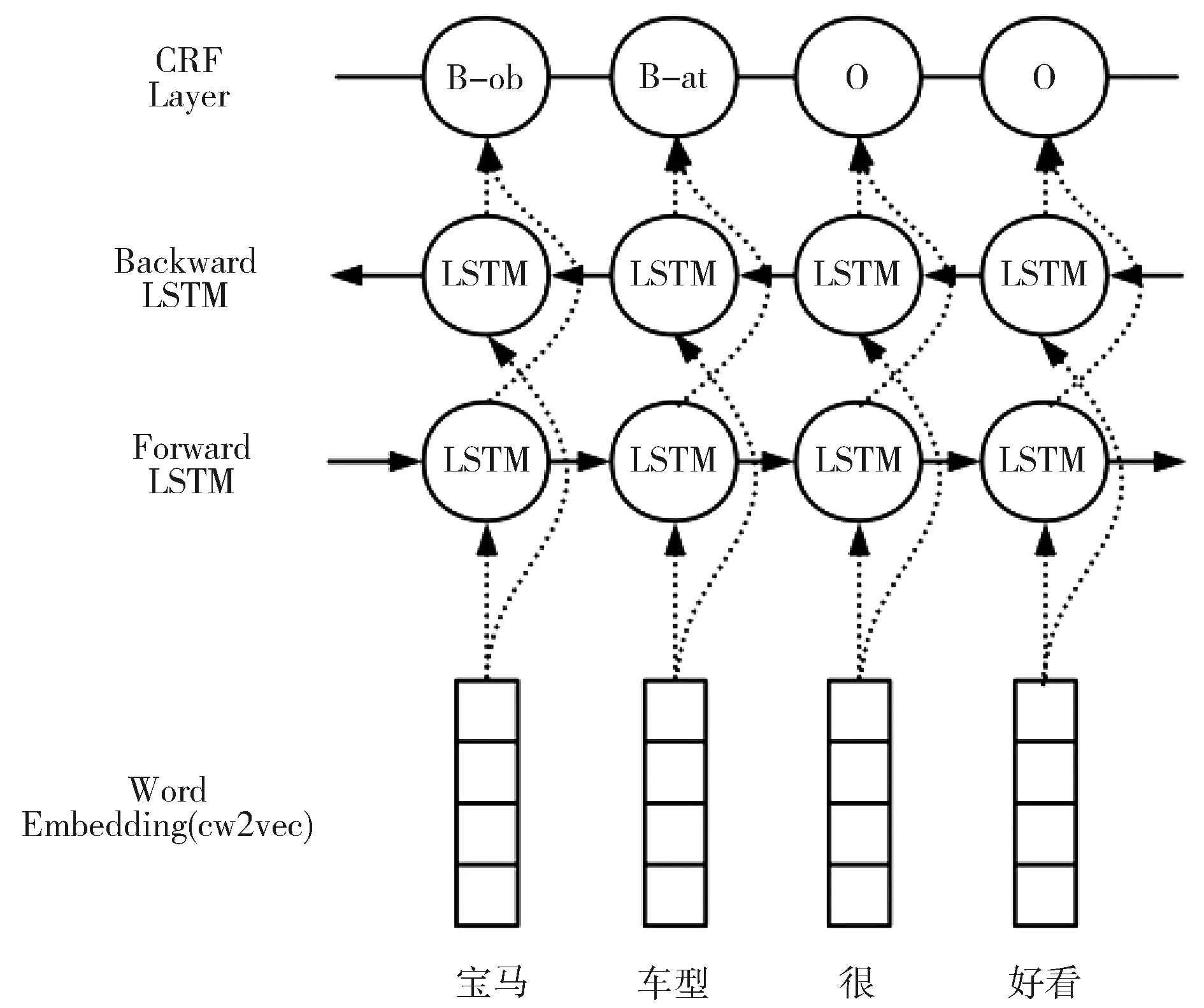
图2 BiLSTM-CRF网络结构示意图
整个抽取过程如下:
(1)使用了BIO标注法来对汽车领域产品评论语料进行标注,标注格式见表2所示。

表2 句子序列标注格式
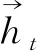
(9)
再用softmax层计算出所有可能标签的概率如公式(10)。
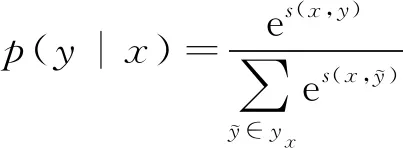
(10)
再将公式进行变换得到公式(11)
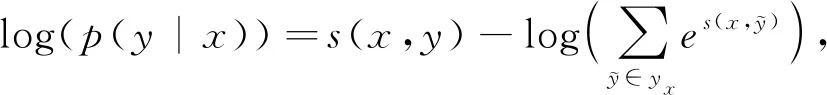
(11)
(3)多次迭代后,不断调整网络参数,获得得分最高的序列作为预测标记的正确序列。
2 实验
2.1 实验数据集与评价指标
为了对模型进行有效性评估,本文收集了汽车领域6 577条用户评论数据,并进行了手工标注。其中5 311条评论数据作为训练集,1 266条评论数据作为测试集。
产品名称与产品属性的识别评价指标采用准确率(P)、召回率(R)和综合指标(F值)。
2.2 实验方案
为了对比各类方法在汽车领域产品名称与属性抽取任务中的性能,选取以下几种方法进行比较:
1)CRF:利用条件随机场模型,结合词特征抽取产品名称和产品属性。
2)word2vec-BiLSTM:利用双向LSTM抽取产品名称和产品属性。
3)word2vec-BiLSTM-CRF:结合BiLSTM和CRF抽取产品名称和产品属性。
4)cw2vec-BiLSTM:使用cw2vec进行word embedding后,使用双向LSTM抽取产品名称和产品属性。
5)cw2vec-BiLSTM-CRF:使用cw2vec进行word embedding后,结合BiLSTM和CRF抽取产品名称和产品属性。
2.3 实验结果与分析
根据第2.2节的设置的实验,列出了5种方法在同一数据集上实验的得到的结果,实验结果见表3,其中,表中的“OB”表示产品名称、“AT”表示产品属性。
由表3在汽车领域产品名称与属性识别任务的5种方法的性能,可以看到:
(1)使用cw2vec模型后,相比于仅使用通用word2vec模型,准确率、召回率、F值都有所提升。
(2)使用CRF模型的F值是最低的。然而无论是采用word2vec还是cw2vec作为词表示,再与LSTM模型结合使用,所有的指标均有所提升,说明词向量表示是有效的。
(3)BiLSTM-CRF与BiLSTM相比,产品名称和产品属性的抽取准确率都有很大提升,表明融合了CRF模型后,通过结合前后标签将有利于预测当前标签,然而,召回率却有所降低。

表3 5种方法的性能对比
(4)5种方法识别产品名称的指标均高于识别产品属性的指标。主要原因是专业名词多集中在产品属性,例如“涡轮增压器”“涡轮进气口”等,造成识别难度较大。
通过分析识别出的产品名称与产品属性,对实验结果的错误分析如下:
(1)因产品名称与产品属性之间没有明确的界限,对预测结果产生了一定的影响。例如“2013款本田雅阁”“本田NEWCIVIC”“16.4grand 超跑”等这类“品牌+型号”组合的产品名称,在产品名称和属性识别时出现了错误标记。
(2)在线用户产品评论用词偏口语化,对汽车产品名称多有别称、简写,也给识别带来了困难。例如“benz”(奔驰的别称)为产品名称,未能正确识别。
(3)当属性词前加定语修饰时,例如“后排空间”“品牌价值”“广告成本”“配件质量”等词,识别时出现漏掉定语的情况,仅抽取出“空间”“价值”“成本”“质量”作为产品属性。
(4)当出现动词性短语时,容易识别错误。例如“涡轮进气口松动不算大问题”,此句中“涡轮进气口松动”为一个整体。
3 结论
针对汽车领域众多评论文本的分析,需要明确识别产品名称产品属性问题。本文采用了BiLSTM-CRF模型,并结合了能挖掘出中文字符笔画特征信息的cw2vec模型,提出了一种基于cw2vec-BiLSTM-CRF深度学习模型的实体识别方法。该方法利用可以记忆上文信息的LSTM 模型作为隐藏层,融合了 CRF 作为标签推理层,从而解决了文本序列标签依赖问题,同时采用了cw2vec模型,使得中文字符内部包含的语义信息得到有效利用。在汽车领域数据上进行实验,验证了cw2vec-Bi-LSTM-CRF模型在中文汽车领域产品名称和产品属性识别任务中的有效性。
