基于SRCGAN的超分辨率图像重建算法研究
2020-07-13毕玉萍李劲华赵俊莉
毕玉萍 李劲华 赵俊莉
(青岛大学数据科学与软件工程学院 山东 青岛 266000)
0 引 言
图像超分辨率(Super Resolution,SR)重建一直以来是一个热门研究方向。它是将一幅或多幅低分辨率(Low Resolution,LR)图像作为输入,输出高分辨率(High Resolution,HR)图像的一种计算机视觉任务。该研究虽然具有较高的挑战性,但有许多应用价值,如医学图像处理[1]、卫星成像[2]、面部图像增强[3-4]和压缩图像[5]等领域。
目前,图像超分辨率算法已趋于成熟,主流的学习算法主要分为三种:基于插值[6]的方法、基于重建[7]的方法和基于学习[8-10]的方法。基于插值的方法主要通过对已有特征进行观测来获取像素点,通过这些已有的像素点拟合出数学模型,从新建的数学模型中提取特征来重建图像。基于插值方法的算法存在计算量大、图像边缘和细节处理效果差的问题。基于重建的方法虽然可以重建较清晰的图像,但是存在计算量大、丢失高频细节的问题。基于深度学习的超分辨率图像重建技术主要有以下几种主要的方法:(1) 基于冗余字典建立低分辨率图片和高分辨率图片的特征块投影矩阵[11-13];(2) 通过建立数学模型实现低分辨率和高分辨率图像之间的一一对应关系[11-12],主要方法有固定的领域回归、岭回归等模型。基于深度卷积神经网络的图像超分辨率模型[14](Super Resolution Convolutional Neural Network,SRCNN)能够保持现有的重建效果,同时实现了较优的实验效果。该模型由三层卷积层组成,并分别负责特征提取、高分辨率特征表示的非线性映射以及高分辨率特征表示的非线性图像重建。SRCNN模型是直接将低分辨率图像(LR)作为输入,输出高分辨率图像(HR),与已有的传统方法相比,处理比较简单。但该方法是一个浅层的网络结构,仍然存在着纹理模糊的问题。Ledig等[15]提出了基于生成对抗网络(GAN)的图像超分辨率方法(Super Resolution Convolutional Generative Adversarial Networks,SRGAN),该方法通过深层神经网络[18-19]实现,在细节处理上取得更好的效果。
在SRGAN的基础上,本文提出一种改进的基于GANs的图像超分辨率算法,即具有类条件图像超分辨率重建框架(Super Resolution Conditional Generative Adversarial Nets,SRCGAN),SRCGAN明确GAN类标签的条件下作为GAN的输入。本文通过为判别器添加这种辅助的自监督损失,可以实现更稳定的训练,使判别器表征对生成器输出质量的依赖性降低,从而提高重建效果。
1 算法设计
1.1 生成式对抗网络
近年来,GANs作为生成模型的框架取得了相当大的成功。GAN网络结构由两个模型组成:生成模型G,其作用是生成图像集,作为判别器的输入;判别模型D,其作用是辨别图像是来自真实图像还是生成器产生的伪图像。在GAN中,发生器和判别器被训练成一个双反馈网络结构,使生成的模型分布与真实分布之间的差异最小化。考虑输入噪声的先验分布pz(z),为了了解生成器在数据x上的分布,由生成器执行从噪声分布到数据空间G(z;θg)的映射。GAN定义判别器D(x;θd),它输出的数值是来自生成器或真实数据集的概率。本文同时训练G和D以最小化对数log(1-D(G(z)))和最小化log(D(x|y))。GANs的标准公式如下:
EZ~PZ(Z)[log(1-D(G(z)))]
(1)
式中:Pdata是数据分布;PZ是通过对抗性min-max优化来学习的生成器分布。
1.2 条件生成对抗网络(CGAN)
Mirza等[18]在上述GANs的基础上提出了有条件的GANs(CGANs),CGANs[19-20]与GAN模型一样也是由生成器和判别器组成,但GAN无法控制数据的生成过程。为了解决此问题,研究者通过调整类标签上的模型,指导数据的生成过程。y被定义为类标签,此时发生器和判别器被训练成一个双反馈回路的一部分,使生成的模型分布与真实分布之间的差异最小化。考虑输入噪声的先验分布pz(z),为了了解生成器在数据x上的分布,由生成器执行从噪声分布到数据空间G(z|y;θg)的映射。GAN定义判别器D(x|y;θd),它输出的概率是判断来自生成器生成的伪数据还是真实数据。同时训练G和D在以y为条件的最小化对数log(1-D(G(z|y)))和D最小化log(D(x|y))。有条件的GANs的标准公式如下:
EZ~PZ(Z)[log(1-D(G(z|y)))]
(2)
式中:Pdata是数据分布;PZ是通过对抗性min-max优化来学习的生成器分布。
1.3 SRCGAN
在CGANs和SRGAN的启发下,本文提出了一种具有类条件的图像超分辨率重建GAN框架(SRCGAN)。首先以比例因子对HR图像(IHR)进行降采样,若要创建LR输入图像(ILR),执行检测采样处理,随后给GAN提供LR图像和原始图像中的数字标签。与SRGAN相比,本文为SRGAN框架加入了条件元素,这也是本文的改进之处。
生成器和判别器分别以D(x,y|θd)和G(x,y|θg)为条件,其中:x表示HR图像(要么是真实图像,要么是生成器产生的图像)作为输入,y是类标签。本文的对抗模式的目标是:
EILR~PG(ILR)[log(1-D(G(ILR,y),y))]
(3)
式中:Pdata是数据分布;PG是通过对抗性min-max优化来学习的生成器分布。通过式(3)的检测采样处理,待优化的目标参数减少,同时加入类标签,让网络的优化训练更具针对性,同时也提高了低分辨率图像的重建效果。本文将条件GANs框架应用于MNIST[21]数据集,并表明它产生的图像更接近MNIST数字。改进的SRGAN结构如图1所示,可知本文方法在下采样图片时加入了条件类,这些类标签是带有数据集特有属性的标签,再将处理过的图片输入到生成器,训练生成器生成的伪高分辨率的图片,生成器生成的伪高分辨率图片和真实的高分辨率图片输入到判别器中让判别器加以判别,当生成器生成的图片能够达到以假乱真的时候,模型训练完毕。本文的核心过程也是通过引入条件类解决在图像重建过程中随机处理的缺陷。通过条件类的引入,解决了重建过程中对于没有更正过程的处理,从而进一步提升生成式对抗网络的重建效果。因此,无论在准确率还是适用范围,本文方法都有效地解决了目前重建效果差的问题。
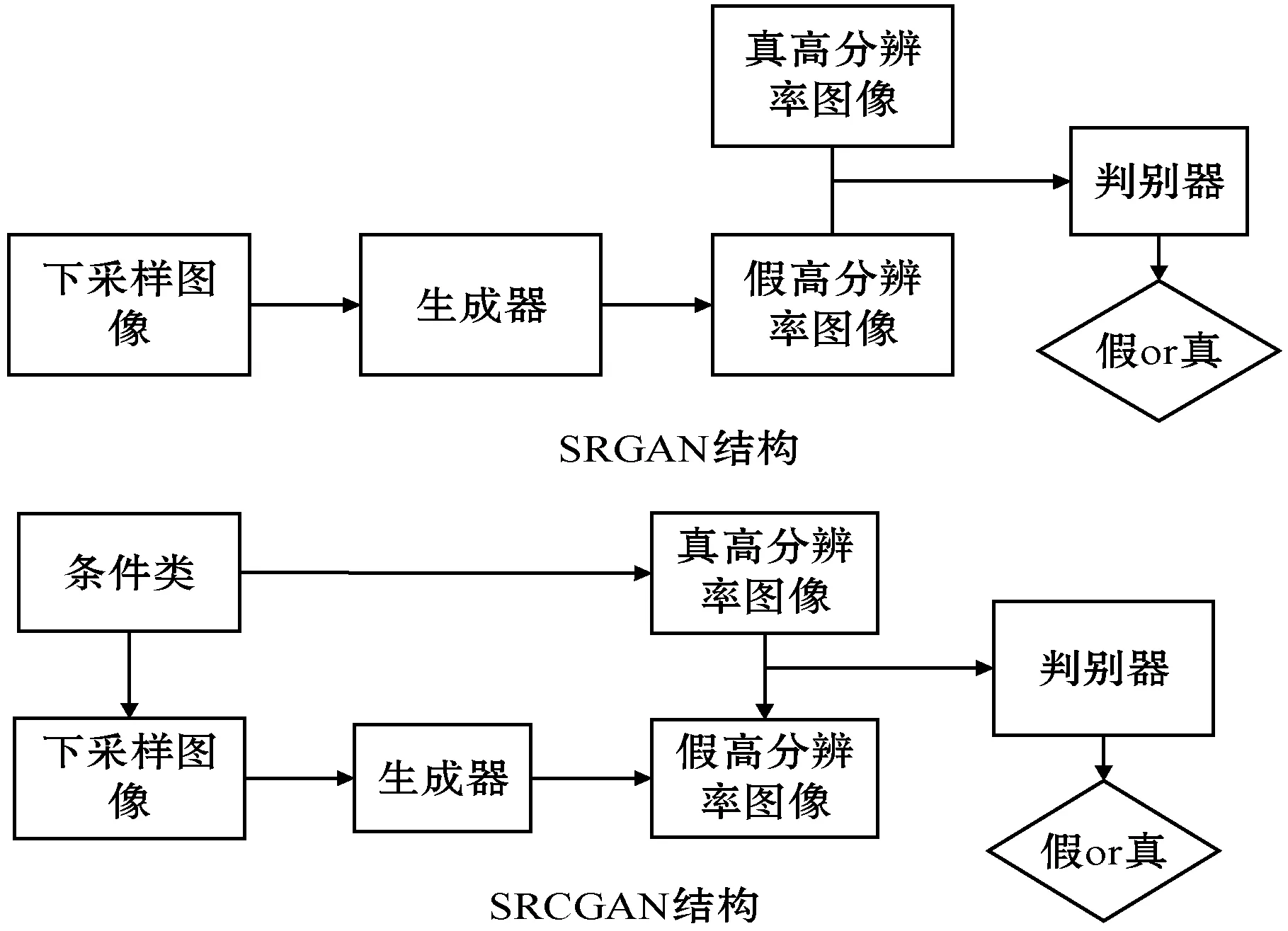
图1 SRCGAN结构图与SRGAN结构图的对比
2 实 验
2.1 数据集处理
本文使用MNIST数据集,共包含70 000幅图像,其中60 000幅用作训练集,10 000幅用作测试集,数据集为手写体数字且服从均匀分布。数据集图像尺寸大小为28×28。首先用双三次插值将图像缩小到7×7(缩小4倍),作为实验的输入,同时输入数字标签作为条件变量,评估SRCGAN相对于传统GAN(即没有任何条件变量)的性能。SRCGAN训练的批次大小为128,学习率为0.001。该模型训练了100个epochs(共迭代46 875次),利用ReLU[22]作为激活函数,Adam[23]作为优化器建立模型。对CNN分类器进行训练,该模型训练了70个epochs(共迭代32 813次),采用ReLU作为激活函数,Adam作为优化器。两种网络结构都由TensorFlow[24]库编写。
2.2 定量评估
由于选取的MNIST数据集不能通过人工验证实验效果,考虑到CNN分类器识别图片的高准确率,本文通过CNN分类器来验证实验结果。CNN分类器的作用相当于一个评分器,通过这个评分器可以比较SRGAN与SRCGAN重建图片的准确率。训练CNN对MNIST数据集的数字进行分类,以评估来自SRCGAN的预测是否可以正确地被识别为实际数字。CNN分类器在MNIST测试集上的准确率为0.986 1。将SRCGAN和SRGAN生成的图像输入CNN分类器,判别分类精度分别为0.802 3和0.682 2。这表明条件信息可以帮助生成更准确的HR图像。表1对比了SRCGAN和GAN生成的图像MNIST数字分类器的准确性。
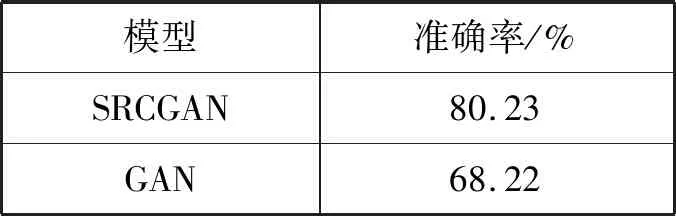
表1 SRCGAN和GAN生成的图像在MNIST测试集上通过CNN分类器判别的准确度
2.3 定性结果
图2比较了SRCGAN和GAN的输出结果,图中第一列为输入的原始低分辨率图像,第二列为GAN重建的图像,第三列为CGAN重建的图像,第四列为原始高分辨率图像。由于GAN产生的大部分图像都非常模糊,因此很难分辨出图片具体代表什么数字;另一方面,用SRCGAN生成的数字图像更清晰,数字更容易识别。SRCGAN的HR输出比缩小的图像有明显的改善。总之,基于GAN的比较分类器和可视化结果表明,加入条件项可以提高HR图像重建的质量。

图2 MNIST分类器对SRCGAN输出和GAN输出的分类结果与LR输入图像和真实HR图像比较
2.4 车牌重建实验及其分析
为了进一步验证本文算法的应用价值,对车牌数据集进行了对比实验,设置并选取标准差为10、均值为0的高斯分布来更新滤波器的初始值,并用随机梯度下降法得到目标函数的最优解。通过多次实验和调整参数,得到当放大因子为原图像的3倍时,图片重建效果表现最优。基于图片的输入,本文应用的主要方法为将RGB的颜色空间转换为YCbCr颜色空间中,通过对亮度Y通道的重建,其余则通过运用双三次插值法得到目标的最终尺寸。
本文选取了部分车牌图像进行处理,当放大因子为3的情况下将本文方法与双三次插值Bicubic算法和基于字典学习的K-SVD算法的重修效果作对比,结果如图3所示。其中第一列为原始高分辨率图像,第二列为Bicubic处理的图像,第三列为K-SVD处理后的图像,第四列为SRCGAN处理后的图像。

图3 放大因子为3的重建效果对比图
可以看出,本文方法优于其他两种算法,能够获得更加清晰的重建图片。在与Bicubic算法作对比时,本文算法得到的重建图像边缘更加清晰且更平滑,图片的整体图像视觉效果更好,且达到人眼的美学标准。而与K-SVD算法作对比时,本文算法可以完全克服K-SVD算法产生的振铃现象。车牌图像虽然经过本文算法得到的整体重建图片效果较好,但是在车牌图像重建后的中文文字部分还是不够清晰,有些细节信息不能很好地恢复和重建,与原始真实的高清车牌图像对比,重建的文字效果和真实的文字还存在一定差距。对整体车牌图像重建后也能高效清晰地重建车牌中的文字部分,是下一步研究工作中的重点和难点。
从客观角度分析,表2是对比不同算法后PSNR值的比较,当PSNR值越大,表示重建的效果越好。由表2可知,本文提出的重建算法得到的PSNR值明显高于其他两种算法,充分说明本文算法重建质量优于其他两种算法。Bicubic算法和K-SVD算法虽然在一定程度上提高了车牌图像的质量,但是重修后的图像仍存在边缘模糊的短板和缺陷。对比实验表明:本文提出的SRCGAN模型重建后的车牌图像的边缘和纹理都更加清晰,且获得的图像的重修效果的PSNR值均高于Bicubic算法和K-SVD算法得到的PSNR值,整体效果更接近原始的高分辨率图像和真实图片。这表明了SRCGAN网络结构能够有效处理细节和边缘问题,显著提高图像的重建效果。
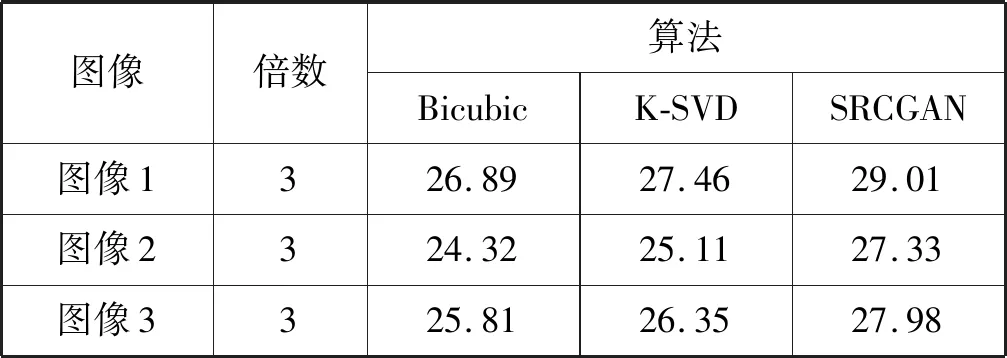
表2 不同算法对车牌重建后的PSNR值
3 结 语
本文提出并实现了图像超分辨率的方法SRCGAN。在MNIST数据集和车牌数据集上评估SRCGAN的性能后,成功地从LR输入中恢复了清晰的HR图像。模型输出与真实MNIST图像几乎一致,车牌的输出与真实图像也较为一致。SRCGAN是明确GAN类标签的条件下作为GAN的输入。深层网络结构模型和CNN架构目前已能够表现出更优的性能,但是SRCNN只能在较大的图像尺度上进行训练,并且只能在特定尺寸的训练集上起作用。本文对SRGAN进行改进,将类标签信息作为生成器的输入,可以指导生成器生成的图像更加接近数据集,从而提高图像的重建效率以及准确率。与无条件信息的GAN相比,本文方法让重建图片更精确且更接近真实图片。
