基于联合信息保持的异构领域自适应*
2020-07-10邓赵红王士同
许 鹏,邓赵红,王 骏,王士同
江南大学 人工智能和计算机学院,江苏 无锡214122
1 引言
领域自适应通过使用含有大量标签的源域数据帮助来自不同分布的目标域数据实现更高效的学习任务[1-2]。根据两个领域特征空间的异同,领域自适应可以分为同构领域自适应和异构领域自适应。而根据目标域是否存在标签,又可以分为无监督领域自适应和半监督领域自适应[3-4]。本文主要关注半监督异构领域自适应场景。
常用的领域自适应方法主要有三种,分别是基于样本选择的方法[5-6]、基于模型参数关系的方法[7-8]和基于特征变换的方法[9-10]。本文关注基于特征变换的方法。一般来说,此类方法的基本思路由两方面构成:一方面是令两个领域的数据在共享子空间中距离最小化;另一方面是在特征变换过程中对原始数据进行信息保持。则不同方法的差异可以总结为三方面,分别是共享子空间的构造方式,源域和目标域数据在共享子空间中的距离度量方式和原始数据信息的保持方式。
在共享子空间的构造方面,有对称特征变换[11]和非对称特征变换两种方式[12-13]。为了实现特征非线性变换,核方法[14]、多核学习[15]和其他非线性方法[16-17]也被引入到领域自适应中。在距离度量方面,已有最大均值差异(maximum mean discrepancy,MMD)[18]、Bregmann 距离[19]、KL 距离[20]和Wasserstein 距离[21]被用来度量两个领域在共享子空间的距离。在数据信息保持方面,已有算法主要通过流形学习来保持结构信息,比如主成分分析(principal component analysis,PCA)[22]、局部保持投影(locality preserving projection,LPP)[23]和判别局部对齐[19]等。
大量已有异构领域自适应算法虽然取得了不错的效果,但是它们有两点共同的不足:(1)在很多场景下,源域和目标域之间存在配对样本。比如在使用图片数据辅助文本分类时,图片和文本不仅具有异构性,而且存在大量的图片文本配对信息。而已有算法几乎没有利用这种配对信息。最近已有个别研究在尝试利用这种信息进行领域自适应[24-26],但是都未能充分考虑两个领域的分布差异,使得共享子空间的构造完全依赖配对样本,算法无法灵活地使用配对数据,扩展性较差。(2)已有算法在保持数据的结构信息时,一方面,它们一般通过单独采用局部的或者全局的流形方法对数据进行结构信息保持,未能充分考虑多层次的结构信息;另一方面,已有方法也未能充分利用源域和目标域的所有标签信息。而充分考虑这些信息能够有效提升算法的效果。
为了克服上述挑战,本文提出了一种联合信息保持算法(joint information preservation,JIP),所提算法可以解决半监督异构领域自适应任务。算法假设源域和目标域具有部分配对样本,源域均为有标签数据,与之配对的目标域数据也被认为是有标签数据,其他目标域数据则为无标签数据。JIP 以一种灵活可扩展的方式将配对信息和结构信息保持整合到一个领域自适应框架中。针对源域数据和目标域数据,JIP采用对称特征变化方式构造共享子空间,而后通过三部分来约束共享子空间的构造,分别是域间分布匹配、域间样本配对信息保持和多层次判别结构信息保持。
更具体的,第一部分域间分布匹配,采用常用的MMD距离,令源域和目标域数据在共享子空间中的MMD最小化。第二部分域间配对信息保持,采用典型相关性分析(canonical correlation analysis,CCA),令源域和目标域的配对样本在共享子空间中相关性最大化,从而使得共享子空间的学习既不完全依赖于配对样本,又能以一种灵活可扩展的方式对其加以利用。第三部分多层次判别结构信息保持,这里采用线性判别分析对数据进行全局结构信息保持,采用有监督局部保持投影对数据进行局部结构信息保持。整合上述三部分,最终特征变换的优化问题可以简化成为一个广义特征值分解问题。
本文的主要贡献可以归纳如下:
(1)在基于特征的异构领域自适应框架中引入了配对信息保持以解决信息损失问题,充分利用了源域和目标域之间的配对样本信息来提升域间自适应特征的学习能力。
(2)较之于传统算法中单一的结构信息保持,提出了判别多层次结构信息保持,即在充分利用数据标签信息的基础上,同时进行了局部结构信息保持和全局结构信息保持。
(3)整合上述两部分,提出了一个联合配对信息与结构信息保持的异构领域自适应算法,从而充分挖掘了信息保持策略对于提升领域自适应效果的价值。
(4)在图片分类、动作识别和多媒体数据上大量的实验验证了所提算法的有效性,超越或者至少竞争于当前最先进的异构领域自适应算法。
2 相关工作
本文主要关注适用范围更广泛也更具有挑战性的异构领域自适应(heterogeneous domain adaptation,HDA)。在基于特征变换的HDA中,HeMap[27](heterogeneous spectral mapping)是一种较早提出的经典框架,其对源域和目标域数据进行对称特征变换,一方面令源域和目标域的投影数据与原始数据差异最小化,另一方面使源域和目标域的投影数据差异最小化。算法DAMA[23](domain adaptation and manifold alignment)将流行对齐引入了HDA,一方面保持了每个领域的流形拓扑结构,另一方面进行了标签流形对齐,即同类样本在新特征空间内保持邻近关系,而非同类样本在新特征空间内保持非邻近关系。不同于HeMap 和DAMA,ARC-t[28](asymmetric regularized cross-domain transforms)将非对称特征变换引入HDA,并且核化变换矩阵使其具有更灵活的参数正则化方式。在基于模型参数关系的HDA 算法中,MMDT[29](max-margin domain transforms)同样采用非对称特征变换,而与ARC-t 不同的是MMDT 整合了大间隔模型求解,最终得到一个自适应SVM(support vector machine)。和MMDT的研究范式类似,SHFA[30](semisupervised heterogeneous feature agumentation)也是基于模型的HDA 算法,其创新在于对数据进行了特征增强,然后使用增强特征进行域适配学习。这里特征增强可以使得同一个领域内的数据具有更好的相似性,从而使得来自不同领域的数据适配效果会更好。不同于大部分算法是对原始数据进行特征变换,SHFR[31](sparse heterogeneous feature representation)首先离线对各领域数据预训练一组线性SVM,得到每个域分类器的模型参数,之后采用类似ARC-t中的非对称变换方式对分类器参数进行差异最小化。对于目标域测试样本,最后可通过整合多个被适配的源域分类器进行预测。另外一类比较重要的就是基于样本选择的算法,LCDS[32](learning cross-domain landmarks)采用了landmark 技术即在域适应过程中为源域和目标域的每个样本都添加一个权重进行优化,最终所有包含非零权重的样本都称为landmarks。TIT[18](together independent transfer)是一个领域自适应框架,其整合了领域分布差异最小化、流形结构保持、样本权重和特征选择,表现出了较之前算法都好的异构领域自适应性能。基于深度学习的算法[33-34]中均使用神经网络完成了HDA任务。有关异构领域自适应更加系统全面的文献回顾可以参考综述文章[1,3]。
已有一些与本文研究相关的工作,即在领域自适应过程中考虑多视角配对信息。这些已有的工作主要可以分为两类:一类是多视角迁移学习[35-37],这类工作假设源域是具有多个视角的有标签数据,目标域是只有一个视角的无标签数据,其主要目的是通过利用源域的大量标签信息和多视角信息来辅助目标域数据的建模。虽然这类工作也在领域自适应过程中涉及多视角信息,但不同于本文所关心的场景。第二类即本文所关注的研究范式,源域和目标域都是单视角数据,但是源域和目标域数据之间存在多视角配对样本。Yeh 等人[24]首先关注到这类数据,并利用CCA学习到一个相关子空间用作自适应特征空间并整合分类器优化过程提出了CTSVM(correlated transfer support vector machine)。Yan等人[25]提出的DCA(discriminative correlation analysis)也使用CCA 学习一个相关子空间进行领域自适应,不同的是其采用了ADMM(alternating direction method of multipliers)算法来优化目标函数。Mehrkanoon等人[26]提出的RSP-KCCA(regularized semi-paired kernel CCA)首次正式地考虑了领域自适应场景中的配对样本信息,并把问题形式化成最小二乘支持向量机的形式来求解。虽然这三个方法都考虑了源域和目标域之间的配对样本,但是它们特征空间的学习完全依赖于配对数据。实际应用中只有少量配对样本,很难构造出一个理想的特征子空间。本文所提算法正是针对此种情况的挑战,使得算法可以灵活地利用源域和目标域之间的配对样本信息,在只有少量配对样本的情况下,也可以达到较好的领域自适应效果。
3 联合信息保持
3.1 问题形式化
在异构领域自适应场景下,给定一个源域和一个目标域,并且它们属于不同的特征空间。源域包含大量有标签数据,而目标域只包含一部分有标签数据和大量的无标签数据,并且源域和目标域包含一部分配对样本。算法的目的就是利用大量源域有标签数据和部分配对样本来提高目标域数据的分类性能。
给定源域数据XS=和对应的标签YS=,目标域数据XT=和对应的伪标签。其中,ds和dt分别表示源域和目标域数据的特征维度,ns和nt分别表示源域和目标域样本的个数。假设其中源域和目标域的配对样本数为np并且np≤min{ns,nt},则源域和目标域的配对样本分别可以表示为。由于两个领域的配对样本的标签共享,则配对样本的标签可以分别表示为。根据基于特征的领域自适应算法的基本思想,即一方面要进行基本的分布匹配,另一方面要最小化信息损失,则本文所提算法可以形式化成如下形式。

其中,φ表示在构造共享子空间时对原始数据进行的特征变化,也是最终需要求解的部分。式中第一项表示最小化源域和目标域在经过φ变换后在新特征空间中的分布距离。第二项表示联合保持原始数据的配对信息和结构信息。它们的具体实现在3.2节~3.4节中详细呈现。
3.2 分布匹配
基于特征的异构领域自适应第一步就是对两个领域的数据进行分布匹配,即最小化它们在共享子空间中投影数据之间的分布距离。本文采用了同构领域自适应算法[38]中的联合分布匹配策略(joint distribution adaptation,JDA)。然而,和JDA中采用的共享变换矩阵不同,本文采用了两个不同的变换矩阵A和B来沟通异构特征空间。这里,m表示共享子空间的维度。JDA 采用MMD 同时对两个领域的边缘概率和条件概率进行了分布匹配。则在异构领域自适应场景下,JDA的优化目标可以重新表达为如下形式。

这里,式(2a)代表边缘概率分布匹配,式(2b)代表条件概率分布匹配,C代表类别个数,分别表示源域和目标域中属于类别c的样本个数。本文也采用了类似于JDA的伪标签迭代更新策略进行优化求解,详细步骤参考算法1。令WT=[AT,BT],则可通过整合式(2a)和式(2b)得到以下目标函数。

3.3 配对信息保持
为了保持配对信息,本文采用CCA[39]来最大化两个领域之间配对样本的相关性。此处CCA的目的是为了寻找一组投影向量来最大化源域投影数据aTXSP和目标域投影数据bTXTP之间的相关性。CCA的目标函数如下:
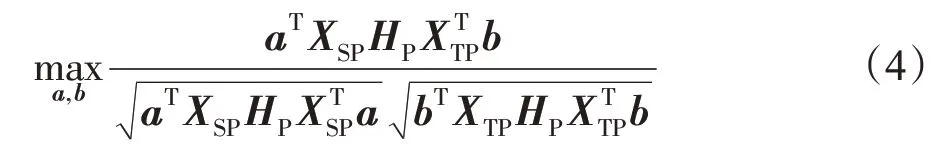
这里,HP表示中心化矩阵,它可以简化式(4)中方差和协方差的计算过程。将单位矩阵表示为,只含1的列向量为,则HP=IP-。通过优化式(4),可以得到一组投影向量并且投影子空间为1维空间。为了将投影数据扩展到高维空间,可以联合一组相关系数,则可以得到多组投影向量A=[a1,a2,…,am]和B=[b1,b2,…,bm],同时优化一组相关系数的目标函数如下:
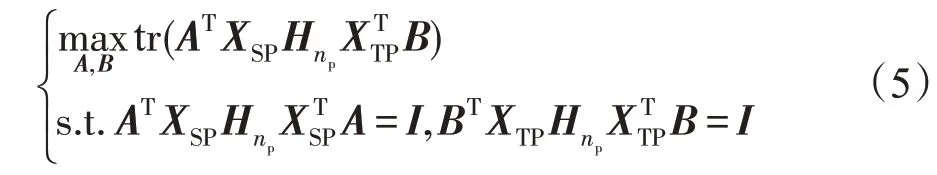
因为投影向量的缩放并不会影响式(4)的最优解,所以才能导出式(5)的有约束优化问题。求解式(5)最常用的方法是拉格朗日乘子法,采用此方法求解,投影矩阵A和B可以依次按顺序得到求解。
在所提算法中,要将配对信息保持整合到分布匹配的框架中。因此,投影矩阵需要同时得到求解而非依次求解。给定两个领域的配对样本,则均为固定值。因此式(5)中等式约束的主要作用是限制投影向量的大小,从而可以只优化其方向。为了对两个投影矩阵同时进行优化,式(5)可以重新整理成如下形式:

因为投影向量的大小并不会影响最终的优化结果,只需要有个约束就可以,所以此处对于A和B大小的约束条件被暂时丢弃了,这个约束条件将在3.5节继续讨论。令WT=[AT,BT],则式(6)可以重新表达为如下形式:
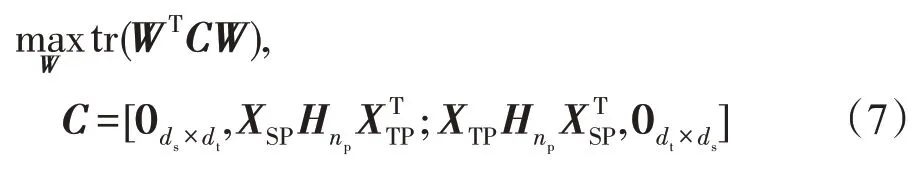
这里,C被叫作相关矩阵,则配对信息保持最终被形式化成式(7)。
3.4 结构信息保持
为了更有效地保持原始数据的结构信息,所提算法同时采用了局部和全局的流形方法。同时为了充分利用源域数据的标签和目标域数据的伪标签,本文采用判别式流形方法。
3.4.1 局部结构保持
为了保持数据的局部流形结构,本文采用LPP算法[40]。LPP 算法是拉普拉斯特征映射[41]的一种线性近似,它能够在线性变化条件仍然保持原始样本的近邻结构关系。LPP的目标函数如下所示。
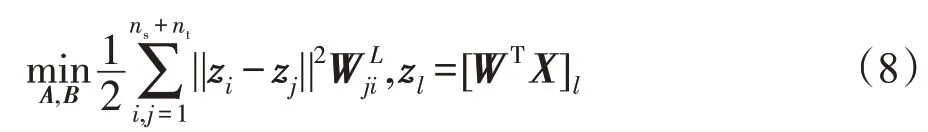
这里,l=1,2,…,(ns+nt)表示投影样本的索引,WL是邻接矩阵,它可以度量每两个样本xi和xj之间的距离。定义D为一个对角矩阵Dii=,则拉普拉斯矩阵可以定义为L=D-WL。式(8)同样可以转化成如下矩阵迹的形式来优化。

此处邻接矩阵WL可以计算每两个样本之间的距离来构造。有很多种方式可以用来构造样本间的距离,比如欧几里德距离、余弦距离、局部近邻关系和标签信息。为了有效地利用标签信息,本文中邻接矩阵WL通过判别式的余弦距离来构造[18]。
3.4.2 全局结构保持
对于未知结构的数据,除了保持局部结构信息外,全局结构信息的保持也很重要,而已有的算法往往只保持了它们其中的一种。本文采用了线性判别分析[42]结构信息,也就是最小化类内散度,最大化类间散度,目标函数如下:

这里,Sb和Sw分别表示类间散度矩阵和类内散度矩阵,Ssb和Ssw代表源域数据的散度矩阵,而Stb和Stw代表目标域数据的散度矩阵。它们的计算公式如下所示:

这里的下标S、s 和T、t 分别表示属于源域和目标域的数据。表示属于第i类的数据矩阵;表示属于第i类的样本个数。表示第i类样本的中心化矩阵,它们的计算和式(4)中的HP类似,唯一的不同是将np替换为表示属于第i类样本的样本均值;μs和μt分别表示源域和目标域数据所有样本的样本均值。
3.5 目标函数和优化
通过整合式(3)、式(7)、式(9)和式(10),并引入正则化参数α、β和λ来分别控制局部结构保持、配对信息保持和全局结构保持之间的平衡关系,则可得到最终的目标函数如下:

由于W的缩放并不会影响式(12)的求解,因此通过缩放W将式(12)的分母看作是一个约束条件,从而使得式(12)只有唯一解。这样就相当于为投影向量添加了约束,解决了式(6)中的遗留的无约束优化问题。最终需要优化的目标函数如下:
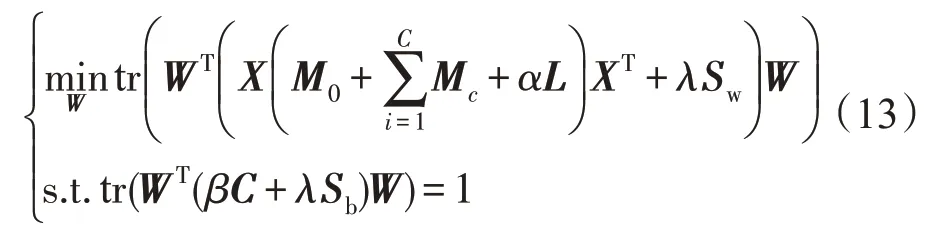
使用拉格朗日乘子法,式(13)可以转化成如式(14)所示的优化形式:

这里,Φ=diag(φ1,φ2,…,φm)代表拉格朗日乘子,m代表共享子空间维度,令=0,可得如下等式:

最终,式(12)的优化问题转化成了式(15)的广义特征值分解问题。则求解最优的W变成了求解式(15)中最小的m个特征值以及对应的特征向量所组成的映射矩阵W。详细的算法流程如算法1所示。
算法1联合信息保持

4 实验
4.1 数据集
本文分别在3个数据集上验证了所提算法的实验效果,它们分别是图片识别数据集Caltech-Office[32]、动作识别数据集IXMAS[24]和内容检索数据集WIKI[26]。
Caltech-Office 是一个由Caltech 数据集和Office数据集组成的图片分类数据集。Office 数据集包含31 类,采集自3 种不同的来源,分别是AMAZON(A)、Webcam(W)和DSLR(D)。Caltech(C)数据集包含256类。在实验中,4种不同的来源被当作4个小数据集,这4个小数据集共有的10类被选出来用于实验。之后对所有图片提取两种特征,分别是SURF(speed up robust feature)特征和DeCAF(deep convolutional activation feature)特征。这两种提取出来的特征就被当作图片的两个视角,为了构造异构领域自适应任务,每个视角都被当作领域自适应中的源域或者目标域。通过上述构造,在领域自适应任务中两个域正好同时也代表两个视角,因此可以很方便地构造配对样本。构造的8 个具有配对样本的异构领域自适应任务如表1 所示,以A-D2S 为例,它表示在A 数据集上,由源域的DeCAF 特征向目标域的SURF特征的迁移。
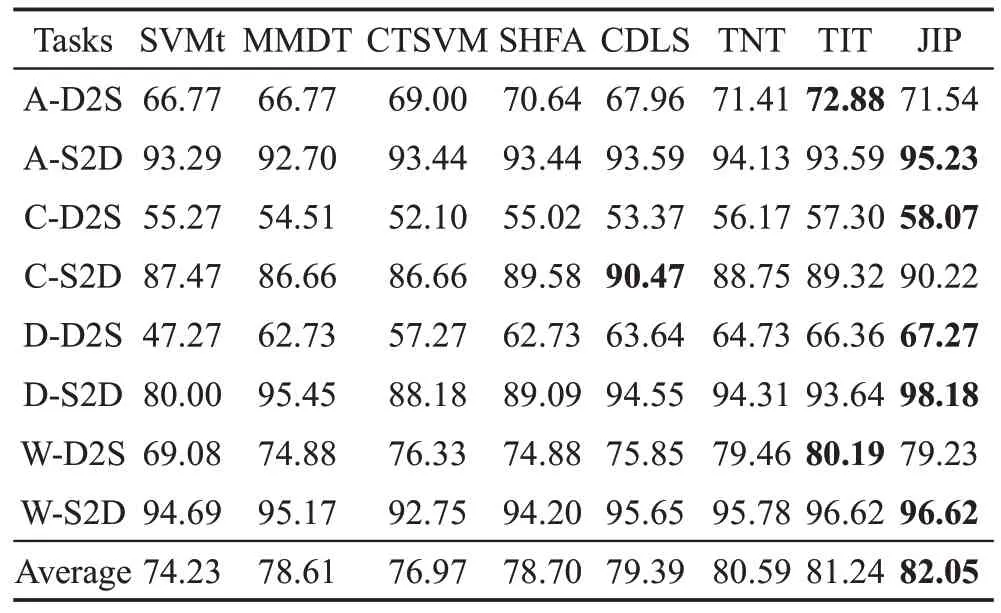
Table 1 Accuracy of algorithms on Caltech-Office datasets表1 在Caltech-Office 数据集上各算法的分类精度 %
IXMAS 是一个动作识别数据集,它一共包含11类,每类动作包含36 个样本。这个数据集中的动作图片都是由5个摄像机拍摄的,因此每个摄像机拍的图片被当作是一个视角或者是一个域。之后采用文献[26]中的预处理方式,将图片转化成1 000 维的向量。实验中,采用来自任意两个相机的图片来构造具有配对样本的异构领域自适应任务。由于每个相机都可以被当作是源域或者目标域,因此在5个相机上一共可以构造20个任务。
WIKI 是一个从网页上构造的数据集,每个样本都包含网页的一张图片和其对应的文本描述。按文献[26]的方式,其中图片使用SIFT(scale invariant feature transform)特征被处理成了128 维的向量,其中的文本使用性判别分析方式被处理成了10维的向量。在实验中,本文选择了5 类,每类包含100 个样本。同样的,这里WIKI数据集包含的图片的文本视角同时也可以被当作是源域或者目标域。从而,可以构造两个异构领域自适应任务,分别是img2txt 和txt2img,其中img2txt 表示从图像到文本的迁移,txt2img表示从文本到图像的迁移。
4.2 实验设置
在实验部分,本文采用了7 个算法作为对比算法。其中将SVMt 作为基线对比算法,SVMt 算法只使用目标域的有标签样本训练一个SVM(support vector machine)分类器,不借用任何源域数据的帮助。另外6 个对比算法都是较先进的HDA 算法,它们分别是MMDT[29]、CTSVM[24]、SHFA[30]、LCDS[32]、TNT(transfer neural trees)[33],它们的详细介绍请参考第2章相关工作。对于所有算法,涉及到迭代策略的算法迭代次数都设置为5;共享子空间维度都设置为100;所有最优正则化参数都通过网格搜索的方式从区间{0,0.01,0.1,1,10,100}中搜索。
对于在Caltech-Office 和IXMAS 数据集上的实验,本文选择每个域30%的样本作为配对样本。对于WIKI 数据集,分别选择每个域10%、20%、30%和40%的样本作为配对样本,来评估算法在不同比例的配对样本上的表现。在所有算法的目标域数据中,只有配对样本是有标签的,其余样本均为无标签样本。
4.3 结果分析
在Caltech-Office 数据集上的实验结果如表1 所示。由表1可知,所提算法在Caltech-Office数据集的8 个任务上有5 个任务都排名第一,在其他3 个任务上也取得了仅次于最优算法的效果,而且所提算法的平均精度在所有对比算法中排名第一。较之于没有采用任何迁移策略的基础对比算法SVMt,所提算法提升了大约8个百分点的精度,从而验证了本文迁移策略的有效性。对于算法MMDT、SHFA 和TIT,它们都包含和所提算法类似的特征变换过程而且容易产生信息损失,但是它们的信息保持策略都较为单一,因此信息损失问题严重影响了它们的算法效果。对于算法CTSVM,其仅仅采用了配对样本学习共享子空间,未能充分利用非配对样本信息,因此算法效果低于所提算法。所提算法甚至优于基于神经网络的TNT 算法,充分验证了联合信息保持对于提升算法效果的作用。
在IXMAS 数据集上的实验结果如图1 所示,显然所提算法在20个任务上的平均性能好于所有对比算法,并且在目标域数据上取得了高达80.38%的分类精度。
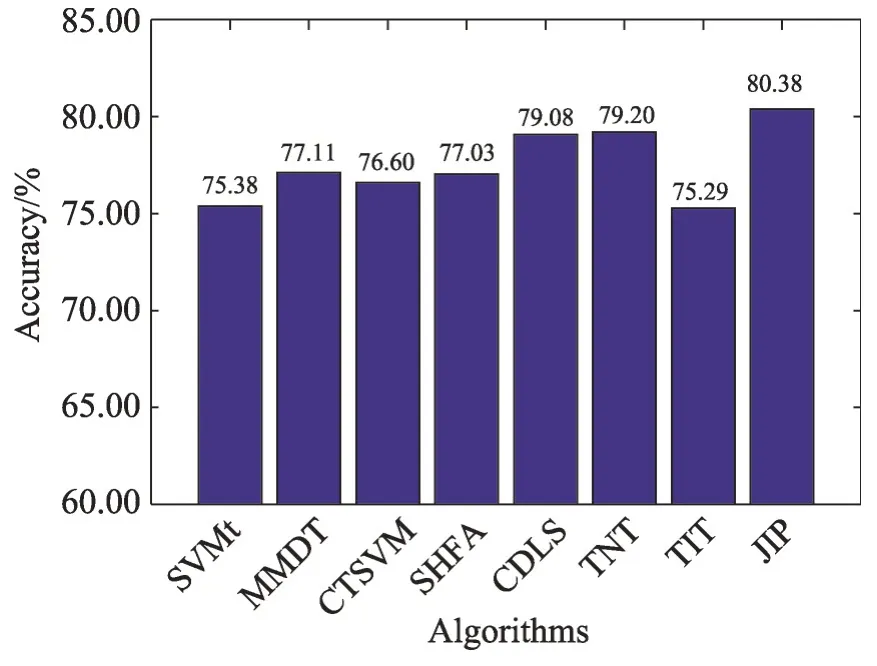
Fig.1 Accuracy of algorithms on IXMAS dataset图1 在IXMAS数据集上各算法的分类精度
在WIKI 数据集上的实验结果如表2 所示,在WIKI数据集上一共有4种不同配对样本比例的实验设置。由表2 可以看出,随着配对样本比例的上升,算法的效果整体上处于上升趋势。对于txt2img 任务,随着配对样本比例的上升,效果提升较为明显,由最初的配对样本比例10%的精度47.56%提升到配对样本比例30%的精度54.57%。由表可知当配对样本增加到40%后,两个任务上分类精度都没有太大的变化,这也说明了在一定范围内配对样本的比例会影响模型的效果,随着配对样本比例的增加,模型效果会由最开始的逐步提升到后来的趋于平稳。考虑在不同配对样本比例设置下,两个不同任务上的平均性能,所提算法较之于其他对比算法也取得了最优效果。

Table 2 Accuracy of algorithms on WIKI datasets表2 在WIKI数据集上各算法的分类精度
4.4 模型分析
本节将分析算法的收敛性和模型的共享子空间维度对于异构领域自适应效果的影响。同时也会通过分析配对信息保持项和结构信息保持项的正则化参数来分析它们的有效性,从而验证联合信息保持对于算法的意义。
4.4.1 收敛性和维度分析
影响所提算法效果的两个重要参数,一个是算法迭代的次数,一个是共享子空间的维度。图2(a)和图2(b)分别展示了在Caltech-Office数据集上随着迭代次数和样本维度的变化算法精度的变化效果。为了简化表示,图中的每个任务的精度都被整体做了上移或者下移的调整,这并不会影响趋势分析的结果。由图2(a)可知,算法具有良好的收敛性,在绝大部分任务上算法完成第3 次迭代以后基本就已经达到了收敛。由图2(b)可知,对于不同的异构领域自适应任务,算法效果随着维度变化而产生的变化趋势也不同,并且最高精度也不一定在最高维度处取得。如果固定其他所有参数,让算法只对共享子空间维度从10 到100 以10 为间隔进行寻优,那么所提算法在Caltech-Office 的8 个任务上最优精度的平均值为82.30%。

Fig.2 Parameter analysis图2 参数分析
4.4.2 信息保持有效性分析
本文从以下四方面分析了信息保持的有效性,从而验证了所提算法的合理性。在图3(a)~图3(c)中,固定其他所有参数,令式(12)中各项的正则化参数α、β和λ分别被设置为0或者是最优参数。由图可以看出,对于绝大部分任务当参数设置为最优参数时总比设置为0时效果要好,这就说明了这一项信息保持的有效性。图3(a)中的柱状图分别表示包含配对信息保持项和不包含配对信息保持项时算法的效果,由图可以看出,除了第4个任务C-S2D,在其他7个任务上算法效果均有较大幅度提升,这就验证了配对信息保持的有效性。同理图3(b)和图3(c)分别将局部信息和全局信息保持项设置为0 或者最优参数,结果中算法效果的提升也验证了其信息保持的有效性。在图3(d)中,局部结构信息和全局结构信息项的正则化参数同时设置为0,从图中可知,图3(d)的精度提升高于图3(b)和图3(c),则验证了较之于单一的局部结构信息保持或者全局结构信息保持,层次结构信息保持能更有效地提升领域自适应的效果。

Fig.3 Effectiveness analysis of information preservation图3 信息保持有效性分析
5 结束语
为了充分考虑领域自适应场景中存在的配对样本,本文提出了一个新的异构领域自适应算法。所提算法将联合信息保持和分布匹配整合到一起,有效地减弱了分布匹配过程中信息损失的问题。不同于以往算法在分布匹配过程中只采用局部的或者全局的结构信息保持策略,所提算法既保持了两个领域之间的配对信息,又保持了数据的层次结构信息,通过有效减轻信息损失提高了算法的领域自适应能力。在三个数据集上的实验效果显示了所提算法的优越性。算法的一个不足之处就是正则化参数的确定依赖于网格搜索,在大型数据集上较为费时。未来的工作将侧重于发明一些自适应的策略算法来确定参数的取值。
