基于深度学习模型的非结构化数据标注方法研究
2020-07-09普措才仁秦亚红
普措才仁,秦亚红
(西北民族大学 数学与计算机科学学院,甘肃 兰州 730030)
0 引言
随着开发文本和图像自动分析深度学习方法的发展,要求创建大型、密集注释的训练数据集,通常由Amazon Mechanical Turk的人工标记.虽然通过非结构化数据包获取数据集注释可以创建由人类审核的黄金标准标签,但这是一个耗时且昂贵的过程,例如,Visual Genome数据集包含了100 k多个图像的密集注释,包含了33 000多名有报酬的工人六个多月的时间[1-2].随着对大型标记数据集的需求不断增加,迫切需要对非结构化数据包注释进行准确和高效的评估.本文探索了深度学习和自然语言处理技术对于非结构化众包数据标签中自动识别用户混淆的应用.数据集包含图像、计算机生成的针对每幅图像的问题以及社交媒体用户的响应.如果(1)响应包含不正确或不相关的答案,(2)无法从给定的图像回答问题,则确定用户响应显示出混淆.
数据的初步分析表明,评估人员通常可以在不查阅相应图像的情况下准确地识别反应中的混淆[1].因此,为了研究图像特征在分类器性能中的作用,本文将混淆检测问题分为两个子任务:①视觉问题响应(VQR),包括分析问题、用户的反应和图像特征;②问题响应(QR),完全依赖于问题和回答.对于每个任务,首先通过预测二进制标签来执行混淆的二进制分类0表示正确答案的存在,1表示上述定义的混淆;然后,从非结构化响应文本中识别出正确的答案.
创建用于评估非结构化数据包标签准确性的自动化方法,能够大大改善现代深度学习工作流范式,减少对非结构化数据包数据进行手动质量分析的需要,并允许在社交媒体平台上使用用户的注释.
1 相关工作
本文将讨论使用图像特征和文本嵌入对数据进行分类的相关方法.
1.1 视觉问题响应(VQR)任务
微软研究公司2017年进行的一项研究提出了一种自下而上和自上而下相结合的注意机制,从图像中提取特征[3-4]:①一个更快的R-CNN模型被用来识别突出的特征(自下而上);②问题文本用作上下文来衡量这些特性(自上而下).从问题文本中提取特征并与图像特征相结合,生成图像和问题的联合嵌入.
Pythia是由Facebook AI Research设计的一个模型,它是2018年视觉问答挑战(VQA)的一个项目,它在VQA_v2.0数据集上达到最高性能(准确率为72.27%).Pythia使用自下而上和自上而下的注意模型作为基线,进行了一系列关键的修改,例如注意机制的改变和基于特征金字塔网络的检测器进行特征提取的使用[7,8,16].Pythia模型为跨图像和文本数据组合特征提供了一种有效的方法,由此发现它是VQR任务的一个合适的起点.然而,由于本文任务的性质,有必要做出重大修改.
1.2 问题响应(QR)任务
经过预先训练的上下文词表示已经被证明可以提高机器对语言的理解[17,10].Google AI在2018年进行的一项研究中,提出了一种新的转换学习方法,称为BERT(Transformers的双向编码器表示),用于生成单词的上下文编码.BERT方法是一种无监督的学习方法,它涉及到使用转换器训练一个深度双向语言模型,然后在其他NLP任务中使用学习编码.
QR任务依赖于来自问题和用户响应的基于文本的特性,因此发现BERT方法是一个合适的起点。由于QR任务不同于标准NLP任务(如问答预测),因此对其自定义化是必须的.
2 数据与方法
2.1 数据
本文的数据包括从社交媒体获取的50 628个图像—问题—回答三组.在Instagram上上传公共照片的用户,会被机器人根据照片的特征来提问,并收集用户的回答,然后收入这个数据集.用户响应以非结构化自然语言数据的形式出现,包括口语、拼写错误和表情符号.回复的平均长度为35.9个字符或6.8个单词.本文的数据集中的所有三组信息都由Amazon Turk工作人员手工标注的真实答案.首先分配二进制标签来表示用户响应中是否存在混淆,如果AmazonTurk注解器无法在用户响应中识别正确的答案,则分配一个标签为1,否则指定标签为0.然后,给所有具有准确的用户响应(标签=0)示例添加附加注释,以便于识别非结构化响应中正确的答案短语.在本研究过程中设计了一个自定义的、能识别表情符号的标识器,用于从响应中提取标识.然后,用答案跨度对所有示例进行注释,包括关于响应标记化的真实答案的起始和结束索引.由于研究过程中所使用数据集中的真实答案是人工编写的,因此存在相当大的噪音.在许多情况下,真实答案并不是用户响应的精确匹配或子字符串.因此,采用模糊字符串匹配算法进行跨度识别.在设计标记化和SPAN提取方法方面进行了大量的开发工作,以解决各种边缘情况(在非结构化响应中非常常见).在某些情况下,尽管在上一步中被标记为“不混淆”(标签=0),但在用户响应中找不到真实答案.这些示例已从数据集中删除[3-5].
2.2 方法
2.2.1 基线模型
本文设计了两个基线模型来识别用户通过问题和响应评估基于文本的特征进行二进制预测,而没有考虑图像特征[6,7,16].
对于研究过程中最初的基线方法,设计了一个单词包模型.问题和响应的朴素标记是基于空格字符执行,并从训练集中出现的10 000个最频繁的单词中生成固定词汇表,然后将所有问题和响应编码为10 000大小的字袋频率矢量.问题和响应向量在被连接并通过最终完全连接层和sigmoid非线性之前,通过分离全连通层和ReLU非线性逐个传递,这导致单个值表示混淆的概率.
第二个基线模型涉及到一个更复杂的神经模型以及一种不同的输入编码方法的使用,再一次执行朴素标记化.问题和用户响应中的每个标记都用300维GloVe向量或300维emoji2向量表示[15,6].然后,编码问题和用户响应通过分离单层的单向的LSTMs传递[9].LSTMs的最终隐藏状态被连接起来,并通过一个全连接层和一个退出层传递.最后,将sigmoid非线性应用于输出,以获得混淆的概率.
2.2.2 视觉问题响应(VQR)
Pythia模型是一个有效的起点,但对执行VQR任务来说,重大的结构改变是必要的.鉴于Pythia预测给定图像和问题的答案标签,本文的模型使用图像—问题—响应三种方法来预测响应是否包含对基于图片问题的正确答案.另一个重要的问题是自然语言与格式化输入之间的区别.Pythia模型和标准的可视问题响应数据集仅用于处理格式化的答案(例如“表格”).另一方面,VQR数据集使用自然语言响应,例如“是的,这是我祖母的桌子.”
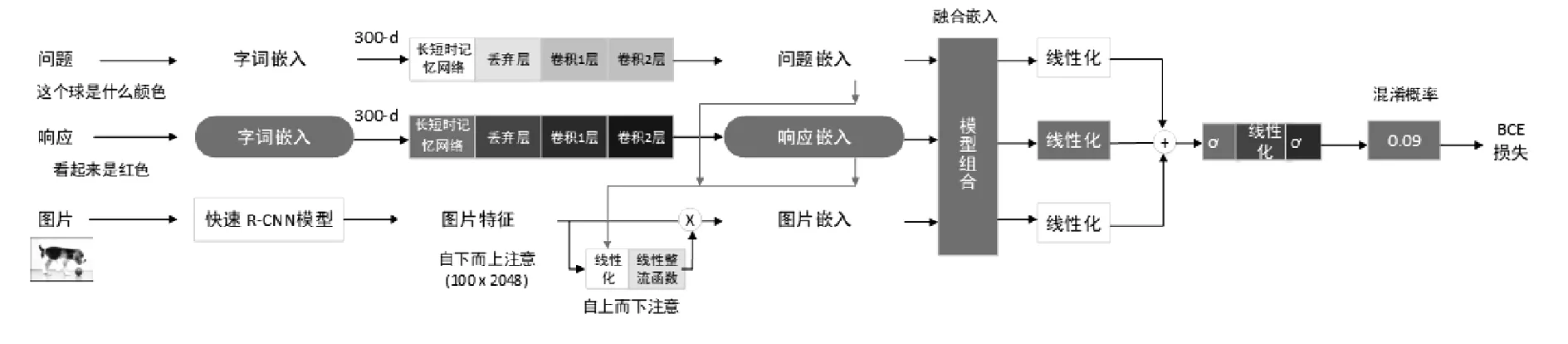
本文对Pythia体系结构的第一个修改是输入数据的映射,将数据集转换为COCO格式,成为标签和响应添加字段(如图1所示).与此同时,开发了一个自定义标识程序来处理非结构化输入,用来解决格式文本数据中通常不存在的各种边缘情况.例如,许多响应包含没有分隔空格的表情符号和标点符号.通过标记程序处理这些情况,以避免

图1 VQR数据集格式
VQR数据集在单个JSON条目中使用的自定义格式,以Microsoft COCO数据集为模型[4].
为了处理用户响应,向Pythia体系结构添加了一个重要的扩展,如图1所示.首先,生成用户响应的单词嵌入.然后,编码通过大小为1 028的退出层之后的两个卷积层和最后的一个Softmax层的隐藏状态的LSTM传递.在获得用户响应的编码后,将每个表示传递给单个线性层和ReLU非线性,生成图像、问题和响应嵌入的联合嵌入,然后计算一个加权的Hadamard乘积.在下面的方程中,e表示联合嵌入,f表示线性层,i表示图像代表,q和r表示问题和响应嵌入.
e=(2*fi(i))∘(0.5*fq(q))∘(0.5*fr(r))
(1)
对于二进制分类,用修改Pythia模型来产生单类输出.通过三个线性层的联合嵌入,组合输出,并对结果进行sigmoid非线性化操作.然后,这个张量通过一个线性层和第二个sigmoid非线性输出.分类器的输出值为0≪y∧≪10,表示用户混淆的概率.计算加权的BCE损失,并按类别比率分配权重.
对于答案预测,Pythia模型进行了修改,以预测用户响应中真实答案的开始和结束索引.节点嵌入通过三个独立的非线性层(每个层由一个线性层和ReLU非线性层组成)和三个线性层.然后,将输出组合起来并通过两个额外的线性层传递,最后对输出应用一个Softmax激活函数.两个由此产生的张量大小为30,表示响应中的最大标记数,第一个张量表示可能是答案跨度开始的指数之间的概率分布.同样,第二个张量表示可能是答案跨度结束的指数之间的概率分布.最后计算预测范围内的BCE损失.
2.2.3 问题响应(QR)
BERT体系结构是QR任务的有效起点.本文所使用的模型建立在GoogleAI预训练的BERT的开源模型基础上.对于二进制分类,来自BERT模型的集合输出通过一个退出层和一个全连接的层传递,产生两个输出类.之后,应用Softmax激活函数.第一个类的输出结果值代表用户给出正确答案的概率,而第二类的值表示用户混淆的概率.这样做是为了模仿BERT现有的分类结构.实际上,AUC-ROC是仅根据第二类的输出计算的[10-11].
(a) 二进制分类的VQR模型

(b) 答案预测的VQR模型
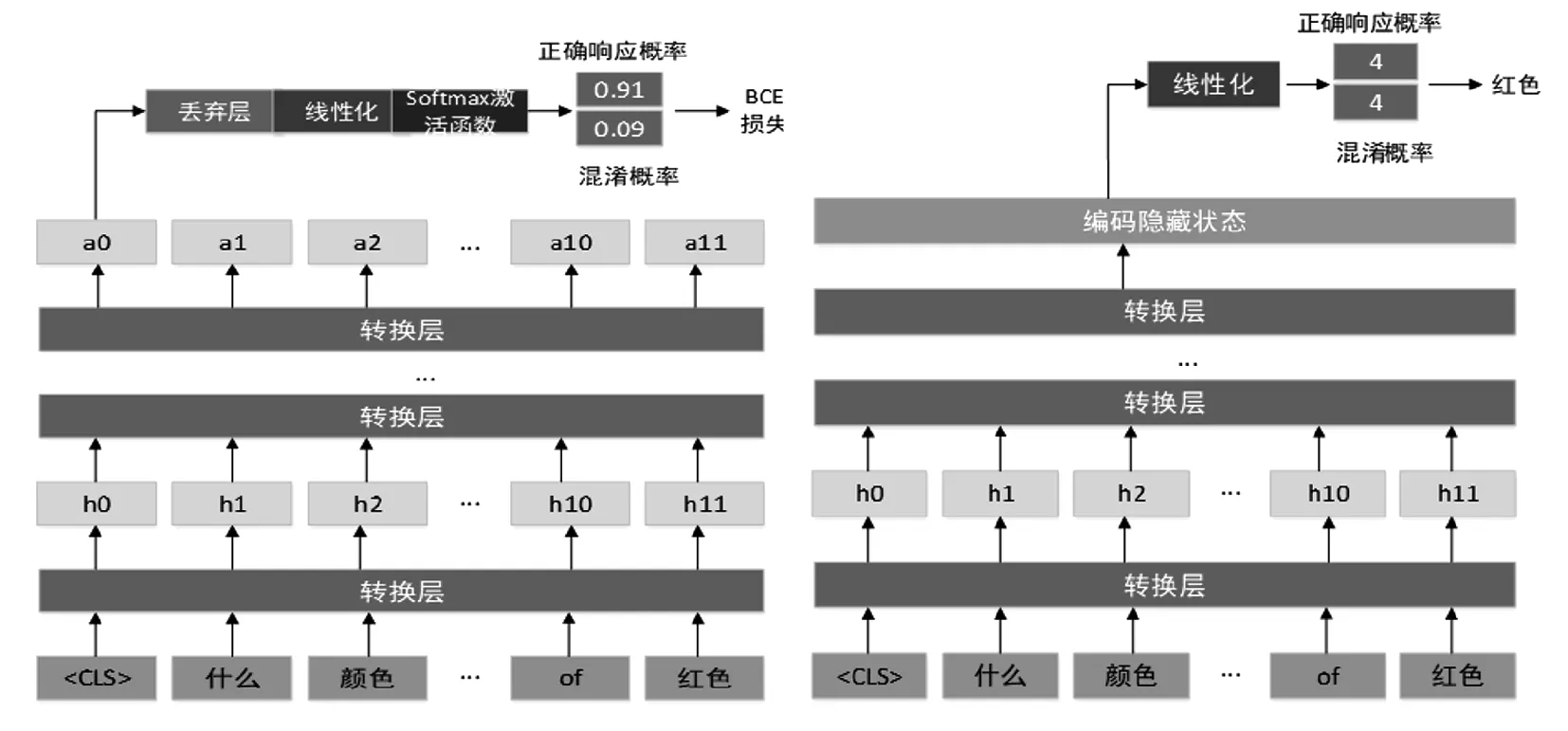
图2所示,初始的Pythia体系结构用浅灰色(如图a中的最上方字词嵌入背景色)显示.本文的自定义用深灰色(如图a中中间字词嵌入背景色)显示.对于答案预测,编码隐藏状态与最后一个通过单一的全连接层的注意块相对应.这使得两个输出类表示响应标记中的索引.第一个值表示答案跨度的开始索引,第二个值表示结束索引.由于BERT执行子字标记化,所以必须在预测的输出索引和字级响应标记之间进行对齐.
如图3所示,本文还设计了一个基于BERT体系结构的多任务模型,同时对两个任务进行训练,对BERT结构的修改是灰色的(如图a中丢弃层的背景色).对于数据集中的每个示例,该模型识别出用户混淆,并预测答案范围,将两个任务的损失值组合在一起.但是,在用户响应显示混淆的情况下(因此没有相关的答案跨度),跨度提取的损失值被手动设置为0.因此,头部提取的答案只对有效的响应更新.
(a) 二进制分类的QR模型 (b) 答案预测的QR模型
图3 QR二进制分类和答案预测的模型结构
3 实验设计与结果
3.1 评估方法
本文通过计算精度、查全率、f1分数和AUC-ROC分数来评估二进制分类任务的性能.答案提取任务的表现用f1和精确匹配(Emm)分数进行评估,并遵循SQuAD挑战赛制定的标准[12].在质量上,本文探讨了模型所做的正确和错误的预测,发现研究过程中使用的模型产生了令人惊讶的结果.由于这个数据集以前还没有发布,所以本次研究的分数是这个数据集上第一个现有的执行者[13-14].
3.2 实验设计
对于单词包基线,本文使用学习率为0.001和默认参数(β1=0.9,β2=0.99)的Adam优化器对模型进行了三次以上大小为16批次的迭代训练.该模型的总训练时间为10小时.对于使用预先训练过的GloVe词嵌入的基线,再次使用学习速率为0.001、默认参数(β1=0.9,β2=0.99)的Adam优化器,对模型进行了大小为32批次的五次迭代训练.训练这个模型大概花了18个小时.
对基于Pythia的VQR方法,首先使用一个快速R-CNN模型对所有图像进行预处理,以提取特征.完成这个过程需要花费四天时间.使用学习率为0.0001的Adamax优化器,对大小为32的批量处理的模型进行了超过12 000次的迭代训练.在显著优化代码库和预处理输入数据之后,所耗费的训练时间减少了4倍,只有88分钟.
对基于BERT的QR方法,对模型进行了10次以上的大小为32批次的迭代训练,大约花费了一个小时.这时使用的是5e-5的默认BERT训练速率的Adam优化器.因为BERT需要一个最大的序列长度,所以执行一个自定义修整方法以适应当前使用的数据集,将组合的最大序列长度设为50.但这表示子字标记化后的标记的合并总数,因此有几个示例超过了最大长度.在这些情况下,修整方法随机选择一个响应窗口,这样就包含了基本的真实答案,而丢弃了其余的响应.如果用户响应不包含真实答案,则会选择一个随机窗口.
3.3 实验结果
表1 用于二进制分类和答案预测任务的延迟测试集模型性能比较
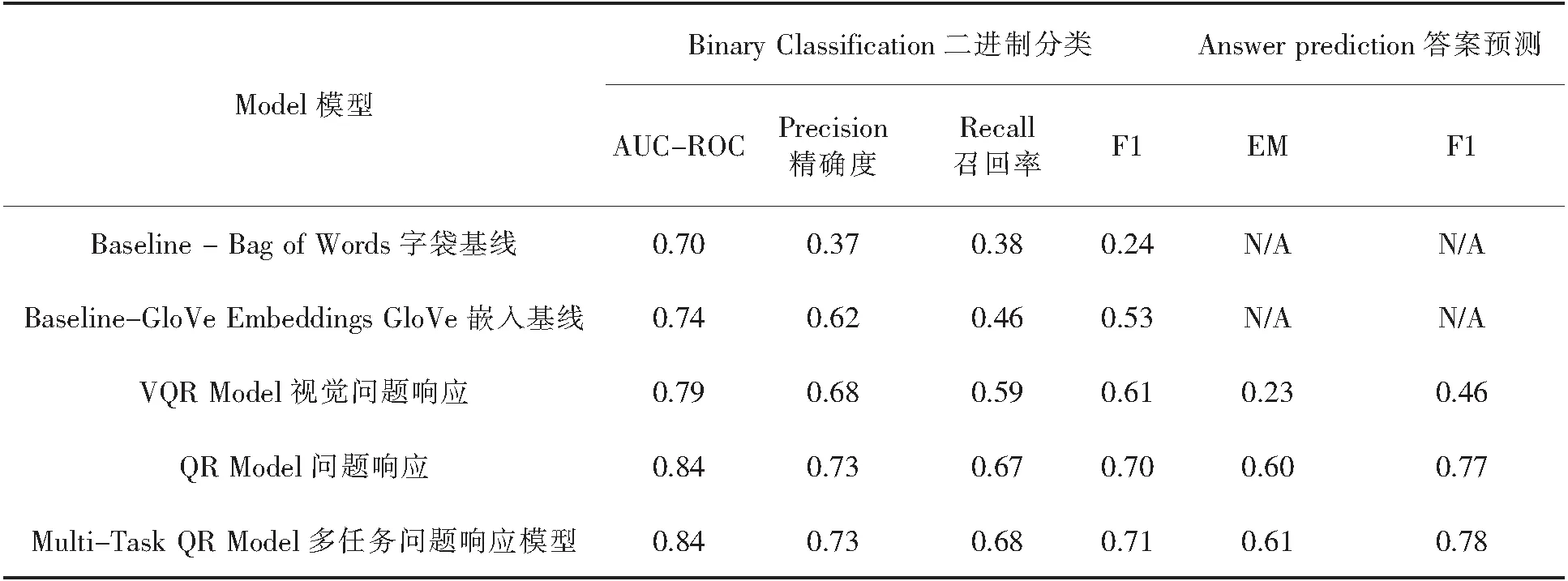
该模型在测试集上实现了AUC-ROC值为0.75(精度=0.37,查全率=0.38).使用预先训练过的GloVe词嵌入的基线在测试集上得到的AUC-ROC值为0.74(精确度=0.62,查全率=0.46).然而,这个基线模型在训练集上只实现了0.774的AUC-ROC.这表明该模型不足以对所有复杂的数据进行建模.此外,这两个基线的训练时间比VQR和QR模型要长得多.
4 总结
本文描述了两种众包数据标签的质量评估和从非结构化响应文本中提取正确答案的深度学习方法.这个项目第一次用这两种方法设计来识别混淆的模型标识.结果表明,本文的研究在解决VQR任务方面对Pythia进行自定义时有效,并且能够设计有效识别反应中混乱的模型(AUC-ROC=0.79),并提取答案(F1=0.46).
