新时代背景下我国劳动争议的影响因素研究*
2020-07-06王志坚
王志坚
(广东财经大学 大数据与教育统计应用实验室∥统计与数学学院,广东 广州 510320)
习近平同志在党的十九大报告中明确指出:加强和创新社会治理,构建和谐劳动关系。随着我国社会经济发展进入新时代,劳动关系也在发生深刻变化,劳动者的利益诉求越来越多元化,劳动争议事件居高不下,这对我国构建和谐劳动关系提出了新的挑战。以劳动争议案件受理数及劳动者当事人数为例,从2001—2017年,我国当期劳动争议案件受理数从154 621件增加到785 323件,16年间增长了5倍多;而涉及劳动者当事人数从467 150人增加到979 016人,16年间增长了2倍多。因此,对劳动争议影响因素的研究,探讨这些因素对劳动争议产生影响的机理,对我国在新时代精准构建和谐劳动关系具有重要意义。
1 文献综述
1.1 国外相关研宄
国外关于劳动争议影响因素的研究主要有:Michele Campolieti(2005)[1]基于1984—1992年加拿大安大略省劳动争议面板数据研究发现,之前发生过集体劳动争议的比从未发生过的工会在未来发生集体劳动争议的概率更高。Youngjin(2008)[2]认为制度化的劳资关系和有作为的工会组织能有效阻止劳动争议的产生。Sadat和Rilstone(2010)[3]基于1981—2002年加拿大人力资源和社会发展部(HRSDC)公布的集体争议数据,运用 Logit 模型进行双因素回归发现,员工主动终止集体劳动争议的原因同员工的性别、年龄以及文化水平等相关。Fraisse等(2015)[4]研究发现争议时诉讼成本和解雇成本将会对劳动争议案件的数量产生影响。
1.2 国内相关研宄
我国关于劳动争议影响因素的研究以前多通过理论分析等定性分析的方式进行探讨。但近年来,也有大量学者选择采用实证分析的研究方法来探索劳动争议的影响因素。主要有:王阳(2013)[5]研究认为经济结构调整、规模扩张对劳动争议案件有正向作用。郭金兴(2014)[6]认为经济发展水平对劳动争议有重要影响。范骏和王一楠(2015)[7]指出经济发展水平提高,会导致劳动争议案件增加,但经济增长速度没有显著的影响。陈冲和何梦醒(2016)[8]指出经济转型升级有助于减少劳动争议的发生。薛文娇(2017)[9]实证分析指出劳动力受教育水平对劳动争议有正向作用。刘影影(2018)[10]用30个省份2003—2015年的面板数据进行实证检验,并结合案例分析研究劳动争议的现状及影响因素。王志坚和谌新民(2019)[11-12]选取广东省佛山市顺德区国家级和谐劳动关系综合试验区162家企业为样本,以劳动合同、薪酬福利与社会保障、劳动安全卫生保护、员工发展与民主管理、劳动争议及调处等作为劳动关系评价的5个维度,从企业、高管及员工层面基于logistic回归模型研究和谐劳动关系影响因素。
学者们基于不同视角对和谐劳动关系进行了富有成效的研究,并且找到了诸多和谐劳动关系的影响因素,提出了许多很好的改善劳动关系的建议。但还存在以下几点不足:(1)方法上多是基于定性分析,量化研究较少;(2)在数据运用上,不管是基于调研数据还是国家统计数据多是没有分地区进行深入讨论;(3)找到了较多对和谐劳动关系有影响的因素,但没有从劳动争议案件总数、产均劳动争议案件数及劳均劳动争议案件数三个角度来研究具有共性的影响因素。鉴于此,本文在前人研究成果基础上基于我国社会经济发展处于新时代背景下,运用科学的研究方法,根据全国省、自治区、直辖市(不含港澳台)的劳动关系数据,基于定性与定量分析方法对我国和谐劳动关系影响因素进行研究。
2 我国劳动争议影响因素的计量分析
2.1 指标说明及数据来源
本文选取新时代背景下与劳动争议有关的7个指标作为被解释变量与解释变量,部分指标的选取参考了王阳(2013)[5]与刘影影(2018)[10]的研究。为了对选取的被解释变量及解释变量相关概念有较好的理解,下面对其涉及的相关指标进行说明。
(1)劳动争议案件数。当期劳动争议案件受理数直接反映了双方的利益冲突;与其他指标相比,更具有综合性。因此,在建立计量模型时,将劳动争议案件总数作为被解释变量。由于我国31个省、自治区、直辖市就业人口数以及经济总量差异较大,导致劳动争议案件数也存在较大差异,故仅比较劳动争议案件数意义不大,在此借鉴布朗(2009)[13]的研究,我们比较产均劳动争议案件数与劳均劳动争议案件数,并将其作为本研究的另外两个被解释变量。产均劳动争议案件数指用劳动争议案件总数除于该省、自治区、直辖市的生产总值,而劳均劳动争议案件数则指用劳动争议案件总数除于该省、自治区、直辖市的第二与第三产业就业人数。本文将劳动争议案件总数作为被解释变量仅作为一个参考。
(2)经济发展水平。经济发展水平对劳动争议具有重要影响。为了全方位衡量经济发展对劳动争议的影响,以各省GDP规模、人均GDP以及GDP增长率等三项指标来度量各省经济发展水平。
(3)工会化程度。工会的主要职责就是为劳动者争取各方面福利,并且在劳动者被企业侵权时代表工人的利益与企业进行谈判,工会的存在对劳动争议的发生与否具有重要作用。在此,以工会组织数作为衡量工会化程度的指标。
(4)劳动者的受教育状况。借鉴郭金兴(2008)的研究,劳动者的受教育水平用15岁及15岁以上人口中非文盲占比来表示。
(5)市场化和城镇化。新时代经济结构及体制转型对劳动关系状况的影响,我们用就业的市场化程度和城镇化水平来体现。
(6)抚养比。抚养比是指劳动者需要赡养老人数和孩子数量占家庭总成员数的比例。显然抚养比越高,劳动者的生活压力越大,从而会提高劳动供给,进而对劳动关系产生影响。
(7)城镇登记失业率。失业率高表明供过于求,会使得劳动争议案件发生频率提高,劳均劳动争议案件数增加,反之亦然。
据以上7个指标,我们细化出12个变量,其中3个被解释变量,分别是:劳动争议案件总数(件)、劳均劳动争议案件数(件/万人)以及产均劳动争议案件数(件/亿元)。9个解释变量,分别是:年度名义GDP(亿元)、抚养比(%)、文盲比(%)、GDP增长率(%)、人均GDP(元)、失业率(%)、工会组织数(个)、市场化(%)以及城镇化(%)。
需要说明的是表1中的各变量数据均来自于《中国统计年鉴》(2003—2018)或《中国劳动统计年鉴》(2003—2018)。由于在年鉴中获取的数据具有一年的滞后性,因此,实际得到各变量的数据为2002—2017年度数据。全文用R语言进行统计分析。
2.2 劳动争议影响因素的多元线性回归分析
以劳动争议案件总数、劳均劳动争议案件数与产均劳动争议案件数作为被解释变量,以年度GDP、抚养比、文盲比、GDP增长率、人均GDP、失业率、工会组织数、市场化和城镇化作为劳动争议的解释变量,采用多元线性回归模型对劳动争议的影响因素进行研究。为了对变量间的相关性有个直观了解,我们先作出3个被解释变量及9个解释变量的相关性图,如图1所示。
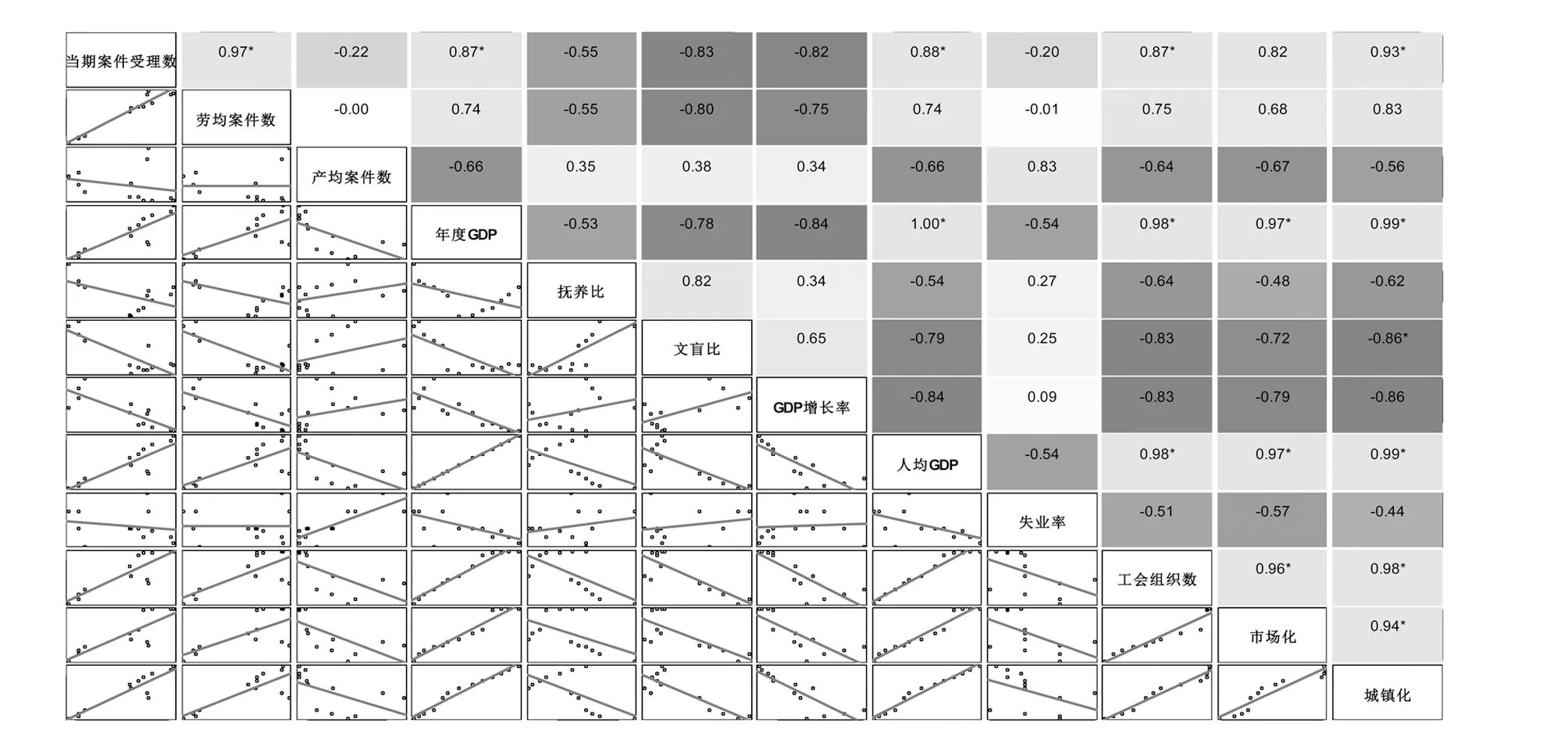
图1 劳动争议各变量的相关性图
图1的右上角是各变量相关系数,左下角是相关散点图,可以看出各变量之间具有较强的相关性。接下来建立多元线性回归模型,由于被解释变量有劳动争议案件总数、劳均劳动争议案件和产均劳动争议案件,因此,我们建立三个多元线性回归模型,各模型的解释变量相同,建模的数据均采用各变量的均值。需要说明的是,虽然前面已经指出以总的劳动争议数作为劳动争议的度量指标意义不大,这里只作为一个参考与劳均劳动争议案件和产均劳动争议案件进行对比。三类模型的多元线性回归结果如表1所示。
从表1可以看出,三类模型中均有部分变量不显著,并且三类模型的调整R方都很高,在0.97以上,说明模型拟合得很好,并且几乎不存在被遗漏的解释变量。鉴于三个模型中均有部分变量不显著,下面采用逐步回归法分别对三类模型进行变量选择,以期筛选出对被解释变量影响显著的解释变量,逐步回归结果如表2所示。
从表2可以看出,对于劳动争议案件总数模型来说,影响显著的变量有:抚养比、文盲比、GDP增长率、人均GDP 、工会组织数和城镇化。对于劳均劳动争议案件数模型来说,影响显著的变量有:抚养比、文盲比、GDP增长率、 工会组织数和城镇化。对于产均劳动争议案件数模型来说,影响显著的变量有:年度名义GDP、抚养比、文盲比、GDP增长率、人均GDP、工会组织数和城镇化。从表2还可以看出,各模型中的解释变量对被解释变量的影响方向是一致的,即相同的解释变量正负号相同。另外,可以从以上三个模型中提炼出对三个被解释变量均有显著影响的共性影响因素分别为:抚养比、文盲比、GDP增长率 、工会组织数和城镇化。
2.3 劳动争议影响因素的聚类分析
聚类分析法是研究“物以类聚”的一种现代统计分析方法,聚类分析法有两种类型:一种叫R型聚类,即对变量进行聚类;另一种Q型聚类,即对样品进行聚类。对变量进行聚类需要求出变量的相关系数矩阵,而对样品聚类需要求出样品间的距离矩阵。为了全方位分析劳动争议的影响因素,本文分别采用R型聚类与Q型聚类方法进行研究。由于所选的各变量单位及数量级不一样,简单将原始数据放在一起没有可比性,因此,我们先将每个省、自治区、直辖市2002—2017年的各变量数据求出平均数,再对其进行标准化。为了更清楚的看出各变量均值的变异差别,将标准化的变量作箱式图,如图2所示。
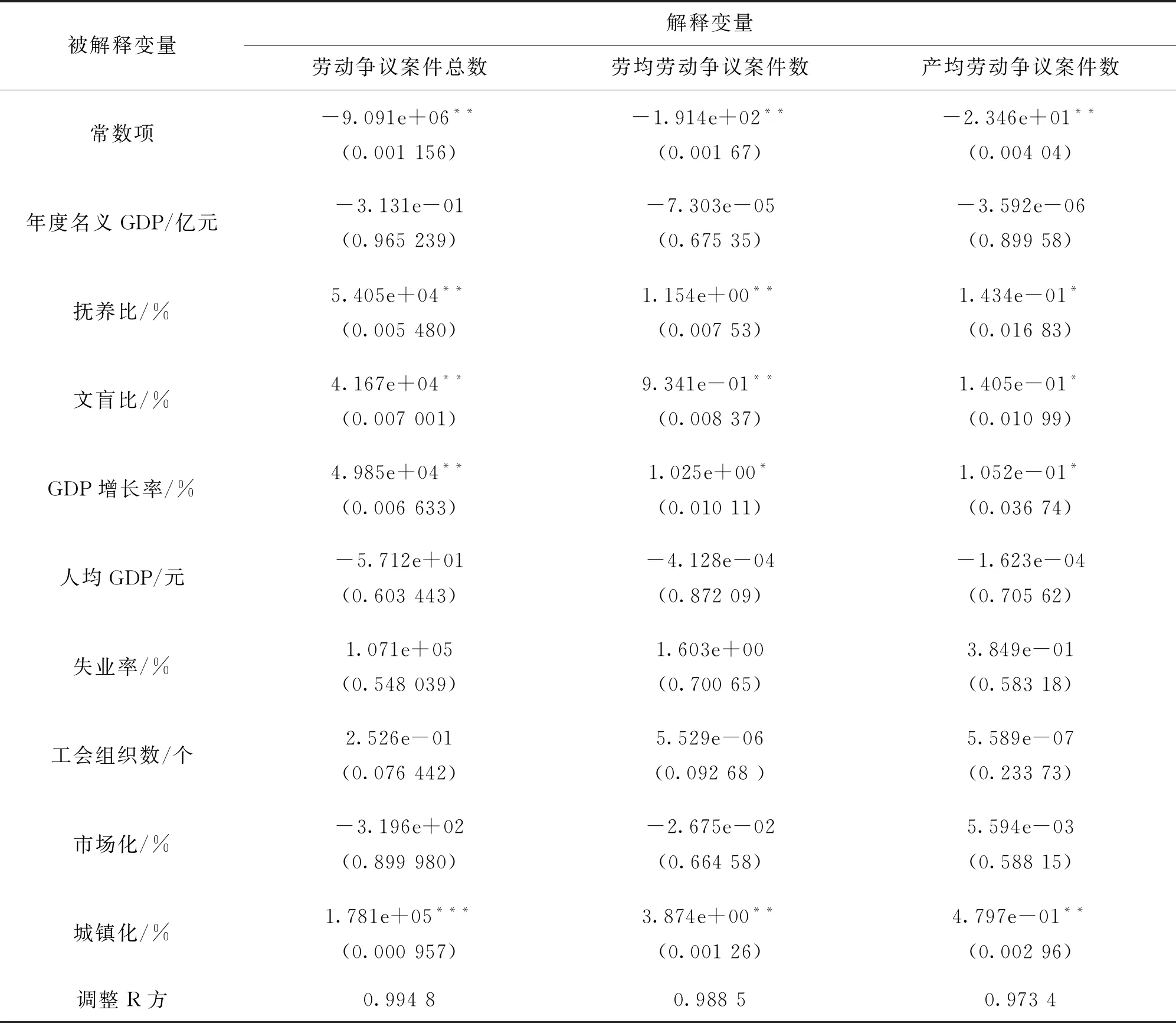
表1 三类模型的多元线性回归结果表
注:1.***表示在 0.001上显著;**表示在 0.01上显著;*表示在 0.05上显著;2. 括号()中的数字表示估计值的标准差。
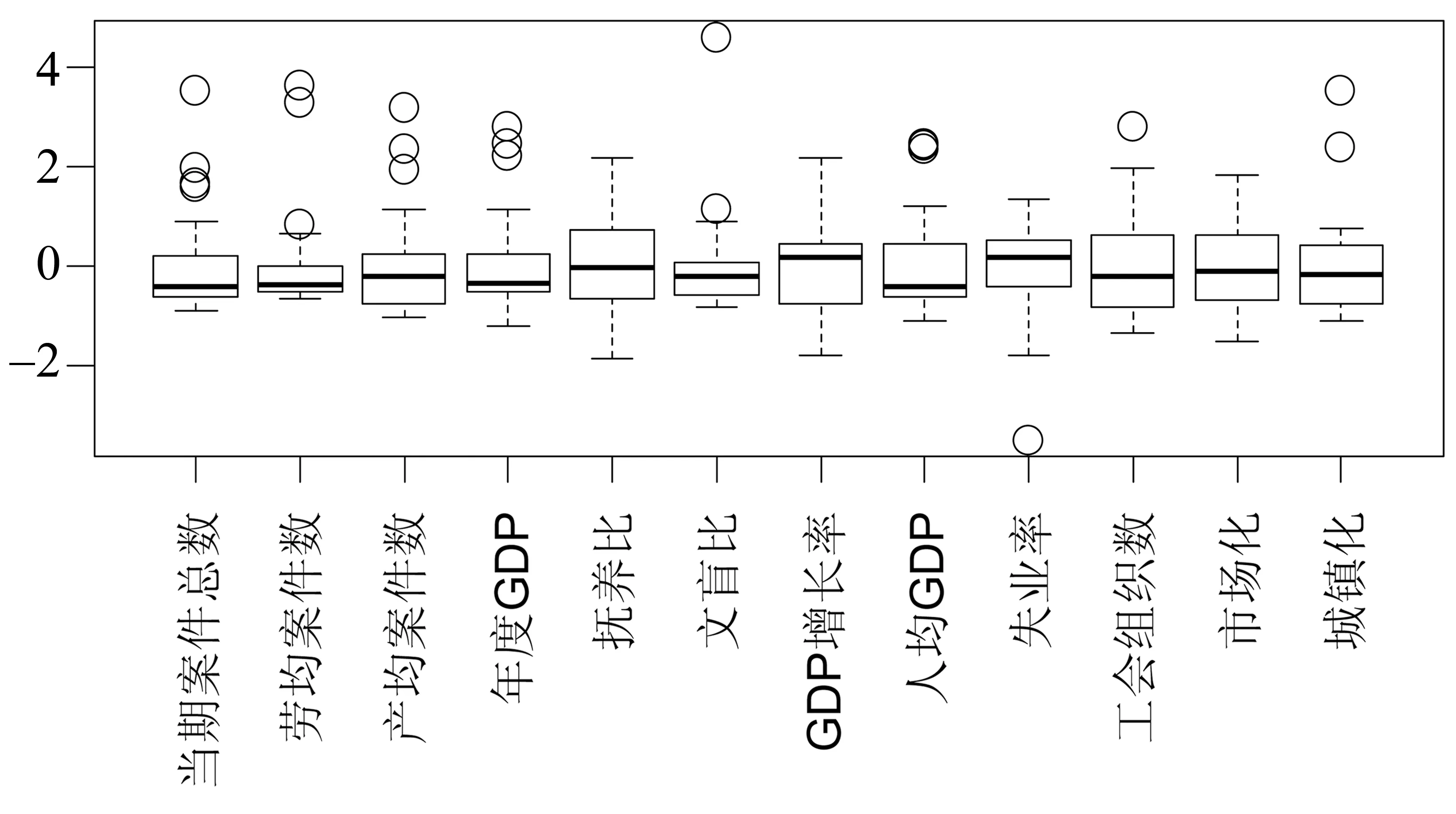
图2 各变量标准化后的箱式图
从图2可以看出,各变量标准化后还是存在较大差异性,并且大部分变量都有离群值。这显然是由于省际差异性导致。先对解释变量进行聚类分析,聚类分析结果如图3所示。
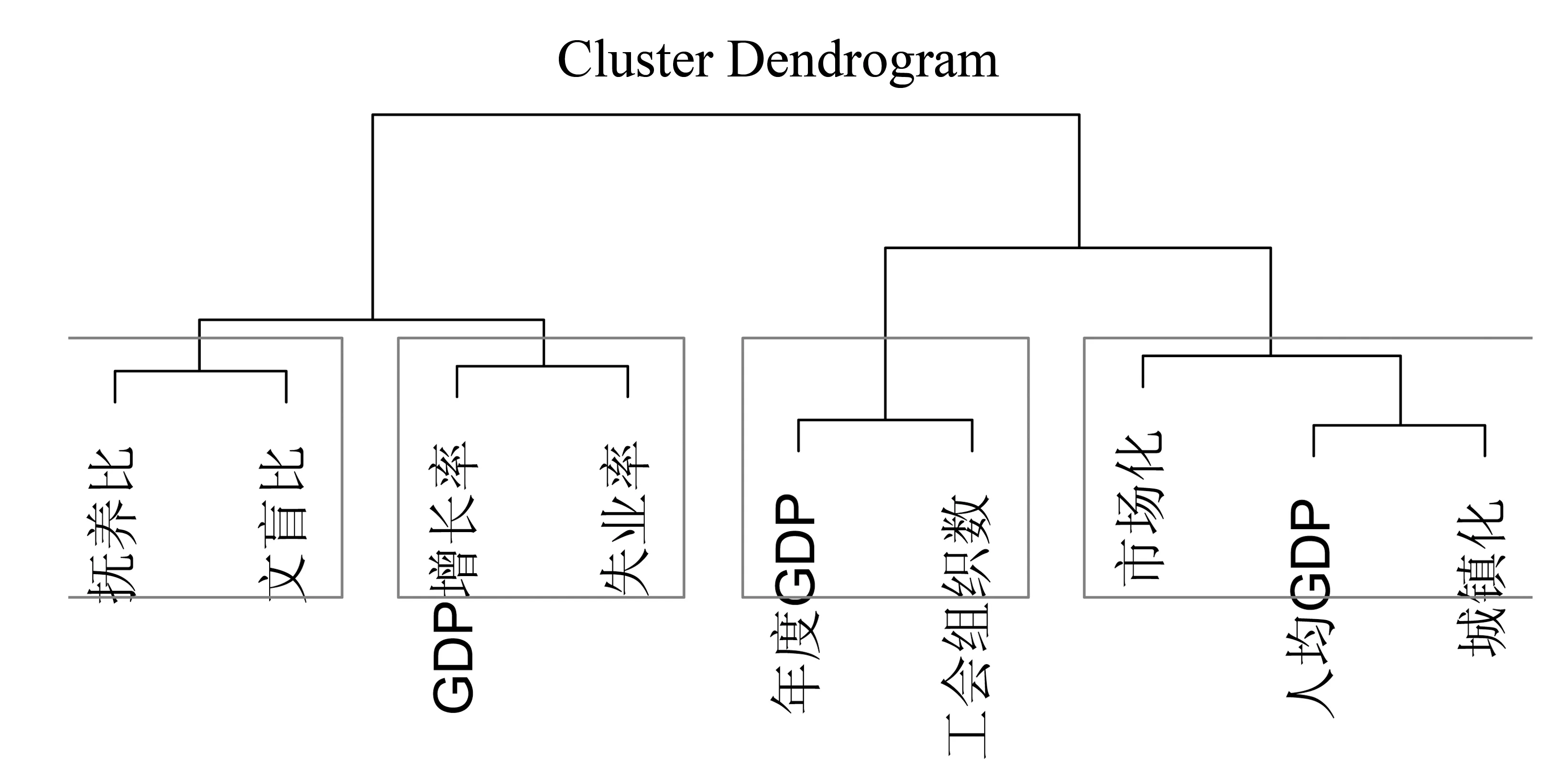
图3 各解释变量系统聚类图
从图3可以看出,若分成4类,抚养比与文盲比成一类,GDP增长率与失业率成一类,年度GDP与工会组织数成一类,市场化、人均GDP与城镇化成一类。显然聚在同一类的变量具有较高的相关性。
下面对样品进行聚类,即对各省、自治区、直辖市进行聚类分析。分别将劳动争议案件总数、劳均劳动争议案件数、产均劳动争议案件数以及各解释变量为统计量,对各省、自治区、直辖市做聚类分析,目的是在劳动争议不同评价标准下,将劳动争议具有相似性的省、自治区、直辖市分类到一起。聚类分析结果如表3所示。

表2 三类模型的逐步回归结果表
注:1.***表示在 0.001上显著;**表示在 0.01上显著;*表示在 0.05上显著;2. 括号()中的数字表示估计值的标准差;3.“—”表示影响不显著
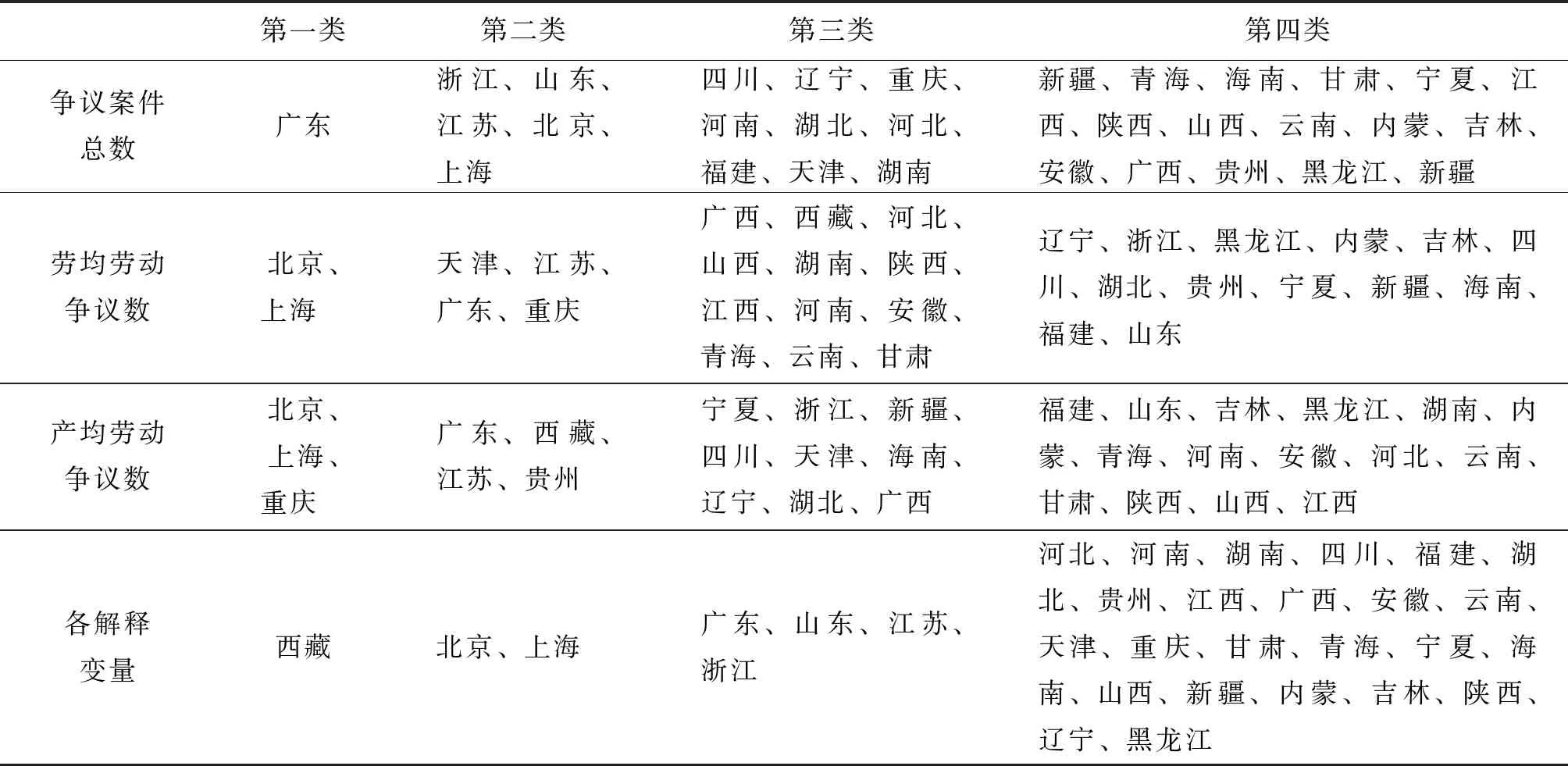
表3 劳动争议各省(直辖市、自治区)分类表
由表3可以看出,从劳动争议案件总数分类结果来看,广东作为全国第一大经济总量省份,劳动争议案件数自然也排在全国前列,第二类的也是经济较为发达的省市,如北京、上海等。由此可见,劳动争议案件总数与经济发达水平具有正相关性,经济发展水平越高,劳动争议案件总数越多。从劳均劳动争议案件数分类结果来看,可以看出劳均劳动争议案件数与劳动争议案件总数分类结果差异较大。从产均劳动争议案件数来看,产均劳动争议案件数与劳均劳动争议案件数、劳动争议案件总数分类结果存在较大差异性。从各解释变量来看,西藏较为特殊,单独成一类。总体来说,从聚类分类结果看,对于劳动争议案件总数、劳均劳动争议案件数、产均劳动争议案件数以及各解释变量的分类结果存在较大省际差异,这显然主要是由于各省的经济发展水平及劳动人口规模差异所导致。
3 结论与启示
第一,多元线性回归分析发现:对劳动争议案件总数、劳均劳动争议案件数及产均劳动争议案件数均有显著影响的因素分别为:抚养比、文盲比例、工会组织数、GDP增长率与城镇化。而且该5个影响因素对劳动争议均有正向影响。背后的原因可能是:对抚养比来说,若抚养比越高,家庭主要劳动力的生活压力越大,这迫使他们将更多的时间投入到工作中去,投入工作的时间越长,则发生劳动关系事件的可能性就越大。文盲比例越高,劳动者中懂法的比例就越小,因此在工作中则更倾向于发生劳动纠纷。而对于工会组织数来说,工会组织数越多,劳动者更倾向于向工会争取自己的权益,从而更容易发生劳动关系事件。GDP增长率与城镇化程度越高则越容易发生劳动争议。因此,我们建议从政府层面制订相关政策减少抚养比和文盲比来改善劳动关系,例如可以对二胎家庭进行适当补贴及加大教育投入力度等。充分发挥工会在劳动关系过程中的协调作用,倾听劳动者诉求,做到“大事化小,小事化了”,从而将可能的劳动争议消灭在萌芽状态。而对于GDP增长率与城镇化程度,这两者都代表着经济发达程度,因此,在经济发展过程中,可以考虑在法律的框架下,协调好经济发展与劳动争议的关系,既要发展经济又要保障劳动者的合法权益,从而尽可能降低劳动争议事件发生的可能性。
第二,聚类分析研究发现:在对变量聚类分析时,若将变量分成4类且每类只保留一个变量,发现分类结果与对三个被解释变量均有共同显著影响因素基本一致。而对样品聚类时,劳动争议的评价标准不一样,则分类结果不一样,并且存在较大的差异性,即:劳动争议案件总数、劳均劳动争议案件数、产均劳动争议案件数以及各解释变量的分类结果存在较大省际差异,这显然是由于经济发展水平及人口规模差异所致。因此,在和谐劳动关系构建中要重视各省、自治区、直辖市的地区差异性,各省、自治区、直辖市可以根据本地经济总量及人口规模,结合地区特点因地制宜、有针对性的制订改善劳动关系的相关政策。特别应重视劳均案件数与产均案件数的省、自治区、直辖市的分类结果。另外,归在同一类的省份在改善劳动关系的政策制订中可以相互借鉴、相互学习彼此好的方法。
