重叠加权法在医学研究混杂因素控制中的应用*
2020-06-28海军军医大学卫生勤务学系军队卫生统计学教研室200433秦宇辰阮一鸣
海军军医大学卫生勤务学系军队卫生统计学教研室(200433) 秦宇辰 郭 威 阮一鸣 吴 骋 贺 佳
【提 要】 目的 介绍重叠加权方法的基本原理、方法特性、相对优劣势及具体实现方法并将其应用于真实世界中比较两种冠脉支架植入对患者住院时间的影响。方法 以逆概率加权方法为参照,介绍重叠加权方法的原理、实现方法、目标人群,对比分析两者异同点及相对优劣势,评估其应用价值。结果 相较于逆概率加权,重叠加权具有诸如简便易行、不易产生极端权重、最小渐进方差、协变量精确均衡、高检验效能、目标人群明确有意义且更易准确估计处理效应等优点,其方法优势在实例应用中充分展现。结论 重叠加权具有良好方法学特性及广阔应用前景,可帮助观察性研究更好实现其处理效应发现职能并为实证研究提供可靠线索,值得在医学研究中广泛应用。
倾向性评分法越来越多地被应用于医疗卫生领域,用于控制观察性数据中的已知混杂因素,实现类似于“随机化”的效果[1]。而倾向性评分法中的加权方法也因原理易懂、结果易读、运算迅速等优点被广泛应用到实践中。但传统的加权方法,例如目前常用的逆概率加权方法,易出现极端值,且难以有效处理。Li[2]等人新近提出的重叠加权法(overlap weighting)可以很好克服传统加权方法的缺点且拥有若干明显方法学优势,具有广阔的应用前景。本文旨在介绍重叠加权的方法原理,对比分析其优劣势,并在真实世界研究中验证其方法特性、介绍其实现方法,以期能为该方法在医疗卫生领域中的推广应用提供参考。
方法原理
Rosenbaum 和 Rubin 于1983年首次提出倾向性评分(propensity score,PS)的概念[3],其基本原理是将受试者的多个协变量特征综合表达为一个倾向评分值来表示,分值实际意义为受试者接受处理或者暴露的概率,相似的受试者应具有相似的倾向性分值。而倾向性评分法即是使用倾向评分值进行不同对比组间的分层、匹配或加权等操作以期能实现各协变量在区间均匀分布,由此实现处理效应准确估计[4]。倾向性评分加权方法实质即为基于倾向性评分计算不同类型的均衡权重(balancing weights),并基于该权重加权构建一个新的虚拟人群,该人群中各类混杂因素独立于处理组分配,从而实现类似随机化的效果,保证处理因素效应的准确估计。目前常用的逆概率加权方法(inverse probability weighting,IPW)与本文主要讨论的重叠加权最大区别在于使用了不同的均衡权重。逆概率加权基于逆概率权重,而重叠加权使用重叠权重(overlap weights)。为方便读者理解,我们以逆概率加权为参照,简要介绍重叠加权的原理、特点及优劣势。
1.逆概率加权的基本原理
逆概率加权的逆概率权重计算方法及效应估计函数,如下式所示:
(1)
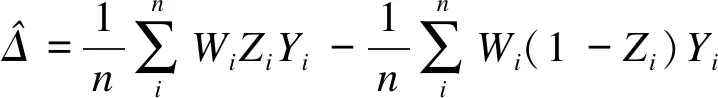
(2)

2.重叠加权的原理及方法特点
重叠加权和逆概率加权的效应估计函数一致(如式(2)),但权重计算方法不同。重叠权重的定义方式如式(3)所示:
Wi=Zi(1-psi)+(1-Zi)psi
(3)
由此可见,重叠权重实际为受试者进入其对立组的概率值,取值范围为(0,1),倾向性分值趋近于0.5的受试者将被赋予较高的权重而具有极端倾向性分值的受试者将被赋予较小的权重。不同于逆概率加权的目标人群是全人群(ATE)或者处理组人群(ATT),重叠加权的目标人群是重叠人群,目标效应是重叠人群平均效应(average treatment effect for the overlap population,ATO)。重叠人群是指全人群中对处理组及对照组没有明显偏向性(倾向性分值趋近于0.5),组间人群特征较相似的子人群。虽然与ATE及ATT的可明确识别的目标人群相比,ATO所指向的重叠人群在现实条件下不能明确界定,但该“模糊”人群仍有较大的现实意义:ATO所指的重叠人群受试者无明显入组倾向,组间受试者特征最相似(重叠度最高),因此其组间可比性最强、效应估计最可靠,类似于实现了完全随机化。在临床实践中,重叠人群指向的可能即是诊疗方案尚未达成共识的患病人群,临床医生尚不清楚哪种治疗方案会使此类人群更受益。因此,此类人群无明显的入组倾向,也应是研究比较的重点。
此外,相较于其他的加权分析方法,重叠加权有两点极具优势的特性。第一,可实现最小渐进方法。Li等人证明了当满足结局变量方差齐性条件时,重叠加权的渐进方差最小。当然在大多数实际应用情况下,即便结局变量方差齐性条件不满足(例如二分类结果)最小渐进方差属性不成立,重叠加权仍可实现较其他加权方法更小的方差;第二,可实现协变量精确均衡。当倾向评分估计模型为基于最大似然估计的logistic回归时,重叠加权可实现组间所有协变量项(包括主效应、交互项及高次项)精确均衡,其标准化差异趋近于0。因此,重叠加权可以始终实现较其他加权算法更好的协变量均衡性,这也确保了其能始终聚焦于最可比的人群(重叠人群)并实现最准确的效应估计。
3.重叠加权与逆概率加权的优劣势对比
逆概率加权最大的问题在于对极端权重很敏感,当组间受试者差异较大、特征重叠性较差时很难实现准确效应估计,此时,必须科学消除极端权重,目前常用的方法为极端权重截尾,例如丢弃权重超过阈值的受试者或用阈值替换极端权重,或只加权分析倾向性分值在经验最优区间[0.1,0.9]内的受试者(具有较好特征重叠性)[6-7]。但这些方法都存在阈值选择随意或者可能需要丢弃大量受试者的问题。同时,这些方法也会使估计效应量偏离原先设计的逆概率加权效应量,很难从个体层面定义该效应量所对应的人群。当然,也有研究指出在实际分析中偏离传统的效应量常见且合理[8],例如组间重叠性较差时使用传统效应量会产生大量偏倚,必须采用偏离传统效应量但能得到较准确效应估计的方法。重叠加权及其对应的ATO就是一个很好的备选。虽然在实际应用中无法从个体层面确定ATO所对应人群,但其所对应的重叠人群有着明确的性质特征,可映射到具有实践意义的现实人群。重叠权重有界,因此重叠加权不易受极端权重影响,即便组间受试者特征重叠性较差时其仍可较准确估计效应量,此外,其独具的最小渐进方差及精确均衡特性也保证了其能获得更准确、更精确的效应估计。虽然精确均衡特性也使传统的协变量均衡性检验方法(如标准化差异等)对重叠加权失效,但可首先使用传统协变量均衡性检验方法基于其他倾向评分分析方法确定最优倾向性评分估计模型再进行重叠加权的思路间接解决此问题。此外,Mao等人的研究发现重叠加权相较于逆概率加权有更高的统计检验效能[8]。由上述可知,相较于逆概率加权,重叠加权具有明显的方法学优势,也具有更为广阔的应用前景。
实例分析
1.实例背景
急性心肌梗死患者常需采用经皮冠状动脉介入术植入冠脉支架再通梗塞血管。传统的裸金属冠脉支架易发生支架内再狭窄,而药物涂层支架可以较好地解决这个问题[9],因此药物涂层支架被越来越多地应用于临床实践[10]。而不同的冠脉支架植入是否会影响患者的住院时间尚待探究。笔者拟以此问题为例,演示如何基于R软件的“survey”包实现重叠加权并进行结果解释。
2.资料概述及分析方法
实例来源于2014年美国住院数据中东北部医院的住院患者数据[11],共纳入8490条因急性心肌梗死入院并接受两种冠脉支架植入患者的住院记录。处理因素为接受裸金属支架或者接受药物涂层支架(Treat),结局为住院时间(LOS,天),纳入患者人口学信息、身体状况及并发症信息、医院特征信息等合计26个协变量。采用标准化差异(SMD)评价加权前后的协变量均衡性,分别使用两独立样本t检验、逆概率加权(IPW)及重叠加权(overlap weighing)估计处理因素效应,逆概率加权采用“survery”包默认输出的稳健标准误,重叠加权依据Li等人[2]的建议采用bootstrap法估计标准误。重叠加权的R软件实现方式请见附录。
3.结果解释
图1展示了加权前后的各协变量的标准化差异,由图可知,加权前接受金属冠脉支架和药物涂层冠脉支架的患者基线情况具有较大差异,各混杂因素在组间分布不均。逆概率加权后,所有协变量的标准化差异均远低于目前常用的推荐阈值0.1[12-13],提示加权后的协变量均衡性较好。由于倾向性评分由logistic回归基于最大似然估计得到,重叠加权如预期的一样实现了组间各协变量“精确均衡”,标准化差异趋近于0。
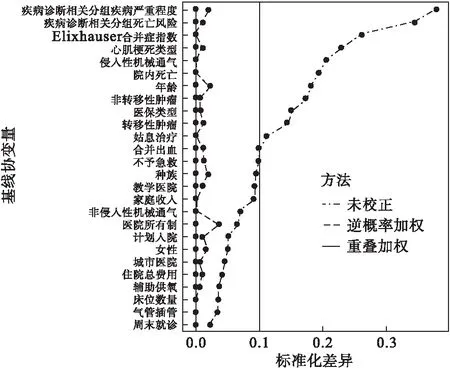
图1 加权前及加权后两组患者各基线协变量均衡性情况
如表1所示,三种方法均得出有统计学意义的效应值,即相较于接受药物涂层冠脉支架的心肌梗死患者,接受金属冠脉支架患者的住院时间更多。未控制混杂时,处理组比对照组平均多出0.90天的住院时间;采用逆概率加权控制混杂后两组住院时间差异缩小到0.50天;而采用重叠加权,该差值进一步缩小到0.38天。由于重叠加权所具有的最小渐进方差特点,其取得了较其他方法更小的标准误及95%置信区间,实现了更精确的效应值估计。综上可知,相较于接受裸金属冠脉支架的心肌梗死患者,接受药物涂层支架虽能获得有统计学意义的住院时间减少,但客观减少数较低,实际意义有限。此处需再次特别强调:逆概率加权和重叠加权估计的效应值分别指向两类不同的人群,前者估计的是ATE指向全人群,后者估计的是ATO指向重叠人群。此点应在分析结果的临床意义解释中予以关注。

表1 采用不同种类冠脉支架对住院时间的影响(接受药物涂层冠脉支架患者为对照组)
#两独立样本t检验;*bootstrap标准误
讨 论
倾向性评分方法近年来被越来越多地运用到观察性医疗卫生数据的分析中,倾向评分加权方法因其简便易行、计算负荷小、协变量均衡效果好等特点倍受青睐。但其中最常用的逆概率加权法所具有的易受极端权重影响、极端权重处理方法瑕疵较大等缺点也很大程度限制了此类方法的实际应用。而新近提出的重叠加权方法却能很好地克服这些缺点且拥有极具优势的方法学特性。该方法可直接推广到多分类处理组、生存分析、抽样调查等多种实际应用情境,可方便地与多种模型联合应用[2,8],因此具有极为广阔的应用前景。
需强调的是,重叠加权方法所对应的目标效应量是ATO,该效应量及其所对应的重叠人群也应获得更广泛应用及更多关注。重叠人群具有明确、实用、显著的临床及公共卫生意义,更重要的是其效应量ATO相较于传统的ATE、ATT、ATC效应量更易准确估计且具有更高的统计学效能,因此对通过观察性研究判定某处理因素对特定人群的效应是否为零并以此指导是否进行实证性试验研究更具意义。此外,需强调的是重叠加权和其他倾向性评分方法一样,需正确定义倾向性评分模型才可准确估计目标效应量ATO。当然由于其协变量“精确均衡”特点,传统基于协变量均衡性检验判定是否存在倾向性评分模型假定错误的方法不再适用,后续研究可聚焦于在重叠加权中判定倾向性评分模型是否存在假定错误的方法展开。
