Duration-HyTE:基于持续时间建模的时间感知知识表示学习方法
2020-06-23崔员宁
崔员宁 李 静 沈 力 申 扬 乔 林 薄 珏
1(南京航空航天大学计算机科学与技术学院 南京 211106)2(国网辽宁省电力有限公司 沈阳 110004)
知识图谱是将人类知识结构化存储的知识系统,其本质是具有有向图结构的知识库,是一种通用的语义知识的形式化描述框架[1].它用节点表示语义符号,用有向边表示符号之间的语义关系,以结构化三元组的形式存储现实世界中的实体以及实体之间的关系[2].知识图谱通常表示为G=(E,R,S),其中E={e1,e2,…,e|E|}表示实体集合,R={r1,r2,…,r|R|}表示关系集合,S=R×E×E表示知识图谱中三元组事实的集合,三元组以(head entity,relation,tail entity)的形式存储元事实数据.目前已有的大型知识图谱,比如Freebase[3],YAGO[4],WorldNet[5]等,不仅为研究工作者提供良好的数据资源,也为推动人工智能学科发展和支撑智能搜索、智能问答、个性化推荐等智能信息服务应用提供重要基础.
知识表示学习问题是贯穿知识图谱的构建与应用全过程的关键问题[6].而知识表示的方法,决定了它的表达能力和语义计算的复杂程度,良好的知识表示方法将给知识应用提供有力的支撑.传统的结构化三元组表示形式虽具有很强的表达能力,但是难以直接利用计算机做语义计算.而数值化表示方法将知识图谱中的离散符号(实体、属性、关系、值等)用连续型数值表示,直接体现语义信息,可以高效地计算实体、关系及其复杂的语义关联,极大地提高知识图谱语义计算的效率,已成为知识图谱研究的重要任务之一.

近几年,将时间信息用于知识表示学习,迅速成为知识表示学习领域研究热点.Jiang等人[16]在2016年首次将时间信息用于知识图谱表示学习中,提出基于翻译模型的时间感知表示学习方法t-TransE,取得了较好的效果.Dasgupta等人[17]在2018年借鉴TransH的方法,将时间看作产生1对多关系的主要因素,提出基于超平面的时间感知表示学习方法HyTE.HyTE方法的核心思想是将实体和关系通过时间信息映射到时间超平面上,计算评价函数,创造性地将时间信息直接嵌入到超平面空间中.实验结果显示,与TransE,TransH,t-TransE,HolE等知识表示方法相比,HyTE对实体和关系链接预测的准确度有了显著提升,引起了广泛关注.
同类知识的有效持续时间长度往往是相近的,但是由于HyTE方法将知识的有效持续时间切割为一个个独立的时间片,导致时间片之间是割裂的,因此HyTE方法训练得到的模型不能有效学习到时间长度的知识.针对这个问题,本文受持续时间模型(duration models)启发,对知识图谱中同类型元事实的有效持续时间进行建模,量化计算知识在不同时间片上的有效可信度,将其作用于评价函数和损失函数计算,提出融合超平面和持续时间建模的时间感知知识表示学习方法Duration-HyTE.
本文的贡献主要有3个方面:
1) 将元事实中的关系分为持续型关系和瞬时型关系,并对知识有效持续时间进行建模,研究知识有效持续时间的分布规律,提出了知识有效可信度.
2) 基于持续时间建模和有效可信度,提出融合超平面和持续时间建模的时间感知知识表示学习方法Duration-HyTE.
3) 在含有时间标签的知识图谱通用数据集Wikidata12K,YAGO11K上设计链接预测对比实验,结果表明Duration-HyTE方法实体链接、关系链接与时间预测的准确度较同类知识表示学习方法有了显著提升.
1 相关工作
TransE将知识图谱的实体和关系集合中的每个实体和关系用1个低维向量表示,将三元组集合中的三元组作为训练样本.三元组(h,r,t)中的h,r,t分别表示头实体、关系和尾实体.TransE将关系向量er看作从头实体到尾实体的翻译向量,对于2个实体向量eh,et,用eh+er与et的差值为翻译效果打分.它的评价函数表示为
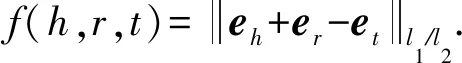
(1)
TransE方法采用负采样方法加速训练.用D+表示正确三元组的集合,负采样得到的错误样本集合表示为D-.负采样方法为
D-={(h′,r,t)|h′∈E,(h′,r,t)∉D+}
∪{(h,r,t′)|t′∈E,(h,r,t′)∉D+}.
(2)
TransH针对TransE方法对于1对多和多对1的关系预测效果较差的问题,将知识图谱中的关系都用超平面表示,超平面的单位法向量记作ωr.在计算评价函数之前,先将头尾实体分别映射到关系超平面上.其中TransH方法评价函数表示为
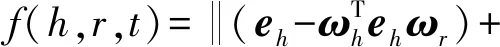
(3)
其中dr表示这对实体间的对应关系.对于同一种关系,可以有多个dr,所以TransH能够比TransE更好地表示1对多和多对1的关系.
HyTE方法是在TransE的基础上,受TransH的启发而设计的时间感知知识表示学习方法.在一些大型知识图谱中,元事实含有时间标记,这些元事实可以被结构化地表示为四元组(h,r,t,[τstart,τend]),[τstart,τend]表示这个元事实有效的时间,τstart,τend分别表示知识有效时间的开始时间点和结束时间点.Dasgupta等人[17]认为时间是产生1对多和多对1关系的主要原因,因此他们提出了HyTE,将每个时间片都用1个超平面表示,超平面的单位法向量记作ωr.在计算评价函数之前,先将头尾实体和关系向量映射到时间超平面上,再计算评价函数.HyTE的评价函数为
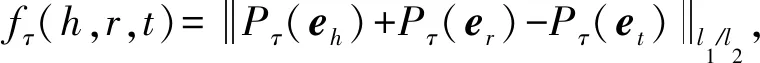
(4)

HyTE最主要的贡献是将三元组有效时间拆分为时间片,将时间超平面的法向量作为训练参数,和实体与关系向量一起训练.其优势是将有效时间信息巧妙地包含到了模型中,所以它对于时间感知的知识图谱的预测效果与TransE和TransH相比有显著提升.但也正是由于HyTE方法将有效时间拆分为独立的时间片,因此模型在训练过程中不能学习到有效持续时间长度的分布知识.本文针对HyTE方法的这个问题,对知识有效持续时间建模,改进训练过程并提出融合超平面与持续时间建模的时间感知知识表示学习方法Duration-HyTE.
2 本文方法
本文针对HyTE方法在训练过程中模型不能学习到有效持续时间长度的分布知识的问题,对知识有效持续时间建模,计算知识有效可信度,应用到评价函数和损失函数,提出融合超平面与持续时间建模的时间感知知识表示学习方法Duration-HyTE.
模型训练算法的流程是:1)持续时间建模,对包含各类关系的元事实数据进行有效持续时间建模,获得该类元事实有效可信度的模型;2)将四元组中的时间拆分成时间片,并按照时间点计算有效可信度,插入四元组生成五元组(头实体,关系,尾实体,时间片,有效可信度);3)初始化训练参数,按照预设维度随机地初始化实体、关系和时间片的向量集;4)从五元组集合中随机抽取1个小型训练集,并由五元组生成负样本;5)将正负样本映射到各自的时间片后计算评价函数,根据损失函数调整模型训练参数;6)输出训练得到的模型,重复4)5)继续训练,训练次数达到预设的次数时停止.Duration-HyTE方法的框架如图1所示:

Fig.1 Framework of the proposed method图1 所提方法的结构图

Fig.2 Distribution of the persistent relation图2 持续型关系持续时间分布图
2.1 基于持续时长的关系分类
持续时间建模指对某类事件的持续时间建立模型,以方便计算某事件在特定时间点上的危险系数、生存函数(可靠函数)等,对未来的同类事件的持续时间和持续时间上的可靠程度做出预测.
知识图谱中的每个包含时间标签的元事实四元组(h,r,t,[τstart,τend])记录对应元事实(h,r,t)在时间维度上从无效到有效再到无效的过程.其中有效的时间段[τstart,τend]称为有效持续时间,它本质上也是一种持续时间.包含某种关系rx的三元组(h,rx,t)组成的所有元事实三元组是同一类事件.按照事件的持续时间将关系分为持续型关系和瞬时型关系2种类型:
1) 持续型关系.持续型关系是指在某一时间段内持续有效的关系,这类关系的特点是持续时间不为0.例如从YAGO11K数据集中抽取的2个持续型关系hasWonPrize和graduatedFrom的持续时间数据,它们的持续时长不为0且满足某种分布规律,其分布统计如图2所示,其中横坐标为持续年数,纵坐标表示持续该年数的四元组元事实总数.
2) 瞬时型关系.瞬时型关系是指发生在某一时刻,并且不会持续的关系.例如从YAGO11K数据集中抽取的WasBornIn和DeadIn这2个瞬时型关系的持续时间数据,它们的持续时长为0,其持续时间分布统计如图3所示,其中横坐标为持续年数,纵坐标表示持续该年数的四元组元事实总数.

Fig.3 Distribution of the transient relation图3 瞬时型关系持续时间分布图
2.2 融合持续时间建模的改进学习算法
受持续时间建模的启发,对知识图谱三元组的有效持续时间进行建模,计算某类事件在特定有效时间点的有效可信度.
持续时间建模的主要对象是含有持续型关系的数据.文献[18]中介绍了持续时间模型,并定义了生存函数(survival function),也称可靠性函数(reliability function),它表示自事件发生开始,经过某长度时间后该事件仍在持续的概率.若T是连续型随机变量,且服从累积分布函数F,那么在t∈[0,+∞)上,可靠函数的公式表示为

(5)
式(5)目前多用于交通事故、设备故障等事件的时长估计和风险评估,可靠函数表示从事件发生开始后时刻t事件仍在持续发生的可靠程度.知识的有效持续时间也是一种特殊的持续时间,与文献[18]中应用场景不同的是,知识图谱中包含多种类型的事件,每种事件的类型由三元组中的关系决定.对每个事件的持续时间分别建模,便可以推导每种关系事件的可靠函数,所以知识有效的可靠程度也可以用持续时间建模来计算.为方便大型知识图谱中大量元事实的持续时间建模,本文采用能够快速有效模拟大多数有效持续时长分布的高斯函数对持续型关系的持续时间建模.所以不同关系概率密度函数f可以表示为
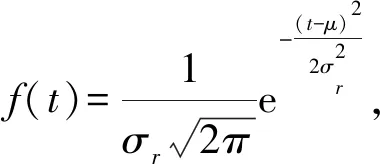
(6)
其中,σr指包含关系r的所有元事实持续时长的标准差.与传统持续时间建模不同,本文有效持续时间建模的目的是计算每个四元组的有效持续时间上,某个特定时间点上知识有效的可靠程度.定义在某个四元组的有效时间段内某个时间点的有效可靠程度为有效可信度.
定义1.知识图谱中包含有效时间区间的四元组(h,r,t,[τstart,τend]),自开始时间τstart经过时间t后,知识仍然有效的概率称为有效可信度,记作cvalid.
四元组(h,r,t,[τstart,τend])持续时间为τpresent时,累积分布函数F表示为

(7)
其中,σr指包含关系r的元事实持续时长的标准差,τend指事件的有效时间的结束时间点,τpresent为当前时间点.式(6)模拟了2.1节中持续型关系事件的概率分布情况,式(7)表示这种持续型关系事件的可靠函数.根据式(5)(7),可以推导出包含持续型关系的元事实四元组(h,r,t,[τstart,…,τend])持续时间为时刻τpresent的有效可信度:
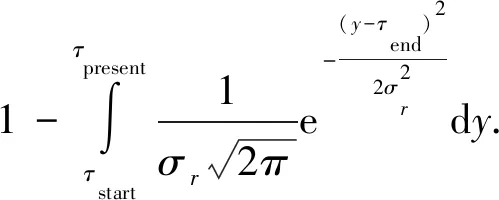
(8)
与持续型关系不同,瞬时型关系的持续时间为0,因此包含瞬时型关系的元事实四元组的有效可信度在有效的时间点上为1,其余无效的时间点上为0.
另外,由于负样本在知识图谱中是不正确的知识,所以无论何时,它不正确的有效性都是成立的.因此负样本作为不正确知识的有效可信度在任何时间点上都为1.
综合上述对正负样本有效可信度取值问题的讨论,正负样本的有效可信度计算为

(9)
其中,Rpersistent为持续型关系集合.根据式(9),可以发现正样本有效可信度的取值在[0,1]上,而负样本的有效可信度为1,即无论在哪个时间点上,正样本的有效可信度都比负样本的小,若直接将这样的有效可信度用于训练,会降低正样本在训练中的作用,因此实际训练的过程中,在正样本的有效可信度基础上增加了平衡因子q(q作为超参数),目的是给予有效时间内正样本的有效可信度一定的纠正,以保持正负样本在训练中的平衡.
通过上述方式,对知识有效时间段进行了持续时间建模,使知识有效性的可信程度能够用有效可信度量化计算,为将有效可靠度用于指导知识的嵌入表示提供了基础.
HyTE模型中将元事实的有效可信度看作二值分布,他们认为在有效持续时间上,元事实的有效可信度都为1,其他时间上有效可信度都为0.而我们认为在表示学习过程中,应该给有效可信度更高的训练样本以更高的权重.基于这种思想,将有效可信度作用于评价函数,得到改进的知识表示学习算法Duration-HyTE.二者的异同如表1所示:

Table 1 Comparison Between HyTE and Duration-HyTE表1 HyTE与Duration-HyTE对比表
从表1中可以得到信息:1)Duration-HyTE与HyTE最主要的不同是持续时间上的有效可信度,Duration-HyTE使有效可信度的变化曲线更加平滑;2)Duration-HyTE将有效可信度作用于评价函数,使可靠性高的样本在训练中的权重更大;3)Duration-HyTE与HyTE方法相比,没有增加更多的训练参数,而训练参数越少,计算效率就越高,所以Duration-HyTE保持了HyTE方法的高计算效率.
2.3 改进模型的损失函数
Duration-HyTE方法是一种时间感知的知识表示学习方法,在计算评价函数时,先将其映射到时间平面上.将时间用超平面表示,对于T个时间片,用T个不同的时间超平面的法向量来表示.Duration-HyTE的评价函数为
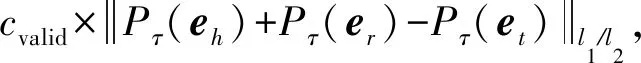
(10)
其中,Pτ(e)表示将头实体、尾实体或者关系向量投影到时间点τ的时间超平面上得到的向量.
Duration-HyTE方法的损失函数为
(11)
其中,D+表示每个时间点τ上的有效三元组集合,在有效三元经组基础上采集负样本,得到负样本集合D-.本文针对链接预测任务采用不考虑时间的负采样方法(time agnostic negative sampling, TANS):
D-={(h′,r,t,τ)|h′∈E,(h′,r,t)∉D+}∪
{(h,r,t′,τ) |t′∈E,(h,r,t′)∉D+}.
(12)
式(12)中只是将头和尾实体做替换得到负样本,是一种不考虑时间维度的负采样方法.
针对时间预测任务采用依赖时间的负采样方法(time dependent negative sampling, TDNS):
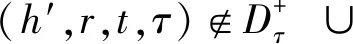
(13)
式(13)从时间维度上替换头和尾实体,以在其他时间片有效但在原时间片上无效的元事实作为负样本.
式(12)是一种忽略时间维度的负采样方法,这种方法采集得到的负样本更侧重于实体和关系向量参数的训练,有助于区分相近的实体,是一种适用于实体和关系预测任务的负采样方法;而式(13)是一种依赖时间的负采样方法,这种方法采集得到的负样本更侧重于时间超平面参数的训练,有助于区分相近的时间超平面,是一种适用于时间预测任务的负采样方法.所以在实验部分中,实体和关系预测任务采用的负采样方法是式(12),时间预测任务采用的负采样方法是式(13).
为了避免负样本数目过大,防止正负样本比例失衡,设置超参数neg_sample来限制负样本的数目,neg_sample表示每个正样本对应的负样本数目.在做负采样时,每个正样本对应的负样本个数都被限制在neg_sample内,从而限制了负样本的总数目.而且,为了提高算法执行效率,负采样在载入数据集时执行,即在训练开始之前做负采样并保存,在训练过程中随对应的正样本一起被抽样.这样就避免了多次训练中正样本的重复负采样,提高了算法执行效率.
融合超平面和持续时间建模的知识表示学习的模型训练算法如算法1所示:
算法1.Duration-HyTE模型训练算法.
输入:训练集S、实体集E、关系集R、时间集T、边界γ、调整因子q、维度数dim、迭代数N;
输出:实体向量集VE、关系向量集VR、时间法向量集VT.
①E中每个e随机初始化dim位向量,得到VE,R中每个r随机初始化dim位向量,得到VR,T中每个τ随机初始化dim位向量,得到VT;
② 正则化VR中每个向量;
③ 创建正样本集合Spos、负样本集合Sneg;
④ FOR EACH (h,r,t,[τstart,τend])∈S
⑤ FOR EACHτ∈[τstart,τend]
⑥ 计算时刻τ时(h,r,t)的cvalid;
⑦Spos插入正样本(h,r,t,τ,cvalid);
⑧ FOR迭代次数j=1,2,…,neg_sample
⑨ 负采样并插入负样本集Sneg;
⑩ END FOR
3 实验结果与分析
为了验证Duration-HyTE方法的有效性,分别在目前通用的含有时间标签的数据集Wikidata12K,YAGO11K上进行了实体链接预测实验、关系链接预测实验与时间预测实验,并与同类算法比较.
为了进一步验证Duration-HyTE在持续型关系型数据集上的预测效果,在新建的2个持续型关系数据集WDP12K,YGP10K上做了进一步的实体和关系链接预测实验.
3.1 数据集
Wikidata[19]和YAGO是2个大型的知识图谱,也是知识表示学习领域通用的数据集.YAGO11K,Wikidata12K是从这2个数据集中抽取了包含时间标记信息的元事实组成的时间感知的频繁关系知识图谱数据集.YAGO11K数据集是从YAGO数据集包含时间标记的事实中抽取得到的,其中含有时间标签的元事实以(#factID,occurSince,ts),(#factID,occurUntil,te)的形式保存.其中包含20 500个三元组、10 623个实体和10个频繁关系.与YAGO11K类似,Wikidata12K是从Wikidata数据集中抽取得到的,其中包含24个频繁关系、40 621个三元组和12 554个实体.
为了进一步证明本文提出模型训练算法在持续型关系数据集上的有效性,我们对Wikidata12K,YAGO10K数据中包含持续型关系的数据进行进一步抽取,从YAGO数据集的四元组数据中抽取了四元组中包含持续型关系的15 525条元事实数据,然后将元事实中包含的10 143个实体和8个关系抽取出来,形成新的持续型关系数据集YGP10K.对Wikidata数据集采样同样的抽取方法,抽取得到WDP12K,其中共有20种关系、11 943个实体和34 496条元事实数据.实验所用数据集如表2所示:

Table 2 Test Datasets表2 实验数据集
3.2 实验设定
1 )评价指标.为了准确地评估我们的模型方法,我们采用了知识图谱表示学习链接预测通用的评价指标[20].对于每一个需要测试的三元组,分别将头和尾实体去掉,然后用数据集中的所有实体来代替,映射到时间超平面后用评价函数打分,将所有的实体评价结果进行排序.同样地,将三元组中的关系向量删除,然后用数据集中所有的关系来代替,并用评价函数来打分.评价指标主要有3个:
① 平均排名(mean rank, MR).统计正确实体或关系在所有实体或关系中的平均排名作为实体或关系链接预测评价指标.
② Hits@10.统计正确实体在所有实体中排名前10的数据所占百分比作为实体链接预测的评价指标.
③ Hits@1.统计正确关系在所有关系中排名第1的数据所占的百分比作为关系链接预测评价指标.
2) 基线设置.第1个基准方法是TransE,这是基于翻译模型中第1个被提出的方法,它不考虑时间标记信息,将三元组集作为训练集,每个实体和每个关系都会输出1个向量.HolE是一种知识表示学习的方法,它的预测效果是目前的知识表示学习方法中比较突出的,它也是一种不考虑时间标记的方法.TransH是在TransE基础上改进的一种知识表示学习方法,它首次将超平面应用到知识表示学习中,HyTE方法的灵感也来自于此.t-TransE也是一种基于翻译的模型,它首次将时间信息应用于知识表示学习.HyTE是在TransE和TransH的基础上改进的时间感知的知识表示学习方法.最后,Duration-HyTE是本文提出的方法.
3) 参数设定.对于所有的方法,在2个数据集上都保持b=50 000,嵌入维度dim∈{64,128,256},边界γ∈{1,2,5,10},学习率l∈{0.01,0.001,0.000 1},调整q∈{0.5,0.6,0.7},负采样数neg_sample∈{1,2,5}.实验中超参数设定为:dim=128,γ=10,l=0.000 1,评价函数使用l1-norm范式,q=0.6或q=0.7(Wikidata12K数据集为0.6,YAGO11K数据集为0.7),neg_sample=5.
3.3 实体链接预测实验
为了验证模型对于实体链接预测的效果,在Wikidata12K,YAGO11K数据集上,分别作了头实体和尾实体的链接预测实验,测试的方法是用每种方法训练得到的模型对测试集中的三元组做头尾实体预测,测试结果的评价指标是正确头尾实体的MR和Hits@10.Duration-HyTE与其他方法的实验性能对比,结果如表3所示:
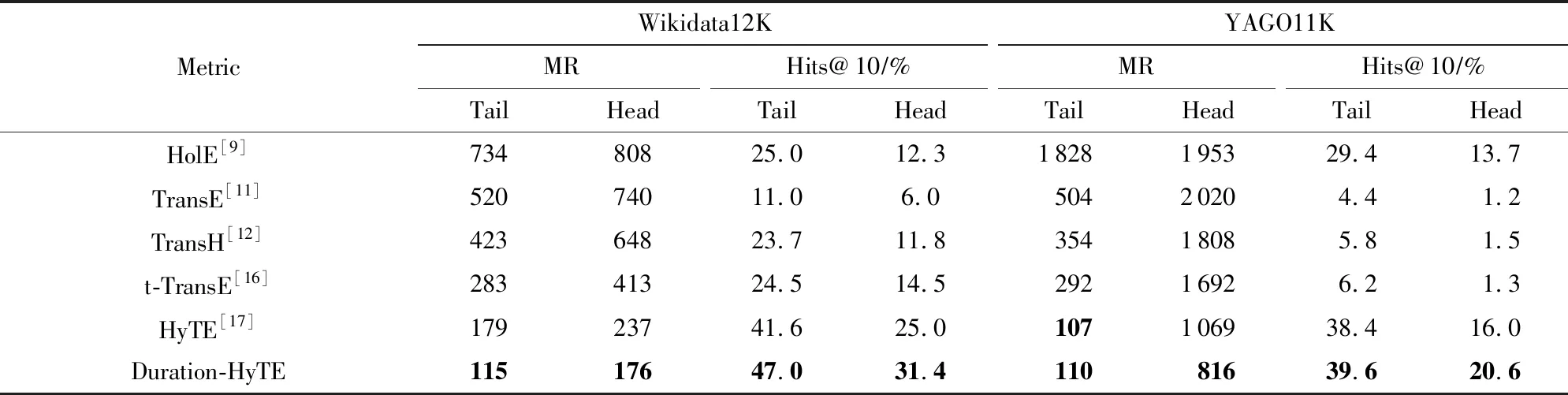
Table 3 Results of Entity Prediction表3 实体预测结果表
Note: The best values are in bold.
如表3所示,在2个数据集上,Duration-HyTE的实验性能都优于基准方法,其中YAGO11K上的头实体预测效果提升了23.7%,尾实体的链接预测基本持平,Wikidata12K上的头尾实体链接效果分别提升了25.7%和35.8%.说明Duration-HyTE时间感知知识表示学习算法对于包含时间标签的知识图谱数据集的学习比其他方法更有效.
为了进一步分析本文的方法对HyTE的改进效果,我们给出了HyTE和Duration-HyTE在Wikidata12K上前500个epoch上得到的模型的实体链接预测结果.图4直观地展示了2种方法随着循环的进行,尾实体预测效果的变化情况.

Fig.4 Comparison chart of prediction mean rank of tail entities图4 尾实体预测平均排名的变化曲线图
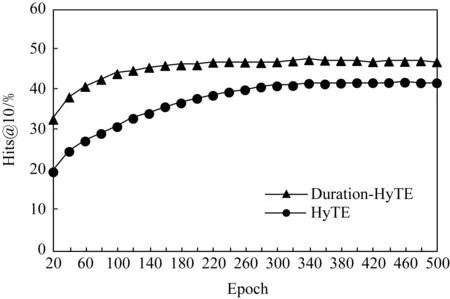
Fig.5 Comparison chart of prediction Hits@10 of tail entities图5 尾实体预测Hits@10变化曲线图
从图4可以发现,HyTE和Duration-HyTE尾实体预测的变化曲线相似,HyTE在第320个epoch时得到最佳表示模型,Duration-HyTE在第280个epoch时得到最佳表示模型,Duration-HyTE方法得到的模型预测结果一直优于HyTE方法得到的模型.
另一项评价指标尾实体预测结果的Hits@10的变化曲线如图5所示:
3.4 关系链接预测实验
在Wikidata12K,YAGO11K数据集上,对Duration-HyTE方法训练得到的模型进行关系的链接预测,测试方法是用每种方法训练得到的最佳模型对测试集中的三元组做关系链接预测,实验的评价指标是正确关系向量的平均排名(MR)和命中第1的百分比Hits@1.将实验结果与基准方法对比,实验结果如表4所示:

Table 4 Results of Relation Prediction表4 关系预测结果表
Note: The best values are in bold.

Fig.6 Comparison chart of prediction mean rank of relation图6 关系预测平均排名的变化曲线图
表4的结果对比显示,在Wikidata12K,YAGO11K数据集上,Duration-HyTE算法的关系预测都比基准方法更加准确,关系的预测效果分别提升了2.7%和7.3%.
图6绘制了HyTE和本文方法训练得到的模型对于关系预测的结果随epoch变化的曲线.尽管HyTE方法对于关系的预测排名已经接近1,优化的空间很小,但是Duration-HyTE方法对于关系的预测效果仍略优于HyTE.
关系链接预测的另一项评价指标Hits@1的对比结果如图7所示,与尾实体的预测的Hits@10变化曲线相似,Duration-HyTE方法训练得到模型的预测结果优于HyTE方法.
为了更清晰地展示2个模型关系预测测试结果的不同,我们从关系的预测结果中提取了实验结果中的一些典型例子来对比HyTE和Duration-HyTE对不同关系的预测,如表5所示.
表5中列1是删除关系后的四元组,列2,3分别是HyTE和Duration-HyTE对缺失关系的预测排名的前2名,其中加粗的关系为正确的预测值.
Note: The right relations are in bold.
3.5 持续型关系数据链接预测实验
2.1节介绍了基于持续时长的关系分类,其中将关系按照持续时间分为持续型关系和瞬时型关系2类.而有效持续时间建模的对象主要是针对持续型关系,所以本节将在持续型关系型数据集上对Duration-HyTE方法做进一步的验证.3.1节中介绍了我们从Wikidata12K,YAGO11K中抽取了所有包含持续型关系的数据,新建了2个持续型关系数据集WDP12K,YGP10K.HyTE,Duration-HyTE训练算法在数据集WDP12K,YGP10K上进行对比实验,用知识表示学习得到的模型做链接预测,得到的实体链接预测结果如表6所示,关系链接预测结果如表7所示.

Table 6 Results of Entity Prediction in Persistent Relation Dataset表6 持续型关系数据集实体预测结果表
Note: The best values are in bold.

Table 7 Results of Relation Prediction in Persistent Relation Dataset表7 持续型关系数据集关系预测结果表
Note: The best values are in bold.
Duration-HyTE方法得到的模型在持续型关系数据集上取得了比HyTE更好的结果,在2个数据集上的尾实体预测分别提升了13.1%和13.4%,头实体链接预测性能分别提升了13.4%和8.9%,关系链接预测性能分别提升了1.7%和8.8%.这进一步验证了我们的模型训练算法在持续型关系数据集上的有效性.
3.6 时间预测实验
目前,知识图谱中的时间标注不够完整,缺失情况严重,因此知识有效时间预测是一项重要任务.时间预测任务就是给定测试的对象(h,r,t,τx),在所有时间超平面上投影三元组的关系和实体,计算评价函数,并以此计算每个时间超平面的排名.如果被测对象是持续型关系三元组,那么考虑有效时间间隔中最低的正确时间超平面排名.在此任务的训练过程中我们采用了式(12)(13)这2种负采样方法,其他的训练过程与链接预测实验一致.对比实验结果如表8所示:
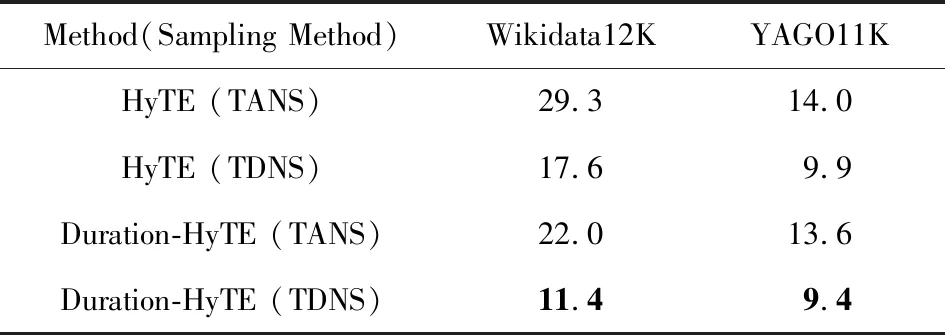
Table 8 Mean Rank of Time Prediction表8 时间预测平均排名结果表
Note: The best values are in bold.
表8展示了HyTE和Duration-HyTE在采用2种负采样方法时在时间预测任务上的对比实验结果.实验结果表明依赖时间的负采样方法(TDNS)更适合用在时间预测任务上,这是因为它更专注于使模型的时间超平面分离,从而提升了时间预测效果.
2种方法在Wikidata12K数据集上采用TDNS负采样方法的平均排名的变化曲线对比结果如图8所示:
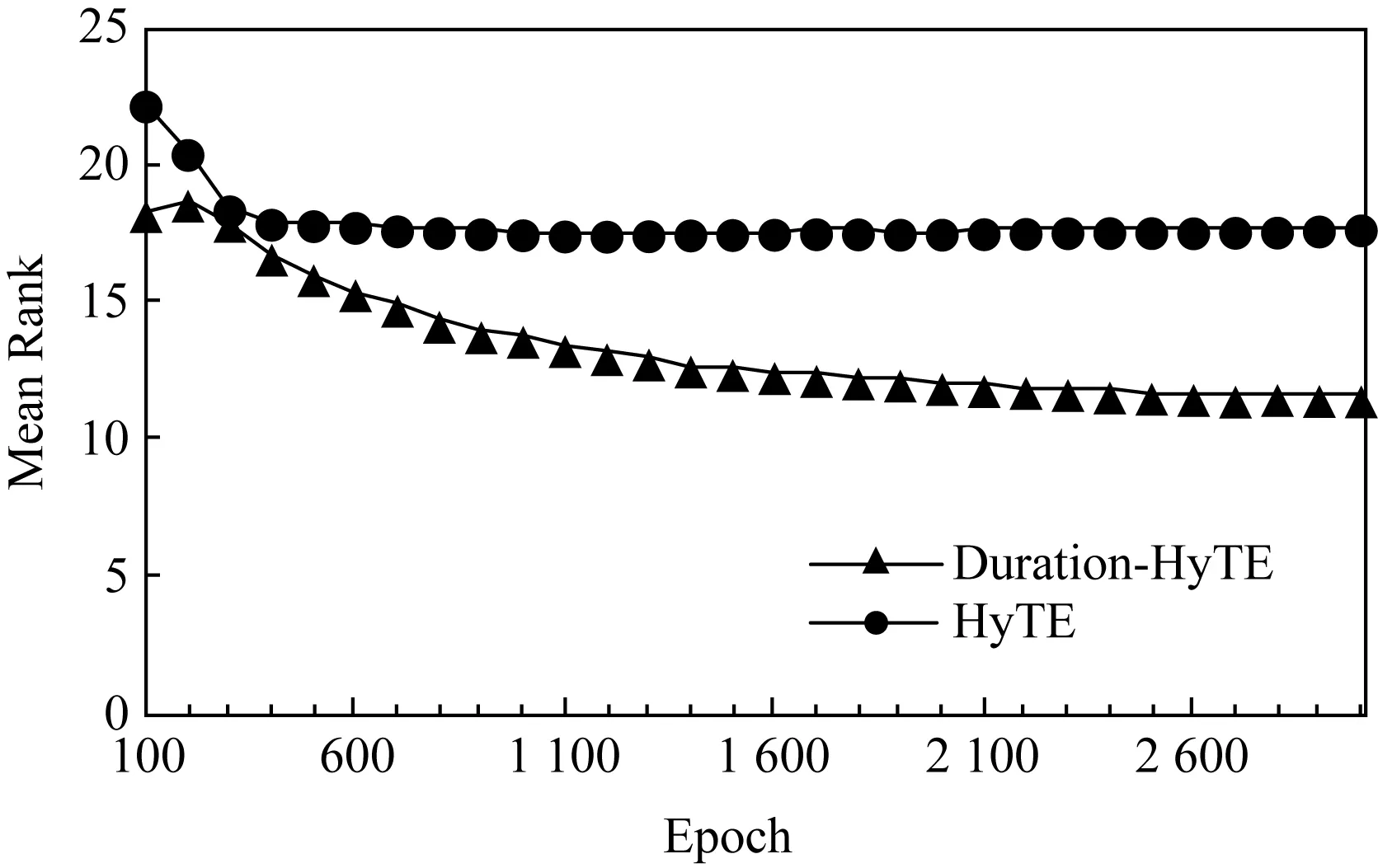
Fig.8 Comparison chart of prediction mean rank of time图8 时间预测平均排名的变化曲线图
4 总 结
本文受持续时间模型启发,针对知识有效持续时长的分布问题,对知识的有效持续时间进行建模,计算知识在不同时间片上的有效可信度,将其作用于训练过程评价函数和损失函数的计算,提出了融合超平面和持续时间建模的时间感知知识表示学习方法Duration-HyTE.并在2个通用数据集和新建的2个持续型关系数据集上设计了对比验证实验.实验结果表明Duration-HyTE算法训练得到的模型对于实体和关系的链接预测与时间预测效果都有显著提升,尤其是在Wikidata数据集上的头尾实体预测准确度分别提高了25.7%和35.8%.
含有时间标签的知识图谱有大量的缺失值,目前已有的方法大多将其默认为最大或最小值,这给模型正确地学习时间知识造成了阻碍.因此,我们将会继续研究含时间标签的大型知识图谱时间标签的预测和迭代补全问题,提高知识标签的数据质量,更好地训练模型,提高链接预测的准确度.目前流行的知识表示学习都采用随机的负采样方法,本文链接预测任务所采用的TANS方法也是一种随机的负采样方法,如何改进负采样方法,获得更高质量的负样本也是一个很好的研究点.另外,如何将Duration-HyTE等时间感知的知识表示学习方法应用于时间相关的关系抽取、知识融合和推理等,也是值得深入研究的方向.
