FPGA图计算的编程与开发环境:综述和探索
2020-06-23郭进阳邵传明朱浩瑾过敏意
郭进阳 邵传明 王 靖 李 超 朱浩瑾 过敏意
(上海交通大学电子信息与电气工程学院 上海 200240)
如今,工业界和学术界尝试设计专用加速器来提升图计算的性能与能效.有多种硬件架构在可选范围之列,比如图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)等.其中,FPGA有多方面优势.与通用架构相比,FPGA能够提供高度的编程灵活性和较高的性能,这为图计算加速器的设计提供了便利.同时,FPGA的开发模式是数据驱动的,少去了译码过程,使得基于FPGA的图计算加速器能够实现更高的能效.
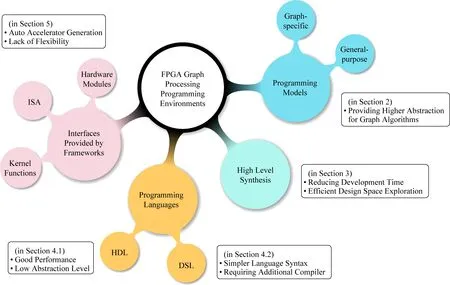
Fig.1 The organization of programming enviornment图1 编程与开发环境部分的组织结构
基于FPGA的图计算加速是国内外热门话题.中国计算机学会有关专委会于2014年在面向新型计算模型的系统软件方面展开了探索,其中对图计算的相关性质做出了详细描述[1];2017年,该学会有关研究人员在可重构加速器领域也做了进一步讨论,指出了FPGA存在的编程墙问题[2].从上述研究可以看到,利用FPGA进行图计算加速需要首先解决FPGA开发存在的固有编程挑战.目前国内外存在许多面向FPGA图计算的编程语言[3-12]、编程工具[13-19]与一些图计算框架[20-24].
编程与开发环境是一个开放的概念,本文中FPGA图计算编程与开发环境包括:1)编程模型;2)高层次综合工具;3)编程语言;4)便于加速器开发的应用程序接口,包含图计算应用开发过程中所涉及到的各个环节.传统FPGA开发方式依赖于硬件描述语言,缺乏软件开发的高层视角,导致开发过程十分耗时.学术界和工业界寄希望于高层次综合工具,以获取更高的开发效率,然而通用的高层次工具在图计算应用上面临性能不佳的问题.同时,一些加速器被设计出来,针对某些特定算法,缺乏灵活性,阻碍了其广泛应用.
近年来,虽然有一些关于FPGA编程与开发环境的相关探索,也有一些综述文章,但是这些综述通常只关注了FPGA图计算加速器设计过程中涉及到的某一部分.以2016年的一篇综述为例[25],虽然其涵盖了诸多HLS工具,但是并没有对常用的成熟工具作出重点介绍,也未谈及图计算的相关优化技术.许多综述对图计算中的可选方案和优化技术进行介绍,这其中包含对某一特定技术的介绍,如对图计算中内存系统的优化技术[26]、对顶点为中心的编程模型进行了介绍[27],以及关于图计算框架的涉及到的一系列技术的介绍[28].其他一些综述[29-30]关注点在于总结图计算中使用的技术和优化策略,而没有以这些框架蕴含的应用程序接口(为方便图计算加速器的开发而提供)作为主要的关注点.为此,本文将对基于FPGA图计算所涉及到的编程与开发环境进行介绍与探索.
简单来讲,编程模型提供高级抽象,使编程人员从底层细节解放.高层次综合通过高级程序语言的支持,能够允许用户快速探索设计空间,降低了所需的硬件知识门槛.精心设计的编程语言能更好地联系底层硬件模块.高度集成的用户接口能便利开发过程.
图1是第2~5节关于FPGA图计算编程与开发环境部分的组织结构.
1 背景介绍
本节分为2个部分:1)介绍图计算相关概念,并对FPGA上流行的图算法做简单分类;2)概述FPGA图专用加速器以及与通用架构的对比.表1对本文中用到的图计算概念和关键符号做简要总结.
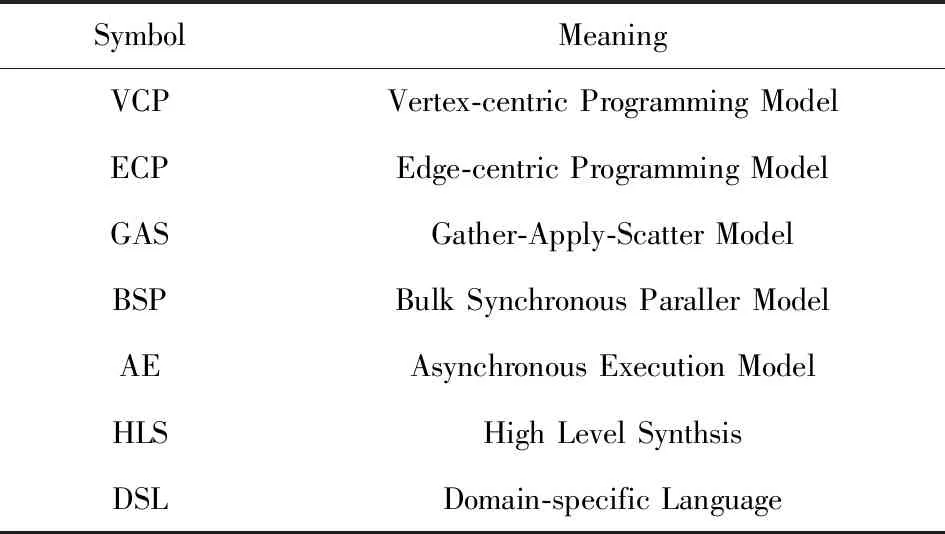
Table 1 The Key Symbols Used in This Article表1 本文中使用的重要符号
1.1 图计算的简介
图是一种由顶点以及连接它们的边所构成的特殊数据结构,可以表示为G=(V,E),顶点集合V={v1,v2,…,vn},边集合E={e1,e2,…,em},且EV×V.e(u→v)表示从顶点vi到vj的一条边,是有向或无向的.对e∈E,有vi和vj是邻居.子图定义:若图G存在一个子图G′,则有G′=(V′,E′),V′V且E′E.
图计算技术可以被应用于各领域,如社交网络、计算机网络、电子交易等.自然图具有稀疏性、幂律性以及小世界性的特征[26].图数据的稀疏性将会导致较差的局部性;幂律性将导致图计算面临严重的负载不均衡问题;小世界性为大图数据分割带来挑战.这些特性使得图计算技术不适宜使用现有的数据处理方法,而且在并行处理上也存在着效率低下的问题[31].
1.2 通用处理器上的图计算
1) 基于CPU的图计算.为了提升CPU上图计算的性能,大量关于构建高效系统的工作已经展开.这些工作整体上可以分成2个类别:分布式系统[32-33]和单机系统.分布式系统利用集群来支持大规模数据处理,但是面临通信开销、同步开销、一致性以及负载不均衡的困扰[34-35].新兴服务器往往配备了大内存,可以将大部分图数据存储其中,因此大量关于开发单机潜力的工作正在开展[36-38].
2) 基于GPU的图计算.由于GPU具有数据并行能力,因此很多相关工作采用GPU来追求图计算的高性能.许多基于GPU系统[39-41]都被设计用来进行高性能图计算.对BFS,CC,BC以及SSSP等常用算法性能优化的工作也被大量展开.图计算领域专用框架领域也被用于提高GPU应用的开发效率.为了支持大规模的图数据,CPU-GPU异构系统、多GPU系统和片外内存系统也被陆续提出.
1.3 FPGA的图计算加速器
由于图数据的特性,现有的图计算系统无法充分发挥通用处理器的硬件潜力[42-43].自然图通常为幂律分布(大多数顶点都只和少数几条边相关联),导致在通用处理器上内存访问开销大且效率低下[44-45],图计算中的数据不规则性决定了在利用传统处理器上的内存级及指令级并行方面存在着固有缺陷.现有的商用多核体系结构对于图计算而言,大量的内存带宽实际上没有得到充分利用[43,45].
现场可编程门阵列(FPGA)是可重配置的计算设备[46],其中包含大量可用于解决特定计算问题的可编程单元.这些处理单元包括用于实现组合逻辑的查找表(LUT)、用于实现寄存器的触发器(FF),以及可编程的互连大容量存储Block RAM(BRAM).将FPGA用于图计算加速有3个优点:
1) 编程灵活性.与ASIC在制造过程中仅“配置”一次不同,FPGA可以根据需要进行多次重新配置.这样可以调节和改进体系结构,应用错误修复或使用FPGA快速原型化硬件设计,然后可以将其设计为ASIC.FPGA还允许即时重新配置以解决不同的任务[47].
2) 高性能.经过精心设计的FPGA系统可以通过利用大规模并行(通常以深层流水线的形式)获得高于CPU的性能.同时,某些不属于CPU指令集的特定于应用程序的指令可以在FPGA上实现需要在单个周期完成计算,而在CPU上实现可能需要更长周期.
3) 高能效.CPU和GPU是指令驱动的,而FPGA设计通常是数据驱动的,这意味着FPGA可以直接处理数据而无需先解码指令.此外,FPGA也无需访问集中式寄存器文件或任何缓存层次结构.由于指令译码、寄存器和高速缓存查询占据了基于指令的体系结构所消耗功率的大部分[48],因此使用FPGA开发往往可以获得更高的性能功耗比.
1.4 FPGA上常用图算法
本节我们将对已在FPGA上实现的主要代表性图算法进行分类.表2是FPGA上常用的图算法及分类.FPGA上常用的算法主要包括:广度优先搜索(BFS)、连通分量(CC)、可达性证明算法、单源最短路径(SSSP)、全对最短路径(APSP)、PageRank(PR)、图形计数(GC)、三角形计数(TC)、中介中心度(BC)、最大匹配(MM)等算法.
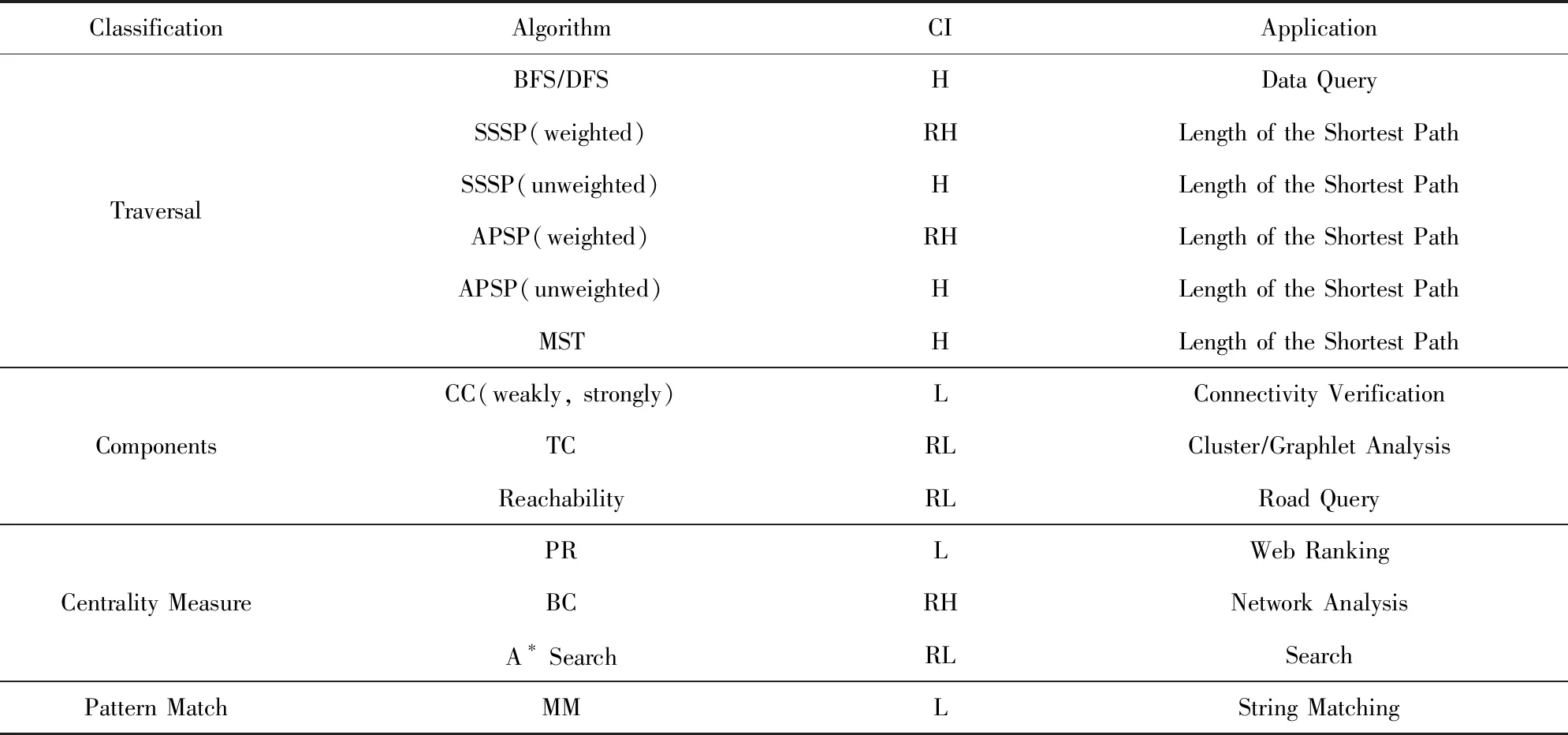
Table 2 Classification of Representative Graph Algorithms Being Deployed on FPGAs表2 FPGA上部署的常见图算法及其分类
Notes: CI represents computational intensity; H/L represents high/low; RH/RL represents relatively high/relatively low.
1.5 相关编程与开发环境
基于FPGA加速器的图计算应用开发面临着2方面的编程挑战:1)因为FPGA的传统开发方式效率低下;2)因为图算法多样,涉及的操作也十分繁多,编程人员难以设计完备的操作集成库以提高编程效率.因此需要很好地进行编程与开发环境设计以获取更高的开发效率.
关于探究FPGA图计算加速器高效编程与开发环境设计的工作早已开展,然而这些工作仅仅关注了编程与开发环境的某一方面.诸如FPGA图计算编程框架、并行高效的HLS工具设计等都是常见的改进FPGA图计算开发的途径.
2 编程模型
图计算涉及的算法多样,各种算法的设计思维迥异,对不同图算法可能要设计不同的数据分区以及通信机制.编程模型能够提供一种高级抽象,使编程人员从底层细节中解放出来,专注于算法逻辑,以提高编程效率,也是高效的图计算编程与开发环境中重要的一环,本节主要将就2类编程模型进行简介.
2.1 图计算专用编程模型
传统的图计算编程模型按照图元素中心可以划分为:以顶点为中心和以边为中心.前者能够提供高度并行性,在部分图算法上能有很好的性能,但是可能存在大量随机访问从而导致高昂访存开销.后者能够提供较好的空间局限性,但由于数据输入顺序受限,会导致额外的时间开销.在此基础上,GAS模型和混合中心模型被提出,用来优化某些图算法的性能.同时,最近的研究关注到一种新兴的子流模型,能够很好地适配FPGA的某些特性.表3对这些常见的图计算专用编程模型进行分类并总结了相关特性.

Table 3 Classification and Characteristics of Common Graphprocessing Programming Models表3 常用图计算编程模型分类及特性
2.1.1 以图元素为中心的编程模型
1) 以顶点为中心的模型.在以顶点为中心[49-51]的模型中,需要独立处理每个顶点的任务,通过对边和邻接点进行计算以及数据传输.每个顶点都可以被单独处理,因此可以通过调度来保证高并行度.但由于相邻点可能存储在存储器的不同位置,所以会导致大量的存储器随机访问,从而导致高昂的内存访问开销.
2) 以边为中心的模型.在以边为中心的模型[52-53]中,边数据以它们在图数据结构中所存储的顺序传输到处理器.此处,边由其成员点的标签以及对应的边权重构成.处理器顺序地处理边数据并在必要时更新关联边的数据.因此这种顺序访问的方式能够改善空间局部性.但是,由于该模型限制了加载顺序,部分算法存在性能低下的问题,例如BFS算法,使用边为中心模型的过程中会造成额外的时间开销[56].
3) 顶点为中心和边为中心相结合的模型.顶点为中心的编程模型适合处理活跃节点占比大的情形,而边为中心的编程模型适合处理活跃节点占比低的情形.可以将顶点为中心和边为中心的模型相结合以获取更大的优势[32].
2.1.2 其他类型的编程模型
1) 集聚散射(GAS)模型.GAS模型[54]与以顶点为中心的方法相似.它提供了关于图算法的以顶点为中心的视图.不同的的是它将每次迭代分为3个部分:聚集(gather)、应用(apply)和分散(scatter).在聚集阶段,顶点收集有关其相邻顶点或边的信息,并可选地将其减小为单个值σ.在应用阶段,将根据先前计算的σ以及顶点的邻居的属性来更新顶点的状态.最终,在分散阶段,每个顶点将其新状态传播到其邻居.然后,将在下一次迭代的收集阶段再次收集该值.
2) 以子流为中心的模型.在子流为中心模型[55]中,需要首先将数据流划分为子流,然后单独对每个子流进行处理,以提高并行度和降低通信开销.这种模型能够更好地适配FPGA特性,可以利用有限的存储器资源来达到高能效、高性能和高精度的要求.
2.2 通用编程模型
除去图计算专用编程框架,也有一些通用的分布式/并行计算框架,可以用于图计算,批量同步并行模型和异步执行模型是其中的典型代表.然而这些通用框架却存在一些问题,批量同步并行(BSP)模型需要特殊的硬件支持以实现全局障碍同步;异步执行(asynchronous execution)模型需要额外的设计,以实现复杂的同步机制.
1) 批量同步并行(BSP)模型.批量同步并行[57]模型中的每个迭代称为超步(super step).在每个超步之后,并行过程将使用障碍进行同步.每个迭代都分为3个阶段:在第1阶段,每个过程都会进行任何所需的本地计算;在下一阶段,进程将发送和接收消息;最后障碍同步保证了仅在当前超步中的所有本地计算完成,并且交换完该超步中的所有消息,才开始下一个超步.
2) 异步执行(asynchronous execution)模型.异步执行模型[58]不同于批量同步模型,它允许部分节点先一步开始下一步迭代,在PageRank这种应用下,能够允许部分节点更频繁地向其邻居节点传播信息,从而达到更快的首先速度.但是相应地,它需要复杂的同步机制来支持这种异步过程.
3 高层次综合
高层次综合(HLS)通常指的是将高层次语言描述的逻辑结构,自动转换成低抽象级语言描述的电路模型的过程.已有研究证明,HLS可以生成性能高效的代码[59].HLS工具能降低软件开发人员利用FPGA进行硬件加速的知识门槛.对于硬件开发人员,HLS工具能够提高相应系统的开发速度,并且允许用户更快地探索设计空间[60].
3.1 针对图计算的HLS优化
HLS工具虽然能够提高设计的抽象等级,但不能简单应用到图计算环境中来.由于自然图的特性[26],图计算面临着数据访问不规则、工作负载不均衡以及严重的数据依赖等挑战.若要利用HLS进行硬件设计,则需要针对这些问题进行大量的手工批注,以适配图计算这种特殊的计算任务.而通用HLS工具缺乏对不规则图算法的有效支撑,需要针对图算法固有数据不规则性问题进行针对性的优化.
3.1.1 HLS的并行优化
早期HLS工具[13-15]支持静态并发的设计,基于C语言的HLS工具通常分析循环并采用展开和流水线化等技术.Intel[13]和Xilinx[15]的HLS工具都致力于实现数据并行性.LegUp[14]通过支持OpenMP和pthread API以实现线程级并行性.IBM的Liquid Metal[16]支持流内核并行性,这些工具都采用静态并发模式,并行结构在硬件生成期间无法更改.
而TAPAS[17]构建于并行编译器的中间表示之上,关注程序中隐式表达的细粒度的并行.借助于动态并行模式,TAPAS使任务可以在运行时动态产生,并与其他任务同步.TAPAS的最大优势是能够解决使用静态并行模式下HLS工具难以实现的软件开发,例如嵌套并行、条件循环、流水线并行、递归并行.Spatial[18]工具也支持动态并行,支持循环嵌套,可以实现任意位置的粗粒度流水线.
康奈尔大学的研究工作提出了多线程流水线[61]和弹性工作流[62]的概念,用于解决静态流水线技术无法发现与利用潜在的数据局部性和并行性的问题,以提升动态并行能力.他们还提出了一种预测流水线HRU[63]以获得更好的并行设计.
3.1.2 HLS的访存优化
有文献提出了3种粒度的片上内存优化策略[64]:1)细粒度优化,通过声明局部数组并将其作用于较大位宽度的存储空间获得高数据传输带宽,是典型的利用LUT和BRAM资源消耗换取大带宽;2)粗粒度优化,主要是通过额外的局部缓冲区以增加带宽,但是需要在计算前后额外地进行数据复制;3)混合粒度则允许综合2种策略的优点.
一些新兴HLS工具针对动态内存管理进行了设计优化.例如,DMM-HLS[65]关注到FPGA上可能的资源匮乏问题,将动态内存管理的想法借鉴到HLS中.该工作研究了堆深度、堆字长以及分配对齐等约束条件,为解决内存碎片、内存一致性以及内存访问冲突等问题提供了可行方案,同时也为支持新兴的多加速系统提供了支持.另外,Spatial[18]则提出了一种基于机器学习的内存分配策略,允许自动进行内存划分.
3.1.3 HLS的其他优化
由于生成RTL代码的过程与具体的图数据耦合,因此在对另一组图数据作计算时,需要按此过程再次编译.解耦数据结构[66]可以提升HLS的综合能力,通过访问器和突变体方法2种方式,使得HLS能够支持除原始数据结构之外的新兴结构,同时也能避免重复编译的问题.
3.2 通用HLS的能力评估
本节将对一些早期HLS工具[13-15]:TAPAS[17],Spatial[18]和Bluespec[19],进行简单的评估,主要从能否支持动态并发以及相应的流水线优化技术支持进行评估,表4是对其基本能力的评估结果.

Table 4 Evaluation of Some HLS Tools表4 HLS工具评估
Bluespec[19]是一种使用Bluespec System Verilog(BSV)的高层次综合工具.BSV是一种基于Verilog,并受到Haskell启发的函数式硬件描述语言.BSV语言基于一种新的硬件计算模型,其中所有行为都描述为一组重写规则或“受保护的原子操作”.与Verilog的进程/线程模型、C/C++的顺序模型不同,BSV程序通过并行协作的FSM表达行为,并且所有行为都可以通过原子规则触发.
Spatial适合挖掘出深度学习及矩阵相乘这类规则访存应用中的并行性,其自动内存划分机制能发挥巨大作用.但在面临BFS等图计算问题时,由于访存的不规则性,其内存自动划分机制难以发挥作用,并且会导致大量的存储单元复制,阻止并行度的提升.
当前通用HLS工具对图计算开发的支持有限.使用这些通用工具,用户难以直接通过高级编程语言为图算法生成高效的并行流水结构,这是由于这些通用语言通常缺乏硬件细节、难以对架构准确进行描述.同时,由于图算法的高数据依赖性,如果没有足够的底层优化,在指定高并行度后会产生数据冲突,导致无法生成硬件电路或者生成效果差.因此,有效支撑图计算的HLS工具是未来FPGA图计算加速的编程与开发环境相关探索的重要方向.
4 编程语言
本节将对FPGA的硬件开发所用的编程语言进行介绍,按照硬件描述语言(HDL)和领域特定语言(DSL).在基于FPGA的图计算加速器的编程与开发环境中,编程语言是其中关键一环,设计出高效且能结合软硬件特点的DSL是编程人员的目标,也是未来图计算加速器编程与开发环境的探索方向.
4.1 HDL
Verilog和VHDL是2种符合IEEE标准的硬件描述语言(HDL),它们有许多共同点.首先,2种语言的程序结构类似,并都支持使用门级原语描述逻辑电路的结构.此外,它们也支持使用过程性语句描述电路的行为.相比VHDL,Verilog程序更加简短,并且许多语言结构和C语言很类似.VHDL是一门强类型的语言,语法更为严谨,具有更强的确定性.
SystemVerilog[3]是对Verilog的扩展,扩充了新的数据类型、压缩和非压缩数组、接口、断言等内容.SystemVerilog结合了硬件描述语言和硬件验证语言(HVL),具有测试平台开发和基于断言的形式验证的功能,并且具有面向对象编程的特点.这些特点使得SystemVerilog具有更强的抽象能力,适合于设计可重用的、可用于综合和验证的IP,以及特大型基于IP的系统级设计和验证.
除此之外,也有运用某种语言作为宏语言生成底层的HDL代码的策略.例如Verischemelog[4]采用Scheme语言的语法,用一种与Verilog相似的方式定义硬件模块.JHDL[5]将Java的类与硬件模块相对应.HML[6]使用标准的ML函数表示电路的连接.这些语言使用简单的方式将硬件描述语言与现有的编程语言联系起来,允许用户使用熟悉的编程语言描述电路结构和行为.但是这些语言需要使用底层的HDL描述一些底层部件,但由于这样一些HDL过于底层的限制,这些语言无法进一步提高抽象能力.
4.2 DSL
当前FPGA的设计工具支持相对原始的编程接口[7],传统HDL缺乏软件编程高级概念,需要设计人员提供时序、控制信号以及内存处理的相关支持,领域特定语言(DSL)对特定领域需求进行了相应的优化,能够让编程人员摆脱体系结构细节的限制,便于版本维护和代码移植[8].
一些DSL是通过元编程的方式实现的.通过将HDL嵌入一种软件编程语言中引进新的编程语言特性,从而获得更高的抽象能力和设计空间探索能力.以下是一些典型例子:
Chisel[9]是嵌入在高级编程语言Scala中的硬件描述语言.借助于Scala的元编程能力,Chisel定义了硬件相关的数据类型和一系列的过程语句,允许用户使用与Scala相近的语法编写程序.同时,它还允许用户定义抽象的数据类型和接口,以及参数化的函数和类,这样可以提高代码的重用性以及支持高度参数化的电路生成.此外,Chisel还可以生成C++代码用于快速、周期精确的软件模拟测试,也可以生成Verilog代码用于FPGA仿真.
VeriScala[10]提供的便捷硬件通信API减少了集成难度,同时在硬件设计中构建了一个填充层用以处理通信协议,提高了用户的开发效率.SysPy[11]基于Python语言,利用了Python脚本语言的优势,将Python语言作为HDL、即用型VHDL组件和可编程处理器软IP内核之间的联系.
还有一些对高级语言进行扩展来形成的DSL,如Pyverilog[12]扩展了Python语言,提供了4个关键库:解析库、数据流分析库、控制流分析库和Verilogcode生成库,用于支持快速原型开发.
总体来说,目前已有的硬件编程语言在实际应用中有代码的功能性强且代码运行高效的优势,利于细粒度的底层元件和逻辑设计.与此同时,它们的缺点在于学习成本高、开发周期长、所需的专业知识强,在特定领域很难发挥自身优势.这也是当前业界对于高层次编程与开发环境封装的探索的重要原因之一.领域特定语言(DSL)的兴起提高了领域专用问题的描述与解决能力,它帮助开发者在专业领域知识不深的情况下,使用简单的语法和部分直接可用的接口来实现,搭建快速有效的面向专用应用的设计平台.但它的问题在于编程标准不够明晰,设计实现需要额外的编译或翻译工具,并且这种方式实现的加速器通常无法提供高层逻辑抽象与底层具体实现的严格对应.将二者融汇结合,能够提供高效的底层代码,同时也能够提高编程效率,是加速器编程与开发环境的未来主要研究方向.
5 用户程序接口
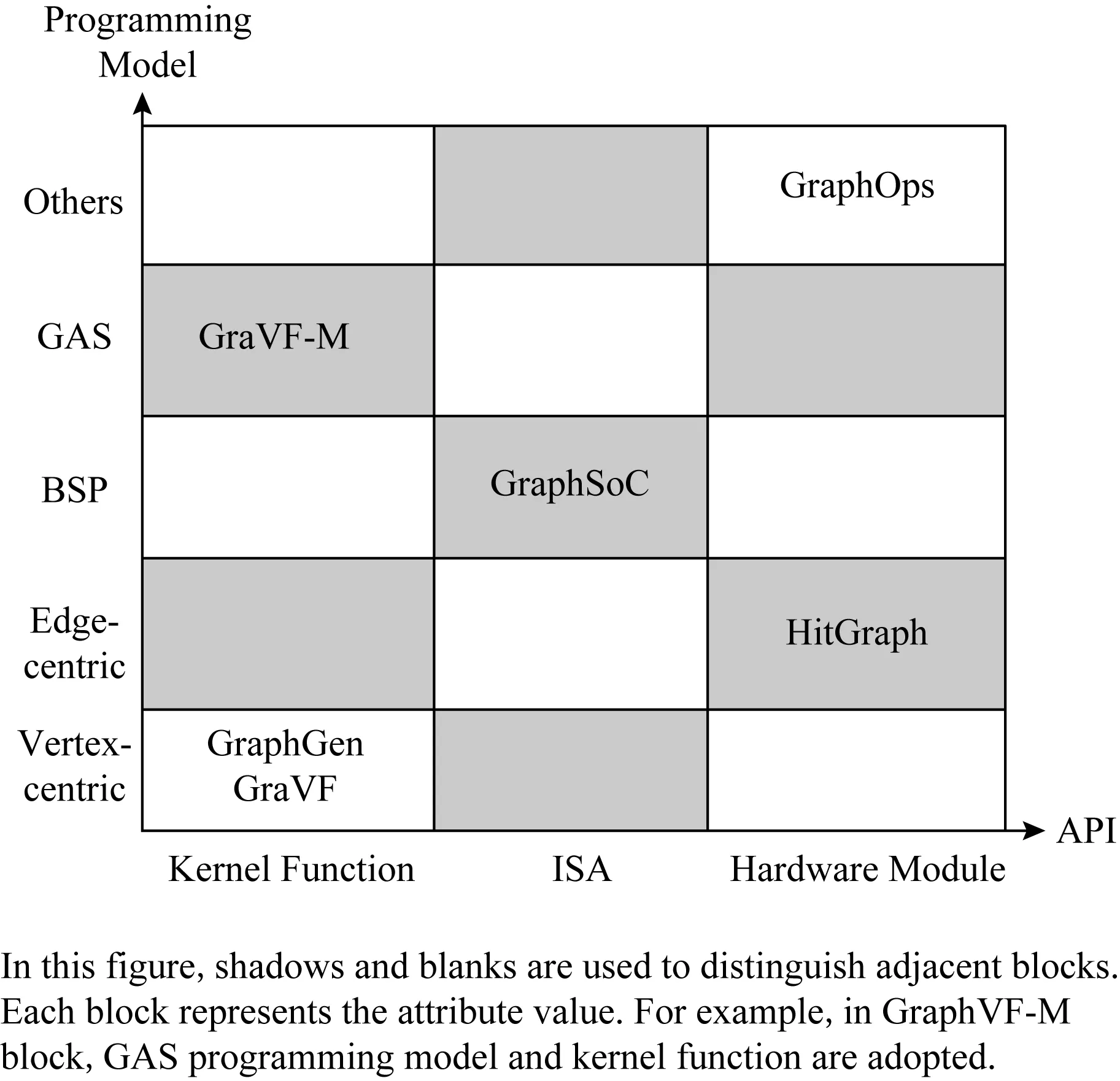
Fig.2 Classification of the interfaces and programming models of the graph processing frameworks图2 图计算编程框架提供的接口及编程模型分类
现有的在FPGA上实现图计算加速的架构很多,但是很大一部分工作[20-22]只专注实现一种图算法(例如SSSP或BFS等),而不能轻易地将其扩展以支持其他图算法.除此之外,许多硬件架构支持多种图算法,这些架构统称为图计算框架(graph processing framework).然而很多框架[23-24]没有给出明确的的应用程序接口,使得其他开发者无法将这些框架用于自己的图计算系统中,因此它们不在编程与开发环境的讨论范畴.在本节中,我们将从3种不同的策略来介绍这些应用程序接口,以提取出便于用户进行加速器开发的逻辑抽象.这些接口可以使用户可以专注于图算法的设计,而无需关心系统底层的实现与优化细节.
通常,这些框架内部采用某一编程模型实现,而编程模型对部分算法的适配性,会限制这些框架能够进行计算的图算法的种类.因此,我们将对文中提到的图计算编程框架按照其提供的接口类型与编程模型分类,如图2所示.下面,我们按照框架提供的用户接口的类型对它们进行分类介绍.
5.1 封装核函数(kernel function)方式
在第2节中,我们介绍了图计算的编程模型.按照特定的编程模型,用户只需要设计出相应的核函数,就可以表达出某种图算法.大部分的图计算编程框架都是按照某种编程模型设计的,只要求用户按照规定的I/O接口定义设计出相应的核函数,就可以结合框架中的其他固定的模块生成图算法的加速器.
由于不同框架采用的编程模型的不同,用户需要定义的核函数的数目也不同.GraphGen[49]采用顶点中心的编程模型,要求用户定义顶点更新函数update-function(v).GraVF[51]同样采用顶点中心的编程模型,但是顶点更新函数的定义要分成apply和scatter两部分(分别称为apply核和scatter核),并最终实现为2个硬件模块.而GraVF-M[54]采用GAS模型,要求用户将核函数分为3个硬件模块:Gather(对每条消息,更新顶点状态)、Apply(在一个超步的最后,根据顶点状态生成消息)、Scatter(将生成的消息发送到目标顶点).
在不同的框架中,定义核函数的方式也各有不同.由于GraVF和GraVF-M使用基于Python的元编程语言Migen[67]生成硬件实现,用户在定义函数时只需要使用Migen的语法编写即可.而GraphGen设计了一套用于定义顶点更新函数的语法,其中包含定义临时变量、对顶点v的邻边进行遍历、对顶点和边关联的数据进行计算和更新等语法结构,其中也可以包含一些用户自定义指令.
考虑到最终的硬件实现需要以RTL代码的形式给出,因此框架需要提供从核函数到RTL代码(如Verilog)的编译器.对于GraVF和GraVF-M,由于核函数和系统其他部分都采用Migen实现,因此RTL代码可以通过Migen的编译器生成.GraphGen的编译过程分为3步:1)需要将图数据分割成适宜的大小并分配到FPGA的各个BRAM上,这一过程既可以采用手动分割的方式,也可由GraphGen自动分割;2)编译器根据用户编写的顶点更新函数和用户自定义指令,结合具体的图分割方式,产生针对每个子图的程序以及FPGA的存储器映像(memory image);3)编译器产生可用于综合的Verilog代码.由于生成RTL代码的过程与具体的图数据耦合,因此在对另一组图数据作计算时需要按此过程再次编译.
5.2 指令集架构(ISA)方式
GraphSoC[68]针对图计算的特点,设计了一个图计算专用的指令集架构.与普通的CPU的架构不同,GraphSoC中包含了用于保存顶点和边的信息的专用寄存器,而不包含通用寄存器.GraphSoC的指令集中包含了专为图计算设计的指令,这些指令可以直接操作专用寄存器.例如,指令RCV的功能是将边数据从存储器中取出,指令ACCU的功能是对一个顶点的入边进行聚合操作,指令UPD的功能是将聚合操作的结果对顶点的值更新.使用GraphSoC的指令编写的图计算程序,可以运行于实现了GraphSoC架构的FPGA上.
为了简化图计算加速器的设计,GraphSoC支持采用BSP编程模型进行图计算.与编程模型的阶段对应,GraphSoC的指令集中包含了4种指令,分别为receive,accum,update,send.由于对不同的图算法,这些指令对应的操作不同,因此这些指令须由用户定义产生.用户首先采用C++ API调用的方式对这4个指令作出定义,通过编译器编译后,再通过GraphSoC提供的汇编器生成相应的微指令代码.
GraphSoC的处理器流水线架构使用Vivado HLS设计编写,虽然需要经过耗时的CAD流程才能编译为RTL代码,但是由于这部分对于所有的图计算任务都固定不变,因此只需编译一次即可.编译、综合后的处理器与用户定义的指令共同构成图计算的运行时系统.
5.3 硬件模块库(hardware module)方式
许多图计算框架提供设计好的硬件模块,其中既包括提供图操作通用的运算符模块的框架[57],也包括将常用图算法封装为硬件模块的框架[53,69].
GraphOps[57]包含许多针对图计算的模块,这些模块接收流式的图数据输入,经过计算并将计算结果流式地输出.通过将这些模块进行组合,可以描述一系列图分析算法.这些模块以MaxJ的函数库的形式提供,可以通过在MaxJ程序中调用,也可通过高层次综合系统编译为RTL代码的方式使用.GraphOps硬件库从各种图算法的硬件实现过程的实际需要出发,提供3类硬件模块,分别为数据模块(data block)、控制模块(control block)、工具模块(utility block).数据模块是GraphOps硬件库中的主要组成部分,主要功能是接收数据输入进行算术运算,然后将结果输出到存储器或者后续的模块中.控制模块包含一些反馈控制逻辑,用于表达状态机.工具模块包含一些与内存系统与主机平台交互的工具.为了使用GraphOps实现一个特定的图计算加速器,用户首先根据算法的特点选择需要的模块,之后通过修改模块的参数对模块进行的计算过程进行配置,最后将这些模块的输入、输出流相连,组合形成满足特定功能的图计算系统.
HitGraph[53]可以根据用户设置的硬件参数等信息直接生成FPGA图算法加速器的RTL实现.HitGraph提供了设计空间探索和硬件生成器的软件工具.用户首先将图算法的名称、图数据的具体信息(顶点和边的数据宽度等)、FPGA设备的硬件条件约束(BRAM的大小等)信息作为参数运行设计空间探索工具.设计空间探索以最大化系统的带宽为目标,计算得到最佳的架构参数(处理单元个数等).之后,用户将算法名称和架构参数信息输入硬件生成器中,生成图加速器的Verilog代码.使用HitGraph生成加速器的过程隐藏了加速器内部的设计细节,具有极大的用户友好和易用性.目前,HitGraph支持的算法包括SpMV,PR,SSSP,WCC这4种.由于HitGraph底层使用以边为中心的编程模型,只需要定义Process_edge和Apply_update两个函数就可将其拓展支持其他图算法,而不需要改动其他部件.
6 国内外研究进展分析
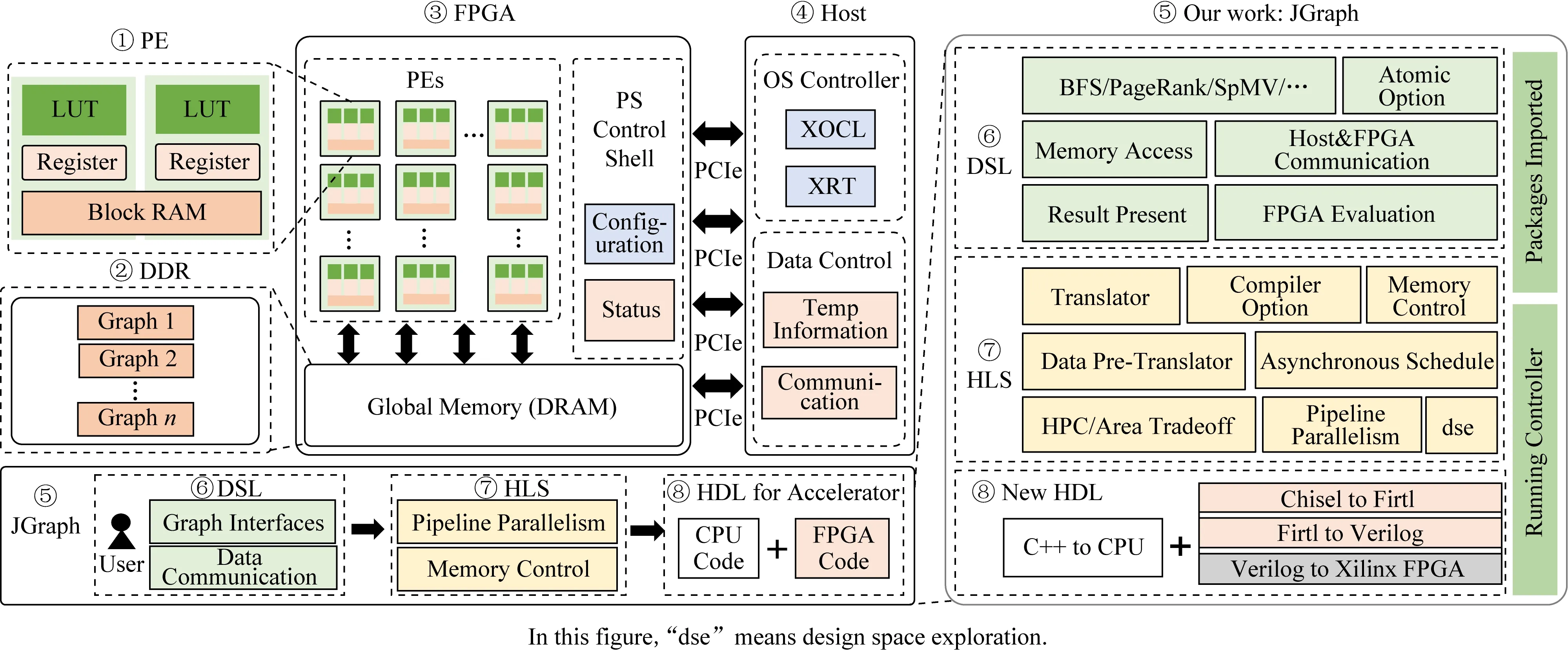
Fig.3 Running environment and design module of JGraph图3 JGraph系统运行环境介绍与系统设计模块图
面向FPGA图计算的编程与开发环境研究工程量大、技术挑战高,目前在国内研究工作局限在少数高校院所.在由上海交通大学与华中科技大学共同进行的FPGA图计算加速器项目中,探索了简单易用的编程与开发环境设计.如图3所示,①②③④描述的是Host与FPGA加速卡的体系架构与通信、控制等模块,图数据从CPU经过PCIe接口传递到主存中,即主要存储在主存上,在运算时会被加载到PE上计算.
该团队设计了如图3中⑤所示的面向图计算系统的FPGA编程与开发环境系统,暂命名为JGraph,以及相关的软件系统设计模块图.图3中JGraph会经过⑥设计的图专用语言编写程序,经过高度优化与凝练的⑦高层次综合系统,生成⑧能够高效运行的代码,一部分在CPU上执行,主要包括数据传输与运行控制部分,算法主体在FPGA板卡上执行,其中会经历从Chisel硬件语言转换为FPGA可用的Verilog语言,共同完成算法的布局与运行.
JGraph能够支持多种图计算编程模型,其中囊括多种经典图操作算子的提取与封装,上层为用户提供简洁易用的程序编写语言和灵活多层次的图计算库函数,设计高效的高层次综合技术,系统能够在保证易用性的前提下生成高性能的硬件代码.
由于FPGA具有高性能高能效计算的潜力,国内外各种基于FPGA的计算硬件加速器层出不穷,诸如Xilinx,Intel等硬件公司推出了各类新型板卡,Amazon以及Facebook等互联网巨头也开发了相应加速器,而国内的浪潮和百度、阿里等互联网公司也在FPGA加速技术上做出探索.作为新兴技术,深鉴科技和美图影像实验室也分别将它们应用于深度学习以及图像处理.
使用FPGA为代表的专用加速器进行图计算已经成为了广泛趋势.Google公司率先开展了大规模图数据的研究,国内外各大企业与高校也开展了相应图计算研究工作.2012年华为和阿里巴巴也进军了该领域.将FPGA应用于图计算加速,学术界已经做出了很多探索,以追求更高的性能和能效,而工业界关于二者的结合探索尚少.FPGA图计算加速的相关工作具体结果如表5所示:

Table 5 FPGA-based Graph Processing Programming Development Environment表5 基于FPGA的图计算编程与开发环境
7 开放问题与挑战
图计算具备广泛的应用前景.在今天,智能电网、医疗保险金融欺诈等应用场景将使得它更加重要,基于FPGA的图计算加速器主要面临着硬件和软件2方面的挑战.在图数据规模日益增加的今天,大图支持是图计算加速器的重要诉求,面向大图的编程与开发环境也是以后图计算开发的重要探索方向.在可编程性的探索中,高效易用且能兼顾软硬件特性的DSL也是有趣的尝试.同时,如何设计出能高效支撑图计算的HLS工具也是重要的探索方向.
7.1 支持复杂环境的大图处理
FPGA片上存储器(BRAM)具有高速随机存取的能力,但是相比于DRAM,BRAM的容量很小,无法存储较大的图数据集.许多图计算加速器,将图数据集存储于单个FPGA的BRAM中,因此在处理大规模图数据的问题上,FPGA开发还面临挑战.在面向大图问题上,使用新兴的内存技术或者支持多FPGA是有效的解决方案,这也为编程开发带来了新的挑战.
1) 新兴内存技术的引入.解决方法之一是在FPGA上增加一块大容量的DRAM.然而由于图计算具有高访存比、随机访存的特点,DRAM的带宽成为系统的瓶颈.改善带宽瓶颈的方式包括使用HMC[21,74-75]或者ReRAM[85]等新型的存储技术,或者通过优化的图存储方式减少随机访存的次数,从而节省带宽,图计算提升性能.
设计有效的语言以支持这些新兴的内存技术,在高级语言层面提供相应的设计支持,以在底层模块提供更好的对应,或者引入相关内存机制优化访存过程,减小开销,这些都是重要的研究课题.
2) 多FPGA架构的引入.采用多FPGA架构是解决问题的第2个方案.使用多个FPGA不仅能够获得更大的片上存储空间,也同时使系统具有更大的带宽和更高的并行计算能力.这种方法的缺点是图数据分布在多个FPGA上,导致计算过程中FPGA之间需要频繁交换数据,跨芯片的通信延迟成为了计算的关键路径.通常的改进方式为使用更为优化的图分割方式,或者对算法的执行流程进行优化,以减少消息的发送量.
在采用多FPGA架构时,高效且开销小的通信机制是未来的重要探索方向之一.为了使用这一特殊架构,将高效的通信机制引入相应的编程与开发环境将是一个有趣的探索.
7.2 支持底层友好的高层编程
虽然FPGA硬件开发人员可选的开发工具(例如硬件描述语言、高层次综合工具,以及图计算框架等)种类繁多,但是开发方式之间各有优势与不足,需要开发者作出权衡.
1) 易用的DSL诉求.现有的FPGA图计算框架只允许用户通过修改硬件架构中的部分模块的方式更改加速器的行为,而架构中其他的模块以及图的存储方式都是固定的,这限制了框架的应用场景.当前,FPGA图计算领域还没有出现像CPU上的图计算DSL那样的具有细粒度图计算算法描述能力的语言,这一方面是由于FPGA在运行方式上与CPU的巨大差异,另一方面是由于FPGA设备的型号与支持的硬件设备的多样性.尽管许多新兴的DSL通过元编程等方式嵌入高级编程语言,降低了编程难度,但是由于相关工具链不够成熟、文档描述不够全面、支持的FPGA设备有限等原因,还没有得到广泛的应用.因此,针对FPGA图计算领域,设计出一种通用的高效易用的DSL仍然是一项巨大的挑战.
2) 高效的HLS支持.传统的硬件描述语言(如Verilog,VHDL)专为硬件开发设计,运行效率较高.但是要求开发人员掌握底层的时序电路等硬件知识,并且相比于计算机编程语言,缺乏足够的抽象能力.因此具有开发周期长、编程难度大的缺点.
HLS工具种类繁多[25],并且各种HLS工具采用的优化策略不同,因此对于不同类型的应用,不同的HLS工具生成的加速器效率可能不同.高效的DSL支持、友好的指令优化、可控的IR表示粒度以及高效的调度算法,都能使得HLS工具有效地支撑图计算,是未来FPGA图计算的编程的探索方向.
根据一些已有的工具[18,89],将机器学习引入到HLS工具中将是一个有意思的尝试.Spatial[18]使用了一种基于机器学习的内存划分机制,而FlexTensor[89]提出了一种自动探索调度空间与优化的框架.
8 总 结
对于FPGA这种特殊的硬件架构,高效的编程与开发环境是提高开发效率的关键要素.我们对FPGA图计算加速器设计过程设计的编程和开发环境做了综述,为了系统地说明编程与开发环境的特性,我们从编程模型、高层次综合、编程语言以及用户接口这4个方面做出了详细介绍.本文对一些关键技术进行说明,能够为以后基于FPGA图计算加速器的开发提供思路与方向.同时,我们还介绍了国内外FPGA图计算加速器的工作进展.最后,本文还总结出了FPGA图计算编程与开发环境的相关挑战,并对FPGA图计算编程与开发环境的有关探索方向进行了展望.
