一种基于强化学习的混合缓存能耗优化与评价
2020-06-23徐光平薛彦兵
范 浩 徐光平 薛彦兵 高 赞 张 桦
1(天津理工大学计算机科学与工程学院 天津 300384)2(智能计算及软件新技术天津市重点实验室(天津理工大学) 天津 300384)3(天津中德应用技术大学 天津 300350)
静态随机访问存储器(static random access memory, SRAM)作为缓存广泛地使用在现有的计算机体系结构中,它极大地缓解了处理器与内存读写速度不匹配问题,提高了计算机性能.但是SRAM也存在缺点,它集成度低、密度小、泄漏功率高.为了缓解这些问题,人们研究了许多新型非易失性存储器(non-volatile memory, NVM).新型非易失性存储器可实现更高的单元密度、更低的泄漏功率和更低的成本.目前,自旋转移力矩随机存取存储器(spin transfer torque RAM, STT-RAM)有可能成为领先的存储技术,具有比SRAM更高的单元密度、更低的泄漏功耗.
然而,STT-RAM也存在高写入能量、高写入延迟的缺点.特别是,它在写操作期间会产生磨损,从而限制了可以为每个单元执行的最大写操作次数.这些缺点限制STT-RAM的使用和性能的发挥.因此许多人在研究如何解决这些问题,从而更好地使用STT-RAM.
目前的研究主要集中在将SRAM和STT-RAM相结合组成混合缓存(SRAM/STT-RAM),充分利用SRAM和STT-RAM各自的优势设计优化数据存储策略.混合缓存结合了SRAM和STT-RAM各自的优点.一方面,由于SRAM的写入能量和写入延迟小于STT-RAM的写入能量和写入延迟,混合缓存有助于减少STT-RAM的写入能耗和写入延迟,从而降低动态能量消耗.另一方面,由于STT-RAM的单元密度大于SRAM和STT-RAM的泄漏功率小于SRAM,在同等面积下混合缓存能提供比SRAM更大的缓存容量和更低的泄漏功率.
在混合缓存中,缓存分为SRAM区域和STT-RAM区域,并且经常写入的块(写密集块)被分配到SRAM区域以减少STT-RAM区域的写入次数.以前的策略仅根据操作类型(读/写)[1-3]来确定写密集型数据,将写密集型数据放入SRAM中,过于简单且效果差.没有考虑到SRAM的容量要小于STT-RAM并占混合缓存中很小一部分,过多地将写密集性数据放入SRAM,可能会增加混合缓存未命中率,降低性能.因此,为不增加混合缓存的未命中率,可以考虑将一部分包含写操作数据放入STT-RAM中,但是需要控制好界限(确定哪些数据分配到STT-RAM),因为过多地往STT-RAM写入数据会增加写入延迟和写入能量.因此,在不增加混合缓存的未命中率和减少对STT-RAM写入次数之间的权衡,是混合缓存设计中的重要挑战.
本文利用缓存访问请求的写入强度(定义见第3节)和重用信息,提出来一种基于能耗的强化学习缓存分配策略,将缓存分配到SRAM区域或者STT-RAM区域中.该分配策略是在不增加混合缓存未命中率的情况下有利于减少STT-RAM的写入次数,从而有效地降低了缓存系统的能耗.
在设计分配策略前,缓存的数据收集必不可少.首先,通过对缓存行进行分类,将具有相似性质的缓存行聚集在一起.然后,在缓存行集合下收集缓存行的写入强度信息和重用信息,根据这些信息计算出缓存行集合的能耗.
分配策略就是将缓存行集合中缓存行分配到能耗小的区域(权重大的区域).关键思想是使用强化学习对缓存行集合的能耗进行学习,得到该集合分配到SRAM区域或者STT-RAM区域的权重,将集合中的缓存行分配到权重大的区域.实验评估表明,与单核和四核系统中现有的方法相比,我们所提出的策略分别降低了16.9%和9.7%的能耗.
1 相关工作
目前针对STT-RAM的研究提出各种优化方法[4].主流的优化方法是结合SRAM低写入能量以及STT-RAM低泄漏功率和大容量的优点提出混合缓存架构.这些研究主要目标是减少STT-RAM写入次数、降低混合缓存能耗,从而提高混合缓存的性能.
Wu等人[5]提出了一种基于饱和计数器的方法,通过使用每个块的饱和计数器识别访问密集型块,用于检测和将写密集型数据迁移到SRAM区域,并将读密集型数据迁移到非易失性随机访问存储器(non-volatile RAM, NVRAM)区域.他们在每条SRAM高速缓存行中添加了一个粘性位,以使LRU块可以进行第2次更改以保留在SRAM中,从而避免了过于频繁的数据迁移.在他们的方法中,饱和阈值被设置为3.Li等人[6]提出了一种基于编译器辅助的方法识别迁移密集型数据块,并将迁移密集型数据块优先选择分配到混合缓存的SRAM部分,以减少迁移带来的开销,提高混合缓存的性能和能效.此外,他们还提出了一种数据分配技术以提高优选缓存的效率.Ahn等人[7]提出来一种基于PC的方法,通过跟踪倾向于加载写密集型块的高速缓存未命中指令,并设计一个新的成本模型来预测未命中缓存块的写强度阈值,将成本高于或者等于写强度阈值的缓存块放入SRAM区域.在他们的方法中,写成本阈值可以动态调整,自动适应每个程序.
Peled等人[8]采用了一种特定的强化学习模型,称为上下文相关的赌博机(contextual bandits)[9-10],然后将捕获的编译器注入的提示获得的许多软件属性和CPU捕获的一些硬件属性用于训练和执行基于上下文相关的赌博机模型的算法,以识别上下文状态和内存地址之间的高级关系并预测未来的内存访问.Ipek等人[11]提出了一种基于强化学习的自我优化的内存控制器设计.该设计使用强化学习原理进行操作,克服传统内存控制器采用固定的、刚性的访问调度策略来设计平均情况下的应用行为问题.因为基于强化学习的内存控制器会连续不断地运行,并会根据与系统的相互作用自动调整其DRAM命令调度策略,以优化性能.
上述部分工作提出的策略仅基于写入强度来区分读写密集型,将写密集型数据分配到SRAM中,将读密集型数据分配到STT-RAM中.这些策略过于简单,也不能准确识别写密集型数据块.还有部分工作提出的策略是根据编译时的信息识别写密集型数据.这些策略过于静态,也没有将程序的动态特性进行考虑.先前的大多数工作都只是根据写入强度来区分缓存读写密集型,并预测缓存行分配到的区域(SRAM或STT-RAM).但是仅仅依赖写入强度,不足以完全区分读写密集型数据.而且也没有考虑混合缓存中SRAM容量与STT-RAM容量的差异,SRAM区域只占混合缓存较小的一部分,其容量较小.因此,需要综合考虑写入强度,混合缓存中SRAM和STT-RAM的容量差异对混合缓存能耗和性能造成的影响.目前,强化学习也用来处理现实世界资源分配问题[8,11-12],使得资源利用最大化.在混合缓存结构下,基于强化学习的数据分配策略可以更准确地区分数据写入强度,自动调整数据分配区域,更好地优化混合缓存性能.
2 研究背景和动机
2.1 研究背景
1) 新型非易失缓存存储器
非易失性存储器具有与传统易失性存储器相媲美的性能,但是有着更高的密度和更低的泄漏功率.然而,非易失性存储器通常在写入能量以及耐用性方面与传统易失性存储器有着较大差距.目前最成熟的NVRAM技术包括相变存储器(phase change memory, PCM)、阻变存储器(resistive RAM, ReRAM)和自旋转移力矩随机存取存储器(STT-RAM)等[13].STT-RAM通常被认为是缓存的最佳匹配,因为它具有较低的读取延迟(接近SRAM的读取延迟)和预计每个单元实现4×1012次写入的耐久性[14].为了充分发挥SRAM和STT-RAM的性能,研究员将SRAM与STT-RAM相结合设计一种混合缓存,试图获得两全其美的优势:SRAM较小的写入能量和写入延迟,STT-RAM更高的缓存容量和更低的泄漏功率.
STT-RAM是新一代磁阻随机存取存储器(magnetic RAM, MRAM).STT-RAM单元不使用电荷来存储数据,而是使用磁隧道结(magnetic tunnel junction, MTJ)存储数据,由2层不同厚度的铁磁层及一层几个纳米厚的非磁性隔离层组成,通过自旋电流实现信息写入的.因此,STT-RAM是一种具有接近零泄漏功耗、存储密度高、读取速度快的非易失性存储器.与基于电荷的存储器(例如SRAM和DRAM)相比,STT-RAM具有更低的泄漏功率和更好的可扩展性.从表1可以看出SRAM和STT-RAM之间读写延迟、能耗和密度的差异.
2) 强化学习
强化学习[15-17]是机器学习的一个重要方法,其原理是代理与环境进行交互,以试图将环境控制到能够获得最大回报的最佳状态.强化学习的任务通常可以描述为Markov决策过程(Markov decision process, MDP),但是状态空间、明确的转移概率和奖励函数并不是必需的[18].它具有自我管理和在线学习的特性.因此,强化学习是一种新兴的解决方案,用于基于统计估计和预期长期效用的最大化来做出决策(例如文献[16]).多臂赌博机(multi-armed bandit, MAB)[8-10]问题是一种经典的强化学习问题.MAB问题也是一种序列决策问题,这种问题需要在一系列决策中选择最有利的决策,从而使长期收益最大化.MAB适合解决动态资源分配问题.目前在处理器调度、存储管理中得到一些研究和应用.
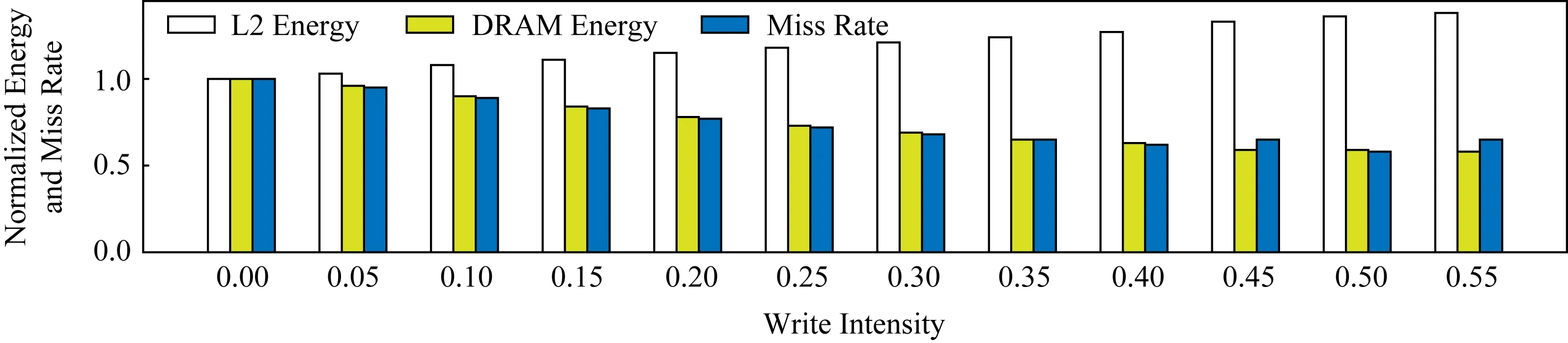
Fig.1 Effect of write intensity on L2 cache图1 写入强度对L2缓存的影响
本文使用MAB的变体探索在线强化学习,并将在线强化学习和遗憾最小化引入到混合缓存中设计缓存分配策略.然而,本文使用的理论框架不同于常规在线学习方法,因为在任何给定时间做出的关于决策的反馈是延迟的而不是瞬时的.我们的算法中只维持2个基本动作的概率分布:缓存分配到SRAM区域的概率和分配到STT-RAM区域的概率.因此,我们算法的目标是“学习”系统的每个状态的“最佳”概率分布,从而达到遗憾最小化.整个算法通过将缓存行分配到能耗较小的区域(SRAM或STT-RAM),接着通过缓存行的特性进行反馈,使得整个过程遗憾最小,每次缓存行分配都是“最佳”的,从而减少混合缓存的能耗,提升混合缓存性能.
2.2 研究动机
混合缓存设计能充分发挥SRAM和STT-RAM的性能,但是先前的策略[1-2,5,7,19-20]仅仅通过写入强度区分读写密集型数据,将写密集数据分配到SRAM中、读密集型数据分配到STT-RAM中.但是在混合缓存中SRAM容量较小,仅基于写入强度分配数据可能导致SRAM未命中率增加,从而增加混合缓存未命中率,影响混合缓存性能.因此可以增加写入强度界限,将一部分含写操作数据分配到STT-RAM中,这样可以降低SRAM未命中率,不增加混合缓存未命中率甚至可能提高了混合缓存命中率.但若是写入强度界限过高会过多地增加STT-RAM的写入次数,从而增加L2写入能量和写入延迟.因此混合缓存分配策略设计中重要的挑战是在不增加混合缓存未命中率的情况下有利于减少STT-RAM的写入次数.
图1显示了在两级缓存层次结构下从PARSEC 3.0基准ferret获得的实验证据.在此图中,x轴为写入强度;y轴显示在以写入强度等于0时为基准,在不同写入强度下,L2 Energy,DRAM Energy,L2 Miss Rate的变化.从图1中可以看出,随着写入强度的增加,L2未命中率和DRAM能耗都在降低,而L2能耗却在增加.这主要是因为将一部分缓存行(有过写操作的)分配到了STT-RAM中,减少了SRAM的压力,从而降低了L2未命中率,减少访问内存的次数,降低了DRAM能耗.然而,这样却增加了STT-RAM的写入次数,从而增加了L2写入能耗.当写入强度大于0.45时,L2未命中率基本不再改变.写入强度继续增大并不能再降低DRAM能耗和L2未命中率,却会继续增加STT-RAM写入次数,继而增加L2能耗.这意味着写入强度影响着混合缓存的未命中率,影响着STT-RAM的写入次数,影响着混合缓存的能耗.因此需要选择一个合适的写入强度,在不增加混合缓存未命中率的情况下有利于减少STT-RAM的写入次数.
我们设计一种基于能耗以及缓存的写入强度和缓存重用,使用强化学习的缓存分配策略.通过缓存行的写入强度信息和重用信息,计算出缓存行集合放入SRAM和STT-RAM所花费的能量,将集合中缓存行分配到所需能量低的区域.这种分配策略在不增加混合缓存未命中率的情况下有利于减少STT-RAM的写入次数,从而提高混合缓存的性能.
3 系统结构
本文利用缓存访问请求的写入强度(读写信息)和重用信息,提出强化学习混合缓存(reinforcement learning hybrid cache, RLHC)架构,一种基于能耗和强化学习的缓存分配策略.
首先给出缓存行的写入强度和重用概念.写入强度是针对混合缓存提出来的概念,规定了缓存行分配到STT-RAM的界限.缓存分配策略将高写入强度的缓存行分配到SRAM中、低写入强度的缓存行分配到STT-RAM中.我们将写入强度定义为缓存行在指定窗口期(规定的访问次数)内写操作数占总操作数的比例.写操作次数越多,写入强度越高.写入强度越高,缓存行分配到SRAM的条件越严.如当写入强度为1时,缓存行在窗口期内全部为写时才能分配到SRAM区域,其他情况缓存行都会被分配到STT-RAM.这种情况会导致过多的缓存行分配到STT-RAM,STT-RAM写入次数过多,增加写入能量和写入延迟,影响整体性能.正式地,写入强度定义为
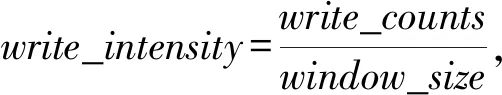
(1)
其中,write_intensiy为写入强度;write_counts为在窗口期内缓存行的写操作次数;window_size为窗口期大小,也为缓存行总操作数(缓存行读操作次数与写操作次数相加).
重用是预测缓存行在SRAM区域或者STT-RAM区域中命中的可能性.对其分为短、中、长3类.在SRAM区域中命中(短重用),在STT-RAM中命中(中等重用)或在2个区域中都未命中(长重用).图2显示了如何判断重用.
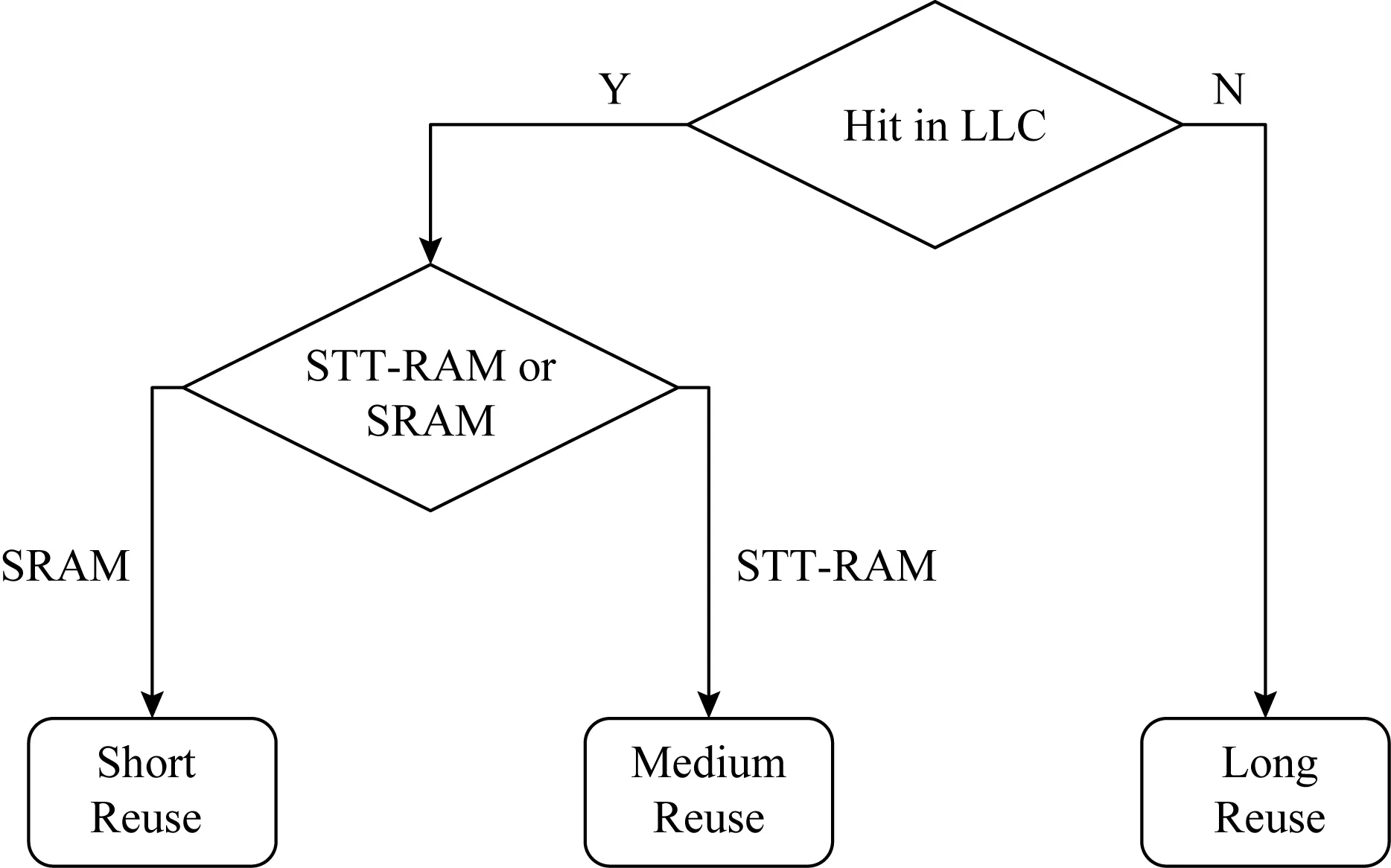
Fig.2 Reuse judgment logic图2 重用判断逻辑
图3给出了混合缓存系统的整体组织架构.该架构由混合缓存和分配预测器组成.与其他混合缓存架构类似,每个高速缓存集分为SRAM区域和STT-RAM区域.数据区域由SRAM和STT-RAM组成,标签区域仅由SRAM构成[21-22].分配预测器存储开销小,需频繁读写,因此也由SRAM构成.
混合缓存架构的整个思想就是在缓存行未命中时,在分配预测器中查找该缓存行的分配策略,然后将未命中的缓存行分配到合适的位置(SRAM或者STT-RAM).图3左侧为分配预测器,展示了RLHC算法框架.RLHC算法框架可以分为数据收集、反馈和预测部分.首先是数据收集,对未命中缓存行的miss-PC进行Hash得到一个签名,然后记录下该缓存行的读写信息(读或者写操作)和重用信息.接着是反馈,在窗口期结束后通过收集的信息,计算出该缓存行放入SRAM区域和STT-RAM区域的能耗,以及读写特性(read-only, RO;write-only, WO;read-write, RW).其中,RO表示缓存行集合中缓存行在窗口期内全为读操作,WO表示缓存行全为写操作,RW表示缓存行读写操作均有.最后是预测,根据反馈阶段得到的SRAM区域和STT-RAM区域的能耗,选择更新能耗较小区域的权重,利用读写特性进行奖励,使遗憾最小化.最后计算出SRAM区域和STT-RAM区域的权重,缓存行则分配到权重大的区域.我们算法的目标是“学习”系统的每个状态的“最佳”概率分布.在每次分配缓存行时,将缓存行分配到“最佳”的区域(SRAM或STT-RAM),从而使整个过程遗憾最小化.从整体设计来看,在混合缓存中应该将缓存行分配到合适的位置,从而减少STT-RAM写入次数,并且不增加混合缓存未命中率,进而减少混合缓存能耗.本文设计的算法目标是使缓存行分配到“最佳”区域,表现出的特征就是整个混合缓存能耗“最低”,并在不增加混合缓存未命中率的情况下有利于减少STT-RAM的写入次数.同时基于强化学习的缓存分配策略能根据能耗,自动调整SRAM区域和STT-RAM区域的权重,更好地适应各种工作负载.
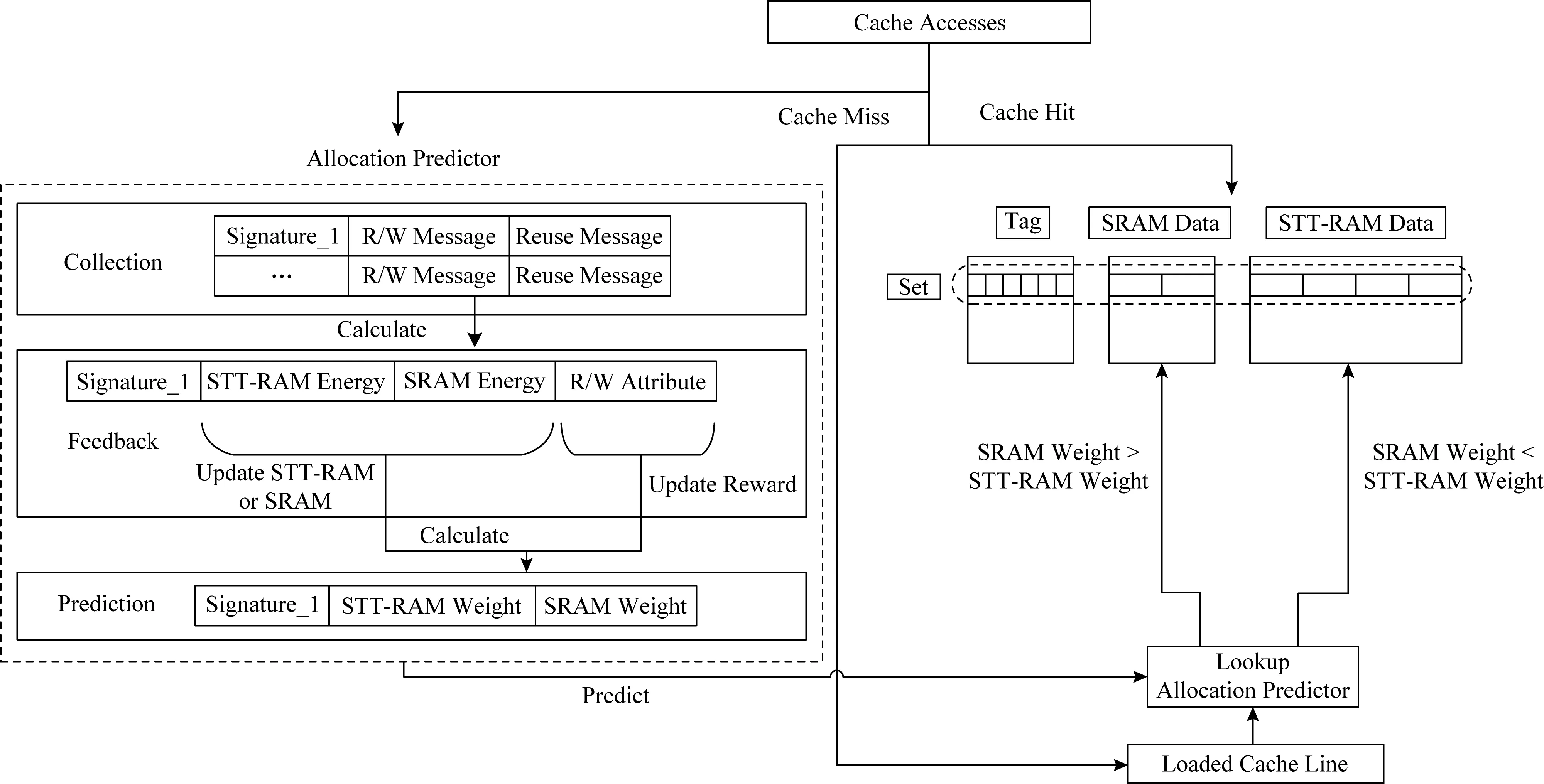
Fig.3 Architecture of RLHC图3 RLHC架构
在设计混合缓存分配策略时,关键的问题有:
1) 如何有效地识别缓存的写入强度?
2) 如何有效地收集所需缓存的信息?
3) 如何将分配策略设计得更加高效?
将在下一部分详细描述解决方法.
4 系统设计与实现
本节详细地介绍基于强化学习的混合缓存分配策略设计整体实现方法.整个设计中主要从缓存行的分类、缓存的状态信息收集、分配策略设计和死区预测这4个方面进行介绍.
4.1 缓存行的分类
当前混合缓存设计的主要挑战之一是如何在缓存行粒度下判断其属性(写入强度和重用).因为必须通过观察缓存行的多次访问才能确定其属性,然后才能存储缓存行的属性,这一过程需要花费足够长的时间.而且存储开销与高速缓存中的缓存行的数量成正比.因此,我们以缓存行为粒度进行学习,会耗时严重、存储开销大,导致学习成本高.为了解决这个问题,我们对缓存行进行分类,以集合为粒度进行学习.一个集合代表一类缓存行.具体来说,我们为每个缓存行分配一个签名,并将具有相同签名的缓存行分类到一个集合中,然后通过收集集合中缓存行的信息来确定整个集合的属性,从而将集合的属性应用于该集合中的缓存行.以集合为粒度能加快学习速度并减少元数据存储.
缓存行集合定义就是具有相同签名的所有缓存行,因此我们需要对缓存行分配一个签名.先前的工作已经提出了各种方式生成缓存行签名,包括指令、指令序列、存储区域、地址、页面偏移、首次访问数据的指令,以及上述的各项的组合[7,22-25].我们选择导致高速缓存行未被加载到高速缓存中的指令miss-PC作为签名.先前的工作也证明了miss-PC作为缓存行签名与写入强度(Ahn等人[7])和重用(Sembrant等人[24])相关.
图4显示了以miss-PC作为签名对PARSEC 3.0中的3个数据集进行分类的结果.3个数据集代表不同的访问模式,blackscholes(读占95%)为读密集型,facesim(写占72%)为写密集型,swaptions(读占55%)为读写均匀型.为方便展示,只统计了这3个数据集在L2中访问次数前十的集合.集合里基本上只有一种操作,如blackscholes前5个集合都是读,facesim前4个都是写.这表明基于miss-PC的签名能够有效地识别缓存行写入强度,我们的分类方法是有效的.
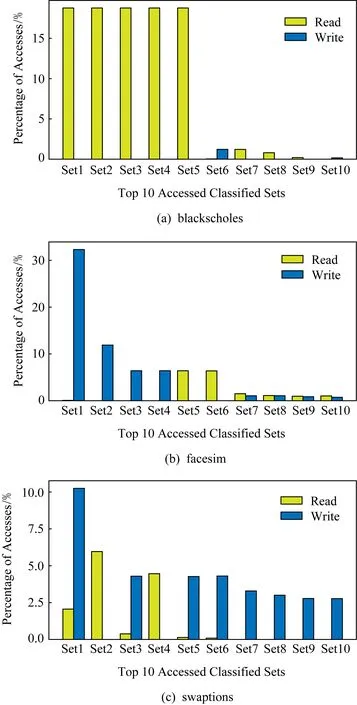
Fig.4 Classification based on miss-PC signature图4 基于miss-PC签名的分类
4.2 缓存的状态信息收集
我们的策略是以集合为学习粒度,需要收集集合中每个缓存行的写入强度和重用信息,并根据这些信息计算出SRAM区域和STT-RAM区域的能耗,使用强化学习算法进行学习,得出该集合分配到SRAM区域和STT-RAM区域的权重,最后得出该集合的分配策略.我们针对不同的工作负载实验不同的窗口期大小.我们发现将窗口期大小设置为20时,我们的策略在不同的工作负载下都能取得一个较好的性能,并且缓存行访问信息的存储开销较小.当缓存行集合收集了20次访问信息便会重置以前收集的信息,重新收集访问信息.
每次缓存行访问时收集2条信息:缓存行操作类型信息和重用信息.这些信息都记录在缓存行对应的集合里.1)缓存行操作类型.记录缓存行访问时是读还是写.2)重用.记录缓存行在SRAM区域还是STT-RAM区域命中或者未命中.
收集的数据信息存储在分配预测表中.该表不仅存放收集的数据,还存放缓存行集合分配策略、死区标签、权重信息.图5展示预测表中一个元素的结构.Signature为缓存行miss-PC签名,当缓存行未命中时,根据miss-PC签名在表中查找分配策略,然后按照分配策略将缓存行分配到指定区域.先前的研究[7]已经使用12个最低有效位来存储miss-PC标签.为了避免存储完整miss-PC的开销,我们也使用12个最低有效位,也观察到与存储完整的miss-PC具有基本相同的精度(在1%内).History Window记录该集合中所有缓存行的访问信息(写入强度和重用).P代表该集合的分配策略;D为该集合的死区计数器,判断该集合是否为死区,从而判断是否需要绕过.Signature为低12 b miss-PC,History Window由6个计数器组成,每个计数器5 b,SRAM Weight和STT-RAM Weight各占4 b,分配策略(P)占2 b和死区饱和计数器(D)占2 b,共54 b/每元素.预测表被设计为LRU缓存,共256个元素,存储在SRAM中,这导致1.69 KB SRAM缓存.
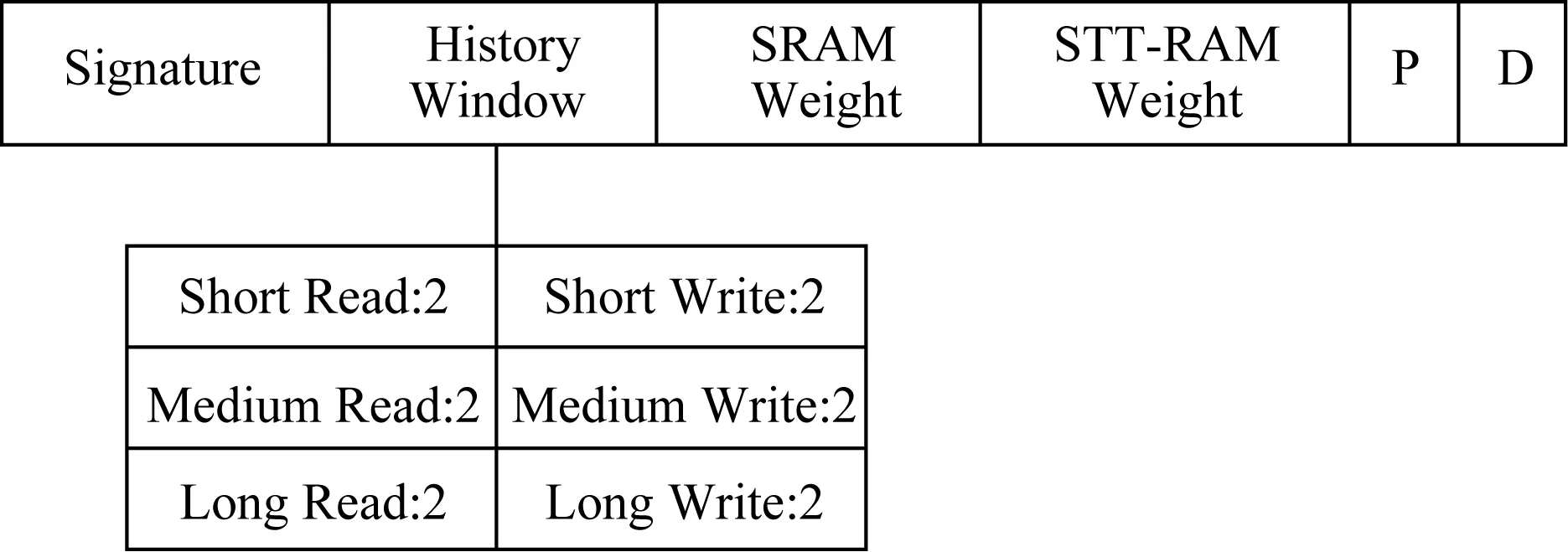
Fig.5 Structure of prediction table entry图5 预测表entry结构
能耗计算.根据图5所示的预测表中的信息计算出能耗.表2显示了如何结合重用信息计算出SRAM区域能耗.重用确定了需要记录(统计)的区域.例如一次短读,SRAM区域记一次SRAM读;一次中读,SRAM区域记一次DRAM读.表3显示了如何结合重用信息计算出STT-RAM区域能耗.
每种能量类型的能量总和相加就是该区域的能耗.读写能量可能不一样,因此每种能量类型还得区分读写.
Power=(Nt_r×Et_r+Nt_w×Et_w)+
(Nsram_r×Esram_r+Nsram_w×Esram_w)+
(Nstt-ram_r×Estt-ram_r+Nstt-ram_w×
Estt-ram_w)+(Ndram_r×Edram_r+
Ndram_w×Edram_w),
(2)
其中,Nt_r:读Tag的次数;Et_r:读一次Tag所需的能量;Nt_w:写Tag的次数;Et_w:写一次Tag所需的能量;Nsram_r:读SRAM的次数;Esram_r:读一次SRAM所需的能量;Nsram_w:写SRAM的次数;Esram_w:写一次SRAM所需的能量;Nstt-ram_r:读STT-RAM的次数;Estt-ram_r:读一次STT-RAM所需的能量;Nstt-ram_w:写STT-RAM的次数;Estt-ram_w:写一次STT-RAM所需的能量;Ndram_r:读DRAM的次数;Edram_r:读一次DRAM所需的能量;Ndram_w:写DRAM的次数;Edram_w:写一次DRAM所需的能量.

Table 2 Calculation of Energy Consumption of SRAM Under Reuse表2 SRAM在重用下能耗的计算

Table 3 Calculation of Energy Consumption of STT-RAM Under Reuse表3 STT-RAM在重用下能耗的计算
4.3 缓存分配策略设计
在4.2节中讲了如何收集访问信息以及如何计算集合的能耗.我们的分配策略是使用强化学习算法学习,得出该集合分配到SRAM区域和STT-RAM区域的权重,最后得出该集合的分配策略.本节主要讲如何使用已有的强化学习算法设计一个分配策略.
本文使用的强化学习算法不同于常规在线学习方法,因为在任何给定时间做出的关于决策质量的反馈是延迟的而不是瞬时的.我们的算法使用在线强化学习和遗憾最小化[26-29],维持着分配到SRAM区域和STT-RAM区域的概率分布.
我们利用强化学习算法设计的分配策略见算法1.权重开始是相等的,尽管我们可以通过缓存行操作类型(读写)来初始化.其中,遗憾(t)可以用缓存行集合的读写特性来描述.因为STT-RAM区域大于SRAM区域,我们更倾向于把偏读的缓存行集合放入STT-RAM区域.缓存行集合的读写特性偏读时遗憾(t)更小.缓存行集合的读写特性是根据统计窗口期里的读写操作确定的,分别为RO,WO,RW.当RO时t=1,WO时t=2,RW时t=3.其中λ是学习率(最初为0.45),d是折扣率(最初为0.0051/N,其中N为高速缓存大小),奖励值r=dt.ratio是根据集合读写特性来定的.当为RO时,缓存行集合中缓存行全为读,更倾向于放入STT-RAM区域,因此ratio=1.05;当为WO时,缓存行集合中缓存行全为写,更倾向于放入SRAM区域,因此ratio=0.95;当为RW时,缓存行集合中缓存行有读有写,无偏向性,ratio=1.0.
算法1.SRAM与STT-RAM权重计算.
输入:SRAM能量sram_energy、STT-RAM能量stt-ram_energy、学习率λ、折扣率d、SRAM权重Wsram、STT-RAM权重Wstt-ram;
输出:更新后的SRAM权重和STT-RAM权重.
①tRO or WO or RW;
②rdt;
③ ifratio×sram_energy>stt-ram_energythen
④Wstt-ramWstt-ram×eλ×r; /*增加
STT-RAM权重*/
⑤ else then
⑥WsramWsram×eλ×r; /*增加SRAM
权重*/
⑦ end if
⑧WsramWsram/(Wsram+Wstt-ram);
⑨Wstt-ram1-Wsram.
通过一个例子来解释我们的分配策略.表4和表5中的数据不代表真实数据,只是为了方便计算和演示.表4展示了每次访问不同区域所需的读写能量.表5展示了缓存行集合A的访问统计,该集合读写特性为RW.由表4和表5可以得出SRAM区域和STT-RAM区域的能耗.

Table 4 Reading and Writing Energy in Different Regions表4 不同区域的读写能量

Table 5 Access Statistics of Cache Set A表5 缓存集合A的访问统计
Esram=1×Etag_r+2×Esram_r+
1×Edram_w+1×Edram_r=421,
Estt-ram=1×Etag_r+1×Etag_w+1×
Estt-ram_r+1×Estt-ram_w+1×Edram_r=272.
根据算法2中Wstt-ramWstt-ram×eλ×r(初始权重都为0.5)得出Wstt-ram=0.78;然后归一化得出SRAM权重为0.39,STT-RAM权重为0.61.因此缓存行集合A中缓存行应该分配到STT-RAM区域.
4.4 缓存死区预测
L2中有部分缓存行只被访问过一次便不再访问,这些缓存行占用了L2存储空间,极大影响了L2性能.已经开发了许多方法来绕过死数据,为实时数据留出更多空间并提高整体命中率[30-33].我们可以使用旁路技术绕过死区,从而减少L2中死区数量,提高L2效率.
我们增加了死区预测,了解缓存集行合是死还是活,并适当地绕过它.因此,我们对缓存行增加一个重用位(1 b),为缓存行集合增加一个死区计数器(2 b),其初始值为11.每次驱逐缓存行时,判断缓存行是否重用,如果重用则递减计数器,否则递增计数器.当死区计数器饱和(值为11)时,确定缓存行集合已死,在缓存行集合的策略中标记,并绕过缓存行集合的后续数据提取.
4.5 小 结
本节分析了缓存行的分类、缓存的状态信息收集、分配策略设计和死区预测.图6显示了我们整个的分配策略.其中,Default代表缓存行为读操作则分配到STT-RAM,若为写操作则分配到SRAM.
5 实验分析与结果
5.1 模拟器配置
我们使用内部跟踪驱动模拟器评估RLHC在单核和四核系统下性能.高速缓存层次结构由32 KB,4/8路组关联专用L1指令/数据高速缓存和每核1 MB,16路组关联共享L2高速缓存组成,其块大小为64字节.缓存一致性由MESI协议管理,而不强制包含属性.混合缓存配置为具有4路SRAM和12路STT-RAM,单核下L2为1 MB,四核下L2为4 MB.
我们提出的混合缓存架构应用于L2高速缓存,并与预测混合缓存(prediction hybrid cache, PHC)[7]的静态版本进行比较.表6显示了我们的评估比较的4种策略.除非另有说明,否则所有结果都将归一化为STT-RAM基线.

Table 6 Evaluated Hybrid Cache Policies表6 评估的混合缓存策略
为了更公平地比较我们的策略和先前的研究结果,这里使用了与先前研究结果[7]相同的SRAM和STT-RAM参数.表7显示了L2缓存的能量和延迟由CACTI 6.5[34]和NVSim[35]在45nm下建模的得到.
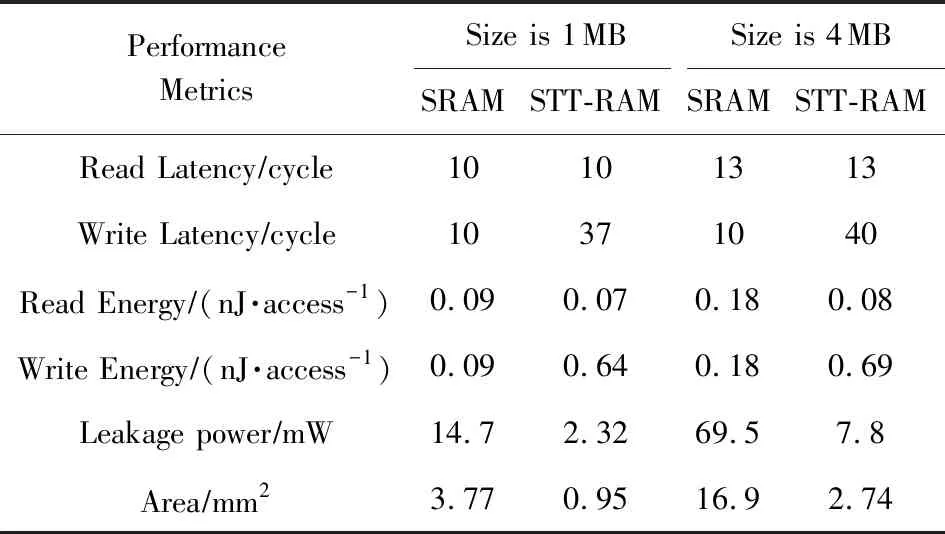
Table 7 Characteristics of L2 Cache表7 L2缓存的特征
在系统结构中,额外的存储开销主要由缓存行存储的12 b miss-PC签名构成.单核系统存储开销包含预测表(1.69 KB)、缓存行存储的12 b miss-PC签名(24 KB)和缓存行存储的一位重用位(2 KB),总计27.69 KB.缓存行签名和缓存行重用位的开销在四核系统中增加了4倍,因为缓存容量增加了4倍,而预测器表的大小保持不变,即总计105.69 KB.总之,我们的策略在单核(四核)系统中引入了2.7%(2.6%)的存储开销.
5.2 工作负载
我们使用来自PARSEC3.0[36]的13个基准测试作为单核和多核工作负载.PARSEC3.0是一个由多线程程序组成的基准套件.该套件专注于新兴的工作负载,旨在代表芯片多处理器的下一代共享内存程序.PARSEC3.0工作负载以涵盖不同领域的应用程序,例如计算机视觉、媒体专业处理、计算财务、企业服务器和动画物理学.表8对PARSEC3.0主要特征进行了定性总结.我们使用Pin[37]在中等输入大小下为每个PARSEC3.0基准测试生成10亿条追踪指令.
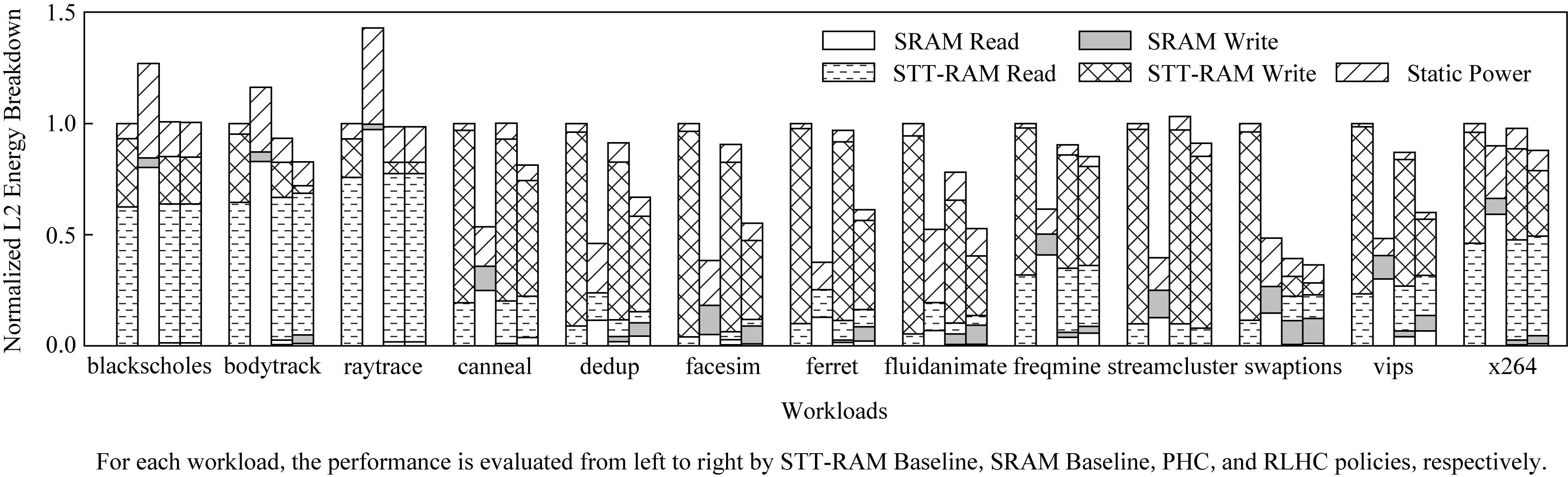
Fig.7 L2 energy breakdown under the single-core system图7 在单核系统下L2能耗分解
Table 8 Qualitative Summary of Key Characteristics of PARSEC 3.0[36]
表8 PARSEC3.0关键特征的定性总结[36]
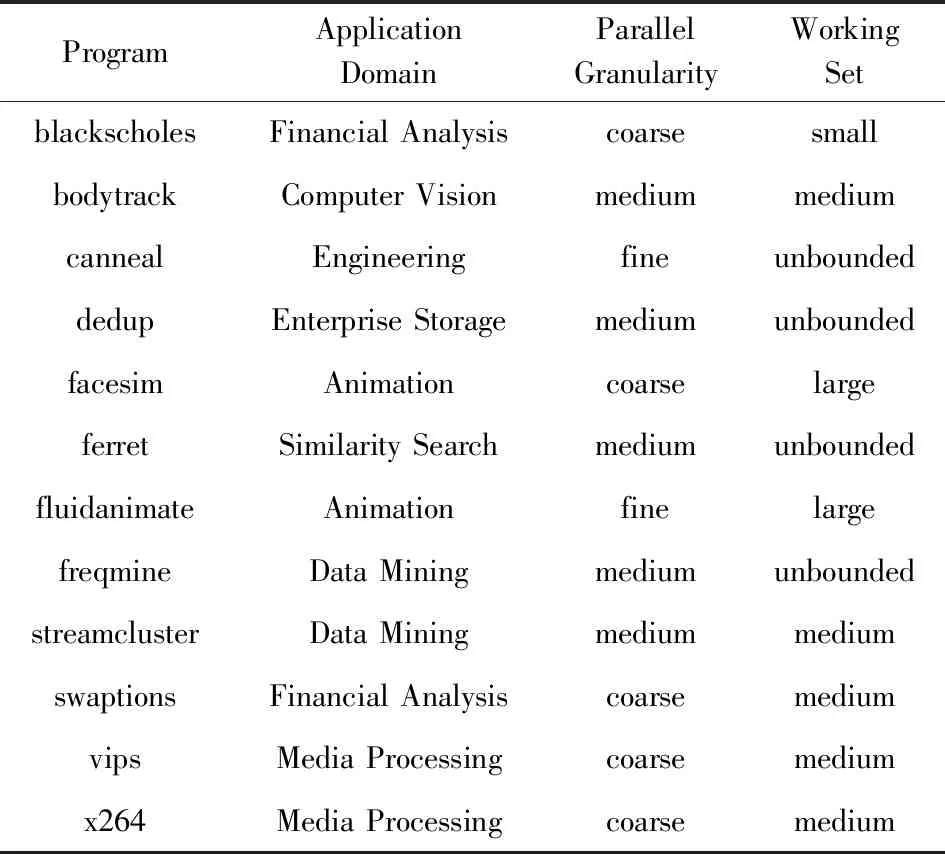
ProgramApplicationDomainParallelGranularityWorkingSetblackscholesFinancial AnalysiscoarsesmallbodytrackComputer VisionmediummediumcannealEngineeringfineunboundeddedupEnterprise StoragemediumunboundedfacesimAnimationcoarselargeferretSimilarity SearchmediumunboundedfluidanimateAnimationfinelargefreqmineData MiningmediumunboundedstreamclusterData MiningmediummediumswaptionsFinancial AnalysiscoarsemediumvipsMedia Processingcoarsemediumx264Media Processingcoarsemedium
5.3 单核上L2能耗
本节首先评估L2在不同策略下的单核系统能耗,分析这些策略对STT-RAM写入次数、L2动态能耗和L2性能的影响,并将我们所提出的策略与SRAM基线、STT-RAM基线和PHC策略分别进行比较.
图7显示了不同策略在单核系统下L2的能量分解,并与STT-RAM基线进行了对比.其中每条被分解为L2缓存静态能量消耗、L2缓存动态能量消耗.其中L2缓存动态能量消耗又被分为SRAM写能量消耗、SRAM读能量消耗、STT-RAM写能量消耗和STT-RAM读能量消耗.如图7所示,前3个数据集(blackscholes,bodytrack,raytrace)SRAM基线的L2能耗高于其他3条(STT-RAM,PHC,RLHC).这主要是因为这3个数据集在L2访问主要为读操作,且读操作占比均超过95%.再加上STT-RAM在读性能上略好于SRAM,泄漏功率只有SRAM的15.7%.这些原因导致SRAM基线在这3个数据集下L2能耗过高.其他的10个数据集,SRAM基线L2能耗比STT-RAM基线要低,主要得益于写操作变多了,STT-RAM写能量超过SRAM的7倍,导致STT-RAM基线中写能量过大.混合缓存表现很好,在这些数据集下混合缓存L2能耗基本都小于STT-RAM基线.这是因为混合缓存结合了SRAM和STT-RAM的优点(相比SRAM具有更低的泄漏功率和相比STT-RAM具有更低的写入延迟和写入能量).总体而言,与STT-RAM基线相比,我们的策略将L2的能耗降低了28.1%,这得益于减少了STT-RAM的写入次数,从而降低了STT-RAM的写入能量.与PHC相比,我们的策略将L2的能耗降低了16.9%.这主要是我们的策略能更好地减少STT-RAM的写入次数,从而减少写入能量.
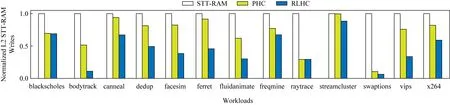
Fig.8 L2 STT-RAM writes under single-core system图8 在单核系统下L2 STT-RAM写入次数
图8显示了在不同策略下L2中STT-RAM的写入次数.PHC和RLHC分别减少了19.9%和49.1%的写入次数.而我们的策略比PHC多减少了29.2%的STT-RAM的写入次数.因此我们的策略更好地降低了L2能耗.与PHC相比,我们的策略将L2的能耗降低了16.9%,同时我们的策略访问DRAM的能耗比PHC只高了0.3%.
5.4 单核上L2性能
图9、图10分别显示了不同策略在单核系统下L2的AMAT和IPC.与STT-RAM基线和PHC相比,我们的策略分别将L2的AMAT降低了2.2%和1.3%.同时,与STT-RAM基线和PHC相比,我们的策略将系统性能分别提高了1.9%和1.1%.PHC和RLHC性能好于STT-RAM,是因为混合缓存中有SRAM,降低了STT-RAM写延迟过高的影响.而PHC和RLHC这两者的性能都略差于SRAM基线,不超过3%.这是因为混合缓存中STT-RAM写延迟过高,降低了性能.
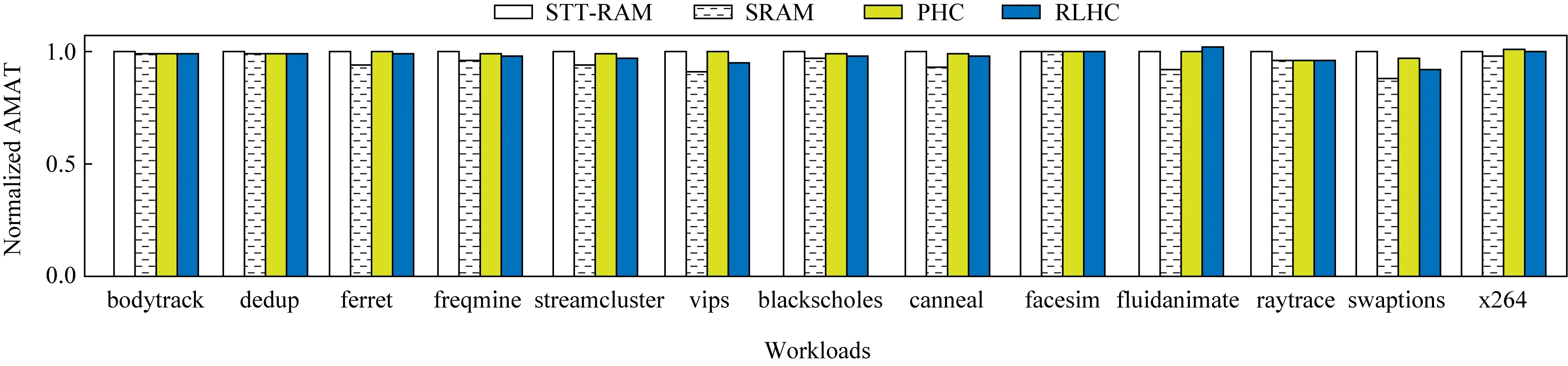
Fig.9 L2 AMAT under single-core system图9 在单核系统下L2 AMAT
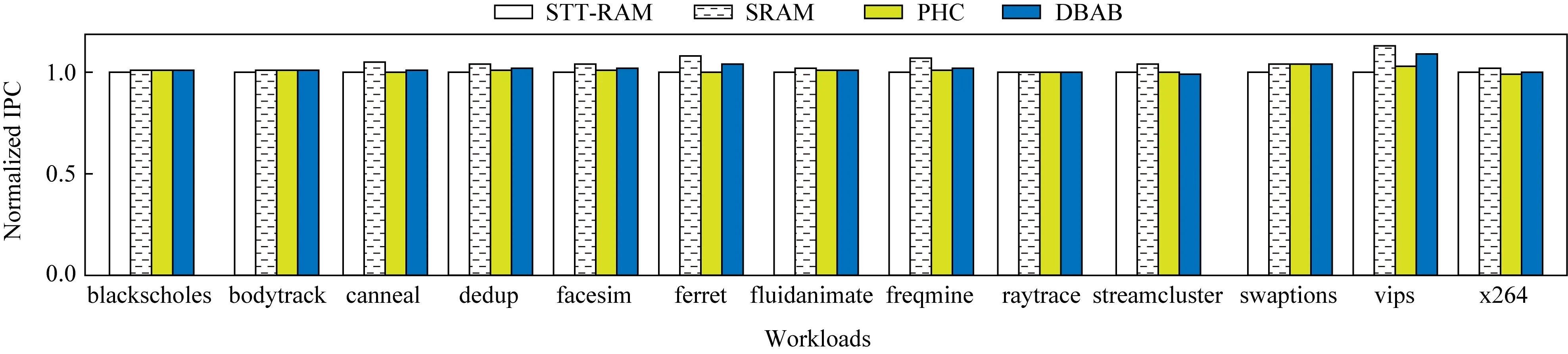
Fig.10 L2 IPC under single-core system图10 在单核系统下L2 IPC
5.5 多核上L2能耗
本节我们评估L2在不同策略下四核系统的能耗.四核配置与单核中的配置类似,只是L2的容量是单核系统下的4倍.
图11、图12分别显示了不同策略在四核系统下L2的能耗分解和STT-RAM的写入次数,并与STT-RAM基线进行了对比.超过半数的数据集,SRAM基线L2能耗都高于STT-RAM基线.主要是因为在四核系统中,SRAM的泄漏功率是STT-RAM的8.9倍,而且读取能量是STT-RAM的2.25倍.再加上这些数据集偏向读,近半数的数据集读操作占比超过75%.特别是blackscholes(读操作占98%),bodytrack(读操作占95%),raytrace(读操作占99%),x264(读操作占86%)这4个数据集,SRAM基线的L2能耗远高于其他3条(STT-RAM,PHC,RLHC).这是因为读操作太多,SRAM低写入能量的特性无法发挥.混合缓存表现不错,在大多数数据集下混合缓存L2能耗要小于STT-RAM基线,在少数数据集下混合缓存L2能耗只是略高于STT-RAM基线.这受益于混合缓存的分配策略减少了STT-RAM的写入次数.PHC和RLHC分别减少了25.7%和44.3%的写入次数.而我们的策略比PHC多减少了18.6%的STT-RAM的写入次数.总体而言,与STT-RAM基线和PHC相比,我们的策略将L2的能耗分别降低了11.9%和9.7%.这比使用单线程应用程序观察到的效果略小.这主要是在多核情况下,每个核访问情况不一样,写访问不均匀分布,导致写入强度很难预测,更难在不增加混合缓存未命中率的情况下减少STT-RAM的写入次数,从而使得比单核系统下效果有所下降.
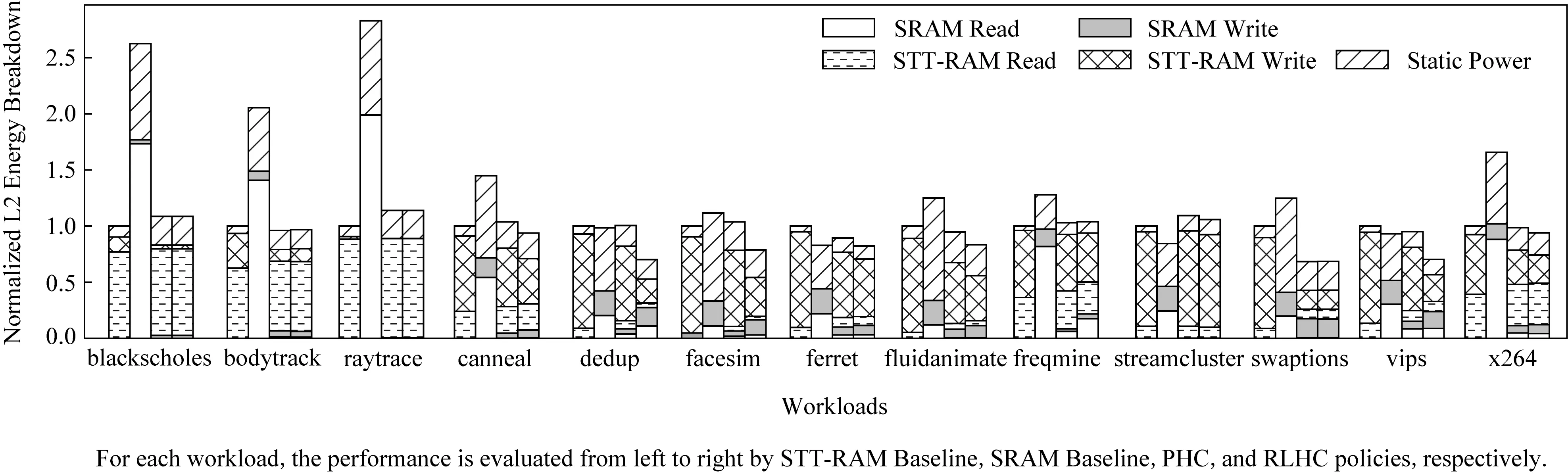
Fig.11 L2 energy breakdown under the quad-core system图11 在四核系统下L2能耗分解

Fig.13 L2 AMAT under quad-core system图13 在四核系统下L2 AMAT
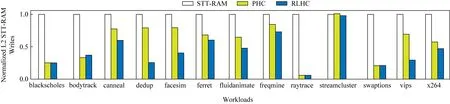
Fig.12 L2 STT-RAM writes under quad-core system图12 在四核系统下L2 STT-RAM写入次数
5.6 多核上L2性能
图13、图14分别显示了不同策略在四核系统下L2的AMAT和IPC.与STT-RAM基线相比,我们的策略将AMAT降低了2%,将IPC提高了2.2%.与PHC相比,我们的策略将AMAT降低了0.7%,将IPC提高了0.8%.
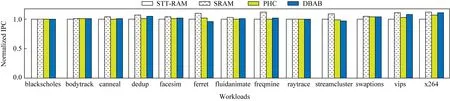
Fig.14 L2 IPC under quad-core system图14 在四核系统下L2 IPC
6 总 结
本文提出了一种在混合缓存架构上缓存数据的智能分配策略.它的关键思想是根据缓存的写入强度和缓存的重用来计算出在指定窗口期下缓存行分配到SRAM区域和STT-RAM区域的能耗,然后基于能耗使用强化学习来计算出缓存分配到SRAM区域和STT-RAM区域的权重,将缓存分配到权重大的区域.基于缓存的写入强度和重用信息能更好地计算出缓存放入SRAM区域和STT-RAM区域所花费的能量,使用强化学习能根据当前能耗动态地调整SRAM区域和STT-RAM区域的权重,能自动适应应用程序负载.这2点使我们的分配策略能在不增加混合缓存未命中率的情况下减少STT-RAM的写入次数,从而提高缓存性能.实验结果表明,与现有的混合缓存策略相比,我们的策略在单核(四核)系统中实现了16.9%(9.7%)的能量降低.这主要得益于我们的策略更好地减少了STT-RAM的写入次数.
