LEDBAT协议优先级反转抑制的启发式动态阈值算法
2020-06-23马阿曼江先亮
马阿曼 江先亮 金 光
(宁波大学信息科学与工程学院 浙江宁波 315211)
随着互联网技术的急速发展,网络应用呈爆炸式增长趋势,其需求的多样性给传输控制协议带来了前所未有的挑战.比如视频会议、在线游戏和VR(virtual reality)等交互式应用要求较低时延、较小抖动以及较小的吞吐量变化[1],而大文件传输、软件更新等非交互式应用传输的数据量往往超过5 MB,其要求高吞吐量而对完成时间并没有严格的要求[2].这种非交互式应用适合以背景流的形式,利用链路剩余带宽进行数据传输,尽量不影响链路中的其他流[3].然而传统拥塞控制算法(congestion control algorithm, CCA)在共享链路带宽时有相同的优先级.相同优先级的拥塞控制协议所导致的时延抖动不能满足非交互式应用的需求,同时也影响了实时交互式应用的用户体验,低优先级拥塞控制(low priority congestion control, LPCC)算法的提出解决了上述问题.
典型的LPCC包括:TCP-NICE[4](2002年)、TCP-LP[5](2003年)、IETF(Internet Engineering Task Force)提出的LEDBAT(low extra delay background transport)[6](2009年)等.TCP-LP与LEDBAT均借助单向时延作为拥塞信号以调节拥塞窗口的尺寸,故能提早感知网络中的拥塞,减小发送速率,保持其低时延的特性.TCP-NICE监控往返时延得到minRTT与maxRTT,若当前的往返时延curRTT超过预设阈值时,将此数据包标记为拥塞.由于LPCC在与标准TCP流(如CUBIC[7],NewReno[8])共享带宽时,排队时延的增加使LPCC不断降低其发送速率,让出带宽,不对标准TCP流产生影响.
LEDBAT自从2009年作为标准草案被IETF工作组提出之后,由于其低优先级性被广泛地应用于许多公司,包括BitTorrent,Apple,Microsoft.BitTorrent公司开发的μTP(micro transport protocol)的拥塞控制算法为LEDBAT,这是LEDBAT的一个主要实现.另外,LEDBAT被Apple公司应用于软件更新等的应用,故Mac OS X和IOS设备中大量的软件下载的应用能够保持低优先级性不干扰实时交互类的应用.最后,作为改进后的LEDBAT算法——LEDBAT++[9],已经能够在Windows 10和Windows Server 2016的TCP协议栈中使用.据统计,截止目前,LEDBAT承载的流量已超过15%.
与此同时,部署在网络层的主动队列管理(active queue management, AQM)算法也可满足应用的低优先级需求[1].AQM部署在中间节点上,可增强TCP的传输性能.现有AQM可按照拥塞指示、参数调整、流区分、控制函数以及反馈信号等进行分类[10].在基于拥塞指示的AQM中,又细分为5类:1)基于队列长度的AQM;2)基于速率的AQM;3)基于负载的AQM;4)基于丢包的AQM;5)以上4类混合的AQM.RED(random early detection)[11]与CHOKe[12]是基于队列长度的AQM.AQM还包括DRR(deficit round robin)[13]和SFQ(stochastic fairness queueing)[14]等的调度算法,以及CoDel(controlled delay)[15].RED算法对平均队列长度进行计算,并根据设置的阈值进行丢包,但参数设置对其性能影响较大.CHOKe改进了RED算法,对已到达路由器的数据包与队列中随机抽取的数据包的ID进行比较,如果2个同属于一个流,则同时丢弃,反之按照RED中的方法进行丢包.CoDel通过数据包在队列中的停留时间来进行控制,有2个主要参数threshold_target与wait_time,threshold_target为可接受的最小队列时延,当数据包驻留时间高于threshold_target,CoDel不会直接丢弃数据包而是在丢弃之前等待wait_time.
路由器等网络设备中的大缓存造成了较大的排队时延以及时延抖动,即“Bufferbloat”[16-17].AQM可以显著减小时延并保持传输公平性,从而解决“Bufferbloat”问题[18].但是,AQM需要中间设备的支持,现有路由器中并未广泛地配置和启用[19].
然而,LPCC与AQM共存时,AQM会破坏LPCC的低优先级.AQM根据策略丢弃或者标记队列中的数据包,导致标准TCP流降低发送速率,而LPCC流由于降低排队时延增加拥塞窗口值.LPCC流发生了优先级反转的情况,并且对标准TCP流产生了影响[20].AQM在解决“Bufferbloat”问题的同时也改变LPCC流的低优先级性[21].
针对上述问题,本文分析了AQM对LEDBAT优先级的影响,并通过实验验证发现LEDBAT中的时延阈值——target值是解决优先级反转问题的关键.然后提出一种根据网络状态动态调整target值的LEDBAT改进算法——启发式动态阈值算法(heuristic dynamic threshold, HDT).
优先级反转问题的根源是源端的拥塞控制算法无法获取链路中间节点的信息,比如路由器是否部署AQM以及该AQM的阈值等.HDT算法根据网络状态采用启发式算法搜索最优的target值以保持其低优先级性.HDT算法能够保证:1)在部署了AQM的链路中,保持HDT流的低优先级,利用剩余带宽;2)在其他链路中,在保持低时延的同时尽量利用带宽,保持较好的带宽利用率.
本文给出了HDT算法关键部分的流程图及伪代码,并采用NS2仿真工具对HDT算法进行分析与评价,从而证明了HDT算法能有效解决优先级反转问题.
本文的主要贡献有3个方面:1)分析了AQM和LPCC算法共存时产生的优先级反转问题的原因,并通过实验验证;2)进一步提出HDT算法,尝试解决优先级反转问题;3)在NS2中搭建了实验场景,通过实验分析评价了HDT算法的性能.
1 LEDBAT的优先级反转问题分析
本节首先分析了LEDBAT中的target值与RED算法中2个阈值的关系,然后搭建实验环境验证了理论分析的正确性.
1.1 优先级反转问题的分析
LEDBAT采用单向时延估计排队时延,以期达到2个目标:1)无其他流竞争带宽时,LEDBAT会在保持低时延的情况下利用带宽;2)与标准TCP流竞争带宽时能主动让出带宽,保持低优先级.
算法1.LEDBAT算法[6].
输入:target;
输出:cwnd.
current_delay=acknowledgement.delay;
base_delay=min(base_delay,current_delay);
queuing_delay=current_delay-base_delay;
off_target=(target-queuing_delay)/target;
cwnd+=VGAIN×off_target×Vacked×VMSS/cwnd.
LEDBAT核心思想如算法1所示,其中base_delay用于保存当前最小的单向时延,并认为最小的单向时延就是在排队时延为0时获得;current_delay为当前的单向时延.当前的排队时延为
queuing_delay=current_delay-base_delay.
(1)
LEDBAT中的target是定义的排队时延阈值.当queuing_delay>target时,off_target值为负值,LEDBAT就减小其发送窗口.故LEDBET能保持其低时延的特性.当标准TCP流与LEDBAT流竞争带宽时,标准TCP流在填充缓冲区的同时,也增加了队列长度.LEDBAT感知到时延增加后减小拥塞窗口,从而实现低时延特性.但是在部署了AQM的链路中,LEDBAT的低优先级性会发生反转,下面以RED算法为例进行说明.
RED算法根据计算平均队列长度来进行拥塞控制,其设置了与队列长度相关的阈值:minth和maxth,并将计算出的平均队列长度avgQ与2个阈值进行比较,若avgQ
在部署AQM的链路中,标准TCP流在发生丢包前,会持续地向网络中发送数据包,导致较高的排队时延.LEDBAT发现排队时延过高,会主动降低自身发送速率,让出带宽给标准TCP流,使其将更多数据包注入到网络中.当队列平均长度达到RED设置的阈值时,RED根据算法进行丢包.因队列中标准TCP流的数据包比例更大,其被丢弃的数据包更多.出现丢包时,标准TCP流的拥塞窗口减半,降低发送速率,队列中的数据包减少,故排队时延减低.LEDBAT中的target值大于RED中设置的阈值所对应的排队时延.LEDBAT增加其发送速率,导致在部署AQM的链路中,LEDBAT与标准TCP共享瓶颈带宽时,无法保证其低优先级性.LEDBAT中的target是算法的关键,该值能对LEDBAT性能起至关重要的作用.
假设链路中RED的2个阈值minth和maxth分别是6.25与18.75(单位是数据包),瓶颈链路容量为10 Mbps,则2个阈值的排队时延分别是7.5 ms及22.5 ms.那么target值存在3种情况:1)LEDBAT的target值大于RED最长队列长度阈值对应的排队时延22.5 ms;2)LEDBAT的最大排队时延target值在7.5 ms到22.5 ms的区间内;3)LEDBAT的target值小于7.5 ms.
当LEDBAT的target值大于22.5 ms(上述情况1)时,标准TCP流持续向网络中注入数据包.当队列长度超过最大队列长度阈值maxth时,RED丢弃所有数据包.标准TCP探测到丢包,开始减小发送速率.而LEDBAT的排队时延降至target值以下,故更加激进地增加其拥塞窗口值,导致发生优先级反转.
当LEDBAT的target值在7.5 ms到22.5 ms的区间内(上述情况2)时.当LEDBAT的排队时延大于target值时,LEDBAT开始减小其拥塞窗口值.然而此时,RED算法也开始进行随机丢包,由于标准TCP所占比例较大,故其被丢弃几率也较大,标准TCP随之降低发送速率,而链路中的排队时延与target值并无较大差别,故LEDBAT以较小幅度增加拥塞窗口值.这种情况下,LEDBAT也发生优先级反转但其程度要弱于情况1.
当LEDBAT的target值小于7.5 ms(上述情况3)时,即使链路中的标准TCP太过激进而导致其降低发送速率,LEDBAT也会由于target值过小,而不能在标准TCP减小其发送速率时,快速反应增加其拥塞窗口的大小,故LEDBAT依旧保持其低优先级的特性.
在LEDBAT的实现中,target是一个定值.但是不同链路存在不同的排队时延.如果不考虑网络链路状态,将target设置为固定值会导致LEDBAT的吞吐量过高而破坏了算法的低优先级性,或吞吐量过低而不能充分利用链路带宽.
1.2 优先级反转问题的验证
本节的实验场景为哑铃型拓扑,瓶颈链路容量设为10 Mbps.为了实现链路的高负载,设置了10条流竞争带宽,分别为5条TCP Reno流和5条LEDBAT流,拓扑如图1所示.
图2显示的是LEDBAT与标准TCP流竞争瓶颈带宽时,LEDBAT与标准TCP的吞吐量变化.本实验选用的标准TCP是Reno,队列管理算法为DropTail.由图2可知,LEDBAT在与Reno竞争带宽时不会积极抢占带宽,反而降低自己的发送速率,其目标是充分利用剩余带宽,同时保持低优先级的特性.

Fig.1 Dumbbell experimental topology图1 哑铃型实验拓扑
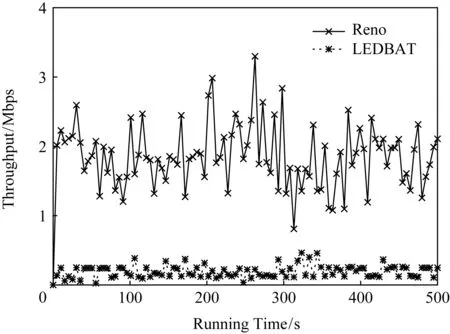
Fig.2 Throughput of LEDBAT and Reno in the link without AQM deployed图2 未部署AQM的链路中LEDBAT与Reno的吞吐量
为了验证LEDBAT与AQM相互作用而导致的优先级反转问题,本文进行的实验拓扑如图1所示,队列管理算法设置为RED.实验结果如图3所示,与图2相比,LEDBAT的吞吐量明显上升了,且具有与Reno一样的侵略性.由图2可知,LEDBAT能保持较低吞吐量,而不影响标准TCP的性能.在图3中,RED算法计算的平均队列长度超过特定阈值并按概率进行丢包,标准TCP减小其发送速率导致排队时延减小,LEDBAT随之增加其拥塞窗口的值,吞吐量上升,从而影响了标准TCP的性能.
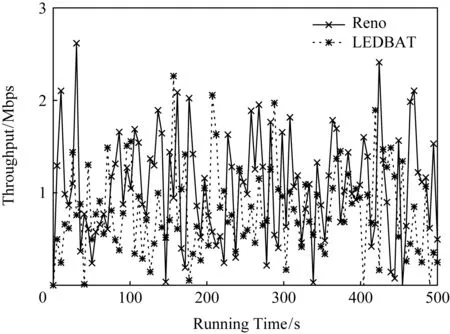
Fig.3 Throughput of LEDBAT and Reno in the link with AQM deployed图3 部署了AQM的链路中的LEDBAT与Reno的吞吐量
表1展示了LPCC与AQM相互作用的结果,PTCP是指链路中标准TCP所占的份额,Qavg表示平均队列长度.可以看出,AQM显著减小了平均队列长度,减小了排队时延,解决了“Bufferbloat”问题.以LEDBAT为例,相比于DropTail算法,部署了RED的链路中的PTCP减少了38.35%,部署了DRR的链路中的PTCP减少了42.42%.这表明部署了AQM之后,LPCC具有与标准TCP相同的侵略性.在减小排队时延方面,相比于部署了DropTail的链路的Qavg,部署了RED的链路的Qavg减少了86.94%,部署了DRR的链路的Qavg减少了57.54%.
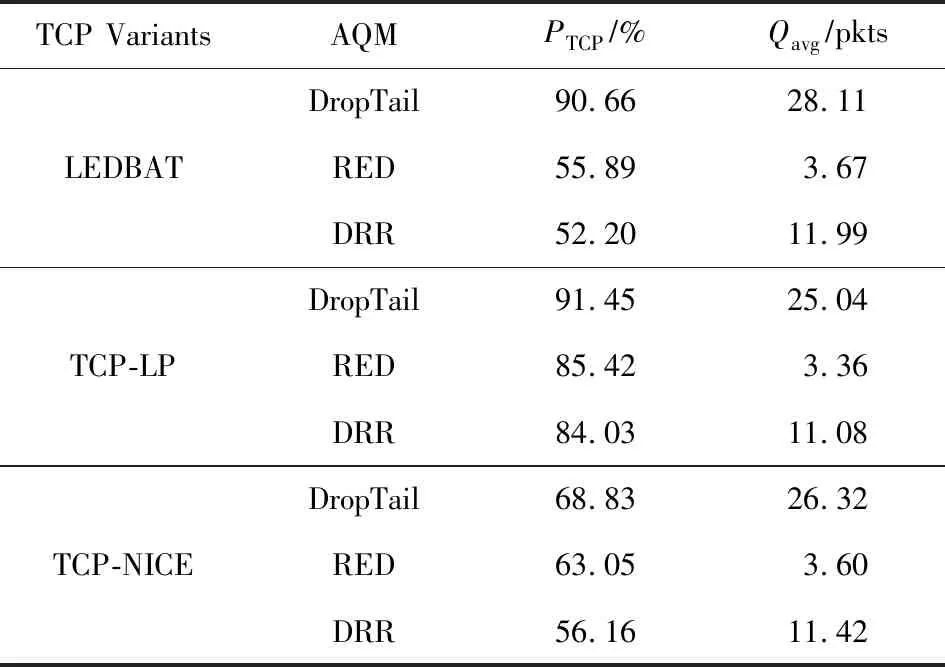
Table 1 Results of Interaction Between LPCC and AQM表1 LPCC与AQM相互作用的结果
Notes:PTCPis the share of standard TCP in the bottleneck link;Qavgis average queue size.
以上实验表明,AQM虽能有效减小队列长度和排队时延,但也导致LPCC优先级反转.
为了验证target值对优先级反转问题的影响,本文根据图1所示的网络拓扑评价了不同target值的LEDBAT算法,标准TCP为Reno,AQM设置为RED.不同target值的LEDBAT以及相应的Reno的平均吞吐量如图4所示.
图4展示了4种不同target值的LEDBAT算法与Reno算法在部署AQM的瓶颈链路中竞争带宽时的平均吞吐量.为避免实验数据的偶然性,每次实验重复运行10次,并根据实验数据得到图4所示的箱线图.由图4可知,Reno的平均吞吐量大于LEDBAT的平均吞吐量.但随着target值的不断增大,Reno与LEDBAT的平均吞吐量开始不断靠近.相比target=1时,target=25时LEDBAT的平均吞吐量与Reno平均吞吐量更加接近.这是由于当target值较小时,LEDBAT要求更小的排队时延,故即使Reno由于丢包减小发送速率,LEDBAT不会增加其发送速率.故在相同网络场景中,target值较高的LEDBAT算法较容易发生优先级反转问题.
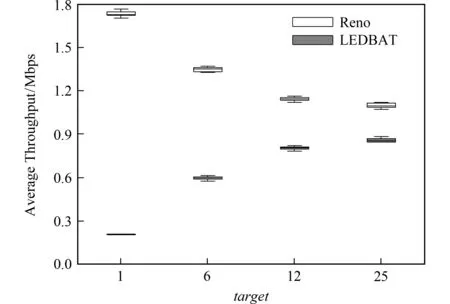
Fig.4 Average throughput of LEDBAT and Reno under different target图4 不同target下LEDBAT以及Reno的平均吞吐量
由实验可知,LEDBAT与AQM共存时,AQM在解决“Bufferbloat”的同时,改变了LEDBAT的低优先级性,也损害了标准TCP的性能.而LEDBAT中target值能够影响优先级反转的程度.
2 启发式动态阈值算法
2.1 基本思想
第1节中详细介绍了LEDBAT与AQM共存时产生的优先级反转问题以及产生原因,并分析了解决优先级反转问题的关键.与其他LPCC不同,本文提出的HDT能感知网络状态,可根据网络状态对target进行动态调整.其目的是能保证:1)在与其他TCP竞争带宽时,HDT算法在部署了AQM的链路中保持其低优先级性;2)当链路中无其他数据流时,HDT能保证在低排队时延的情况下,尽量利用链路带宽.通过上述分析,如何根据网络状态动态调整target值是HDT的重点和难点.
2.2 HDT算法设计与实现
HDT首先要获取中间节点的信息,例如是否部署AQM等.从图2和图3可看到,相比于没有部署AQM的链路,在部署AQM的链路中,LEDBAT流的吞吐量急剧上升.故周期性地计算HDT流的吞吐量可解决这一问题.HDT算法设置的周期为4个往返时延(round-trip time, RTT),并且只计算周期中最后一个RTT的吞吐量,认为经历了3个RTT后,前一个周期调整过的target已经起作用且每个周期最后一个RTT的吞吐量可以代表调整过后的效果.HDT在每个周期最后一个RTT计算出的吞吐量为Tc,计算为
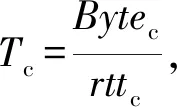
(2)
其中,Bytec为当前周期中最后一个RTT收到确认的字节数,rttc为每个周期的最后一个RTT.
HDT算法设置了一个吞吐量阈值Tmax,当Tc大于吞吐量阈值Tmax时,就认为当前链路中部署了AQM,需减小target值,这时使用启发式搜索算法来搜索最优的target值.由于可能的target值存在上界与下界以及明显次序关系,且二分搜索算法效率较高,能够较快找到最合适的target值.故HDT算法使用二分搜索算法查找最优的target值.
HDT算法定义了最大target值——targetmax,最小target值——targetmin.在[targetmin,targetmax]中通过二分查找来查找最优的target值,其计算式为
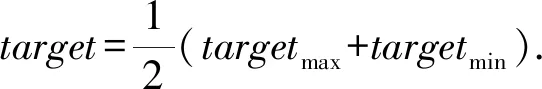
(3)
然而,如果链路中没有与HDT流竞争带宽的数据流时,这时HDT的吞吐量也会超过定义的吞吐量阈值Tmax.通过分析可知,导致HDT吞吐量过高有2种情况:1)部署了AQM的链路;2)HDT单独存在.因为无法区分是哪种情况导致的吞吐量过大,就盲目降低target值会导致HDT无法在单独存在时尽量利用带宽.
这2种情况下提高吞吐量的方式是不同的.当无其他数据流与HDT流竞争带宽时,HDT可在保持低时延情况下保证带宽利用率,故可通过往返时延来对区分2种情况.HDT设置了区别以上2种情况的RTT阈值rttmax,并根据rttmax更新target的值:

(4)
HDT算法流程如图5所示.首先收集周期中最后一个RTT的吞吐量和时延,并根据收集到的数据判断是否更新target,若更新,则使用二分搜索找到合适的target,否则保持不变.
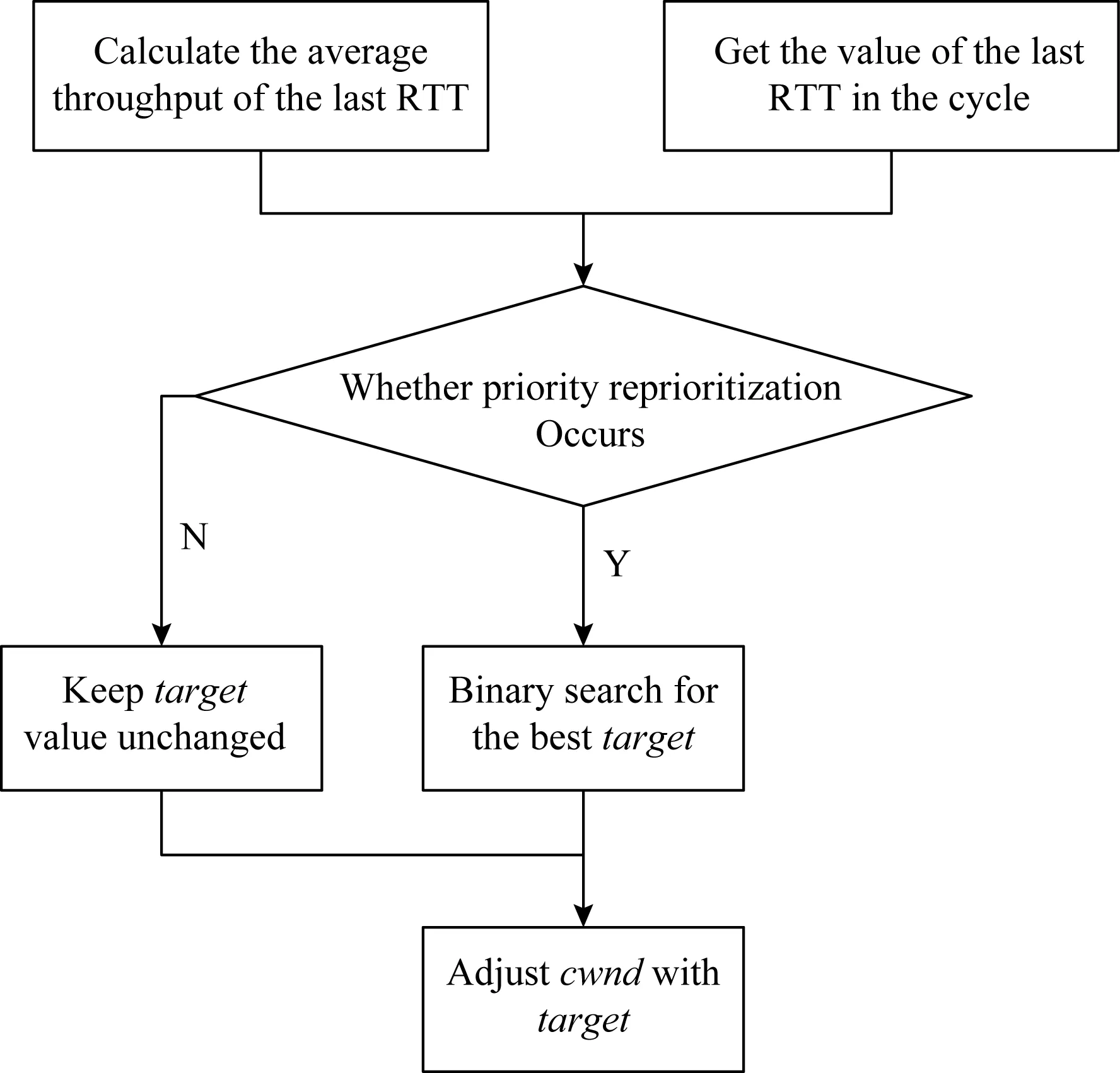
Fig.5 HDT algorithm flow chart图5 HDT算法流程图
HDT核心的具体实现如算法2所示:
算法2.HDT算法.
输入:targett,Tmax,rttmax;
输出:targett.
interval=0;targetmin=0;targetmax=50;
IFinterval==4 THEN
rttc=acknowledgement.delay;
Tc=Bytec/rttc;
IFTc>TmaxTHEN
IFrttc>rttmax
interval=0;
END IF
ELSE
interval++;
END IF
END IF
3 实验和结果
本节采用NS2对HDT的性能进行评估.首先介绍了实验设置及评价指标,然后分析了不同AQM对HDT的影响,最后分析讨论了不同类型拥塞控制算法对HDT的影响.
3.1 实验设置及评价指标
本节的拓扑结构如无特别说明均如图1所示,即5条标准TCP流与5条LPCC流竞争带宽.
本节实验均选择Reno算法与HDT竞争带宽.这是由于Reno是基于丢包的算法,使用经典的AIMD机制,即加性增和乘性减.Reno以丢包作为拥塞信号,仅在发生丢包时才进行减窗操作.故在未部署AQM的情况下,当LPCC流与Reno流竞争带宽时,LPCC流可保持其低优先级性,作为背景流存在.而当链路部署AQM时,优先级反转现象较明显,故选择Reno算法.
本节实验的默认参数如表2所示.瓶颈链路容量为以太网的最初的带宽10 Mbps,往返时延设置为50 ms,故缓冲区容量大于2BDP,即100个包.

Table 2 Experimental Default Parameters表2 实验默认参数
评价指标包括平均吞吐量、PTCP以及Qavg.其中,平均吞吐量为n条流吞吐量的均值,可计算为
(5)
其中,Ti为第i条流的吞吐量,n表示流的数量.
3.2 AQM对HDT的影响
本节主要对HDT算法在不同AQM以及不同场景下的性能进行评估.
3.2.1 HDT与标准TCP竞争带宽
实验拓扑为图1所示的哑铃型拓扑结构.这里选择的对比算法为LEDBAT,TCP-LP,TCP-NICE.图6表示不同AQM下LEDBAT,HDT,TCP-LP,TCP-NICE的平均吞吐量.
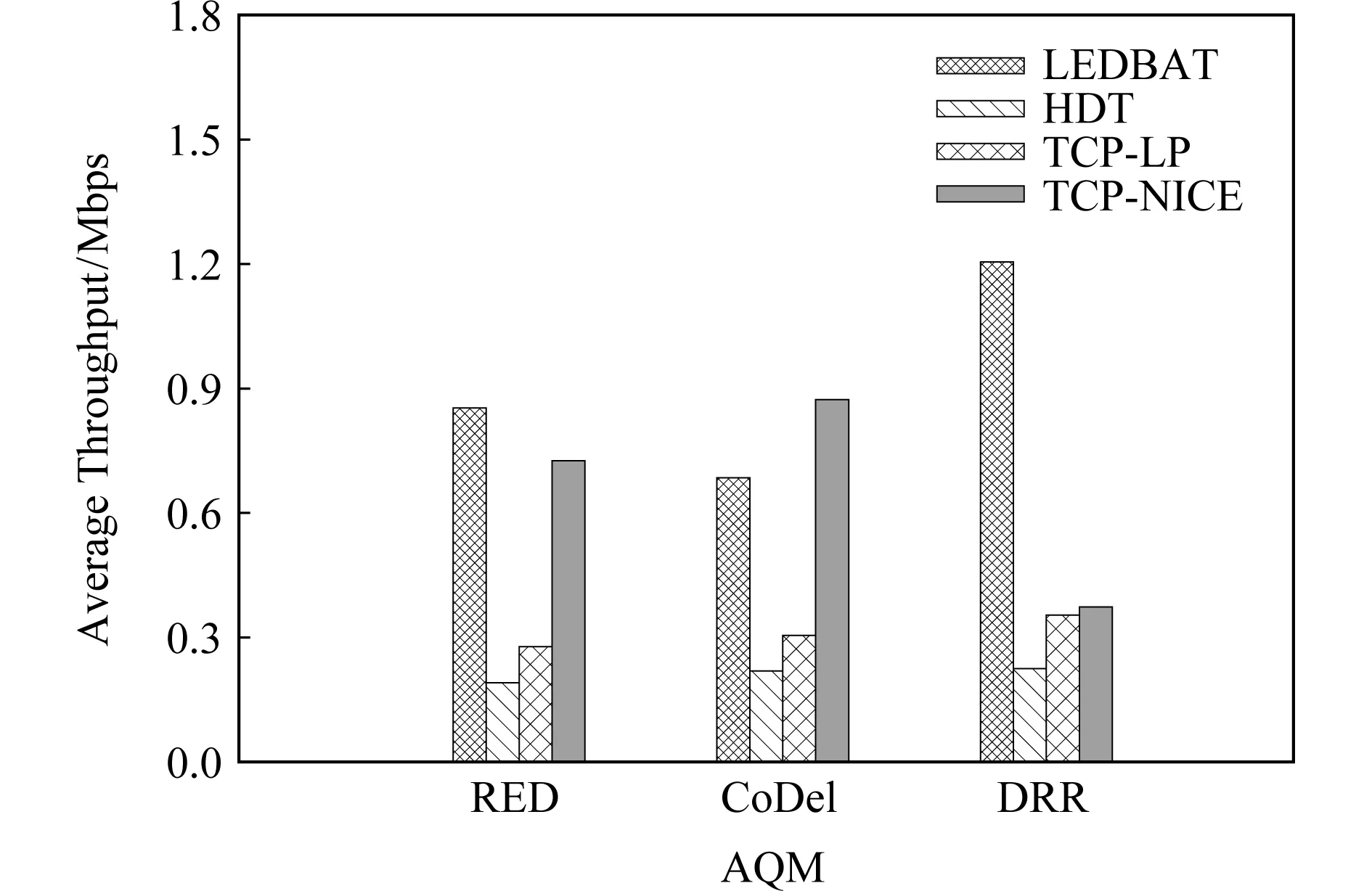
Fig.6 Average throughput when LPCCs compete with standard TCP for different AQMs图6 不同AQM下LPCC与标准TCP竞争带宽时的平均吞吐量
由图6可知,AQM对LEDBAT以及TCP-NICE的影响较大,而本文提出的HDT以及TCP-LP能在不同AQM下表现较为平稳,且能够较好地保持低优先级的特性.LEDBAT算法在不同AQM下都保持较高的平均吞吐量.RED下的LEDBAT已发生了优先级反转的问题,其平均吞吐量比HDT算法的平均吞吐量提高了346.6%,说明HDT算法中对于target值的动态调整有效解决了低优先级流的优先级反转问题.
不同AQM下HDT算法中的PTCP以及Qavg如表3所示.不同AQM下HDT算法与标准TCP竞争带宽时,标准TCP所占的份额尽在85%以上.这表明HDT算法能够有效让出带宽,保持低优先级性.
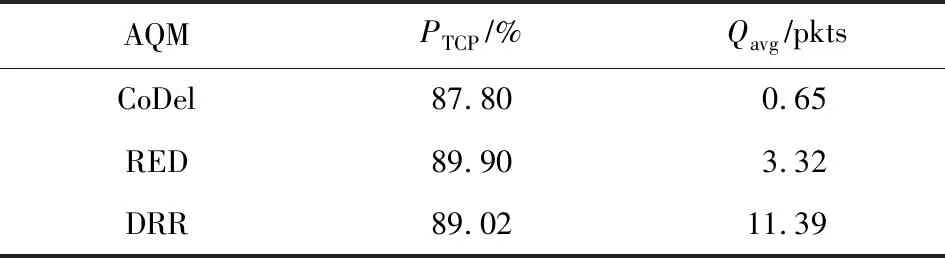
Table 3 PTCP and Qavg of Different AQM for HDT Algorithm表3 HDT算法在不同AQM时的PTCP以及Qavg
Notes:PTCPis the share of standard TCP in the bottleneck link;Qavgis average queue size.
3.2.2 HDT单独存在链路中
本节的实验拓扑如图7所示,HDT以单条流的形式存在于链路中,无其他流与其竞争带宽.本节选择的对比算法仍为LEDBAT,TCP-LP,TCP-NICE.

Fig.7 Single stream experimental topology图7 单条流实验拓扑图
图8展示了在单条流的情况下AQM对不同LPCC的影响.可以看出,在不同AQM下,HDT都表现了较高的平均吞吐量,表明HDT在单独存在时能充分利用带宽,实现较高吞吐量.虽然TCP-LP能在与标准TCP竞争带宽时表现出较稳定的低优先级性,但其单独存在时却不能充分利用链路带宽.并且相比于HDT,LEDBAT与TCP-NICE的平均吞吐量受AQM影响较大.综上所述,HDT算法单独存在链路中时,能较为稳定地充分利用带宽.
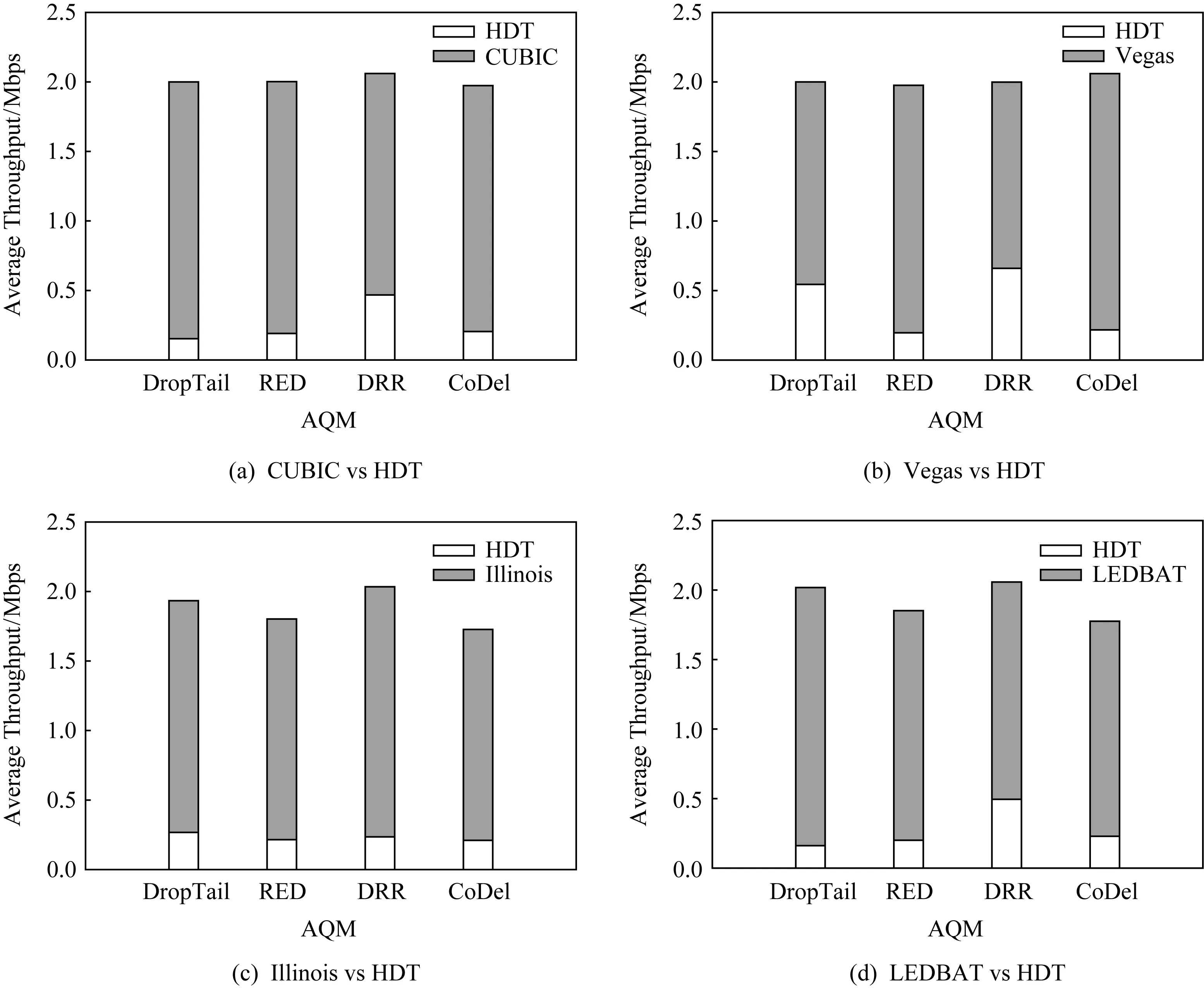
Fig.9 Average throughput of different algorithms under different AQM图9 不同AQM下不同算法的平均吞吐量

Fig.8 Average throughput when LPCCs exist separately under different AQM图8 不同AQM下LPCC单独存在时的平均吞吐量
3.3 拥塞控制算法对HDT的影响
本节选择了不同类型的拥塞控制算法,主要是评价AQM下与不同拥塞控制算法交互时HDT的性能.
这里选取了基于丢包的CUBIC、基于时延的Vegas[22]、基于混合的Illinois[23]以及低优先级的LEDBAT.实验环境仍为图1所示的哑铃型拓扑结构.仿真结果如图9所示.
图9表明,HDT算法在与不同的拥塞控制算法交互时都能够保持其低优先级的特性.在基于丢包的CUBIC以及基于混合的Illinois交互时,HDT在链路中占有带宽较小,而在与基于时延的Vegas以及低优先级的LEDBAT中,HDT占有带宽较高.这是由于Vegas与LEDBAT对时延较敏感,Vegas与LEDBAT较早感知到网络拥塞,并减小发送速率,在它们减小发送速率的同时,HDT能以较小幅度增加发送速率.
3.4 链路带宽对HDT的影响
本节主要考察不同瓶颈链路带宽对HDT算法的影响,选用RED算法为默认的AQM算法,对比的拥塞控制算法为LEDBAT,TCP-LP,TCP-NICE.
这里选择的瓶颈链路带宽分别为0.5 Mbps,1 Mbps,2 Mbps,5 Mbps,10 Mbps.低优先级流的平均吞吐量如图10所示:

Fig.10 Average throughput of LPCCs under different link bandwidths图10 不同链路带宽下LPCC的平均吞吐量
可以看出,HDT算法能在不同链路带宽中以较低吞吐量存在,不对标准TCP产生影响,利用剩余带宽.在链路容量较低时(0.5 Mbps),4种LPCC算法的平均吞吐量大致相同,但当链路容量增大时,不同LPCC算法的优先级反转的程度不同.当链路容量为5 Mbps时,LEDBAT,TCP-LP,TCP-NICE的平均吞吐量分别是HDT的2.57倍、1.64倍及2.44倍,即在相同条件下,LEDBAT与TCP-NICE以较强的侵略性占据了更多的带宽资源,并影响了标准TCP的性能,而HDT在不同的链路容量下均保持了低优先级的特性.
4 总结与未来工作展望
本文针对LEDBAT与RED,分析了优先级反转问题并进行了实验验证.针对此问题,提出了HDT算法,使用启发式算法动态调整target值来感知网络链路状态,从而保持低优先级.通过一系列的实验分析评价了HDT算法的性能,即HDT能实现2个目标:1)在部署了AQM的链路中,HDT流与标准TCP流竞争带宽时,能保持其低优先级性,让出带宽;2)无其他数据流竞争带宽时,HDT会在保持低时延的情况下利用带宽.HDT算法能够在不同的AQM算法以及不同类型的拥塞控制算法下保持其低优先级性.
本文算法存在2个可调参数,需要静态按照网络状况进行配置,故下一步工作将考虑继续完善算法,对参数进行自适应控制,对理论模型进行进一步的优化,使其能够适应更多的网络状态.另外,将完善后的HDT算法部署在发送端,在真实的网络环境下对其性能进行充分的评价,并且增加不同的网络环境以及最新的TCP拥塞控制协议.
