特征工程和深度前馈网络结合的刀具磨损预测
2020-06-20张超标孙延明
张超标,孙延明
(1.华南理工大学工商管理学院,广东 广州 510641;2.广州大学工商管理学院,广东 广州 510006)
1 引言
机械加工过程大多数是切削加工过程,刀具的磨损对该过程有重要的影响,当刀具磨损至报废状态却未停止加工过程时,会破坏加工工件,甚至会损坏机床,刀具是加工过程的重要资源。传统的固定换刀模式已经逐步演变成根据预测的刀具磨损进行换刀的模式,然而预测磨损值或高或低,当预测的刀具磨损值过高则可能出现刀具利用率低的情况,当预测的刀具磨损值过低则可能出现加工质量差的情况。能更精确地预测加工过程中刀具的磨损,不仅能提高刀具利用率和加工质量,还能减少刀具带来的直接成本和间接成本,此外,能减少安全事故和降低停机率。目前,刀具磨损预测的研究主要是基于数据驱动的方法研究,其中主流的是特征工程和机器学习方法结合的研究,这方面的研究有:文献[1]在特征提取和特征选择的基础上,提出一种多线性模型融合的方法,改进了单个线性模型低准确率的缺陷;文献[2]遵循标准的特征工程步骤提取与刀具磨损相关的特征,在此基础上从多个实验验证了AdaBoost集成的回归树的准确性和适应性比单回归树更强。文献[3]通过特征提取和利用广义回归神经网络强大的学习能力,对刀具磨损预测偏差进行了修正。这些研究虽然在预测准确性和可靠性上已经很高,但仍存在三方面的局限性:(1)对主轴电流、振动信号、切削力信号等监测信号进行特征提取的过程中,仅依据专家的领域知识提取出只适用于某一种刀具相关的特征,无法应用于更多种类的刀具;(2)特征选择的过程主要是假设检验,但此过程中错误发现率(False Discovery Rate,FDR)缺乏有效的控制,选择出来的特征与目标磨损相关性不高;(3)对磨损的预测是对某一时间段的附加磨损量的预测,现有研究多数缺乏附加磨损量非负的约束。因此在其他研究的基础上,提出了一个新的改进传统特征工程和Dropout深度前馈网络结合的框架。
2 刀具磨损预测
刀具磨损量预测的整体框架,如图1所示。离线训练过程使用历史监测数据,提取并选择特征,所选特征用于优化Dropout深度前馈网络的参数。在线预测过程在训练好的模型基础上,对实时监测数据计算模型输入特征,计算当前刀具磨损量并进行评估。因在线预测过程依赖于在线预测过程,故整个框架的核心是离散训练过程,本节将详细介绍该过程。
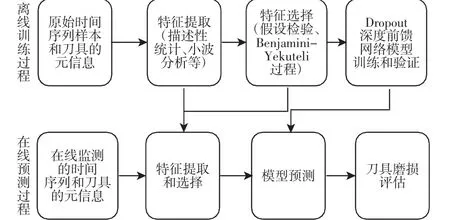
图1 刀具磨损预测整体框架Fig.1 The Overall Framework of Tool Wear Prognostic
2.1 刀具状态监测和特征提取
基于数据驱动的刀具磨损预测是基于监测刀具磨损相关的传感器信号的刀具状态监测(Tool Condition Monitoring,TCM)框架,研究中所用的传感器信号有切削力、振动、声波/超声波、声发射、温度、主轴转速/电流/功率、表面粗糙度、位移等[4],出于成本和工程的考虑,在此使用切削力、振动和声发射测量传感器信号。
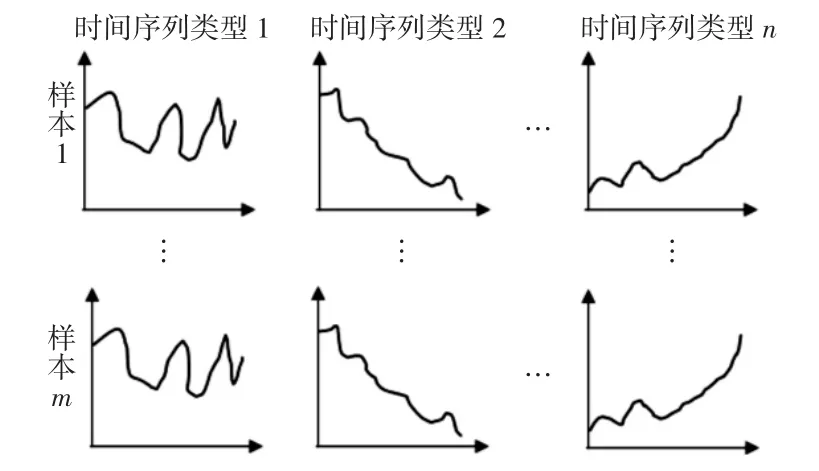
图2 包含多种时间序列类型的多个样本Fig.2 Multiple Samples with Multiple Time Series Types
刀具状态监测下的某一特定时间段内采集到的不同传感器信号可以视为一个包含不同时间序列类型的样本,每种时间序列类型对应一种传感器信号,如图2所示。对于样本i(i=1,2,…,m)和时间序列类型j(j=1,2,…,n),有时间序列:
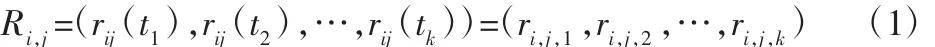
式中:tl+1=tl+Δt(l=1,2,…,k)。

该映射刻画了时间序列的一个属性,例如,关于样本i和时间序列类型j的平均值映射是:

对每种时间序列类型应用多个这种类型的映射便提取出了关于该时间序列的特征,如果每种时间序列都是提取出p种特征,且刀具的元信息(即刀具的材质、刀具直径等属性)有q种特征,那么最终提取出u=pn+q种特征。
现有研究提取的是与自身领域知识相关的一些专有特征,这种方法仅适用于特定的加工环境,当加工环境(工件、刀具种类等)变化时提取的特征并不一定有效,更好的方法是提取更全面的特征。文献[5]从时间序列中提取数千种特征解决时间序列分类问题。文献[6]提出TSFRESH收集不同领域的特征用于改进特征工程。此处对每种时间序列类型应用前述映射各提取794种特征。
2.2 特征选择
经过特征提取步骤得到的特征为X1,X2,…,Xu,而目标变量即刀具磨损变量为Y。传统的特征选择过程是为每个特征Xj实行统计检验检查如下的零假设和备择假设:

由于目标变量Y是连续变量,当Xj是二元特征时,可以通过Kolmogorov-Smirnov检验计算p值[7];当Xj是离散特征或者连续特征时,则可以采用Kendall等级检验来计算p值[8]。比较选定的显著性水平与p值来确定Xj与Y是否统计独立。然而,这种方法存在缺陷,如果Xj是被错误选择的特征,说明应该被接受却被拒绝,犯这种错误的概率会随着被检验的假设数量增加而变大,多重检验中错误拒绝在所有拒绝中的期望占比称为错误发现率[8]。错误发现率可以通过Benjamini-Yakutieli过程进行有效控制,且该方法已经在解决二类分类问题和回归问题上的有效性得到了验证[6]。Benjamini-Yakutieli过程如下:

2.3 Dropout深度前馈网络预测模型
常见的预测模型在面对庞大、高维的数据集时存在泛化能力不足的问题,且未考虑非负约束。为此引入了Dropout深度前馈网络预测模型,Dropout深度前馈网络是一种特殊的深度前馈网络,采用Dropout学习算法对模型进行训练[10]。Dropout指的是在标准深度网络的训练过程中,临时性地删除隐藏单元和输入单元,同时删除与这些单元的连接,如图3所示。(a)为包含2层隐藏层的标准深度前馈网络,(b)为Dropout操作后的子深度前馈网络,(b)中带叉号的单元表示从(a)中删除的单元,与其连接的边也被删除了。考虑一个包含L层隐藏层的深度前馈网络,l∈{1,…,L}表示隐藏层的索引,l=0表示输入层的索引,l=L+1表示输出层的索引,由于任务是预测刀具的磨损,输出层仅包含一个单元。令 z(l)表示第 l层的输入向量,y(l)表示第 l层的输出向量,W(l)和b(l)分别是第l层和第l-1层之间的权值矩阵和偏置向量,此外有,y(0)=z(0)=x。对于 l∈{0,1,…,L},标准的深度前馈网络的前馈计算如下:

式中:f—单元的激活函数,考虑到前述的非负约束,对于所有的隐藏层单元和输出层单元,激活函数采用现代多数深度网络使用的整流线性函数(Rectified Linear Unit,ReLU):

这样就确保了网络输出值的非负性,同时能使训练速度更快。
对于 l∈{0,1,…,L},存在 dropout的前馈计算如下:

式中:v(l)—每个元素都为一个服从伯努利分布的随机变量的向量,每个元素等于 1的概率为 p,当=0时表示第l层的第i个单元被丢弃,反之则被保留。
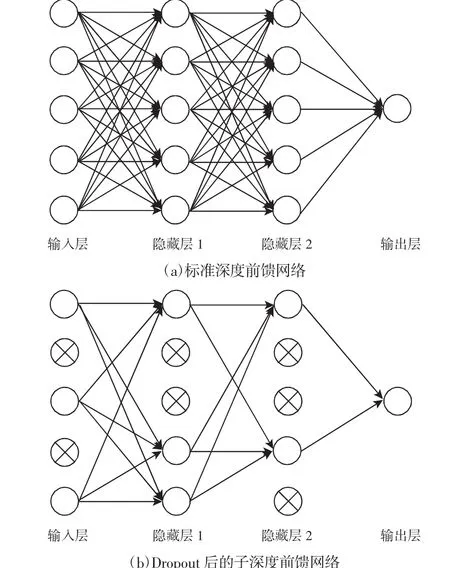
图3 标准深度前馈网络和Dropout后的子深度前馈网络Fig.3 Standard Deep Feedforward Network and Sub Deep Feedforward Network After Dropout
Dropout深度前馈网络的训练过程类似于标准深度前馈网络使用随机梯度下降的训练过程,区别在于,对于每个小批量的每个训练样本,通过Dropout操作来产生标准深度前馈网络的一个子网络,所有的子网络共享权值,该样本的前馈计算过程如前所述,反向传播过程仅对存留的单元间的权值矩阵和偏置向量进行更新,而被删除的边关联的权值和偏置则保留不变,更新后的权值和偏置用于下个训练样本的更新。Dropout深度前馈网络训练完成后,训练过程最后的权值矩阵和偏置向量被代入原来的深度前馈网络,同时对权值矩阵和偏置向量进行缩放:测试时使用的网络是未做任何Dropout操作的深度前馈网络,其权值矩阵和偏置向量为

3 实验分析
实验使用的数据集是PHM社区的高速数控铣刀磨损数据集,实验环境为主轴转速10400RPM,进给速度1555mm/min,包含3个训练集c1,c4,c6和3个测试集c2,c3,c5,每个数据集记录对应的铣刀的315次铣削过程,每次铣削都记录了X、Y、Z三个方向的切削力和振动与声发射7种不同的传感器信号,采样频率为50KHz,训练集包含了每次铣削三个不同槽flute1、flute2、flute3切削后的当前磨损值(单位:10-3mm),而测试集则不包含。由于只有训练集包含磨损值,选取训练集c1,c4,c6作为实验数据集,且只考虑第一个槽flute1的磨损,同时三个数据集删除第一个样本,然后计算每个样本和前一个样本之间的附加磨损来作为预测目标,此外将磨损值的单位转化为10-6mm避免预测目标值过小。由于采样频率为50kHz,(314×3)个样本中的每个样本都包含20几万条不同时间点下的记录,使用了1.25kHz的采样频率对数据集进行了重采样,重采样后每个样本仍包含5000条不同时间点下的记录。如前文所述,对7种不同的传感器信号,分别提取时域特征、频域特征、时频域特征等794种特征,提取的特征数量总共794×7=5558个特征。
特征提取后数据集大小为(942×5559),即样本量为942,前5558列为提取的特征,最后一列为磨损值。对数据集按行进行随机打乱操作,并划分成大小为(753×5559)的训练集和(189×5559)的测试集。特征选择和预测模型训练及验证均在训练集上实验。特征选择如前文所述,多次实验后FDR水平取q=0.05,实施Benjamini-Yakutieli过程后,有595个特征始终为常量,余下的4963个特征按p值排序后,如图4所示。分隔线左侧的1832个相关的特征被选择出来。特征选择后训练集和测试集大小分别为(753×1832)和(189×1832)。
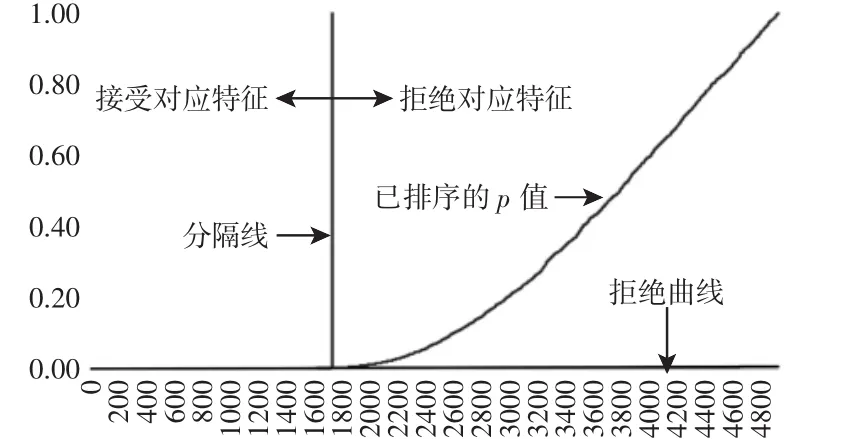
图4 Benjamini-Yakutieli过程Fig.4 Benjamini-Yakutieli Procedure
为了验证Dropout深度前馈网络预测模型的性能,首先比较标准深度前馈网络和Dropout深度前馈网络在该数据集上的性能。由于训练数据集样本数量仅为753,因此选择对比的网络结构只包含输入层、两层隐藏层和输出层,实际应用中可以选择更深的网络,通过训练集划分出来的验证集选择最佳的隐藏层数量,两层隐藏层均为128,两种网络均在训练集上进行20次的4折交叉验证,每一折进行500轮的训练,对20次的训练误差和验证误差取平均值,结果如图5所示。(a)为两种网络在训练集上的平均绝对误差,标准深度前馈网络在第50轮时训练平均绝对误差达到最小,此后模型开始出现发散的现象,而Dropout深度前馈网络在第62轮时训练平均绝对误差达到最小,该轮之后模型也比较稳定,此外,标准深度前馈网络的训练误差比Dropout深度前馈网络小,可以得出结论,Dropout深度前馈网络的训练过程比深度前馈网络稳定,同时,Dropout深度前馈网络不易产生过拟合现象。观察图5(b)可知,标准深度前馈网络在第59轮时验证平均绝对误差达到最小,此后开始产生过拟合现象,而Dropout深度前馈网络在第36轮时验证平均绝对误差达到最小,此后开始产生过拟合现象,整体上标准深度前馈网络的验证误差要高于Dropout深度前馈网络,进一步说明Dropout深度前馈网络泛化性能更好。

图5 训练平均绝对误差和验证平均绝对误差Fig.5 Training Mean Absolute Error and Validation Mean Absolute Error
接着,对标准深度前馈网络使用整个训练集训练59轮,而对Dropout深度前馈网络训练36轮,在测试集上对两种网络计算均方误差和平均绝对误差,标准深度前馈网络的测试均方误差和平均绝对误差为33883.145和111.863,而Dropout深度前馈网络的测试均方误差和平均绝对误差为19475.918和81.632,在测试集上Dropout深度前馈网络的性能优于标准深度前馈网络。

表1 20次5折交叉验证结果对比Tab.1 Comparison of Twenty 5-Fold Cross-Validation Results
最后,实验将提出的预测模型与其他已提出的预测模型进行了比较,以文献[2]中的模型作为参照模型,对提出的Dropout深度前馈网络,在整个数据集上进行了20次重复5折交叉验证,网络结构的选择如前所述,计算平均R2和平均均方误差,结果如表1所示。提出的预测模型在两项性能评估指标上均优于文献[2]中的两种模型。
4 结论
为精确预测刀具磨损,提出了特征工程和Dropout深度前馈网络结合的刀具磨损预测框架,随后的实验结果表明,一方面,Dropout深度前馈网络的训练过程比标准深度前馈网络的稳定性高,而且能解决过拟合的问题,泛化性能更好,另一方面,与应用传统特征工程和回归树/提升回归树的模型相比,提出的预测框架提取和选择的特征与目标磨损的相关性更高,说明了提取和选择的变量可解释性更强,而且预测精度也更高。
