基于深层神经网络的猪声音分类
2020-06-20罗顺元乔玉龙
苍 岩,罗顺元,乔玉龙
基于深层神经网络的猪声音分类
苍 岩,罗顺元,乔玉龙
(哈尔滨工程大学信息与通信工程学院,哈尔滨 150001)
猪的声音能够反映生猪的应激状态以及健康状况,同时声音信号也是最容易通过非接触方式采集到的生物特征之一。深层神经网络在图像分类研究中显示了巨大优势。谱图作为一种可视化声音时频特征显示方式,结合深层神经网络分类模型,可以提高声音信号分类的精度。现场采集不同状态的猪只声音,研究适用于深层神经网络结构的最优谱图生成方法,构建了猪只声音谱图的数据集,利用MobileNetV2网络对3种状态猪只声音进行分类识别。通过分析对比不同谱图参数以及网络宽度因子和分辨率因子,得出适用于猪只声音分类的最优模型。识别精度方面,通过与支持向量机,随机森林,梯度提升决策树、极端随机树4种模型进行对比,验证了算法的有效性,异常声音分类识别精度达到97.3%。该研究表明,猪只的异常发声与其异常行为相关,因此,对猪只的声音进行识别有助于对其进行行为监测,对建设现代化猪场具有重要意思。
信号处理;声音信号;识别;深度学习;猪只音频;梅尔倒谱系数;分类
0 引 言
生猪的声音信息是其重要体征之一,与猪的生长状态和健康状况息息相关。群养条件下,生猪呼吸系统的疾病具有一定的传染性,容易引发群体性疾病,声音特征可以直接反应呼吸系统的疾病。另外,声音也被认为是判断猪只应激状态的一个依据,猪只在运输或者屠宰的过程中,会产生应激反应。在这类情况下,特别是其他应激源特征不明显或者不易采集时,由于声音强度高,特征明显,可以作为一个应激程度的判别条件。此外,生猪的声音是一种较为容易获取的一种生物学信息,并且声音信号的采集可以与猪只保持一定距离,不会引发猪只任何应激反应,因此声音已经逐渐成为一种用于分析行为、健康和动物福利的重要方法[1]。特别是,随着无线传感器网络技术的快速发展[2-4],围绕着家畜[5-8],特别是猪只声音分析的研究逐渐增多[9-14]。
早期动物声音领域中,通常使用包络模板匹配方法识别,将待识别的动物声音,比如咳嗽声音,生成包络模板,将采集到的现场声音信号与模板进行逐一匹配,从而实现声音的分类识别[10]。然而,这种方法中存在着一定弊端,其他类型的声音也有可能在包络特征上与模板匹配,比如屠宰过程中,由于应激而产生的短促叫声与疾病引起的咳嗽声,二者包络匹配度也很高[15]。后期随着声音信号处理技术的发展,猪只声音处理方法也逐渐进步。2003年,Van Hirtum等Berckmans[9]利用模糊算法对猪只声音进行分析,数据集包含5 319条声音,正确识别率为79%。Moshou等[13]利用线性预测编码(Linear Predictive Coding,LPC)谱对生猪声音进行了处理,声音识别率为87%。2008年,Ferrari等[16]通过分析猪声音信号波形的均方根及峰值频率,发现了正常猪与患有呼吸道疾病的声音信号的差异性,从而识别出患病猪,对后续进行的养殖场多种行为状态的动物声音的差异性分析,提供了理论依据。同年,Exadaktylos等[17]对猪咳嗽的声音信号进行了功率谱密度分析,并用欧式距离衡量声音信号的相似性,通过对应的阈值设定,实现了猪咳嗽声音信号的监测。2013年,Chung等[18]通过对猪声音信号进行梅尔频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)提取,并用支持向量机分类算法对患有不同疾病的猪声音信号进行分类识别,实现了对应疾病与不同声音信号的匹配,这为养殖场猪的患病状况提供了有效参考。2016年,马辉栋等[19]用语音识别中的端点检测法进行猪咳嗽声音信号的检测,提出了用双门限检测法对猪咳嗽声音信号进行端点检测,有效提高了猪咳嗽声音信号的检测效率,有利于后期对猪咳嗽声音信号的识别。
本研究旨在通过深度学习技术实现对猪只声音分类识别,以促进福利化养殖、提升猪只的健康水平。通过对现场采集的声音进行分析,对多种类别的声音进行声音预加重、端点检测、加窗分帧后,提取猪只声音信号的多种特征参数,通过分析研究猪只声音信号的谱图特征,探究适用于深层神经网络结构的最优谱图生成方法,最终选择MobileNetV2网络模型作为试验基础模型,改进了网络原有的优化策略,并利用提取的声音特征训练分类模型,建立猪只声音识别系统,有效地识别猪只不同状态的声音。
1 试验数据采集与处理
1.1 试验数据采集
1.1.1 试验场地
本研究的试验地点在河北省承德市某试验猪场,试验猪的类型为三元母猪杜长大。数据采集时间从2017年3月至2017年6月。猪只采用群养方式饲养于1.8 m×5 m的猪栏内。在试验期间内,猪舍平均温度为22 ℃,最高温度25.4 ℃,最低温度18.6 ℃。自然光照时间从早晨7时至傍晚19时。试验设备采用吊装的方式安装于猪栏的中间位置(图1)。

图1 试验现场
1.1.2 数据采集
本研究使用的声音数据均在养殖场的实际环境下,通过使用数据采集盒、笔记本电脑等设备采集得到。采集盒内部的主要构造为ReSpeaker Core v2.0开发板(图 2a),现场声音数据传输存储方式如图2b所示。
采集数据为采样率为16 KHz的单通道音频,并以wav. 格式储存于存储设备中。为保证录音效果以及得到可靠标签的声音数据,录音过程中需要实时监测,并根据现场生猪的状态对已录的音频进行初步标记,方便后续处理。采集的基本声音类型分为正常的哼叫声、受惊吓的尖叫声、喂食前嚎叫声。其中,正常声音为生猪在无应激反应时正常哼叫状态下采集得到。喂食前的声音为饲养员在投喂饲料时,猪由于看到食物产生应激反应而发出的声音,类似嚎叫声。受惊吓的声音为生猪在打针、咬架、被追赶时发出的声音,在采集这类声音时,需要进行强烈的人为刺激,因此采集难度较前2种更大,实际采集中也最为费时。
1.1.3 数据集构建
采集盒采集的声音数据,在一段音频中可能存在多种状态下的声音、无效声音段,并且音频长短不一,因此需要进一步的进行手工打标签及批量切分操作,以构建试验所需的数据集。手工标注使用的软件为Audacity音频处理软件,操作界面如图3所示。

图2 数据采集方案
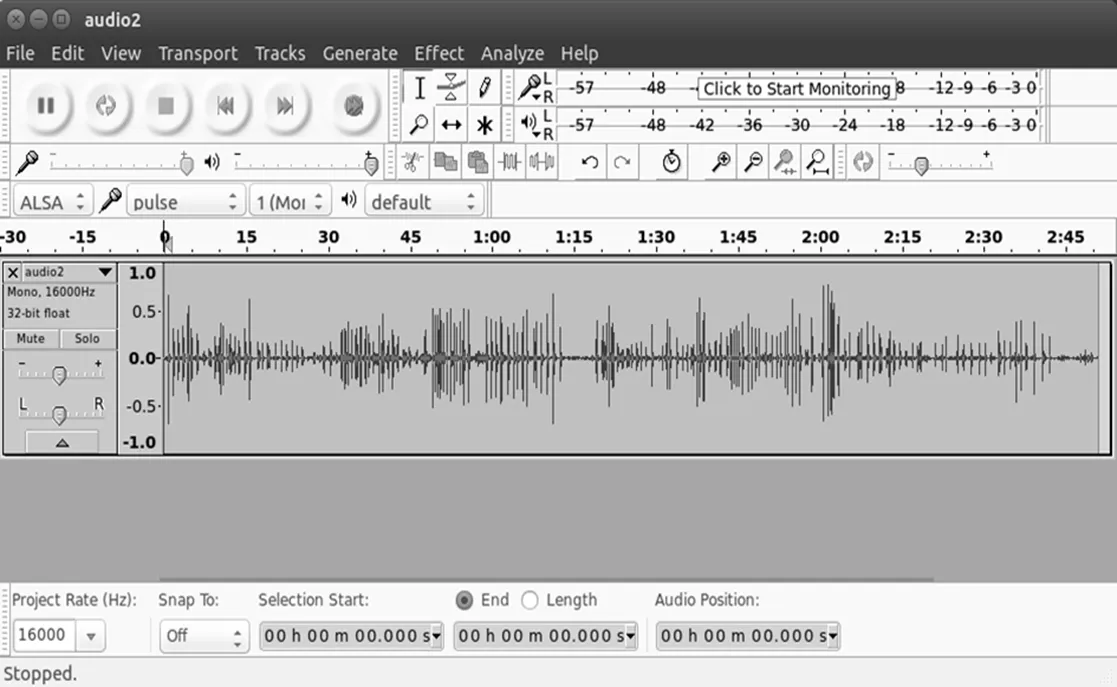
图3 Audacity操作界面
使用Audacity为音频标记后,对标签后的音频按类别进行批量切分,切分程序由Python编程实现。基于正常猪叫声的周期性(0.5~1.8 s),确定2 s为音频切分长度,即切分后的每条样本至少包含一个声音的完整周期。
制作数据库如表1所示,其列出的数据库是切分处理后的所有音频按8∶2随机分为训练集和测试集,且每类均匀分布,得到的最终试验数据库。数据库中包含正常哼叫、受惊吓、喂食前状态的声音样本,本研究主要讨论这3种声音的识别。

表1 数据库音频量分类统计
1.2 声音数据预处理
在声音信号的特征提取之前,需要先对声音信号进行预处理,这个过程对后面的特征提取、特征识别的效果都有重要的影响[20]。生猪声音信号的预处理与语音信号处理中的预处理过程相似,包括声音信号的预加重、分帧加窗、端点检测。
1.2.1 预加重
在对猪音频信号进行处理之前,为了增强声音信号的高频分量,去除发音过程中口唇辐射效应的影响,需要对音频信号进行预加重处理。预加重就是让声音信号通过一个数字滤波器,通过预加重,可以补偿猪只声音信号的高频特性[21]。滤波器的阶数为1,其传递函数如式(1)所示


1.2.2 加窗分帧



1.2.3 端点检测
由于采集到的猪音频信号中存在无效的声音片段,即有噪声段和无声段的干扰。因此需要对猪音频信号进行端点检测,确定声音的起点和终点,以改善数据质量同时为后续特征提取减少了运算量,提高了计算效率。对猪的音频信号进行端点检测,本研究借鉴了语音信号处理中效果较好的双门限检测法,利用短时过零率和短时能量进行信号分析[22]。算法计算步骤如下:



2 提取谱图特征



图4 音频波形图
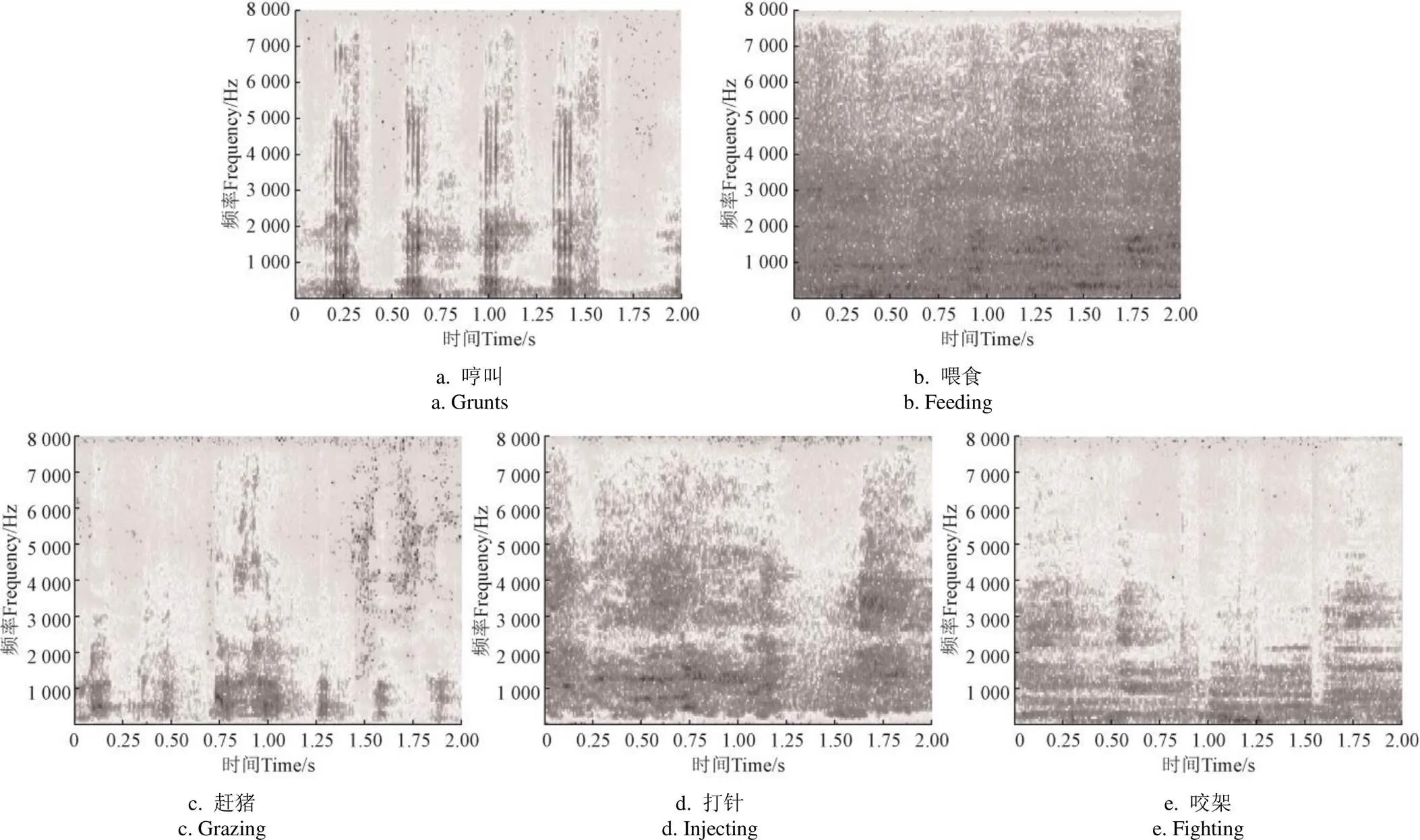
图5 音频谱图
3 分类网络的选取与优化
谱图生成后,利用图像处理领域中的深度卷积神经网络模型实现分类识别。本研究采用的MobileNetV2网络模型[26],该模型是在残差网络和MobileNetV1[24]网络模型的基础上提出的轻量级的深层神经网络,在保证准确度的同时,大幅减少乘法和加法的计算量,从而降低模型参数和内存占用,提高计算速度。MobileNetV2网络模型基本的构建块是残差瓶颈深度可分离卷积块,网络包含初始的32个卷积核的全卷积层,后接7个瓶颈层,网络中使用ReLU6作为非线性激活函数。MobileNetV2网络采用大小为3×3的卷积核,在训练时候利用丢弃(dropout)[27]和批标准化(batch normalization)技术防止过拟合。本研究中dropout取0.5。在训练开始时,随机地“删除”一般的隐层单元,保持输入层不变,更新网络的权值,依次迭代,每次迭代过程中,随机的“删除”一般隐层单元,直至训练结束。MobileNetV2网络模型的详细模型结构如表2所示。

表2 MobileNetV2 网络模型结构[26]
注:表示样本的类别数。
Note:represents the number of categories of samples.






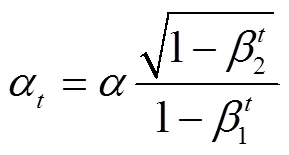

在相同数据且除优化器本身参数外其余参数相同的情况下,分别用RMSprop优化器和Adam优化器进行对比试验,其结果如图6所示。

图6 2种优化算法下模型损失函数变化
4 试验数据分析
在本研究试验中,模型训练的所用的软硬件平台如下:
CPU:Core i7-8700K
内存:16GB DDR4
GPU:NVIDIA GeForce GTX 1080Ti
系统平台:Ubuntu 16.04 LTS
软件环境:Tensorflow 1.8.0、Cuda 9.0、Cudnn 7.0、Anaconda3.
4.1 不同谱图参数试验
由于本试验的数据规模比较小,过训练的现象不会出现,因此本研究试验中数据集直接分为训练集和测试集2个部分。为确定最优的谱图参数,包括窗长和窗移参数,每次训练集和测试集以8∶2随机分配,测试不同参数生成的谱图对识别率精度的影响。每组参数都进行了5次独立试验,试验采用标准的MobileNetV2网络模型,输入图像尺寸为224×224,由试验结果可见(图 7),不同类别的谱图对模型性能有一定影响,在多次试验下发现256点FFT、1/2窗移下的谱图训练模型识别效果最好,进而将谱图类别与平均准确率绘制成折线图,如图8所示。
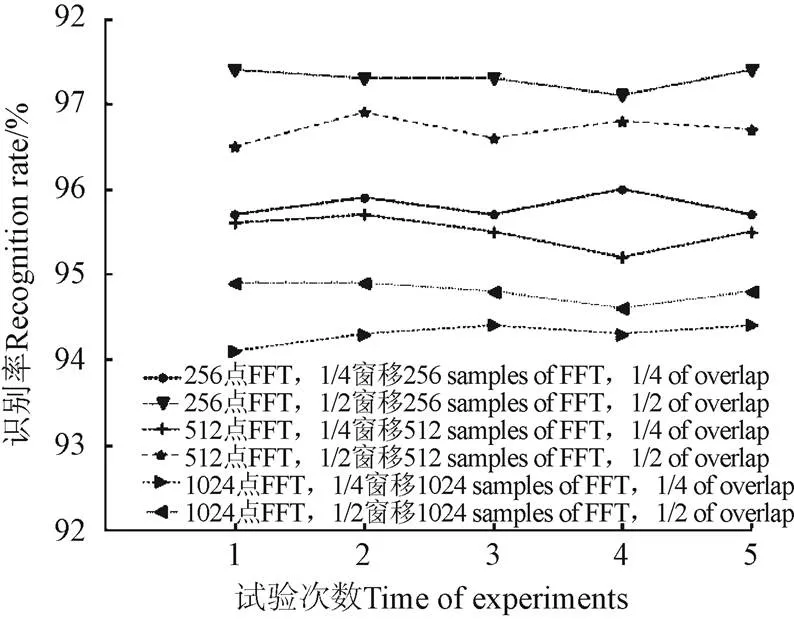
注:FFT表示信号的快速傅里叶变化,下同。

图8 各类谱图平均识别率统计图
由图8可知,相同窗长参数,1/2窗移参数的谱图训练所得模型识别率更优;相同窗移参数,256点FFT的谱图训练所得模型识别率更优,即频率分辨率较高的谱图表现更好。综上,通过谱图的优化试验,较标准MobileNetV2网络模型结果,优化后模型分类准确率提高1.8%。优化后的模型最终总体识别率为97.3%。对最优模型在测试集上各类别的识别率进行分类统计(表 3),表中测试样本数目、正确识别数目及识别率都是5次试验的平均值。
4.2 模型宽度因子和分辨率因子试验
由于未来应用场景中,猪舍声音监控模块集成在一个小型手持设备中,对硬件设备的内存和运行速度有一定的限定条件,因此在保证精度的前提下,希望获得更快更小的模型。本研究通过对宽度因子和分辨率因子的试验,在标准MobileNetV2网络模型的基础上训练定义出更小更有效的模型。

表3 测试集识别结果统计



进行分辨率因子调整后的网络计算量如式(18)所示

进行宽度因子调整前后的网络计算量之比如式(19)所示



进行宽度因子、分辨率因子调整前后的网络计算量之比如式(21)所示


不同宽度因子和分辨率因子下的试验结果如表4所示。由表中试验结果可知,网络宽度越小、谱图的分辨率越低,模型的大小越小,速度越快,同时识别率有一定损失。分析可知,在识别率损失0.5%以内时,模型运行速度可有3到4倍的提升;识别率损失1.0%以内时,模型速度可有7~10倍的提升。通过对宽度因子和分辨率因子试验,对网络结构进行调整,可求得模型速度和精度的权衡,满足适应实际应用中的需求。实际应用中,可根据应用场景的不同需求进行选择。试验结果表明,压缩后的模型,在损失很小的精度的情况下,模型大小大大减小,模型运行速度显著提升。
4.3 对比试验
选取支持向量机(Support Vector Machine,SVM)以及梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、随机森林(Random Forest,RF)、极端随机树(Extra Trees,ET)算法分别进行了猪声音数据集的训练和测试,将测试结果与本研究分类网络结果进行对比分析。
为了方便分析,测试结果以多分类混淆矩阵的形式表示(表5)。混淆矩阵中的每一列代表样本预测值,每一行代表样本的真实值,混淆矩阵可以反映出识别模型的性能。由混淆矩阵的性质可知,对角线元素为正确识别的样本,非对角线元素为错判样本。对测试集的识别结果进行统计,各算法模型下得到的混淆矩阵如下列表格所示,所有结果均取模型的最优结果进行对比。
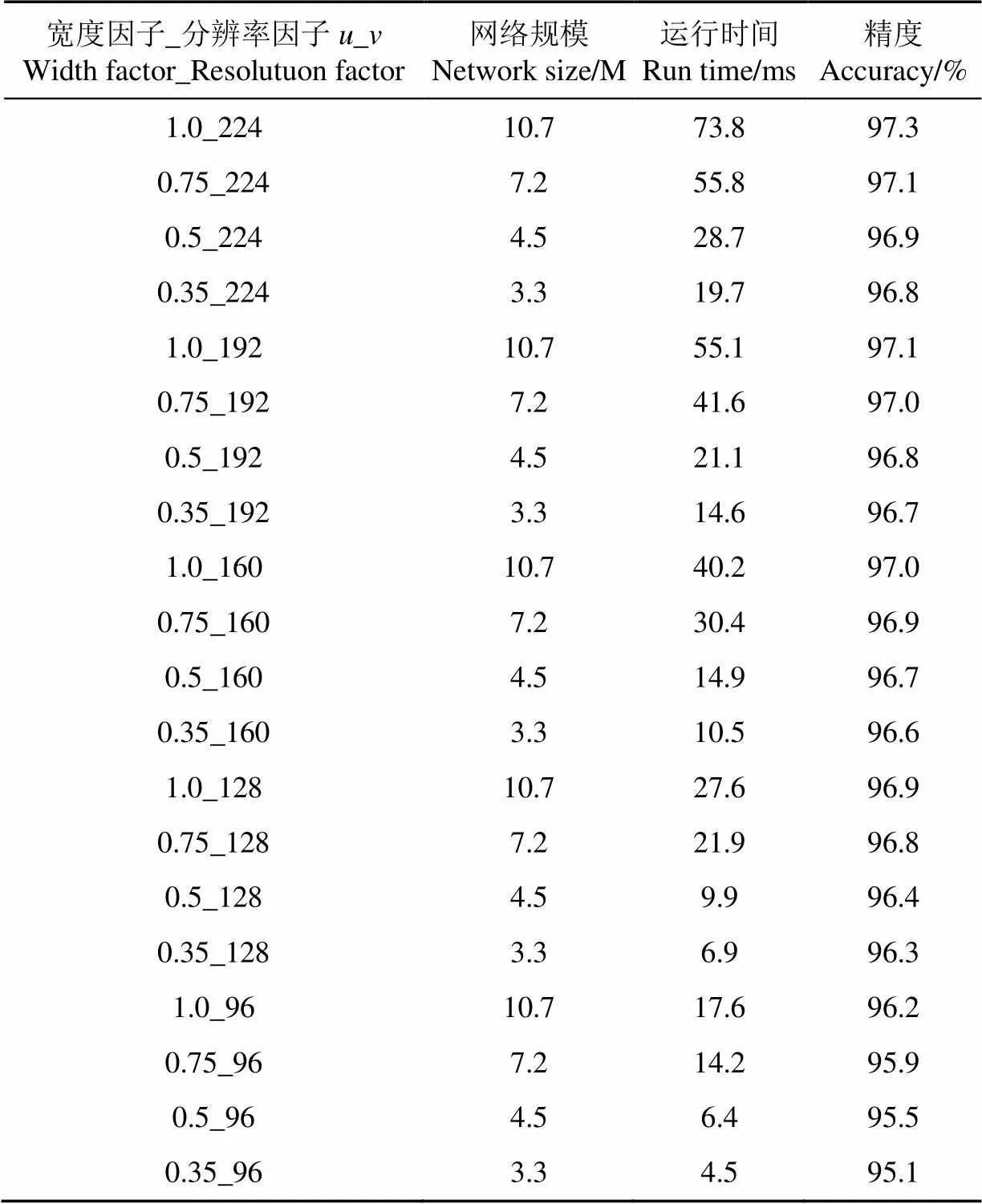
表4 不同宽度因子和分辨率因子下的试验结果统计

表5 4种算法模型下试验结果的混淆矩阵统计
通过对4种模型在测试集上的混淆矩阵进行初步分析可以看出,各个模型对正常状态的样本识别率高,而对受惊吓和喂食前状态的样本识别率较低。
通过对以上试验结果进一步分析,可以得出以下几点结论:
1)较SVM,3种集成学习算法识别率更优;
2)3类集成学习算法中,ET算法模型对猪声音识别效果最好,RF模型次之,且优于GBDT模型;
3)4种模型对不同类别声音的识别率差异明显,对正常状态的样本的识别率高,对受惊吓和喂食前状态的样本的识别率较低。
基于上述试验得出的最优MobileNetV2网络模型参数以及谱图的最优参数基础上,利用相同的数据集合,将本研究提出的网络与上述4种算法进行了识别精度的对比分析(图9)。
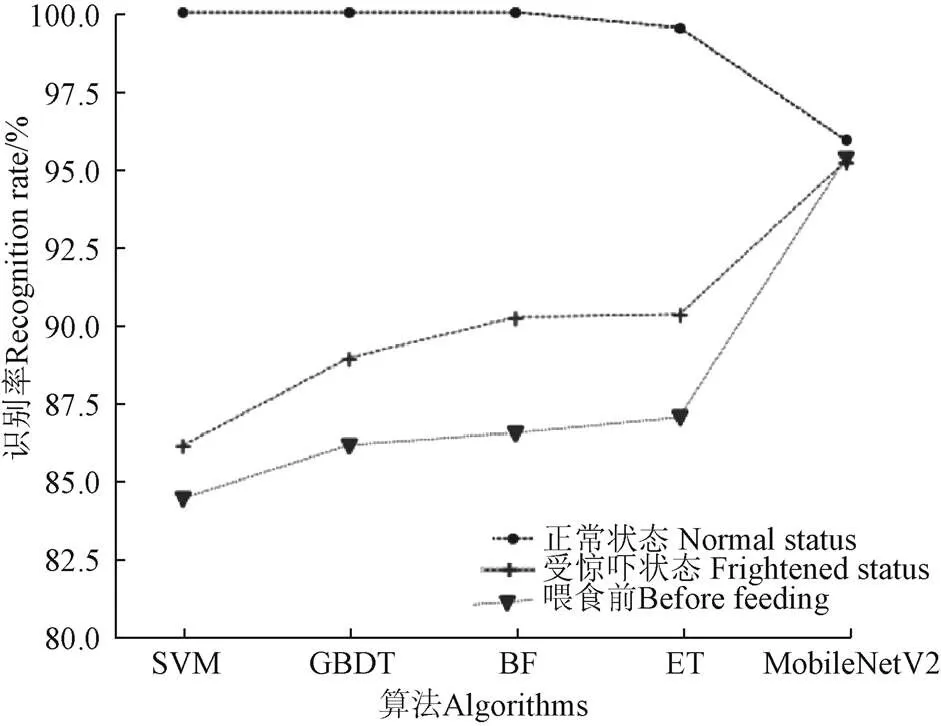
图9 各模型对测试集样本识别率分类统计图

5 结 论
针对猪只音频识别中集成学习模型和支持向量机(Support Vector Machine,SVM)模型类间识别率差异明显,对受惊吓和喂食前状态声音样本识别率较低的问题,本研究提出了深层神经网络结合谱图的识别方法,使用手工制作的数据集对模型进行了设计、实现及和优化。模型以MobileNetV2网络为基础,改进了其网络原有的优化策略,提升了模型性能。此外,本研究进一步的从谱图的生成方式以及网络结构调整这2个方面来及进行模型优化。在标准MobileNetV2网络上初步训练所得模型准确率95.5%,通过谱图优化试验,模型识别性能提升了1.8%,即最终训练得到的模型识别率为97.3%,且模型对各类别识别率都很高,克服了集成学习分类器存在的问题。进一步的,通过宽度因子和分辨率因子试验,在标准MobileNetV2模型的基础上定义了更小更有效的模型,通过损失很小精度来显著提升模型速度,满足实际应用中的需求。
[1] 黎煊,赵建,高云,等. 基于深度信念网络的猪咳嗽声识别[J]. 农业机械学报,2018,49(3):179-186. Li Xuan, Zhao Jian, Gao Yun, et al. Recognition of pig cough sound based on deep belief nets[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(3): 179-186. (in Chinese with English abstract)
[2] Gutiérrez A, González C, Jiménez-Leube J, et al. A heterogeneous wireless identification network for the localization of animals based on stochastic movements[J]. Sensors. 2009, 9(5): 3942-3957.
[3] Handcock R N, Swain D L, Bishop-Hurley G J, et al. Monitoring animal behavior and environmental interactions using wireless sensor networks, GPS collars and satellite remote sensing[J]. Sensors. 2009, 9(5): 3586-3603.
[4] Hwang J, Yoe H. Study of the ubiquitous hog farm system using wireless sensor networks for environmental monitoring and facilities control[J]. Sensors. 2010, 10(12): 10752-10777.
[5] Yeon S C, Lee H C, Chang H H, et al. Sound signature for identification of tracheal collapse and laryngeal paralysis in dogs[J]. Journal of Veterinary Medical Science. 2005, 67(1): 91-95.
[6] Jahns G, Kowalczyk W, Walter K. Sound analysis to recognize animal conditions and individuals[C]//Annual Meeting National Mastitis Council, New York, USA, 1998: 228-235.
[7] Moi M, Nääs I A, Caldara F R, et al. Vocalization as a welfare indicative for pigs subjected to stress situations[J]. Arquivo Brasileiro de Medicina Veterinária e Zootecnia, 2015, 67(3): 837-845.
[8] Mucherino A, Papajorghi P, Pardalos P. Data Mining in Agriculture[M]. New York: Springer, 2009.
[9] Van Hirtum A, Berckmans D. Fuzzy approach for improved recognition of citric acid induced piglet coughing from continuous registration[J]. Journal of Sound and Vibration, 2003, 266(3): 677-686.
[10] Moreaux B, Nemmar A, Beerens D, et al. Inhibiting effect of ammonia on citric acid-induced cough in pigs: A possible involvement of substance P[J]. Pharmacology & Toxicology. 2000, 87(6): 279-285.
[11] Chedad A, Moshou D, Aerts J M, et al. AP-animal production technology: Recognition system for pig cough based on probabilistic neural networks[J]. Journal of Agricultural Engineering Research, 2001, 79(4): 449-457.
[12] Marchant J N, Whittaker X, Broom D M. Vocalizations of the adult female domestic pig during a standard human approach test and their relationships with behavioral and heart rate measures[J]. Applied Animal Behavior Science. 2001, 72(1): 23-39.
[13] Moshou D, Chedad A, Van Hirtum A, et al. An intelligent alarm for early detection of swine epidemics based on neural networks[J]. Transactions of the American Society of Agricultural and Biological Engineers, 2001, 44(1): 167-174.
[14] Moura D J, Silva W T, Naas I A, et al. Real time computer stress monitoring of piglets using vocalization analysis[J]. Computers & Electronics in Agriculture, 2008, 64(1): 11-18.
[15] Van Compernolle D, Janssens S, Geers R, et al. Welfare monitoring of pigs by automatic speech processing[C]// Proceedings 12thCongress of the International Pig Veterinary Society. Hague, Netherlands, 1992: 570-571.
[16] Ferrari S, Silva M, Guarino M, et al. Cough sound analysis to identify respiratory infection in pigs[J]. Computers and Electronics in Agriculture, 2008, 64(2): 318-325.
[17] Exadaktylos V, Silva M, Ferrari S, et al. Real-time recognition of sick pig cough sounds[J]. Computers and Electronics in Agriculture, 2008, 63(2): 207-214.
[18] Chung Yongwha, Oh S, Lee J, et al. Automatic detection and recognition of pig wasting diseases using sound data in audio surveillance systems[J]. Sensors, 2013, 13(10): 12929-12942.
[19] 马辉栋,刘振宇. 语音端点检测算法在猪咳嗽检测中的应用研究[J]. 山西农业大学学报:自然科学版, 2016, 36(6):445-449. Ma Huidong, Liu Zhenyu. Application of end point detection in pig cough signal detection[J]. Journal of Shanxi Agricultural University: Nature Science Edition, 2016, 36(6): 445-449. (in Chinese with English abstract)
[20] 张彩霞,武佩,宣传忠,等. 母羊声音信号处理与识别系统的设计[J]. 内蒙古农业大学学报:自然科学版, 2013, 34(5):145-149. Zhang Caixia, Wu Pei, Xuan Chuanzhong, et al. Design of acoustic signal processing and recognition system for the ewe[J]. Journal of Inner Mongolia Agricultural University: Natural Science Edition, 2013, 34(5): 145-149. (in Chinese with English abstract)
[21] 胡明辉. 基于支持向量机和HMM的音频信号分类算法研究[D]. 长春:长春工业大学, 2015. Hu Minghui. Automatic Audio Stream Classification Based on Hidden Markov Model and Support Vector Machine[D]. Changchun: Changchun University of Technology, 2015. (in Chinese with English abstract)
[22] 许乐灵,胡石. 一种引导滤波自适应双阈值优化边缘检测算法[J]. 南京理工大学学报,2018, 42(2):177-182. Xu Leling, Hu Shi. Adaptive double threshold modified edge detection algorithm for boot filtering[J]. Journal of Nanjing University of Science and Technology, 2018, 42(2): 177-182. (in Chinese with English abstract)
[23] Lipovskii A A, Shustova O V, Zhurikhina V V, et al. On the modeling of spectral map of glass-metal nanocomposite optical nonlinearity[J]. Optics Express, 2012, 20(11): 12040-12047
[24] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. 2017, https: //arxiv. org/abs/1704. 04861.
[25] Khaliq A, Ehsan S, Milford M, et al. A holistic visual place recognition approach using lightweight CNNs for severe viewpoint and appearance changes[EB/OL]. 2018, https: //arxiv. org/abs/1811. 03032.
[26] Sandler M, Howard A G, Zhu Minglong, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake, USA, IEEE, 2018: 4510-4520.
[27] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[EB/OL]. 2012, https: //arxiv. org/abs/1207. 0580.
[28] Kingma D P, Ba J. Adam: A method for stochastic optimization[EB/OL]. 2015, https: //arxiv. org/abs/1412. 6980.
Classification of pig sounds based on deep neural network
Cang Yan, Luo Shunyuan, Qiao Yulong
(,,150001,)
Pig sounds reflect the stress and health status of pigs, also it is the most easily collected biomarker through non-contact methods. To improve the classification accuracy of pig sound signals, this study used the spectrogram to visualize the time-frequency characteristics, and combined with the deep neural network classification model. Four contents were discussed as followed: 1) The sound data set was constructed. According to the different sound signals, the pig's behavior could be recognized by the classification network. When the pig was in normal statuses, the pig sounds were called as grunts. If the pig was in frightened statuses, such as injected or chased, pig sounds were defined as screams. Before the feeding, when pigs see the food, pigs made long irritable sounds. The sounds were called as howls of hunger. All pig sounds were collected on-farm by the sound collection box. On the farm, a laptop was used as a host computer to display all the working parameters of the collection box. The data transmission and storage scheme adopted the Client/Server architecture. Besides, the worker labeled sounds, according to the behavior. 2) Spectrograms of different sounds built up the training and test dataset of the image recognition network. The pig sound was a stationary signal in short time duration, therefore, continuously calculating the frequency spectrum of the sound signal in the vicinity of the selected instant of time gave rise to a time-frequency spectrum. The study discussed the optimal spectrogram parameters, which were suitable for the structure of the deep neural network. Experiment results showed that the segment length of the pig sounds was 256 samples and the overlap was 128 samples, the classification accuracy of the deep neural network was highest. The spectrogram optimization experiment results showed that the recognition accuracy was improved by 1.8%. 3) The deep neural network was designed. The study used the MobileNetV2 network to achieve recognition, which was based on an inverted residual structure where the shortcut connections were between the thin bottleneck layers. Aiming to the portable platform in the real application, the width factor and the resolution factor were introduced to define a smaller and more efficient architecture. Also, Adam optimizer formed an adequate substitute for the underlying RMSprop optimizer, and it made the loss function convergent faster. Adam optimizer calculated the adaptive parameter-learning rate based on the mean value of the first moment, making full use of the mean value of the second moment of the gradient. The result implied the width factor was chosen as 0.5, the accuracy was highest. 4) Compared experiments had been done. Support Vector Machine (SVM), Gradient Boosting Decision Tree (GBDT), Random Forest (RF), and Extra Trees (ET) algorithms were compared with the proposed pig sound recognition network. All algorithms were trained and tested on the same sound dataset. Specifically, the proposed algorithm increased the recognition accuracy of screams from 84.5% to 97.1%, and the accuracy of howls was increased from 86.1% to 97.5%. But the recognition accuracy of grunts was decreased from 100% to 97.3%. This was caused by the difference in the principle of different recognition algorithms. Furthermore, through the experiments on the width factor and resolution factor, a smaller and more efficient model was defined based on the standard MobileNetV2 model, and the running speed of the model was significantly improved to meet the needs of practical applications, however, the accuracy remained. This study showed that the abnormal pig vocalization was related to abnormal behavior, so sound recognition could help to monitor behaviors. In the future, the abnormal behaviors combined the sound recognition and video analysis would be discussed.
signal processing; acoustic signal; recognition; deep learning; pig sounds; MFCC; classification
苍岩,罗顺元,乔玉龙. 基于深层神经网络的猪声音分类[J]. 农业工程学报,2020,36(9):195-204.doi:10.11975/j.issn.1002-6819.2020.09.022 http://www.tcsae.org
Cang Yan, Luo Shunyuan, Qiao Yulong. Classification of pig sounds based on deep neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(9): 195-204. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2020.09.022 http://www.tcsae.org
2019-12-16
2020-03-16
国家自然科学基金(61871142)
苍岩,博士,讲师,主要从事智能信息处理研究。Email:cangyan@hrbeu.edu.cn
10.11975/j.issn.1002-6819.2020.09.022
TP391.4
A
1002-6819(2020)-09-0195-10
