基于CEEMDAN-LSTM的股票市场指数预测建模研究
2020-06-18贺毅岳韩进博
贺毅岳,李 萍,韩进博
(1.西北大学 经济管理学院,陕西 西安 710127;2.西安财经大学,陕西 西安 710100)
一、引言
股票市场是上市公司筹集社会资金的重要途径之一,股票投资已成为投资者实现资产保值、增值目标的主要方式之一。在股市投资研究中,资产价格行为的分析与建模是备受研究者关注的重要课题。对主动型股票投资研究而言,价格行为研究的核心是对股票价格的走势或未来值进行有效预测,进而指导投资者的交易决策行为,以使其所持有的投资组合经风险调整后收益最优化。然而,面对信息错综复杂、状态瞬息万变的股票市场,如何透过复杂现象看本质、把握股票市场行情脉络和资产价格运动状态及趋势,进而通过持续的交易决策获得理想的投资收益甚至超额收益,是股票投资者尤其是机构投资者高度关注并深入研究的核心课题。然而,传统股票投资分析方法,包括基本面分析法和技术分析法,却因建模数据体量小、模态单一、蕴含信息量少或模型发现数据变化规律低效等缺陷,难以对股市行情和资产价格的走势或未来值进行有效预测,进而难以为股票持续交易过程中的动态最优投资决策提供足够的信息支撑[1-2]。
主动型股票量化投资利用计算机技术深入分析大量的市场交易与参与者相关数据,以捕获市场的短期非有效现象,然后运用线性或非线性优化方法构建投资策略模型,包括选股、择时、风险管控等子模型,进而应用于选股、择时和风险管理等实务操作所依赖的系列决策过程,以获取投资者期望的最优风险调整收益[1]。择时是金融投资过程中的关键环节,即投资者根据其对资产价格运动趋势或未来状态的预测,在恰当的时机进入或退出市场,从而实现规避亏损、获取收益的目标。对于股票投资中的非系统风险,通常需要通过择时加以规避。股票量化择时就是运用数量化方法判断股票的走势或未来状态值,进行高抛低吸操作以获取超额收益的交易行为。择时的关键在于如何有效预测股价走势或未来值,而股票市场是一个受多种经济社会因素驱动的非线性复杂系统,其价格波动具有显著的非平稳、非线性和高噪声的复杂特性。传统的股市预测方法,包括金融计量方法、统计建模方法、浅层的机器学习方法,存在建模数据的容量较小或模型发现数据复杂模式的能力不足等重要缺陷,使得股价序列的特征提取及预测建模成为了金融数据建模领域的一个关键难题[3]。
近年来,机器学习在计算机视觉和语音识别等领域取得了系列突破性进展,特别是谷歌Alpha Go的出现,激起了众多行业、领域展开人工智能研究与应用的热潮,对数据密集型的金融投资行业产生了尤其深远的影响。国内外机构投资者正深入研究如何将最新的机器学习与人工智能技术引入到量化投资策略建模过程中,并已逐步形成了新的结合智能方法的主动型量化投资模式[4]。目前,国内已出现了一些该类投资模式的成功案例,如广发证券金融工程团队证实了深度学习在多因子选股、量化择时和CTA策略构建等方面的优异表现[5]。深度学习是一种新型的多隐藏层神经网络,通过模拟人类大脑在学习过程中的多层抽象机制,建立从底层信号到高层语义的非线性可逆映射关系,在对复杂输入样本本质特征的抽取方面表现出了强大的能力。在计算机视觉、自然语言处理和金融数据建模等众多应用领域中,基于深度学习构建的模型性能及泛化能力优异,多数应用效果取得了历史性突破[6]。因此,将深度学习中的最新方法拓展应用于股市指数序列的预测建模,可为复杂金融时序数据的建模研究提供有益的参考,同时有利于提升量化择时研究方法的科学性与实用性,这也正是当前股票量化投资研究的一个热点[1,3]。
二、文献综述
股票价格预测建模即建立股价走势或未来值的预测模型,是量化择时策略建模过程中的核心环节,也是量化投资理论和实务界形成共识的重要研究课题[3]。国内外学者针对股票价格及市场指数的预测建模展开了系统的研究,提出了三类预测建模方法。(1)技术分析法以道氏理论为基础,认为股价基本走势与市场波动趋势趋同,包括短、中、长三种走势,三者同时存在相辅相成。典型的股票技术分析研究大多以择时方法或策略的构造为应用背景。Mabu等运用一种基于图的进化计算方法——遗传网络规划方法,提取大量的技术指标规则创建规则池,并构建了适合日本股票市场的基于多技术指标规则组合的量化择时模型,实证研究结果表明:其所构建的多指标组合择时策略的收益比传统的单指标择时策略更高[7]。Wang等将技术指标规则组合应用于NASDAQ100指数成分股,构建了一个复杂的绩效奖励交易策略,其中使用时变粒子群算法获得策略的最优参数集,实证结果表明技术规则组合择时表现胜过基于单个指标规则的择时[8]。梁淇俊等以技术指标为择时策略依据,根据指标MACD、RSI和OBV构建交易信号以及信号有效性的择优体系,并以中信证券收盘价数据为例,对基于三个技术指标的单策略、联合策略有效性进行了量化分析,得到了MACD指标择时相对最优的结论[9]。(2)统计建模方法依据严谨的统计学理论对股价序列进行预测建模。国内外学者对ARIMA、GARCH和HMM等代表性方法进行了系列研究。Hassan提出一种新的HMM与模糊模型相结合的股价预测方法,使用HMM识别股价变化模式并用模糊逻辑进行预测,得到了比ARIMA、ANN等模型精度更高的预测效果[10]。张超提出基于误差校正的ARMA-GARCH股价预测方法,并将其应用于上证指数,显著提升了预测精度[11]。张蓓利用高斯混合GHMM模型对IBM的股价进行预测,并验证了其预测效果优于HMM模型[12]。(3)利用机器学习方法对金融时序进行预测建模是近年来金融数据分析领域的研究热点。Tay等从结构风险最小化角度深入分析了SVM的最小化泛化误差优势,首次利用SVM对标普500指数进行预测,验证了SVM的金融预测性能优于传统神经网络[13]。Chen等提出了一个基于信息增益的特征加权SVM和KNN结合的预测模型,并对沪深股市指数进行预测实验,获得了比现有模型更好的预测效果[14]。Bao等实证证明了长短期记忆网络(LSTM)对金融时序的预测性能优于传统的RNN[15]。Thomas等利用LSTM对标普500指数的变化方向进行预测,发现LSTM比随机森林、深度神经网络与logistic回归的分类效果好[16]。杨青等构造深层LSTM神经网络并对全球30种股票指数的3种不同期限进行预测,结果表明LSTM泛化能力强,对全部指数在不同期限下的预测效果稳定,比ARIMA、MLP和SVR预测精度更高,并能有效控制误差波动,提高不同期限下指数预测的稳定度[5]。
上述三类方法在金融时序预测问题上大多取得了较好的实证效果,但依然存在一定的理论或实用性缺陷:技术分析法直观,但其时效性较弱、所产生的买卖信号不确定性过高,易导致预测偏误;统计建模方法的预测结果在统计意义上可靠,但通常假定所预测序列线性或近似线性,难以实现对非线性、低信噪比金融时序的高精度预测;机器学习方法避免了统计建模方法中数据分布假设过于严格的问题,并具有更强的非线性关系抽象能力,能显著提升股价预测的准确性[3]。然而,股票市场是一个以多种方式对外部环境变化进行响应的复杂系统,随机性很强且各种现象之间存在复杂的非线性内在关系,而现有的金融时序预测建模通常依靠单一方法直接对序列模式进行挖掘,无法充分提取复杂的序列变化模式,故即便通过SVM、RNN和LSTM等机器学习方法,依然难以获得股票投资决策所需的高精度股价预测信息。
随着对金融市场微观结构与交易行为心理等方面研究的不断深入,学者们逐渐认识到单个技术难以高效地挖掘并刻画复杂金融市场中的多维量价变化规律,进而实现高精度预测,而融合金融计量、信号处理和机器学习等多学科方法的混合或集成模型,则能通过其不同子模块识别数据的不同模式,进而汇总获得其中蕴含的完整变化规律,实现金融时序的高精度预测[5]。美国工程院院士Huang等创造性地提出了经验模态分解(EMD)方法,将时序信号中不同尺度的趋势或波动逐级分解,生成一系列具有不同特征尺度的本征模函数(IMF),理论上可实现对非平稳、非线性时序信号的分解[17]。针对EMD分解不彻底、产生虚假分量和模态混叠的问题,Wu等通过引入频率分布均匀的辅助噪声改进EMD方法,提出了集成经验模态分解(EEMD)方法,解决了模态混叠问题,但处理过程中加入的高斯白噪声很难完全去除[18]。Torres等通过加入自适应白噪声进一步改进EEMD,提出了CEEMDAN方法,有效克服了EEMD分解不完备和重构误差过大的问题。CEEMDAN分解获得的各IMF相对简单且相互独立,为充分提取IMF子序列的波动特征提供了有利条件,从而显著降低了金融时序预测建模的难度[19]。EMD早期主要应用于信号去噪与气象科学领域,近年被引入到经济与金融等领域,其中与机器学习方法相结合的典型研究有:Yang等将汇率序列经EMD分解获得的IMF输入极限学习机,实现了对汇率预测精度的提升[20];贺毅岳等提出了EMD分解下基于SVR的股价集成预测方法EMD-SVRF,实证结果表明该方法比EMD-Elman和ARMA-GARCH等已有方法具有更小的预测误差[21];李合龙等运用EEMD方法对投资者情绪和股指价格序列进行分解和重构,并结合计量模型分析两者在不同时间尺度下的波动关联性[22];Zhang等在对地表温度的预测研究中提出构建EEMD与LSTM混合的预测模型,其实证结果表明该模型的预测效果优于RNN、LSTM和EMD-RNN等机器学习预测模型[23]。上述研究表明:CEEMDAN克服了模态混叠问题并具有自适应分解完备和重构误差低的优点,在提取复杂时间序列的波动模式进而提升预测建模精度方面具有突出的优势,是金融时间序列分析领域极具应用前景的新方法;另一方面,LSTM通过引入门控单元系统,解决了传统RNN模型训练中梯度爆炸和梯度消失问题,在提取序列数据中的长期依赖关系方面极具优势,可利用前期“记忆”为当期决策提供支持,是当前复杂高维时序数据分析中最成功的非线性建模方法之一,也是近年来金融数据建模领域的研究热点[3,5]。
为此,本文提出一种CEEMDAN与LSTM结合的股市指数预测建模方法CEEMDAN-LSTM:首先,运用CEEMDAN方法对市场指数序列进行分解与重构,获得高频分量、低频分量与趋势项3个子序列;然后,分别构建各子序列LSTM预测模型,并依据模型获得各子序列的预测值,进而通过加和集成处理获得市场指数的整体预测值。最后,以沪深300和中证500等5个代表性的国内股市指数为测试数据集,对本文预测建模方法和现有主流的金融时序机器学习预测建模方法的市场指数预测效果进行对比实验,以分析、验证本文方法的有效性和实用性。
本文旨在提出高精度的股市指数预测建模方法,为主动型量化投资研究与实践者把握股市动态趋势、规避市场风险进而增强超额收益能力提供更有效的工具。本文的主要创新在于:(1)将具有自适应分解能力的CEEMDAN方法引入到股市指数的预测建模过程中,从而获得波动特征相对简单且相互独立的高频、低频分量和趋势项3个子序列,为进一步对各子序列的高精度预测建模创造了有利条件,避免了现有建模方法直接从指数时序数据中提取波动模式的技术难题,显著降低了指数时序预测建模的难度。(2)针对指数CEEMDAN分解所产生的多个子序列,运用LSTM构建各子序列的预测模型,克服了传统统计建模方法对适用数据的分布假设过于严格的局限性,且能更高效地提取序列中蕴含的长期动态依赖关系,可为复杂金融时序的非线性预测建模提供有益参考。(3)将CEEMDAN的自适应分解功能与LSTM的长期依赖关系提取能力有效结合,构建股市指数的高精度混合预测模型,对提升量化择时信号的准确度与有效性具有较强的应用参考价值,有利于拓宽基于机器学习建模的量化投资策略设计的研究思路。
三、预测建模的理论基础
(一)CEEMDAN分解和重构
1.CEEMDAN原理。EEMDAN是针对经验模态分解(EMD)和集成经验模态分解(EEMD)的不足而提出的一种噪声辅助数据分析方法。EMD作为自适应信号时频处理方法可用于非线性、非平稳信号的分析处理,其特征是将信号平稳化,提取出信号中不同尺度的波动模式,生成一系列具有不同时间尺度局部特征的数据序列,每一个序列即为一个本征模态函数(IMF)。EMD分解的基本思路是用上、下包络的平均值去确定“瞬时平衡位置”,进而提取IMF,具体包括如下四个步骤:
(1)识别S(t)中所有极大值点max和极小值点min,用三次样条插值方法分别绘制出上、下包络线。其中,S(t)表示当前待分解序列,本文中其取值为市场指数收盘价序列。
(2)计算每一时刻上、下包络线的局部瞬时均值,从而获得平均包络线m(t),按照式(1)计算新序列d(t)。
d(t)=S(t)-m(t)
(1)
然后,按照式(2)计算出Sd值来判断d(t)是否为本征模函数。
(2)
其中,di(t)为第i次筛分的结果,Sd的阈值通常设定为0.2~0.3。若Sd值小于阈值,则筛分处理停止;否则,将d(t)当作新的待分解序列S(t),重新执行上述迭代处理过程。
(3)若d(t)满足IMF成立所需要的两个条件,则d(t)为一个IMF,将d(t)从S(t)中分离,得到余项r(t)=S(t)-d(t)。
(4)若余项r(t)已成为一个单调函数或常数,或振幅低于既定阈值而无法进一步提取IMF,则整个分解过程结束。否则,将r(t)当作待分解序列S(t),返回步骤(1),重新执行上述迭代处理过程。
经EMD分解原序列S(t)被迭代分解为n个彼此正交的IMF,记为ci(t),i=1,2,…,n,以及表示原时序信号S(t)趋势的最终残差项rn(t)。如式(3)所示,其中ci(t)依次取为步骤(3)所得到的本征模函数d(t)。
(3)
为解决EMD分解中存在的模态混叠问题,Wu等在EMD分解中引入频率分布均匀的辅助噪声,提出了EEMD方法:每次将不同的频率均匀分布的辅助白噪声加入目标信号,然后利用EMD分解含有附加白噪声的信号,重复执行上述过程N次,最后对分解获得的IMFs和趋势项分别进行集成平均,得到原信号的最终分解结果[18]。虽然EEMD显著改进了EMD的不足,但EEMD对原序列所添加的白噪声仍可能在多次平均后影响分解产生的子序列,进而影响子序列的预测精度。CEEMDAN进一步改进EEMD算法,在每次分解中都添加自适应白噪声来平滑干扰脉冲,进一步提升了EEMD分解的完整性,降低了重构误差[19]。
2.IMF重组方法。原序列S(t)进行CEEMDAN分解获得的各本征模函数ci(t),按如下三个步骤进行重组[21-22],可获得S(t)的高频分量、低频分量和趋势项3个子序列:
(1)分别计算各本征模函数ci(t)的均值,i=1,2,…,n;
(2)给定显著性水平为0.05,按i=1,2,…,n的顺序,依次对ci(t)执行均值不为0的t检验;
(3)若ck(t)为第一个均值显著非零的IMF,则将c1(t)至ck-1(t)加和得到S(t)的高频子序列,将ck(t)至cn(t)加和得到S(t)的低频子序列,而将rn(t)作为S(t)的趋势项。
(二)LSTM内部结构与工作原理
图1给出了循环神经网络(RNN)按时间展开的结构,其中主体结构A在t时刻读取输入信息,包括来自输入层的xt以及模型的上一时刻状态ht-1,以此更新其自身状态为ht并产生输出ot[16]。RNN凭借其在不同时刻隐含节点具有连接的结构,可实现对历史信息的记忆并应用于当前输出的计算,因而适用于时序信息的挖掘问题,已被广泛应用于包括语音识别等多领域中序列数据的建模过程。然而,RNN参数优化时面临梯度消失和梯度爆炸的问题,致使其参数难以训练达到最优值,进而使得RNN网络无法有效处理长期时序依赖关系。
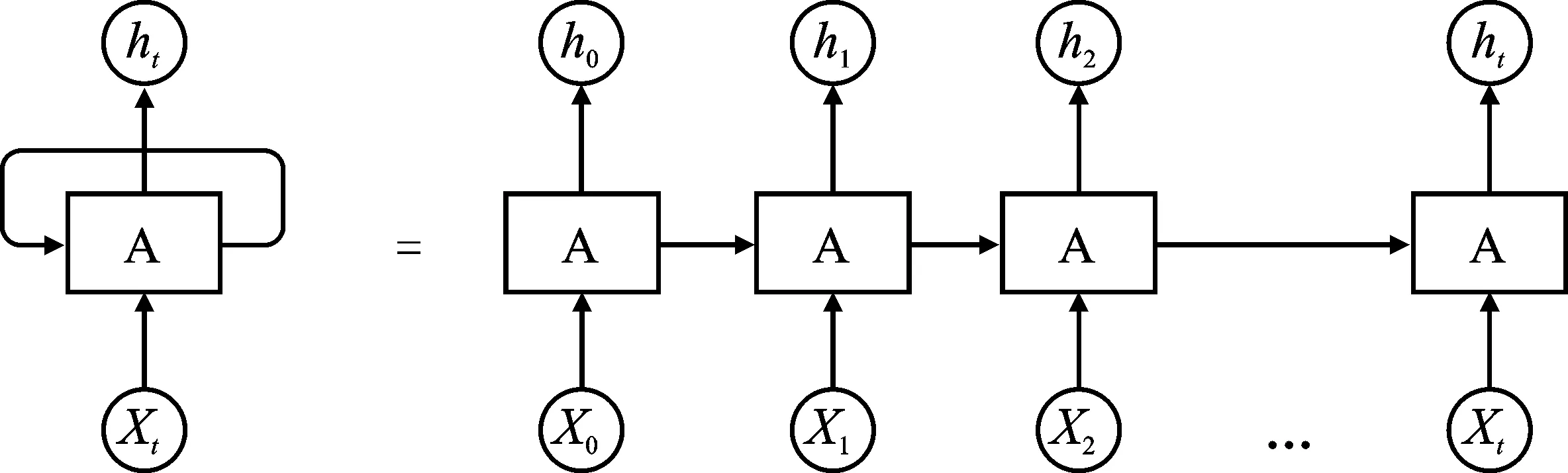
图1 RNN按时间展开的结构
LSTM是通过引入由输入门、遗忘门和输出门构成的门控单元系统而产生的一种RNN变体[3]。“门”是一种能对信息的通过进行选择性控制的结构,通过一个sigmoid层和一个逐点相乘操作来实现,其输出值在0~1之间,0表示完全不通过,1表示完全通过。LSTM用内部记忆单元即细胞的状态保存历史信息,并利用不同的“门”动态地让网络学习适时遗忘历史信息、依据新信息更新细胞状态,以解决RNN中梯度消失与梯度爆炸的问题。LSTM神经网络记忆单元的基本结构如图2所示[5]。

图2 LSTM单元的内部结构
LSTM通过遗忘门控制从当前状态中移除哪些信息,输入门控制哪些信息传递到当前状态中,输出门控制当前状态中的哪些信息用作输出,三个“门”共同作用、处理信息,完成时间序列的预测。遗忘门决定哪些信息被细胞状态丢弃,它读取ht-1和xt,按照式(4)计算遗忘门的输出ft:
ft=σ(Wf[ht-1,xt]+bf)
(4)

it=σ(Wi[ht-1,xt]+bi)
(5)
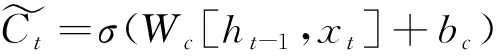
(6)

(7)
最后,通过“输出门”来确定输出什么信息。通过sigmoid层确定细胞状态的输出部分,然后使用tanh层对细胞状态Ct进行处理并与sigmoid门的输出相乘,确定最后的输出ht:
ot=σ(Wo[ht-1,xt]+bo)
(8)
ht=ottanh(Ct)
(9)
在式(4)~(9)中,xt、ht和Ct分别表示细胞的输入、输出和状态向量;ft、it和ot分别表示遗忘门输出、输入门输出和输出门输出向量;W和b表示权重向量和偏置项。用LSTM单元替代标准RNN中的隐状态节点可以构建出LSTM网络。基于门控单元系统的结构特征使得LSTM网络可以高效地处理复杂的长期时序动态依赖关系,特别适用于复杂金融时间序列建模。
四、面向股市指数预测的CEEMDAN-LSTM模型构建
(一)CEEMDAN-LSTM的建模思路
股市指数经CEEMDAN分解与重组产生的子序列波动特征相对简单,为进一步构建预测建模以充分提取子序列的波动模式创造了有利条件,可显著降低对指数序列高精度预测建模的难度。为此,本文将CEEMDAN的时序分解与LSTM的时序预测的两个优势功能进行结合,提出一个高精度的市场指数预测方法CEEMDAN-LSTM。图3是CEEMDAN-LSTM的建模流程:以股市指数收盘价序列为输入数据,通过CEEMDAN分解、本征模函数IMF的重组、高/低频分量及趋势项的LSTM建模及各分量预测值的加和集成四个处理阶段,最终获得高精度的指数序列预测值。

图3 CEEMDAN-LSTM预测建模的流程
步骤1:运用CEEMDAN方法将市场指数收盘价序列分解为n个本征模函数ci(t),i=1,2,…,n,以及一个趋势项rn(t)。
步骤2:按照前文所述的基于均值t检验的IMF重组方法,将各本征模函数ci(t)重组为原指数序列的高频分量、低频分量以及趋势项3个子序列。
步骤3:针对高、低频分量和趋势项3个子序列,分别建立对应的LSTM预测模型,并对高频子序列重组中IMF组合方式进行优化,以使高频预测模型达到最优预测效果。
步骤4:利用步骤3构建的3个子序列LSTM预测模型,计算获得各子序列的预测值,进而通过加和集成处理获得指数的高精度预测值。
(二)建模数据的选取及检验
本文在阐述股市指数的预测建模过程中选取沪深300指数作为建模的数据基础,原因包括:首先,沪深300指数是以沪深两市具有很强代表性的300只股票为基础编制而成,覆盖了A股市场中大多数蓝筹股,覆盖的行业较均衡合理,其市值约占A股市场的六成,具有很强的市场代表性,能较准确地反映沪深两市股价变化的整体行情及趋势。其次,该指数收益率是评价股票组合投资业绩的重要基准之一,可为市场中的指数化投资、指数衍生产品的创新提供基础条件,因而研究沪深300指数预测建模对衍生品市场的投资研究也具有重要意义。
利用Python从聚宽量化平台在线提取了2006年1月1日至2018年2月1日之间沪深300指数的收盘价,剔除节假日等因素的影响,共计2 955个数据作为指数预测建模的原始时序数据。在图4所示的建模时间区间内,指数先后两次大致经历了上涨、下跌和横盘震荡三种行情阶段,构成了两个完整的股指运行周期,这使得本文所建立的模型对股市指数变化规律的表达更充分、对行情变化的适应性更强,从而能增强本文研究结论的说服力。

图4 沪深300指数序列
对沪深300指数序列数据进行ADF检验,结果显示在1%显著性水平下指数非平稳;对指数的对数收益率序列进行Jarque-Bera检验,偏度为-0.587,峰度为3.639,具有尖峰厚尾特征,p值近似为0,指数收益率分布显著非正态。同时,利用Ljung-Box统计量检验指数收益率序列的ARCH效应,结果显示滞后阶数超过4以后,p值远远小于0.05,表明收益率序列有显著的波动聚集性。沪深300指数序列非平稳且包含大量的噪声,而传统的ARIMA、GARCH等计量模型,在未进行高效的降噪处理情况下,很难对这种复杂金融时序进行高精度的预测建模。因此,本文引入CEEMDAN对指数进行自适应分解、去噪与重构,然后运用非线性时序建模方法LSTM对指数进行预测建模是合理且必要的。
(三)指数序列的CEEMDAN分解和重组
1.指数序列的CEEMDAN分解。按照前文所述CEEMDAN分解过程,对沪深300指数序列进行自适应分解,结果如图5所示,得到从上往下依次排列的10个IMF和1个残余项,其中横轴表示指数的时间序号,纵轴表示各IMF的频率,从IMF1~IMF10到残余项频率逐步下降,变化模式也较原序列更简单。

图5 沪深300指数CEEMDAN分解结果
2.IMF重组处理。为了适当降低LSTM预测建模的复杂度和避免模型过拟合,参考李合龙等的研究,按照前文所述IMF重组方法,对沪深300指数经CEEMDAN分解所产生的10个IMF进行重组[22]。依次对IMF1~IMF10进行均值为0的t检验,检验结果显示其中IMF5是首个P值小于0.05的本征模函数,即IMF5的均值显著不等于0。因此,本文将IMF1~IMF4重组成为指数的高频分量,IMF5~IMF10重组为指数的低频分量,将残余项作为指数的趋势项r(t),从而获得图6所示从不同频率视角下刻画原指数序列变化模式的3个子序列。子序列变化模式相对简单、有规律性,便于进一步充分提取各子序列的波动特征。

图6 IMF重组得到的3个子序列
(四)子序列LSTM建模及效果评价
针对CEEMDAN分解与重组获得的3个分量子序列,包括高频分量、低频分量和趋势项,分别构建各子序列的LSTM预测模型,进而利用模型对预测区间内各子序列进行滚动预测,并采用确定系数R2、可解释方差EVS、均方根误差RMSE和平均绝对误差MAE四个评价指标,对各模型的预测效果进行评估。
1.子序列LSTM预测建模。采用滚动预测建模方式,以最近30天的指数值为输入来预测下一天的指数值[5,21]。从建模的原始时序数据中选取2006年1月1日至2016年2月1日共2 450个数据构建模型训练集,并采用Python库Pandas中的DataFrame对象来表示,大小为(2420×30),以剩余的505个数据构建测试集,对应的DataFrame对象大小为(505×30)。然后依次建立高、低频分量和趋势项对应的LSTM预测模型。
本文所构建的深层LSTM网络具有图7所示的计算图结构,虚线方框内表示深层网络的结构。在建模过程中,为消除数据间的量纲影响并提升模型的运算速度,对数据进行Z-score标准化处理[4]。模型参数设置方面参照了杨青等的研究,考虑到金融时序的非线性复杂特征及模型的运算效率,将隐藏层个数设置为2层,且每次投入模型的样例个数即batch_size设置为41,迭代次数设置为100次,同时增设Dropout层以优化神经网络,失活率设置为0.2。为使模型快速收敛时损失函数取全局最小值,选取优化器为Adagrad,设置动态学习率的初值设定为0.1,并根据经验公式0.1×(0.96epoch)动态调整,其中epoch为迭代次数,以使学习率随模型迭代次数的增加而均匀下降[5]。

图7 LSTM网络的计算图结构
表1给出了不同神经元个数组合条件下高频子序列LSTM预测模型的多指标评价结果,其中(10,10)对应的实验结果整体最佳,故将高频模型中两个隐藏层的神经元个数设定为(10,10)。按照同样的方法,将低频、趋势子序列预测模型的两个隐藏层神经元个数均设定为(6,6)。在确定上述参数条件下,建立各子序列的LSTM预测模型,模型均在100次迭代后损失函数均能收敛到平稳状态,故本文选取100次迭代后的训练模型作为最优预测模型。按照最近30天预测下一天的滚动预测方式,利用已建立的LSTM预测模型对预测区间内的高频、低频和趋势项3个子序列进行预测。表2给出了各子序列预测模型的多指标评价结果:高频子序列预测模型的R2只有0.408 1,表明该模型解释能力不足、预测误差较大,结合图8所示,高频子序列预测值相对真实值的右偏特征,表明高频子序列预测模型存在明显的滞后问题,需进一步改进;而低频和趋势子序列预测模型对应的R2都已超过0.997,表明两者的预测值和实际值均已非常接近,预测效果出色。

图8 高频子序列的LSTM滚动预测结果

表1 不同神经元个数条件下高频分量预测模型的评估结果
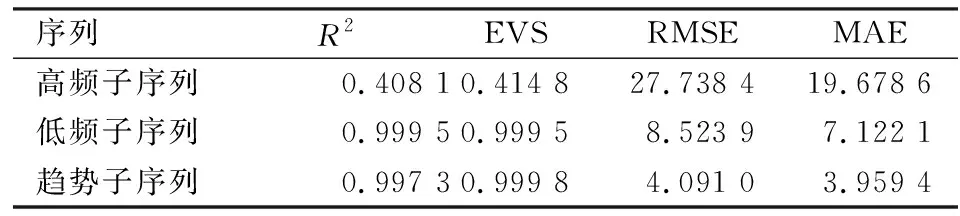
表2 各子序列预测模型的多指标评价结果
2.高频子序列重组中IMF组合方式的优化。重组构成高频子序列的IMF1~IMF4在包含股市指数波动特征信息的同时携带大量的噪声。因此,以IMF1~IMF4的不同子集重组产生的高频子序列,也会同时包含指数的波动特征信息以及不同比例的噪声。显然,在IMF1~IMF4中,IMF3和IMF4的频率相对更低,包含指数的波动信息相对更多,而IMF1、IMF2则含有更多的噪声。因此,优化后重组形成高频子序列的IMF集合,至少应包含IMF3和IMF4。进一步采用本文所确定的子序列LSTM预测模型参数,并根据预测效果评估结果确定最优的高频IMF组合方式。如表3所示,在4种合理的IMF组合方式中,剔除IMF1后利用IMF2~IMF4重组产生高频子序列,进而构建的高频预测模型的预测效果最优。相对于第一种组合方式,最优组合方式的R2值、EVS、RMSE、MAE分别提升了116.3%、113.1%、47.6%、45.4%。图9为最优组合方式下高频子序列的滚动预测结果,其滞后性比图8中高频子序列的预测结果有明显改善。

表3 不同IMF组合方式下高频预测模型的评估结果

图9 最优组合方式下高频子序列的预测结果
(五)指数整体预测值的加和集成及效果评价
将组合方式优化后产生的高频、低频与趋势项3个子序列的预测值加和,获得优化后的指数集成预测结果,如图10所示。可观察到未经优化的预测值相对于真实值存在较明显的整体右偏缺陷,表明未经优化的预测值具有一定的滞后性,而优化后的预测值明显更加贴近真实值。表4给出了优化前后指数集成预测效果的多指标评估结果:R2值提升了0.5%,EVS提升了0.5%,RMSE提升了43%,MAE提升了40.3%。这表明,IMF组合方式优化处理显著降低了模型预测的滞后性,并提升了预测精确度。

图10 优化前后指数的CEEMDAN-LSTM集成预测结果

表4 优化前后指数的集成预测效果的评估结果
五、CEEMDAN-LSTM模型预测效果的对比验证分析
本文选取包括沪深300、上证综指等5个最具代表性的国内股市指数为实验数据,并以已经研究证实预测效果较突出的指数预测建模方法[5,21],包括多层感知器MLP、支持向量回归SVR和LSTM,作为实验的对比方法,对CEEMDAN-LSTM模型的预测有效性、适应性进行评估。
(一)基于沪深300指数的预测效果对比分析
以本文所述训练期内的沪深300指数时序数据为输入,分别运用MLP、SVR和LSTM三种指数预测建模方法,直接针对指数序列数据构建相应的指数预测模型,然后以可视化方式呈现各种预测模型的滚动预测效果,并对各模型的预测效果进行采用多指标评估与对比分析,以客观地评估CEEMDAN-LSTM指数预测建模方法的有效性。
多层感知器(MLP)是一种前向结构的人工神经网络(ANN),其中包含多个节点层,每个节点代表一个带有非线性激活函数的神经元。MLP是一个有向图,每一层都全连接到下一层,能将一组输入向量映射到输出向量,通常采用反向传播BP算法训练网络权值。本文通过交叉验证与网格搜索方法设定MLP参数的最优值:正则化惩罚项系数α为0.1,隐层层数为3,相应的节点数为(13,23,9),激活函数为“tanh”,优化算法为“lbfgs”。图11给出了指数MLP预测模型的滚动预测结果,存在一定的预测滞后性。

图11 MLP模型的滚动预测结果
按照本文所述LSTM预测建模方法,针对沪深300指数序列的前2 450个数据,创建训练集并直接建立基于LSTM的指数序列预测模型,其参数设定参照前文所述的子序列LSTM预测模型参数。直接通过LSTM建模的指数预测结果如图12所示,其中预测值相对真实值有一定右偏,表明该预测方法存在预测滞后性问题。

图12 LSTM模型的指数滚动预测结果
参照贺毅岳等关于股市指数SVR预测建模的研究结果,以指数时序数据为基础创建训练集和测试集[21]。在对指数的SVR建模过程中,为避免模型超参数较多导致参数搜索计算代价过高的问题,本文限定系数γ和惩罚系数C的搜索区间为[0.01,20],待选核函数为:多项式核、线性核函、高斯核,进一步采用随机参数优化方法进行参数寻优实验,搜索到SVR预测模型中最优的核函数为“linear”、惩罚系数α为20,其余参数设定为Sklearn库中SVR函数提供的默认值。图13给出了基于SVR的指数滚动预测结果,仍存在一定的预测滞后性。

图13 SVR模型的指数滚动预测结果
在CEEMDAN分解的基础上进一步构建预测模型CEEMDAN-MLP和CEEMDAN-SVR,在模型参数寻优过程中均采用了随机参数优化方法[3]。图14给出了本文方法及上述5种对比建模方法在预测区间的前100个指数值上的滚动预测对比结果。表5进一步给出了各预测方法的多指标评估结果,其中CEEMDAN-LSTM的R2和EVS最大,RMSE和MAE最小,其在所有评估指标上一致优于其他5种对比方法。表5中模型CEEMDAN-MLP和CEEMDAN-SVR显著优于SVR和MLP直接建模的预测效果,也证实了对指数进行CEEMDAN分解与重组处理能显著提升建模的精确度。这表明通过CEEMDAN分解与重组产生子序列,再建模预测并集成最终预测值的思路是合理有效的。

图14 六种建模方法的滚动预测结果对比

表5 不同预测建模方法在沪深300上的评估结果
(二)基于上证综指等四个典型指数的预测效果对比分析
利用Python从聚宽量化平台在线提取2006年1月1日至2018年2月1日之间上证综指、上证50、深圳成指3个典型股市指数的收盘价,提取2008年1月1日至2018年2月1日之间中证500指数的收盘价,剔除节假日等因素的影响,前3个指数均含有2 955个数据,中证500含有2 472个数据,作为指数预测建模的输入数据。对上述4个指数的统计性质分析与检验表明:与沪深300指数类似,上述4个指数包含大量的噪声,具有显著的非正态、非平稳特征,对应的收益率序列波动聚集性显著,直接应用传统的计量方法难以获得高精度的预测效果,因而选用CEEMDAN-LSTM对各指数进行预测建模。
分别以上述4种指数的2016年2月1日之前共2 450个数据(中证500前1 967个数据)作为建模输入数据,参照前文所述沪深300指数序列CEEMDAN-LSTM建模过程,采用滚动预测建模方式,以最近30天的指数值为输入变量来预测下一天的指数值,依次通过指数序列的CEEMDAN分解和重组、子序列LSTM预测建模及高频子序列重组中IMF组合方式优化、加和集成指数整体预测值等一系列建模步骤,构建出与每一种指数对应的CEEMDAN-LSTM预测模型。同时,参照本文基于沪深300指数的预测效果对比分析部分所述,针对上述每一种指数,采用滚动预测建模方式,分别运用MLP、SVR、LSTM、CEEMDAN-SVR和CEEMDAN-MLP建模方法,构建5个对应的指数预测对比模型。然后,以每一个指数2016年2月2日至2018年2月1日共505个数据构建滚动预测的测试集,分别利用上述6种预测模型进行周期为30天的按日滚动预测,以对比分析各模型的预测效果。
图15依次给出了上述6种建模方法在上证综指、上证50、深圳成指和中证500四个指数预测区间上的滚动预测对比结果。其中,相比其他对比建模方法的预测曲线,CEEMDAN-LSTM预测曲线与原指数曲线贴合最紧密,时间滞后性最弱。进一步地,表6~9依次给出了各模型在四个指数上滚动预测效果的多指标评估结果,其数据证实,在对上述每一个指数的预测表现中,相对于其他5种对比建模方法,CEEMDAN-LSTM的R2和EVS值均最大,而RMSE和MAE值均最小,即其在所有评估指标上一致优于包括LSTM在内的其他5种对比方法;同时,在对每一个指数的预测表现中,CEEMDAN-SVR和 CEEMDAN-MLP又分别优于SVR和MLP直接建模,证实了对指数进行CEEMDAN分解与重组处理能显著提升进一步预测建模的有效性。因此,将CEEMDAN的自适应分解功能与LSTM的长期依赖关系提取能力结合运用,进而构建股市指数的高精度混合预测模型的思路是合理、有效的。

(a)上证综指

(b)上证50

(c)深圳成指

(d)中证500图15 6种建模方法在4个典型股市指数上的滚动预测效果对比

表6 不同预测建模方法在上证综指上的评估结果

表7 不同预测建模方法在上证50上的评估结果

表8 不同预测建模方法在深圳成指上的评估结果

表9 不同预测建模方法在中证500上的评估结果
六、结论及展望
本文针对股票市场指数预测建模这一金融投资领域的核心问题,运用CEEMDAN分解与重组产生波动特征更简单的高频、低频及趋势子序列,为进一步构建子序列预测模型充分提取子序列的复杂波动模式创造了有利条件,显著降低了指数序列高精度预测建模的难度,使得本文通过CEEMDAN进行指数分解与重组后分别构建预测模型,进而加和集成获得指数整体预测值的思路合理、可行。本文在对指数CEEMDAN分解与重组的基础上,充分利用LSTM对复杂序列中长期依赖关系高效提取的优势,提出并详细阐述了一种CEEMDAN和LSTM结合的股市指数集成预测建模方法CEEMDAN-LSTM。最后,选取了包括沪深300、上证综指等5个最具代表性的国内股市指数为实验数据,并以经研究证实预测效果较突出的主流机器学习指数建模方法,包括MLP、SVR与LSTM,作为实验的对比方法,对CEEMDAN-LSTM模型的预测有效性、适应性进行多维度量化评估。实验结果证实,CEEMDAN-LSTM的预测表现一致性地优于现有建模方法,其预测结果误差小、精度高,且相对真实指数值具有更低的时间滞后性。然而,本文在CEEMDAN-LSTM的建模过程中,对网络隐藏层个数等部分参数的选取仍具有一定的主观性;同时,双层LSTM单元未必能充分挖掘出非线性复杂指数序列中蕴含的深层次变化模式信息,故还需进一步研究模型参数的最优化处理。
