指标无量纲化的性质分析与方法选择
2020-06-18岳立柱施光磊
岳立柱,许 可,施光磊
(辽宁工程技术大学 工商管理学院,辽宁 葫芦岛 125105)
一、引言
指标数据无量纲化是数据分析的基础,如多准则决策(MCDM)、神经网络(NN)、线性判别法分析(LDA)和主成分分析(PCA)等模型,应用前均需要对原始数据进行无量纲化处理。采用不同的无量纲化方法,模型结果往往并不相同。选择哪种无量纲方法更适合模型,至今仍充满争议。
学者们对无量纲化问题进行了深入研究,但观点并不一致。张卫华和赵铭军根据序数特征,在逐步探寻合理等级排序依据的前提下,认为均值化(数据除以其均值)是一种较好方法[1]。樊红艳和刘学录认为均值化和比重化(数据除以其向量模)来进行数据的无量纲化的方法更加科学合理[2]。与此不同,郭亚军和易平涛根据理想线性无量纲化6条性质,认为标准化处理法、极差正规化法和功效系数法满足的性质最多,因而相对于其他方法来说更为优良[3]。胡永宏的结论更具一般性,认为选择线性无量纲方法应遵循的基本原则: 一般情况下宜采取不带截距项的线性无量纲化方法,如均值化、初值化、比重法等[4]。均值化方法易受样本值,特别是极端值的影响,李伟伟等提出了中位数方法改进了均值化方法[5]。不过,在样本没有极端值的情况下,中位数方法的效果不一定强于均值法。争论拓展了对指标无量纲化的认识,但也给实践应用带来了困扰。
上述争论可以归结为两种观点,一种是无截距的观点,另一种是有截距的观点。前者有实证分析结论为依据,后者有6条性质为依托,各自都有有效“证据”。郭亚军和易平涛提出了理想线性无量纲化性质应满足6个性质,胡永宏认为其缺少非常重要的一条,即变异信息的不变性,该性质是支持无截距观点的关键。实际上,由6条性质中的差异比不变性能够推导出变异系数不变性。因此,变异系数不变性不是判定是否采用截距的判定条件。从数学角度讲,无量纲化是一种映射,也就是将各指标的实际数据映射到一个共同的合适的区间,确定无量纲化方法就是确定一个函数关系式[4]。上述争议的产生,本质上是双方忽略了指标的等值域性,即数据映射到一个共同的合适区间。
无量纲化要保证不同单位的指标数据具有可比性。无量纲化对各指标均取相同区间值,如果映射后的区间不同(例如均值化方法),即使权重相同,区间值的作用并不相同。同值域性不仅是指标聚合的前提,也是赋予模型意义、增强可解释的必要步骤。不同类型的指标一般是不可以直接综合的,比如收入水平和人均寿命。从统计学角度来看,可以通过指标共同遵循的结构特征进行综合分析,例如变动的百分比。无量纲化过程要保持易理解性和可解释性。结合权重视角来看,在线性模型中,Choo等认为权重表示指标每变换一个抽象单位,对目标值增长“贡献”一个权重量[6]。尽管作者没有明确抽象单位为何物,但默认指标取值是同值域的。如果无量纲不满足同值域性,从统计和权重角度均很难或无法解释。
目前研究多集中于线性无量纲化方法,非线性无量纲化方法鲜有关注。Rezaei研究了折线型无量纲化方法,若采用非线性规范方式,建议采用折线型方法,因为模拟发现二者效果差异并不明显[7]。但该研究存在一个明显缺陷,不能总是满足指标同值域性。尽管该文中所有指标的值域为[0,1],但很多原始指标属于适度型指标而非单调指标。对适度型指标需要拆分为若干的单调指标。对于适度指标可以适度值为界限,将指标取值区间分为两部分,在不同的部分适度指标就转化为正向指标和逆向指标,因为每个单调指标区间映射为[0,1],多个单调区间实际上会出现多个[0,1]区间[4]。不进行拆分的话,会失去可理解性和解释性。对于非线性转换方式,认为很多时候会改变原始数据的比例关系。实际上,原始数据比例关系表现方式与所研究的问题性质有关,例如收入水平与效用关系,一般来说随着收入的增加,边际效用递减,同样增加一元钱,不同收入水平条件下,增加的效用不同。因此,保持数据比例关系是一个理想追求,但不是规范化的必要条件。
逆向指标转化在实际中最常见的就是取倒数,其好处之一是取倒数后的指标可能有实际的意义,比如“万元产值能耗”取倒后可变为“每单位能耗实现的产值”[4]。叶宗裕认为“这种取倒数的变换方法完全改变了原指标的分布规律,所得综合评价结果肯定是不准确的,因而是不可取的”[8]。取倒数法的确不是一个可选方法,其关键是指标取值不满足同值域性。单纯从数据角度考虑要保持指标数据分布,该标准不必刻意遵循,因为指标和研究对象之间的函数关系才是问题的核心。
当前,国外直接研究无量纲化的文献非常少见,因其更多地集中于指标函数和指标集结问题的研究,相对而言,无量纲化是一个“小”问题。Bell从效用函数的视角,证明了当效用函数的自变量相互独立时,各指标的综合函数为线性函数[9]。由偏好强度可以衡量和显示价值函数[10]。Bleichrodt等提出不确定条件下,决策者常使用期望函数构造价值函数[11]。无论是效用函数还是价值函数,在最终的指标集结环节,均需要对指标进行无量纲化处理。
综上,本文以指标无量纲化应满足同值域性为出发点,遵循简单实用的原则,对无量纲化所具备的特征进行分析,给出一种更一般性的无量纲化方法,不仅适用于线性而且还能适用于非线性无量纲化处理方式。
二、线性无量纲化的性质分析
无量纲化函数要满足同值域性。为了遵从习惯和分析方便将值域规定为[0,1]区间,设指标初始取值区间为[a,b],a,b∈R。适度性指标的评价需要拆分成单调型指标,对适度指标可以适度值为界限,将指标取值区间分为两部分,在不同的部分适度指标就转化为正向指标和逆向指标。首先对郭亚军和易平涛(文献[3])提出的理想无量纲化的性质进行分析,重点分析性质2(差异比不变性),在此基础上再对其它性质进行简要讨论。
文献[3]提出6条性质中,差异比不变性是一个最为重要的性质,一定条件下,根据该性质可以推导出其它性质。所谓差异比不变性,即要求无量纲化后的数据保留原有数据之间对于某个标准量的比较关系,即有:
(1)
(x1,x2为极大型指标x的任意两个观测值,x′为一特定的标准值)成立。
函数f(x)若满足性质2,则其一定为线性函数。由性质2题设可令x′=a,x2=b,带入式(1)有:
(2)
整理式(2)得:

(3)
根据式(3)可知,满足差异比不变性的无量纲化函数一定为线性函数。由于线性函数一定是单调函数,自然满足文献[3]的性质1即保序性;由于线性函数满足变异不变性,即变异系数σ/μ于无量纲化前后保持不变,由性质2可得胡永宏强调的变异系数不变性[4]。文献[3]的性质6为总量恒定性,缩放后总量保持不变,即缩放平移后原始数据之和保持不变。性质2则表明无量纲函数为线性函数,保持数据总和不变,易知f(x)=x。因此,性质6与性质2是不能同时存在的。实际上总量恒定性不是一个好的性质。无量纲化的目的是使量纲指标数据具有可比性,各指标应映射到一个恒定的区间,与数据总和是否变动没有必然关系。
另外,式(1)的表达不便理解,需要将其转为更为直观的表达方式。对∀x1,x2,x3∈[a,b],根据式(1)可知:
(4)
(5)
整理式(4)和(5)可得:
(6)
定义若函数f:[a,b]→[0,1]在定义域上连续且单调,则称f(x)为0-1规范函数。
为了与习惯相符,0-1规范函数也可称为0-1无量纲化函数。下面定理表明,任意形式的线性无量纲函数,转换至0-1规范函数均有相同的函数形式。
定理1设f(x)为[a,b]上的线性函数,若将其转换成0-1线性规范函数g(x),则:
①当f(x)单调增,则有g(x)=(x-a)/(b-a);
②当f(x)单调减,则有g(x)=(b-x)/(b-a)。
证明:函数f(x)为[a,b]上的线性函数,于是设f(x)=px+q。当其为单调增时有f(a)≤f(x)≤f(b),于是0≤f(x)-f(a)≤f(b)-f(a),进一步有:
(7)
将f(x)=px+q带入上式,整理得[f(x)-f(a)]/[f(b)-f(a)]=[x-a]/[b-a],显然g(x)=[x-a]/[b-a]为0-1规范函数。
再证唯一性。若存在两个不同的0-1规范函数,即设gi(x)=pix+qi,i=1,2。由0-1规范函数可知:
g1(a)=p1a+q1=0,g2(a)=p2a+q2=0
g1(b)=p1b+q1=1,g2(b)=p2b+q2=1
整理得g1(b)-g1(a)=p1(b-a)=1,g2(b)-g2(a)=p2(b-a)=1,显然p1=p2,同理可知q1=q2。故唯一性成立。
综上,可知定理1①成立。定理1②证明类似,证略。
推论任意线性函数转换成0-1线性规范函数,均受区间端点值的影响。
在线性规范背景下,由定理1可知,0-1规范函数满足文献[3]的性质3、性质4和性质5。性质3为平移无关性,即对原始数据进行“平移” 变换不会影响无量纲化后的结果。性质4为缩放无关性,即对原始数据进行“缩小” 或“放大”变换不会影响无量纲化后的结果。性质5为区间稳定性,即对任意一指标原始数据的无量纲化处理结果都处在一个确定的取值范围内。
三、非线性无量纲的选择方法
无量纲函数可分为单调型和适度型两类,单调型可细分为线性单调和非线性单调,适度型函数又可细分为折线型和非折线型两种。适度型指标需要拆分,对拆分后的指标取值区间分别进行同值域化处理。因此,对无量纲函数的研究转换为对单调型函数的研究。
无量纲函数f(x)单调增或减,可分别采用如下公式进行0-1规范化处理:
[f(x)-f(a)]/[f(b)-f(a)]
(8)
[f(b)-f(x)]/[f(b)-f(a)]
(9)
对非线性0-1规范函数,函数形式有时比较复杂,需要借助下面定理进行研究。
定理2若f(x)为0-1规范函数且单调增,则存在唯一连续且单调增函数φ(x),使得f(x)=φ(g(x)),其中g(x)=(x-a)/(b-a)。
证明:由于g(x)为线性函数,故其存在逆函数g-1,于是x=g-1(g(x))=(g-1∘g)(x)。将其代入f(x)得:
f(x)=f(g-1(g(x)))=(f∘g-1)(g(x))
令φ=f∘g-1,由于f,g-1连续单调增且给定的,故φ(x)连续单调增且唯一的。证毕。
为了方便,称定理2中的φ(x)为生成函数,由证明过程可知φ(x)=f(g-1(x)),于是单调非线性0-1规范函数f(x)均可转换成对φ(x)的研究。显然,函数φ(x)与f(x)同序;f(x)为非线性函数,则φ(x)为非线性函数。不难验证,若函数φ(x)连续,且满足φ(0)=0,φ(1)=1,则φ(g(x))是0-1规范函数。
在应用中,对单调增的非线性0-1规范函数,对原始数据先应用g(x)=(x-a)/(b-a)进行线性化处理,之后再根据实际情况,采用特定的φ(x)构造出规范函数。
Rezaei(文献[7])介绍了一种应用较灵活的非线性无量纲函数,即:
(10)
不过式(10)函数形式相对复杂,调节参数ρ时,要考虑边界值a,b。同样的ρ值,由于边界值的不同,表示的含义不同。在模拟仿真分析中,文献[7]要不断变换指标边界值。根据定理2,能得到式(10)的一般表示形式。函数g(x)的逆函数为g-1(x)=(b-a)x+a,根据φ=f∘g-1,得到:
(11)
令(b-a)/ρ=θ,代入式(11)右端上式,整理得:
(12)
进而,根据式(12)和式(11)整理有:
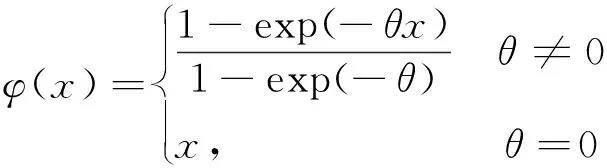
(13)
根据式(13)中参数θ的取值变化,分别绘制了其大于零和小于零时的若干曲线图。
从图1和图2可以看出,参数θ取值决定着函数形状。当θ>0时函数φ(x)为上凹函数;当θ<0时函数φ(x)为下凸函数;当θ=0时函数φ(x)为线性函数。根据实际情况,可以选择相应的函数形式。例如,研究收入对效用的影响,根据边际效用递减规律可采用上凹函数,即θ>0;令Δ表示空气污染物So2的浓度增量,当浓度很小时,一个小的浓度增量变化对人体危害不大,当浓度很大时,特别是接近于人体承受临界,一个小的增量Δ便起到了“压死骆驼的最后一根稻草”的作用,此时应选择上凸函数。
如何根据实际情况确定参数θ的凹凸形状,即参数θ具体取值呢?实际上,在一些情况下,过于“精确”反而起到反作用,因为这些细节会给我们带来困惑与苦恼,会给我们一个精准的假象。然而,输出结果并不会因广泛的近似而贬值。但对式(13)的函数特征可以给出辅助性的判定方法。对φ(x)进行求导:
(14)
对∀x1,x2∈[0,1],二者导数的比值整理得:

(15)
令exp[θ(x2-x1)]=k,两端取对数整理得:

(16)
在模糊语义隶属函数构造过程中,特别是五级划分中,围绕0.2为轴构造的隶属函数表示较低水平、0.8为轴对应较高水平。假如在空气质量污染较高水平下一个小的增量效果是较低水平下的2倍,于是根据公式(16)可得到θ=ln2/(0.8-0.2)=1.155。

图1 参数θ为正值对应的曲线图

图2 参数θ为负值对应的曲线图
四、逆向指标的转换方法
指标同向化处理过程中,学者们注意到了将逆向指标转换为正向指标存在的问题。当前常取倒数进行正向化处理。叶宗裕认为取倒数的变换方法完全改变了原指标的分布规律,该方法不可取,提出了对逆向指标正向化方法通过端点值简单变换即可,即给定逆向指标原始数据x,通过b-x变换即满足要求。取倒数本质上是采用了非线性变换,不满足差异比不变性,更不满足指标同值域化基本要求。
逆向指标的选择还应满足同向不变性。所谓同向不变性是指,无论将所有指标转换为正向指标,还是将其转换成逆向指标,二者的排序应该是互反的,即优劣关系保持不变。容易验证,倒数法的同向化处理方法,不满足同向不变性。
对于0-1规范函数f(x),遵循简单易行的原则,对逆向指标采用如下正向化方法:
f(b)-f(x)=1-f(x)
(17)
式(17)遵循了叶宗裕的思路,但适用范围更广。当f(x)为0-1非线性函数时,1-f(x)也为0-1非线性函数。该变换方法保证了同向不变性。设有n个指标,x=(x1,x2,…,xn)正向化向量记(f(x1),f(x2),…,f(xn)),根据式(17)逆向化向量为(1-f(x1),1-f(x2),…,1-f(xn))。正向化线性综合值如下:
F1(x)=ω1f(x1)+ω2f(x2)+…+ωnf(xn)
逆向化线性综合值为:
F2(x)=ω1[1-f(x1)]+ω2[1-f(x2)]+…+ωn[1-f(xn)]=1-F(x)
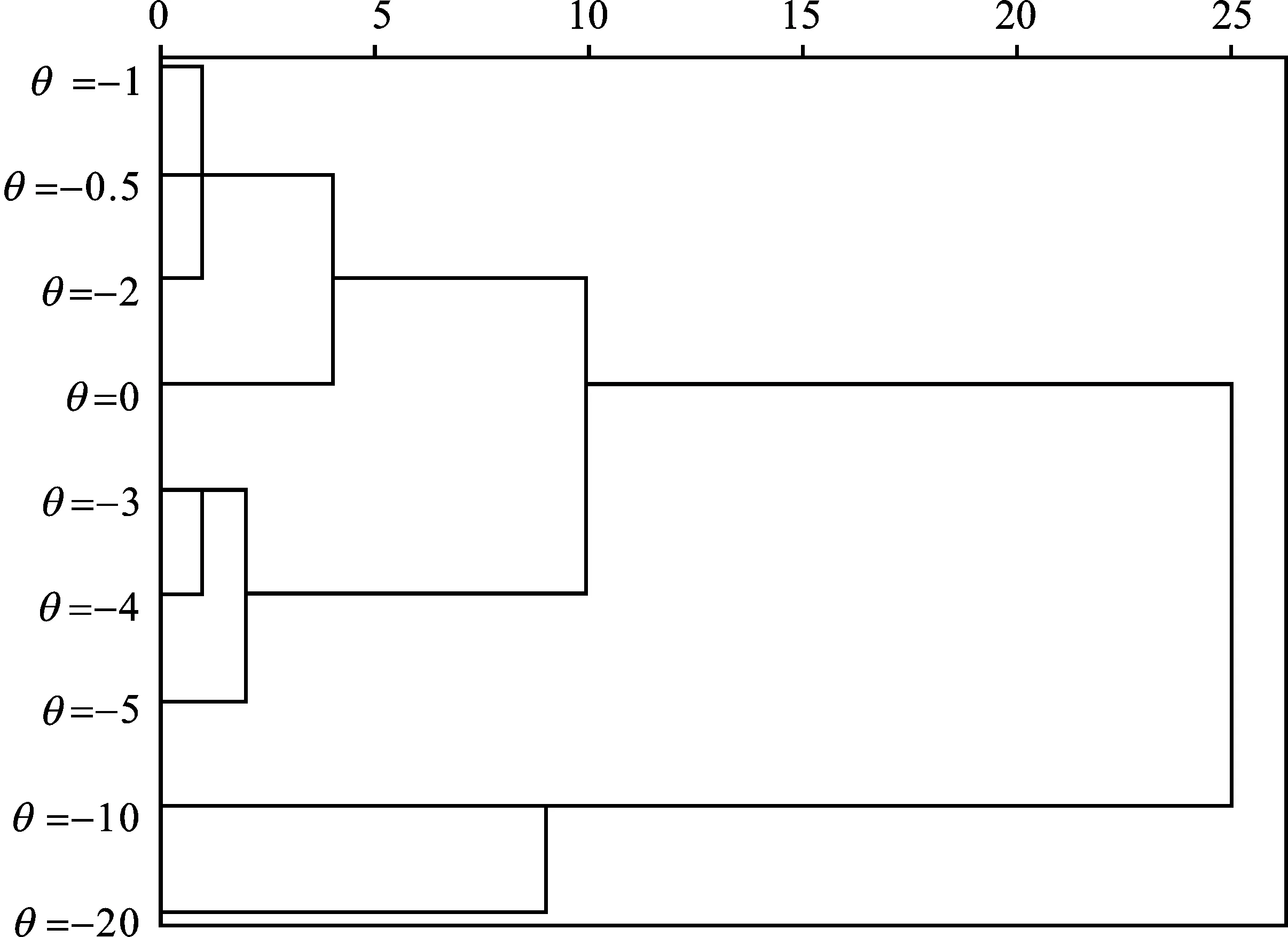
于是,可知对任意两个x,y∈Rn,若F1(x)>F1(y),则有F2(x) 应用0-1规范函数对指标进行无量纲化处理。首先明确指标边界。结合定理1和定理2可知,任何0-1规范函数都受边界值影响,因此边界值的确定是规范化重要的基础性步骤。确定边界值更多需要借助专业人士来完成。同样的数据在不同的情境下意义可能并不相同,其可能的边界也会变动。其次,根据各指标反映的研究对象,通过模型与实践背景相结合的原则,估计无量纲函数的θ。最后对指标进行同向化处理。具体操作步骤如下: 第一步:确定指标边界值; 第二步:根据定理1中的①,将指标取值变换至[0,1]区间; 第三步:确定参数θ,根据式(13)对指标进行无量纲化处理; 第四步:根据式(17)将逆向指标调整为正向指标。 尽管文献[7]研究多个适度型指标,出于简单方便的原则认为折线型适度指标很大程度可以代替非折线适度型指标。由于适度型指标需要拆分成单调指标,因此只需讨论线性与非线性指标的无量纲化问题。选择实例目的在于,验证线性与非线性无量纲化方法两种结果多大程度能保持一致。 例子选自邹志红等的文献,该例对三峡库区重庆、长寿等城市江段13个监测断面,运用线性综合方法进行水质评价[12]。水质评价采用了溶解氧(DO)、高锰酸盐(CODmu)、化学耗氧量(CODCr)、五日生化耗氧量(BOD5)、总磷(TP)等5项非生物代表性指标作为指标集,原始数据见表1。 表1 原始数据 出于简便的原则,采用各指标的最大与最小值作为各指标的取值边界(实践中可能需要专家经验确定取值边界)。根据定理1中的①,将指标取值变换至[0,1]区间(见表2),注意逆向指标溶解氧(DO)也采用同样的变换方式。 表2 正向0-1线性归一化数据 由于污染物随着浓度的增加,其对环境的影响程度随着边际浓度增加而增大,因此参数θ的取值应小于零,分别选择0、-0.5、-1、-2、-3、-4、-5、-10和-20等9个参数。分别根据式(13)对指标进行无量纲化处理(对逆向指标溶解氧(DO)根据式(17)进行正向变换)。根据各指标权重(见表3),采用线性函数对5个标准化后的指标进行集结。 表3 准则权重 对集结结果进行排序,序值越小表示污染程度越大。各参数值对应的排序结果见表4。 表4 对应不同参数值下的方案排序 采用k-means算法进行聚类分析。对排序结果进行聚类分析,得到图3。由图3可以看出,θ取值排序结果可以分成三个大类:A={0,-0.5,-1,-2}、B={-3,-4,-5}和C={-10,-20}。 聚类结果表明,线性规范排序结果与非线性排序结果存在差异;多个非线性规范也存在差异,例如B类和C类。因此,直接用线性函数来替代非线性规范函数有时是不可取的。在本例中,根据经验判定,假若θ值小于0,但不会小于-2,此时可以选择线性0-1规范函数进行无量纲化处理;但是,若θ取值为C类,这时用线性规范函数会发生较明显偏差。 该例显示,不同的无量纲函数的确可能有不同排序结果。在实践应用中,评估θ取值是选择线性函数和非线性函数的关键。另外,差异程度不仅与评价模型类型有关,与模型中具体参数设置也有关,例如权重取值。因此,需要理论与实践经验相结合来估计参数θ,并评估包含该参数值的稳定区间。 图3 k-means聚类图 研究发现,同值域性是实施指标无量纲化过程的关键性必要条件。遵循同值域性指标的无量纲化方法可以归结为统一形式,即首先通过极差无量纲化公式将指标数据映射至[0,1]区间;根据实际意义选择线性或者非线性函数,再次进行数值转换;之后,对逆向指标根据式(17)同向变换。极差无量纲化方法不仅是最佳的线性规范方法,更是非线性规范的基础。通过生成函数,有助于选择非线性无量纲化函数,降低对其进行分析的难度,有效规避指标区间端点不断变动而导致的分析困难。对无量纲化的分析表明,无论采用何种0-1规范函数,均不可避免受到区间端点的影响,确定区间端点是有效避免逆序发生的关键。需要注意的是,本文应用的0-1非线性规范函数,即式(13)仅是非线性函数中的一类,对于有拐点的呈“S”型单调规范函数(如文献[13])也是一种常用类型。对该类函数的分析,将在今后的研究过程中有所体现。五、实施步骤
六、实例分析




七、结论
