基于混合智能算法的支持向量机的粮食产量预测
2020-06-17高心怡
高心怡,韩 飞
(江苏大学 计算机与通信工程学院,江苏 镇江 212013)
对于中国这个粮食大国来说,农业经济预测十分重要,它为国家、政企及其他有关部门把握未来经济运行状况、判断发展后劲、制定相关决策等提供科学依据.早先,国内外学者对农业经济预测进行了大量研究,提出了很多预测方法,如因果预测法、时间序列预测法、决策树法、先期调查等,这些都是传统经济预测的基本方法.此后有学者提出BP神经网络预测模型[1-3],但BP神经网络在非线性预测中易于陷入局部极值,影响预测精度,即农业经济预测对于模型的非线性预测性能有着比较高的要求.支持向量机回归算法[4]是一种用于趋势预测的支持向量机,它通过一个映射函数将输入数据非线性地映射到高维特征空间,并在此高维空间进行回归.由于支持向量机中核参数γ、惩罚参数C的选取对其预测效果有一定影响,因此求得较优的参数组合可以提高支持向量机的预测性能.粒子群算法(PSO)[5]是根据鸟群觅食行为而产生的仿生设计算法,属于一种较为简单有效的全局优化算法,但在进化后期收敛慢,粒子容易趋于同一化,失去多样性,优化精度较差.针对此缺陷,文中提出一种改进的基于混合智能算法的支持向量机的农业经济预测方法,融合了改进的PSO算法与人工鱼群算法,通过自身内部的变异交叉以及族外竞争机制,使得目标函数值向全局最优解快速收敛,提高粒子的多样性以及算法的全局搜索能力,最终得到支持向量机的最优参数组合.并以BP 神经网络预测模型、PSO-SVM预测模型与文中预测模型进行试验对比,结果表明基于混合智能算法的支持向量机的农业经济预测模型比其他方法有着更高的预测精度.
1 支持向量机
支持向量机(support vector machine,SVM)是一种机器学习过程,其基本原理是将样本数据映射到一个高维空间,并在高维空间中寻找一个最大间隔超平面,将不同类别的样本数据隔离,使得间隔最大,从而正确分类样本数据.对于给定的线性可分数据集{xi,yi},i=1,2,…,l,yi∈{-1,+1},xi∈Rn,满足
yi[w·xi+b]-1≥0,i=1,2,…,l,
(1)
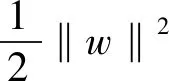
利用Lagrange乘子法并满足KKT(Karush Kuhn Tucher)条件,最终可得到解上述问题的最优分类函数为
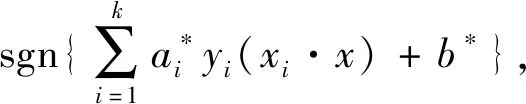
(2)
式中:a*,b*为确定最优划分超平面的参数.
对于线性不可分情况,通过在约束条件中引入松弛变量以及在目标函数中加入惩罚变量来解决这一问题.这时广义最优分类面问题可以进一步演化为求取下列函数的极小值:
(3)
式中:C为惩罚系数,用于控制错分样本惩罚的程度.
支持向量机引入核函数,避免了高维空间的向量内积而造成大量运算.目前,径向基函数是应用最广泛的核函数,函数形式如下:
K(xi,yi)=exp(-γ‖xi-xj‖2),γ>0,
(4)
式中:参数γ是核函数中的重要参数,影响着SVM分类算法的复杂程度[6].
综上所述,支持向量机中核参数γ、惩罚参数C的选取对其预测效果有一定影响[7],因此,拟采用混合智能算法选取合适的支持向量机参数组合.
2 粒子群算法
粒子群算法(particle swarm optimization,PSO)将搜索最优解的过程看成是鸟类觅食活动,用粒子来模拟鸟类个体,每个粒子可视为n维搜索空间中的一个搜索个体,粒子的当前位置即为对应优化问题的一个候选解,粒子的飞行过程即为该个体的搜索过程.粒子的飞行速度可以根据粒子的历史最优位置和种群的历史最优位置进行动态调整.粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向.每个粒子单独搜寻的最优解叫做个体极值pbest,当前全局最优解即为粒子群中最优的个体极值.通过不断的迭代,粒子更新速度和位置,最终可以得到满足终止条件的最优解.
设一个包含M个粒子的粒子群在n维空间中进行搜索,将食物视为最优解,所有的粒子都清楚它们自身的位置.同时,能够依据适应度的值判断位置的优劣.粒子根据它们自身的经验和群体的经验更新粒子的速度和方向,直到能够达到停止条件为止.首先对i个粒子进行初始化,粒子i的位置矢量和速度矢量分别记做xi=(xi1,xi2,…,xin)和vi=(vi1,vi2,…,vin,记为pi=(pi1,pi2,…,pin),群体最优解为gbest,记为gi=(gi1,gi2,…,gin),在迭代期间,粒子i在n维子空间中的飞行速度和位置按下式调整:
vid=wvid+c1r1(pid-xid)+c2r2(pgd-xid),
(5)
xid=xid+vid,
(6)
(7)
式中:i=1,2,…,M;d=1,2,…,n;w为惯性权重;c1和c2是加速常数;r1和r2是[0,1]之间的随机数;vmax,vmin是粒子运动速度的限制范围.
在PSO的搜索过程中,粒子之间会互相分享信息而得到最优解.这样的分享方式可以让粒子在刚开始的时候拥有较快的收敛速度,但是在迭代的后期,粒子的更新受到限制,速度变慢,陷入局部最优的可能性增大.因此,需要针对这些问题对PSO算法加以改进.
3 混合智能算法
单一的群智能算法通常会存在许多局限性,例如蚁群算法不能处理连续优化问题,混合蛙跳算法易陷入局部最优等问题.因此很多学者通过融合多种算法特性来改进这些缺陷,同时提出了混合群智能算法优化支持向量机参数[8-12]的方法.群智能算法之间的混合使用,可以帮助寻找到更优的参数组合,并且更大程度地提高SVM 的预测与分类精度,多数混合群智能算法在SVM 参数优化的试验结果中表明,改进的算法不仅具备了其中一种群智能算法的优点,还具备其他群智能算法的优点,比单一的算法更加可行且有效.
遗传算法具有更好的全局寻优能力以及能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则.而人工鱼群算法具有寻优速度快、全局寻优能力以及较强的并行处理能力等优点.两者皆能改善粒子群算法易于陷入局部最优的缺陷,因此采用这两种算法对粒子群算法进行改进.针对PSO易于陷入局部最优解的缺陷,文中提出一种引入内部交叉变异与外部竞争机制的算法.
3.1 改进的PSO算法
PSO算法提高个体的方式是分享个体之间的有用信息以及个体的自学习.改进的PSO算法在个体提高以后,采用GA算法中的交叉和变异步骤,得到更加优秀的下一代群体,流程图如图1所示.新的算法既保证了粒子群的个体之间交流与位置转移的思想,又同时融合了遗传算法强大的全局搜索性能.这样,经过改进的算法充分利用了粒子群算法中的种群的信息和个体的信息,其寻优过程更有效率,所得到的结果精度更高.
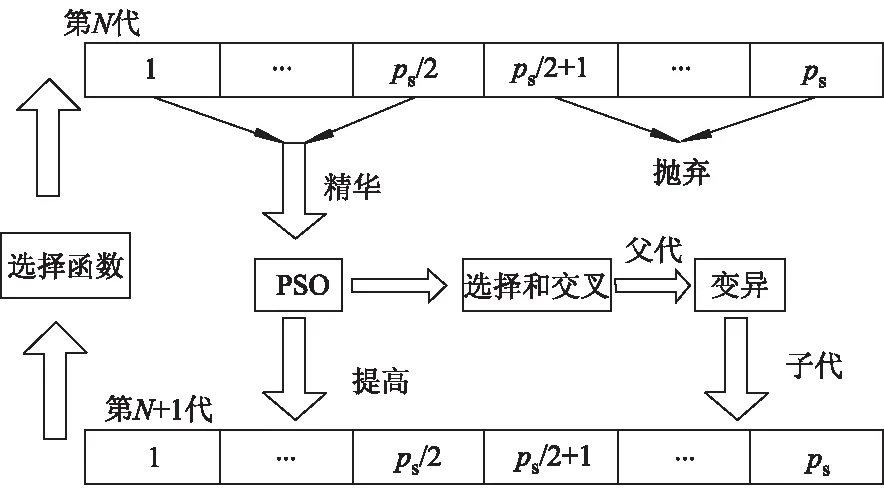
图1 改进的粒子群算法流程图
改进的粒子群算法首先计算适应度函数值,对群体中的个体按适应度函数值的大小进行排序,再采用PSO算法对群体中的优秀个体进行提高,提高以后的个体被保留并进入下一代,其他适应度函数值差的个体则被淘汰.对已经提高的优秀个体再通过交叉和变异步骤得到剩下的个体.采用新方法得到的下一代个体比采用单一算法得到的下一代个体要优秀,不过这仍然是在一个种群中不断优化的内部竞争.
3.2 GAPSO和AFSA混合优化算法
人工鱼群算法(artificial fish-swarm algorithm,AFSA) 是一种基于模拟鱼群行为的随机搜索优化算法.它是说在一片水域中,鱼往往能自行或尾随其他鱼找到营养物质多的地方,因而鱼生存数目最多的地方一般就是本水域中营养物质最多的地方.人工鱼群算法就是根据仿生学特点,通过构造人工鱼来模仿鱼群的觅食、聚群及追尾行为,从而实现寻优,过程如下:
(8)
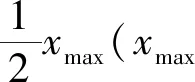
为了加强个体之间的竞争压力,将个体的内部的竞争扩大到不同种群之间,将进化种群中的最优解的个体与随机组成的种群的最优解形成竞争.引入AFSA算法,通过族外竞争使目标函数值向全局最优解快速收敛.既利用了PSO算法追逐当前全局最优点来保证算法的收敛性,又利用人工鱼群算法的搜索随机性,加大了搜索范围,克服了PSO陷入局部极值点和AFSA算法运行速度慢等缺点.
GAPSO-AFSA算法的基本思想:将种群一分为二成A,B两个子群体,在每次的迭代中,A子群体利用改进的粒子群算法进化,而B子群体利用人工鱼群算法进化,然后通过对比两种进化算法的最优解得到整个群体中能够搜索到的最优解,流程如图2所示.这种算法既利用了改进的粒子群算法追逐当前全局最优点来保证算法的收敛性,又利用人工鱼群算法的搜索随机性,加大了算法的搜索范围,同时克服了PSO易陷入局部极值点和 AFSA 算法寻优精度不高等缺点,从而兼顾了算法的优化精度和效率,提高了算法的优化性能.
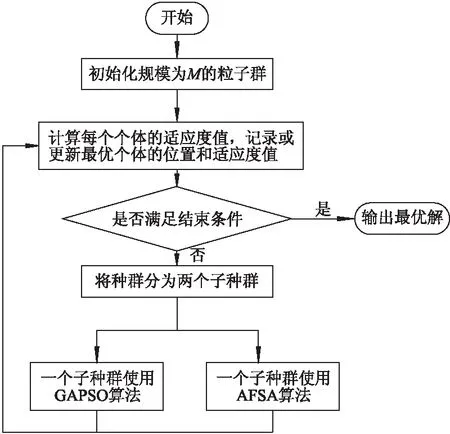
图2 GAPSO-AFSA算法的流程图
3.3 GAPSO-AFSA优化的SVM预测模型
GAPSO-AFSA预测模型基本流程:
1) 对所有样本数据进行初始化.
2) 人工鱼群算法的思想:
① 设定鱼群的参数,包括鱼群规模m,最大迭代次数iter,最大尝试次数try_number,最大移动步长step,拥挤度因子δ等;
② 计算初始适应度值,把最优值存储起来;
③ 计算得到追尾行为和群聚行为的值,鱼的前进方向即为最优的行为值,同时与存储起来的最优值进行比较,如果优于存储起来的最优值则更新最优解;
④ 判断是否已经满足最大迭代次数,若已经满足则终止寻优过程,输出存储的最优值;否则,返回到②,继续运行.
3) GAPSO算法的基本思想:
① 生成初始种群,初始化种群,赋值种群中的参数;
② 计算种群中个体的初始适应度值,按适应度的值大小进行排序,保留更优的前ps/2个个体,抛弃后ps/2个个体;
③ 对前ps/2中的个体进行提高和进化并直接进入下一代;
④ 对下一代的剩下的ps/2个体,从已经进化后的ps/2个个体中按竞争选择方法,先随机选择2个较为优秀的个体,然后比较2个个体的适应度函数值大小,选择其中适应度函数值大的作为父体,再以同样的方式选择一个母体,最后以概率pc进行交叉,生成2个新的个体,重复上述过程直到获得ps/2个个体;
⑤ 对于选择交叉后获得的ps/2个个体以概率pm进行变异.变异操作完后,把ps/2个个体带入到下一代种群中再次竞争;
⑥ 判断是否达到迭代次数或者当前种群是否满足预设的条件,若满足则终止寻优,否则跳转回②.
4) 比较2种算法所取得的惩罚系数C和核参数γ的值,取最佳组合(C,γ).
5) 将最优(C,γ)带入到SVM预测模型中对数据进行预测试验.
4 试验结果与分析
文中使用的数据源自于国家统计局历年粮食报告(中国1949—2016年的粮食产量),如图3所示.选择1949年至2016年我国粮食的产量数据及影响其产量的因素作为数据集,数据源自中国国家统计局网站.选取了全国总体统计数据以及江苏、山西、黑龙江等多个省或直辖市的地区统计数据,由于影响粮食产量的因素众多,并且各因素之间还有相互影响的可能,因此在综合考虑以后,选择粮食播种面积、农作物有效灌溉面积、施用农用化肥的总量、本年度末所拥有的农业机械总动力、农村用电总量以及从事农业的劳动力共六项指标作为函数的输入值,以粮食总产量这一项作为整个函数的输出.
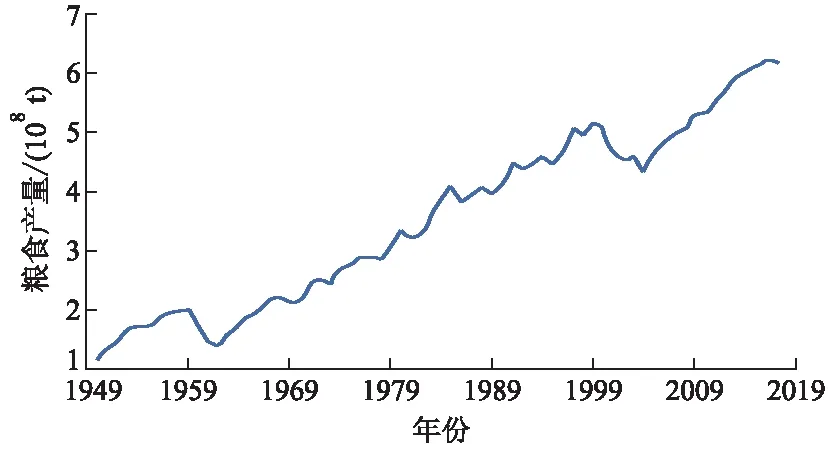
图3 中国实际粮食产量曲线图
选取1949—1999 年的粮食产量数据作为训练数据,以每5年的数据预测下一年的数据,分别采用BP,PSO-SVM[11],GAPSO-AFSA算法对数据进行训练,同时将训练好的预测模型带入试验数据进行测试.对于混合智能算法选取合适的支持向量机的参数组合,其中径向基核参数γ搜索范围为[0.1,10],惩罚参数C的搜索范围为[1,500],设定染色体种群大小为40,并设定最大进化代数为160,交叉率与变异率分别为0.6,0.003,try_number=3,Visual和Step按式(8)动态调整,s=3.
将得到的最优参数组合赋予支持向量机以获得优化的支持向量机预测模型.以BP神经网络、PSO-SVM预测模型与文中GAPSO-AFSA预测模型进行对比分析,三者的预测产量与实际值如图4所示,BP神经网络平均相对误差为1.034 0,PSO-SVM预测模型的平均相对误差为0.020 4,而GAPSO-AFSA平均相对误差仅为0.014 1.表1为2005—2016年GAPSO-AFSA预测模型及PSO-SVM预测模型的差值比较.由表可见,基于混合智能算法的支持向量机的农业经济预测模型比其他单一预测模型有着更高的预测精度.
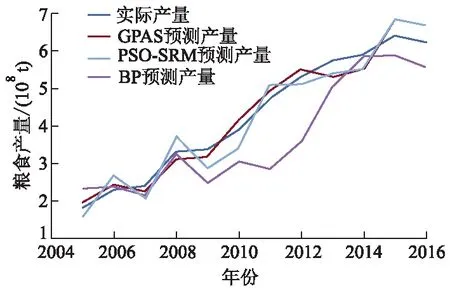
图4 各算法预测的粮食产量以及实际产量对比图
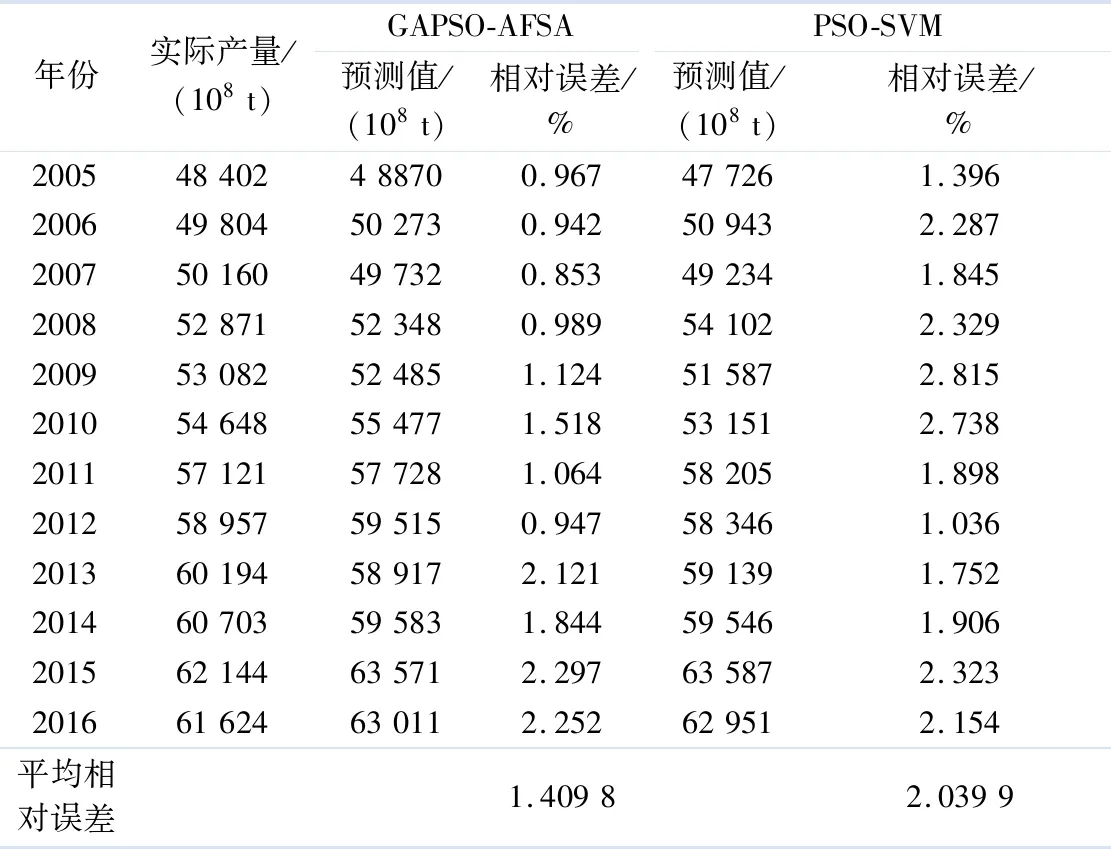
表1 PSO-SVM和GAPSO-AFSA预测模型对比
为了进一步验证文中所提出的GAPSO-AFSA预测模型的优越性,又分别采用GAPSO-AFSA与PSO-SVM 预测模型对江苏省粮食产量、黑龙江省粮食产量、山西省粮食产量等多个案例进行测试与分析,测试结果表明采用PSO-SVM预测粮食产量的平均相对误差处于0.02 ~ 0.05,而基于GAPSO-AFSA的粮食产量预测的平均相对误差处于0.007 ~ 0.024,可以看出,基于混合智能算分的支持向量机预测模型有着更高的预测精度.
5 结 论
提出了基于混合智能算法的支持向量机的农业经济预测方法,支持向量机通过一个映射函数将输入数据非线性地映射到高维特征空间,并在此高维空间进行回归,通过混合智能算法选取合适的支持向量机参数组合,以PSO-SVM预测模型与文中的GAPSO-AFSA预测模型进行对比分析.试验结果表明,基于混合智能算法的支持向量机的粮食产量预测模型比基于单一智能算法支持向量机的预测模型有着更高预测精度.与此同时,通过此次试验,以下两点改进及创新还有待后续研究:①虽然引入人工鱼群算法提高了算法的精度,但此算法的时间复杂度较高,在迭代的过程中消耗的时间稍长,因此在未来的工作中可对其进行改进,以提高算法的效率;② 由于影响粮食产量因素较多也比较复杂,后续工作中还将引入多目标算法,通过多目标对多个因素的最优规划来得到更精确的预测值.
