基于深度自动编码器的小麦种子聚类识别方法
2020-06-17刘赛雄
刘赛雄,耿 霞,陆 虎
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
中国是一个人口大国,也是一个农业大国,小麦作为第二大粮食作物不仅要满足人们的日常饮食需求,还在确保粮食安全及实现国民经济发展方面起着举足轻重的作用.因此,发展一套农产品数据检测和分析系统是一件迫在眉睫的事情.以前,农业生产的相关检测工作都是依靠人工视觉进行主观判断,该方法主观性强,缺乏科学依据,并且极其费时费力.随着计算机的迅速发展,基于机器学习和深度学习的农产品品质检测与分级成为了国内外研究的热门话题[1-4].面对海量的数据,首先需要利用分类或聚类的方法对数据进行划分.分类是有监督的方法,它需要用到类别标签,有监督则意味着需要先验的人为判断诊断来指导分类,因此,具有非常大的主观性.无监督的聚类分析是一种合理地对原始数据进行划分的方法,它不需要用到标签,而是数据驱动.
经典聚类算法如模糊聚类(FCM)和K均值聚类(K-means)往往适合于低维度、低特征数据[5-8].面对高维度的数据集,出现了许多改进的聚类算法.模糊核聚类是聚类算法在模糊集理论上引入核函数作为映射的一种聚类算法.最常见的模糊核聚类是高斯核模糊聚类算法,因其较好的聚类性能而被广泛应用[9-12].上述聚类算法都是直接在数据集上进行分析,无法对数据特征进行有效提取,近年来,深度学习网络作为有效自动特征分析方法在各种行业中得到了应用[13-16],尤其是自动编码器网络.自动编码器是近几年在特征提取中比较流行的研究方法,相比于误差反向传播算法(BP)、循环神经网络(RNN)等[17-19],它是无监督的.但是现有的基于自动编码器的聚类分析方法结合聚类与自动编码来划分数据的类别时,它们往往是先把数据特征提取出来,然后再用聚类方法进行类别划分[6],这些聚类方法需要分两步实施.
为了避免这种两步走和盲目的先提取特征再聚类的方法,文中提出在自动编码器最中间层新建一层,把模糊核聚类作为最中间一层嵌入到自动编码器中去,并利用新的损失函数进行反向传播,最终实现聚类结果.文中用新的损失函数将高斯核模糊聚类嵌入自动编码器中,并将其应用到农产品小麦数据的无监督识别中.
1 相关算法
1.1 FCM算法
聚类的目标是根据每个数据点的隶属度将数据分成具有相似属性.FCM[4]作为一种经典的聚类算法,它被广泛地应用在医学成像、生物信息学、模式识别和数据挖掘中.与另一经典聚类算法K-means相比,它在球形集群体现了更加优越的性能[7].FCM算法的隶属度描述了属于聚类中心的数据点的不确定性,因此包含比清晰聚类更多的信息[8].
假设有N个数据点,输入xi∈{X1,X2…,XN},聚类数为C.FCM算法是通过每个数据xi到第c个群集中心vc的距离,以求取每一个xi的最佳的隶属度,从而可以获得每个数据点xi的所属类.FCM聚类算法优化目标公式为
(1)

1.2 GKFCM算法
FCM因使用欧氏距离,而对非线性数据没有较好的分类能力.基于此,文献[9]提出了核聚类(KFC),将聚类样本映射到高维的特征空间,使其能够线性可分,从而解决聚类样本不可分的问题.但该模糊核聚类为隐核模糊均值聚类,没有显式的聚类中心表示,对模糊指标较为敏感,而且只能对模糊隶属度初始化.文献[11]基于 Gauss 核函数的特殊性将核聚类目标函数中的核函数变更为 Gauss 核,并提出高斯核模糊聚类(GKFCM).

(2)
通过公式(2),目标函数可以展开到式(3):
(3)
且Ki≥0,1≤i≤N,1≤c≤C.

1.3 自动编码器
自动编码器[10]是近年来出现的一种深度学习网络结构,且在机器学习学科中很受欢迎.自动编码器是由输入层、隐藏层和输出层三层神经网络构成的神经网络,由编码层和解码层组成,顾名思义,编码层将输入数据编码为表示,解码层则将表示解码为具有最小损失的输出,重构误差是衡量学习效果的依据.
每层中的神经元激活可以被视为原始输入的表示,对于单个输入数据x,一般的自动编码器的计算过程为
(4)
其中自动编码器共有L层,其中l= 1,2,…,L,Yl表示第l层的神经元,由输入数据x推导而来,a和b是在训练自动编码器保存的参数部分.g(·)是Relu激活函数,Relu激活函数的定义如公式(5)所示:

(5)
2 文中算法
2.1 网络架构
文中提出的基于自动编码器的高斯核聚类模型如图1所示.

图1 提出的基于自动编码器的高斯核聚类模型
该过程主要有两个模块:自动编码器模块和自我表达层模块.自动编码器由输入、隐藏层、输出构成,而自我表达层模块则主要用来执行高斯核映射和模糊聚类.假设自动编码器有L层,设L/2=mid,自我表达层模块在自动编码器的部分用mid表示,文中在L/2层后嵌入一层自我表层模块后,则模型层数变为L+1层.其中该带自我表达层的自动编码器的前L/2层对输入进行编码,后L/2层进行解码,最中间层模块进行构建高斯核矩阵并执行聚类功能.
2.2 学习策略
文中使用的叠堆编码器是通过逐层训去噪自动编码器构建深度网络的原始策略,每一层都是训练自动编码器的隐藏层参数,以对每层输入的损坏后重建进行去噪[12].相比于自动编码器,叠堆编码器能更快速地迭代收敛.文中重写了公式(4),在公式(6)中,输入数据的格式X为N×d的矩阵,N为数量,小麦粒数,d为X的维度,即包含的属性.公式(6)描述的过程即为前向传播:
(6)
为了能让网络学习最佳参数,需要最小化重构数据与原始数据之间的误差,并使其趋向聚类.文中提出了一个全新的损失函数,该表达式为
(7)
在反向传播中,文中使用随机梯度下降来优化网络.为使网络的反向传播的推导更加清晰,文中用J表示公式(7),得到公式(8):
J=J1+J2+J3,
(8)
并且令J1,J2和J3表示方程式(7)中的第1,第2和第3项,得到公式(9):
(9)
为方便公式的进一步推进,让上述式(9)中的两项J1,J2分别对Z求导,并写作公式(10):
(10)


(11)
(12)
为了训练网络,所有权重wl和偏差bl应该在训练之前随机初始化,根据链式法则,wl和bl的传播由下式给出:
(13)
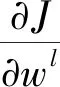
(14)
以上是带自我表达层自动编码器的推理过程,接下来将讨论自我表达层模块高斯核模糊聚类的推导过程.
2.3 自我表达层模块
自我表达层部分由上一层编码器的输出作为输入,是一个全过程的核模糊聚类,并传递出3个神经元到解码层部分,来进行自动编码器的反向传播.因此在该过程中,只要求解聚类中心Vc和隶属度矩阵u,就可以知道最后的聚类的类别.现在文中来单独求解损失函数中的J2部分,具体可以描述成求解公式(3)中的u和Vc,为方便表示,文中用T替代式(3),因此得到公式(15):
(15)
令公式(15)对聚类中心vc求偏导,并令求导结果等于0,能够获得输入空间的核聚类中心点vc,求导表示为公式(16),所求vc为公式(17).
(16)
(17)
为顺利地求出u,固定v的值,同文献[15]一样,使用拉格朗日定理,并结合等式(18)后,求偏导数便可以解出uic.可以证明,所求uij如下:
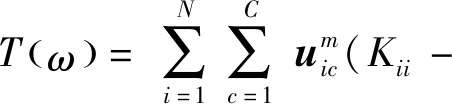
(18)
(19)
最后,文中提出的新的基于自动编码器网络聚类算法AE-KFC算法流程描述如下:
输入:数据X,λ1,λ2,学习率η,隶属度m,聚类数C,高斯核参数σ,阈值ε.
1) 初始化的隶属度矩阵u和初始化聚类中心点vj.
2) 通过前向传播公式(6)得到自我表达层,进行高斯核映射.
3) 重复迭代.
4) 通过公式(17)更新聚类中心vj.
5) 通过公式(19)更新隶属度矩阵ut.

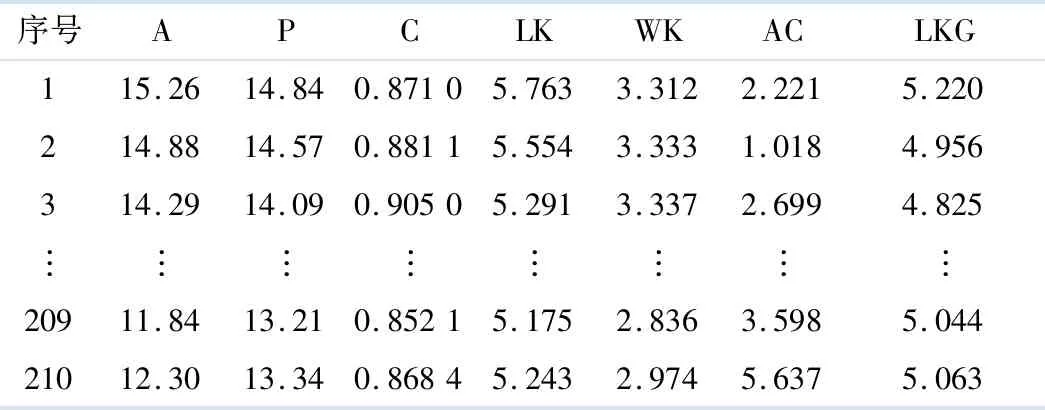
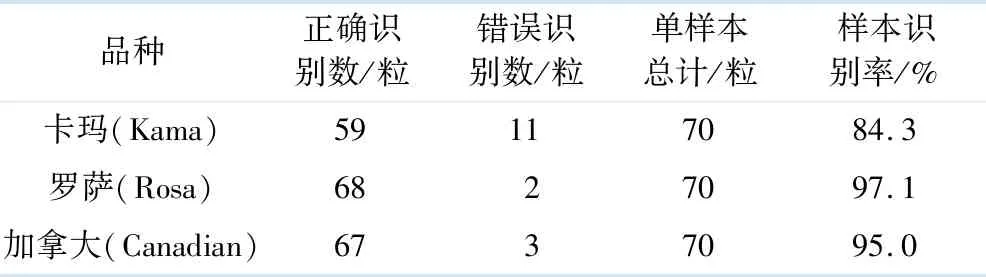
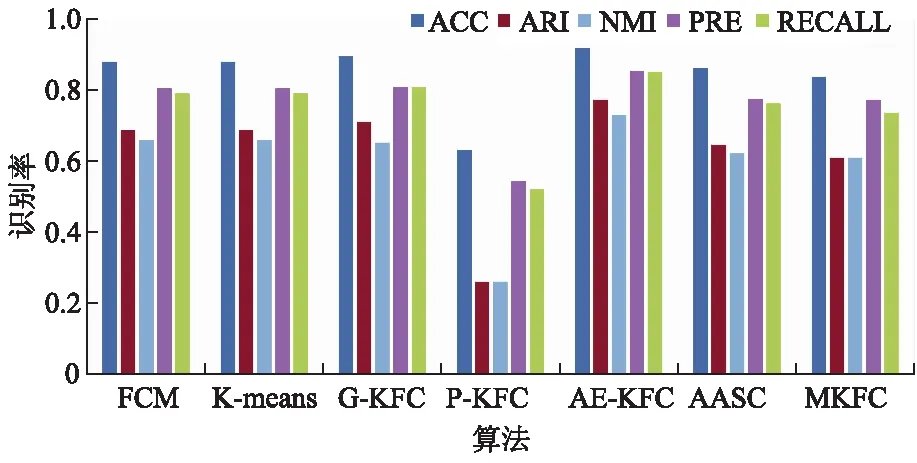
7) 通过前向传播公式(6),得到输出,当iter 8) 通过公式(10)计算梯度. 9) 用公式(14)更新的wl和bl. 10) 迭代结束,用更新好的w和b,通过前向传播,再训练一次编码部分,得到自我表达层. 11) 在最后一层的自我表达层部分实行步骤3)-6). 输出:聚类结果. 在本节中,将提出的AE-KFC应用于农产品的检测中,以 UCI国际常用标准数据集中的Seeds数据为试验数据,来测试文中提出算法的性能.该数据源自实验田的联合收割的小麦籽粒,且卢布林的波兰科学院农业物理研究对3种小麦品种的籽粒进行了记录与预处理.该Seeds数据共有3个不同品种的小麦籽粒:卡玛(Kama)、罗萨(Rosa)和加拿大(Canadian),每个品种的小麦粒各有70粒,共有210条样品记录,随机取自所在的试验样本中.每粒小麦通过软X射线技术得到7个几何参数:面积(area)、周长(perimeter)、紧凑度(compactness)、内核长度(length of kernel)、内核宽度(width of kernel)、偏度系数(asymmetry coefficient)及核槽长度(length of kernel groove).这7个几何参数值作为聚类的属性,构成了文中输入数据X中的d维度,也就是数据X是一个210×7的输入矩阵.文中把各个属性用它们的英文首字母表示,如表1所示. 表1 Seeds数据 与文献[15]中使用的高斯核函数一样,文中使用聚类中常用的高斯核作为基础核函数.高斯核函数可以表示为:Kij(xi,xj)=exp(-(xi·xj)T(xi·xi)/2σ2),σ=t0D0,D0是样本xi之间的最大距离,选取σ的值为1,并且隶属度m设置为1.08.把自动编码器的学习率设为0.001,迭代循环次数10 000次,层数设为2层.影响该算法的因素还包括超参数λ1和λ2,在本试验中,λ1设置为 1,λ2为0.5.以上参数均由大量试验获得.在这些参数下,AE-KFC在Seeds数据下取得最好的聚类效果. 考虑文献[13-14]中的度量标准,文中采用聚类准确度(ACC)、归一化信息(NMI) 、调整兰德系数(ARI)、精确度(PRE)、召回率(RECALL)5个度量标准综合评价AE-KFC算法的性能.所有这些度量值都落在[0,1]的区间内,它们的较大值表示更好的聚类结果.同时,为避免中间表达层部分隶属度矩阵和聚类中心的随机初始化等带来的误差,文中单独将试验运行20次后取均值,并且对比试验FCM,K-means等算法,也同样地运行了20次,以求得均值. 提出的AE-KFC算法在小麦籽粒上的识别率如表2所示.从表2可以看出,试验结果比较理想,其中罗萨小麦品种准确率高达97.1%,加拿大小麦品种的准确率高达95.0%.卡玛品种的结果不如罗萨和加拿大品种令人满意,这意味着在使用小麦种子的主要几何参数作为属性时,卡玛品种不能像罗萨和加拿大品种那样明显区分. 表2 AE-KFC算法在Seed数据集上的识别率 为了更加全面评估提出的AE-KFC算法在小麦粒种子识别上的性能,文中挑选了2种经典算法K-means和FCM作为对比.AE-KFC的自我表达层部分组成核函数是高斯核,因此单个的核聚类算法G-KFC也添加到文中的对比试验中.与此同时,多项式核模糊聚类P-KFC也被添加到对比试验中.并且,还将文中提出的模型与对非线性数据聚类效果较好的多核算法亲和聚合谱聚类(AASC)[17]、多核模糊聚类(MKFC)[15]比较.综合表现结果如图2所示. 图2 各算法综合表现的试验结果 由图2可以看出,AE-KFC的综合表现最好,且在ACC,ARI,NMI,PRE,RECALL上的平均值分别为0.919,0.774,0.730,0.855,0.851.AE-KFC在准确率上超出第二高的G-KFC约3.6%,超出经典聚类算法K-means和FCM算法4.1%.在图2 中不难发现,P-KFC在小麦种子识别上效果最差,MKFC算法的组成函数中因包含多项式核函数,因此性能表现一般. 影响AE-KFC算法的参数主要为超参数λ1,λ2.其中λ1用来调节最中间层的损失,λ2调节整个自动编码器的网络的大小.文中在其他参数如自动编码器层数,高斯核σ取值调到最优且不变的情况下,做了以下参数对比试验,试验结果如表3所示,主要对比了几组不同λ1,λ2值下的AE-KFC性能.从表3中可以看出,AE-KFC在λ1=1,λ2=0.5时,取得最好的试验结果. 表3 不同超参数λ1,λ2取值下的AE-KFC性能 提出了一种基于自动编码器的高斯核模糊聚类方法.该方法与现有的在自动编码器上进行研究的聚类方法不同,通过提出一个新的损失函数约束整个自动编码器网络,而该损失函数能使整个网络趋向于聚类,是一个基于自动编码器端到端的聚类算法.通过试验表明,AE-KFC算法在农产品小麦种子上有较高的聚类准确率.这也意味着该方法在农产品的识别检测中具有实际意义.3 试验结果及分析
3.1 数据集
3.2 试验设置
3.3 试验比较与讨论
3.4 参数分析

4 结 论
