基于改进遗传算法的区间光谱特征波长变量选择方法
2020-06-17冒智康张小鸣李绍稳
刘 鑫,冒智康,张小鸣,李绍稳,金 秀
(1.常州大学 信息科学与工程学院,江苏 常州 213164;2.安徽农业大学 信息与计算机学院,安徽 合肥 230036)
近红外光谱定量分析技术是利用化学计量学方法通过多元校正模型实现的.土壤有机物化学键结合的各种基团对近红外光谱不同波长产生振动倍频或合频吸收度光谱,反映了特定土壤养分质量分数的吸收特征,也是提取特征波长变量的基础.土壤样本近红外光谱数据包含有噪声信号、冗余数据,通过预处理技术可以有效消除噪声的影响,但同时也会损失部分有用信息[1].通过特征波长变量提取技术,可以有效剔除不相关的冗余数据和非线性干扰数据,提高校正模型的稳健性和预测能力.张世芝等[2]利用近红外光谱波长变量纯度和多元校正模型的回归系数绝对值构建特征波长变量选择权重,将权重值降序排序,按前向提取准则,从大至小依次带入PLS计算校正集的交叉验证均方根误差(root mean square error of cross validation,RMSECV),使RMSECV变小者保留,直到遍历所有变量后,保留的变量即是特征波长变量子集.该方法选择时间较长,而且前向选择难免选择冗余数据.章海亮等[3]应用遗传算法,在原始全光谱波长变量中选择若干个不同数量的特征波长变量子集,考察预测响应精度贡献率最大的特征波长子集,再利用连续投影算法将这个特征波长变量子集进一步筛选,减少为18个特征波长变量.该方法说明在全光谱中用遗传算法选出的特征波长变量之间还存在信息重叠,利用连续投影算法进一步去除了冗余信息,降低了模型运算量.宾俊等[4]研究比较了5种智能优化算法:蚁群优化(ant colony optimization,ACO)、遗传优化(genetic algorithm ,GA)、粒子群优化( particle swarm optimization,PSO)、随机青蛙(random frog,RF)和模拟退火(simulated annealing,SA)在烟叶氮和烟叶碱质量分数近红外光谱预测中选择特征波长变量的应用,结果表明:GA提取50个特征波长变量建模的偏最小二乘回归算法(PLS-R)预测性能优于其他4种优化算法,有较大的全局搜索优势,不仅简化了校正模型,而且预测精度较高.但是遗传算法从全光谱波长变量中选择特征波长变量,信息重叠问题较严重.采用基于机器学习算法的回归模型预测土壤氮质量分数、有机磷质量分数、有机碳质量分数都取得了一定研究成果[5].
基于区间光谱选择的间隔偏最小二乘(iPLS)算法是将全光谱(full spectrum,FS)分成等间隔的若干个区间光谱(interval spectrum,IS),在每个区间光谱上建立PLS-R模型,通过区间光谱模型的预测结果选择特征波长变量.根据区间选择策略的不同,iPLS算法又衍生出了一系列特征变量区间选择算法,如向前间隔PLS算法和向后间隔PLS算法等.这类算法在全光谱范围内选择特征波长变量,难以消除近红外光谱高度重叠和相邻特征变量之间共线性问题,但算法选择特征波长变量的稳定性一般较高.基于群智能优化算法的特征变量选择算法将PLS-R的预测均方根误差作为目标函数,随机搜索预测均方根误差最小的特征波长变量组合.但是,在全光谱范围内选择特征波长变量,选择弱相关性的波长变量概率较大,也容易陷入局部最优解.
文中通过建立近红外光谱波长变量纯度梯度和PLS-R的变量投影重要性系数相结合的区间光谱提取准则,构建与测量目标量相关性大的区间光谱,提出一种改进遗传算法的区间光谱特征波长变量选择方法,应用于近红外光谱土壤速效磷质量分数预测中,取得较高的预测精度.
1 光谱特征波长选择方法
1.1 全光谱波长变量纯度行向量
全光谱波长变量纯度行向量是由各个波长变量纯度值作为元素组成的行向量,一个波长变量纯度值定义为每个近红外光谱波长扫描所有样本产生的光谱数据列向量的标准差除以该光谱数据列向量的平均值,计算式为
(1)
式中:pi为第i个光谱变量纯度;σi,μi分别为第i个光谱波长下所有数据样本的数据标准差、平均值.若某一光谱波长变量纯度pi越大,说明该光谱波长变量所含信息量越大.
1.2 全光谱波长变量纯度梯度行向量
全光谱波长变量纯度梯度行向量是由全光谱波长变量纯度行向量中相邻两个纯度在水平方向从左到右的线性梯度作为元素组成的行向量,线性梯度计算公式为
(2)
式中:y1,yi,yn分别为波长变量纯度梯度向量中的第1,i,n列纯度梯度元素;xi(i=1,2,…,n)为全光谱变量纯度行向量的纯度元素.波长变量纯度梯度值大小反映该光谱波长变量纯度值的变化率大小,梯度值越大,说明光谱波长变量包含的有用信息越多,找到潜在特征波长变量的可能性越大.
1.3 全光谱波长变量投影重要性系数
采用偏最小二乘回归算法对校正集样本进行光谱数据分析,提取对预测目标量解释性最强的光谱波长变量.变量投影重要性系数(variable importance in projection,用VVIP表示)是PLS-R模型重要输出参数之一,它反映PLS-R模型对每个光谱波长变量的评分.一般认为当VVIP大于1时,该光谱波长变量对预测目标有重要的作用[6].相关计算式为
(3)
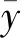
LLV值是PLS-R模型的输入参数.若LLV值较小,模型会出现欠拟合,均方根误差较大;若LLV值较大,模型会出现过拟合,均方误差也会增大,且模型较复杂.LLV值为5~10对应的模型均方根误差最小,故选取LLV=10建立PLS-R回归模型[7].
1.4 改进遗传优化算法
遗传算法最常用的决策变量编码方式有2种:二进制编码和实数编码.二进制编码编码形式简单,选择、交叉、变异操作易实现,但二进制编码与决策变量实数之间需要解码公式解码,存在解码误差较大、搜索速度慢、容易早熟收敛等缺点.实数编码用实数直接代表决策变量值,物理意义明确,可以直接表示实际问题的解.实数编码长度较短,不存在解码误差.但变异算子不像二进制编码有完备的理论基础,变异算子仅有表达形式,全局搜索能力较差,收敛速度较慢,最优解精度易受到变异算子控制等[8].
文中提出一种采用差分变异算子的改进遗传算法(improved genetic algorithms,iGA),差分变异算子公式为
G(i,j)=F×(E(r1,j)-E(r2,j))+E(i,j),
(4)
式中:G(i,j)为第i个个体的第j个染色体的子代(下一代)值;F为变异因子(即缩放因子);E(r1,j)为种群中随机产生的第r1个体的父代(上一代)第j个染色体;E(r2,j)为种群中随机产生的第r2个体的父代第j个染色体;E(i,j)为第i个个体的第j个染色体的父代值;E(r1,j)-E(r2,j)为父代任意两个个体之间的差异.在迭代初期,由于种群个体是随机产生的,一般任意两个个体之间的差异较大,则差分变异算子产生新的下一代的能力强,有利于跳出局部极值点,扩大搜索空间.当F大于1时,变异作用强,但收敛速度较慢;当F小于1时,变异作用弱,收敛速度较快.通常F取值为0.6~1.2.若新一代个体组成的决策变量代入适应度函数产生的适应度值优于父代个体,就通过选择算子取代父代个体,否则保留父代个体.
1.5 区间光谱提取与特征波长选择方法
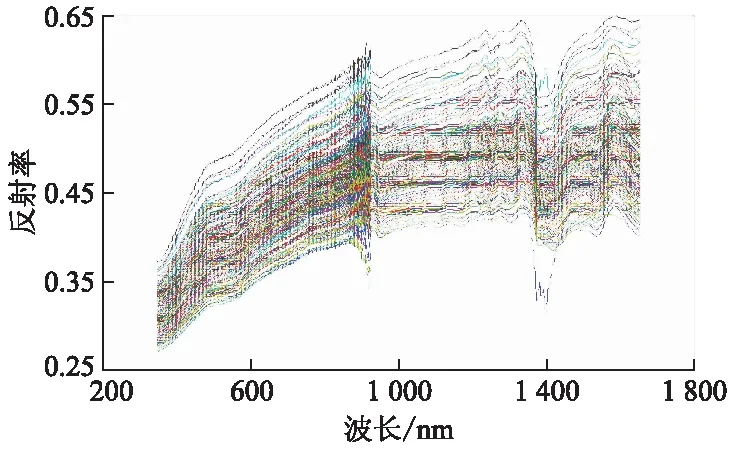
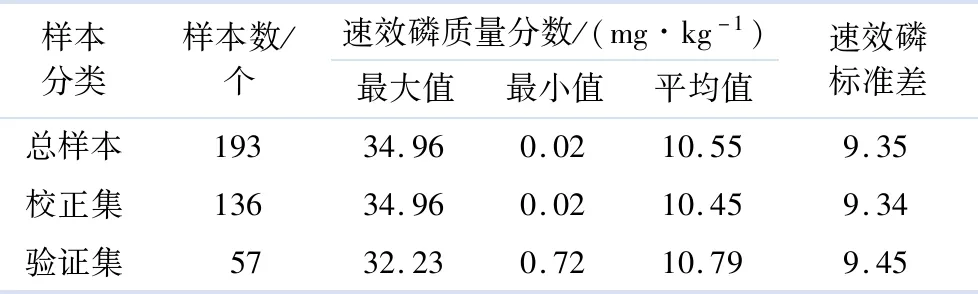
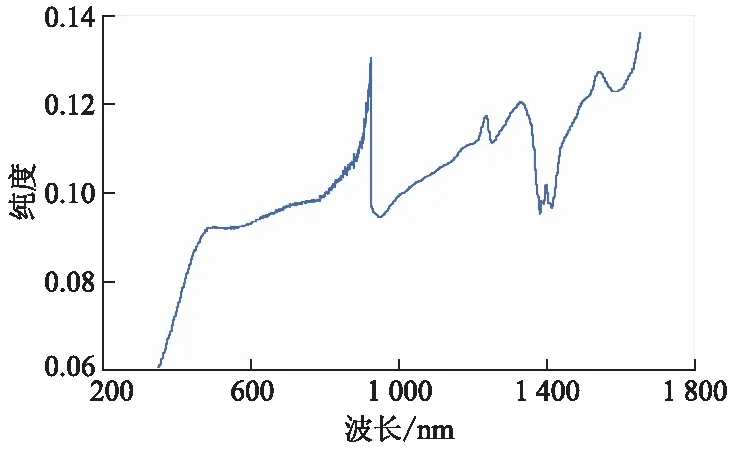
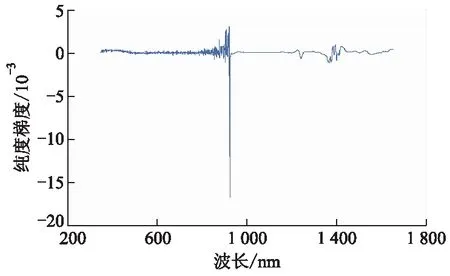
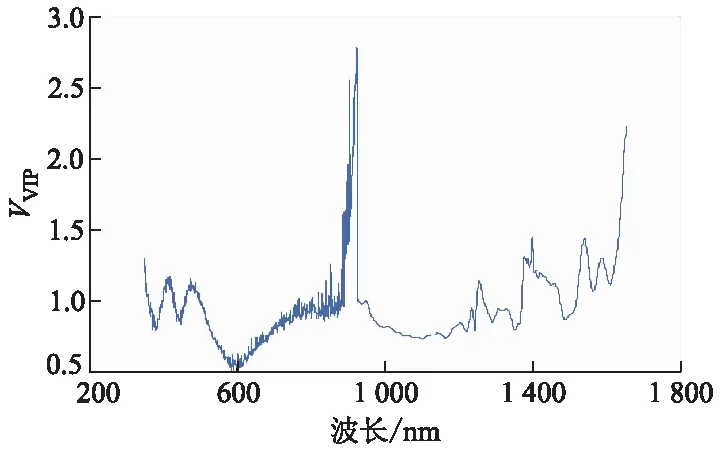
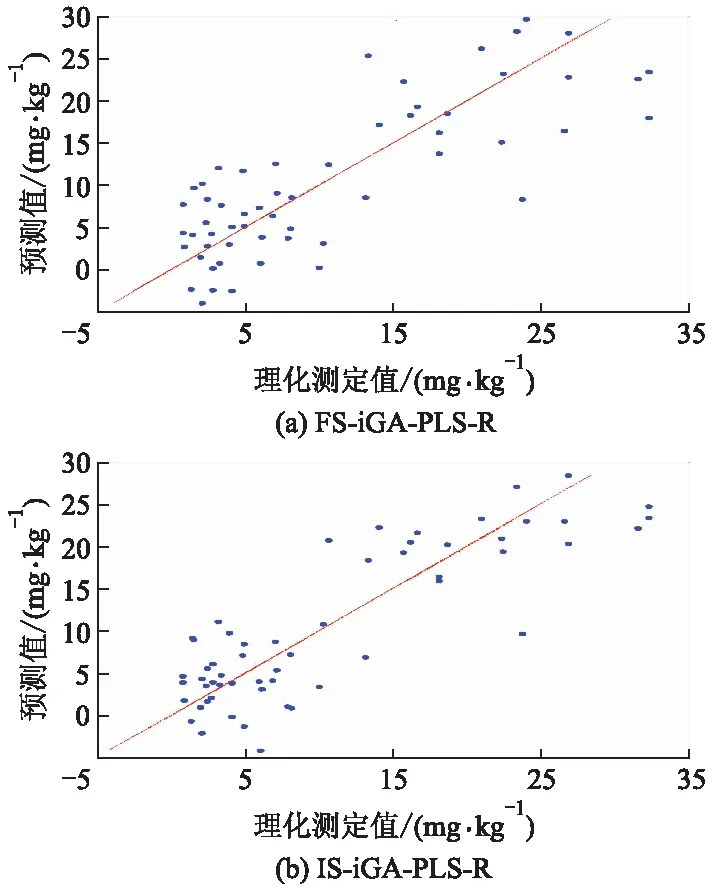
把全光谱划分为多个波长间隔可有两种方法:第1种是将全光谱人为等分为N个等间隔的波长间隔,属于现有技术;第2种是利用某种方法将全光谱划分为若干个不等间隔的波长间隔.文中利用波长变量线性纯度梯度的正负变化次数,将全光谱划分为s个不等间隔的波长间隔,再以全光谱每个波长变量投影重要性系数(VVIP)大于1作为重要波长光谱提取准则,从s个区间光谱中,提取任何包含VVIP大于1的k个区间光谱(k 每种土壤养分都有自己的吸收光谱波长,信号弱,谱带重叠,还包含环境噪声和无关信息等干扰信息.同一样本的光谱数据内部存在共线性关系,易产生数据冗余.在全光谱等间隔区间光谱中选择特征波长变量,难以消除近红外光谱高度重叠和相邻特征波长变量之间共线问题,容易陷入局部最优解,回归模型的预测精度和稳健性不高.利用波长变量对预测目标变量的贡献大小来划分波长间隔,并利用PLS-R模型的VVIP值大于给定阈值来选择对目标量起重要作用的波长变量,使改进遗传算法选择强相关性特征波长变量概率增大,有利于剔除共线性关系和冗余数据,降低弱相关性波长变量的选择概率,提高回归模型的预测精度和稳健性. 图1 改进遗传算法的区间光谱特征波长选择方法流程图 回归模型评价标准包括相对分析误差RRPD(标准偏差除以均方根误差)、决定系数(R2),计算式为 (5) (6) 3.1.1土壤样本采集与处理 193个土壤样本采自皖北蒙城县、埇桥区和怀远县3个地区的不同采样点,这几个地区的土壤为砂姜黑土.采用对角采样的方法将土壤采集后混合,去除其中的石块、秸秆和作物残根,作为其中一个采样点的样本,每个样本约1.5 kg,采样深度为0~20 cm.采集的土壤样本封存后在实验室内进行自然风干处理,研磨后过20目筛子,得到待测量的土壤样本粉末.将样本均匀分成2份,其中1份用于标准化学方法标定土壤速效磷质量分数,另1份用于土壤样本可见/近红外漫反射光谱数据的采集.使用碱解扩散法对193个样本的速效磷质量分数进行化学标定.使用海洋光学的OFS1700地物光谱仪和卤钨灯接触式反射探头扫描近红外光谱范围350~1 655 nm,光谱分辨率1 nm,利用黑白板校正得到光谱漫反射率,共采集1 306个光谱波长的漫反射率数据,构成1931 306阶光谱数据矩阵.193个土壤样本的原始近红外漫反射光谱图如图2所示. 图2 土壤样本近红外漫反射光谱图 由图2可见光谱波长在400~500 nm处反射率较低,在500~700 nm处有明显上升;在930 nm处有明显的波动,可能是土壤中铁氧化物(针铁矿、赤铁矿)对光谱吸收引起的[9];在1 400 nm处有明显吸收峰,可能是土壤样品中残留水分的影响[10].光谱图像出现较多毛刺,伴有较多噪声,可能的原因是土壤颗粒大小不均,且均匀度不同,光谱仪受到高频噪声干扰,以及光谱仪的基线漂移等等. 3.1.2校正集与验证集划分 采用浓度梯度法将193个土壤数据样本按照速效磷质量分数参考值进行排序,以7 ∶3的比例划分为136个土壤数据样本作为校正集,57个土壤数据样本作为验证集.校正集和验证集的均值、标准差等统计量数据如表1所示. 表1 速效磷质量分数样本校正集和验证集数据统计表 由表1可见,速效磷质量分数的最大值和最小值之间相差34.94,平均值为10.55,离散程度较大,但校正集与验证集划分有相近的标准差分布特征,说明划分出的校正集与验证集可以代表整体数据集的分布特征.校正集136个样本约占总样本数的70%,用于土壤速效氮质量分数回归模型建模.验证集57个样本,用于预测模型的评价参数验证,对回归模型预测优劣进行评价. 土壤速效磷校正集全光谱波长变量纯度曲线见图3. 图3 土壤速效磷校正集全光谱波长变量纯度曲线 由图3可见,在全光谱范围(350~1 655 nm)内变量纯度曲线总体波动明显,变量纯度最小值约为0.070,最大值约为0.098.在光谱波长350~500 nm时有1个峰值,在500~800 nm时有1个谷值,在800~1 000 nm时有1个峰值和1个谷值,在1 000~1 655 nm时有多个峰值和多个谷值.其中峰谷过渡曲线最陡峭的波长点在930 nm和1 400 nm附近,与图2中明显波动点的分析相吻合.这说明近红外光谱数据组成信息成分复杂,可以同时测定多组土壤营养成分和其他矿物质质量分数,但是为了减少非目标量对目标量预测的干扰和不利影响,有必要提取对目标量预测贡献大的特征波长变量. 土壤速效磷校正集全光谱波长变量纯度梯度曲线见图4. 图4 土壤速效磷校正集全光谱波长变量纯度梯度曲线 由图4可见,在光谱波长350~900 nm时,波长变量纯度梯度的变化频率较高,说明这个波段包含较多对预测目标量贡献大的潜在特征波长变量.在900~1 100 nm时波长变量纯度梯度的变化频率较低,说明这个波段包含较少的潜在特征波长变量.在1400~1 655 nm时波长变量纯度梯度的变化频率也较高,说明这个波段包含较多的潜在特征波长变量. 土壤速效磷校正集全光谱波长变量PLS-R模型的VVIP曲线见图5. 图5 土壤速效磷校正集全光谱PLS回归VVIP曲线 由图5可见,波长变量VVIP>1的波段位于350~500 nm,800~950 nm,1 300 nm周边,1 400~1 655 nm,这些波段的波长变量对目标量预测的解释性较强. 对校正集136个样本和验证集57个样本进行土壤速效磷PLS-R回归模型训练和验证,分为全光谱波长变量PLS-R回归模型(FS-PLS-R)、全光谱iGA选择特征波长变量PLS-R回归模型(FS-iGA-PLS-R)、区间光谱iGA选择特征变量PLS-R回归模型(IS-iGA-PLS-R).其中,区间光谱是通过光谱波长变量纯度梯度和变量投影重要性系数选择方法在全光谱中筛选.PLS-R回归模型评价参数试验结果如表2所示. 表2 PLS-R回归模型评价参数试验结果 由表2可见,FS-PLS-R预测性能最差,其次为FS-iGA-PLS-R,IS- iGA-PLS-R最优. 土壤速效磷验证集57个样本的参考方法测定值与FS-iGA-PLS-R模型、IS-iGA- PLS-R模型预测值之间的对比效果图如图6所示. 图6 土壤速效磷验证集参考方法测定值与预测值对比图 从图6可见,全光谱iGA选择的特征波长变量PLS-R回归模型测预值在Y=X一元回归线周边比在区间光谱iGA选择的特征波长变量PLS回归模型测预值更松散,说明iGA在区间光谱中选择特征波长变量建模比在全光谱中选择建模具有更好的解释能力和预测精度. 用光谱波长变量纯度梯度和变量投影重要性系数作为波长间隔划分与提取准则,提取出31个重要波长间隔,波长分布在350~399,480~488,840~1 122,1 237~1 502,1 510~1 655 nm的不连续波长间隔中,与文献[7]中所述对土壤速效磷预测有重要作用波长大致相同,证明了波长间隔提取的正确性.一个光谱波长变量的非零纯度梯度可能因土壤有机质O—H基团的吸收度所致.光谱波长变量纯度梯度最陡峭峰值位于的波长间隔是840~1 122 nm.土壤速效磷质量分数是通过土壤有机化合物近红外光谱间接测量的[10]. 在全光谱中用FS-iGA-PLS-R模型选择的25个特征波长变量中,位于光谱波长变量纯度梯度最大陡峭峰值附近的波长值共有6个,分别是815,865,901,1 066,1 102,1 303 nm. 在区间光谱中用IS-iGA-PLS-R模型选择的25个特征波长变量中,位于光谱波长变量纯度梯度最大陡峭峰值附近的波长值共有13个,分别是855,940,994,1 018,1 023,1 085,1 102,1 112,1 124,1 129,1 144,1 166,1 198 nm.可见,对于提取相同数量的特征波长变量,在光谱波长变量纯度梯度最大陡峭峰值附近波长区间中,IS-iGA-PLS-R模型比FS-iGA-PLS-R模型能多选出1倍以上数量的特征波长变量.在光谱变量纯度梯度最大陡峭峰值附近波长区间中,含有与目标预测量相关的更多有用信息,从该波长区间提取更多的特征波长变量,有利于提高回归模型的预测精度. 区间光谱iGA选择特征波长变量SVM回归模型(IS-iGA-SVM)与文献[7]的PLS-BP神经网络回归模型(PLS-BPNN)对土壤速效磷的预测试验结果比较如表3所示. 表3 土壤速效磷的IS-iGA-SVM与文献[7]的PLS-BPNN模型评价参数比较 由表3可见,IS-iGA-PLS-R模型选择的特征波长变量运用到其他非线性回归模型中,预测精度与PLS-BPNN模型的相当,但区间光谱改进遗传算法选择的特征波长变量使预测模型结构更加简单,计算量更小,具有更好的解释性和实用性.由于波长变量与目标量之间存在非线性关系,采用单一回归模型预测精度很难再有提高.必须用本方法选择的特征波长变量结合集成模型才能进一步提高预测精度. 粒子群优化算法在找寻最优解效率上要好于遗传算法,但是粒子群优化算法严重依赖参数大小和初始种群的设置,容易陷入局部最优解,算法不稳定.而改进遗传算法克服了这个缺点,且不会陷入局部最优解.虽然针对粒子群算法容易陷入局部最优解的状况,出现很多改进粒子群算法,但改进粒子群算法的设置参数多,算法实现复杂.而改进遗传算法的设置参数少,算法实现简单.全局搜索能力强,收敛速度较快,克服了传统遗传算法的缺点. 1) 提出一种重要区间光谱提取和区间光谱改进遗传算法的特征波长选择方法,提取对速效磷质量分数预测贡献大的重要区间光谱,使改进遗传算法在重要区间光谱选择潜在特征波长变量的概率大大增加,解决了在全光谱选择潜在特征波长变量概率不高的问题. 2) 25个特征波长变量的IS-iGA-PLS-R模型预测性能优于全光谱波长变量PLS-R模型,同时与文献[7]的PLS-BPNN模型模型预测精度相当. 3) IS-iGA-PLS-R模型能够有效减少高光谱数据冗余和共线性影响,简化预测模型,提高预测精度,可用于土壤速效磷的定量预测. 4) 下一步研究利用集成模型进一步提高预测精度和稳健性.
2 回归模型评价标准
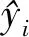
3 试验结果与分析
3.1 土壤样本与光谱数据集
3.2 建模方法试验结果

3.3 预测模型分析与比较

3.4 改进遗传算法与粒子群算法的比较分析
4 结 论
