基于Copula EDA优化BP神经网络的表面粗糙度预测
2020-06-17裴宏杰陈钰荧李公安刘成石王贵成
裴宏杰,陈钰荧,李公安,刘成石,王贵成
(江苏大学 机械工程学院,江苏 镇江 212013)
表面粗糙度作为机械加工表面质量的一个重要评价指标,能够实现对其在线预测预报,对智能切削具有重要的意义.C.A.VAN LUTTERVELT等[1]指出了早期理论模型存在的局限性.因此人工智能算法,如小波包分析[2-3]、贝叶斯网络[4]、多维云[5]和支持向量机法[6]等方法被广泛应用于表面粗糙度的预测分析.而神经网络由于具有一定的优势,因此采用神经网络混合算法实现预测预报的研究较多.N.S.K.VARMA等[7]在外圆磨削AISI 1040钢试验中,基于神经网络和自适应神经模糊系统(ANFIS)来预测切削速度、切削深度和进给速率的输出响应,结果表明ANFIS预测精度更高,达到91%,同时切削深度的影响程度最大.G.KANT等[8]通过耦合人工神经网络和遗传算法两种智能方法,开发了一种全新的表面粗糙度预测和优化模型,试验证明该模型平均误差只有4.11%.HUANG P.B.[9]为了解决神经网络和模糊逻辑的缺点,利用神经辅助方法为模型生成模糊IF-THEN规则,构成了一个新的智能神经模糊进程的表面粗糙度预测模型,大大提高了预测精度.CHEN Y.N.等[10]利用嵌套的人工神经网络(ANN),建立表面粗糙度预测模型,基本思路是先将切削参数作为输入参数,得到切削力和振幅数据,然后再将所有输出值转给下一个人工神经网络,试验结果表明,基于相同试验数据,该模型预测效果比常规ANN和响应曲面法(RSM)模型更好.A.ARRIANDIAGA等[11]基于递归神经网络,考虑新磨粒的产生及砂轮磨损,构建了表面粗糙度动态模型,试验效果较好.
Copula分布估计算法(estimation of distribution algorithm,EDA)[12]是将Copula理论和分布估计算法相结合,不仅能够解决分布估计算法中建立概率分布模型过程较为繁琐的问题,同时也能够提高估计算法的效率和精度.Copula EDA是基于全局来寻找最优解,但速度较慢,且难以确定解的最优位置,而BP算法收敛速度慢,容易陷入局部极小值.为此,笔者将两种方法相结合,采用Copula EDA方法对铣削加工粗糙度的预测、预报结果进行分析.
1 试验方法
机床使用MazakVTC-16A三轴立式加工中心.冷却装置采用Accu-Lube MQL喷雾系统.刀片为ISCAR HM90 APKT 1003PDR IC928硬质合金涂层铣削刀片,刀杆为ISCAR HM90A-D20-3-C20的高精度硬质合金刀杆,刀具主偏角90°,副偏角12°,前角5°,后角11°,刃倾角-3°,坡走铣角32°.工件选用130 mm×50 mm×20 mm的45#钢块料,工件两侧开有两个水平间距为100 mm、直径为12 mm的孔,并通过螺栓固定在测力仪上.
试验分成两组.表1为两组铣削试验设计及结果.第1组作为样本数据试验,采用控制变量法,3个控制因子分别为切削速度v(m·min-1)、每齿进给量fz(mm·z-1)、切削深度ap(mm),每个因子各有4个水平值,切削宽度ae为5 mm,如表1中序号1- 64的数据.第2组为验证试验,如表1中65-76的数据.
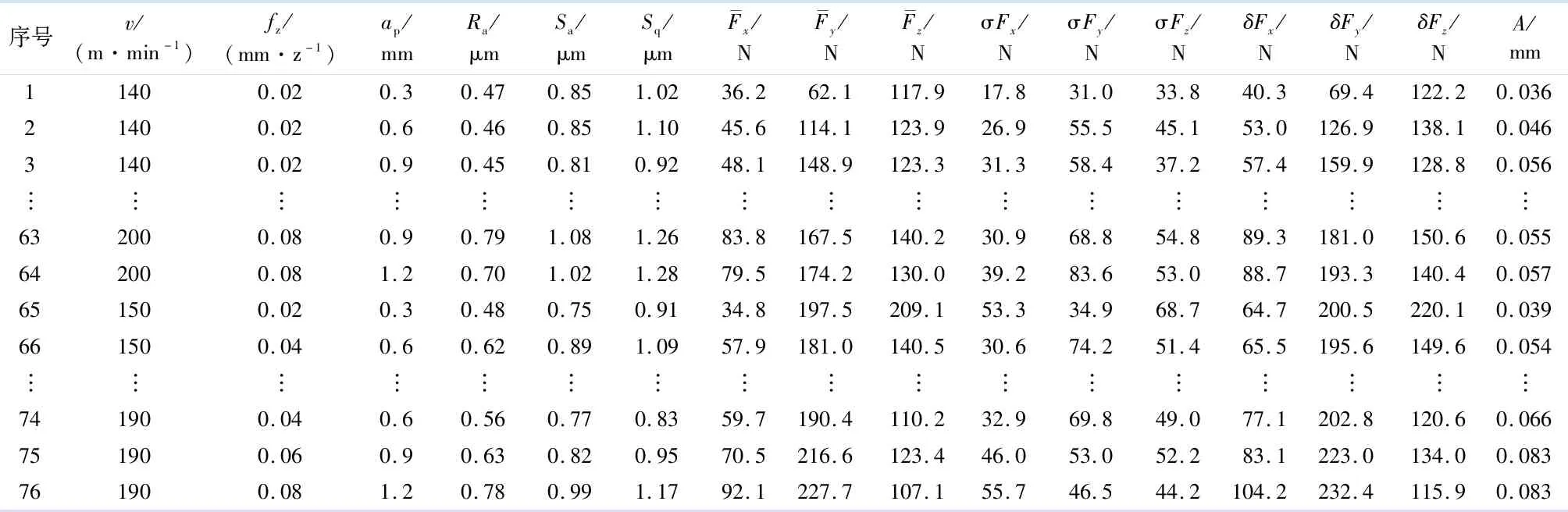
表1 铣削试验设计及结果
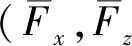
2 Copula EDA
EDA源于遗传算法,为反映变量的相关性,多变量相关的分布估计算法往往采用贝叶斯网络、高斯网络或马尔科夫网络等结构.但是,这些网络结构的学习本身要花费大量时间.Copula EDA[12]是将Copula理论和分布估计算法相结合,不仅能够解决分布估计算法中建立概率分布模型的过于繁琐问题,同时也能够提高估计算法的效率和精度.
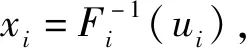
① 随机生成符合均匀分布函数的P个初始群体.
② 根据适应值,运用某种选择策略找到适应值最好的s个个体,组成优势群体.
③ 对优势群体中的s个个体的随机变量Xj进行边缘分布估计,得到边缘分布函数,记作Fj.
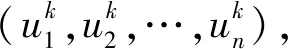
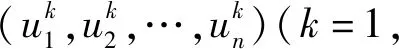
3 表面粗糙度预测
3.1 输入参数的选择
为了预测粗糙度,需要选用相关性最高的输入参数,因此需要定量评估相关性.选用Kendall秩相关系数τ作为评价指标.τ的定义如下:设(X1,Y1)和(X2,Y2)为独立同分布,τ(X,Y)=P((X1-X2)×(Y1-Y2)>0)-P((X1-X2)(Y1-Y2)<0),τ能度量X与Y变化的一致性程度,τ为-1~1.τ=1表示X的变化与Y的变化完全一致;τ=-1表示X的变化与Y的反向变化完全一致;τ=0不能判断两者是否存在相关性.将相关数据带入到SPSS 20.0,计算得到τ值,如表2所示.
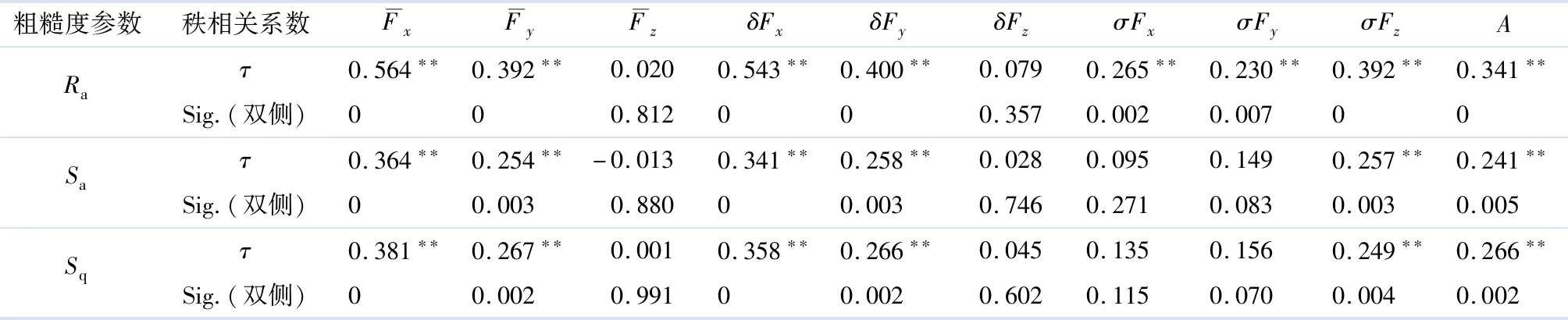
表2 Kendall秩相关系数值
注:Sig.为差异性显著的检验值;**表示在置信度(双测)为 0.01 时,相关性是显著的.
3.2 基于BP神经网络的预测方法
BP算法作为网络学习算法对网络中各层的连接权值进行训练,经过学习掌握样本信息的内在规律,能够把样本信息的规则和特点分布在神经网络的连接权上,使得算法适用于多层网络的学习,是一种监督学习算法.BP算法具有理论上逼近任意非线性连续函数的能力,信息处理的大部分问题都可以归纳为数学映射.因此,BP算法在神经网络研究中得到广泛应用.将BP神经网络应用于表面粗糙度预测的具体步骤如下:
① 样本数据预处理.将第1组试验结果中的切削力和表面粗糙度数据进行量纲一化,采用线性函数转换方法,y=2(x-xmin)/(xmax-xmin)-1,量纲一化后的数据分布在[-1,1]内,并将量纲一化后的切削力和表面粗糙度分别作为神经网络的输入和输出样本.

③ BP神经网络训练.在Matlab中通过编程实现对样本数据的训练,设置网络的迭代次数(net.trainParam.epochs=10 000)、网络的迭代步长(net.trainParam.show=50)、网络的训练目标(net.trainParam.goal=0.001)、网络的学习系数(net.trainParam.lr=0.05)和网络的动量因子(net.trainParam.mc=0.9),最终得到最优的网络参数(权值和阈值).
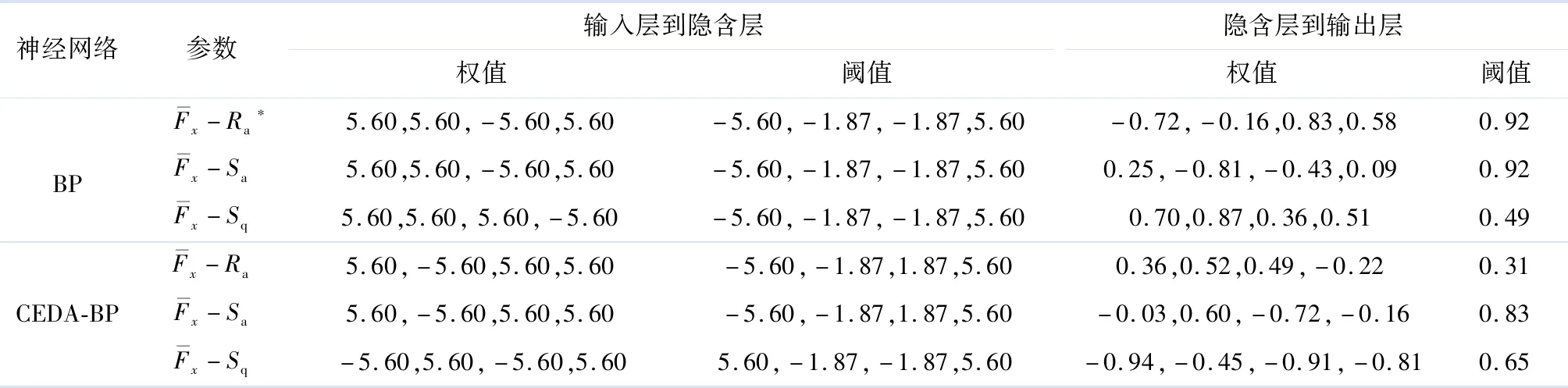
表3 神经网络相关参数
3.3 基于Copula EDA优化BP神经网络预测法
BP算法收敛速度慢,容易陷入局部极小值,而Copula EDA是基于全局来寻找最优解,但速度较慢,且难以确定解的最优位置.因此将BP算法和Copula EDA算法结合起来,根据试验数据来优化神经网络的权值和阈值,并最终得到一个能够精确预测表面粗糙度的网络.具体算法流程如图1所示.详细步骤内容如下:
① 样本数据预处理(方法同BP神经网络预测方法的步骤①).
② 确定基于Copula EDA优化BP神经网络(同BP神经网络步骤②).
③ 初始化群种.随机产生P=50个个体{xi1,xi2,…,xij},其中i=1,2,…,50.j是权值和阈值按照编码方式排列成长度为k(m+n)+n+k的一维数组的字符数,表示权值和阈值的维数.一维数组作为Copula EDA的初始群种,本案例的编码长度j=k(m+n)+n+k=13.得到50组权值和阈值.
④ 选择S个优秀个体.将步骤3产生的50组权值和阈值逐一赋给基于Copula EDA优化BP神经网络,并用量纲一化的切削力作为输入参数得到表面粗糙度预测值,以实测值和预测值误差来评价这P个权值和阈值优劣,从其中选择实测值和预测值误差最小、权值和阈值最优的r=15个个体,以及随机选择t=10个个体作为Copula EDA的S(S=r+t=25)个优秀个体.建立这S个优秀个体{xij,i=1,2,…,25,j=1,2,…,13}的概率分布模型Fj,其边缘分布为正态分布,即Xi~N(mean(xi),std(xi)).
⑤ 基于Clayton Copula函数采样.根据Marshall和Olkin提出的Copula估算法[13],对于n维的阿基米德Copula函数C(u1,u2,…,un)=φ-1(φ(u1)+φ(u2)+,…,+φ(un)),生成元为φ,φ-1是φ反函数.若φ-1是正态分布函数F的反拉普拉斯变换:
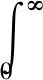
则采样Copula的算法如下:首先随机产生n个相互独立的服从均匀分布函数的变量yj,j=1,2,…,n.然后随机产生一个服从正态分布函数F的变量y.最后令uj=-lgyj/y,xj=Fj-1(uj),j=1,2,…,n,(x1,x2,…,xj)即为服从Copula的变量.
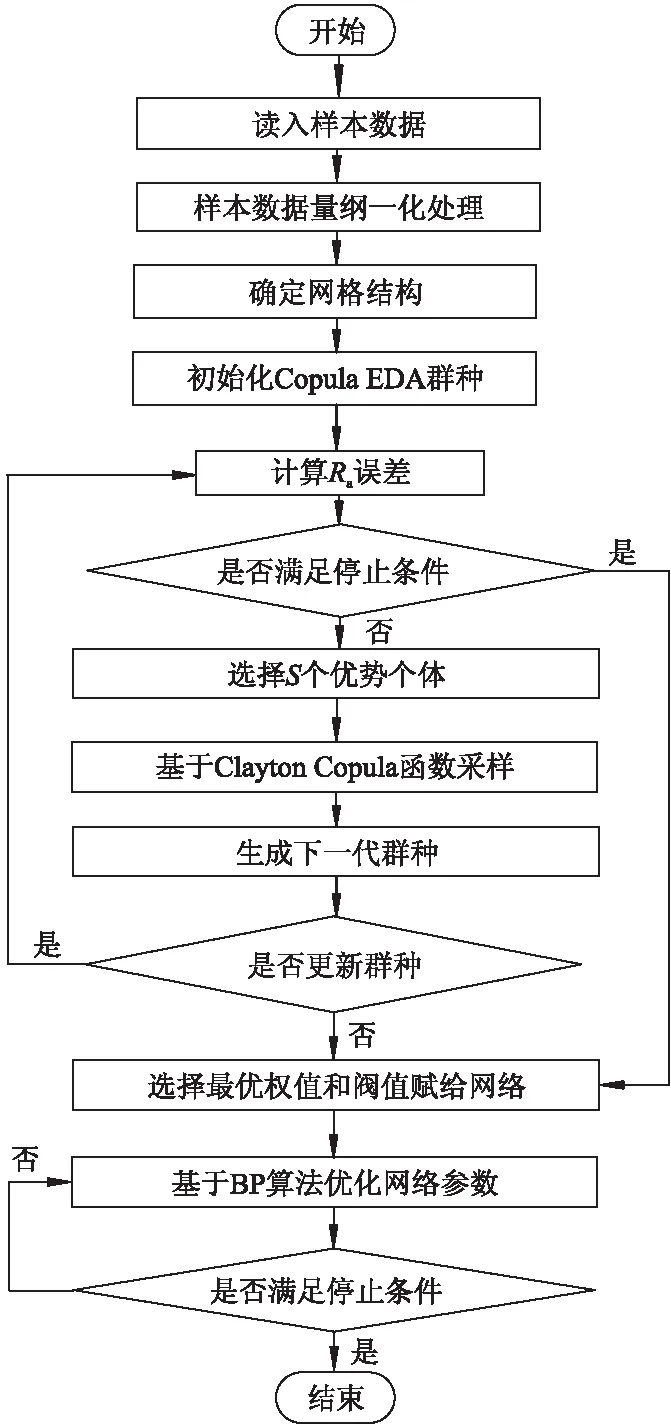
图1 基于Copula EDA优化BP算法流程图

⑥ 生成下一代初始群种.从S=25个优秀个体中选择d=10个个体,并随机产生P-R-d=15个符合均匀分布的个体,将这3组组合起来作为下一代初始群种,返回步骤4.直到达到期望误差或者迭代次数,停止优化,选出最小误差所对应的个体解码,从而得到权值和阈值.
⑦ 设置网络的迭代次数(net.trainParam.epochs=10 000)、网络迭代步长(net.trainParam.show=50)、网络的训练目标(net.trainParam.goal=0.001)、网络的学习系数(net.trainParam.lr=0.05)以及网络的动量因子(net.trainParam.mc=0.9),将步骤⑥得到的最优权值和阈值赋给神经网络,并在训练样本数据的过程中,利用BP算法不断地修正权值和阈值,达到期望误差或者迭代次数,停止训练,最终得到最优权值和阈值.粗糙度预测结果如表3所示.
⑧ 评价网络.将步骤7得到的最终权值和阈值赋给网络,以验证试验的切削力为输入参数,并计算表面粗糙度预测值和表面粗糙度实测值的误差,以此评价网络结构的准确性和可靠性.
4 预测模型的验证
将测得的切削力和振幅作为预测模型的输入参数,得到表面粗糙度的预测值,并与实测值对比,最后以预测值和实测值的误差来评价预测模型的好坏.表4为运用两种方法分别预测表面Ra,Sa和Sq的结果.
由表4数据还可知,两种方法的粗糙度预测值与实际值变化趋势一致.但对于个别奇异点,如表4中下划线数据,BP神经网络的预测精度较低,基本低于70%,而Copula EDA优化BP神经网络预测精度比BP神经网络的预测精度高10%~15%.其原因在于BP算法容易陷入局部极小值,而Copula EDA是基于全局来寻找最优解,所以Copula EDA优化BP神经网络预测精度较高,整体平稳,基本不存在奇异点现象.
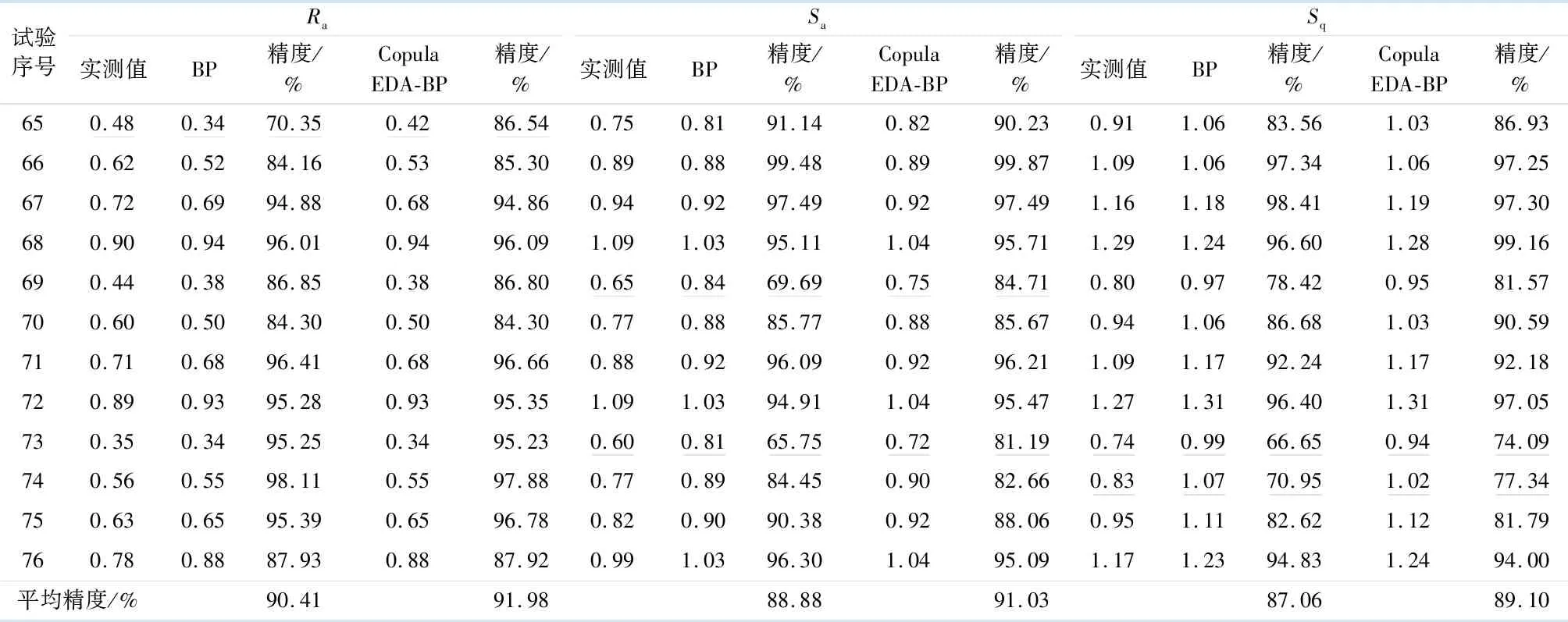
表4 BP神经网络与Copula EDA优化BP神经网络的粗糙度预测结果
5 结 论
2) 切削力分量对二维表面粗糙度的相关性要高于三维表面粗糙度.
3) 基于Copula EDA优化BP神经网络的预测精度总体要高于BP神经网络;对于个别奇异点,BP神经网络的预测精度较低;基于Copula EDA优化BP神经网络的预测整体平稳,基本上不存在奇异点现象.
4) Copula EDA优化BP神经网络法和BP神经网络法对二维粗糙度Ra的预测精度要高于三维粗糙度,与相关性大小一致.
