高精度视频配准算法中的静态图像配准算法
2020-06-16王苹
王 苹
(1. 阳光学院 人工智能学院,福建 福州350015;2. 空间数据挖掘与应用福建省高校工程研究中心,福建 福州350015)
1 引 言
多视频配准即应用多个相机在同一场景对同一个物体进行拍摄,从而得到多个在时间或者空间上存在某种对应关系的视频,通过配准寻找到这种对应关系的变换参数[1]。现阶段已经产生了多个视频配准算法[2-3]。在发展历程上,Caspi[4]等开展了基于特征和基于区域的视频配准算法研究。Shakil[5]针对两个拍摄同一物体时自由运动的相机提出了一个新的视频配准算法。Sand[6]等人提出了一种新的可应用于多个视频配准工作的算法。陈为龙[7]等提出了视频配准算法中的静态图像配准算法,即通过视频提取出一些图像帧,通过对这些静态的图像帧进行匹配来配准视频,将基于特征的图像配准算法应用到视频配准工作中,取得了有效的结果。深度学习的卷积神经网络因具有模式识别[8]的优势,已经在图像识别[9]和分类[10-11]、目标检测[12]等领域发挥了重大作用,且已应用于遥感图像配准领域中。
本文应用深度学习的卷积神经网络VGGNet,设计了高精度视频配准算法中的图像配准算法,研究了VGGNet在视频中静态图像配准工作的可行性及其对配准性能的影响,探讨了图像缩放、亮度变换等对视频中图像配准的影响,比较了本配准算法与传统基于方向梯度直方图(HOG)[13]、局部二值模式(LBP)[14]特征提取配准算法的性能。
2 基于卷积神经网络的静态图像配准算法
卷积神经网络(CNN)在图像识别和分类问题上能发挥出巨大的优势,因此设计了基于卷积神经网络的静态图像配准算法,研究网络中不同层下图像配准的精度,并阐述了实验的数据源和环境配置。
2.1 多视频配准算法中静态图像配准算法设计
本文的静态图像配准算法及流程如图1所示。首先从视频S1中获取某一帧的图像,并从视频S2中获取某一帧的待配准图像。第二步,通过尺度不变特征变换(SIFT)方法对两张图像进行预处理,降低噪声对图像信息的干扰,获取基本的特征图像,大小为128×128。第三步,将特征图像作为CNN模型VGGNet的输入,经过卷积神经网络后,输出抽象化的特征信息。第四步,根据抽象化特征信息获取两幅图像的同名点,从而计算出两幅图像的变换参数,通过图像变换得到最终的配准结果图。
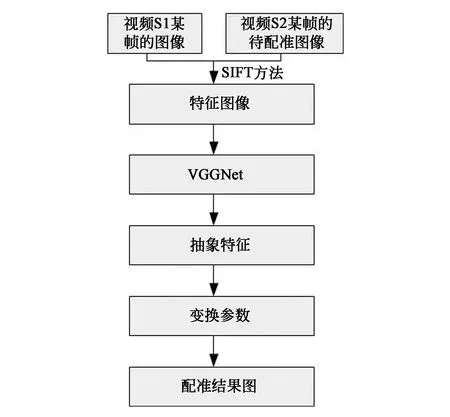
图1 静态图像配准算法Fig.1 Static image registration algorithm
近几年来,深度学习得到了迅速发展。卷积神经网络在图形分类、目标识别等领域取得了良好成绩。其中,VGGNet模型经过大型数据库ImageNet训练后,可以从图像中提取出更高层次的抽象化特征。仿真实验结果表明16层的VGGNet具有更优异的识别性能。
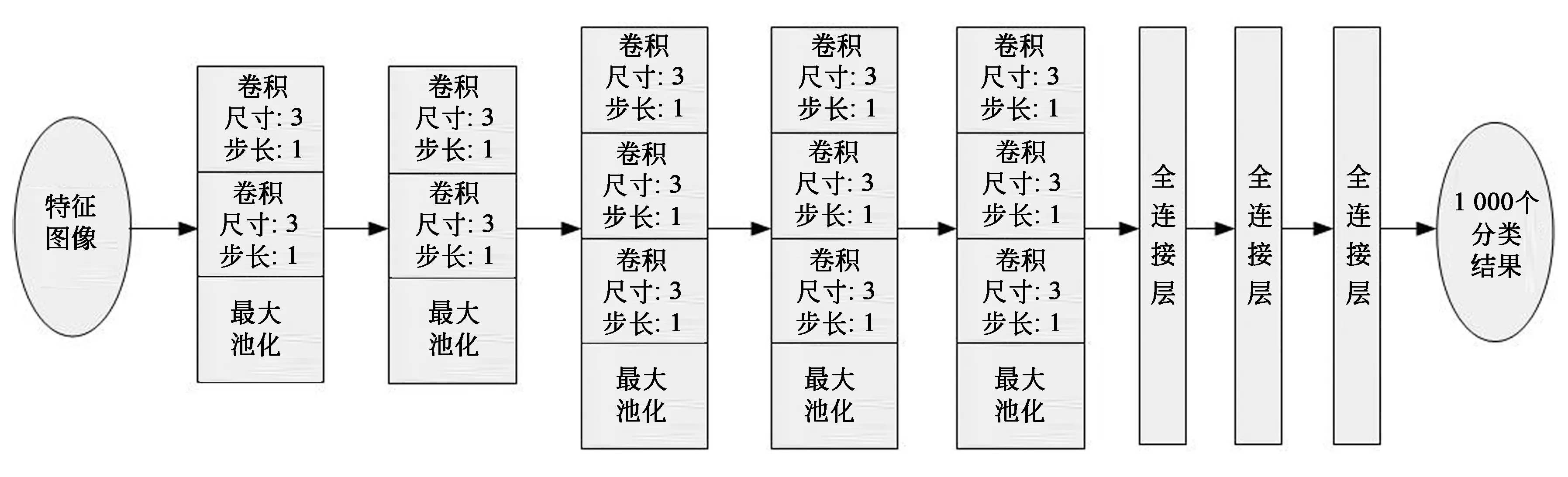
图2 VGGNet模型Fig.2 VGGNet model
VGGNet网络结构如图2所示。它由13个卷积层、5个池化层和3个全连接层组成。在卷积层中,它应用了大小为3×3的卷积核,这在保证一定范围感受野的条件下减少了网络的参数规模,也引入了更复杂的非线性因素,有效增强了模型的特征表达。最大池化层的窗口大小为2×2,在降采样特征量的同时保证关键特征信息不会丢失。通过反复堆叠小型卷积核和最大池化层,既增强了非线性特征表达能力,又将参数量控制在较低的范围内,具有很好的应用价值。在全连接层中,模型应用多个神经元可有效拟合特征的分布,从而提升分类的准确率。
2.2 实验环境配置
本文选取了官方训练好的VGGNet模型。为了使得模型提取出的特征适用于静态图像的配准,本文从视频中提取了12 000对静态图像数据对VGGNet模型进行了微调,如表1所示。其中,2 000对静态参考图像和待配准图像来自于从多对待配准视频中提取的静态图像,对它们做增强变换,旋转90°、旋转180°、旋转270°、左右变换、上下变换后增大数据集为12 000对。随机划分10 000对参考图像和待配准图像为训练数据集,剩余的2 000对参考图像和待配准图像为测试数据集。
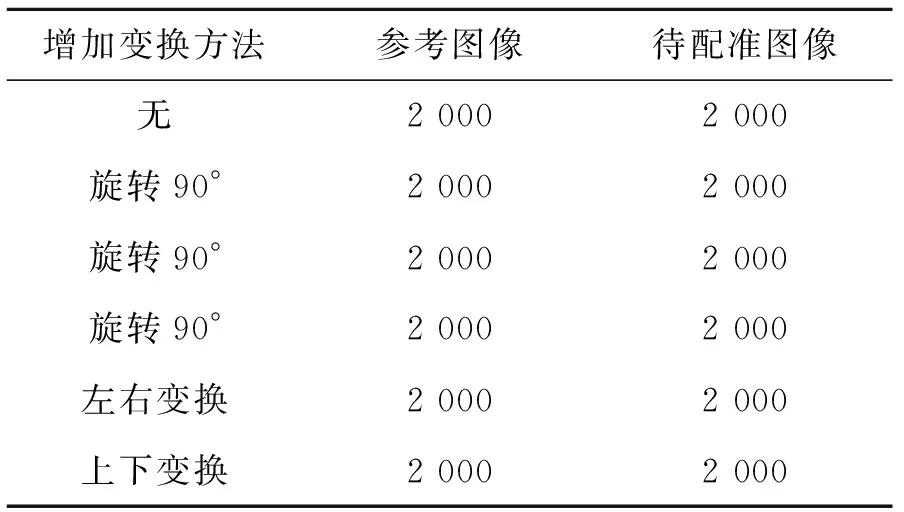
表1 数据集Tab.1 Dataset
因此,本文将卷积和最大池化的堆叠操作作为一个网络层,设置一个全连接层为一个网络层,研究它们的输出特征。则此时共有8个网络层,命名为Conv1、Conv2、Conv3、Conv4、Conv5、FC1、FC2、FC3。原VGGNet的网络层FC3被用于图像的分类工作,不适用于静态图像配准工作,因此舍弃FC3。
在对VGGNet进行微小的训练过程中,设置初始的学习率为0.003,运行平台是Ubuntu14.04服务器,应用的深度学习框架是Tensorflow。
3 静态图像配准-均方根误差分析
在本章节中,确定了通过卷积网络提取的抽象化特征被用于配准的可行性,并应用均方根误差分析法评估了不同网络层特征的配准精度,最后与传统图像配准算法比较。
3.1 静态图像配准可行性分析
为了验证卷积神经网络提取的抽象化特征对静态图像配准工作的可行性,本文随机选取了一对测试数据集中的参考图像和待配准图像进行实验,结果如图3所示。
视频S1和视频S2是在同一时间段、同一地点、不同角度拍摄的落日图像,分别选取两个视频中的某帧图像作为实验对象。从配准结果图中可知,两幅图像大部分相同,纹理区域均配准成功,因此卷积神经网络可被应用于视频配准中的静态图像配准工作中。

图3 配准图像Fig.3 Registration image
3.2 均方根误差分析
采用均方根误差方法来定量分析静态图像配准的精度。均方根误差的计算公式如式(1)所示。
(1)
其中,N为参考图像和待配准图像的对应点对数量,(Xi′,Yi′)为参考图像的点(X,Y)在待配准图像的对应点坐标,(Xi″,Yi″)为对待配准图像进行配准变换后的坐标。均方根误差值越低越好。
对于图3中的图像,卷积神经网络VGGNet的各层特征的均方根误差分析值如表2所示。由表2数据分析可知,第一个网络层输出特征的配准误差最大;第二个网络层的配准误差比第一个网络层低约0.5%;第三、第四和第五个网络层的特征配准误差较为接近;FC1特征和第5个网络层的输出特征的配准误差较为接近;经过FC2的特征变换后,输出的特征值的配准误差降低了约0.4%。
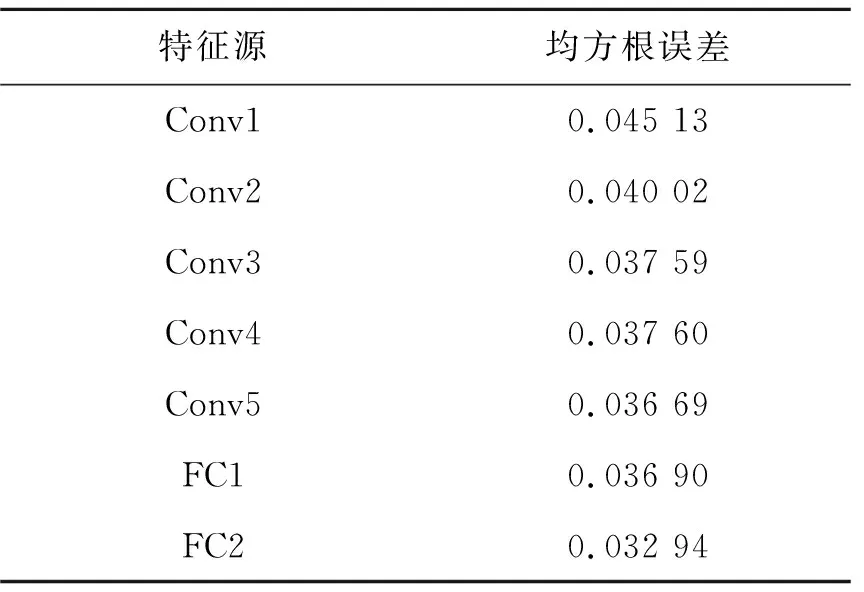
表2 特征的均方根误差值Tab.2 Root mean square error for feature
对于VGGNet的各个网络层特征,计算2 000对测试图像的配准均方根误差,并求取各层配准误差均值,结果如表3所示。由表3可知,Conv5、FC1和FC2的输出特征的均方根误差均值较低,FC2最低为0.031 22。将包含FC2的完整VGGNet作为静态图像配准算法开展后续研究。
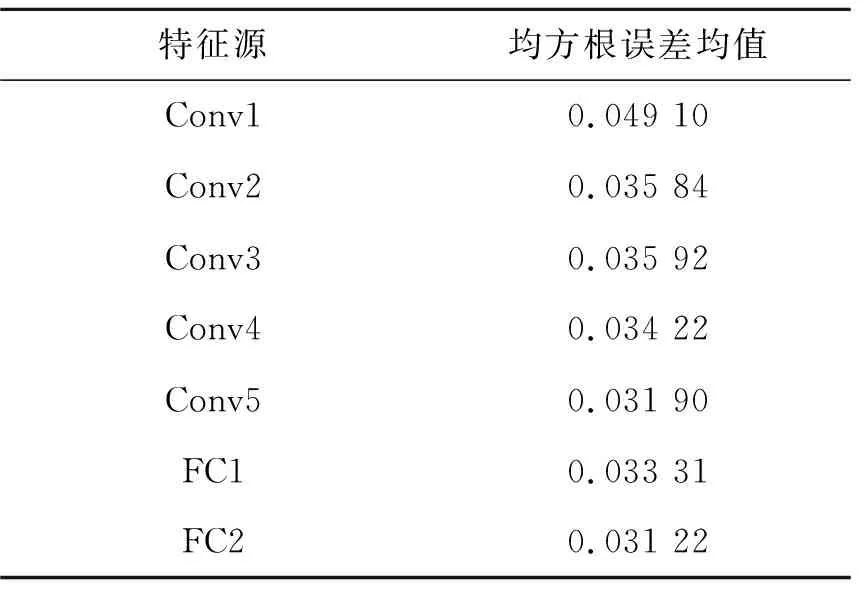
表3 特征的均方根误差均值Tab.3 Mean root mean square error for feature
研究VGGNet图像配准算法与基于HOG、LBP特征提取的图像配准算法精度,结果如表4所示。
表4 多个算法的均方根误差均值
Tab.4 Mean root mean square error of different algorithms

算法均方根误差均值VGGNet图像配准算法0.031 22基于HOG特征提取的图像配准算法0.040 31基于LBP特征提取的图像配准算法0.042 29
VGGNet图像配准算法的均方根误差均值为0.031 22,明显低于基于HOG、LBP特征提取的图像配准算法,具备较高的配准精度。
4 静态图像配准Nred分析
在本章节,应用Nred方法研究静态图像配准的正确率,探究了视频缩放和亮度转换对图像配准的影响,最后与传统图像配准算法做比较。
4.1 Nred分析
Nred表示静态图像配准过程中正确同名点的数量,数值越高越好。
根据卷积神经网络层的输出特征,对2 000对测试数据集求得图像配准的Nred值的平均数,结果如表5所示。可知第1~4个网络层输出特征的配准Nred均值范围在60~70之内;Conv5、FC1和FC2的输出特征的配准Nred均值分别为73,73,74,说明这3层的输出特征的配准性能较好,在此基础上开展进一步的视频缩放和亮度转换研究。
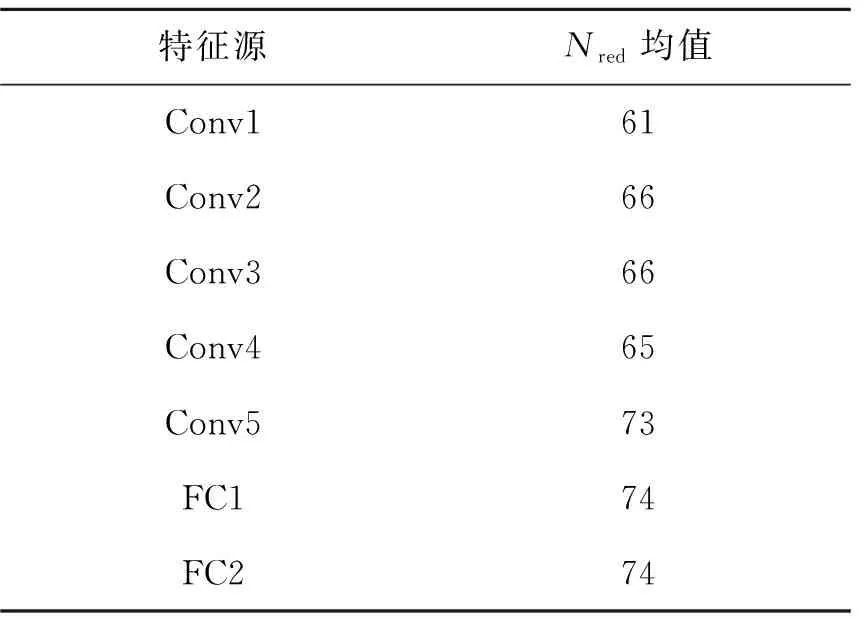
表5 特征的Nred均值Tab.5 Nred mean for feature
4.2 视频缩放和亮度转换研究
对视频做缩放操作即对每帧的图像进行了缩放操作。本文对2 000对测试数据集采取了不同倍数的缩放操作,并统计在Conv5、FC1和FC2下的图像配准Nred均值,结果如图4所示。

图4 特征的Nred均值Fig.4 Nred mean values for feature
进行缩放后,图像的配准Nred均值均不同程度地减小。当采取缩小操作时,配准Nred均值减小的幅度很大;而当采取放大操作时,配准Nred均值减小的幅度较小。3个网络层的输出特征值的配准Nred均值较为接近。
在相同的实验环境下,对视频做亮度变换操作,结果如图5所示。
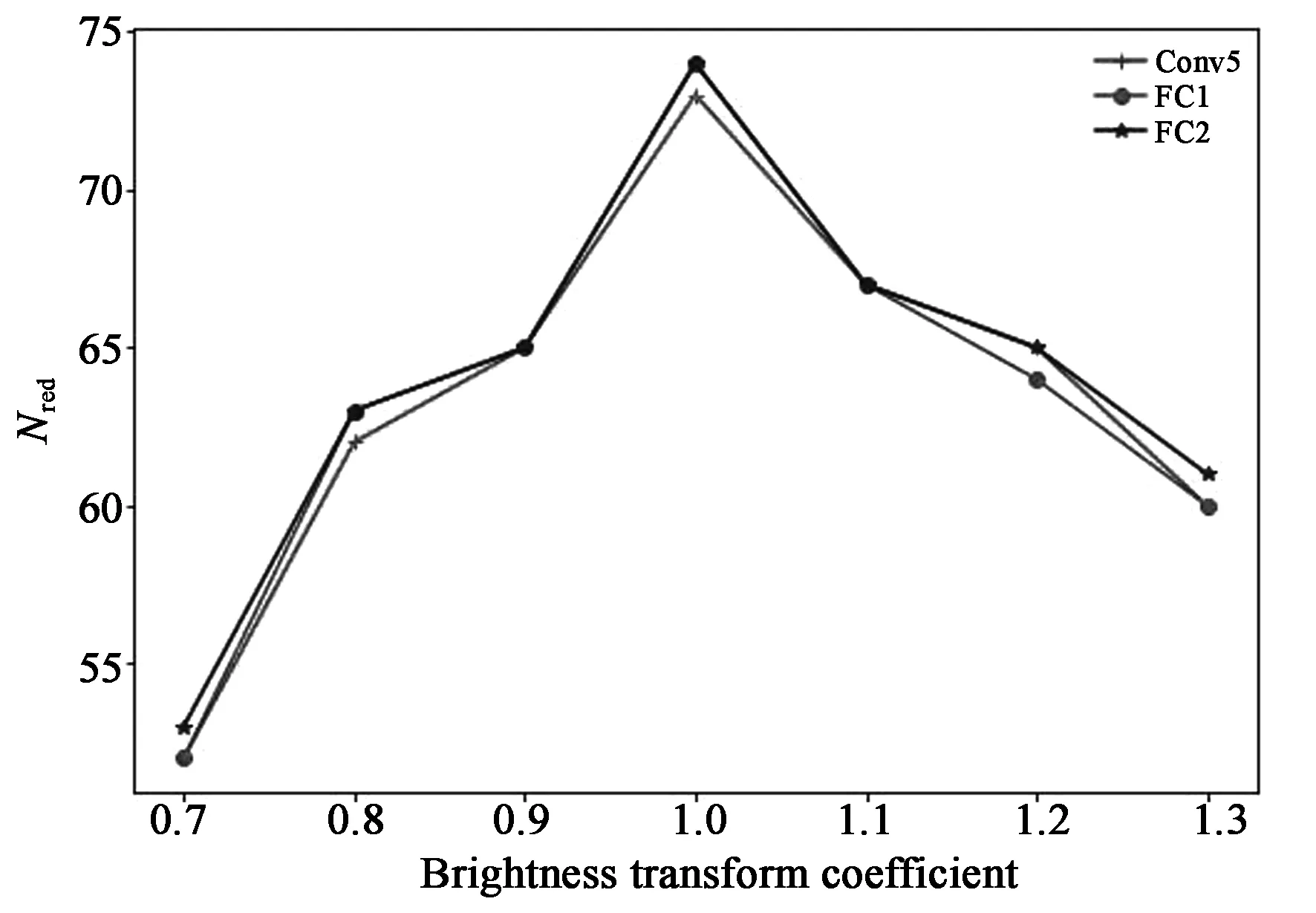
图5 特征的Nred均值Fig.5 Nred mean values for feature
采取亮度变换操作后,图像的配准Nred均值有所减小。减小亮度变换系数的配准Nred均值减小幅度比增加亮度变换系数大。FC2的配准Nred均值总体较高。将包含FC2的VGGNet作为本图像配准算法开展后续研究。
4.3 图像配准性能分析
统计当前配准算法与经典HOG、LBP配准算法的正确同名点数目,结果如表6所示。

表6 多个算法的Nred均值Tab.6 Nred mean values for feature
VGGNet图像配准算法的Nred均值为74,远高于基于HOG、LBP特征提取的图像配准算法,具备较高的图像配准正确率。
5 结 论
本文研究了视频配准工作中的静态图像配准算法,设计了一个由较小尺寸卷积核、非线性激活操作、池化操作组成的静态图像配准算法模型,期望捕获一定范围感受野、非线性的图像语义信息。经仿真可知,算法模型的FC2输出特征的配准精度为0.031 22,配准Nred为74,具备较好的配准可信度和配准性能,优于传统的HOG、LBP图像特征提取算法。算法模型对于图像的缩放变换和亮度变换操作具备一定的抗干扰能力,FC2输出特征的综合配准性能较优。
