融合注意力机制的移动端人像分割网络
2020-06-16姚剑敏林志贤郭太良
周 鹏, 姚剑敏,2 *, 林志贤, 严 群,2, 郭太良
(1. 平板显示技术国家地方联合工程实验室,福州大学 物理与信息工程学院,福建 福州 350108;2. 晋江市博感电子科技有限公司,福建 晋江 362200)
1 引 言
语义分割作为计算机视觉的重要课题之一,从像素级理解图像,旨在为图像中的每一个像素点分配一个分类类别,从而获得逐像素的特征分类图[1]。现如今,越来越多的应用场景需要精确而高效的语义分割技术,如室内导航、无人驾驶、增强现实等。特别是在手机端相册的应用中,需要利用语义分割技术完成人像分割,从而满足人们对于拍摄图片中人像背景的替换、渲染、虚化等美图功能。
近些年随着深度学习算法的蓬勃发展[2-4],大量研究员开始投入精力研究如何将神经网络应用于语义分割技术中。2012年,Farabet[5]等人利用一种新颖的场景标注方法,首次将卷积神经网络应用于语义分割算法中。2014 年,Long[6]等人提出了FCN(Fully Convolutional Networks),利用卷积层代替全连接层的方式实现了端到端的图像分割。2017年,Chen[7]等人提出了DeepLabV3模型,使用空洞卷积(Atrous convolution)来扩展感受野,该方式可以获取更多的空间上下文信息,有效提升了分割精度。2017年, Zhao[8]等人提出PSPNet (Pyramid Scene Parsing Network),在FCN基础上,提出在空间维度上建立空间金字塔模块,该方式精细化了物体的边缘,可以更好地分割物体。2017年,Lin[9]等人提出RefineNet(Multi-path refinement net-works),设计了多路径提取特征的结构,改善了特征提取效果,语义分割精度提升明显。
语义分割网络为了追求精度,需要占据庞大的计算资源。移动端有限的硬件条件,始终阻碍着语义分割技术在移动端的部署。2018年,Sandler等人提出的MobileNetV2[10]为解决这一难题带来了可能。大量研究员通过将语义分割网络的主干部分替换为MobileNetV2的方式,成功地将网络在移动端部署,但也因此带来了分割精度差、分割边界模糊等问题。
FCN[6]、SegNet[11](A deep convolutional encoder-decoder architecture)和UNet[12]作为最早将编码器-解码器结构应用于语义分割领域的神经网络,证明了该结构可以有效地捕获特征细节,获得具有丰富上下文信息的特征地图。2018年,Zhang[13]等人提出通道注意力模型,将常用于语音识别中的注意力机制应用到语义分割领域中,证明该方式可以利用丰富的上下文信息,有效地探索特征地图通道之间的关系,恢复分割物体的边界。
本文受此启发,将注意力机制融入到编码器-解码器结构中,有效地解决了移动端人像分割网络分割效果差的问题。为了解决引入注意力模型带来的额外计算量问题,对注意力模型进行了轻量化处理。最后为了降低训练难度,加速网络收敛,在训练阶段,将原有的损失函数改为Multi-Loss(多损失函数),有效提升了分割精度。实验证明本文提出的网络结构在速度和精度上达到了有效平衡,可以部署到移动端使用。
2 模型设计
2.1 优化注意力模块
NLNet[14](Non-local neural networks)是目前常见的注意力模型之一,由全局上下文特征模块、特征信息转换模块、特征融合模块3个模块组成。通过全局上下文特征模块来获得融合了上下文信息的特征地图,利用特征信息转换模块对融合了上下文信息的特征地图进行通道校验,最后由特征融合模块将融合了上下文信息的特征地图整合到原特征地图中。本文在NLNet的基础上对模块结构进行了优化,在可接受的精度损失范围内,有效提升了模快的运行速度。模型结构对比图如图1所示。
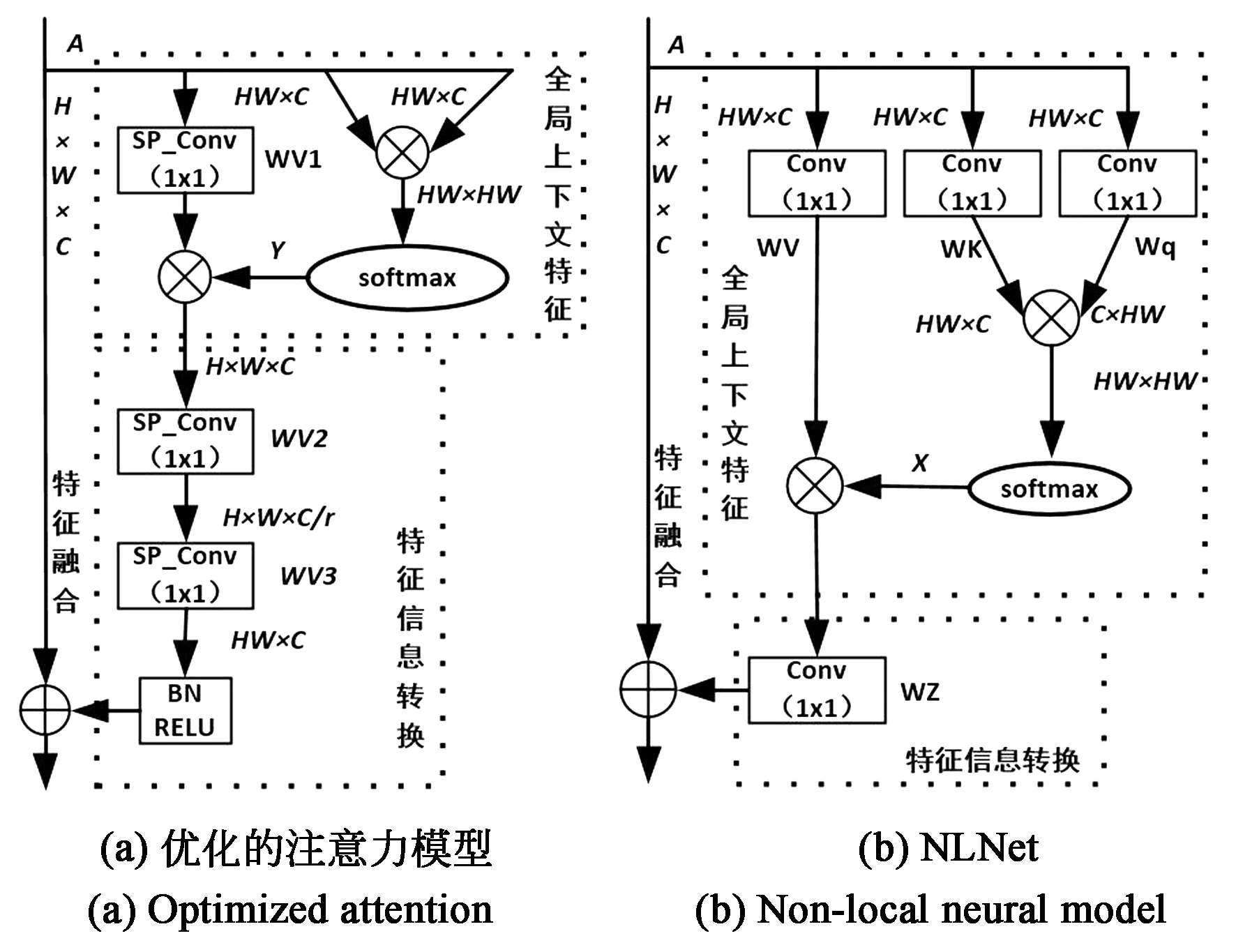
图1 NLNet与优化模型结构对比Fig.1 Structural comparison of NLNet and optimized model
图中H、W、C分别为输入图像的高、宽、通道数目;WV1、WV2、WV3为尺寸为1的深度可分离卷积;WV、WK、Wq、WZ为尺寸为1的普通卷积核。
2.1.1 优化全局上下文特征模块
在全局上下文特征模块中,NLNet将输入特征地图A分别经过两个1×1卷积核进行特征聚合,然后利用Embedded Gaussian(嵌入式高斯)对任意两个通道之间的成对关系进行建模,获得注意力地图X,见公式(1)。然后将特征地图A经过一个卷积核WV进行特征聚合,随后与注意力地图X相乘获得融合丰富上下文信息的特征地图。但是对通道之间的成对关系建模前,对特征地图A进行特征聚合会破坏特征通道之间隐含的相互关系,同时会引入多余的计算量。设输入特征地图A的通道为1 024,则两个1×1卷积核的参数达1 024×1×1×1 024×2(输入通道×卷积核尺寸×输出通道×2)之多。为此,本文将两个1×1的卷积核舍弃,直接对特征地图A进行Gaussian(高斯)计算得到注意力矩阵Y,见公式(2)。该方式保留了通道之间隐含的相互关系,同时有效降低了计算量。另外,将NLNet中对特征地图进行特征聚合的普通卷积WV换为深度可分离卷积[15]WV1,该卷积核将普通的卷积操作分解为depthwise(深度卷积)和pointwise(点卷积)两个过程,可将计算量降为原有计算量的1/Cout+1/(KW+KH)。(Cout为输出的通道数目,KW、KH为卷积核的宽和高),推演过程见公式(3)。
(1)
(2)
C表示输入特征地图的通道数目。i是特征图中第i个通道的索引,j为所有通道中的一个索引枚举。Xij和Yij分别是注意力地图X和Y中的权值系数,表示特征地图中第i个通道对第j个通道的重要性。
(3)
其中:depthwise为深度卷积的计算量,pointwise为点卷积的计算量,conv为普通卷积核的计算量。Cin和Cout为输入输出的通道数,W和H为输入图像的宽和高,KW、KH为卷积核的宽和高。
2.1.2 优化特征信息转换模块
NLNet采用一个1×1的卷积核作为特征信息转换模块来校准通道之间的依赖关系,帮助网络理解语义信息,但该方式引入了过多的计算量。设输入特征地图的通道为C,则1×1卷积核的参数达C×1×1×C(输入通道×卷积核尺寸×输出通道)之多。为了适应移动端的硬件环境,本文将单一卷积核替换成两个深度可分离卷积,通过对特征地图的通道进行先压缩再扩张的方式来降低计算量。第一个深度可分离卷积的输入通道为C,输出通道为C/8(其中8为压缩系数),对特征图进行通道压缩。第二个深度可分离卷积的输入通道为C/8,输出通道为C,对特征图进行通道扩张。该方式将参数数量由C×C降低为2×C×(C/8),有效地将计算量降低为原计算量的1/4。
最后将特征信息转换模块得到的特征地图输出给特征融合模块。本文沿用了NLNet中的融合方式,对具有丰富上下文信息的特征地图与原始特征地图进行像素级求和得到结果特征地图。
2.2 注意力机制融入到解码网络
常见的编码器-解码器结构由编码网络和解码网络两部分组成。利用堆叠的卷积和池化层作为编码网络来提取图像的特征信息,然后将编码器中包含低等级特征信息的特征地图跳跃连接到解码网络中。解码网络由多个子模块组成,每个子模块由连续的一两个卷积核堆叠而成,负责对上一层子模块输出的特征地图与编码网络跳跃连接而来的特征地图进行特征聚合,以此获得具有高、低等级特征信息的特征地图。
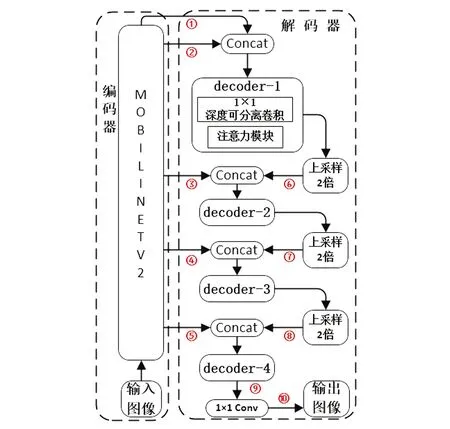
图2 模型网络结构示意图Fig.2 Schematic diagram of model network structure
本文模型利用MobileNetV2作为编码网络。解码网络堆叠了4层解码子模块(Decoder),每个解码子模块嵌入了一个优化过的注意力模块和一个用来压缩特征地图通道数目、尺寸为1的深度可分离卷积。为了获得丰富的上下文信息,选取编码网络中的第2、4、7、14层(尺寸分别为原始特征地图的1/2,1/4,1/8,1/16)的输出特征地图跳跃连接到解码网络中,与解码子模块输出的特征地图在通道维度上进行堆叠,再输出给下一层解码子模块。为了堆叠时特征地图尺寸的一致性,在堆叠前对解码子模块输出的特征地图进行了上采样操作。重复上述操作,最终将特征地图经过一个1×1的卷积核和SoftMax层得到分割结果图,尺寸为输入图像的一半。模型具体结构见图2。其中,①:编码网络的输出特征地图。②~⑤:编码网络第14、7、4、2层的输出特征地图。⑥~⑨:经过解码子模块并上采样后的特征地图。⑩:输出特征地图。decoder-i(i=1,2,3,4)为解码子模块,包含一个深度可分离卷积和一个轻量化注意力模块。表1给出了各特征地图的尺寸和通道数目。
表1 模型各层输出特征地图尺寸
Tab.1 Size of the output feature map of each layer of the model

特征地图 尺寸(高×宽)通道数目①14×14320②14×1496③28×2832④56×5624⑤112×11216⑥28×28192⑦56×5664⑧112×11248⑨112×1128⑩112×1122
2.3 Multi-Loss
语义分割网络因为网络过深,存在训练难度大、分割精度难以提升等问题。为此,本文在损失函数上做了一些修改,采用Multi-Loss对各层输出结果进行监督。将标签尺寸大小改变为原图的1/16、1/8、1/4、1/2,然后分别与解码网络中的decoder-1,decoder-2,decoder-3,decoder-4生成的特征地图做交叉熵操作得到各层的损失值Loss1,Loss2,Loss3,Loss4,最终的损失函数为各层交叉熵的系数和。
(4)
其中β为损失权值系数。随着网络的进行,损失逐渐降低,为了权衡各层损失对整体损失的影响,将β1、β2与β3、β4的比值设为1∶2。图3展示了整体损失与各层的损失的收敛情况。
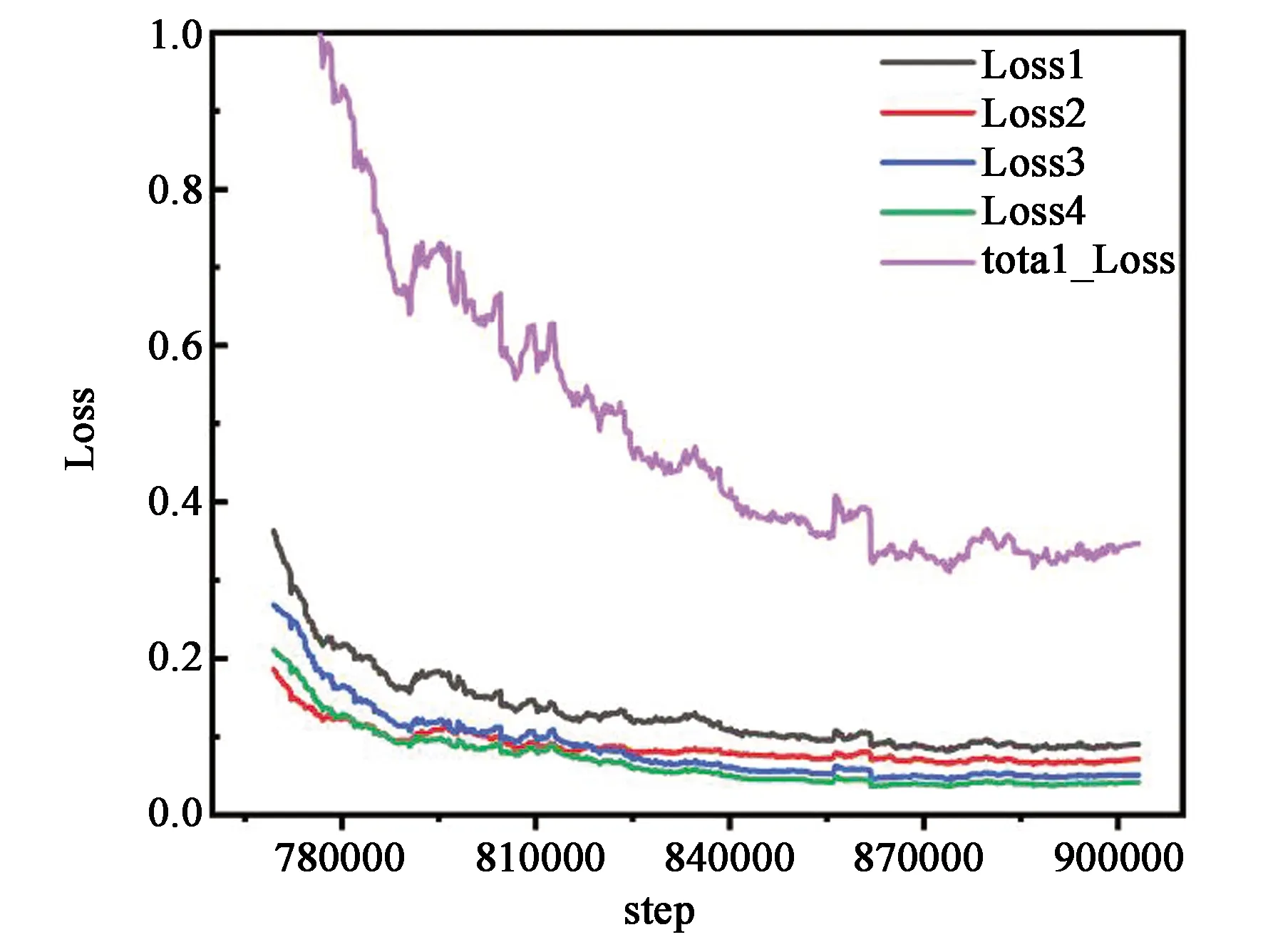
图3 总损失与编码层各层损失收敛图Fig.3 Convergence graph of total loss and loss of each layer of the decoder layer
3 实验及结果分析
实验环境:实验采用开源的深度学习框架TensorFlow,并利用该框架下的TensorBoard对精度和损失的收敛情况进行观察。计算机配置为Window10操作系统,8 G内存,处理器为Inter(R)Core i5。为了更好地匹配移动端条件,整个实验在CPU环境中进行测试。
数据集处理:实验在PASCAL、COCO等4个公开数据集中挑选了38 470张与人像有关的图片作为预训练样本对模型进行预训练。然后利用自采集的6 166张人像图片作为数据集对模型进行微调(Finetune)。验证集为自采集的人像图片550张。利用左右翻转和随机裁取操作进行数据增强。所有图片的标注均采用语义分割标注工具Labelme。
训练策略:实验采用的梯度优化器为Adam算法。学习率采用多项式学习率迭代策略,初始学习率为0.1,每2万步衰减到原学习率的1/10,训练总步长为90万步。输入图像尺寸为224×224。
评价指标:图片单张分割时间(s)、平均像素精度MPA与交并比MIOU。见公式(5)、(6)。
(5)
(6)
其中:k为分类的类别,Pii为真正的数量;Pij为假正的数量;Pji为假负的数量。
3.1 注意力模块的优化效果
为了验证轻量化注意力模块的效果,实验分别将优化了全局上下文特征模块的注意力模型、优化了特征信息转换模块的注意力模型、两者同时优化后的注意力模型与原模型NLNet分别嵌入到解码网络中,对模型的分割情况进行测试,结果见表2。
表2 注意力模块优化效果对比
Tab.2 Comparison of the optimization effect of the attention module
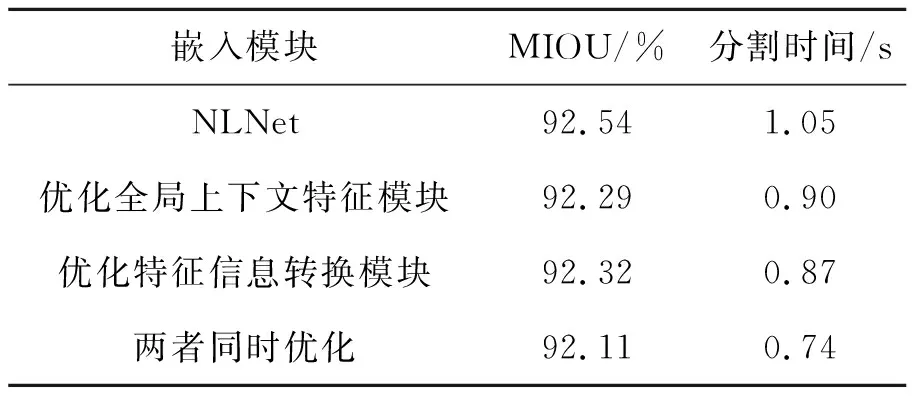
嵌入模块 MIOU/% 分割时间/s NLNet92.541.05优化全局上下文特征模块92.290.90优化特征信息转换模块92.320.87两者同时优化92.110.74
观察可知,与嵌入原模块NLNet相比,优化全局上下文特征模块后,MIOU损失了0.25%,速度提升了0.15 s。优化特征信息转换模块后,MIOU损失了0.22%,速度提升了0.18 s。两者同时优化后,MIOU仅仅损失了0.43%,速度提升了0.31 s。在可接受的精度损失范围内,速度提升明显。证明了文章中提出的注意力模块优化方案具有可行性。
3.2 解码网络层数的设计
解码网络可以有效地捕捉上下文信息,配合注意力模块可以提升分割精度,但解码网络的层数对网络运行速度有一定影响。实验就融合注意力机制的解码网络层数进行实验,实验结果见表3。
表3 加入不同层数解码网络的分割指标
Tab.3 Segmentation indicator of decoding network with different layers
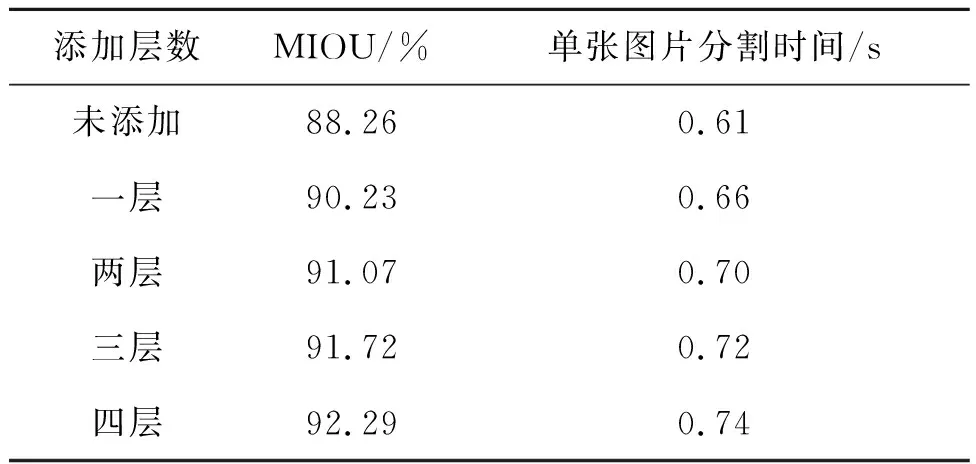
添加层数 MIOU/% 单张图片分割时间/s 未添加88.260.61一层90.230.66两层91.070.70三层91.720.72四层92.290.74
分析表3可知,随着解码网络层数的增加,MIOU得到提升,但单张图片分割消耗的时间相应增加。未添加解码网络时MIOU为88.26%,时间为0.61 s。添加1层、2层、3层、4层后MIOU分别提升了1.97%和2.81%,3.46%和4.03%。但时间相应增加了0.05,0.09,0.11,0.13 s。相对于精度的提升,带来的速度影响在可接受范围内,因此网络设计最终选择了4层解码网络。
3.3 解码网络中融合注意力机制对分割效果的影响
解码网络中融合注意力机制可以有效地恢复物体的分割边界,提升分割细节。实验将解码网络中融合注意力模块和未融合注意力模块产生的分割图片做对比实验。部分对比数据见图4。

图4 解码网络中融合注意力模块对分割效果的影响。(a)原图;(b)标签;(c)未融合;(d)融合后。Fig.4 Effect of the fusion attention module in the decoding network on segmentation. (a) Orrginal; (b) Label; (c) Unfused; (d) Fased.
观察图4可知,解码网络未融合注意力模块时,对于人体的边缘和细节部分分割效果较差,多分割漏分割情况严重。如例1中不能分割出人的耳朵。例2中只能大致分割出人体的轮廓,对于胳膊、小臂等部位存在漏分割情况。例3中无法正确分割出人的手指。在解码网络中融合注意力模块后,对于细节的分割效果明显提升。恢复了未添加注意力模块时漏分割的耳朵、手指部分,对于人体的轮廓边缘分割较为清晰。证明了解码网络融合注意力模块可以有效地修复分割边界,提升分割的效果。
3.4 Multi-Loss对分割精度的影响
Muli-Loss可以减小训练的难度,提升分割像素精度。实验对比了引入Multi-Loss前后的平均像素精度MPA的收敛情况,实验结果见图5。
观察精度收敛情况可知,引入Multi-Loss训练策略后,收敛精度一直优于未引入Multi-Loss训练策略,精度最终收敛到98%左右。相较于未引入Multi-Loss的最终精度96%,精度提升了2%左右,证明了Multi-Loss训练策略能够有效提升分割精度,减小网络训练难度。
3.4 与其他分割方法对比
为了验证本文研究模型的分割性能,挑选了FCN、PSPNet、SegNet和Unet共4种前沿的语义分割网络作对比,它们的主干网络均为MobileNet-V2。统计了各模型单张图片分割时间与MIOU指标,结果如表4所示。
由表4可知,本文研究模型达到了较为可观的速度与精度。与分割效果较差的FCN相比,MIOU超出了6.03%,与SegNet和Unet相比,MIOU也有着2.61%和2.23%的优势。PSPNet与本模型分割精度相当,但分割单张图片,PSPNet需要1.14 s,本文研究模型仅需要0.74 s,快了0.4 s左右。与其他模型相比,本文研究模型在分割单张图片的时间上也都快了0.5 s左右,速度优势明显。
表4 不同分割模型的分割指标
Tab.4 Segmentation indicator of different segmentation models
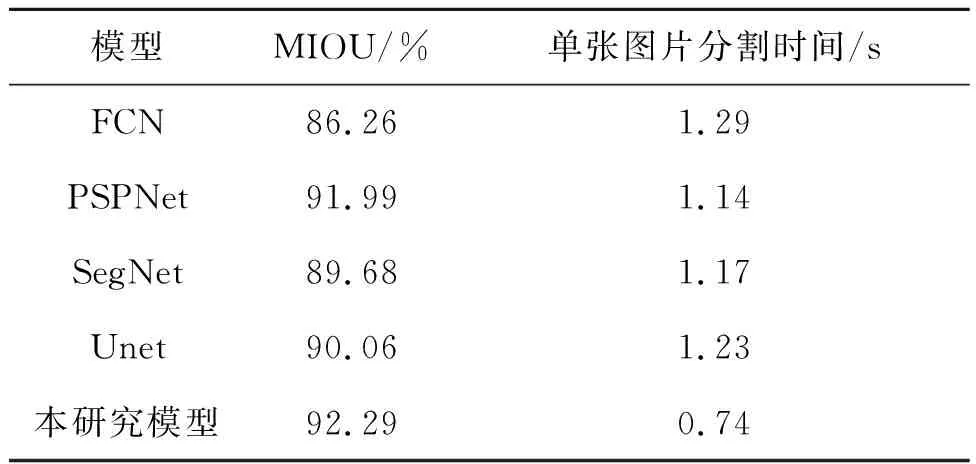
模型 MIOU/%单张图片分割时间/sFCN86.261.29PSPNet91.991.14SegNet89.681.17Unet90.061.23本研究模型92.290.74
为了更直观对本文研究网络的分割性能进行评估,对各方法的分割结果图进行了可视化。部分数据结果如图6所示。观察可知:本研究模型可以清晰地分割出鼻子、耳朵的轮廓边界。分割边界几乎没有锯齿状。对于手指、胳膊等难分割部位分割表现良好,几乎没有漏分割、多分割现象。相较之下FCN分割效果较差,分割边界较模糊。SegNet分割锯齿状严重。Unet与PSPNet存在对于胳膊、手指的多分割、漏分割现象。对比之下证实了本文模型分割性能的优越性。

图6 不同分割方法对比图Fig.6 Comparison of different segmentation methods
4 结 论
提出了一种轻量化人像分割网络,通过在解码网络中融合注意力机制,有效恢复了物体的分割边界,提升了分割精度。为了进一步轻量化网络,提升分割速度,对注意力模块进行了轻量化处理。同时将损失函数改为Multi-Loss,加速网络收敛。实验证明,本研究网络模型达到了92.29%的MeanIOU,单张图片分割时间为0.74 s。相较其他分割网络,速度精度优势明显,适合在移动端应用。
