多粒度特征融合的行人再识别研究
2020-06-16张良,车进*,杨琦
张 良,车 进*,杨 琦
(1. 宁夏大学 物理与电子电气工程学院,宁夏 银川 750021;2. 宁夏大学 沙漠信息智能感知重点实验室,宁夏 银川 750021)
1 引 言
行人再识别[1-4](Person ReID)通常被视为一个图像检索问题,即从非重叠的摄像机视角中实现行人匹配任务。给定一幅查询图像,行人再识别旨在从行人图像库中找出该行人的所有图像。由于拍摄的图像受到光照、姿势、视角、遮挡、背景杂波等影响,会造成同一行人在不同摄像机视角中表现出较大的类内差异,给行人再识别任务造成了巨大的困难和挑战。
随着深度学习在计算机视觉领域的广泛应用,提取的深度特征已被证实具有良好的判别性和鲁棒性,近年来涌现出一批优秀的行人再识别算法。文献[5-7]考虑到样本空间中类内差异与类间差异的影响,提出多损失联合训练的方式来优化网络。文献[8]提出一种改进的三元组损失算法,在特征空间内将正负样本对分开,而且优化了正样本对之间的距离。文献[9]提出一种难样本采样损失函数,在每一个训练的批量样本中挑选一张图像,从批量样本中选择一个最难的正样本以及负样本与该图像组成一个三元组,实验结果显示,使用该损失函数训练的网络模型鲁棒性更强。在此之后,不少研究学者开始利用局部特征来提高行人再识别的精度。文献[10-12]提出将人物图像由上至下分为几个不同部分,对不同的部分进行特征提取,利用多损失共同监督网络,融合不同部分的特征得到最终的特征表示。上述算法的缺点就是对图像对齐的要求较高,为了解决上述的不对齐问题,文献[13]提出一种基于SP距离的自动对齐模型,在不需要额外监督信息的条件下自动对齐局部特征。文献[14-17]提出利用姿态预估模型得到关键点,利用人体关键点将人体划分为不同的区域,得到不同尺度下的特征,通过融合各部分特征进而提高精度。文献[18]也采用人体关键点作为先验知识,不同于文献[14]采用仿射变换对人体区域进行划分,它直接利用关键点将人体分为7个ROI区域,最后将全局特征与局部特征进行融合。文献[19]提出一种全局-局部对齐特征描述子,不同的是将人体区域分为3部分,每部分的输入对应每部分的损失,并不是融合为一个特征计算损失。文献[20-21]提出同时学习全局与局部特征,并通过权重子网络对不同部分加权融合局部与全局特征。然而以上的算法都必须有一个姿态预估模型,增加了学习的难度。
本文提出一种用于ReID的深度学习算法,在不引入任何人体框架先验知识的前提下,融合人物图像的全局、局部、以及人体结构特征。采用三元组损失与ID损失在不同尺度下的多级监督机制优化网络。实验结果表明,这种采用联合监督机制的多粒度特征融合算法有一定的优越性。
2 网络架构
文献[22-24]提出多尺度提取特征,融合不同的特征得到最终的特征表示。考虑到网络的竞争性能以及相对简洁的架构,本文采用ResNet-50[25]作为基准网络,保留全均值池化层(Global Average Pooling,GAP)之前的结构,之后的网络层均被抛弃。对修改的基准网络输出的特征图采用不同的池化策略,得到加权后的全局特征、局部特征以及人体结构特征,如图1所示。在训练阶段,采用多级损失函数监督机制对网络进行训练。在测试阶段,将全局特征、局部特征以及人体结构特征级联形成最终的行人特征描述符实现多粒度特征融合。
2.1 全局特征
行人图像经过基准网络得到特征图F,F经过一个双分支网络,上层分支为全局均值池化层(Global Average Pooling,GAP),由于平均池化能够感知整幅图像中的全局信息,对邻域内的特征点求平均,能够减小邻域大小受限造成的估计值方差增大,更多地保留图像的背景信息。下层分支为全局最大池化层(Global Max Pooling,GMP),最大池化的目标是提取最具有鉴别性的信息,对邻域内的特征点取最大值,能够减小卷积层参数误差造成估计均值的偏移。最大池化忽略了由于平均池化造成的干扰信息,保留更多的纹理信息。考虑到两种池化策略的不同优势,本文采用两种池化策略相结合得到更具有判别性的全局特征,可以表示为:
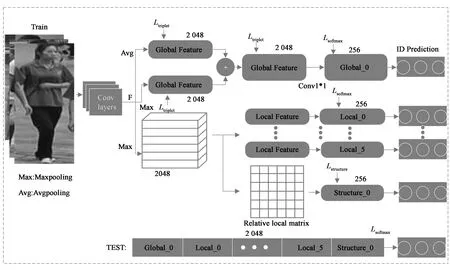
图1 网络架构Fig.1 Network architecture
G=avgpool(F)+maxpool(F).
(1)
降维前的全局特征均采用批量硬三元损失[26]优化网络,批量硬三元损失的核心内容是随机选择P类行人,每类随机选择K张图片,形成一个包含PK张图像的批量样本,对于该批量样本中某个确定的样本,选择批量样本中最难的正样本和最难的负样本来计算损失。优化该批量样本内最难的正样本以及最难的负样本,在特征空间内满足类内距离的最大化并且类间距离最小化,使得网络学习特征的鲁棒性变强。每条支路的损失函数都是独立且不共享网络参数,可以表示为:
(2)
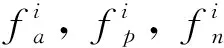
2.2 局部特征
当关注的对象受到遮挡时,由于全局特征无法分辨出前景和背景这一劣势,全局特征的表达能力就会被削弱。此时需要局部特征来弥补全局特征的不足,局部特征是某些特定区域的稳定且具有良好判别性的特征,即使发生了部分遮挡等情况,一些局部的强辨识性特征仍然存在。
最大池化的目标是提取最具有鉴别性的特征,提取邻域内最大的特征点,因此采用最大池化策略获取局部特征。特征图切片[8]是一种常见的局部特征提取方式,本文对特征图F首先进行水平方向池化,将特征向量在水平方向的分量池化为单个部件级别的向量。由于人物图像是垂直的,在垂直方向上特征的鲁棒性较强,因此将经过水平池化后的特征图F沿垂直方向均分为6个区域,每个区域特征降维得到局部特征,采用Softmax损失计算每部分的损失,局部特征中所有的Softmax损失共享参数,可以表示为:
(3)
其中:pi表示预测i属于类别qi的概率,N表示行人图像的总数量。
由于测试集中的人物图像从未在训练集中出现过,因此行人再识别可以看作是One-Shot任务,因此防止网络过拟合是十分重要的。Lable Smoothing[25](LS)是一种广泛的防止分类任务过度拟合方法,具体是改变公式(3)中的qi:
(4)
其中:N表示行人图像的总数量,ε是一个常量,本文中设置为0.1。
2.3 人体结构特征
本文在不引入任何人体姿态先验知识的前提下,对特征图进行切片操作得到局部特征。利用局部特征的相对距离得到局部特征相对矩阵D,进而得到人体结构特征,如图2所示(图2中仅仅列出h1与其他块的关系)。局部特征相对矩阵D是由局部特征之间的余弦距离得到,余弦距离使用两个特征向量夹角的余弦值作为衡量两个特征之间的差异,相比于欧式距离,余弦距离更加注重两个向量在方向上的差异,使用余弦距离能够更好地显示两个特征向量之间的相似度。定义dij表示两个局部特征向量的余弦距离:
(5)
以矩阵的表示形式为:
D=HTH.
(6)
由于人物图像是垂直分布的,相对距离矩阵D对各种可变形的人体结构具有很强的鲁棒性。受到摄像机视角、可变的姿势等影响,采集到的人物图像在相同部位的大小、形状存在很大差异。因此将矩阵D重构为特征向量,用来表示人体结构特征。为了通过人体结构特征区分不同的行人,在重构的特征向量之后加入两层全连接层以及对应的人体结构损失使得人体结构特征是可以学习的。我们可以根据相对距离矩阵D区分不同行人的ID信息,采用Softmax作为人体结构的损失函数,如式(3)所示。
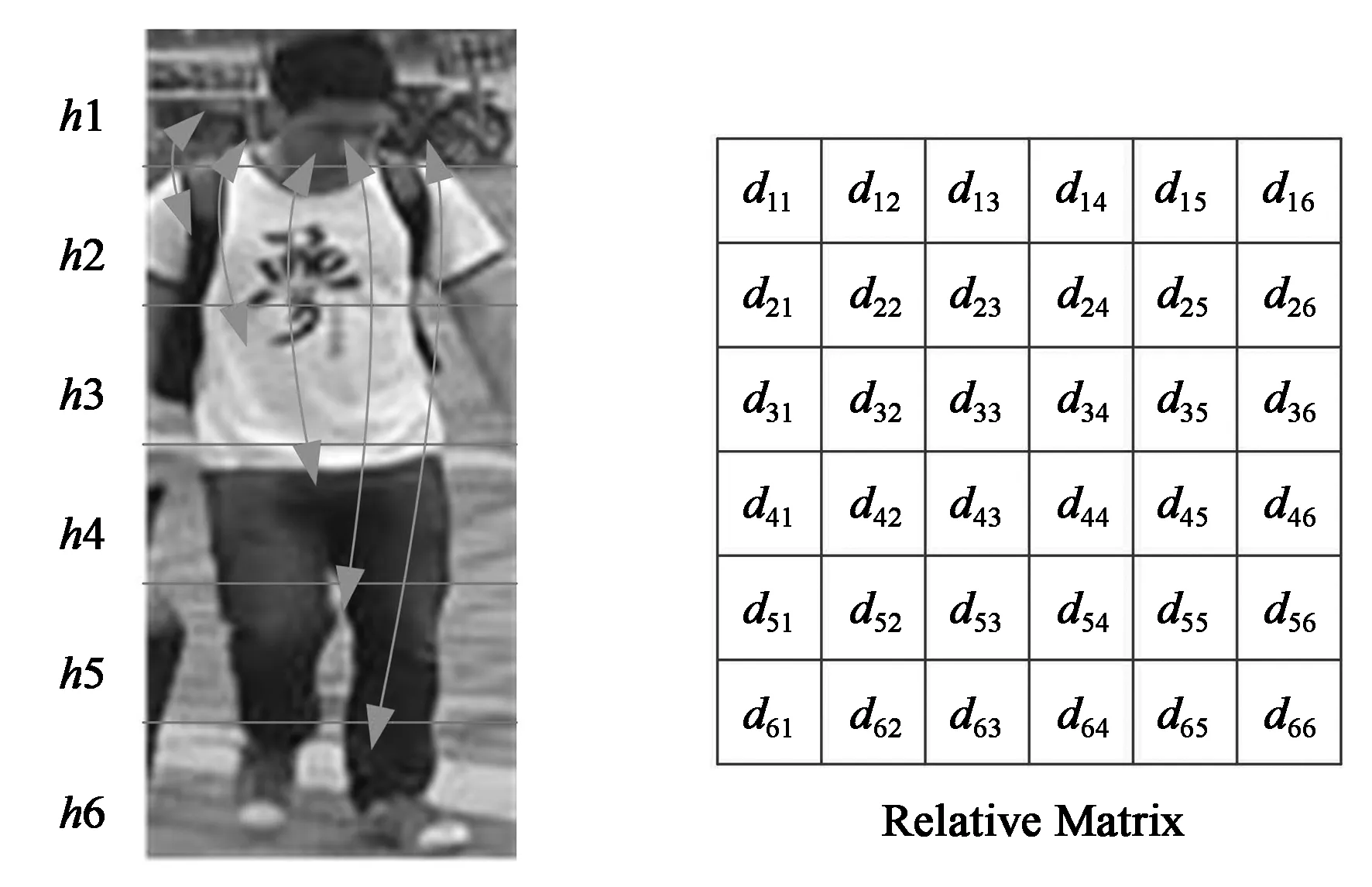
图2 人体结构和局部特征相对矩阵Fig.2 Human body structure and local feature relative matrix
2.4 总损失
采用三元组损失与ID损失相结合的多级监督机制优化网络,网络的总损失包括ID损失、三元组损失、人体结构损失:
L=Lid+Lbhtri+Lstr.
(7)
3 实 验
3.1 数据预处理

图3 REA 效果图Fig.3 REA renderings
3.2 实验设置
为了验证本算法的有效性,实验在pytorch环境下搭建深度网络进行实验,实验设备为搭载4块TITAN V GPU的图形工作站。本文中,擦除概率pe设置为 0.5,设置擦除面积最小值sl=0.02、最大值sh=0.4,擦除区域宽高比最小值r1=0.3、最大值r2=3.33,常量ε设置为0.1,基础的学习率设置为2E~4,迭代周期设置为160,批量大小设置为128,类别P=32,K=4,常量α=0.3,正负样本的初始比例为1/3。
3.3 实验数据库
在两大公开的数据集Market1501、DukeMTMC-reID对模型的有效性进行实验验证,并与几种最新的行人再识别算法进行比较,使用累积匹配特征曲线(CMC)[29]和平均精度(mAP)[30-31]这两个指标来评价所提算法的性能,其中CMC曲线的指标为:首位命中率(Rank-1,R1)、前五位命中率(Rank-5,R5)、前十位命中率(Rank-10,R10)。表1列出了数据集的详细信息。
Market1501数据集是行人再识别中最常用的数据集,该数据集包含了1 501个行人的32 668幅带标签的边界框。由6个不同的摄像头在不同时间、不同光照条件下拍摄。数据集被分为训练集和测试集,训练集包含751个行人的12 936个裁剪图像,测试集包含750个行人的19 732个裁剪图像,边界框直接由可变形零件模型(DPM)[32]检测而不是使用手绘的边界框,这更接近于真实的场景。

表1 数据集的详细信息Tab.1 Details of the dataset
DukeMTMC-reID数据集由8个摄像头采集的视频序列经过等间隔采样得到,数据库包含1 812个行人,其中1 404个行人出现在大于两个摄像头视角下,这些出现在多摄像头的图片分为702个行人训练集16 522张和702个行人的测试集19 889张,剩下的408个行人仅出现在一个摄像头下,因此并没有采用该部分的行人图像。
3.4 实验数据
为了验证不同的池化策略下的全局特征对模型的影响,在Market1501数据集上进行实验,数据如表2所示,由表中数据可得结合两种池化策略的网络性能比任何单一池化策略的性能要好,进一步验证了结合两种池化策略的可行性与有效性。
表2 不同池化策略下的全局特征对模型的影响
Tab.2 Effect of global features on different models under different pooling strategies
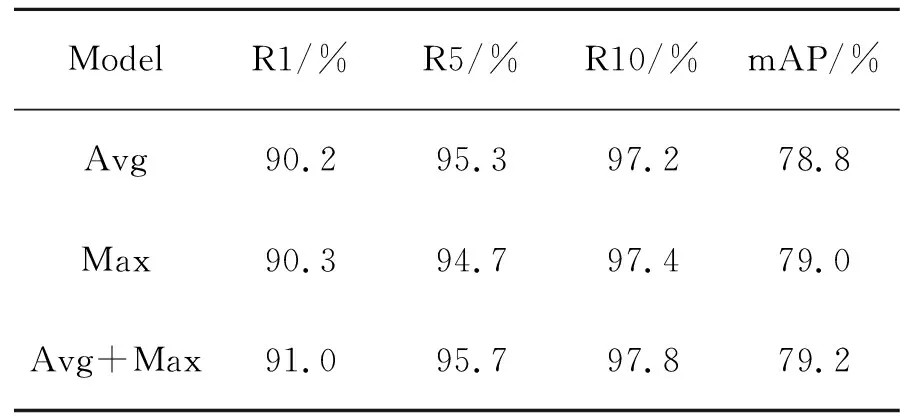
ModelR1/% R5/% R10/% mAP/% Avg90.295.397.278.8Max90.394.797.479.0Avg+Max91.095.797.879.2
本文提出的特征融合策略,在Market1501数据集上对全局特征、局部特征、人体结构特征进行消融实验,实验数据如表3、4所示,其中str表示人体结构特征,由表中的数据可得融合人体结构特征能进一步提高网络模型的性能,进一步验证了可以利用局部特征之间的相对特征表征人体结构特征。
表3 全局特征与人体结构特征对模型的影响
Tab.3 Effect of global features and anatomical features on the model

ModelR1/% R5/% R10/% mAP/% Global91.095.797.879.2Global +str92.797.398.380.8
表4 局部特征与人体结构特征对模型的影响
Tab.4 Effect of local features and human structural features on the model
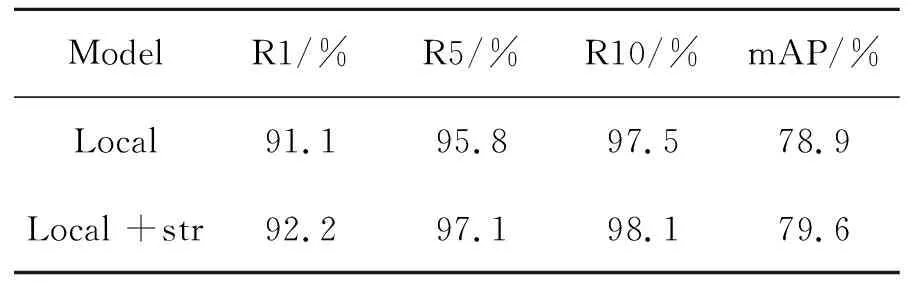
ModelR1/% R5/% R10/% mAP/% Local91.195.897.578.9Local +str92.297.198.179.6
本文提出的行人再识别算法在两大公开的数据集上进行实验,实验数据如表5所示,由表3、4、5中的数据可得,多粒度特征融合能进一步提高网络的性能。

表5 全局特征、局部特征与人体结构特征对模型的影响Tab.5 Effect of global features, local features and anatomical features on the model
本文所提出的算法与现有的算法进行比较如表6所示,可以看出所提出的算法性能优越,在Market1501上的Rank-1仅仅比PCB+RPP稍低,但mAP的性能要高于PCB+RPP。在DukeMTMC-ReID的Rank-1的表现效果很好,mAP仅次于PSE+ECN。由实验数据可得,所提出的算法在两大公开数据集上的表现优越,Rank-1以及mAP要高于现有的大多数算法,充分说明了所提算法的优越性。
表6 本文算法与现有的算法比较
Tab.6 Comparison of the algorithm in this paper with existing algorithms
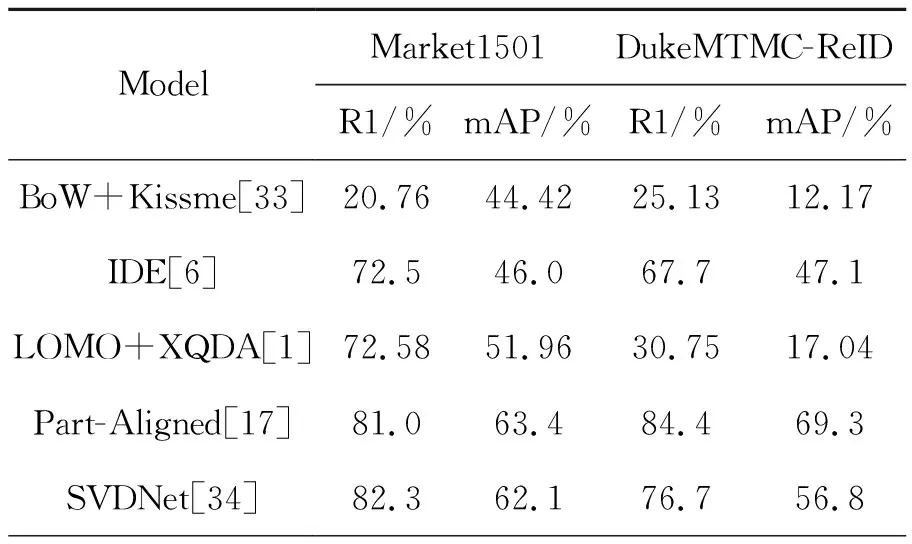
ModelMarket1501DukeMTMC-ReIDR1/% mAP/%R1/% mAP/% BoW+Kissme[33]20.7644.4225.1312.17IDE[6]72.546.067.747.1LOMO+XQDA[1]72.5851.9630.7517.04Part-Aligned[17]81.063.484.469.3SVDNet[34]82.362.176.756.8
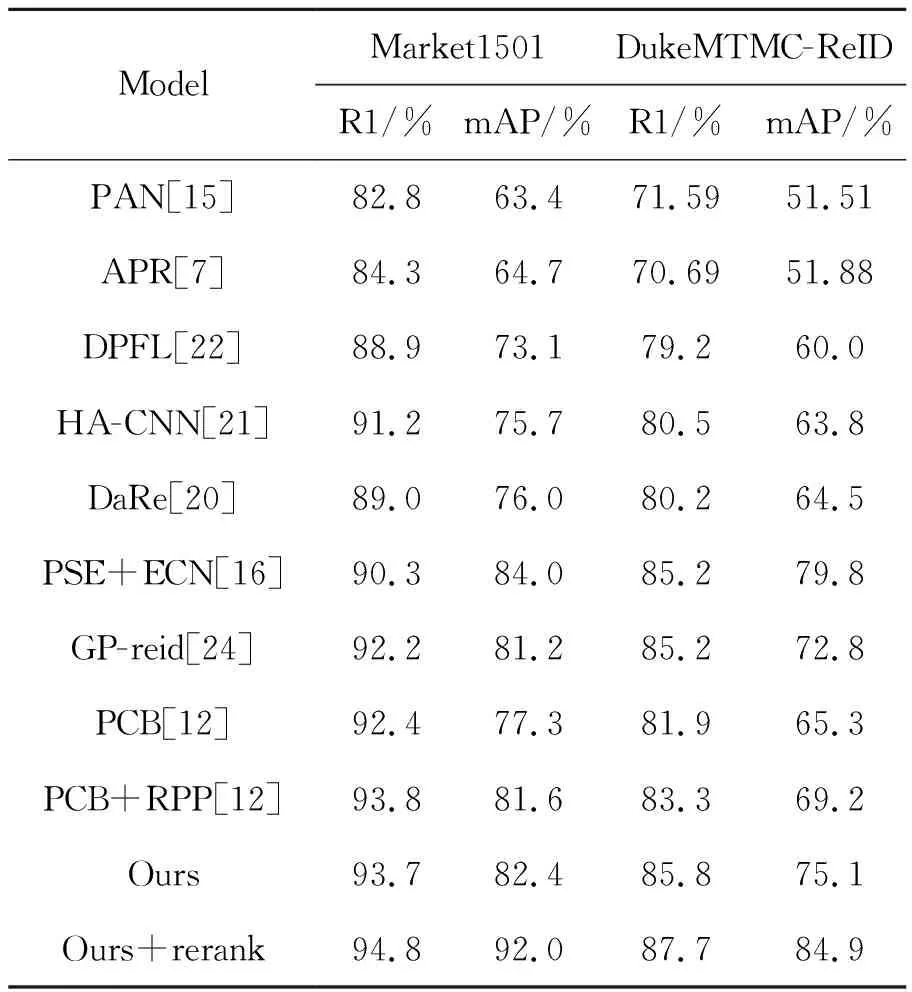
续 表
4 结 论
本文在不考虑任何人体结构先验知识的前提下,提出一种融合人物图像的全局特征、局部特征以及人体结构特征的行人再识别算法。采用不同的池化策略加权捕获人物图像的全局特征,对特征图切片获取局部强辨识性特征,利用局部特征的相对距离得到人体结构特征。采用不同的损失函数在不同尺度下对网络进行监督,这种利用多级损失函数进行监督的监督机制使得网络模型变得更加鲁棒。在公开数据集的实验结果显示,算法的Rank-1指标相比于PCB方法提升了1.3%、3.9%,mAP提升了5.1%、9.8%。
