带有纠删或纠错性质的隐私保护信息检索方案
2020-06-11葛奕飞郑彦斌
葛奕飞,郑彦斌
(1. 桂林电子科技大学 数学与计算科学学院, 广西 桂林 541004;2. 桂林电子科技大学 广西密码学与信息安全重点实验室,广西 桂林 541004)
隐私保护信息检索(private information retrieval,PIR)最早由Chor等[1-2]提出,并逐渐发展成为理论计算机科学和密码学领域的经典问题之一[3-5]。这一问题考虑如何在一串n个比特位中检索特定的一个比特,且使得服务器无法得知所检索比特的具体指标信息。在仅有一个服务器的情况下,平凡的解决方案是下载整个数据库,在有多个服务器的时候,可以设计出更好的PIR方案。衡量方案优劣的主要指标是计算整个检索过程中的数据传输量,其中既包括查询时的上传量,也包括来自服务器反馈的下载量。在这一领域已有一系列工作逐步优化了数据传输量,主要结果详见文献[6-10]及其中的参考文献。

经典的模型下,各个服务器的反馈被假定为真实无误的。但是信息的传递必然会伴随着数据的丢失、噪声干扰甚至人为的篡改。因此,本文将考虑带有纠删性质或带有纠错性质的PIR模型,其具体定义如下。
带有纠删性质的PIR模型:在这种模型中,N个服务器中的至多Z个服务器的反馈信息会在文件检索过程中丢失,用户在检索之前并不知晓哪些服务器的反馈会丢失,这一模型在文献[19,25]中提出。
带有纠错性质的PIR模型:在这种模型中,N个服务器中的至多B个服务器的反馈信息会在文件检索过程中发生错误,这既可能来自信道的噪音,亦可能来自第三方的人为恶意篡改,用户在检索之前并不知晓哪些服务器的反馈会发生错误。这一模型在文献[26]中提出。
本文的主要贡献为推广文献[15-16,19,21]中的PIR方案构造,以适用于带有纠删或纠错性质的PIR变种模型。主要结果如下:


本文结构如下。第1章给出PIR经典模型及本文所考虑的3个变种的具体数学描述,并以一个例子来解释经典模型下的一类PIR方案的设计;第2章考虑带有纠删性质的PIR模型;第3章考虑带有纠错性质的PIR模型;第4章总结并展望后续的研究方向。
1 问题模型
下面介绍PIR模型及其相关变种的具体数学描述。

每个文件经由一个(N,K)-MDS码独立存储于分布式系统中,这一存储码的生成矩阵记为
G=[g1g2…gN]K×N。
(1)

(2)

(3)

(4)
当用户从所有服务器得到反馈之后,通过一定的译码过程得到所需要检索的文件W[i]。PIR方案需要保证译码的正确性:
(5)
在整个检索过程中,经典的PIR模型假设任意T个服务器之间可合谋分析用户的隐私,这些服务器所能分析的即为用户向其发送的问询,或者等价地说,其向用户发送的反馈。PIR模型需要保证任意T个合谋的服务器无法得到关于文件指标i的任何信息:
(6)

以上是经典的PIR模型的数学描述。下面介绍各个变种中的细节变化。
在带有纠删性质的PIR模型中,假设所有N个服务器的某Z个的反馈会在传输过程中丢失。在这种情况下,译码的正确性只能依靠正常收到的N-Z个反馈,即经典模型中的译码正确性的描述(5)应修改为
(7)
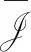
在带有纠错性质的PIR模型中,假设所有N个服务器的某B个(记为集合B)的反馈会在传输过程中发生自然的或者人为的错误,也就是说,对于这些服务器而言,其反馈并不是完全由问询和存储内容所唯一决定的函数,即经典模型中的反馈内容描述(4)应修改为
(8)
用户需要统筹利用这些带有错误的反馈和其他服务器上的正确反馈,借由纠错码完成文件检索。其他数学描述与经典模型一致。
下面简单回顾以文献[15]为蓝本的一类PIR方案的构造思路。考虑参数N=3,M=3,K=1,T=1这一情形,且不考虑纠删纠错性质。这一设定下的PIR方案如表1所示(以字母a、b、c代指3个不同文件,用户检索文件a),其码率达到了最优的PIR容量9/13。

表1 N=3,M=3,K=1,T=1时的PIR方案
表1中,每个文件长度为27,a[1:27],b[1:27],c[1:27]分别为3个文件的27 位字符各自经过随机的置换之后所得到的字符串(这里随机的置换也是用来保障隐私性的一环)。此PIR方案包括如下几步:
①用户首先向各服务器下载文件a的一个字符a1、a2、a3;为保障隐私性,需要对其它文件也采取同样的行为,下载b1、b2、b3、c1、c2、c3;
②此时,所下载的b1、b2、b3、c1、c2、c3作为冗余信息,可以用来作为进一步检索文件a时的辅助信息,则有了形如a4+b2这一部分下载,通过已知的辅助信息b2来得到a4,注意到每个服务器利用的都是其他服务器所提供的辅助信息;
③同理,在有了形如a4+b2、a10+c2这类下载之后,需要对文件b、c的组合采取同样的行为,得到形如b4+c4这一部分下载;
④最终,形如b4+c4这种冗余信息,又可以用来作为进一步检索文件a时的辅助信息,则有了形如a16+b6+c6这一部分下载,即通过已知的辅助信息b6+c6来得到a16。
本质上,这一类PIR方案设计的核心思路是层层利用冗余信息作为辅助信息,保持查询方案中文件之间的对称性和服务器之间的对称性。在接下来本文所考虑的带有纠删性质和带有纠错性质的PIR模型中,也将依照这样的方法构造PIR 方案,但在参数K、T和纠删纠错性质的影响下,下载的内容形式并不仅仅是简单的来自文件的某个信息位字符或者多个信息位字符的组合,而需要是各个文件经过一定编码方式之后的字符组合。
2 带有纠删性质的PIR方案

2.1 方案构造
带有纠删性质的PIR方案的构造需以下几个步骤:
①取定参数α和β,它们是满足下述方程的最小正整数(最小这个要求可忽略,只是为了尽量简化方案的规模/文件的大小,不影响整个方案的设计)

(9)
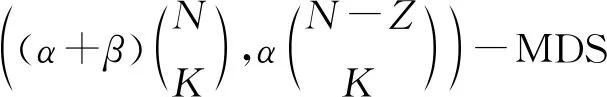
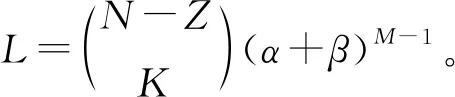
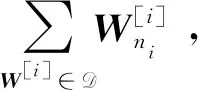

⑥将已预备的模块进行分组,设集合D 为所有N个文件的一个非空子集,但不包含文件W[1]。如第④步中所要求,标号为D 的模块数目为αM-|D |β|D |-1,标号为D ∪{W[1]}的模块数目为αM-|D |-1β|D |。将这些模块划分到αM-|D |-1β|D |-1个区组之中,每个区组里有α个标号为D 的模块和β个标号为D ∪{W[1]}的模块。这些区组也称为标号为D 的区组,记为ΓDλ, 1≤λ≤αM-|D |-1β|D |-1。

下节将通过一个例子来理解上述构造。
2.2 例N=6, Z=1, K=2, T=2, M=2
参照构造方案,所涉及的参数取值为α=9,β=1,L=100,辅助阵列形如

2个文件符号简记为U和V。每个文件长度为200,并各自以100×2矩阵的形式表示为
(10)
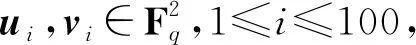

不失一般性,假设服务器Ⅰ的传输内容丢失,则用户可成功得到的信息只有{ai+bi:6≤i≤15}和{x15η+i:x∈{a,b},1≤η≤9,6≤i≤15}。下面说明这部分信息已足够。利用MDS150×90的性质,用户可以通过获得的90个b型字符串译码得到所有的b[1:150],特别地,用户可以最后译码得出{bi:6≤i≤15}。在{ai+bi:6≤i≤15}之中去掉来自{bi:6≤i≤15}的干扰信息后,用户成功得到{ai:6≤i≤15}。最后,借由MDS15×10的性质和S1为满秩矩阵这一事实,用户可译码得到全部{a15η+i:0≤η≤9, 1≤i≤15},即得到整个文件U。
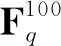
2.3 方案分析



综上所述,对于带有纠删性质的PIR模型,本文构造的方案满足:


3 带有纠错性质的PIR方案
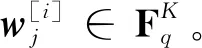
3.1 方案构造
带有纠错性质的PIR方案的构造与第2章带纠删性质的模型相仿,但由于在问询符号之间需引入不同的冗余方式,则整个方案的相关参数也有一定的变化。参照带纠删性质的方案,带有纠错性质的PIR方案的构造需以下几个步骤:
①决定参数α和β的方程调整为
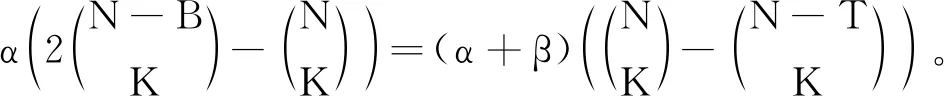
(11)
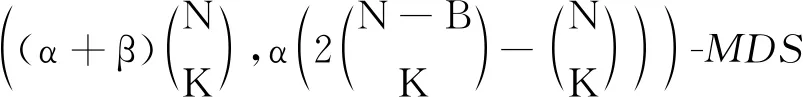
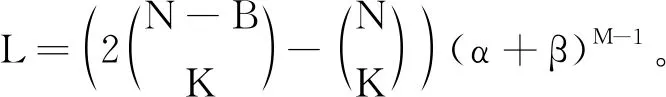
③与④同2.1节保持一致。

⑥同2.1节保持一致。

通过与2.1节纠删PIR方案的对比可见,2个方案的核心区别源于参数α和β的选取,进而影响了问询符号之间的冗余度设置以及同一个区组之中不同标号的模块的数目比例。同样,下节将通过一个例子来理解上述构造。
3.2 例N=8, B=1, K=2, T=2, M=2
参照构造方案,所涉及的参数取值为α=13,β=1,L=196,辅助阵列形如

2个文件符号简记为U和V,每个文件长度为392,并各自以196×2矩阵的形式表示为:
(12)




3.3 方案分析
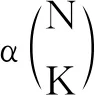

综上所述,对于带有纠错性质的PIR模型,本文构造的方案满足:
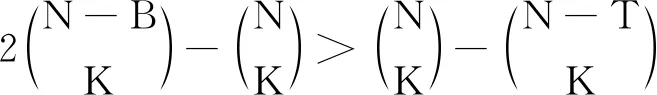
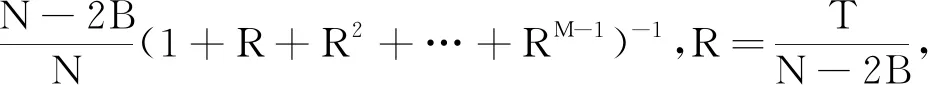
4 总结
本文将经典PIR模型中的一类PIR方案加以推广,增加了在传输过程中的纠删或纠错的能力。本文核心方法是在问询向量中引入一定的冗余并依赖一定的数学结构将这些问询向量分配到不同的服务器上。本文方法可进一步推广至既带有纠删又同时带有纠错能力的PIR模型中,这类模型中的最优PIR容量仍为一个公开问题,后续的研究方向可以是利用信息论工具研究最优PIR 容量的上下界,或者进一步优化本文PIR方案的码率。
