改进R-FCN 的船舶识别方法*
2020-06-11黄致君桑庆兵
黄致君,桑庆兵
江南大学 物联网工程学院,江苏 无锡214122
1 引言
船舶对于海上交通运输起着重要作用,有效地监测海上的船舶情况,可以帮助监测人员及时进行预警、援救等工作,这对于海洋经济[1]的发展有着深远影响。目前国内外在船舶识别方向的研究主要是围绕合成孔径雷达(synthetic aperture radar,SAR)[2]开展研究,其原因在于云雾与光照等自然环境的因素容易影响到光学遥感图像。然而,与SAR 图像相比,光学图像分辨率更高,具有更强的目视判读能力,更易于解译等特点。随着遥感卫星技术的不断加强,其分辨率也会更高,细节部分特征抓取更丰富,因此光学图像下的船舶检测可以作为基于SAR 图像研究下的重要补充。
早期主流的船舶识别都是基于SAR 图像,并且使用的方法多以传统方法为主,以机器学习的基本理论开展的传统的目标检测方法有很多,能够概括为两部分:一是提取船舶目标候选区域;二是鉴别船舶候选区域。提取候选区域方面:Yang 等[3]学者提出的方法能够快速提取船舶目标候选区域,即灰度直方图统计。由于船舶的边缘信息等特性在光学图像中更显著,Zhu 等[4]在此特性的基础上,再根据形状分析提取特征。鉴别候选区域方面:张雷等[5]采取的是多向量综合的方式,Wang 等[6]针对不同种类的军舰则采用了贝叶斯网络来做分类的工作。此外,支持向量机(support vector machine,SVM)[7]、迭代器(AdaBoost)[8]等方法[9-15]是分类鉴别过程中采取的主要的传统方法。然而船舶的目标检测和其他应用场景面临着同样的问题,即传统的目标识别方法泛化能力差,在处理特定的识别任务时,无法适应通用性及鲁棒性等特征。因此在解决实际问题时,过分依赖人工对特征进行设计,那么传统机器学习的方法在目标检测方面便遇到瓶颈,同时深度学习也在快速发展中,特别是在图像领域不断取得好的效果,更多的研究人员开始采取深度学习的方法进行图像处理与目标检测的工作。
在目标检测方面,2014 年,Girshick 等人在CVPR(computer vision and pattern recognition)大会上第一次提出R-CNN(region-convolutional neural networks)[16]网络,该网络将一个空间金字塔添加在全连接层之前,由于不需要将归一化的图像尺寸输入到全连接层,因此更好的尺度不变性则起到了降低过拟合的作用,而在VOC 2012 数据集的表现上,平均准确率(map)则提升到了53.3%。之后Fast R-CNN[17]和Faster R-CNN[18]在2015 年被相继提出,检测速度与准确率都有了提高。2016 年,YOLO v1[19]与YOLO v2[20]被Redmon 等人相继提出,相比于YOLO v1,YOLO v2 将map 值提升到了78.6%,实时检测速率也达到了67 frame/s 的效果。之后基于区域卷积神经网络[21]以及区域全卷积神经网络(regional fully convolutional networks,R-FCN)[22-23]的提出,大幅降低了目标标记的成本。根据目标识别的相关流程,结合船舶识别过程中的特性,图1 为遥感图像下的基于深度学习的目标检测系统流程,其中Liu 等[24]在CNN(convolutional neural networks)基础上改进的RR-CNN 能够准确提取候选区域特征,Zou 等[25]提出的SVD 网络是根据卷积神经网络与奇异值分解提出的,Zhang 等提出的S-CNN[26](ship model CNN)模型能够解决当面临船舶目标多类别、多尺度的情况下,检测情况差的问题。经实验证实,在多复杂背景的场景下以及多方式的船舶停靠等情况下,具备高鲁棒性。

Fig.1 Ship detection flow chart based on deep learning图1 基于深度学习的船舶识别流程图
本文主要根据区域全卷积网络(R-FCN)开展研究并根据船舶识别的特性进行模型的改进。实验表明,本文设计的针对光学图像的船舶识别模型在识别精度上的表现要优于目前主流的目标检测算法,如Faster R-CNN、YOLO V3、R-FCN 等。
2 改进的R-FCN 船舶识别方法
区域全卷积网络R-FCN 的网络结构设计适用于通用的目标检测数据集PASCAL VOC[27],该数据集中的检测目标加上背景一共有21 类。R-FCN 的特征提取网络所提取的Feature Map 个数是由R-FCN 中的位置敏感区域池化层PSRoIPooling(position-sensitive region of interest pooling layer)所决定的,PSRoIPooling会根据检测的类别个数来决定特征提取网络提取的Feature Map 个数,检测类别越多,网络提取的Feature Map 个数也越多。而本文的船舶目标加上背景只有4 类,远小于PASCAL VOC 中的类别数,继续用原始的R-FCN 会导致网络的畸形。因此,如何对原始的R-FCN 进行改进并在船舶识别上获得较好的效果是本文的目标所在。
2.1 船舶检测模型介绍
图2 为改进后的R-FCN 算法模型示意图,主要分为两部分:(1)特征提取网络;(2)改进的区域全卷积网络。在特征提取阶段,使用现有的全卷积神经网络自动提取原始图像的高维空间特征信息;接着使用改进后的R-FCN 在特征提取网络得到的Feature Map 上回归出船舶在原始图像中的位置并进行船舶分类,将Feature Map 与ROIs(regions of interest)位置结合能够提高特征提取效率,如果和原图再结合就会增加计算量,提取不必要的特征。
由于船舶识别类别个数远小于PASCAL VOC 数据集的检测类别个数,会造成特征提取网络提取的Feature Map 个数也会远小于在PASCAL VOC 数据集上进行检测的R-FCN,从而使整个网络架构处于畸形状态。针对这一问题,本文改进位置敏感区域池化层,将其在船舶识别上提取的特征Feature Map个数和PASCAL VOC 数据集检测上提取的Feature Map 个数保持一致,使得改进后的R-FCN 在船舶检测上的性能能够完全发挥。
2.2 特征提取网络模型结构
在特征提取阶段,本文选取在ImageNet 数据集上已经预训练过的ResNet50[28]自动进行提取船舶图像特征,图像通道数定为3,图像尺寸为600 像素×1 000 像素。将该网络最后一层的卷积层得到的特征图高宽为35×63(约为原图的1/16)自动提供给网络的第二部分,用来回归出船舶的位置并进行分类。
2.3 改进的位置敏感区域池化层介绍

Fig.2 Improved R-FCN schematic diagram图2 改进的区域全卷积网络示意图
由于原始R-FCN 中的位置敏感区域池化层的特殊性,原始R-FCN 生成的Feature Map 的通道数根据检测类别数来确定,在PASCAL VOC 数据集中,20 是其目标检测数,因此在原始R-FCN 中的c+1=21,若用R-FCN 对船舶进行检测,则c+1=4 会造成特征Feature Map 的通道数变为原来的1/5,整个网络架构相对于原始的R-FCN 将会变得非常畸形。本文尝试将c减小,发现模型失调,并且不能提取足够的特征用以识别船舶,无法用于船舶识别。
因此本文对位置敏感区域池化层进行了更适合船舶检测的优化改进,如图3 所示,通过RPN(region proposal network)能够得到ROIs 的位置。此步骤完成后,将Feature Map 与该位置结合,对位置敏感区域池化层进行改进,同时生成位置敏感分数图(positionsensitive score maps),通道数为k2(c+1),且c=20,与原始R-FCN 的c数量保持一致。再对位置敏感分数图做全局最大值池化(Maxpooling),得到长度为k2(c+1)的Feature Vector。最后对Feature Vector 做全连接操作后放入SoftMax 中进行分类。在这一基础上,又将原本的ROIPooling 层改为了ROIAlign,该方法取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
改进后的位置敏感区域池化层具体操作是:对于1 个大小为w×h的ROI,将该ROI 分割成k2个宽高分别为w/k、h/k的矩形方块,并使用(i,j)来表示ROI 和位置敏感分数图的每个分块的位置,且(i,j)取值范围(0 ≤i≤k-1,0 ≤j≤k-1)。具体操作如式(1):

式中,rc(i,j|θ)为位置敏感分数图第c个通道中k2个分块中的第(i,j)个分块,Zi,j,c为Feature Map 中第c通道的Map,且c的取值范围为0 ≤c≤k2(c+1)。bin(i,j)代表ROI 中k2个分块中第(i,j)个分块对应在Feature Map 中位置集合,(x0,y0) 表示ROI 的左上角坐标,(x,y)表示ROI 中以(x0,y0)为原点时每个元素的坐标值,且(x,y)的取值范围为i×w/h≤x≤(i+1)×w/h,n表示第(i,j)个块里的像素总数,且θ表示网络的参数。
接着对通道数为k2(c+1)的位置敏感分数图做最大值池化操作,如式(2)所示:

式(2)中的Vc(θ)表示Feature Vector。Max 表示每个位置敏感分数图中的最大值。然后对向量做Fully Connect,如式(3)所示:

最后对特征向量做Softmax 分类操作,如式(4)所示:

在网络训练阶段,采用梯度下降的训练方法,总的损失函数为每个ROI 的交叉熵损失以及边界框回归损失之和,如式(5)所示:
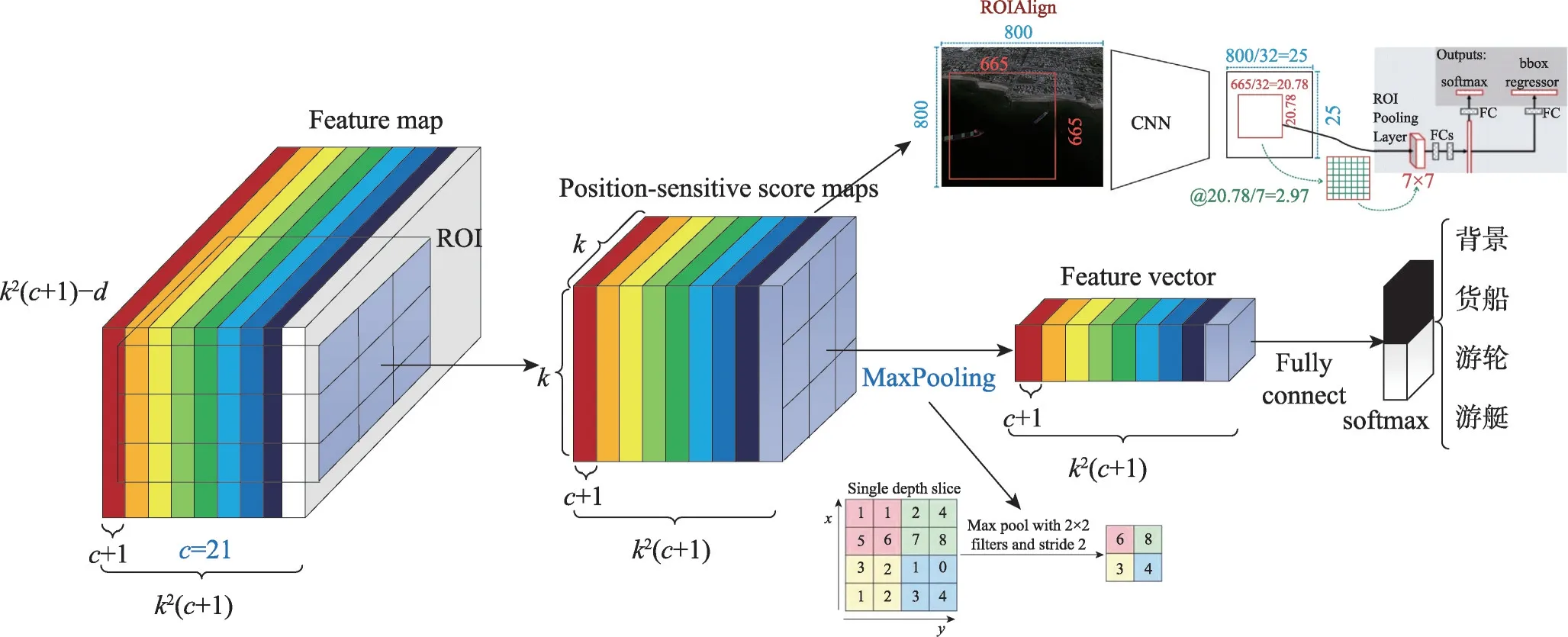
Fig.3 Improved position-sensitive ROI pooling layer图3 改进的位置敏感兴趣区域池化层

上述公式中λ=1,c*表示ROI的类标(c*=0 时,表示这个ROI是背景类),Lreg中的表示真实的回归框的参数,由RPN 得到的回归框的参数用t=(tx,ty,tw,th)表示,并且t*和t与faster R-CNN 中的边界回归框的参数相同。损失函数R为SmoothL1(x)如式(6)所示:

相比于L1与L2,SmoothL1在趋近于0时表现得更平滑,能够使得模型更加稳定。简而言之,SmoothL1“光滑”后的L1保留了L1Loss 中梯度稳定的特点,同时吸取了L1Loss 中中心点不可求导的缺陷,引入了L2Loss 中的中心点附近的部分作为分段函数,并克服了L2Loss 在数据较大时梯度很大的缺陷,使Loss函数更具鲁棒性。对比图如图4 所示。
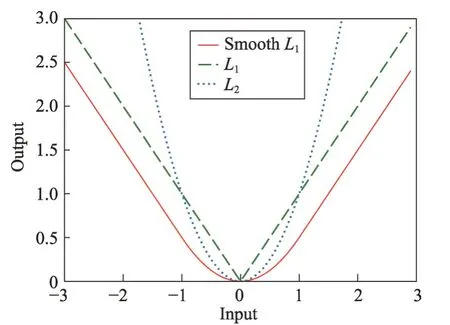
Fig.4 Comparison of 3 loss functions图4 3 种损失函数对比
原版的R-FCN 使用的是ROIPooling,类比于ROIPooling,ROIAlign 的反向传播则进行了修改:在ROIAlign 中,由前向传播计算后,xi*(r,j)表示的是浮点数的坐标位置(采样点),在池化前的特征图中,每一个与xi*(r,j)横纵坐标均小于1 的点都应该接受与此对应的点yij回传的梯度,故ROIAlign 的反向传播如式(7)所示:

在传统的以Faster-RCNN 检测框架为基础的网络结构中,由于步长(Stride)的存在,故使得每次缩放之后的边长均有可能出现小数,若此时使用量化操作,在映射回原图像时,特征图上很小的误差经过步长放大之后会使得误差变大,导致与原图不匹配的情况,故本文使用了双线性内插的方式代替了原有的量化操作,即不对浮点数进行边界量化操作,而是直接使用双线性内插对候选区域进行插值计算,用以减小缩放导致的误差。
3 建立训练数据库
本实验选择的数据集是2017 年CCF 大数据与计算智能大赛(big data & computing intelligence,BDCI)主办方方一信息科技公司提供的海上船舶图像。分辨率为1 024×1 024,场景分为两类,清晰和非清晰,船舶共有3 类,游轮、游艇以及货船。笔者经过筛选,提取了其中有标签并可以用于训练与测试的图片共5 560 张,4 448 张作为训练样本,1 112 张作为测试样本。图5 显示的是该数据集部分用于测试的原图,可以看到背景复杂,存在云、雾等元素。
4 实验结果及分析
本文实验是在Windows 10 系统下,使用Visual Studio 2013进行的,采用Anaconda+Pycaffe 框架,Python为2.7,GPU是GTX 1080,CPU是Intel Core i7。
本文采用准确率(Precision)、召回率(Recall)、平均准确率(average precision,AP)和平均准确率均值(mean average precision,mAP)等多个参数来综合衡量检测算法的效果。式(8)和式(9)分别是准确率和召回率的计算公式,其中PR表示准确率,RR表示召回率,TP表示正确识别的目标数量,FP表示错误判断为目标的数量,FN表示漏检目标数量。
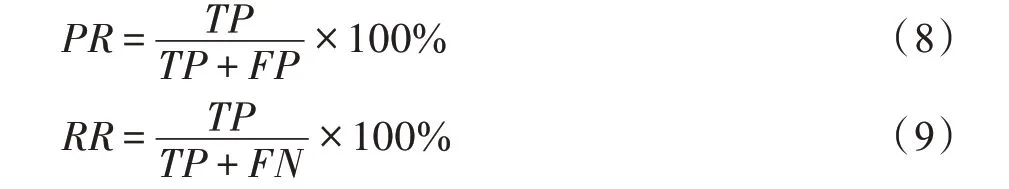
本文中的召回率与准确率的计算方式如下,比如对参照货船分析,测试集图像共有货船K个,训练好的模型检测的目标数为N个,其中确实为货船的有M个,因此召回率和准确率定义为:召回率Recall=M/K,准确率Precision=M/N。

Fig.5 Part of original images of test dataset图5 部分测试数据集原图

Fig.6 Part of test results images图6 部分测试结果图
图6 为本文改进的R-FCN 与图5 中相对应的检测结果,分别用红色、绿色以及蓝色来区分三种船舶的类别,红色代表货船,绿色代表游轮,蓝色代表游艇,每个船舶的匹配率也在图上进行了标注。
在目标检测中,主要通过召回率-准确率(P-R)曲线衡量一个分类器的性能指标,横纵轴分别为Recall和Precision,式(10)中,PR、RR分别表示准确率和召回率。衡量一个学习器是否比另一个更优,则观察PR图呈现的效果可以得出结论,AP越大,即两个参数的曲线和坐标轴之间的面积越大,代表检测器的检测效果越好。若A学习器可以完全包住B学习器,则A的性能优于B。


Fig.7 Cargo ships’P-R image图7 货船的P-R 图

Fig.8 Cruise ships'P-R image图8 游轮的P-R 图

Fig.9 Yachts'P-R image图9 游艇的P-R 图
为了更直观地验证目标检测网络的性能,检测性能的衡量标准使用PASCAL VOC 竞赛的衡量标准mAP。图7~图9 分别是货船、游轮以及游艇的P-R图,图中实线代表初始的R-FCN(已做防止过拟合处理);虚线代表第一次改进的R-FCN,命名为improved-R-FCN-1,这里c=21,将原版的平均池化层改成了最大池化层;点线代表第二次改进的R-FCN,命名为improved-R-FCN-2,这里c=21,在improved-R-FCN-1 的基础上,将ROIPooling 改成ROIAlign。三个模型在三种船舶上AP的表现在图的最上方也进行了标注。
通过直观的比对可以看出,图7 和图8 中货船和游轮的AP的提升幅度较小,但本文中改进的两个版本基本完全包住了原始的R-FCN,因此本文模型在货船和游轮的表现上的性能更优。图9 中,improved-R-FCN-1中游艇的AP比原始的R-FCN 提升了4.08个百分点,而improved-R-FCN-2 相比于improved-R-FCN-1又提升了8.78 个百分点,比原版的R-FCN 提升了近13 个百分点,并且本文中两个模型的曲线完全包住了原始的R-FCN。由于游艇的体积相比另外两种船舶体积很小,本文认为全局最大值池化以及ROIAlign 这两个变化使得本文模型在小目标的检测表现上更优。
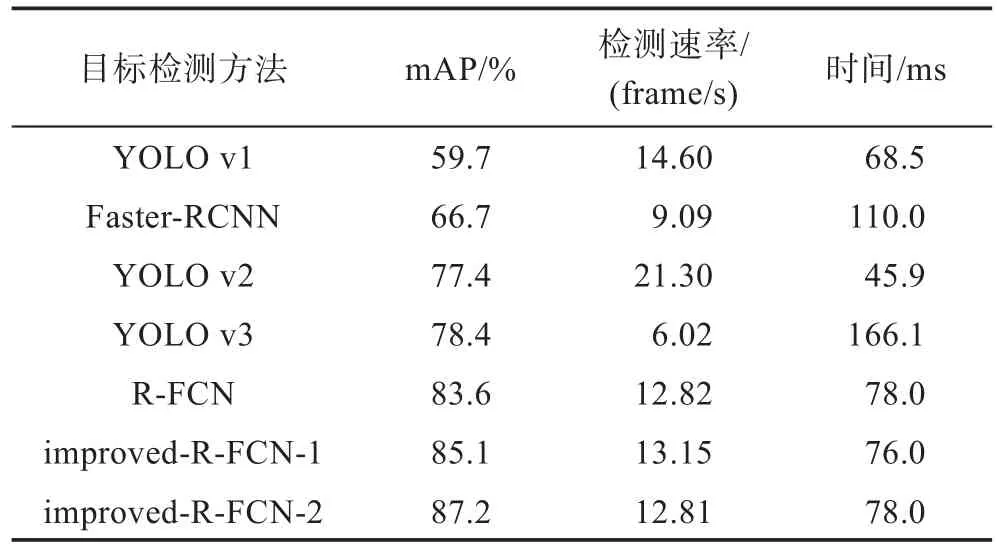
Table 1 Experimental results of each target detection method表1 各目标检测方法实验效果
本文还与其他目前深度学习的目标检测方法进行了对比。如表1所示,在本实验条件下,设定IOU>0.5即目标检测正确,对比的算法有YOLO 系列模型、Faster-RCNN,可以看出本文模型在该数据集上mAP值的表现要更好,Faster-RCNN 的mAP 为66.7%,YOLO 系列方面,最新的YOLO v3 的mAP 为78.4%。本文模型与原始的R-FCN 相比,mAP 从83.6%提升到了87.2%。本文采用每秒帧数指标来衡量算法的时效性。从表1 中可以看出,本文模型的检测速率与其他方法基本持平,但识别精度更高。因此,实验结果表明,本文模型能够解决船舶识别过程中因船舶过小而识别率过低的问题,并且在较大船舶的识别上也能完成准确率的提升以及性能的优化。
5 结束语
本文模型在光学图像上的船舶识别表现优于其他深度学习的算法,在此数据的表现上,将mAP 值提高到了87.2%,同时在测算速率上也与其他主流方法基本持平,通过分析实验结果,总结以下四点因素使得本文模型在船舶识别上表现更优:(1)结合船舶识别与R-FCN 的特性,在ROIPooling 之前,使得特征层数量达到c+1=21 层,避免了模型在层数过低的情况下有可能出现的过拟合及模型失调等情况。(2)将ROIPooling 由全局平均池化改为全局最大值池化,提升了显著特征的保留数量,同时也避免了部分由于卷积层参数的误差而导致的均值偏移。(3)ROIAlign对于原ROIPooling,提出了取消量化操作,使用双线性内插法进行特征点的计算,从而将特征提取过程转化为一个连续的特征采样过程。通过在映射过程取消了取整操作的做法,变相提升了采样点的数量。(4)SmoothL1的特性是在x较小时,x梯度很小,避免了等梯度(L1)条件下x极小时梯度保持不变的缺陷,在x很大时(otherwise),x梯度上限为1,避免了过大梯度导致的网络参数失调,即有效避免了梯度爆炸(L2),使模型稳定性更高。随着大数据与云计算的不断发展,船舶检测上的研究也会不断深入,监测船舶的效率与准确度,反馈数据的真实性与实效性都对海洋经济起到积极的作用。
