基于Seq2Seq 模型的自定义古诗生成*
2020-06-11王乐为张应龙
王乐为,余 鹰,张应龙
华东交通大学 软件学院,南昌330013
1 引言
在文本生成领域,古诗生成一直是专家学者们关注与研究的热点内容之一,其中常用的模型包括:基于给定规则的生成模型[1-2]、基于文本生成算法的生成模型[3-4]、自动摘要模型[5]和基于统计的机器翻译模型[6-7]等。近年来,伴随着深度学习技术的发展,基于循环神经网络(recurrent neural network,RNN),如长短时记忆网络(long short-term memory,LSTM)、门控循环单元(gated recurrent unit,GRU)等[8],也被广泛应用于古诗生成,并取得了一定的效果。
在进行古诗生成时,人们往往希望能得到一段与某种意境相符的诗句,为此会提前输入几个表达意境的关键字或词,对古诗的生成进行控制指导。当采用经典RNN 模型生成诗句时,首先预先给定一个关键字,然后系统会生成以该关键字为起始的诗句,随机性较大,诗句所蕴含的意境一般很难达到要求。例如,要生成一句能表达在船中把酒言欢意境的诗句,若采用经典RNN 模型,则只能分别给定“船”或“酒”作为起始字来生成诗句,很难将二者同时融合在一句诗中,从而达不到一种既有“船”又有“酒”的意境效果。这是因为,经典RNN 模型虽然在训练阶段采用了N-N模式,即输入N个文字,输出N个文字,但在预测阶段则采用了1-N模式,即输入1 个关键字,生成N个文字。由于只能控制起始字符,使得生成的诗句随机性较大,最终的生成效果无法控制。
经典RNN 模型要求输入和输出序列等长,但现实中大部分问题序列是不等长的,序列到序列模型(sequence to sequence,Seq2Seq)对此进行了改进。Seq2Seq 模型又称Encoder-Decoder 模型,它突破了输入与输出序列必须等长的限制,在Encoder 端输入N个文字,在经编码后传给Decoder 端,再解码成M个文字。文献[9-10]基于Seq2Seq 模型,实现了基于多个文字的古诗生成,但其缺点在于仅对第一句诗的输出产生影响,无法将输入的关键字信息体现在整首古诗中。Attention 机制将Encoder 端传给Decoder端的编码进行了针对性加权合成,在不同时刻赋予Decoder端不同的Encoder编码,即它能够在不同的时刻考虑不同的输入信息,然后根据每个输入文字生成包含该文字的诗句。加入Attention 机制[11]的Seq2Seq模型结构在机器翻译上已取得非常好的效果,在机器翻译任务上,输入端的每个词在输出端往往都有其对应的翻译词。
因此,本文基于Seq2Seq 模型构建古诗生成模型,将关键字作为源语言,包含关键字的古诗句作为目标语言,并引入Attention 机制对其进行训练,克服了文献[8-10]所提算法的缺点,使得最终生成的古诗每一句内容可控。在预测阶段,如果从描述性信息中提取的关键字不足,则通过word2vec[12]方法,寻找相似的关键字对输入信息进行补充。此外,针对已有的古诗生成模型在生成五言或七言古诗时随意性较大的问题,通过加入格式控制符,结合Attention 机制,有效地控制了古诗的体裁。
2 相关工作
2.1 Seq2Seq 模型
Seq2Seq 模型又称作Encoder-Decoder 模型[13],设有一组输入序列集合XN和输出序列集合YN,N表示样本总数,第i个样本的输入和输出序列分别为xi1,xi2,…,xis和yi1,yi2,…,yip。s和p分别代表第i个样本的输入和输出序列的字符个数。该模型可以计算出在某输入序列样本xi发生的情况下,输出序列样本yi发生的概率,其中vi表示第i个样本的输入序列xi1,xi2,…,xis经Encoder 端得到的隐含状态向量。
Decoder 端在t时刻第i个样本的概率分布为P(yit|vi,yi1,yi2,…,yi(t-1))=f(hi(t-1),yi(t-1),vi),其与Decoder端上一时刻的隐含状态hi(t-1)以及输出yi(t-1)还有Encoder 端的状态向量vi相关,其中f(⋅)是Decoder端中的LSTM 的输出。因此Seq2Seq 模型需使输入训练样本的输入序列能得到对应输出序列的概率之和最 大,对 应 的对数似然条件概率函数为,使之最大化,θ是待确定的模型参数。
2.2 Attention 机制
最基本的Seq2Seq 模型包含一个Encoder 和一个Decoder,通常的做法是将一个输入的句子编码成一个固定大小的状态信息,然后作为Decoder 的初始状态,但这个状态对于Decoder 中所有时刻都相同。随着序列的不断增长,Decoder 端的解码过程将表现越来越差。
加入Attention 机制后,Encoder 端可赋予输入序列不同时刻的隐层特征不同的权重,在Decoder 端解码的不同时刻,都会接受来自Encoder 端经不同加权组合的信息,从而达到在不同解码阶段有着不同的输入信息。
假设x1,x2,…,xs为输入序列,在Encoder 端的隐层向量为h1,h2,…,hs,另外zo为Decoder 端的初始状态向量,计算每个隐层向量与zo的相似度a1,a2,…,as,使用softmax函数将其转化成,传入给Decoder 端作为输入,根据zo和c0计算得到Decoder 端新的隐状态向量z1,再计算Encoder 端的隐层向量与z1相似度,再得到c1,如此循环,直到解码过程全部结束。
3 基于Seq2Seq 模型的古诗生成模型
使用引入Attention 机制的Seq2Seq 模型进行古诗生成时,将整个过程划分为训练和预测两个阶段。在训练阶段,首先创建训练数据集,每条训练数据的Encoder 输入部分包含四个关键字及一个格式控制符。格式控制符主要用来控制古诗的体裁,例如五言或七言。Decoder 输出部分则为每句都包含对应关键字的一首古诗。在预测阶段,用户输入一段描述性文字,系统从中提取出关键字并传给模型的Encoder 端,若Encoder 端的输入不足四个关键字,则通过word2vec方法进行关键字补全。
3.1 模型结构
图1 给出了t时刻古诗生成模型的结构图,Encoder 端和Decoder 端均使用LSTM 模型,Encoder数据集中存放了关键字。在训练时,输入5 个关键字符,用x1、x2、x3、x4、x5表示,其中x5是格式控制符,在“A”和“B”间选择,“A”表示生成五言古诗,“B”表示生成七言古诗。h1、h2、h3、h4、h5表示在不同时刻输入信息在Encoder 端中经LSTM 处理输出的对应隐状态。
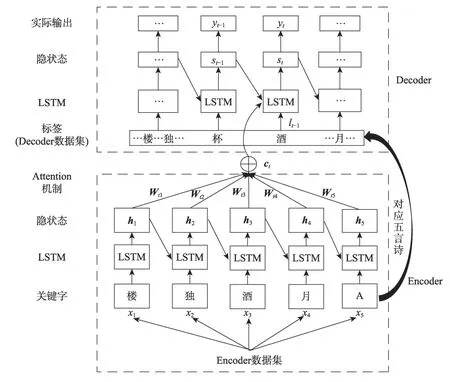
Fig.1 Model structure图1 模型结构
首先计算在t时刻输入Decoder 端的隐藏层状态st-1对Encoder 每一个隐含层状态hi的权重wt(i),如式(1)所示。
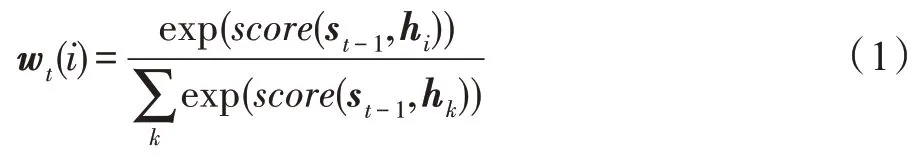
其中,score表示st-1和hi的相似度,使用余弦相似度进行度量,如式(2)所示。
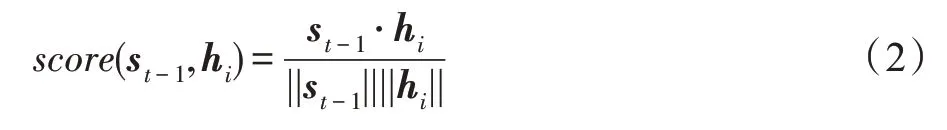
接着利用权重wt(i)计算Encoder 端所有隐藏层状态hi加权之和ct,即在t时刻整个Encoder 端最终输出的状态向量,计算方法如式(3)所示。

在训练阶段,需将ct和Decoder 隐藏层的t时刻状态st-1以及t-1 时刻的真实标签lt-1作为t时刻Decoder 的输入,经LSTM 处理得到yt。在预测阶段,则将lt-1换成t-1 时刻的实际输出yt-1,yt的计算如式(4)所示。

为了减少计算量,在训练阶段,采用Sampled Softmax 作为输出层,对应的全连接层矩阵为,在预测阶段使用普通的Softmax 作为输出层,全连接层矩阵用Wout表示。其中f(⋅) 是Decoder 端中的LSTM,Wout是Decoder 端中连接LSTM 输出的全连接层,另外st-1和ct每次都需要更新,其中ct随着st-1的更新而更新,st的更新方法如式(5)所示。

3.2 关键字补全
为了生成一首古诗,需要先输入一段表达需求的描述性语言,然后从这段描述性语言中提取出关键字作为输入信息。当提取的关键字数量不足时,需对关键字进行补充,但是所补充的关键字应与已提取的关键字具有较高的相关度。因此,首先采用word2vec 方法获取Encoder 词库中每个关键字的词向量kwm,然后利用余弦相似度度量词库中的关键字kwm与已提取关键字kwn之间的相似度sim(m,n)=。
为了简化计算,在使用word2vec 方法时,每首古诗仅保留关键字部分,并将其作为word2vec方法的上下文,而不是将整首诗作为上下文。同时,将word2vec中的窗口大小设置为7,词向量维度设置为200,选取skip-gram 模型进行处理,具体过程如图2 所示。
此外,在进行关键字补充时,如果在描述内容中仅提取出一个关键字,则选取与该关键字相关度最高的三个作为补充;如果提取出两个关键字,则随机从与每个关键字相关度最高的前三个中分别选取一个作为另外两个关键字;如果提取三个关键字,则分别计算与每个关键字相似度最高的前三个,取其交集作为第四个关键字,如果交集为空,则随机选取三个关键字中的一个,再随机选取与其相似度最高的前三个中的一个作为第四个关键字,具体过程如图3所示,其中括号里的值表示相似度大小。
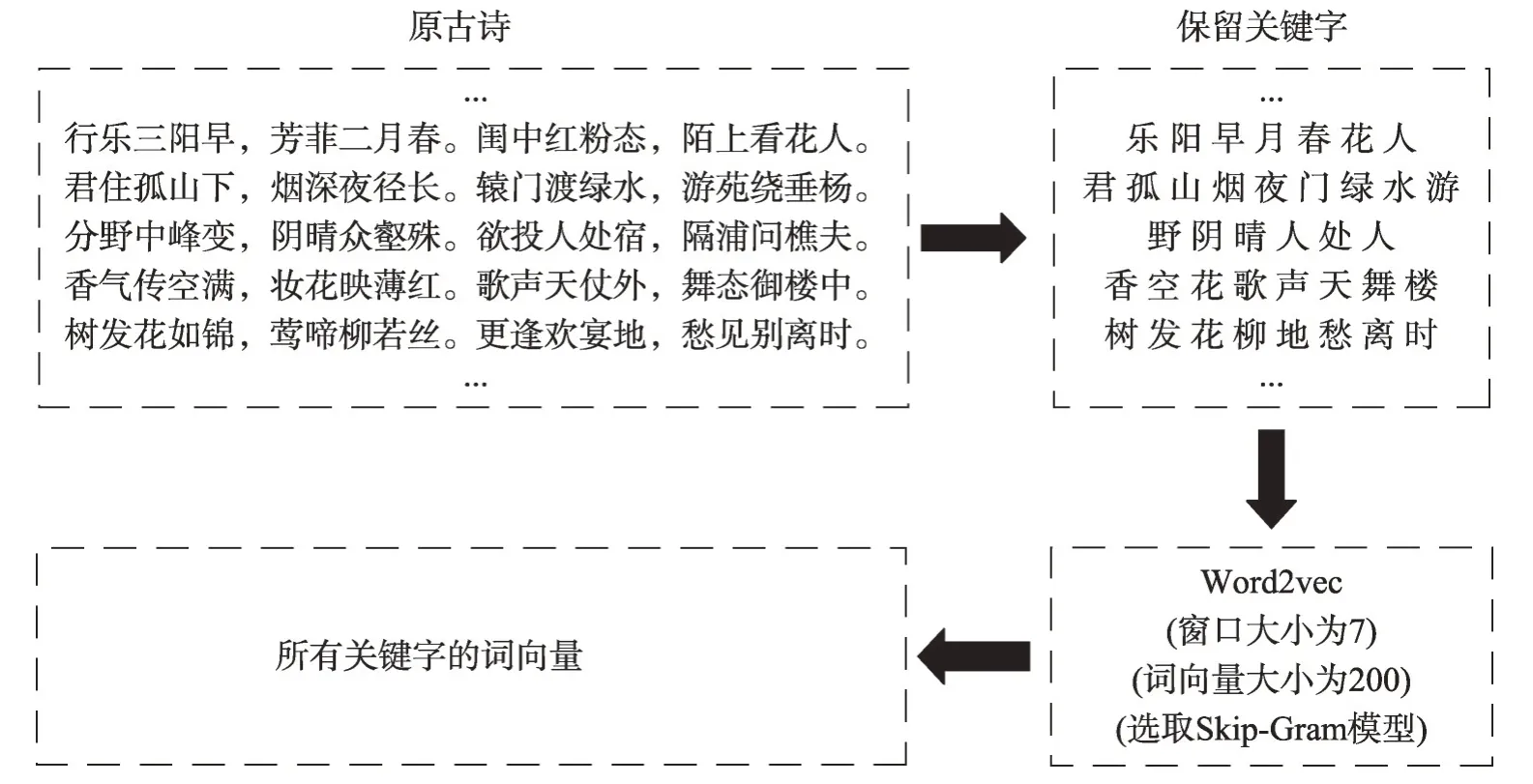
Fig.2 Use word2vec to turn keywords into vectors图2 使用word2vec将关键字转化为向量
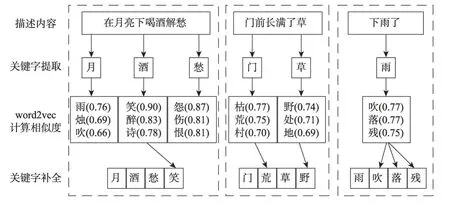
Fig.3 Keyword completion operation图3 关键字补全操作
4 实验与分析
4.1 数据集构建
为了完成实验,人工收集整理了四万多首唐诗,用于构建实验数据集。首先将原唐诗中的八句诗转换成两首四句诗,并统计所有字的字频,取出频率最高的前200 个字作为Encoder 的词库,然后遍历每首唐诗中存在于该词库中的字,用排列组合的方式分别对关键字进行匹配,先对前两句和后两句进行部分排列组合,再进行整体排列组合,所有关键字的组合作为Encoder数据集部分,对应诗句则作为Decoder数据集部分。此外,如果是五言诗,则在Encoder 数据集中的每一个关键字组合后加上格式控制符“A”,如果是七言诗,则加上“B”。经过处理,最终得到27万对信息,将其中的23 万对作为训练集,另外4 万对作为测试集。数据集的构建过程如图4 所示,具体数据集样本展示如图5 所示。
4.2 模型参数
本文Encoder 和Decoder 都使用了LSTM 模型,隐层数量都为三层,每层神经元个数为256 个。每个字的Embedding Size 大小为256,为了使模型更快地收敛,在训练阶段,Decoder 端每个时刻的输入没有采用上个时刻的输出,而是使用真实样本作为输入,且使用了Sampled SoftMax[14],采样个数为512。batch size 设置为64,优化过程选择随机梯度下降算法,初始学习率(learning rate)设置为0.5,学习率衰减(learning rate decay)设置为0.9。
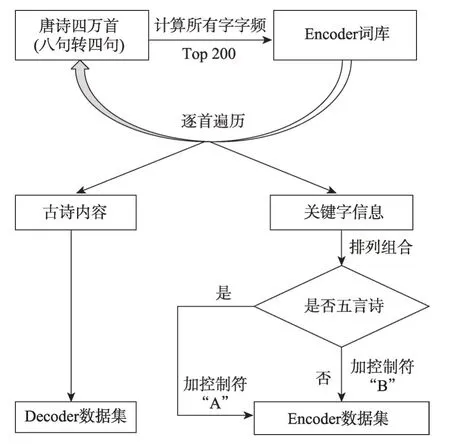
Fig.4 Data set construction process图4 数据集构建过程
4.3 评价指标
由于古诗的评价涉及到多个方面,就目前而言还没有具体的古诗生成评价指标,虽然有不少学者借助机器翻译中的BLEU(bilingual evaluation understudy)评价指标[15],但并不能真实反映古诗的生成效果,其主要问题在于古诗中的韵律、意义等方面无法用具体的指标表达,但古诗的流畅度是可以通过语言模型的方法进行一定的评价,故本文首先选择了困惑度指标Perplexity,该指标表示在逐字生成语句时,每个字生成的可选择性大小。该指标越小,说明在每个字生成时的可选择性越少越具体,最终的句子出现的概率越大,句子质量也越高,模型生成效果越好,Perplexity 的计算如式(6)所示。
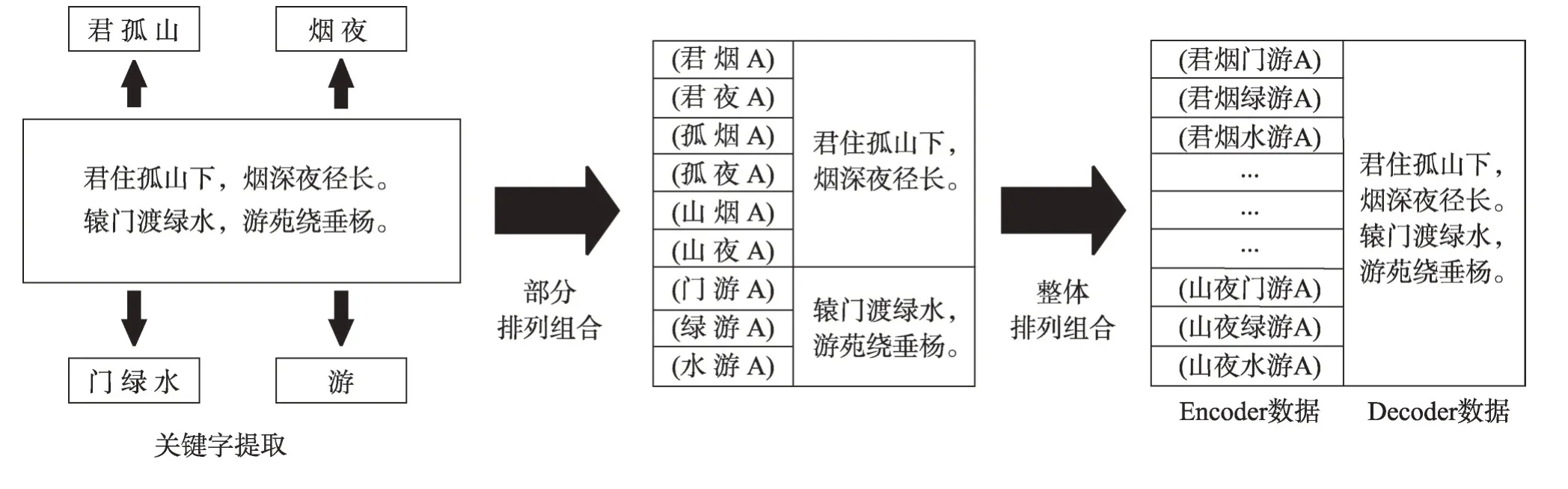
Fig.5 Data set samples display图5 数据集样本展示

此外,由于仅使用Perplexity 评价指标并不能充分体现出所生成诗句的好坏,因此额外选择了主观的人工评价指标,即选取了30 位硕士学历以上的文学专业的学者从流畅度、韵律、意义三方面对本文的方法和一些基准方法进行了打分和比较。
4.4 实验分析

Fig.6 Perplexity values图6 Perplexity 指标
本文每间隔300 步在训练集和测试集上分别使用困惑度指标Perplexity 对五言古诗和七言古诗进行评价,如图6 所示。实验结果表明在训练集上,不论五言还是七言古诗困惑度都会随着训练步数的增加而降低,模型具有较好的收敛效果。而在测试集上,当训练到20 000 步左右时,五言和七言古诗的困惑度指标都开始上升,模型出现了过拟合现象。另外一点是,相比七言古诗而言,五言古诗有着更低的Perplexity值。
分别选取五言和七言Perplexity最低时的模型用来生成古诗,采用人工评价的方法,本文对比了三种基准方法:SMT(statistical machine translation models)、RNNPG(recurrent neural networks for poetry generation)、ANMT(attention-based neural machine translation)。其中SMT 模型使用了统计机器翻译的方法,RNNPG模型整合了CNN(convolutional neural network)、句子级别的RNN、字符级别的RNN,ANMT 使用了基于神经网络的机器翻译模型,结果如表1 所示。
相比基准模型,本文模型在流畅度、韵律、意义上都取得较好效果,其中五言诗的效果在三方面都取得一定提升,而七言诗在流畅度及韵律上较ANMT模型略显不足,但在意义上不论五言还是七言诗的生成效果都得到提升,这源于本文使用了基于注意力机制的编码方法,在不同时刻生成诗句时考虑到不同的关键字信息,从而生成更有意义的诗句。本文的模型较SMT 和RNNPG 都显得有很大提升,这在一定程度上也说明了Seq2Seq 模型相比于传统的基于语言模型的生成方法有着更好的效果。
为了展示本文模型的生成效果,表2 分别给出了一首五言和七言古诗的示例展示。在五言诗的生成中,先从描述内容中提取出“月”“风”“叶”“孤”这四个关键字,最后生成的诗句中也都体现了这四个关键字的信息,且整体上表现出了“一个人寂寞和孤独”的意境效果。在七言诗的生成中,同样也从描述中提取出了“夜”“酒”“雨”“愁”四个关键字,最后所生成的诗句不仅体现出关键字信息,还创造出一种“在船上送别友人,充满了离愁之情”的画面效果。

Table 1 Manual evaluation表1 人工评价结果
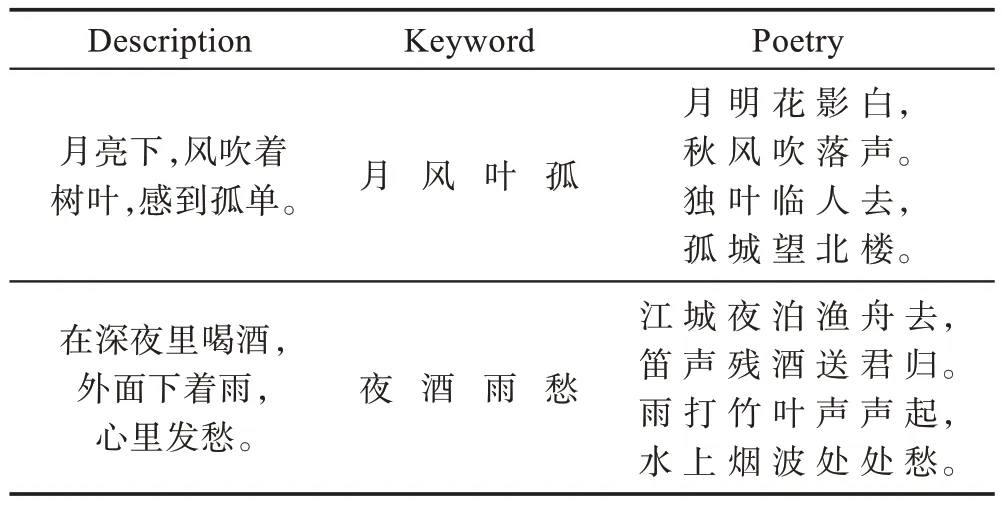
Table 2 Poetry generation examples表2 古诗生成示例
5 结束语
本文基于Seq2Seq 模型构建了古诗生成模型,将编码、解码和Attention 机制运用到了古诗生成上。设计和构建了相应的古诗生成数据集,并加入了关键字控制符的概念,在关键字不足时,可进行关键字补全,与传统的古诗生成任务相比,显得更加灵活可控,能够生成与大致意境相符的诗句。在接下来的工作中,将加入生成对抗和强化学习的思想,让古诗的生成更加丰富,更加符合人们的审美。
